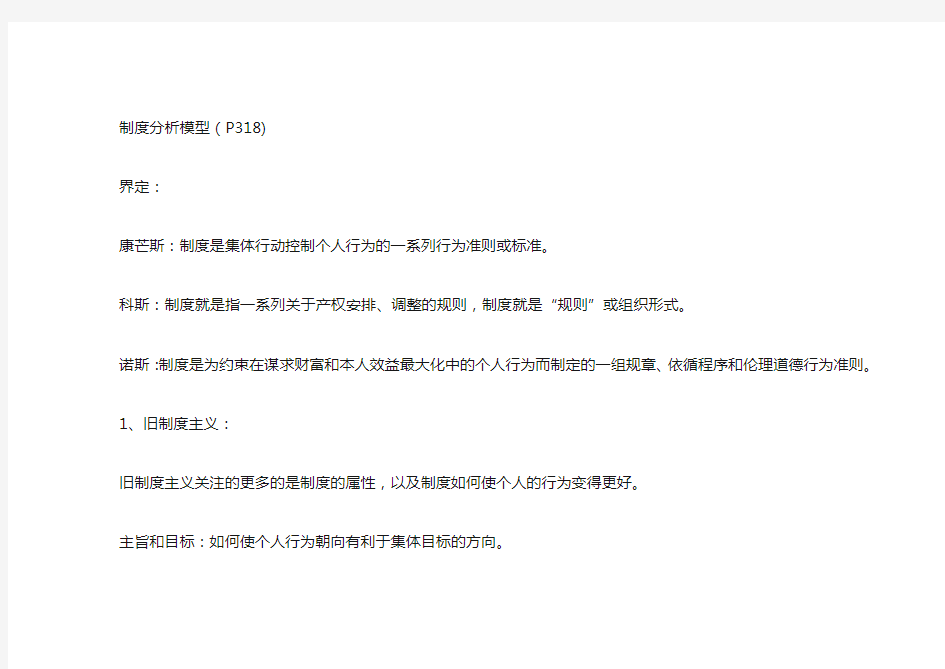

制度分析模型(P318)
界定:
康芒斯:制度是集体行动控制个人行为的一系列行为准则或标准。
科斯:制度就是指一系列关于产权安排、调整的规则,制度就是“规则”或组织形式。
诺斯:制度是为约束在谋求财富和本人效益最大化中的个人行为而制定的一组规章、依循程序和伦理道德行为准则。
1、旧制度主义:
旧制度主义关注的更多的是制度的属性,以及制度如何使个人的行为变得更好。
主旨和目标:如何使个人行为朝向有利于集体目标的方向。
重点:制度的规范性导向,以及制度对社会的影响。
诟病所在:旧制度主义的目标是规范性的,它致力于在限定的政治系统中追求好的制度,相当程度上是以国家为中心的,其主要的研究领域是公共政策的制定和形成,它侧重于对立法、行政、司法等制度和机构进行相对机械的研究。
评价:旧制度主义更多的是以国家为导向,侧重于对宏观层面的制度进行研究,对运作中的制度及其操作规则缺乏一种动态的视觉进行考察,抹杀了个人行为和人类活动的能动性。
2、新制度主义
新制度主义制度沿用旧制度主义的一些假设,但在研究工具和理论关注上吸收了行为主义和理性选择分析的要素,从而丰富了旧制度主义的研究内涵。在一定程度上改变了旧制度主义中以国家为中心的研究倾向。
新制度主义着力对制度与公共政策的关系进行探讨,把制度当成一个变量,并着重探讨不同的制度安排对于公共政策的影响是如何的不同。
奥斯特罗姆的制度分析与发展框架,区分了操作、集体选择与立宪选择三个相互作用的层次或领域。
多制度的中心安排:主张让大、中、小幅规模的政府和非政府的企业相互竞争,又相互合作。
新制度主义事实上是旧制度主义与理性主义、行为主义互相影响和渗透而发展形成的新的研究途径。
精英分析模型(P321)
核心观点:公共政策是统治精英的偏好和价值体现,大众在相当程度上是被精英所操纵的核心观点:公共政策是统治精英的偏好和价值体现,大众在相当程度上是被精英所操纵的
1、理论代表人物及主张:
帕累托:任何社会都可以分为三个群体:人数较少的统治精英集团、非统治的精英集团和普通大众或非精英集团。
莫斯卡:一切社会都存在统治阶级和被统治两个阶级。
米歇尔斯:组织从来就是寡头的组织。
米尔斯:在《权力精英》中表明,三种互相封闭的集团支配着美国社会,即政治领袖集团,社会领袖集团和军事领袖集团。当人们在社会组织中占据支配地位时,他们便拥有了权力。
2、对精英分析模型的简要评价
精英分析模型认为,公共政策是由掌握统治权的精英人物决定,并由行政官员和行政机关付诸实施,公共政策反映的是精英阶层的偏好、利益和价值选择。
启示:公共政策并非集合大众的意见而形成,而是由社会上少数人所决定,尤其是在一些民主根基并不深厚的地方。其次,政治精英的分析方法为比较政治研究及比较政策分析开辟了新的研究途径
它是将公共政策视为反映占统治地位的精英们所持有的信念、价值观和偏好的一种决策理论。更多地强调居社会少数的精英阶层的利益,在一定程度上偏离了公共政策的公共原则,漠视了公众的公共利益。
集团分析模型(P324)
集团分析模型认为,公共政策是集团斗争的产物。
核心假设:集团是个人与政府间发生联系的纽带,集团的存在与斗争是政治生活的基本特征,利益集团之间的互动是政治生活中最重要的事件。
1、理论代表人物及其主张
本特利:创始人,认为利益集团是经济、政治生活中起主导作用的基本力量
杜鲁门:在政治过程中有两种不同的利益——隐藏利益和外显利益。这两种利益又导致了潜在群体和组织化群体的形成。
2、对集团分析模型的简要评价
政治团体的分析方法是一种中观分析方法,它是从政治系统的中层分析单位—政治团体着手,向上可以分析整个政治过程,向下亦可以分析团体成员之间及团体与成员之间的利益互动。打破了传统比较政治对正规结构和法律结构的研究。
利益集团的活动首先可以澄清和明确表达公民的需求,为政策问题提供信息分析。其次,利益集团的活动可以形成可行的议程。
启示;公共政策是利益集团之间力量均衡的结果,是政府受集团压力的综合表现。
存在的问题;它低估了政府决策者在政治制定过程中的独立和富于创造性的作用,无法解释危机时期政府的许多措施的制定;集团活动是造成巨大政治不平等的根源;利益集团在追求自身狭隘或片面的利益时忽视了共同的福利。
完全理性决策模型(P327)
1、主张:只要决策过程的每一个步骤都是出于理性的考虑,最后所决定的政策自然是合理的,能使问题迎刃而解。
其特征是用“目的——方法分析”的途径来规划政策,即首先确定目的,然后再寻求达成目的的方法,用最佳得手段达成某一个既定的目标。
其必须具备的条件:完善的政府结构,畅通无阻的信息渠道,正确可靠的反馈信息,政策制定者有权衡各种社会影响的能力,政府的决策者必须知道所有的社会价值偏好及其相对比重,政策制定者优秀的个人素质
其最终目的:希望能够设计出一套程序,以使决策者能够通过程序制定出一个最有净价值成效的合理政策。(完全理性决策旨在花最少的代价取得最大的成果。)
具备的要求:有明确的解决问题的目标;穷尽目标的策略和方案;预测每种方案的结果及其概率;选择成本最低的解决问题的方案。
2、对完全理性决策模型的评价
批判者认为:其适用的条件过于苛刻,而这种条件在现实生活中往往是不可能实现的;人类决策者的能力是有限的,不能全面地确立可选的方案,也无法综合地计算成本和收益;存在着政治和制度上的限制,规定了方案的选择和决策的选择。
理性综合模型是误导性的,甚至可能是有害的。
它是一种理想的模型,在现实中并不可行。
对它的批判和思考,催生出有限理性决策模型和渐进理性决策模型。
有限理性决策模型(P328)
1、缘起:有限理性决策模型缘于对完全理性决策模型的批评,认为人类行为受知识、能力、心理及信息等各方面因素的影响,并没有办法达到完全理性决策模型的要求。
西蒙提出了一系列的阻碍完全理性决策的因素:按照其要求,行为主体必须完全了解并预期每项政策的结果,而实际上,决策者对决策结果的了解总是不完整的、零碎的;其假设决策者可能提前知道每一种决策的结果,而这在事实上并非如此;其困难还在于区分决策过程中的事实和价值,手段和目的。
2、主张:有限理性模型有两种,一种是不采取最佳的政策,而愿意采取第二最佳或者第三、第四最佳的政策,这种方法可称之为次佳决策模型:另一种
是最满意的模型,即决策者不坚持采取最佳的政策,而愿意采取任何可以被认为“满意”的政策。
3、实践中的公共决策并不是沿着收益成本最大化的思路,而仅仅是满足决策者在某个问题上的满意标准。这种满意的标准,在人类有限理性的前提下才是现实的。(该模型是建立在西蒙行政人的人性假设判定的基础之上。)
渐进决策模型(P331)
1、林德布洛姆认为,决策为何无法大幅度地改变现状,主要原因有:①讨价还价的活动需要各方参与者共同对有限资源进行分配②墨守成规是官僚的特性③在多数的政策领域中,政策选择的一致性是难以达成的。
主张:决策是解决目前问题的实践活动,而不是追求远大的目标。决策的手段是从试错过程中产生出来的,而不是通过对所有可能的手段进行综合评估。决策者考虑的仅仅是一些熟悉的恰当选择,当他们发现一个可接受的方案时,就会停止寻求这个过程。)
基本原则:按部就班原则、积少成多原则、稳中求变原则。
2、简要评价
最大启示:公共政策是对旧政策中存在的问题的补充和修正。其关键在于寻找临界点,在老政策还是好政策的指导原则下,根据外界的政治、经济和社会环境来确定渐进模式的速度。从政治学的角度看,渐进决策是理性的。
它在政治上也比较可行,该模型对缓解矛盾冲突、维持政治稳定和社会安定,具有现实的重要意义。
缺陷:在理论和实践中都带有维持现状和缺乏变革的保守主义色彩,使公共政策的制定成为修修补补的游戏;被认为是不民主的,把决策的范围局限在小部分高级决策者之中;由于它排斥系统的分析和计划,破坏了寻找有益的新选择的动力;批评者对渐进决策模型的适用性提出了质疑,其只适用于相对稳定的环境中,而在社会危机面前,渐进决策模型便失去了解释力。
公共政策的分析框架(P334)
阶段模型的缺陷:从根本上讲并不是一个因果模型;由于缺乏因果机制,它不能提供验证经验假设的明确基础;对从议程设置到政策制定、政策执行及政策评估的发展进程的描述是不充分、不准确的;其固有的关注重心在于条文主义和自上而下的要素;把政策周期作为时态的分析单元,这是不恰当的;无法有效地对政策分析和政策导向的学习进行整合。
支持联盟框架(P336)
萨巴蒂尔提出来支持联盟框架,他认为:
1、分别探讨政治家、压力集团和行政管理者的作用根本就是离题的,在一定程度上应该把政策过程看成是政策支持者的联盟。
2、在政策领域的政策共同体中,利益集团是有组织的。在支持联盟框架的典型模型中,2-4个有着共同价值和信仰的支持联盟形成了一个特有的政策领域。
3、在支持联盟框架中,支持联盟一般是比较稳定的。
4、联盟者的资源对改变政策起着基础性的作用。
5、强调各种各样的个人和机构的行为者,把公共政策制定看作是一个长年累月反复不断地过程。同时,它不仅考虑到政策改变的可能性,而且涉及到了政策改变的机制,同时更加强调系统中执行和反馈的影响。
6、在支持联盟的框架中,信仰体系和利益因素决定了联盟所采取的政策。与此同时,各种因素影响了政策的成功与否。
间断性均衡框架(P337)
鲍姆加特纳和琼斯在《美国政治议程和不稳定性》一书中提出了间断性均衡框架,他们认为:
1、从长期来看,利益集团政治权力的平衡相对稳定。而一旦公众对公共性突然有了变化,或者集团寻求打破已有的利益格局,这种平衡就会被打破。
2、其关键在于政策垄断的思想,与政策子系统的思想相对应。政策垄断是指政策制定中,由最重要的行为者所组成的集中的、封闭的体系。
3、媒体对问题的关注会使政策垄断浮出水面。(媒体只是政策垄断破裂的一个诱因,利益集团还可以通过法院或其他政府部门,不断寻求政策改变的场所,来最好的表达他们的需求,获得政策辩论的机会)
4、其假设的核心在于,长期的稳定之后会有一个急剧的改变,然后又是一个长期的稳定时期。
政策创新和传播框架(P338)
对政策创新的认知是理解政策制定的前提。而对于政策创新的研究,主要集中在国家之间、政府之间的政策如何传播。
主要由两种解释框架:一是内部决定模型(假设地方政府的行为不会受其他地方政府行为的影响,认为职能部门创新的因素在于地方政府内部的政治、经济或社会特性);二是传播模型(认为政策创新本质上是政府之间的关系,它把一个地方政府采纳的某项政策视为模仿其他地方政府先前采取的政策。)1、内部决定模型
假设导致地方政府采纳一项新项目或新政策的因素是该地方政府的政治、经济和社会特性所决定的。因此,它排除了地方政府受其他地方政府或中央政府所影响的传播效果。
内部决定模型假设,规模越大,资源越充实,经济越发达的地方政府越具有创新性。
就总体来说,财政资源及政府能力是其中最重要的影响因素。(首先,财政资源在政策创新过程中有着十分重要的地位;其次,在政策创新过程中,支持政策理念并愿意奉献于推动理念的人员有着举足轻重的作用。)
2、传播模型(传播指的是一项创新通过某种渠道随着时间的流逝在一个社会系统中的成员之间被交流的过程.)
全国性互动模型(假设在州的官员之中存在关于公共部门项目的全国性交流网络,由此官员们可以了解其他州同行的项目;已采纳新项目的州的官员能够与尚未实施新项目的州的官员自由互动,在互动和接触中,前者会给后者提供一定的激励,刺激后者采纳新的政策。)
区域传播模型(假设,各州主要受地理上相邻的州的影响;学习、竞争和公众压力是其传播途径的基础;各州有着向邻州学习的倾向。)
领导跟进模型(假设,某些州在一项政策的采纳方面是先行者,其它州争相模仿这些先行者和领导者;更加强调在学习过程中相互仿效,而不是州与州之间的竞争或者公众压力。)
垂直影响模型(州不是效仿其它州的政策,而是仿效全国性政府的政策)
关联分析
目录 一、概括 (1) 二、数据清洗 (1) 2.1公立学费(NPT4_PUB) (1) 2.2毕业率(Graduation.rate) (1) 2.3贷款率(GRAD_DEBT_MDN_SUPP) (2) 2.4偿还率(RPY_3YR_RT_SUPP) (2) 2.5毕业薪水(MD_EARN_WNE_P10)。 (3) 2.6 私立学费(NPT4_PRIV) (3) 2.7 入学率(ADM_RATE_ALL) (4) 三、Apriori算法 (4) 3.1 相关概念 (5) 3.2 算法流程 (6) 3.3 优缺点 (7) 四、模型建立及结果 (7) 4.1 公立模型 (7) 4.2 私立模型 (10)
一、概括 对7703条样本数据,分别根据公立学费和私立学费差异,建立公立模型和私立模型,进行关联分析。 二、数据清洗 2.1公立学费(NPT4_PUB) 此字段,存在4个负值,与实际情况不符,故将此四个值重新定义为NULL。重新定义后,NULL值的占比为75%,占比很大,不能直接将NULL值删除或者进行插补,故将NULL单独作为一个取值分组。 对非NULL的值按照等比原则进行分组,分组结果如下: A:[0,5896] B:(5896,7754] C:(7754, 9975] D:(9975, 13819] E:(13819, +] 分组后取值分布为: 2.2毕业率(Graduation.rate) 将PrivacySuppressed值重新定义为NULL,重新定义后,NULL值的占比为20%,占比较大,不适合直接删除或进行插补,故将NULL单独作为一个取值分组。 对非NULL值根据等比原则进行分组,分组结果如下: A:[0,0.29]
比较分析四种估值模型标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
股利折现模型优点: 概念简单:股利是股票所得到的报酬,因此要对他们进行预测。 可预测性:股利通常在短期内相当稳定,因此(在短期内)股利容易 预测。 缺点: 不相关:股利支付与价值无关,至少在短期是如此;股利预测忽略了 支付中的资本利得部分。 预测期:通常要求预测长期的股利;到期价格的计算不可信。 何时能最好地发挥作用 当收入总是与公司创造的价值相关时,模型可以最好地发挥作用。例 如,公司有一个固定的股利分配比率(股利/利润)。 现金流折现模型 优点: 概念简单:现金流是实际发生的且易于考虑,它不会受会计准则的影 响。 熟悉:现金流分析是已熟悉的净现值方法的直接应用。 缺点: 可疑之处: 1.自由现金流不能衡量短期内所增加的价值,得到的价值与放弃的价 值不匹配。 2.自由现金流不能体现有非现金流因素所产生的价值。 3.投资被认为是价值的损失。 4.自由现金流部分是一个清算概念,公司通过减少投资能增加自由现 金流。 预测期:通常需要进行长期的预测来确认投资产生的现金流入,尤其 是当投资在扩张时,更需要长期预测。 有效性:难以确认预测的自由现金流是否有效。 与预测的内容不一致:分析家预测的是利润而不是自由现金流,把利 润调整为现金流需要进一步预测增加额。 何时能最好地发挥作用 当投资能产生稳定的自由现金流或产生以固定比率增长的自由现金流 时,现金流折现分析能最好地发挥作用。 剩余收益模型 优点: 集中于价值动因:集中于决定价值创造的投资盈利能力和投资增长两 个动因,对这两个因素进行战略的思考。 利用财务报表:利用资产负债表已确认的资产价值(账面价值)。预 测利润表和资产负债表而不是预测现金流量表。
燃气轮机系统建模与性能分析 摘要:燃气轮机机组具有超强的北线性,人们掌握它的具体实施工作过程运行 规律是很难得。在我过电力工业中对它的应用又不断加强。为了更加透彻的解决 这个问题,本文将通过建立燃气轮机机组系统建模及模拟比较研究机组设计和运 行中存在的问题,从而分析它的性能。 关键词:燃气轮机;系统建模;性能 1模拟对象燃气轮机的物理模型 在标准IS0工况条件(15℃101.3kpa及相对湿度60%)下,压气机不断从大气中 吸入空气,进行压缩。高压空气离开压气机之后,直接被送入燃烧室,供入燃料 在基本定压条件下完成燃烧。燃烧不会完全均匀,造成在一次燃烧后局部会达到 极高的温度,但因燃烧室内留有足够的后续空间发生混合、燃烧、稀释及冷却等 复杂的物理化学过程,使得燃烧混合物在离开燃烧室进入透平时,高温燃气的温 度己经基本趋于平均。在透平内,燃气的高品位焙值(高温、高压势能)被转化为功。 1.1燃气轮机数值计算模型与方法 本文借助于 GateCycle软件平台,搭建好的燃气轮机部件模块实现燃气轮机以上物理模型的功能转化,进行燃气轮机的热力学性能分析计算的。在开始模拟燃 气轮机之前,首先对燃气轮杋部件模块数学模型及计算原理方法进行简单介绍。1.2压气机数值计算模型 式中,q1 、q2 、ql 分别为压气机进、出口处空气、压气机抽气冷却透平的 空气的质量流量; T1*、 p1* 分别为压气机进出口处空气的温度、压力; T2*、 p2* 分别为压气机出口处空气的温度、压力 ηc、πc分别为压气机绝热压缩效率,压气机压比 γa为空气的绝热指数;ρa为大气温度;?1为压气机进气压力损失系数 ιcs、ιc分别为等只压缩比功和实际压缩比功 i*2s、i*2、i*1分别为等只压缩过程中压气机出口处空气的比焓,实际压缩过程中压气机出日处空气的比烩和压气机进日处空气的比焓; 当压气机在非设计工况下工作时,一般计算方法是将压气机性能简单处理编制成 数表,通过插值公式求得计算压气机的参数,即在压气机性能曲线上引入多条与 喘振边界平行的趋势线,这样可以把压比,流量,效率均视为平行于喘振边界的 等趋势线和转速的函数。本文采用了同样的计算方法,在计算燃气轮机变工况性 能过程中引入无实际物理涵义的无量纲参变量CMV(compressor map variable),仅相当于引入的平行于压气机喘振边界的趋势线,压气机的质量流量、压力和效 率计算是通过上下游回馈的热力计算结果,插值寻找能够使得上下游热力参数 (压力,温度,输出功率,转速,流量)计算收敛的工作点,即压气机的变工况 工作点。 1.3燃烧室数值计算模型 其中 式中: α为过量空气系数: L0为燃料的理论空气量:
第1章数学建模与误差分析 1.1 数学与科学计算 数学是科学之母,科学技术离不开数学,它通过建立数学模型与数学产生紧密联系,数学又以各种形式应用于科学技术各领域。数学擅长处理各种复杂的依赖关系,精细刻画量的变化以及可能性的评估。它可以帮助人们探讨原因、量化过程、控制风险、优化管理、合理预测。近几十年来由于计算机及科学技术的快速发展,求解各种数学问题的数值方法即计算数学也越来越多地应用于科学技术各领域,相关交叉学科分支纷纷兴起,如计算力学、计算物理、计算化学、计算生物、计算经济学等。 科学计算是指利用计算机来完成科学研究和工程技术中提出的数学问题的计算,是一种使用计算机解释和预测实验中难以验证的、复杂现象的方法。科学计算是伴随着电子计算机的出现而迅速发展并获得广泛应用的新兴交叉学科,是数学及计算机应用于高科技领域的必不可少的纽带和工具。科学计算涉及数学的各分支,研究它们适合于计算机编程的数值计算方法是计算数学的任务,它是各种计算性学科的联系纽带和共性基础,兼有基础性和应用性的数学学科。它面向的是数学问题本身而不是具体的物理模型,但它又是各计算学科共同的基础。 随着计算机技术的飞速发展,科学计算在工程技术中发挥着愈来愈大的作用,已成为继科学实验和理论研究之后科学研究的第三种方法。在实际应用中所建立的数学模型其完备形式往往不能方便地求出精确解,于是只能转化为简化模型,如将复杂的非线性模型忽略一些因素而简化为线性模型,但这样做往往不能满足精度要求。因此,目前使用数值方法来直接求解较少简化的模型,可以得到满足精度要求的结果,使科学计算发挥更大作用。了解和掌握科学计算的基本方法、数学建模方法已成为科技人才必需的技能。因此,科学计算与数学建模的基本知识和方法是工程技术人才必备的数学素质。 1.2 数学建模及其重要意义 数学,作为一门研究现实世界数量关系和空间形式的科学,在它产生和发展的历史长河中,一直是和人们生活的实际需要密切相关。用数学方法解决工程实际和科学技术中的具体问题时,首先必须将具体问题抽象为数学问题,即建立起能描述并等价代替该实际问题的数学模型,然后将建立起的数学模型,利用数学理论和计算技术进行推演、论证和计算,得到欲求解问题的解析解或数值解,最后用求得的解析解和数值解来解决实际问题。本章主要介绍数学建模基本过程和求解数学问题数值方法的误差传播分析。 1.2.1 数学建模的过程 数学建模过程就是从现实对象到数学模型,再从数学模型回到现实对象的循环,一般通过表述、求解、解释、验证几个阶段完成。数学建模过程如图1.2.1所示,数学模型求解方法可分为解析法和数值方法,如图1.2.2所示。 表述是将现实问题“翻译”成抽象的数学问题,属于归纳。数学模型的求解方法则属于演绎。归纳是依据个别现象推出一般规律;演绎是按照普遍原理考察特定对象,导出结论。演绎利用严格的逻辑推理,对解释现象做出科学预见,具有重要意义,但是它要以归纳的结论作为公理化形式的前提,只有在这个前提下
现代消费者研究(市场调查中的一个重要环节)以实证主义方法为主流,实证主义的研究方法源于自然科学,包括实验、调查、观察法,其结果是对比较大的总体进行描述、检查和推理,收集的数据是量化的实际数据,并利用计算对它进行统计分析。 研究是探寻消费者行为规律、消费行为发生的原因、影响因素以及消费者行为之间的关系,研究不是毫无目的的收集消费行为方面的事实和信息,也不是不加解释地拼凑和记录消费行为的事实和信息而我们消费者行为研究的目的是去发现,去系统的收集数据资料、并系统的收集解释数据资料。 我们如何设计研究方法要定义所需要的信息有哪些,进而思考和说明测量工具的设计程序;设计调查问卷、访谈表、或者其它数据资料收集表格,并进行预测调查;最后我们要制定数据分析计划。数据资料收集的具体方法有:调查法、观察法、实验法消费者研究方法分析 1、聚类分析:根据研究对象间的相似性进行分类,对市场进行分层,寻找竞争对手从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。 2、回归分析:寻找某些事物的影响因素及其描述其影响程度。还可用于对某些事物的预测。回归分析是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。 3、因子分析:因子分析是指研究从变量群中提取共性因子的统计技术。最早由英国心理学家C.E.斯皮尔曼提出。他发现学生的各科成绩之间存在着一定的相关性,一科成绩好的学生,往往其他各科成绩也比较好,从而推想是否存在某些潜在的共性因子,或称某些一般智力条件影响着学生的学习成绩。因子分析可在许多变量中找出隐藏的具有代表性的因子。将相同本质的变量归入一个因子,可减少变量的数目,还可检验变量间关系的假设。 4、差异性检验和方差分析:分析和检验不同类别或变量间是否存在显著差异方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。 6、对应分析:用于探索和研究各分类变量之间的关系对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。主要应用在市场细分、产品定位、地质研究以及计算机工程等领域中。原因在于,它是一种视觉化的数据分析方法,它能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。对应分析法整个处理过程由两部分组成:表格和关联图。对应分析法中的表格是一个二维的表格,由行和列组成。每一行代表事物的一个属性,依次排开。列则代表不同的事
对应分析数学模型解析 1.对应分析模型的提出 在因子分析时常常会出现以下三个问题: 第一,因子分析分为R型和Q型,寻找变量的公因子就采用R型,寻找样品的公因子就采用Q型;R型是从变量的相关系数矩阵出发,Q型是从样品的相似矩阵出发。在因子分析中把R型和Q型互相割裂单独进行,有些问题只做R型分析,有些只做Q型分析,即使有些问题同时做了这两种分析,在解释时也无法将它们有机地联系起来。然而变量和样品是分不开的,这也就说明R型分析和Q 型分析是不可分割的。 第二,在实际生活中,我们往往取得样本数目要远远大于变量的数目,这就给Q型因子分析带来了计算上的困难。比如说,有150个样品,每个样品分析10个变量,如果做R型因子分析时只需计算10 10?阶的变量向关系数矩阵的特征值和特征向量,而Q型因子分析则要计算150 150?阶的样品相似矩阵的特征值和特征向量,这个计算量相当可观。 第三,在因子分析中我们为了能将量纲不同的变量进行比较,往往要对变量进行标准化处理,然而这种标准化只能对变量进行,对样品则无从谈标准化,所以标准化对变量和样品是非对等的,这也就给R型和Q型因子分析之间的联系带来障碍。 针对以上问题,我们综合了Q型和R型因子分析的优点,并将他们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q型分析计算量大的问题,更重要的是可以把变量和样品的载荷反映在相同的公因轴上,这样把变量和样品连接起来便于解释和推断。 2. 基本思想:是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。首先编制两变量的交叉列联表,将交叉列联表中的每个数据单元看成两变量在相应类别上的对应点;然后,对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图;最后,通过观察对应分布图就能直接地把握变量之间的类别联系; 3. 它最大特点:是能把众多的样品和众多的变量同时作到同一张图解
灰色关联分析法原理及解题步骤 ---------------研究两个因素或两个系统的关联度(即两因素变化大小,方向与速度的相对性) 关联程度——曲线间几何形状的差别程度 灰色关联分析是通过灰色关联度来分析和确定系统因素间的影响程度或因素对系统主行为的贡献测度的一种方法。 灰色关联分析的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密 1>曲线越接近,相应序列之间的关联度就越大,反之就越小 2>灰色关联度越大,两因素变化态势越一致 分析法优点 它对样本量的多少和样本有无规律都同样适用,而且计算量小,十分方便,更不会出现量化结果与定性分析结果不符的情况。 灰色系统关联分析的具体计算步骤如下 1》参考数列和比较数列的确定 参考数列——反映系统行为特征的数据序列 比较数列——影响系统行为的因素组成的数据序列 2》无量纲化处理参考数列和比较数列 (1)初值化——矩阵中的每个数均除以第一个数得到的新矩阵
(2)均值化——矩阵中的每个数均除以用矩阵所有元素的平均值得到的新矩阵 (3)区间相对值化 3》求参考数列与比较数列的灰色关联系数ξ(Xi) 参考数列X0 比较数列X1、X2、X3…………… 比较数列相对于参考数列在曲线各点的关联系数ξ(i) 称为关联系数,其中ρ称为分辨系数,ρ∈(0,1),常取0.5.实数第二级最小差,记为Δmin。两级最大差,记为Δmax。为各比较数列Xi曲线上的每一个点与参考数列X0曲线上的每一个点的绝对差值。记为Δoi(k)。所以关联系数ξ(Xi)也可简化如下列公式: 4》求关联度ri 关联系数——比较数列与参考数列在各个时刻(即曲线中的各点)的关联程度值,所以它的数不止一个,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻(即曲线
各种价值评估方法的理论模型、适用环境及其优缺点 1、市净率法(账面净值调整法) 适用环境:市净率法主要适用于需要拥有大量资产、净资产为正值的企业。 优点:可以直接根据企业的报表资料取得,具有客观性强、计算简单、资料易得等特点。 缺点:①账面价值的重置成本变动较快的公司②固定资产较少、商誉或只是资本较多的服务行业。 2、市盈率法或EV/EBITDA倍数法 适用环境:①充分竞争行业的公司②没有巨额商誉的公司③净利润亏损,但毛利、营业利益并不亏损的公司。 优点:首先,计算市盈率的数据容易取得,并且计算简单;其次,市盈率把价格和收益联系起来,直观地反映投入和产出的关系;再次,市盈率涵盖了风险补偿率、增长率、股利支付率的影响,具有很高的综合性。 缺点:如果收益是负值,市盈率就失去了意义。再有,市盈率除了受企业本身基本面的影响以外,还受到整个经济景气程度的影响。在整个经济繁荣时市盈率上长,整个经济衰退时市盈率下降。如果目标企业的β值为1,则评估价值正确反映了对未来的预期。如果企业的β值显著大于1,经济繁荣时评估价值被夸大,经济衰退时评估价值被缩小。如果β值明显小于1,经济繁荣时评估价值偏低,经济衰退时评估价值偏高。如果是一个周期性的企业,则企业价值可能被歪曲。 3、PEG指标法 适用环境:成长性行业 优点:就是将适应率和公司业绩成长对比起来看,其中的关键是要对公司的业绩做出准确的预期。 缺点:它的最大问题是没有对PE进行区分 4、股利贴现模型 适用环境:是现金流折现模型的一种特殊形式,仅用于为公司的股权资产定价 优点:无
缺点:股息贴现模型产生于1938年,由美国经济学家约翰·伯尔·威廉姆斯最早提出。当时投资者买进股票的主要目的确实是获得股息,股票的股息率经常被用来和债券的孳息率做对比。但是,自从20世纪中期以后,由于税收上的考虑,上市公司逐渐减少了股息的发放,转而倾向于保留大部分收益用作再投资,以避免股东缴纳高昂的股息税。当公司需要把一部分资金分配给股东的时候,往往采取股票回购的方式,而非发放股息。这种情况是股息贴现模型无法应对的。 除此之外,模型本身的假设也存在技术上问题: ①股息率问题:现实中稳定而且永久维持的普通股股息增长率未曾存在,这假设明显失真,业绩高增长的公司几乎不派发股息[6],从而导致模型的简化版本不适用,但按逐期现金流贴现的模型形式(即上方第一条公式)依然有效。 ②派息问题:未必所有普通股股票均会派息,因为派息会导致股价短期下降,而且公司管理层可能更倾向于股息资本化,即不派发股息而为公司保留现金作投资(会计学称之为留存收益)。假若没有股息,股东没有现金流的增加,他所持有的股票现值也不会有所增长。因此,更常见的办法是借用莫迪尼亚尼-米勒定理,假定股息派发与否对公司价值没有影响,从而在模型中以每股溢利取代股息作为参数。但是,溢利增长率又不同于股息增长率,两者的计算结果可能有别。 ③模型中,股价对股息增长率的变化非常敏感,而股息增长率只是一个期望数据。 ④投资者预期问题:如果投资者没有预期收取股息,模型便意味着股票没有任何价值 5、自由现金流量贴现模型 适用环境:稳定的现金流量的公司,或是早期发展阶段的公司。 优点:很好的体现了企业价值的本质;与其他企业价值评估方法相比,现金流量贴现法最符合价值理论,能通过各种假设,反映企业管理层的管理水平和经验。 缺点:首先从折现率的角度看,这种方法不能反映企业灵活性所带来的收益,这个缺陷也决定了它不能适用于企业的战略领域;其次这种方法没有考虑企业项目之间的相互依赖性,也没有考虑到企业投资项目之间的时间依赖性;第三,使用这种方法,结果的正确性完全取决于所使用的假设条件的正确性,在应用是切不可脱离实际。而且如果遇到企业未来现金流量很不稳定、亏损企业等情况,现金流量贴现法就无能为力了。
题目灰色关联分析及其应用 学生姓名魏婧学号 1109014115 所在学院数学与计算机科学学院 专业班级数学与应用数学数教1101班 指导教师马引弟 完成地点陕西理工学院 2015年06月08日
灰色关联分析及其应用 魏婧 (陕西理工学院数计学院数学与应用数学(师范类)专业数教1101班,陕西汉中 723000) 指导教师:马引弟 [摘要] 本文对灰色关联分析相关理论进行研究和总结,通过建立教师教育教学的评价指标体系,用灰色关联度模型进行决策,将定性与定量方法有机结合,使决策简单清晰,计算简单,便于实用. [关键词] 灰色关联分析;教育教学;评价;决策 1 引言 灰色系统理论是20世纪80年代,由中国华中理工大学邓聚龙教授首次在“含未知数系统的控制问题”的学术报告中提出“灰色系统”一词,它是以数学理论为基础的系统工程学科,为灰色系统理论鉴定基础[1].自灰色系统理论诞生以来,灰色关联分析理论作为其中最重要 的一部分就受到学术界的广泛关注.它不仅是灰色系统理论的重要组成部分,也是灰色系统、预测和决策的基石. 随着灰色系统在各个方面的推广、应用,对灰色关联分析的关注也越来越多,同时也存在一些不足.因此,为了更好的将灰色关联应用到实际生活中,对灰色关联分析理论探讨及实际应用进行研究是十分必要的. 党的十八大明确提出深化教育领域综合改革,努力办好人民满意的教育,要坚持教育优先发展,全面贯彻党的教育方针,对教师进行教育教学评价是十分有必要的.由于影响教师教育教学评价的因素很多,如何建立灰色关联模型进行合理的评价,是灰色关联分析应用实际教育教学评价体系的重点. 2 灰色关联分析概述 灰色关联分析理论的基本思想就是根据描述所研究系统指标序列曲线的几何形状与所选的标准系统指标序列曲线的相似程度来判断它们的关联程度是否紧密[1].曲线形状越接近,说明相对应的指标序列关联程度越大;曲线形状差异越大,说明相对应的指标序列的关联程度越小. 由此可以看出,对于如何定义关联度以及关联度的计算方法是灰色关联分析理论的重要组成部分[2].同时在进行关联分析时,必须先确定参考序列,然后比较其他序列的接近程度, 这样才能对其他序列进行比较,进而做出判断. 2.1灰色关联主要基本概念 X为表征系统特征行为的量,其在序号k上的观测数据为定义1[1]:设
预算分析模型报告 ——孙平平(20081428)时秀英(20081399)张振华(20081666) 一、模型总体构想 1、预算模型的目标 预算目标是集团公司战略目标在本期内的财务具体化,公司战略是预算管理的目标导向,引导年度预算目标的确定; 年度预算目标强调可操作性,必须能通过预算编制体现出来。 2、预算模型的功能 (1)公司管理、提升公司治理能力 (2)预算是企业平衡各项资源的有效方法:收入与费用平衡,成本发生与行为责任平衡,贡献业绩与奖励平衡,现金流入与流出平 衡,人力、物力、财力平衡,管理手段、经营目标、经济活动、 组织措施平衡。 (3)计划预算工作的渗透性对组织的渗透:影响企业组织结构、职权关系和行为规范,影响领导工作:集权还是分权,贯穿控制全过程:没有预算,就没有控制。 二、功能模块的实现 1、经营预算 经营预算是从维持企业生产经营的角度出发,来预测企业所需的人 工,物料的需求情况。
图一经营预算的内容 (1)、销售预算 是根据本年度实际来推算本年的销售量,来预计本年度的销售收入,本年的现金流入,及应收账款和税金的支付情况。这些是根据以前年度的历史情况来计算的,这样的预测更具有可信性。其中的会有一些是支付现款,而一些则是留作应付账款,这样更符合企业的实际情况。 (2)、生产预算 是对生产中的一些问题进行预算,比如,生产中的生产成本的预算,生产成本中直接人工,直接材料,还有制造费用。对与这些中的各项问题进行预算。 图二直接人工 图三直接材料
图四制造费用预算 图五生产成本预算 按照这个步骤来实现对生产总成本的预算,结合销售预算来看看本年度中的各个季度的销售成本与销售收入,及哪个季度可能的利润最高等等。 2、资本预算 在这个例子中的资本预算包括,增加了一项固定资产,还有投资收益的增加。 图六资本预算模型 3、财务预算
4.1 Grey Relational Analysis First,select a reference sequence as shown below : (){}()()()()00000|1,2,1,x 2,x x x k k n x n === And the other group of sequence is, (){}()()()()|1,2,1,2,,1,2,i i i i i x x k k n x x x n i m ==== Then the correlation degree of i x to 0x is, ()1 1n i i k r k n ξ==∑ In which, ()()()()() ()()()() 0000min min max max max max s s s t s t i s s s t x t x t x t x t k x t x t x t x t ρξρ-+-= -+- Then, we use i r to describe the correlation degree between i x and 0x ,namely to describe the influence on 0x caused by the change of i x . In general,Practical problems often have different numbers of different dimension,but when we calculate the correlation degree, it requires the same numbers of same dimension.So we want to carry out a variety of data processing dimensionless.in addition ,For comparison easily, all the sequseces are required to have a common point.In order to solve these two problems, we transform the given sequences.The given sequence ()()()() 1,x 2,,x ,x x n = we name ()()()()()()231,,,,111x x x n x x x x ??= ? ??? as initialization sequence of Original sequence ()()()() 1,x 2,,x x x n = 4.2 Water resources carrying capacity evaluation indexes and classification indexes The establishment of evaluation index system of water resources carrying capacity is a key issue in the study of water resources carrying capacity. Regional water resources carrying capacity is influenced by many factors, Should be selected according to the requirements of the specific regional social development backlog of social - economic index system response - natural
消费者行为分析模型
消费者行为模型的演变 AIDMA,是1920年代美国营销广告专家山姆·罗兰·霍尔(Samuel Roland Hall)在其著作中阐述广告宣传对消费者心理过程缩写。该理论认为,消费者从接触到信息到最后达成购买,会经历这5个阶段: A:Attention(引起注意)——花哨的名片、提包上绣着广告词等被经常采用的引起注意的方法 I:Interest (引起兴趣)——一般使用的方法是精制的彩色目录、有关商品的新闻简报加以剪贴。 D:Desire(唤起欲望)——推销茶叶的要随时准备茶具,给顾客沏上一杯香气扑鼻的浓茶,顾客一品茶香体会茶的美味,就会产生购买欲。推销房子的,要带顾客参观房子。餐馆的入口处要陈列色香味具全的精制样品,让顾客倍感商品的魅力,就能唤起他的购买欲。 M:Memory(留下记忆)——一位成功的推销员说:“每次我在宣传自己公司的产品时,总是拿着别公司的产品目录,一一加以详细说明比较。因为如果总是说自己的产品有多好多好,顾客对你不相信。反而想多了解一下其他公司的产品,而如果你先提出其他公司的产品,顾客反而会认定你自己的产品。” A:Action(购买行动)——从引起注意到付诸购买的整个销售过程,推销员必须始终信心十足。过分自信也会引起顾客的反感,以为你在说大话、吹牛皮,从而不信任你的话。 AISAS模型是由电通公司针对互联网与无线应用时代消费者生活的变 化,于2005年提出的一种全新的消费者行为分析模型。电通公司注意到目前营销方式正从传统的AIDMA营销法则逐渐向含有网络特质的AISAS发展。理论模型如下: A:Attention(引起注意):顾客从互联网的各个角落看到我们的信息,从而引起他们的注意。 I:Interest(提起兴趣):这个阶段顾客可能从我们的信息中发掘到了他需求的东西从而提起了对我们信息的兴趣。 S:Search(信息搜寻):顾客对我们的信息或者产品提起了兴趣,那么他就会从他熟知的互联网各个角度去分析对比相关信息。 A:Action(购买行动):通过了上个层次的分析对比客户最终作出了购买决定。 S:Share(与人分享):客户购买后通常会在互联网上进行分享,比如:微博,博客,SNS等等。
提供众多的预测模型,这使得它们可以应用在多种商业领域中:如超市商品如何摆放可以提高销量; 分析商场营销的打折方案,以制定新的更为有效的方案; 保险公司分析以往的理赔案例,以推出新的保险品种等等,具有很强的商业价值。 超市典型案例 如何摆放超市的商品引导消费者购物从而提高销量,这对大型连锁超市来说是一个现实的营销问题。关联规则模型自它诞生之时为此类问题提供了一种科学的解决方法。该模型利用数据挖掘的技术,在海量数据中依据该模型的独特算法发现数据内在的规律性联系,进而提供具有洞察力的分析解决方案。通过一则超市销售商品的案例,利用“关联规则模型”,来分析商品交易流水数据,以其发现合理的商品摆放规则,来帮助提高销量。 关联规则简介 关联规则的定义 关联规则表示不同数据项目在同一事件中出现的相关性,就是从大量数据中挖掘出关联规则。有关数据挖掘关联规则的具体理论依据这里不做详细讲解,大家可以参看韩家炜的数据挖掘概论。为了更直观的理解关联规则,我们首先来看下面的场景。 一个市场分析人员经常要考虑这样一个问题:哪些商品是频繁被顾客同时购买的? 顾客1:牛奶+面包+谷类
顾客2:牛奶+面包+糖+鸡蛋 顾客3:牛奶+面包+黄油 顾客4:糖+鸡蛋 以上的情景类似于当年沃尔玛做的市场调查:啤酒+尿片摆放在同一个货架上,销售业绩激增的著名关联规则应用。 市场分析员分析顾客购买商品的场景,顾客购买面包同时也会购买牛奶的购物模式就可用以下的关联规则来描述: 面包 => 牛奶 [ 支持度 =2%, 置信度 =60%] (式 1) 式 1中面包是规则前项(),牛奶是规则后项 ()。实例数()表示所有购买记录中包含面包的记录的数量。 支持度()表示购买面包的记录数占所有的购买记录数的百分比。规则支持度()表示同时购买面包和牛奶的记录数占所有的购买记录数的百分比。 置信度()表示同时购买面包和牛奶的记录数占购买面包记录数的百分比。 提升()表示置信度与已知购买牛奶的百分比的比值,提升大于1 的规则才是有意义的。 关联规则式 1的支持度 2% 意味着,所分析的记录中的 2% 购买了面包。置信度 60% 表明,购买面包的顾客中的 60% 也购买了牛奶。如果关联满足最小支持度阈值和最小置信度阈值,就说关联规则是有意义的。这些阈值可以由用户或领域专家设定。就
常用结构计算软件的分析模型与使用 按语:读了工业建筑2005-5期,中国建筑设计研究院,常林润、罗振彪“常用结构计算软件与结构概念设计”一文,感到其内容、观点对更深层次讨论PKPM很有有帮助,现分几个部分摘编如下,供网友发帖时参考,其目的是将J区的讨论提高到一个更高的层次。 一、TAT的分析模型与使用。 二、SARWE的分析模型与使用, 三、从整体上把握结构的各项性能。 四、现阶段常用的结构分析模型。 五、结构计算软件的局限性、适用性和近似性。 六、抗震概念设计的一些重要准则。 七、结语。 一、TAT的分析模型与使用 TAT是中国建科院开发的,程序对剪力墙采用开口薄壁杆件模型,并假定楼板平面内刚度无限大,平面外刚度为零。这使得结构自由度大为减少,计算分析得到一定程度的简化,从而大大提高了计算效率。 薄壁杆件模型采用开口薄壁杆件理论,将整个平面联肢墙或整个空间剪力墙模拟为开口薄壁杆件,每个杆件有两个端点,每个端点有7个自由度,前6个自由度的含义与空间杆单元相同,第7个自由度是用来描述薄壁杆件截面翘曲的。开口薄壁杆件模型的基本假定是: 1)在线弹性条件下,杆件截面外形轮廓线在其平面内保持不变,在平面外可以翘曲,同时忽略其剪切变形的影响。这一假定实际上增大了结构的刚度,薄壁杆件单元及其墙肢越多,则结构刚度增加程度越高。 2)将同一层彼此相连的剪力墙墙肢作为一个薄壁杆件单元,将上下层剪力墙洞口之间的部分作为连梁单元。这一假定将实际结构中连梁对墙肢的线约束简化为点约束,削弱了连梁对墙肢的约束,从而削弱了结构的刚度。连梁越多,连梁的高度越大,则结构的刚度削弱越大。 3)引入了楼板平面内刚度无限大,平面外刚度为零。 实际工程中许多布置复杂的剪力墙难以满足薄壁杆件的基本假定,从而使计算结果难以满足工程设计的精度要求。 1)变截面剪力墙:在平面布置复杂的建筑结构中,常存在薄壁杆件交叉连接、彼此相连的薄壁杆件截面不同、甚至差异较大的情况。由于这些薄壁杆件的扇形坐标不同,其翘曲角的含义也不同,因而由截面翘曲引起的纵向位移不易协调,会导致一定的计算误差。 2) 长墙、短墙:由于薄壁杆件模型不考虑剪切变形的影响,而长墙、短墙是以剪切变形为主的构件,其几何尺寸也难以满足薄壁杆件的基本要求,采用薄壁杆件理论分析这些剪力墙时,存在着较大的模型化误差。 3)多肢剪力墙:薄壁杆件模型的一个基本假定就是认为杆件截面外形轮廓线在自身平面内保持不变,在墙肢较多的情况下,该假定会会导致较大的误差。 4)框支剪力墙:框支剪力墙和转换梁在其交接面上是线变形协调的,而菜用薄壁杆件理论分析框支墙时,由于薄壁杆件是以点传力的,作为一个薄壁杆件的框支墙只有一点和转换梁的某点是变形协调的,这必然会带来较大的计算误差。
本技术提供了一种基于大数据挖掘的虚拟身份关联分析算法模型,属于大数据挖掘技术领域。该方法包括获取电子串号信息和物理地址信息;对源数据进行清洗处理、规则过滤;并对处理后的数据进行属性分割、特征提取、指标计算;针对样本类别不平衡问题,调整不同类别训练样本;搭建Logistic Regression算法模型,以计算手机物理地址和电子串号之间关系的匹配度,实现虚拟身份的挖掘分析和关联匹配,本技术可以通过轨迹追查,确定犯罪轨迹,对犯罪嫌疑人实施跟踪和追捕,侦破案件,最终达到对犯罪的有效控制和打击。 技术要求 1.一种基于大数据挖掘的虚拟身份关联分析算法模型,其特征在于,包括以下步骤: S1:电子串号及物理地址数据预处理;分别对无线数据采集终端的电子串号和物理地址 的脏数据进行处理; S2:关联数据筛选及存储;将满足筛选规则的数据存储于数据库中; S3:样本特征构建及提取;对关联数据进行属性分割及结合,构建M个样本特征,并对特征数据进行降维处理,使样本变量维度变为N; S4:类别不平衡问题处理;采用Fisher判别法调整不同类别训练样本; S5:建立及优化电子串号与物理地址关联模型;根据算法建立模型,得出电子串号与物 理地址的匹配度。
2.根据权利要求1所述的基于大数据挖掘的虚拟身份关联分析算法模型,其特征在于,所述步骤S2中筛选规则具体步骤为: S201、将时间差范围内(即|t1-t2|<Δt,其中t1和t2分别表示电子串号和物理地址被采集到的时间)采集到的电子串号和物理地址数据中的无线数据采集终端经纬度字段进行匹配,若经纬度一致,则将此组电子串号和物理地址作为匹配对,并转入步骤S202;若不一致,则舍弃; S202、从预处理后的数据中分别取出匹配对相应的电子串号/物理地址、采集时间、经度和纬度等字段,满足以下条件的匹配对保留作为匹配组并存储:|d1-d2|
比较分析四种估值模型 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】
股利折现模型 ?优点: ●概念简单:股利是股票所得到的报酬,因此要对他们进行预测。 ●可预测性:股利通常在短期内相当稳定,因此(在短期内)股利容易预 测。 ?缺点: ●不相关:股利支付与价值无关,至少在短期是如此;股利预测忽略了支付 中的资本利得部分。 ●预测期:通常要求预测长期的股利;到期价格的计算不可信。 ?何时能最好地发挥作用 ●当收入总是与公司创造的价值相关时,模型可以最好地发挥作用。例如, 公司有一个固定的股利分配比率(股利/利润)。 现金流折现模型 ?优点: ●概念简单:现金流是实际发生的且易于考虑,它不会受会计准则的影响。 ●熟悉:现金流分析是已熟悉的净现值方法的直接应用。 ?缺点: ●可疑之处: 1.自由现金流不能衡量短期内所增加的价值,得到的价值与放弃的价值 不匹配。 2.自由现金流不能体现有非现金流因素所产生的价值。 3.投资被认为是价值的损失。
4.自由现金流部分是一个清算概念,公司通过减少投资能增加自由现金 流。 ●预测期:通常需要进行长期的预测来确认投资产生的现金流入,尤其是当 投资在扩张时,更需要长期预测。 ●有效性:难以确认预测的自由现金流是否有效。 ●与预测的内容不一致:分析家预测的是利润而不是自由现金流,把利润调 整为现金流需要进一步预测增加额。 ?何时能最好地发挥作用 ●当投资能产生稳定的自由现金流或产生以固定比率增长的自由现金流时, 现金流折现分析能最好地发挥作用。 剩余收益模型 ?优点: ●集中于价值动因:集中于决定价值创造的投资盈利能力和投资增长两个动 因,对这两个因素进行战略的思考。 ●利用财务报表:利用资产负债表已确认的资产价值(账面价值)。预测利 润表和资产负债表而不是预测现金流量表。 ●采用应计会计准则:利用应计会计制的性质,认识到价值增加限于先进流 动,将价值增加与价值付出相配比,将投资作为资产而不是价值的损失。 ●多样性:适用于广泛多样的会计原则。 ●利用已有的预测结果:分析师预测收益(利用这一预测计算剩余收益)。 ●有效性:预测的剩余收益可通过随后来(经审计)的财务报表来验证。
网络购物分析 【摘要】 本题是对网购问题的分析,由于商场旨在追求利益的最大化,因此对商品聚类分析、找出利益最高的组合,为商家呈现出最好的营销方式,是本题主旨。同时由于本题数据繁杂庞多,其结果也与数据有着直观和密切的联系,所以对于数据的处理极其准确程度也显得尤为重要。(本题所给数据皆真实有效)。 对于问题一,求其商品之间的关联程度,即指如果买一副镜框,一般情况下也要买一副镜片,此时可认为镜片和镜框的关联度很高。故解决此问题可以运用聚类的方法和概率论知识相结合的办法,建立相应的模型,找出关联度很高的组合,即为所求的的结果。 对于问题二,利用穷举法以及第一问的模型,便可以找出同时被频繁购买的商品的组合,便可以据此进行第三问的求解,所以第二问是一个承接的作用。 对于问题三,在问题二的基础上得出促销方案。故需知道各种组合的利益,运用最优解法,结合购买的次数最多以及商品的价格较高两个因素,找出各种组合中的利益最大的组合,促销在此基础上进行。例如:在最大利益的组合中,有一利益最小的商品,则可以对此商品进行打折,以此达到薄利多销的营销策略。经过市场调查,可以得到使其利润最大的打折率f(i),,那么f(i)便是我们的促销打折率,以此便可制定促销方案。与此,也可运用其他的策略。 问题一,问题二结果如下表所示: 问题一结果: 组合商品编号数目关联度 V368 6822860.07732872 V368 5293290.076986159 V956 538 413 120 0.005608505 V368 937 829 413 72 0.00003998 问题二结果: 组合商品编号数目 V368 529329 V368 829307 V368 489 682 122 V368 937 829 413 72