
多元回归与神经网络的应用
摘要
本文主要是通过整理分析数据,以得出题目中所给出的i x 与j y 的函数关系.由于数据并不是很充足,我们选择了所有数据为样本数据和部分数据为验证数据。我们首先采用了多元回归方法,由于数据之间并没有明显的线性或者其它函数关系,模型很难选择,得到的结论对于1y 来说残值偏大,效果很差,于是我们引用了BP 神经网络,经过选择合适的参数,多次训练得到合适的网络,拟合得到了相对精确的结果,并进行了验证,最后将三种模型进行了对比。
关键字: 多元线性回归 多元非线性回归 最小二乘法 牛顿法 BP 神经网络
1.问题重述
现实生活中,由于客观事物内部规律的复杂性及人们认识程度的限制,人们常收集大量的数据,基于数据的统计分析建立合乎基本规律的数学模型,然后通过计算得到的模型结果来解决实际问题.回归分析法和神经网络是数学建模中常用于解决问题的有效方法.本文要解决的主要问题是:通过对所给数据的分析,分别用回归方法或神经网络来确立x i 与y i
之间的函数关系,并验证结论。
2.问题分析
题目要求我们使用神经网络或回归方法来做相关数据处理,相比较之下,我们对回归方法比较熟悉,所以首先选取了回归方法。得到相关函数,并分析误差,再利用神经网络模型建立合理的网络,进行误差分析并和前者比较,得出合理的结论。
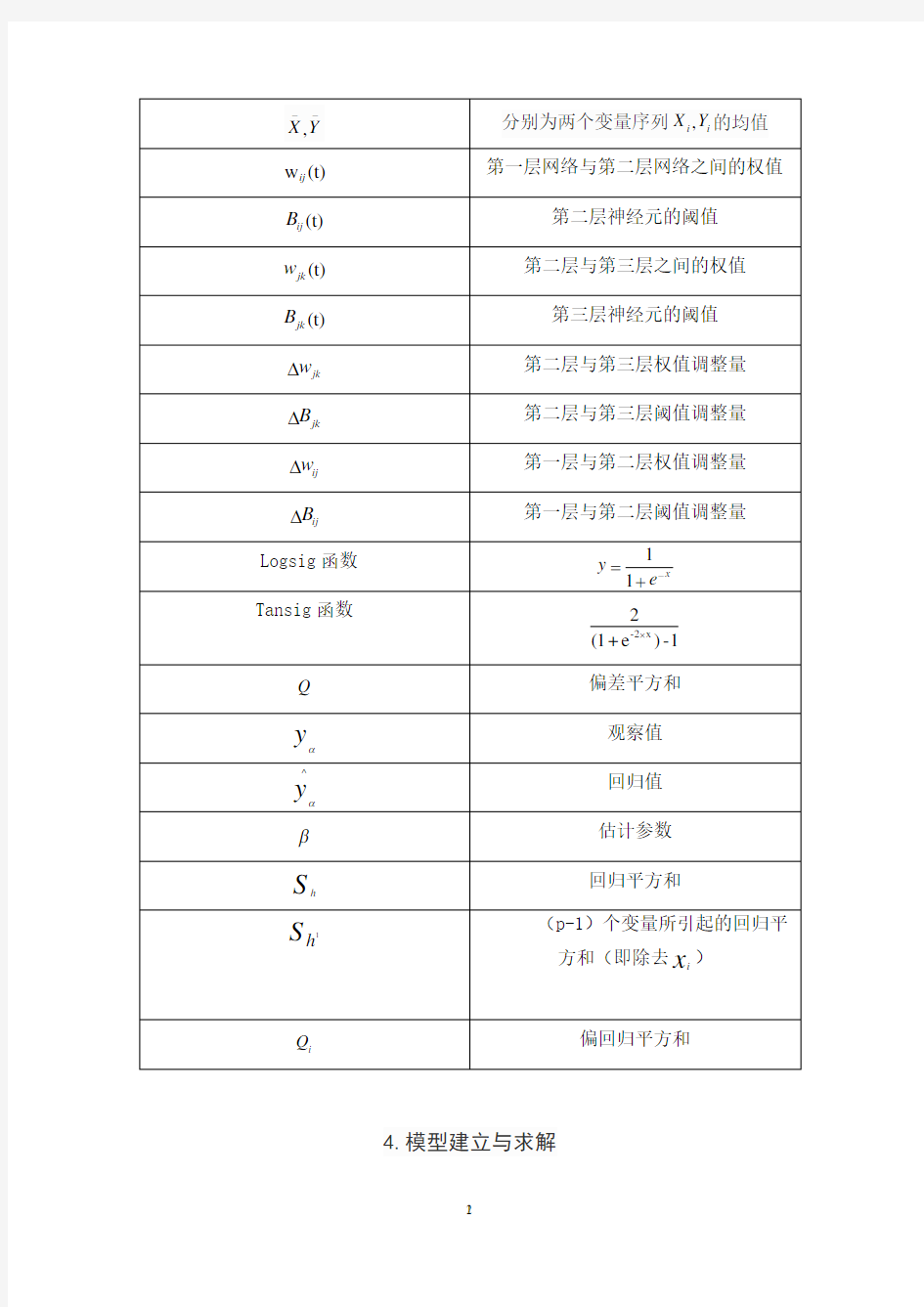
3.符号说明
m x 的自变量个数 β
回归系数 ε
残差 Q
偏差平方和
,X Y --
分别为两个变量序列,i i X Y 的均值 w (t)ij 第一层网络与第二层网络之间的权值
(t)ij B 第二层神经元的阈值 (t)jk w 第二层与第三层之间的权值 (t)jk B
第三层神经元的阈值 jk w ? 第二层与第三层权值调整量 jk B ? 第二层与第三层阈值调整量 ij w ? 第一层与第二层权值调整量 ij
B ?
第一层与第二层阈值调整量
Logsig 函数 x e y -+=11
Tansig 函数
1
-)e
+(12x
2-?
Q
偏差平方和 y α
观察值 ^
y α
回归值 β
估计参数 h
S
回归平方和
1
h
S
(p-1)个变量所引起的回归平方和(即除去i x )
i Q
偏回归平方和
4.模型建立与求解
4.1多元回归方法
它是研究某个变量与另一些变量的函数关系.主要内容是从一组样本数据出发,通过合理分析得到正确的函数关系,建立相应的表达式,并通过相关软件处理得到相应的系数。
4.1.1多元线性回归方法
1.回归模型的一般形式为:Y=0112
2...m m X X X ββββε+++++
其中01,,...,m βββ是待估计参数,e 是随机误差即残差。残差ε服从均数为0,方差为2σ的正态分布。这就是线性回归的数学模型。
12Y y y ??
??=??????
,X =11
14491494501
504111x x x x x
x ?? ? ?
?
? ? ? ??
?,01234ββββββ??
? ?
? ?
= ? ? ?
? ???
,1
2εεε
??= ?
???
, 那么多元线性回归数学模型可也写成矩阵形式:Y X βε=+ 其中ε的分量是独立的。
2.参数β的最小二乘估计.为了估计参数β,我们采用最小二乘估计法.设
014,,...,b b b 分别是参数014,,...,βββ的最小二乘估计,则回归方程为
^
01144...y b b x b x =+++
由最小二乘法知道,014,,...,b b b 应使得全部观察值y α
与回归值^
y α
的偏差平
方和Q 达到最小,即使
2
^
Q y y α
αα=??-∑
???
=最小
所以Q 是014,,...,b b b 的非负二次式,最小值一定存在。根据微积分中的极值原理,014,,...,b b b 应是下列正规方程组的解:
^
^20,20,
j j
Q
Q y y
b y y x b αααααααδδδδ?? ?=--= ??
?
?? ?=--= ???
∑???∑
显然,正规方程组的系数矩阵是对称矩阵,用A 来表示,则'A X X =,则其右端常数项矩阵B 亦可以用矩阵X 和Y 来表示:'B X Y =,所以可以得到回归方程的回归系数:
()1
1
'
'b A B X X X Y --==
3.由于利用偏回归方程和i Q 可以衡量每个变量在回归中所起的作用大小(即影响程度),设h S 是p 个变量所引起的回归平方和,1
h
S 是(p-1)个变量
所引起的回归平方和(即除去i x ),则偏回归平方和i Q 为
1
2
*
p
j j h j i
j ii
i j
h
b Q b S S
b B B c
==-=-=
∑∑
就是去掉变量i x 后,回归平方和所减少的量。
4.建立模型
453423121x b x b x b x b b y i ?+?+?+?+=
5.模型的求解
我们通过MATLAB ,求得其回归系数,并最终得到i x 与i y 的函数关系:
12341
12342
339.849916.811411.548967.541415.5485,
164.55800.1874 1.797629.972812.4426,y x x x x y x x x x ?=-++-??
=-+-++?? 同时通过MATLAB 可以得出i x 与i y 的误差结果如下:
由此,我们可得出结论,采用多元线性回归得出的函数关系对于1y 残差太大,效果很差,对于2y 的拟合也并不是很完美。
4.1.2非线性回归方法
1.数据标准化
我们选用的是非线性模型LSE 的Gauss-Newton 算法:
采用Z-score 标准化法,即对序列12,,...,m x x x 进行变换:
i
i
s
x x y -
-=, (1其中,1
1
N
i
i N
x x -
==
∑,2
1
11N i s i N x x =-
=
-??-∑ ???
,则构成新序列,均值为0,方差为1.
。
首先考虑单参数的非线性回归模型: (),i
i
i
f
x Y
βε
=+
其残差平方和函数为
()()2
1
,N i S i i f Y X ββ==
-??∑??
要使()S β取极小值,则令其一阶导数为0,来求β.一个近似的方法是用Taylor 近似展开来代替。设β的初值为1β,则在1β点附近函数有近似Taylor 展式: ()()()
()1
1
1
,,,i
i
i
df
f
f d X X X βββββ
β
β≈+
-
可以求的其导数值,简记为: ()()1
1
,i
i
df
d X Z βββ
β=
∣
则
()()()()()()2
2
1
1
11111,.N
N
i i S i i i i i f Y X Z Y Z ββββββββ====??
??----∑∑???
???
即为线性回归
()()1
1
.i
i
i Z Y ββ
βε
=+
的残差和.上式被称为拟线性模型.其最小二乘估计是
)()()]()([)
()
()(1~
'
111'12
1
1
1
1
1
~
2ββββββββY Z Z Z Z Z Y n
i i
n
i i
i
-===?=
∑∑
如果我们有β的初值,就可以得到另一个新值,进而可以得到一个序列,写出一个迭代表达式,即
1
n β
+与
n
β
的关系。若在迭代过程中有
1
n β
+=
n
β
,即()S β的一阶导数为0,
此时()S β取得一个极值。
为了避免迭代时间过长或迭代来回反复,可以引入进步长控制函数n
t
,
'1
1[Z()Z()]n
n n n n n dS
t d ββββββ
-+=-'1'2[Z()Z()]()[Y (X,)]
n n n n n n t Z f βββββ-=--
n
t
由计算机程序根据误差自动调整.上述算法一般称为Gauss-Newton 算法.
2.建立非线性回归模型:采用多元二次多项式函数 设函数:
2
2
1
1
2
2
3
3
4
4
5
1
6
1
2
7
1
3
8
1
4
9
2
10
2
3
1
2
2
11
2
4
12
3
13
3
4
14
4
y b b x b x b x b x b x b x x b x x b x x b x b x x b x x b x b x x b x
=++++++++++++++通过Gauss-Newton 算法和MATLAB 计算最终得出以下结果:
21234112
1
22131422324334
2412212575.940129.457127.81901597.99601695.57780.87100.4665
35.3093 2.1549 1.289824.79770.912131.894694.336757.08592483.447814.5988 5.8585y x x x x x x x x x x x x x x x x x x x x y x x =--+-++--+-++++-=--2
3411222
1314223243342412.5802302.89100.48880.09558.72100.49710.2123 3.04590.141024.6923 5.203310.1871x x x x x x x x x x x x x x x x x x ????
???+-++???+-+--+-??+?
通过MATLAB 编写相应程序所得结果如下:
1
2
,y y
的残差图
由图可以明显看出误差很大,拟合效果不好。综合多元非线性和多元线性这两种模型,我们可以发现y1并不适合这两种模型,y2模拟相对较好,但误差并没有足够小,不再我们的预期效果之内。于是我们采用了BP 神经网络。
4.2神经网络
4.2.1模型的原理
BP (Back Propagation)神经网络是一种多层前馈神经网络。其由输入层、中间层、输出层组成的阶层型神经网络,中间层可扩展为多层。相邻层之间各神经元进行全连接,而每层各神经元之间无连接,网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,各神经元获得网络的输入响应产生连接权值(Weight ),隐含层神经元将传递过来的信息进行整合,通常还会在整合过程添加一个阈值,这是模仿生物学中神经元必须达到一定阈值才会触发的原理。输入层神经元数量由输入样本的维数决定,输出层神经元数量由输出样本的维数决定,隐藏层神经元合理选择。然后按减小希望输出与实际输出误差的方向,从输出层经各中间层逐层修正各连接权,回到输入层。此过程反复交替进行,直至网络的全局误差趋向给定的极小值,即完成学习的过程。BP 网络的核心是数学中的“负梯度下降”理论,即BP 的误差调整方向总是沿着误差下降最快的方向进行。
.
相关传递函数(或激励函数):
阈值型(一般只用于简单分类的MP 模型中)
0,0
()1,0
x f x x =?
线性型(一般只用于输入和输出神经元) ()f x x = S 型(常用于隐含层神经元)
1
()1x
f x e -=+ 或 1()1x x e f x e ---=+
BP 神经网络模型
通常还会在激励函数的变量中耦合一个常数以调整激励网络的输出幅度。
4.2.2 模型的建立与求解
步骤1、准备训练网络的样本
我们此次的BP网络是一个4输入2输出的网络,如下表所示:
序号X
1 X
2
X
3
X
4
Y
1
Y
2
1 8 10 0.5 14 41.3
2 14.3
2 8 14 0.7 15 725.67 0.0053
3 8 18 1 16 113.78 12.14
4 8 22 1.2 17 867.16 0.005
5 8 2
6 1.5 18 905.63 0.003
6 10 10 0.
7 16 5.52 71.68
7 10 14 1 17 100.4 1
8 10 18 1.2 18 329.85 0.42
9 10 22 1.5 14 24.02 57.32
10 10 26 0.5 15 191.13 3.89
11 13 10 1 18 3.88 77.4
12 13 14 1.2 14 36.83 19.57
13 13 18 1.5 15 217.93 9.06
14 13 22 0.5 16 258.35 0.0041
15 13 26 0.7 17 398.46 0.0058
16 15 10 1.2 15 2.24 85.32
17 15 14 1.5 16 29.24 15.74
18 15 18 0.5 17 296.98 7
19 15 22 0.7 18 207.52 0.036
20 15 26 1 14 204.86 0.706
21 18 10 1.5 17 3.16 85.5
22 18 14 0.5 18 15.92 36.32
23 18 18 0.7 14 49.4 29.52
24 18 22 1 15 149.6 0.51
25 18 26 1.2 16 255 0.05
26 8 28 1.2 18 69.3 86.32
27 8 20 1 18 58.9 81.9
28 8 17 0.7 18 125.5 98.39
29 8 15 0.5 18 85.1 95.2
30 8 13 1.5 18 115.3 97.75
31 10 28 1 18 15.5 35.44
32 10 20 0.7 18 18.8 42.4
33 10 17 0.5 18 17.3 41.98
34 10 15 1.5 18 66.4 83.58
35 10 13 1.2 18 58.6 82.52
36 13 28 0.7 18 18.1 42.48
37 13 20 0.5 18 21.8 50.7
38 13 17 1.5 18 77.1 87.58
39 13 15 1.2 18 62 82.24
40 13 13 1 18 36.2 66.06
41 15 28 0.5 18 26.9 62.04
42 15 20 1.5 18 135.3 98.15
43 15 17 1.2 18 61.3 84.26
44 15 15 1 18 36.3 68.88
45 15 13 0.7 18 17.7 45.72
46 18 28 1.5 18 184.9 99.2
47 18 20 1.2 18 80.5 90.58
48 18 17 1 18 41.9 69.6
49 18 15 0.7 18 21.2 48.84
50 18 13 0.5 18 8 22.74 步骤2、确定网络的初始参数
参数数值
最大训练次数50000
隐含层神经元数量8
网络学习速率0.033
训练的目标误差
3
?
0.6510-
步骤3、初始化网络权值和阈值
因为是4个输入因子8个隐含层神经元,则第一层与第二层之间的权值w(t)
ij ?的随机数矩阵:
为84
[-0.044 0.325 -0.099 0.149
-0.031 0.180 0.332 0.350
0.2393 0.364 0.206 0.187
0.1475 0.248 0.394 0.322
-0.005 0.191 0.163 0.269 0.1475 0.307 0.139 0.192 -0.026 0.339 0.300 0.023 -0.072 0.394 0.013 0.233]
神经网络的阈值是用来激活神经元而设置的一个临界值,有多少个神经元就会有多少个阈值,则第二层神经元的阈值(t)ij B 为81? 的矩阵: [-0.058
0.212 0.230 0.264 0.345 0.391 0.284 0.190]T
同理,第二层与第三层之间的权值(t)jk w 为28? 的随机数矩阵: [0.364 -0.091 0.331 0.322 0.176 -0.084 0.081 0.144 0.190 -0.039 0.142 0.004 0.214 0.20 -0.075 -0.003] 同理,第三层阈值(t)jk B 为21? 的矩阵:
[-0.038 0.002] 步骤4、计算第一层神经元的输入与输出
假设第一层神经元中放置的是线性函数,所以网络第一层输入和输出都等于实际输入样本的值, 所以第一层输出值1O =X 。
但是,因为输入和输出样本的量纲以及量级都不相同,所以须进行归一化处理。
步骤5、计算第二层神经元的输入
对于第二层,神经元的输入是第一层所有的神经元的值与阈值的和,即
2ij ij I w X B ones =?+? ,其中ones 是一个全为1的矩阵,所以2I 是一个850? 的矩阵,很容易得出2I 。 步骤6、计算第二层神经元的输出
假设第二层神经元激励函数为单极S 型函数,即为1
f(x)1x
e -=
+ ,所以第二层神经元的输出2
21
1I O e
-=
+ .所以第二层输出也是一个850? 的矩阵。 步骤7、计算第三层的输入和输出
第三层输入与第二层输入相似,即32jk jk I w O B ones =?+? ,所以3I 是一个
250? 的矩阵。
步骤8、计算能量函数E
能量函数,即网络输出与实际输出样本之间的误差平方和,其目的是在达到
预定误差就可以停止训练网络。Y 是归一化处理后的实际输出样本。则:
23(Y O )136.9006E =-=∑
步骤9、计算第二层与第三层之间的权值和阈值调整量
权值调整量:32(Y O )O jk jk
E
w w η
η??=-=-?-?? ,jk w ? 是一个28? 的矩阵 [-33.644 -39.7786 -38.55 -40.2511 -41.395 -41.33 -37.804 -38.256 -11.433 -11.8610 -12.38 -12.077 -12.935 -13.32 -12.509 -12.633]
同理,阈值调整量:3B (Y O )jk jk
E
ones B η??=
=-?-?? ,jk B ? 是一个21? 矩阵:
[-67.628 -22.343]
步骤10、计算第一层与第二层之间的权值和阈值调整量
因为对于传递函数1f (x)1x
e
-=
+,有 '
(x)(x)[1(x)]f f f =- , 故权值调整量: 322(Y )(1)ij jk ij
E
w w O O O X w η
η??=-=-??-??-?? 所以ij w ? 是一个84? 的矩阵: -0.183 0.482 0.710 -3.319 0.056 -0.135 -0.193 0.769 -0.099 0.547 0.615 -2.893 -0.138 0.635 0.438 -2.696 -0.072 0.132 0.615 -1.432 0.0764 -0.39 0.320 0.728 -0.062 0.251 -0.066 -0.730 -0.101 0.323 0.1105 -1.263 同理,阈值调整量:322B (Y )(1)ij jk ij
E
w O O O ones B η??=
=-??-??-??
所以ij B ? 为81? 的矩阵: [-7.113
1.674 -6.119 -5.1014
-3.945 0.2310 -0.9220 -2.335]T
步骤11 计算调整之后的权值和阈值
(t 1)(t)w +(t)(t 1)(t)+B (t)(t 1)(t)w +(t)
(t 1)(t)+B (t)jk jk jk jk jk
jk jk jk jk jk
ij ij ij ij ij ij ij ij ij ij
E
w w w w E
B B B B E
w w w w E
B B B B ηηηη
?+=-+=???+=-+=???+=-+=???+=-+=??
此算法是让网络沿着E 变化量最小的方向搜索,所以经过一段时间的训练之后,神经网络会慢慢蜷缩收敛,直到完全拟合成目标输出值或接近目标输出值。
下面是y1的神经网络训练动态图:
步骤12 还原网络输出的值
因为在训练网络时,将输入和输出的样本经过了归一化的处理,所以要将3O 还原成原始数据的量级。
根据此算法,我们编出了matlab 程序,最终拟合结果如下:
可以看出结果并不理想,相对于回归模型,误差并没有减小。
4.2.3模型的修正
由于模型的参数没有选择好,隐含层数量不足,模拟的效果并不好,于是我们重新建立了神经网络模型。
最大训练次数5000
学习速率0.05
隐含神经元层数 3
训练目标误差
3
10 65
.0-
?
第一层隐含神经元个数8
第二层隐含神经元个数12
第三层隐含神经元个数8
第一层隐含神经元传递函数Logsig函数
第二层隐含神经元传递函数Tansig函数
第二层隐含神经元传递函数Logsig函数
通过编写MATLAB工具箱程序,训练得到了下面的结果:
由此得到的结果从视觉上非常完美。
我们用训练得到的网络验证了全部数据并提取了误差:
可以得到只有几个数据不是那么精确。
评价与总结
我们抽取了部分数据,分别检验了回归模型和通过神经网络算法训练得到的网络,得到了误差,在此我们进行了具体的对比:
Y1各种方法的误差如下表所示:
多元线性回归多元非线性回归神经网络
-85.0904821787169 -95.61931925 3.29699779745964 424.792490319265 544.5753159 1.03267427223443
-306.965839850488 -118.2241891 1.41849261959817 387.691377753137 591.0004461 1.40769147165338 380.142282029398 578.5609411 -0.344012787002839 -199.616107238563 -80.20782097 -1.45635726638154 -129.642502715347 -36.23732595 -0.741747572508700 128.499371703981 149.0573092 -2.38062294681544 -154.070310811591 -285.4248746 -0.983439225507443 -86.1574120256765 -81.42055792 -0.0768780510191220 113.101241465220 -20.57910932 1.64258269795374 97.5809506531405 -109.527153 -4.60593752005365 21.7785166473820 20.66334204 0.315506918113215 -75.7492520794316 97.97765872 0.0213160796229772 160.434115149431 193.9322939 -7.79320436823031 45.4330777517973 -48.75028985 0.962562717276339
-89.5074215609946 -72.65979483 -0.193131496568324 37.1321320006323 231.9745218 -1.98561499149395 131.160156045192 98.35915699 -31.6251837157761 153.754072389387 -32.9530268 -2.43601124801970
Y2各种方法的误差如下表所示:
多元线性回归多元非线性回归神经网络
-30.3987049539152 6.152597099 0.0872585163590145 -12.9490793890884 -19.38873073 -0.0205934880545422 10.7510720967549 -21.49794239 0.0911796316330200 -11.0095339782298 -44.87957022 0.118073363295188 -39.8078620699404 -59.12548187 -0.0973856112318899 51.2514250166275 32.2781036 -0.201480587958699 -28.5404648955414 -52.64580805 -0.250510979385689 -56.9811916534564 -64.47243588 -0.328652838291651 37.4678862524014 40.39669528 -0.0458938130025786 4.89850695510008 11.68747331 -0.0897937770061654 -7.32940262702650 3.55897192 -3.54122679937848 -19.8734750618800 -3.304613092 -0.984659461024723 -11.7901706398783 -28.05852475 0.0509553283729591 19.9219390377847 -12.39364672 -0.0234371252933647 -5.39651527410106 -23.63857455 -0.288405093538314
40.7565778922047 42.43752124 0.467194393960085 -30.9074590838061 -41.38639041 -0.114443773936806 12.1920784918839 -25.40561238 -0.0272714852628626 -38.3271965029317 -43.61624021 -0.986235253808523 -18.7163800397156 5.022890952 -0.993467108071047 从对比中我们可以得出,无论是通过模拟的视觉效果上还是最后的误差对比中,我们可以明显的得出,神经网络相对于回归模型误差小,得到的结果更加的精确。而回归模型中非线性相对于线性拟合的效果更好一些,对于1y和2y,不管是哪种模型,对于y2的拟合效果要比y1更精确。神经网络具有很强的鲁棒性、记忆能力、非线性映射能力以及强大的自学习能力,因此有很大的应用市场。但是实际神经网络也特别的不稳定,例如学习效率和神经元数量等参数对最后训练的结果影响非常的大,神经网络把一切问题的特征都变为数字,把一切推理都变为数值计算,其结果势必是丢失信息,因此理论和学习算法还有待于进一步完善和提高。而回归分析法在分析多因素模型时,更加简单和方便;运用回归模型,只要采用的模型和数据相同,通过标准的统计方法可以计算出唯一的结果,但在图和表的形式中,数据之间关系的解释往往因人而异,不同分析者画出的拟合曲线很可能也是不一样的;回归分析可以准确地计量各个因素之间的相关程度与回归拟合程度的高低,提高预测方程式的效果;在回归分析法时,由于实际一个变量仅受单个因素的影响的情况极少,要注意模式的适合范围,所以一元回归分析法适用确实存在一个对因变量影响作用明
显高于其他因素的变量是使用。多元回归分析法比较适用于实际经济问题,受多因素综合影响时使用。但是有时候在回归分析中,选用何种因子和该因子采用何种表达式只是一种推测,这影响了用电因子的多样性和某些因子的不可测性,使得回归分析在某些情况下受到限制。不管是哪种方法都有各自的优缺点。合理选择适合问题的方法是最重要的。
5.参考文献
【1】姜启源.数学模型.北京:高等教育出版社,2003.
【2】赵静,但琦等,数学建模与数学实验,北京:高等教育出版社施普林格出版社,2000年
【3】李庆扬,王能超,易大义.数值分析(第四版)[M].北京:清华大学出版社,2001.
【4】张德丰.MATLAB数值计算方法.北京:机械工业出版社,2010.
【5】王惠文,《偏最小二乘回归方法及应用》,国防科技出版社,北京,1996.
【6】徐国章,等.曲线拟合的最小二乘法在数据采集中的应用【J】.冶金自动化增刊,2004年
【7】(美)里德.数值分析与科学计算.北京:清华大学出版社,2008.
【8】(美)约翰逊.数值分析与科学计算.北京:科学出版社,2012.
【9】姜绍飞,张春丽,钟善桐.BP网络模型的改进方法探讨【J】哈尔滨建筑大学学报,2000.
【10】郝中华.《B P神经网络的非线性思想》. 洛阳师范学院学报2008.3(4) 【11】巨军让,卓戎.《B P神经网络在Matlab中的方便实现》.新疆石油学院学报.2008.2
【12】周开利,康耀红编著.《神经网络模型及其MATLAB仿真程序设计》.2006:10-43
年份 (年) 1(1988) 2(1989) 3(1990) 4(1991) 5(1992) 6(1993) 7(1994) 8(1995) 实际值 (ERI) 年份 (年) 9(1996) 10(1997) 11(1998) 12(1999) 13(2000) 14(2001) 15(2002) 16(2003) 实际值 (ERI) BP 神经网络的训练过程为: 先用1988 年到2002 年的指标历史数据作为网络的输入,用1989 年到2003 年的指标历史数据作为网络的输出,组成训练集对网络进行训练,使之误差达到满意的程度,用这样训练好的网络进行预测. 采用滚动预测方法进行预测:滚动预测方法是通过一组历史数据预测未来某一时刻的值,然后把这一预测数据再视为历史数据继续预测下去,依次循环进行,逐步预测未来一段时期的值. 用1989 年到2003 年数据作为网络的输入,2004 年的预测值作为网络的输出. 接着用1990 年到2004 年的数据作为网络的输入,2005 年的预测值作为网络的输出.依次类推,这样就得到2010 年的预测值。 目前在BP 网络的应用中,多采用三层结构. 根据人工神经网络定理可知,只要用三层的BP 网络就可实现任意函数的逼近. 所以训练结果采用三层BP模型进行模拟预测. 模型训练误差为,隐层单元数选取8个,学习速率为,动态参数,Sigmoid参数,最大迭代次数3000.运行3000次后,样本拟合误差等于。 P=[。。。];输入T=[。。。];输出 % 创建一个新的前向神经网络 net_1=newff(minmax(P),[10,1],{'tansig','purelin'},'traingdm') % 当前输入层权值和阈值 inputWeights={1,1} inputbias={1} % 当前网络层权值和阈值 layerWeights={2,1} layerbias={2} % 设置训练参数 = 50; = ; = ; = 10000; = 1e-3;
回归分析——20121060025 吕佳琪 企业编号生产性固定资产价值(万元)工业总产值(万元) 1318524 29101019 3200638 4409815 5415913 6502928 7314605 812101516 910221219 1012251624 合计65259801 (2)建立直线回归方程; (3)计算估价标准误差; (4)估计生产性固定资产(自变量)为1100万元时总产值(因变量)的可能值。解: (1)画出散点图,观察二变量的相关方向 x=[318 910 200 409 415 502 314 1210 1022 1225]; y=[524 1019 638 815 913 928 605 1516 1219 1624]; plot(x,y,'or') xlabel('生产性固定资产价值(万元)') ylabel('工业总产值(万元)') 由图形可得,二变量的相关方向应为直线 (2)
x=[318 910 200 409 415 502 314 1210 1022 1225]; y=[524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x))', x']; [b,bint,r,rint,stats] = regress(y',X,0、05); b,bint,stats b = 395、5670 0、8958 bint = 210、4845 580、6495 0、6500 1、1417 stats = 1、0e+004 * 0、0001 0、0071 0、0000 1、6035 上述相关系数r为1,显著性水平为0 Y=395、5670+0、8958*x (3) 计算方法:W=((Y1-y1)^2+……+(Y10-y10)^2)^(1/2)/10 利用SPSS进行回归分析:
1.1 BP 神经网络原理简介 BP 神经网络是一种多层前馈神经网络,由输入、输出、隐藏层组成。该网络的主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐藏层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP 神经网络预测输出不断逼近期望输出。结构图如下: 隐藏层传输函数选择Sigmoid 函数(也可以选择值域在(-1,1)的双曲正切函数,函数‘tansig ’),其数学表达式如下: x e 11)x ( f α-+=,其中α为常数 输出层传输函数选择线性函数:x )x (f = 1.隐藏层节点的选择 隐藏层神经元个数对BP 神经网络预测精度有显著的影响,如果隐藏层节点数目太少,则网络从样本中获取信息的能力不足,网络容易陷入局部极小值,有时可能训练不出来;如果隐藏层节点数目太多,则学习样本的非规律性信息会出现“过度吻合”的现象,从而导致学习时间延长,误差也不一定最佳,为此我们参照以下经验公式: 12+=I H ]10,1[ ,∈++=a a O I H I H 2log = 其中H 为隐含层节点数,I 为输入层节点数,O 为输出层节点数,a 为常数。 输入层和输出层节点的确定: 2.输入层节点和输出层节点的选择 输入层是外界信号与BP 神经网络衔接的纽带。其节点数取决于数据源的维数和输入特征向量的维数。选择特征向量时,要考虑是否能完全描述事物的本质特征,如果特征向量不能有效地表达这些特征,网络经训练后的输出可能与实际有较大的差异。因此在网络训练前,应全面收集被仿真系统的样本特性数据,并在数据处理时进行必要的相关性分析,剔除那些边沿和不可靠的数据,最终确定出数据源特征向量的维度。对于输出层节点的数目,往往需要根据实际应用情况灵活地制定。当BP 神经网络用于模式识别时,模式的自身特性就决定了输出的结果数。当网络作为一个分类器时,输出层节点数等于所需信息类别数。(可有可无) 训练好的BP 神经网络还只能输出归一化后的浓度数据,为了得到真实的数据
什么是回归分析 回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。 回归分析之一多元线性回归模型案例解析 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:(数据可以先用excel建立再通过spss打开) 点击“分析”——回归——线性——进入如下图所示的界面:
摘要 回归分析和方差分析是探究和处理相关关系的两个重要的分支,其中回归分析方法是预测方面最常用的数学方法,它是利用统计数据来确定变量之间的关系,并且依据这种关系来预测未来的发展趋势。本文主要介绍了一元线性回归分析方法和多元线性回归分析方法的一般思想方法和一般步骤,并且用它们来研究和分析我们在生活中常遇到的一些难以用函数形式确定的变量之间的关系。在解决的过程中,建立回归方程,再通过该回归方程进行预测。 关键词:多元线性回归分析;参数估计;F检验
回归分析在数学建模中的应用 Abstract Regression analysis and analysis of variance is the inquiry and processing of the correlation between two important branches, wherein the regression analysis method is the most commonly used mathematical prediction method, it is the use of statistical data to determine the relationship between the variables, and based on this relationship predict future trends. introduces a linear regression analysis and multiple linear regression analysis method general way of thinking and the general steps, and use them to research and analysis that we encounter in our life, are difficult to determine as a function relationship between the variables in the solving process, the regression equation is established by the regression equation to predict. Keywords:Multiple linear regression analysis; parameter estimation;inspection II
1、 多元线性回归在回归分析中,如果有两个或两个以上的自变量,就称为 多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。 在实际经济问题中,一个变量往往受到多个变量的影响。例如,家庭消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。这样的模型被称为多元线性回归模型。(multivariable linear regression model ) 多元线性回归模型的一般形式为: 其中k 为解释变量的数目,j β (j=1,2,…,k)称为回归系数(regression coefficient)。上式也被称为总体回归函数的随机表达式。它的非随机表达式为: j β也被称为偏回归系数(partial regression coefficient)。 2、 多元线性回归计算模型 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和(Σe)为最小的前提下,用最小二乘法或最大似然估计法求解参数。 设( 11 x , 12 x ,…, 1p x , 1 y ),…,( 1 n x , 2 n x ,…, np x , n y )是一个样本, 用最大似然估计法估计参数: 达 到最小。
把(4)式化简可得: 引入矩阵: 方程组(5)可以化简得: 可得最大似然估计值:
3、Matlab 多元线性回归的实现 多元线性回归在Matlab 中主要实现方法如下: (1)b=regress(Y, X ) 确定回归系数的点估计值 其中 (2)[b,bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检 验回归模型 ①bint 表示回归系数的区间估计. ②r 表示残差 ③rint 表示置信区间 ④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r2、F 值、与F 对应的 概率p 说明:相关系数r2越接近1,说明回归方程越显著;F>F1-alpha(p,n-p-1) 时拒绝H0,F 越大,说明回归方程越显著;与F 对应的概率p<α 时拒绝H0,回归模型成立。 ⑤alpha 表示显著性水平(缺省时为0.05) (3)rcoplot(r,rint) 画出残差及其置信区间
1、 多元线性回归 在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。 在实际经济问题中,一个变量往往受到多个变量的影响。例如,家庭消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。这样的模型被称为多元线性回归模型。(multivariable linear regression model ) 多元线性回归模型的一般形式为: 其中k 为解释变量的数目,j β (j=1,2,…,k)称为回归系数(regression coefficient)。上式也被称为总体回归函数的随机表达式。它的非随机表达式为: j β也被称为偏回归系数(partial regression coefficient)。 2、 多元线性回归计算模型 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和(Σe)为最小的前提下,用最小二乘法或最大似然估计法求解参数。 设( 11 x , 12 x ,…, 1p x , 1 y ),…,( 1 n x , 2 n x ,…, np x , n y )是一个样本, 用最大似然估计法估计参数: 达 到最小。
把(4)式化简可得: 引入矩阵: 方程组(5)可以化简得: 可得最大似然估计值:
3、Matlab 多元线性回归的实现 多元线性回归在Matlab 中主要实现方法如下: (1)b=regress(Y, X ) 确定回归系数的点估计值 其中 (2)[b,bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检 验回归模型 ①bint 表示回归系数的区间估计. ②r 表示残差 ③rint 表示置信区间 ④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r2、F 值、与F 对应的 概率p 说明:相关系数r2越接近1,说明回归方程越显著;F>F1-alpha(p,n-p-1) 时拒绝H0,F 越大,说明回归方程越显著;与F 对应的概率p<α 时拒绝H0,回归模型成立。 ⑤alpha 表示显著性水平(缺省时为0.05) (3)rcoplot(r,rint) 画出残差及其置信区间
实习报告书 学生姓名: 学号: 学院名称: 专业名称: 实习时间: 2014年 06 月 05 日 第六次实验报告要求 实验目的: 掌握多元线性回归模型的原理,多元线性回归模型的建立、估计、检验及解释变量的增减的方法,以及运用相应的Matlab软件的函数计算。 实验内容: 已知某市粮食年销售量、常住人口、人均收入、肉、蛋、鱼的销售数据,见表1。请选择恰当的解释变量和恰当的模型,建立粮食年销售量的回归模型,并对其进行估计和检验。
表1 某市粮食年销售量、常住人口、人均收入、肉、蛋、鱼的销售数据 年份粮食年销售 量Y/万吨 常住人口 X2/万人 人均收 入X3/ 元 肉销售 量X4/万 吨 蛋销售 量X5/ 万吨 鱼虾销 售量 X6/万吨 197498.45560.20153.20 6.53 1.23 1.89 1975100.70603.11190.009.12 1.30 2.03 1976102.80668.05240.308.10 1.80 2.71 1977133.95715.47301.1210.10 2.09 3.00 1978140.13724.27361.0010.93 2.39 3.29 1979143.11736.13420.0011.85 3.90 5.24 1980146.15748.91491.7612.28 5.13 6.83 1981144.60760.32501.0013.50 5.418.36 1982148.94774.92529.2015.29 6.0910.07
1983158.55785.30552.7218.107.9712.57 1984169.68795.50771.1619.6110.1815.12 1985162.14804.80811.8017.2211.7918.25 1986170.09814.94988.4318.6011.5420.59 1987178.69828.731094.6 523.5311.6823.37 实验要求: 撰写实验报告,参考第10章中牙膏销售量,软件开发人员的薪金两个案例,写出建模过程,包括以下步骤 1.分析影响因变量Y的主要影响因素及经济意义; 影响因变量Y的主要影响因素有常住人口数量,城市中人口越多,需要的粮食数量就越多,粮食的年销售量就会相应增加。粮食销量还和人均收入有关,人均收入增加了,居民所能购买的粮食数量也会相应增加。另外,肉类销量、蛋销售量、鱼虾销售量也会对粮食的销售量有影响,这些销量增加了,也表示居民的饮食结构也在发生变化,生活水平在提高,所以相应的,生活水平提升了,居民也有能力购买更多的粮食。
神经网络 例 解:设计BP网,编写文件ch14eg4.m,结构和参数见程序中的说明。clear;close all; x = [0:0.25:10]; y = 0.12*exp(-0.213*x)+0.54*exp(-0.17*x).*sin(1.23*x); % x,y分别为输入和目标向量 net=newff(minmax(x),[20,1],{'tansig','purelin'}); % 创建一个前馈网络 y0 = sim(net,x); % 仿真未经训练的网络net net.trainFcn='trainlm'; % 采用L-M优化算法TRAINLM net.trainParam.epochs = 500; net.trainParam.goal = 1e-6; % 设置训练参数[net,tr]=train(net,x,y); % 调用相应算法训练网络 y1 = sim(net,x); % 对BP网络进行仿真 E = y-y1; MSE=mse(E) % 计算仿真误差
figure; % 下面绘制匹配结果曲线 plot(x,y0,':',x,y1,'r*',x,0.12*exp(-0.213*x)+0.54*exp(-0.17*x).*sin(1.23*x),'b'); 运行如下: >> ch14eg4 MSE =9.6867e-007 例14.6 蠓虫分类问题。两种蠓虫Af和Apf已由生物学家W.L.Grogan和W.W.Wirth(1981)根据他们的触角长度和翅长加以区分。现测得6只Apf蠓虫和9只Af蠓虫的触长、翅长的数据如下: Apf: (1.14,1.78),(1.18,1.96),(1.20,1.86),(1.26,2.),(1.28,2.00),(1.30,1.96). Af: (1.24,1.72),(1.36,1.74),(1.38,1.64),(1.38,1.82),(1.38,1.90),(1.4,1.7), (1.48,1.82),(1.54,1.82),(1.56,2.08) 请用恰当的方法对触长、翅长分别为(1.24,1.80),(1.28,1.84),(1.40,2.04)的3个样本进行识别。 解:设计一个Lvq神经网络进行分类。编写m文件ch14eg6.m clear; close all; Af=[1.24,1.36,1.38,1.38,1.38,1.4,1.48,1.54,1.56;1.27,1.74,1.64,1.82, 1.9,1.7,1.82,1.82,2.08]; Apf=[1.14 1.18 1.20 1.26 1.28 1.30;1.78 1.96 1.86 2.00 2.00 1.96]; x=[Af Apf];%输入向量 y0=[2*ones(1,9) ones(1,6)];%类2表示Af, 类1表示Apf y=ind2vec(y0);%将下标向量转换为单值向量作为目标向量 net = newlvq(minmax(x),8,[0.6,0.4]);%建立LVQ网络 net.trainParam.show=100; net.trainParam.epochs = 1000;%设置参数 net = train(net,x,y); ytmp=sim(net,x);%对网络进行训练并用原样本仿真 y1=vec2ind(ytmp);%将单值向量还原为下标向量作为输出向量 xt=[1.24,1.28,1.40;1.80,1.84,2.04];%测试输入样本 yttmp=sim(net,xt)%对网络用新样本进行仿真 yt=vec2ind(yttmp)%输出新样本所属类别 figure;%打开一个图形窗口 plot(Af(1,:),Af(2,:),'+',Apf(1,:),Apf(2,:),'o',xt(1,:),xt(2,:),'*');
数学建模
论文题目: 一个医药公司的新药研究部门为了掌握一种新止痛剂的疗效,设计了一个药物试验,给患有同种疾病的病人使用这种新止痛剂的以下4个剂量中的某一个:2 g,5 g,7 g和10 g,并记录每个病人病痛明显减轻的时间(以分钟计). 为了解新药的疗效与病人性别和血压有什么关系,试验过程中研究人员把病人按性别及血压的低、中、高三档平均分配来进行测试. 通过比较每个病人血压的历史数据,从低到高分成3组,分别记作,和. 实验结束后,公司的记录结果见下表(性别以0表示女,1表示男). 请你为该公司建立一个数学模型,根据病人用药的剂量、性别和血压组别,预测出服药后病痛明显减轻的时间.
一、摘要 在农某医药公司为了掌握一种新止痛药的疗效,设计了一个药物实验,通过观测病人性别、血压和用药剂量与病痛时间的关系,预测服药后病痛明显减轻的时间。我们运用数学统计工具m i n i t a b软件,对用药剂量,性别和血压组别与病痛减轻
时间之间的数据进行深层次地处理并加以讨论概率值P (是否<)和拟合度R-S q的值是否更大(越大,说明模型越好)。 首先,假设用药剂量、性别和血压组别与病痛减轻时间之间具有线性关系,我们建立了模型Ⅰ。对模型Ⅰ用m i n i t a b 软件进行回归分析,结果偏差较大,说明不是单纯的线性关系,然后对不同性别分开讨论,增加血压和用药剂量的交叉项,我们在模型Ⅰ的基础上建立了模型Ⅱ,用m i n i t a b软件进行回归分析后,用药剂量对病痛减轻时间不显着,于是我们有引进了用药剂量的平方项,改进模型Ⅱ建立了模型Ⅲ,用m i n i t a b 软件进行回归分析后,结果合理。最终确定了女性病人服药后病痛减轻时间与用药剂量、性别和血压组别的关系模型: Y=1x 3x 1x 3x 2 1 x 对模型Ⅱ和模型Ⅲ关于男性病人用m i n i t a b软件进行回归分析,结果偏差依然较大,于是改进模型Ⅲ建立了模型Ⅳ,用m i n i t a b软件进行回归分析后,结果合理。最终确定了男性病人服药后病痛减轻时间与用药剂量、性别和血压组别的关系模 型:Y=1x1x 3x 2 1 x关键词止痛剂药剂量性别病痛减轻时 间
曲线拟合与回归分析 1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下: (1)说明两变量之间的相关方向; (2)建立直线回归方程; (3)计算估计标准误差; (4)估计生产性固定资产(自变量)为1100万元时的总资产 (因变量)的可能值。 解: (1)工业总产值是随着生产性固定资产价值的增长而增长的,存 在正向相关性。 用spss回归 (2)spss回归可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示: .0+ y =x 896 . 395 567 (3)spss回归知标准误差为80.216(万元)。 (4)当固定资产为1100时,总产值为: (0.896*1100+395.567-80.216~0.896*1100+395.567+80.216) 即(1301.0~146.4)这个范围内的某个值。 MATLAB程序如下所示: function [b,bint,r,rint,stats] = regression1 x = [318 910 200 409 415 502 314 1210 1022 1225]; y = [524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x))', x']; [b,bint,r,rint,stats] = regress(y',X,0.05); display(b); display(stats); x1 = [300:10:1250]; y1 = b(1) + b(2)*x1; figure;plot(x,y,'ro',x1,y1,'g-');
BP神经网络 算法原理: 输入信号 x i通过中间节点(隐层点)作用于输出节点,经过非线形变换,产生输 出信号 y k,网络训练的每个样本包括输入向量x 和期望输出量d,网络输出值y 与期望输出值 d 之间的偏差,通过调整输入节点与隐层节点的联接强度取值w ij和隐层节点与输出节点之间的联接强度T jk以及阈值,使误差沿梯度方向下降,经过反复学习训练, 确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。 变量定义: 设输入层有 n 个神经元,隐含层有p 个神经元 , 输出层有 q 个神经元 输入向量: x x1 , x2 ,L , x n 隐含层输入向量:hi hi1, hi2 ,L , hi p 隐含层输出向量:ho ho1 , ho2 ,L ,ho p 输出层输入向量:yi yi1, yi2 ,L , yi q 输出层输出向量:yo yo1, yo2 ,L , yo q 期望输出向量 : do d1, d2 ,L , d q 输入层与中间层的连接权值:w ih 隐含层与输出层的连接权值:w ho 隐含层各神经元的阈值: b h 输出层各神经元的阈值:b o 样本数据个数 :k1,2,L m 激活函数 : f 误差函数: e 1 q(d o (k )yo o (k )) 2 2 o1
算法步骤: Step1. 网络初始化 。给各连接权值分别赋一个区间( -1 , 1)内的随机数,设定 误差函数 e ,给定计算精度值 和最大学习次数 M 。 Step2. 随机选取第 k 个输入样本 x( k) x 1( k ), x 2 (k),L , x n (k ) 及对应期望输出 d o ( k) d 1 (k ), d 2 ( k),L , d q (k) Step3. 计算隐含层各神经元的输入 n hi h ( k) w ih x i (k ) b h h 1,2,L , p 和输出 i 1 ho h (k) f (hi h (k )) h 1,2, L , p 及 输 出 层 各 神 经 元 的 输 入 p yi o (k ) w ho ho h (k) b o o 1,2,L q 和输出 yo o ( k) f ( yi o (k )) o 1,2, L , p h 1 Step4. 利用网络期望输出和实际输出, 计算误差函数对输出层的各神经元的偏导 数 o (k ) 。 e e yi o w ho yi o w ho p yi o ( k) ( h w ho ho h (k ) b o ) ho h (k ) w ho w ho e ( 1 q (d o ( k) yo o (k))) 2 2 o 1 ( d o (k ) yi o yi o (d o (k) yo o (k ))f ( yi o (k )) @ o (k ) Step5. 利用隐含层到输出层的连接权值、输出层的 差函数对隐含层各神经元的偏导数 h (k ) 。 e e yi o o ( k) ho h (k ) w ho yi o w ho e e hi h (k) w ih hi h ( k) w ih n hi h (k ) ( w ih x i (k ) b h ) i 1 x i ( k) w ih w ih yo o (k )) yo o (k ) o ( k) 和隐含层的输出计算误
什么就是回归分析 回归分析(regression analysis)就是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析与多元回归分析;按照自变量与因变量之间的关系类型,可分为线性回归分析与非线性回归分析。如果在回归分析中,只包括一个自变量与一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量与自变量之间就是线性关系,则称为多元线性回归分析。 回归分析之一多元线性回归模型案例解析 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟
BP 神经网络 算法原理: 输入信号i x 通过中间节点(隐层点)作用于输出节点,经过非线形变换,产生输出信号k y ,网络训练的每个样本包括输入向量x 和期望输出量d ,网络输出值y 与期望输出值d 之间的偏差,通过调整输入节点与隐层节点的联接强度取值ij w 和隐层节点与输出节点之间的联接强度jk T 以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。 变量定义: 设输入层有n 个神经元,隐含层有p 个神经元,输出层有q 个神经元 输入向量:()12,, ,n x x x x = 隐含层输入向量:()12,,,p hi hi hi hi = 隐含层输出向量:()12,,,p ho ho ho ho = 输出层输入向量:()12,,,q yi yi yi yi = 输出层输出向量:()12,,,q yo yo yo yo = 期望输出向量: ()12,, ,q do d d d = 输入层与中间层的连接权值: ih w 隐含层与输出层的连接权值: ho w 隐含层各神经元的阈值:h b 输出层各神经元的阈值: o b 样本数据个数: 1,2,k m = 激活函数: ()f ? 误差函数:2 1 1(()())2q o o o e d k yo k ==-∑
算法步骤: Step1.网络初始化 。给各连接权值分别赋一个区间(-1,1)内的随机数,设定误差函数e ,给定计算精度值ε和最大学习次数M 。 Step2.随机选取第k 个输入样本()12()(),(), ,()n x k x k x k x k =及对应期望输出 ()12()(),(),,()q d k d k d k d k =o Step3.计算隐含层各神经元的输入()1 ()()1,2, ,n h ih i h i hi k w x k b h p ==-=∑和输出 () ()(())1,2, ,h h ho k f hi k h p ==及 输出层各神经元的输入 ()1 ()()1,2, p o ho h o h yi k w ho k b o q ==-=∑和输出()()(())1,2, ,o o yo k f yi k o p == Step4.利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数()o k δ。 o ho o ho yi e e w yi w ???=??? (()) () ()p ho h o o h h ho ho w ho k b yi k ho k w w ?-?==??∑ 2 1 1((()()))2(()())()(()())f (()) () q o o o o o o o o o o o o d k yo k e d k yo k yo k yi yi d k yo k yi k k δ=?-?'==--??'=---∑ Step5.利用隐含层到输出层的连接权值、输出层的()o k δ和隐含层的输出计算误差函数对隐含层各神经元的偏导数()h k δ。 ()()o o h ho o ho yi e e k ho k w yi w δ???==-??? 1() ()(()) () () h ih h ih n ih i h h i i ih ih hi k e e w hi k w w x k b hi k x k w w =???= ????-?==??∑
第1章引言 1.1 人工神经网络的介绍 人工神经网络(Artificial Neural Networks, ANN),亦称为神经网络(Neural Networks,NN),是由大量的处理单元(神经元Neurons)广泛互联而成的网络,是对大脑的抽象、简化和模拟,反映人脑的基本特性.人工神经网络的研究是从人脑的生理结构出发来研究人的智能行为,模拟人脑信息处理的功能.它是根植于神经科学、数学、物理学、计算机科学及工程等科学的一种技术. 人工神经网络是由简单的处理单元所组成的大量并行分布的处理机,这种处理机具有储存和应用经念知识的自然特性,它与人脑的相似之处概括两个方面:一是通过学习过程利用神经网络从外部环境中获取知识;二是内部神经元(突触权值)用来存储获取的知识信息. 人工神经网络具有四个基本特征: (1)非线性非线性关系是自然界的普遍特性.大脑的智慧就是一种非线性现象.人工神经元处于激活或抑制二种不同的状态,这种行为在数学上表现为一种非线性关系.具有阈值的神经元构成的网络具有更好的性能,可以提高容错性和存储容量. (2)非局限性一个神经网络通常由多个神经元广泛连接而成.一个系统的整体行为不仅取决于单个神经元的特征,而且可能主要由单元之间的相互作用、相互连接所决定.通过单元之间的大量连接模拟大脑的非局限性.联想记忆是非局限性的典型例子. (3)非常定性人工神经网络具有自适应、自组织、自学习能力.神经网络不但处理的信息可以有各种变化,而且在处理信息的同时,非线性动力系统本身也在不断变化.经常采用迭代过程描写动力系统的演化过程. (4)非凸性一个系统的演化方向,在一定条件下将取决于某个特定的状态函数.例如能量函数,它的极值相应于系统比较稳定的状态.非凸性是指这种函数有多个极值,故系统具有多个较稳定的平衡态,这将导致系统演化的多样性. 人工神经网络是近年来的热点研究领域,涉及到电子科学技术、信息与通讯工程、计算机科学与技术、电器工程、控制科学与技术等诸多学科,其应用领域包括:建模、时间序列分析、模式识别和控制等,并在不断的拓展.本文正是居于数学建模的神经网路应用. 1.2人工神经网络发展历史 20世纪40年代中期期,在科学发展史上出现了模拟电子计算机和数字电子计算机两种新的计算工具和一种描述神经网络工作的数学模型.由于电子技术(特别是大规模、超大规模集成电路)的发展,使数字电子计算机作为高科技计算工具已发展到当今盛世地步,而人工神经网络模拟仿真生物神经网络的探索则经历了半个世纪的曲折发展道路.
1. 一个班有7名男性工人,他们的身高和体重列于下表 请把他们分成若干类并指出每一类的特征。这里身高以米为单位,体重以千克为单位。 2.有两种跳蚤共10只,分别测得它们四个指标值如表。 样本号甲种乙种 X3 X4 X1 X2 X3 X4 X1 X 2 1 189 245 137 163 181 305 184 209 2 192 260 132 217 158 237 13 3 188 3 217 276 141 192 18 4 300 166 231 4 221 299 142 213 171 273 162 213 5 171 239 128 158 181 297 163 224 1)用距离判别法建立判别准则。 2)问(192, 287, 141,198 和(197, 303, 170, 205 各属于哪一种? 3.考察温度x对产量y的影响,测得下列10组数据: 求y关于x的线性回归方程,检验回归效果是否显著,并预测 x=42C时产量的估值 4. 在研究化学动力学反应过程中,建立了一个反应速度和反应物 %-备 含量的数学模型,形式为y — 1 +卩2为+ P3X 2 +P4X3 其中i…,飞是未知参数,X1,X2,X3是三种反应物(氢,门戊烷, 异构戊烷)的含量,y是反应速度?今测得一组数据如表,试由此确定参数订…宀
序号反应速度y 氢X1 n戊烷X2 异构戊烷X3 1 8.55 470 300 10 2 3.79 285 80 10 3 4.82 470 300 120 4 0.02 470 80 120 5 2.75 470 80 10 6 14.39 100 190 10 7 2.54 100 80 65 8 4.35 470 190 65 9 13.00 100 300 54 10 8.50 100 300 120 11 0.05 100 80 120 12 11.32 285 300 10 13 3.13 285 190 120 5. 主成分与卡方检验已课件为主
数学建模B P神经网 络论文
BP 神经网络 算法原理: 输入信号i x 通过中间节点(隐层点)作用于输出节点,经过非线形变换,产生输出信号k y ,网络训练的每个样本包括输入向量x 和期望输出量d ,网络输出值y 与期望输出值d 之间的偏差,通过调整输入节点与隐层节点的联接强度取值ij w 和隐层节点与输出节点之间的联接强度jk T 以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。 变量定义: 设输入层有n 个神经元,隐含层有p 个神经元,输出层有q 个神经元 输入向量:()12,, ,n x x x x = 隐含层输入向量:()12,,,p hi hi hi hi = 隐含层输出向量:()12,,,p ho ho ho ho = 输出层输入向量:()12,,,q yi yi yi yi = 输出层输出向量:()12,,,q yo yo yo yo = 期望输出向量: ()12,, ,q do d d d = 输入层与中间层的连接权值: ih w 隐含层与输出层的连接权值: ho w 隐含层各神经元的阈值:h b 输出层各神经元的阈值: o b 样本数据个数: 1,2, k m =
激活函数: ()f ? 误差函数:21 1(()())2q o o o e d k yo k ==-∑ 算法步骤: Step1.网络初始化 。给各连接权值分别赋一个区间(-1,1)内的随机数,设定误差函数e ,给定计算精度值ε和最大学习次数M 。 Step2.随机选取第k 个输入样本()12()(),(), ,()n x k x k x k x k =及对应期望输出 ()12()(),(),,()q d k d k d k d k =o Step3.计算隐含层各神经元的输入()1 ()()1,2, ,n h ih i h i hi k w x k b h p ==-=∑和输出 ()()(())1,2, ,h h ho k f hi k h p ==及输出层各神经元的输入 ()1 ()()1,2, p o ho h o h yi k w ho k b o q ==-=∑和输出()()(())1,2, ,o o yo k f yi k o p == Step4.利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数()o k δ。 o ho o ho yi e e w yi w ???=??? (()) () ()p ho h o o h h ho ho w ho k b yi k ho k w w ?-?==??∑ 2 1 1((()()))2(()())()(()())f (()) () q o o o o o o o o o o o o d k yo k e d k yo k yo k yi yi d k yo k yi k k δ=?-?'==--??'=---∑ Step5.利用隐含层到输出层的连接权值、输出层的()o k δ和隐含层的输出计算误差函数对隐含层各神经元的偏导数()h k δ。