
浅谈神经网络
先从回归(Regression)问题说起。我在本吧已经看到不少人提到如果想实现强AI,就必须让机器学会观察并总结规律的言论。具体地说,要让机器观察什么是圆的,什么是方的,区分各种颜色和形状,然后根据这些特征对某种事物进行分类或预测。其实这就是回归问题。
如何解决回归问题?我们用眼睛看到某样东西,可以一下子看出它的一些基本特征。可是计算机呢?它看到的只是一堆数字而已,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。
例:假如有一串数字,已知前六个是1、3、5、7,9,11,请问第七个是几?
你一眼能看出来,是13。对,这串数字之间有明显的数学规律,都是奇数,而且是按顺序排列的。
那么这个呢?前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几?
这个就不那么容易看出来了吧!我们把这几个数字在坐标轴上标识一下,可以看到如下图形:
用曲线连接这几个点,延着曲线的走势,可以推算出第七个数字——7。
由此可见,回归问题其实是个曲线拟合(Curve Fitting)问题。那么究竟该如何拟合?机器不
可能像你一样,凭感觉随手画一下就拟合了,它必须要通过某种算法才行。
假设有一堆按一定规律分布的样本点,下面我以拟合直线为例,说说这种算法的原理。
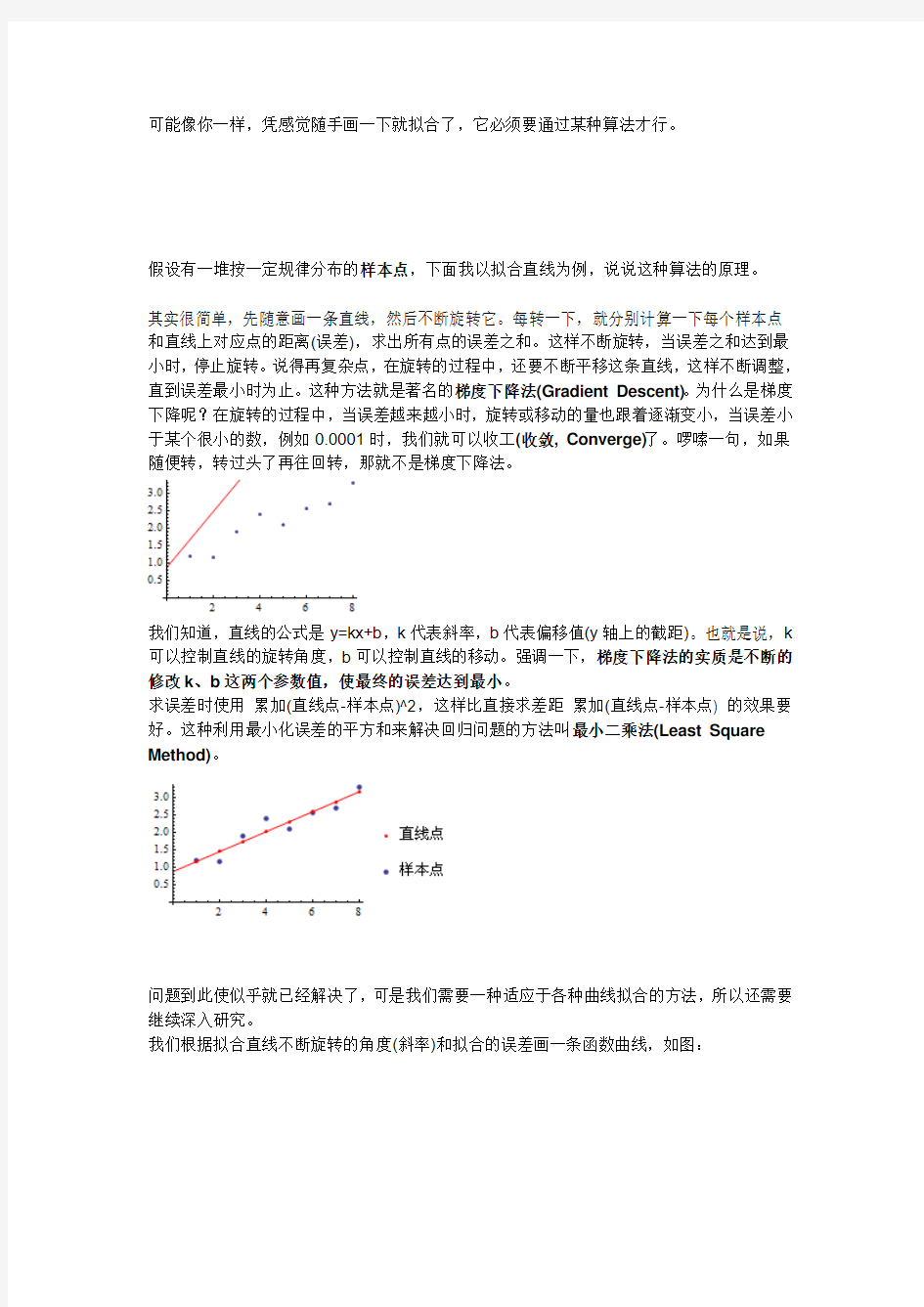
其实很简单,先随意画一条直线,然后不断旋转它。每转一下,就分别计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是著名的梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数,例如0.0001时,我们就可以收工(收敛, Converge)了。啰嗦一句,如果随便转,转过头了再往回转,那就不是梯度下降法。
我们知道,直线的公式是y=kx+b,k代表斜率,b代表偏移值(y轴上的截距)。也就是说,k 可以控制直线的旋转角度,b可以控制直线的移动。强调一下,梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。
求误差时使用累加(直线点-样本点)^2,这样比直接求差距累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。
问题到此使似乎就已经解决了,可是我们需要一种适应于各种曲线拟合的方法,所以还需要继续深入研究。
我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图:
从图中可以看出,误差的函数曲线是个二次曲线,凸函数(下凸, Convex),像个碗的形状,最小值位于碗的最下端。如果在曲线的最底端画一条切线,那么这条切线一定是水平的,在图中可以把横坐标轴看成是这条切线。如果能求出曲线上每个点的切线,就能得到切线位于水平状态时,即切线斜率等于0时的坐标值,这个坐标值就是我们要求的误差最小值和最终的拟合直线的最终斜率。
这样,梯度下降的问题集中到了切线的旋转上。切线旋转至水平时,切线斜率=0,误差降至最小值。
切线每次旋转的幅度叫做学习率(Learning Rate),加大学习率会加快拟合速度,但是如果调得太大会导致切线旋转过度而无法收敛。
注意:对于凹凸不平的误差函数曲线,梯度下降时有可能陷入局部最优解。下图的曲线中有两个坑,切线有可能在第一个坑的最底部趋于水平。
微分就是专门求曲线切线的工具,求出的切线斜率叫做导数(Derivative),用dy/dx或f'(x)表示。扩展到多变量的应用,如果要同时求多个曲线的切线,那么其中某个切线的斜率就叫偏导数(Partial Derivative),用?y/?x表示,?读“偏(partial)”。由于实际应用中,我们一般都是对多变量进行处理,我在后面提到的导数也都是指偏导数。
以上是线性回归(Linear Regression)的基本内容,以此方法为基础,把直线公式改为曲线公式,还可以扩展出二次回归、三次回归、多项式回归等多种曲线回归。下图是Excel的回归分析功能。
在多数情况下,曲线回归会比直线回归更精确,但它也增加了拟合的复杂程度。
直线方程y=kx+b改为二次曲线方程y=ax^2+bx+c时,参数(Parameter)由2个(分别是k、b)变为3个(分别是a、b、c),特征(Feature)由1个(x)变为2个(x^2和x)。三次曲线和复杂的多项式回归会增加更多的参数和特征。
前面讲的是总结一串数字的规律,现实生活中我们往往要根据多个特征(多串数字)来分析一件事情,每个原始特征我们都看作是一个维度(Dimension)。例如一个学生的学习成绩好坏要根据语文、数学、英语等多门课程的分数来综合判断,这里每门课程都是一个维度。当使用二次曲线和多变量(多维)拟合的情况下,特征的数量会剧增,特征数=维度^2/2 这个公式可以大概计算出特征增加的情况,例如一个100维的数据,二次多项式拟合后,特征会增加到100*100/2=5000个。
下面是一张50*50像素的灰度图片,如果用二次多项式拟合的话,它有多少个特征呢?——大约有3百万!
它的维度是50*50=2500,特征数=2500*2500/2=3,125,000。如果是彩色图片,维度会增加到原来的3倍,那么特征数将增加到接近3千万了!
这么小的一张图片,就有这么巨大的特征量,可以想像一下我们的数码相机拍下来的照片会有多大的特征量!而我们要做的是从十万乃至亿万张这样的图片中找规律,这可能吗?
很显然,前面的那些回归方法已经不够用了,我们急需找到一种数学模型,能够在此基础上不断减少特征,降低维度。
于是,“人工神经网络(ANN, Artificial Neural Network)”就在这样苛刻的条件下粉墨登场了,神经科学的研究成果为机器学习领域开辟了广阔的道路。
神经元
有一种假说:“智能来源于单一的算法(One Learning Algorithm)”。如果这一假说成立,那么利用单一的算法(神经网络)处理世界上千变万化的问题就成为可能。我们不必对万事万物进行编程,只需采用以不变应万变的策略即可。有越来越多的证据证明这种假说,例如人类大脑发育初期,每一部分的职责分工是不确定的,也就是说,人脑中负责处理声音的部分其实也可以处理视觉影像。
下图是单个神经元(Neuron),或者说一个脑细胞的生理结构:
下面是单个神经元的数学模型,可以看出它是生理结构的简化版,模仿的还挺像:
解释一下:+1代表偏移值(偏置项, Bias Units);X1,X2,X2代表初始特征;w0,w1,w2,w3代表权重(Weight),即参数,是特征的缩放倍数;特征经过缩放和偏移后全部累加起来,此后还要经过一次激活运算然后再输出。激活函数有很多种,后面将会详细说明。
举例说明:
X1*w1+X2*w2+...+Xn*wn这种计算方法称为加权求和(Weighted Sum)法,此方法在线性代数里极为常用。加权求和的标准数学符号是,不过为了简化,我在教程里使用女巫布莱尔的符号表示,刚好是一个加号和一个乘号的组合。
这个数学模型有什么意义呢?下面我对照前面那个y=kx+b 直线拟合的例子来说明一下。
这时我们把激活函数改为Purelin(45度直线),Purelin就是y=x,代表保持原来的值不变。这样输出值就成了Y直线点= b + X直线点*k,即y=kx+b。看到了吧,只是换了个马甲而已,还认的出来吗?下一步,对于每个点都进行这种运算,利用Y直线点和Y样本点计算误差,把误差累加起来,不断地更新b、k的值,由此不断地移动和旋转直线,直到误差变得很小时停住(收敛)。这个过程完全就是前面讲过的梯度下降的线性回归。
一般直线拟合的精确度要比曲线差很多,那么使用神经网络我们将如何使用曲线拟合?答案是使用非线性的激活函数即可,最常见的激活函数是Sigmoid(S形曲线),Sigmoid有时也称为逻辑回归(Logistic Regression),简称logsig。logsig曲线的公式如下:
还有一种S形曲线也很常见到,叫双曲正切函数(tanh),或称tansig,可以替代logsig。
下面是它们的函数图形,从图中可以看出logsig的数值范围是0~1,而tansig的数值范围是-1~1。
自然常数e
公式中的e叫自然常数,也叫欧拉数,e=2.71828...。e是个很神秘的数字,它是“自然律”的精髓,其中暗藏着自然增长的奥秘,它的图形表达是旋涡形的螺线。
融入了e的螺旋线,在不断循环缩放的过程中,可以完全保持它原有的弯曲度不变,就像一个无底的黑洞,吸进再多的东西也可以保持原来的形状。这一点至关重要!它可以让我们的数据在经历了多重的Sigmoid变换后仍维持原先的比例关系。
e是怎么来的?e = 1 + 1/1! + 1/2! + 1/3! + 1/4! + 1/5! + 1/6! + 1/7! + ... = 1 + 1 + 1/2 + 1/6 + 1/24 + 1/120+ ... ≈ 2.71828 (!代表阶乘,3!=1*2*3=6)
再举个通俗点的例子:从前有个财主,他特别贪财,喜欢放债。放出去的债年利率为100%,也就是说借1块钱,一年后要还给他2块钱。有一天,他想了个坏主意,要一年算两次利息,上半年50%,下半年50%,这样上半年就有1块5了,下半年按1块5的50%来算,就有1.5/2=0.75元,加起来一年是:上半年1.5+下半年0.75=2.25元。用公式描述,就是(1+50%)(1+50%)=(1+1/2)^2=2.25元。可是他又想,如果按季度算,一年算4次,那岂不是更赚?那就是(1+1/4)^4=2.44141,果然更多了。他很高兴,于是又想,那干脆每天都算吧,这样一年下来就是(1+1/365)^365=2.71457。然后他还想每秒都算,结果他的管家把他拉住了,说要再算下去别人都会疯掉了。不过财主还是不死心,算了很多年终于算出来了,当x趋于无限大的时候,e=(1+1/x)^x≈ 2.71828,结果他成了数学家。
e在微积分领域非常重要,e^x的导数依然是e^x,自己的导数恰好是它自己,这种巧合在实数范围内绝无仅有。
一些不同的称呼:
e^x和e^-x的图形是对称的;ln(x)是e^x的逆函数,它们呈45度对称。
神经网络
好了,前面花了不少篇幅来介绍激活函数中那个暗藏玄机的e,下面可以正式介绍神经元的网络形式了。
下图是几种比较常见的网络形式:
- 左边蓝色的圆圈叫“输入层”,中间橙色的不管有多少层都叫“隐藏层”,右边绿色的是“输出层”。
- 每个圆圈,都代表一个神经元,也叫节点(Node)。
- 输出层可以有多个节点,多节点输出常常用于分类问题。
- 理论证明,任何多层网络可以用三层网络近似地表示。
- 一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
计算方法:
- 虽然图中未标识,但必须注意每一个箭头指向的连线上,都要有一个权重(缩放)值。
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
前面讲过,使用梯度下降的方法,要不断的修改k、b两个参数值,使最终的误差达到最小。神经网络可不只k、b两个参数,事实上,网络的每条连接线上都有一个权重参数,如何有效的修改这些参数,使误差最小化,成为一个很棘手的问题。从人工神经网络诞生的60年代,人们就一直在不断尝试各种方法来解决这个问题。直到80年代,误差反向传播算法(BP 算法)的提出,才提供了真正有效的解决方案,使神经网络的研究绝处逢生。
BP算法是一种计算偏导数的有效方法,它的基本原理是:利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。
为了便于理解,后面我一律用“残差(error term)”这个词来表示误差的偏导数。
输出层→隐藏层:残差= -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差= (右层每个节点的残差加权求和)* 激活函数的导数
如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差= -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数= Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差= -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)*输出值*(1-输出值)
隐藏层→隐藏层:残差= (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数= 1 - tansig^2
残差全部计算好后,就可以更新权重了:
输入层:权重增加= 当前节点的Sigmoid * 右层对应节点的残差* 学习率
隐藏层:权重增加= 输入值* 右层对应节点的残差* 学习率
偏移值的权重增加= 右层对应节点的残差* 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
BP神经网络的特点和局限:
- BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
- BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性> 生理相似性。
- BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
- BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
文字的公式看上去有点绕,下面我发一个详细的计算过程图。
这里介绍的是计算完一条记录,就马上更新权重,以后每计算完一条都即时更新权重。实际上批量更新的效果会更好,方法是在不更新权重的情况下,把记录集的每条记录都算过一遍,把要更新的增值全部累加起来求平均值,然后利用这个平均值来更新一次权重,然后利用更新后的权重进行下一轮的计算,这种方法叫批量梯度下降(Batch Gradient Descent)。
例1:我们都知道,面积=长*宽,假如我们有一组数测量据如下:
我们利用这组数据来训练神经网络。(在Matlab中输入以下的代码,按回车即可执行)
p = [2 5; 3 6; 12 2; 1 6; 9 2; 8 12; 4 7; 7 9]'; % 特征数据X1,X2
t = [10 18 24 6 18 96 28 63]; % 样本值
net = newff(p, t, 20); % 创建一个BP神经网络ff=FeedForward
net = train(net, p, t); % 用p,t数据来训练这个网络
出现如下的信息,根据蓝线的显示,可以看出最后收敛时,误差已小于10^-20。
你也许会问,计算机难道这样就能学会乘法规则吗?不用背乘法口诀表了?先随便选几个数字,试试看:
s = [3 7; 6 9; 4 5; 5 7]'; % 准备一组新的数据用于测试
y = sim(net, s) % 模拟一下,看看效果
% 结果是:25.1029 61.5882 29.5848 37.5879
看到了吧,预测结果和实际结果还是有差距的。不过从中也能看出,预测的数据不是瞎蒙的,
至少还是有那么一点靠谱。如果训练集中的数据再多一些的话,预测的准确率还会大幅度提高。
你测试的结果也许和我的不同,这是因为初始化的权重参数是随机的,可能会陷入局部最优解,所以有时预测的结果会很不理想。
例2:下面测试一下拟合正弦曲线,这次我们随机生成一些点来做样本。
p = rand(1,50)*7 % 生成1行50个0~7之间的随机数
t = sin(p) % 计算正弦曲线
s = [0:0.1:7]; % 生成0~7的一组数据,间隔0.1,用于模拟测试
plot(p, t, 'x') % 画散点图
net = newff(p, t, 20); % 创建神经网络
net = train(net, p, t); % 开始训练
y = sim(net, s); % 模拟
plot(s, y, 'x') % 画散点图
从图中看出,这次的预测结果显然是不理想的,我们需要设置一些参数来调整。
人工神经网络控制 摘要: 神经网络控制,即基于神经网络控制或简称神经控制,是指在控制系统中采用神经网络这一工具对难以精确描述的复杂的非线性对象进行建模,或充当控制器,或优化计算,或进行推理,或故障诊断等,亦即同时兼有上述某些功能的适应组合,将这样的系统统称为神经网络的控制系统。本文从人工神经网络,以及控制理论如何与神经网络相结合,详细的论述了神经网络控制的应用以及发展。 关键词: 神经网络控制;控制系统;人工神经网络 人工神经网络的发展过程 神经网络控制是20世纪80年代末期发展起来的自动控制领域的前沿学科之一。它是智能控制的一个新的分支,为解决复杂的非线性、不确定、不确知系统的控制问题开辟了新途径。是(人工)神经网络理论与控制理论相结合的产物,是发展中的学科。它汇集了包括数学、生物学、神经生理学、脑科学、遗传学、人工智能、计算机科学、自动控制等学科的理论、技术、方法及研究成果。 在控制领域,将具有学习能力的控制系统称为学习控制系统,属于智能控制系统。神经控制是有学习能力的,属于学习控制,是智能控制的一个分支。神经控制发展至今,虽仅有十余年的历史,已有了多种控制结构。如神经预测控制、神经逆系统控制等。 生物神经元模型 神经元是大脑处理信息的基本单元,人脑大约含1012个神经元,分成约1000种类型,每个神经元大约与102~104个其他神经元相连接,形成极为错综复杂而又灵活多变的神经网络。每个神经元虽然都十分简单,但是如此大量的神经元之间、如此复杂的连接却可以演化出丰富多彩的行为方式,同时,如此大量的神经元与外部感受器之间的多种多样的连接方式也蕴含了变化莫测的反应方式。 图1 生物神经元传递信息的过程为多输入、单输出,神经元各组成部分的功能来看,信息的处理与传递主要发生在突触附近,当神经元细胞体通过轴突传到突触前膜的脉冲幅度达到一定强度,即超过其阈值电位后,突触前膜将向突触间隙释放神经传递的化学物质,突触有两
%%%清除空间 clc clear all ; close all ; %%%训练数据预测数据提取以及归一化 %%%下载四类数据 load data1 c1 load data2 c2 load data3 c3 load data4 c4 %%%%四个特征信号矩阵合成一个矩阵data ( 1:500 , : ) = data1 ( 1:500 , :) ; data ( 501:1000 , : ) = data2 ( 1:500 , : ) ; data ( 1001:1500 , : ) = data3 ( 1:500 , : ) ; data ( 1501:2000 , : ) = data4 ( 1:500 , : ) ; %%%%%%从1到2000间的随机排序 k = rand ( 1 , 2000 ) ; [ m , n ] = sort ( k ) ; %%m为数值,n为标号
%%%%%%%%%%%输入输出数据 input = data ( : , 2:25 ) ; output1 = data ( : , 1) ; %%%%%%把输出从1维变到4维 for i = 1 : 1 :2000 switch output1( i ) case 1 output( i , :) = [ 1 0 0 0 ] ; case 2 output( i , :) = [ 0 1 0 0 ] ; case 3 output( i , :) = [ 0 0 1 0 ] ; case 4 output( i , :) = [ 0 0 0 1 ] ; end end %%%%随机抽取1500个样本作为训练样本,500个样本作为预测样本 input_train = input ( n( 1:1500 , : ) )’ ; output_train = output ( n( 1:1500 , : ) )’ ; input_test = input ( n( 1501:2000 , : ) )’ ;
浅谈神经网络 先从回归(Regression)问题说起。我在本吧已经看到不少人提到如果想实现强AI,就必须让机器学会观察并总结规律的言论。具体地说,要让机器观察什么是圆的,什么是方的,区分各种颜色和形状,然后根据这些特征对某种事物进行分类或预测。其实这就是回归问题。 如何解决回归问题?我们用眼睛看到某样东西,可以一下子看出它的一些基本特征。可是计算机呢?它看到的只是一堆数字而已,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。 例:假如有一串数字,已知前六个是1、3、5、7,9,11,请问第七个是几? 你一眼能看出来,是13。对,这串数字之间有明显的数学规律,都是奇数,而且是按顺序排列的。 那么这个呢?前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几? 这个就不那么容易看出来了吧!我们把这几个数字在坐标轴上标识一下,可以看到如下图形: 用曲线连接这几个点,延着曲线的走势,可以推算出第七个数字——7。 由此可见,回归问题其实是个曲线拟合(Curve Fitting)问题。那么究竟该如何拟合?机器不
可能像你一样,凭感觉随手画一下就拟合了,它必须要通过某种算法才行。 假设有一堆按一定规律分布的样本点,下面我以拟合直线为例,说说这种算法的原理。 其实很简单,先随意画一条直线,然后不断旋转它。每转一下,就分别计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是著名的梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数,例如0.0001时,我们就可以收工(收敛, Converge)了。啰嗦一句,如果随便转,转过头了再往回转,那就不是梯度下降法。 我们知道,直线的公式是y=kx+b,k代表斜率,b代表偏移值(y轴上的截距)。也就是说,k 可以控制直线的旋转角度,b可以控制直线的移动。强调一下,梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。 求误差时使用累加(直线点-样本点)^2,这样比直接求差距累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。 问题到此使似乎就已经解决了,可是我们需要一种适应于各种曲线拟合的方法,所以还需要继续深入研究。 我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图:
神经网络与复杂网络的分析 摘要 复杂网络在现实生活中是无处不在的,生物网络是它的一个分类。神经网络是很重要的生物网络。利用神经网络是可以研究一些其他的方向,如网络安全、人工智能等。而神经网络又可以因为它是复杂的网络,可以利用复杂网络的部分性质里进行研究,比如小世界效应的。 本文只要介绍了几篇应用复杂网络的研究,并进行简单的介绍和分析。 关键词:复杂网络、神经网络 Abstract The Complex network is in everywhere in real life, while Biological network is one of kinds of it. And neural network is one of the most important of biological network. The neural network could be used to research other subjects such as network security, artificial intelligence and so on. However we also use some properties of complex network to study neural network. Foe example we could use small-world to study it. This paper introduces and analysis five articles that use complex network. Key word:complex network、neural network
基于动态BP神经网络的预测方法及其应用来源:中国论文下载中心 [ 08-05-05 15:35:00 ] 作者:朱海燕朱晓莲黄頔编辑:studa0714 摘要人工神经网络是一种新的数学建模方式,它具有通过学习逼近任意非线性映射的能力。本文提出了一种基于动态BP神经网络的预测方法,阐述了其基本原理,并以典型实例验证。 关键字神经网络,BP模型,预测 1 引言 在系统建模、辨识和预测中,对于线性系统,在频域,传递函数矩阵可以很好地表达系统的黑箱式输入输出模型;在时域,Box-Jenkins方法、回归分析方法、ARMA模型等,通过各种参数估计方法也可以给出描述。对于非线性时间序列预测系统,双线性模型、门限自回归模型、ARCH模型都需要在对数据的内在规律知道不多的情况下对序列间关系进行假定。可以说传统的非线性系统预测,在理论研究和实际应用方面,都存在极大的困难。相比之下,神经网络可以在不了解输入或输出变量间关系的前提下完成非线性建模[4,6]。神经元、神经网络都有非线性、非局域性、非定常性、非凸性和混沌等特性,与各种预测方法有机结合具有很好的发展前景,也给预测系统带来了新的方向与突破。建模算法和预测系统的稳定性、动态性等研究成为当今热点问题。目前在系统建模与预测中,应用最多的是静态的多层前向神经网络,这主要是因为这种网络具有通过学习逼近任意非线性映射的能力。利用静态的多层前向神经网络建立系统的输入/输出模型,本质上就是基于网络逼近能力,通过学习获知系统差分方程中的非线性函数。但在实际应用中,需要建模和预测的多为非线性动态系统,利用静态的多层前向神经网络必须事先给定模型的阶次,即预先确定系统的模型,这一点非常难做到。近来,有关基于动态网络的建模和预测的研究,代表了神经网络建模和预测新的发展方向。 2 BP神经网络模型 BP网络是采用Widrow-Hoff学习算法和非线性可微转移函数的多层网络。典型的BP算法采用梯度下降法,也就是Widrow-Hoff算法。现在有许多基本的优化算法,例如变尺度算法和牛顿算法。如图1所示,BP神经网络包括以下单元:①处理单元(神经元)(图中用圆圈表示),即神经网络的基本组成部分。输入层的处理单元只是将输入值转入相邻的联接权重,隐层和输出层的处理单元将它们的输入值求和并根据转移函数计算输出值。②联接权重(图中如V,W)。它将神经网络中的处理单元联系起来,其值随各处理单元的联接程度而变化。③层。神经网络一般具有输入层x、隐层y和输出层o。④阈值。其值可为恒值或可变值,它可使网络能更自由地获取所要描述的函数关系。⑤转移函数F。它是将输入的数据转化为输出的处理单元,通常为非线性函数。
神经网络模型预测控制器 摘要:本文将神经网络控制器应用于受限非线性系统的优化模型预测控制中,控制规则用一个神经网络函数逼近器来表示,该网络是通过最小化一个与控制相关的代价函数来训练的。本文提出的方法可以用于构造任意结构的控制器,如减速优化控制器和分散控制器。 关键字:模型预测控制、神经网络、非线性控制 1.介绍 由于非线性控制问题的复杂性,通常用逼近方法来获得近似解。在本文中,提出了一种广泛应用的方法即模型预测控制(MPC),这可用于解决在线优化问题,另一种方法是函数逼近器,如人工神经网络,这可用于离线的优化控制规则。 在模型预测控制中,控制信号取决于在每个采样时刻时的想要在线最小化的代价函数,它已经广泛地应用于受限的多变量系统和非线性过程等工业控制中[3,11,22]。MPC方法一个潜在的弱点是优化问题必须能严格地按要求推算,尤其是在非线性系统中。模型预测控制已经广泛地应用于线性MPC问题中[5],但为了减小在线计算时的计算量,该部分的计算为离线。一个非常强大的函数逼近器为神经网络,它能很好地用于表示非线性模型或控制器,如文献[4,13,14]。基于模型跟踪控制的方法已经普遍地应用在神经网络控制,这种方法的一个局限性是它不适合于不稳定地逆系统,基此本文研究了基于优化控制技术的方法。 许多基于神经网络的方法已经提出了应用在优化控制问题方面,该优化控制的目标是最小化一个与控制相关的代价函数。一个方法是用一个神经网络来逼近与优化控制问题相关联的动态程式方程的解[6]。一个更直接地方法是模仿MPC方法,用通过最小化预测代价函数来训练神经网络控制器。为了达到精确的MPC技术,用神经网络来逼近模型预测控制策略,且通过离线计算[1,7.9,19]。用一个交替且更直接的方法即直接最小化代价函数训练网络控制器代替通过训练一个神经网络来逼近一个优化模型预测控制策略。这种方法目前已有许多版本,Parisini[20]和Zoppoli[24]等人研究了随机优化控制问题,其中控制器作为神经网络逼近器的输入输出的一个函数。Seong和Widrow[23]研究了一个初始状态为随机分配的优化控制问题,控制器为反馈状态,用一个神经网络来表示。在以上的研究中,应用了一个随机逼近器算法来训练网络。Al-dajani[2]和Nayeri等人[15]提出了一种相似的方法,即用最速下降法来训练神经网络控制器。 在许多应用中,设计一个控制器都涉及到一个特殊的结构。对于复杂的系统如减速控制器或分散控制系统,都需要许多输入与输出。在模型预测控制中,模型是用于预测系统未来的运动轨迹,优化控制信号是系统模型的系统的函数。因此,模型预测控制不能用于定结构控制问题。不同的是,基于神经网络函数逼近器的控制器可以应用于优化定结构控制问题。 在本文中,主要研究的是应用于非线性优化控制问题的结构受限的MPC类型[20,2,24,23,15]。控制规则用神经网络逼近器表示,最小化一个与控制相关的代价函数来离线训练神经网络。通过将神经网络控制的输入适当特殊化来完成优化低阶控制器的设计,分散和其它定结构神经网络控制器是通过对网络结构加入合适的限制构成的。通过一个数据例子来评价神经网络控制器的性能并与优化模型预测控制器进行比较。 2.问题表述 考虑一个离散非线性控制系统: 其中为控制器的输出,为输入,为状态矢量。控制
神经网络分析法是从神经心理学和认知科学研究成果出发,应用数学方法发展起来的一种具有高度并行计算能力、自学能力和容错能力的处理方法。 神经网络技术在模式识别与分类、识别滤波、自动控制、预测等方面已展示了其非凡的优越性。神经网络是从神经心理学和认识科学研究成果出发,应用数学方法发展起来的一种并行分布模式处理系统,具有高度并行计算能力、自学能力和容错能力。神经网络的结构由一个输入层、若干个中间隐含层和一个输出层组成。神经网络分析法通过不断学习,能够从未知模式的大量的复杂数据中发现其规律。神经网络方法克服了传统分析过程的复杂性及选择适当模型函数形式的困难,它是一种自然的非线性建模过程,毋需分清存在何种非线性关系,给建模与分析带来极大的方便。 编辑本段神经网络分析法在风险评估的运用 神经网络分析方法应用于信用风险评估的优点在于其无严格的假设限制,且具有处理非线性问题的能力。它能有效解决非正态分布、非线性的信用评估问题,其结果介于0与1之间,在信用风险的衡量下,即为违约概率。神经网络法的最大缺点是其工作的随机性较强。因为要得到一个较好的神经网络结构,需要人为地去调试,非常耗费人力与时间,因此使该模型的应用受到了限制。Altman、marco和varetto(1994)在对意大利公司财务危机预测中应用了神经网络分析法;coats及fant(1993)trippi 采用神经网络分析法分别对美国公司和银行财务危机进行预测,取得较好效果。然而,要得到一个较好的神经网络结构,需要人为随机调试,需要耗费大量人力和时间,加之该方法结论没有统计理论基础,解释性不强,所以应用受到很大限制。 编辑本段神经网络分析法在财务中的运用 神经网络分析法用于企业财务状况研究时,一方面利用其映射能力,另一方面主要利用其泛化能力,即在经过一定数量的带噪声的样本的训练之后,网络可以抽取样本所隐含的特征关系,并对新情况下的数据进行内插和外推以推断其属性。 神经网络分析法对财务危机进行预测虽然神经网络的理论可追溯到上个世纪40年代,但在信用风险分析中的应用还是始于上个世纪90年代。神经网络是从神经心理学和认识科学研究成果出发,应用数学方法发展起来的一种并行分布模式处理系统,具有高度并行计算能力、自学能力和容错能力。神经网络的结构是由一个输入层、若干个中间隐含层和输出层组成。国外研究者如Altman,Marco和Varetto(1995),对意大利公司财务危机预测中应用了神经网络分析法。Coats,Pant(1993)采用神经网络分析法
神经网络在数据挖掘中的应用
————————————————————————————————作者:————————————————————————————————日期: ?
神经网络在数据挖掘中的应用 摘要:给出了数据挖掘方法的研究现状,通过分析当前一些数据挖掘方法的局限性,介绍一种基于关系数据库的数据挖掘方法——神经网络方法,目前,在数据挖掘中最常用的神经网络是BP网络。在本文最后,也提出了神经网络方法在数据挖掘中存在的一些问题. 关键词:BP算法;神经网络;数据挖掘 1.引言 在“数据爆炸但知识贫乏”的网络时代,人们希望能够对其进行更高层次的分析,以便更好地利用这些数据。数据挖掘技术应运而生。并显示出强大的生命力。和传统的数据分析不同的是数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。所得到的信息具有先未知,有效性和实用性三个特征。它是从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示三个步骤。数据准备是从各种数据源中选取和集成用于数据挖掘的数据;规律寻找是用某种方法将数据中的规律找出来;规律表示是用尽可能符合用户习惯的方式(如可视化)将找出的规律表示出来。数据挖掘在自身发展的过程中,吸收了数理统计、数据库和人工智能中的大量技术。作为近年来来一门处理数据的新兴技术,数据挖掘的目标主要是为了帮助决策者寻找数据间潜在的关联(Relation),特征(Pattern)、趋势(Trend)等,发现被忽略的要素,对预测未来和决策行为十分有用。 数据挖掘技术在商业方面应用较早,目前已经成为电子商务中的关键技术。并且由于数据挖掘在开发信息资源方面的优越性,已逐步推广到保险、医疗、制造业和电信等各个行业的应用。 数据挖掘(Data Mining)是数据库中知识发现的核心,形成了一种全新的应用领域。数据挖掘是从大量的、有噪声的、随机的数据中,识别有效的、新颖的、有潜在应用价值及完全可理解模式的非凡过程。从而对科学研究、商业决策和企业管理提供帮助。 数据挖掘是一个高级的处理过程,它从数据集中识别出以模式来表示的知识。它的核心技术是人工智能、机器学习、统计等,但一个DM系统不是多项技术的简单组合,而是一个完整的整体,它还需要其它辅助技术的支持,才能完成数据采集、预处理、数据分析、结果表述这一系列的高级处理过程。所谓高级处理过程是指一个多步骤的处理过程,多步骤之间相互影响、反复调整,形成一种螺旋式上升过程。最后将分析结果呈现在用户面前。根据功能,整个DM系统可以大致分为三级结构。 神经网络具有自适应和学习功能,网络不断检验预测结果与实际情况是否相符。把与实际情况不符合的输入输出数据对作为新的样本,神经网络对新样本进行动态学习并动态改变网络结构和参数,这样使网络适应环境或预测对象本身结构和参数的变化,从而使预测网络模型有更强的适应性,从而得到更符合实际情况的知识和规则,辅助决策者进行更好地决策。而在ANN的
神经网络控制 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
人工神经网络控制 摘要: 神经网络控制,即基于神经网络控制或简称神经控制,是指在控制系统中采用神经网络这一工具对难以精确描述的复杂的非线性对象进行建模,或充当控制器,或优化计算,或进行推理,或故障诊断等,亦即同时兼有上述某些功能的适应组合,将这样的系统统称为神经网络的控制系统。本文从人工神经网络,以及控制理论如何与神经网络相结合,详细的论述了神经网络控制的应用以及发展。 关键词: 神经网络控制;控制系统;人工神经网络 人工神经网络的发展过程 神经网络控制是20世纪80年代末期发展起来的自动控制领域的前沿学科之一。它是智能控制的一个新的分支,为解决复杂的非线性、不确定、不确知系统的控制问题开辟了新途径。是(人工)神经网络理论与控制理论相结合的产物,是发展中的学科。它汇集了包括数学、生物学、神经生理学、脑科学、遗传学、人工智能、计算机科学、自动控制等学科的理论、技术、方法及研究成果。 在控制领域,将具有学习能力的控制系统称为学习控制系统,属于智能控制系统。神经控制是有学习能力的,属于学习控制,是智能控制的一个分支。神经控制发展至今,虽仅有十余年的历史,已有了多种控制结构。如神经预测控制、神经逆系统控制等。 生物神经元模型 神经元是大脑处理信息的基本单元,人脑大约含1012个神经元,分成约1000种类型,每个神经元大约与 102~104个其他神经元相连接,形成极为错综复杂而又灵活多变的神经网络。每个神经元虽然都十分简单,但是如此大量的神经元之间、如此复杂的连接却可以演化出丰富多彩的行为方式,同时,如此大量的神经元与外部感受器之间的多种多样的连接方式也蕴含了变化莫测的反应方式。 图1 生物神经元传递信息的过程为多输入、单输出,神经元各组成部分的功能来看,信息的处理与传递主要发生在突触附近,当神经元细胞体通过轴突传到突触前膜的脉
人工神经网络 分析 班级: 学号: 姓名: 指导教师: 时间:
摘要: 人工神经网络也简称为神经网络,是一种模范动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。 自从认识到人脑的计算与传统的计算机相比是完全不同的方式开始,关于人工神经网络的研究就开始了。半个多世纪以来,神经网络经历了萌芽期、第一次高潮期、反思低潮期、第二次高潮期、再认识与应用研究期五个阶段。而近年来,人工神经网络通过它几个突出的优点更是引起了人们极大的关注,因为它为解决大复杂度问题提供了一种相对来说比较有效的简单方法。目前,神经网络已成为涉及计算机科学、人工智能、脑神经科学、信息科学和智能控制等多种学科和领域的一门新兴的前言交叉学科。 英文摘要: Artificial neural networks are also referred to as the neural network is a neural network model of animal behavior, distributed parallel information processing algorithm mathematical model. This network relies on system complexity, achieved by adjusting the number of nodes connected to the relationship between, so as to achieve the purpose of processing information. Since the understanding of the human brain compared to traditional computer calculation and are completely different way to start on artificial neural network research began. Over half a century, the neural network has experienced infancy, the first high tide, low tide reflections, the second peak period, and again knowledge and applied research on five stages. In recent years, artificial neural networks through which several prominent advantage is attracting a great deal of attention because it is a large complex problem solving provides a relatively simple and effective way. Currently, neural networks have become involved in computer science, artificial intelligence, brain science, information science and intelligent control and many other disciplines and fields of an emerging interdisciplinary foreword. 关键字:
clear %% 训练数据预测数据提取及归一化 %下载四类语音信号 load data1 c1 load data2 c2 load data3 c3 load data4 c4 %四个特征信号矩阵合成一个矩阵 data(1:500,:)=c1(1:500,:); data(501:1000,:)=c2(1:500,:); data(1001:1500,:)=c3(1:500,:); data(1501:2000,:)=c4(1:500,:); %从1到2000间随机排序 k=rand(1,2000); [m,n]=sort(k); %输入输出数据 input=data(:,2:25); output1 =data(:,1); %把输出从1维变成4维 for i=1:2000 switch output1(i) case 1 output(i,:)=[1 0 0 0]; case 2 output(i,:)=[0 1 0 0]; case 3 output(i,:)=[0 0 1 0]; case 4 output(i,:)=[0 0 0 1]; end end %随机提取1500个样本为训练样本,500个样本为预测样本input_train=input(n(1:1500),:)'; output_train=output(n(1:1500),:)'; input_test=input(n(1501:2000),:)'; output_test=output(n(1501:2000),:)'; %输入数据归一化 [inputn,inputps]=mapminmax(input_train); %% 网络结构初始化 innum=24; midnum=25; outnum=4;
5.4 神经网络与遗传算法简介 在本节中,我们将着重讲述一些在网络设计、优化、性能分析、通信路由优化、选择、神经网络控制优化中有重要应用的常用的算法,包括神经网络算法、遗传算法、模拟退火算法等方法。用这些算法可以较容易地解决一些很复杂的,常规算法很难解决的问题。这些算法都有着很深的理论背景,本节不准备详细地讨论这些算法的理论,只对算法的原理和方法作简要的讨论。 5.4.1 神经网络 1. 神经网络的简单原理 人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connectionist Model),是对人脑或自然神经网络(Natural Neural Network)若干基本特性的抽象和模拟。人工神经网络以对大脑的生理研究成果为基础的,其目的在于模拟大脑的某些机理与机制,实现某个方面的功能。所以说, 人工神经网络是由人工建立的以有向图为拓扑结构的动态系统,它通过对连续或断续的输入作出状态相应而进行信息处理。它是根据人的认识过程而开发出的一种算法。假如我们现在只有一些输入和相应的输出,而对如何由输入得到输出的机理并不清楚,那么我们可以把输入与输出之间的未知过程看成是一个“网络”,通过不断地给这个网络输入和相应的输出来“训练”这个网络,网络根据输入和输出不断地调节自己的各节点之间的权值来满足输入和输出。这样,当训练结束后,我们给定一个输入,网络便会根据自己已调节好的权值计算出一个输出。这就是神经网络的简单原理。 2. 神经元和神经网络的结构 如上所述,神经网络的基本结构如图5.35所示: 隐层隐层2 1 图5.35 神经网络一般都有多层,分为输入层,输出层和隐含层,层数越多,计算结果越精确,但所需的时间也就越长,所以实际应用中要根据要求设计网络层数。神经网络中每一个节点叫做一个人工神经元,他对应于人脑中的神经元。人脑神经元由细胞体、树突和轴突三部分组成,是一种根须状蔓延物。神经元的中心有一闭点,称为细胞体,它能对接受到的信息进行处理,细胞体周围的纤维有两类,轴突是较长的神经纤维,是发出信息的。树突的神经纤维较短,而分支众多,是接收信息的。一个神经元的轴突末端与另一神经元的树突之间密
基于神经网络的频谱分析设计 1.神经网络训练步骤 Step1. 以采样周期Ts =T/2N,对信号f ( t ) 采样, 获取2N + 1 个训练样本f ( k ) , k = 0, 1,...,N , 随机产生权值an 和bn, n = 1, 2,...,N . 给定任意小正实数Tol ,然后确定学习率eta = 0. 6 * 4/3*(N + 1)=0. 8/(N + 1), 令J = 0; Step2. 由式( 6) 计算神经网络输出f nn( k ) ; Step3. 由式( 7) 和( 8) 分别计算误差函数与性能指标e( k ) 和J ; Step4. 由式( 9) 和式( 10) 进行权值调整; Step5. 判断性能指标是否满足J < Tol?若满足, 结束训练; 否则令J = 0 返回Step2 重复上述训练过程. 2.频谱分析实例 设周期信号为 yd=240.*sin(s.*t)+0.1.*sin(2.*s.*t+10*pi/180)+12*sin(3.*s.*t+20*pi/18 0)+0.1.*sin(4.*s.*t+30*pi/180)+2.7.*sin(5.*s.*t+40*pi/180)+0.05.*sin( 6.*s.*t+50*pi/180)+2.1*sin(7.*s.*t+60*pi/180)+0.3.*sin(9.*s.*t+80*pi/ 180)+0.6.*sin(11.*s.*t+100*pi/180); 其中基波角频率为s=80*pi,M=40,是39个采样点:最低基频一个周波+2。学习率为eta =0.0192,经过652次神经网络训练, 性能指标为: J = <1x652double>,tol=1.00e-19;a=<1x13double>,b=<1x13double>,幅频特性误差,如图2所示, 相频特性误差图,如图3所示。 3.程序 clear,close all,format long e J=0;k=0;s1=0;s2=0;s3=0; tol=1e-29;N=13;M=40;%39采样点:最低基频一个周波+2 fs=1510;eta=10/(N*M);a0=0;a=zeros(1,N);%权值初始值
%% SVM神经网络的数据分类预测----意大利葡萄酒种类识别 %% 清空环境变量 close all; clear; clc; format compact; %% 数据提取 % 载入测试数据wine,其中包含的数据为classnumber = 3,wine:178*13的矩阵,wine_labes:178*1的列向量 load chapter12_wine.mat; % 画出测试数据的box可视化图 figure; boxplot(wine,'orientation','horizontal','labels',categories); title('wine数据的box可视化图','FontSize',12); xlabel('属性值','FontSize',12); grid on; % 画出测试数据的分维可视化图 figure subplot(3,5,1); hold on for run = 1:178 plot(run,wine_labels(run),'*'); end xlabel('样本','FontSize',10); ylabel('类别标签','FontSize',10); title('class','FontSize',10); for run = 2:14 subplot(3,5,run); hold on; str = ['attrib ',num2str(run-1)]; for i = 1:178 plot(i,wine(i,run-1),'*'); end xlabel('样本','FontSize',10); ylabel('属性值','FontSize',10); title(str,'FontSize',10); end % 选定训练集和测试集 % 将第一类的1-30,第二类的60-95,第三类的131-153做为训练集
神经网络算法简介 () 人工神经网络(artificial neural network,缩写ANN),简称神经网络(neural network,缩写NN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。 神经网络是一种运算模型[1],由大量的节点(或称“神经元”,或“单元”)和之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重(weight),这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。 神经元示意图: ●a1~an为输入向量的各个分量 ●w1~wn为神经元各个突触的权值 ●b为偏置 ●f为传递函数,通常为非线性函数。以下默认为hardlim() ●t为神经元输出 ●数学表示
●为权向量 ●为输入向量,为的转置 ●为偏置 ●为传递函数 可见,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。 单个神经元的作用:把一个n维向量空间用一个超平面分割成两部分(称之为判断边界),给定一个输入向量,神经元可以判断出这个向量位于超平面的哪一边。 该超平面的方程: 权向量 偏置 超平面上的向量 单层神经元网络是最基本的神经元网络形式,由有限个神经元构成,所有神经元的输入向量都是同一个向量。由于每一个神经元都会产生一个标量结果,所以单层神经元的输出是一个向量,向量的维数等于神经元的数目。示意图: 通常来说,一个人工神经元网络是由一个多层神经元结构组成,每一层神经元拥有输入(它的输入是前一层神经元的输出)和输出,每一层(我们用符号记做)Layer(i)是由Ni(Ni代表在第i层上的N)个网络神经元组成,每个Ni上的网络
多元回归与神经网络的应用 摘要 本文主要是通过整理分析数据,以得出题目中所给出的i x 与j y 的函数关系.由于数据并不是很充足,我们选择了所有数据为样本数据和部分数据为验证数据。我们首先采用了多元回归方法,由于数据之间并没有明显的线性或者其它函数关系,模型很难选择,得到的结论对于1y 来说残值偏大,效果很差,于是我们引用了BP 神经网络,经过选择合适的参数,多次训练得到合适的网络,拟合得到了相对精确的结果,并进行了验证,最后将三种模型进行了对比。 关键字: 多元线性回归 多元非线性回归 最小二乘法 牛顿法 BP 神经网络 1.问题重述 现实生活中,由于客观事物内部规律的复杂性及人们认识程度的限制,人们常收集大量的数据,基于数据的统计分析建立合乎基本规律的数学模型,然后通过计算得到的模型结果来解决实际问题.回归分析法和神经网络是数学建模中常用于解决问题的有效方法.本文要解决的主要问题是:通过对所给数据的分析,分别用回归方法或神经网络来确立x i 与y i 之间的函数关系,并验证结论。 2.问题分析 题目要求我们使用神经网络或回归方法来做相关数据处理,相比较之下,我们对回归方法比较熟悉,所以首先选取了回归方法。得到相关函数,并分析误差,再利用神经网络模型建立合理的网络,进行误差分析并和前者比较,得出合理的结论。 3.符号说明 m x 的自变量个数 β 回归系数 ε 残差 Q 偏差平方和
,X Y -- 分别为两个变量序列,i i X Y 的均值 w (t)ij 第一层网络与第二层网络之间的权值 (t)ij B 第二层神经元的阈值 (t)jk w 第二层与第三层之间的权值 (t)jk B 第三层神经元的阈值 jk w ? 第二层与第三层权值调整量 jk B ? 第二层与第三层阈值调整量 ij w ? 第一层与第二层权值调整量 ij B ? 第一层与第二层阈值调整量 Logsig 函数 x e y -+=11 Tansig 函数 1 -)e +(12x 2-? Q 偏差平方和 y α 观察值 ^ y α 回归值 β 估计参数 h S 回归平方和 1 h S (p-1)个变量所引起的回归平方和(即除去i x ) i Q 偏回归平方和 4.模型建立与求解
一种递归模糊神经网络自适应控制方法 毛六平,王耀南,孙 炜,戴瑜兴 (湖南大学电气与信息工程学院,湖南长沙410082) 摘 要: 构造了一种递归模糊神经网络(RFNN ),该RFNN 利用递归神经网络实现模糊推理,并通过在网络的第 一层添加了反馈连接,使网络具有了动态信息处理能力.基于所设计的RFNN ,提出了一种自适应控制方案,在该控制方案中,采用了两个RFNN 分别用于对被控对象进行辨识和控制.将所提出的自适应控制方案应用于交流伺服系统,并给出了仿真实验结果,验证了所提方法的有效性. 关键词: 递归模糊神经网络;自适应控制;交流伺服中图分类号: TP183 文献标识码: A 文章编号: 037222112(2006)1222285203 An Adaptive Control Using Recurrent Fuzzy Neural Network M AO Liu 2ping ,W ANG Y ao 2nan ,S UN Wei ,DAI Y u 2xin (College o f Electrical and Information Engineering ,Hunan University ,Changsha ,Hunan 410082,China ) Abstract : A kind of recurrent fuzzy neural network (RFNN )is constructed ,in which ,recurrent neural network is used to re 2alize fuzzy inference temporal relations are embedded in the network by adding feedback connections on the first layer of the network.On the basis of the proposed RFNN ,an adaptive control scheme is proposed ,in which ,two proposed RFNNs are used to i 2dentify and control plant respectively.Simulation experiments are made by applying proposed adaptive control scheme on AC servo control problem to confirm its effectiveness. K ey words : recurrent fuzzy neural network ;adaptive control ;AC servo 1 引言 近年来,人们开始越来越多地将神经网络用于辨识和控 制动态系统[1~3].神经网络在信号的传播方向上,可以分为前馈神经网络和递归神经网络.前馈神经网络能够以任意精度逼近任意的连续函数,但是前馈神经网络是一个静态的映射,它不能反映动态的映射.尽管这个问题可以通过增加延时环节来解决,但是那样会使前馈神经网络增加大量的神经元来代表时域的动态响应.而且,由于前馈神经网络的权值修正与网络的内部信息无关,使得网络对函数的逼近效果过分依赖于训练数据的好坏.而另一方面,递归神经网络[4~7]能够很好地反映动态映射关系,并且能够存储网络的内部信息用于训练网络的权值.递归神经网络有一个内部的反馈环,它能够捕获系统的动态响应而不必在外部添加延时反馈环节.由于递归神经网络能够反映动态映射关系,它在处理参数漂移、强干扰、非线性、不确定性等问题时表现出了优异的性能.然而递归神经网络也有它的缺陷,和前馈神经网络一样,它的知识表达能力也很差,并且缺乏有效的构造方法来选择网络结构和确定神经元的参数. 递归模糊神经网络(RFNN )[8,9]是一种改进的递归神经网络,它利用递归网络来实现模糊推理,从而同时具有递归神经网络和模糊逻辑的优点.它不仅可以很好地反映动态映射关系,还具有定性知识表达的能力,可以用人类专家的语言控制规则来训练网络,并且使网络的内部知识具有明确的物理意 义,从而可以很容易地确定网络的结构和神经元的参数. 本文构造了一种RFNN ,在所设计的网络中,通过在网络的第一层加入反馈连接来存储暂态信息.基于该RFNN ,本文还提出了一种自适应控制方法,在该控制方法中,两个RFNN 被分别用于对被控对象进行辨识和控制.为了验证所提方法的有效性,本文将所提控制方法用于交流伺服系统的控制,并给出了仿真实验结果. 2 RFNN 的结构 所提RFNN 的结构如图1所示,网络包含n 个输入节点,对每个输入定义了m 个语言词集节点,另外有l 条控制规则 节点和p 个输出节点.用u (k )i 、O (k ) i 分别代表第k 层的第i 个节点的输入和输出,则网络内部的信号传递过程和各层之间的输入输出关系可以描述如下: 第一层:这一层的节点将输入变量引入网络.与以往国内外的研究不同,本文将反馈连接加入这一层中.第一层的输入输出关系可以描述为:O (1)i (k )=u (1)i (k )=x (1)i (k )+w (1)i (k )?O (1)i (k -1), i =1,…,n (1) 之所以将反馈连接加入这一层,是因为在以往的模糊神经网络控制器中,控制器往往是根据系统的误差及其对时间的导数来决定控制的行为,在第一层中加入暂态反馈环,则只需要以系统的误差作为网络的输入就可以反映这种关系,这样做不仅可以简化网络的结构,而且具有明显的物理意义,使 收稿日期:2005207201;修回日期:2006206218 基金项目:国家自然科学基金项目(N o.60075008);湖南省自然科学基金(N o.06JJ50121) 第12期2006年12月 电 子 学 报 ACT A E LECTRONICA SINICA V ol.34 N o.12 Dec. 2006