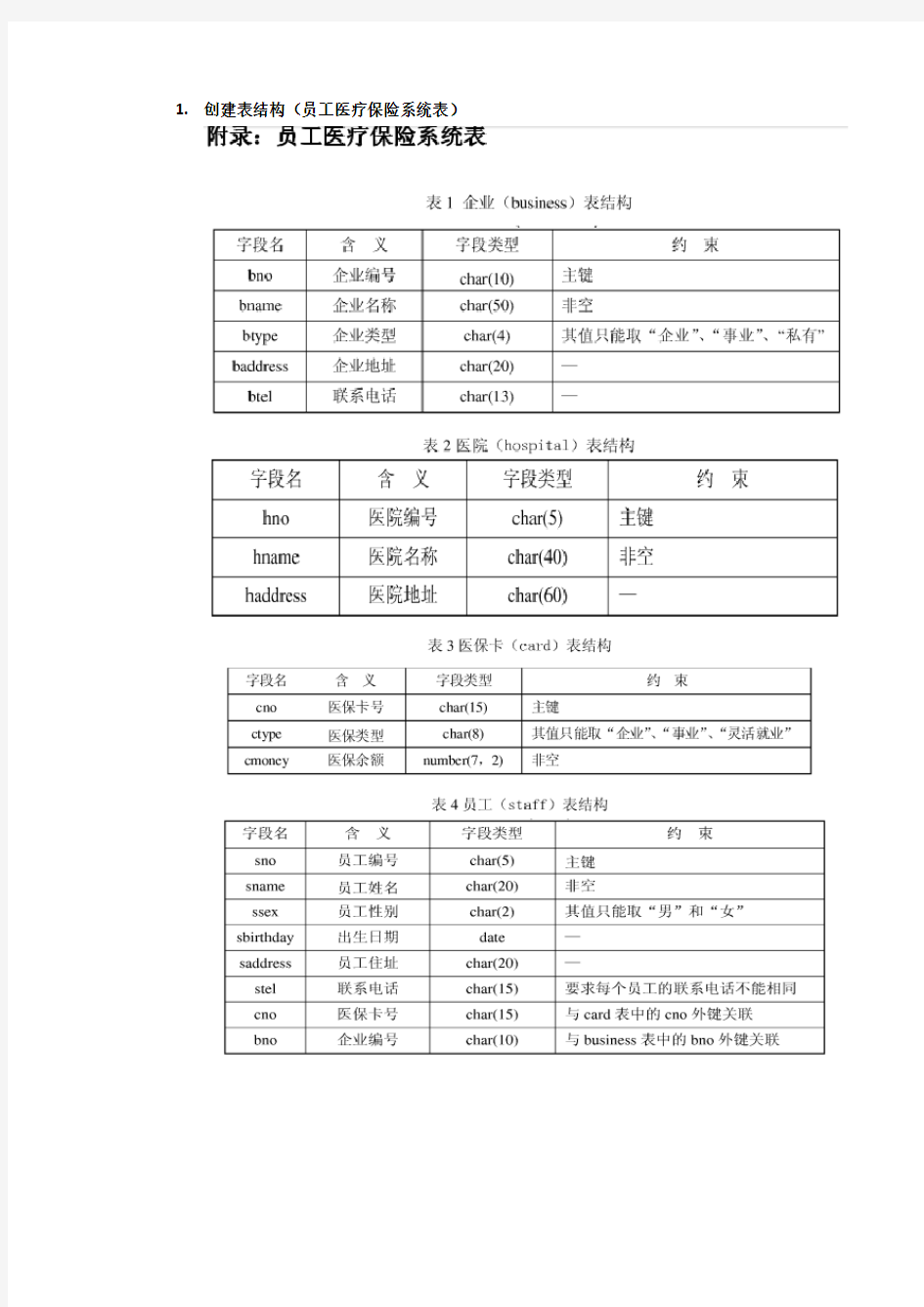

1.创建表结构(员工医疗保险系统表)
企业表:
医院表:
医保卡表:
员工表:
就诊表:
消费表:
医保表:
2.查看表结构
(1) 利用OEM查看员工医疗保险系统所有表的字段信息和约束信息。
(2) 利用SQL*Plus或iSQL*Plus从数据字典DBA_TAB _COLUMNS查看员工医疗保险系统
所有表的字段信息。
(3) 利用SQL*Plus或iSQL*Plus从数据字典DBA_ CONSTRAINTS查看员工医疗保险系统所
有表的约束信息。
SELECT * FROM DBA_TABLES WHERE TABLE_NAME= 'STAFF';
3.修改表结构
(1) 利用SQL*Plus或iSQL*Plus将表“staff_sql”重新命名为“staff_sql0”。
Alter table staff rename to staff_sql0;
(2) 利用企业管理器为“staff_sql0”表添加“age INT”字段,利用DESC命令查看“staff_sql0”
表的字段信息。
(3) 利用SQL*Plus或iSQL*Plus为“staff_sql0”表添加“salary NUMBER(5,2)”、“salary_add NUMBER(3,1)”两个字段,利用DESC命令查看“staff_sql0”表的字段信息。
(4) 利用SQL*Plus或iSQL*Plus向“staff_sql0”表添加“sname”字段惟一性约束,从数据字典DBA_CONSTRAINTS查看“staff_sql0”表的约束信息。
(5) 利用SQL*Plus或iSQL*Plus删除“staff_sql0”表上“sname”字段惟一性约束,从数据字典DBA_CONSTRAINTS查看“staff_sql0”表的约束信息。
(6) 利用企业管理器从“staff_sql0”表删除“age”字段,利用DESC命令查看“staff_sql0”表的字段信息。
(7) 利用SQL*Plus或iSQL*Plus从“staff_sql0”表删除“salary”、“salary_add”两个字段,利用DESC命令查看“staff_sql0”表的字段信息。
(8) 利用SQL*Plus或iSQL*Plus将“staff_sql0”表“sname”字段长度修改为30,利用DESC 命令查看“staff_sql0”表的字段信息。
alter table 表名modify 字段名varchar2(长度); 或
alter table 表名modify 字段名number(长度);
只能改大。
想改小只能重新建表将数据导到新表,再将旧表drop掉。
如果想改小,没有数据可能直接用alter table table_name modify column datatype;
如果有数据,改小的话可以会丢失数据。
比如:
表:stu(name varchar2(20)) 要将字段name的长度改为10
表中有一条数据:name(中国华西村刀光剑影) 长度超过10,截取的时候必然要丢失数据。
当然如果表中的数据长度都小于10,则可以用sql语句段来直接搞定。
begin
alter table stu add (name2 varchar2(10)); 增加新字段
update stu set name2=substr(trim(name),1,10); 赋值给新字段
alter table stu drop(name); 删除原字段
alter table stu rename column name2 to name; 将新字段改名
end;
4.删除表结构
(1) 利用SQL*Plus或iSQL*Plus删除员工表3,看能否成功。从原理上解释原因,同时记录外键约束表删除顺序的影响。
(2) 利用企业管理器删除员工表2,看能否成功。从原理上解释原因。
索引、视图、同义词及序列操作
1.创建索引
(1) 利用企业管理器为医院表的医院名称创建索引,并以降序排列,索引名为“hospital_name_index”。
create unique index idx_test on test (testcol1 asc) --按照testcol1字段升序排列create unique index idx_test on test (testcol1 desc) --按照testcol2字段降序排列
(2) 利用SQL*Plus或iSQL*Plus为员工表的员工姓名、员工性别、出生年月排序,以员工姓名升序、员工性别降序、出生年月降序排列,索引名为“staff_info_index”。
2.查看索引
(1) 利用企业管理器查看“ygbx_user”方案下有几个隶属于该方案的索引,有几个系统创建的索引,有几个用户创建的索引。
------以下两个都可以
select table_name,constraint_name,constraint_type from user_constraints
where table_name='大写的表名'
select table_name,constraint_name,constraint_type from dba_constraints
where table_name='大写的表名'
---------另外以下可以只查看表中的索引
select * from USER_INDEXES where table_name = '大写的表名'
下边的也可以
select * from ALL_INDEXes where table_name = '大写的表名'
(2) 利用SQL*Plus或iSQL*Plus从DBA_INDEXES数据字典中查看员工医疗保险系统所有索引的信息。
(3) 利用SQL*Plus或iSQL*Plus从DBA_INDEXES数据字典中查看“staff_info_index”索引的信息,并查看该索引列的顺序及状态。
3.删除索引
(1) 利用企业管理器删除“hospital_name_index”索引。
drop index test_index;
create index test_index on sys_test(aaa) indextype is ctxsys.context;
执行删除操作时先判断索引是否存在,如果索引存在则删除,望给出正确SQL语句。PL/S QL。
(2) 利用SQL*Plus或iSQL*Plus将“staff_info_index”索引删除。
4.创建视图
(1) 利用企业管理器为实现显示医保卡信息创建视图,该视图中包括医保卡信息、医保卡所属人信息和所属人单位信息,视图名为“ygbx_card_view”。
create or replace view ygbx_card_view as
select https://www.doczj.com/doc/313447939.html,o,staff.sno,business.bname
from insurance,staff,business
where https://www.doczj.com/doc/313447939.html,o=https://www.doczj.com/doc/313447939.html,o and staff.bno=business.bno;
(2) 利用SQL*Plus或iSQL*Plus为实现员工持医保卡到医院消费的功能创建视图,该视图中包括员工的信息、医保卡信息、医保信息和消费等信息,视图名为“consume_view”。
create or replace view consume_view as
select staff.sno,https://www.doczj.com/doc/313447939.html,o,insurance.imoney,consume.csmoney
from staff,insurance,consume
where https://www.doczj.com/doc/313447939.html,o=https://www.doczj.com/doc/313447939.html,o and https://www.doczj.com/doc/313447939.html,o=https://www.doczj.com/doc/313447939.html,o;
(3) 利用SQL*Plus或iSQL*Plus为企业医保缴费信息功能创建视图,该视图中包括医保缴费的企业信息,医保卡信息和企业医保缴费费用等信息,视图名为“insurnce_view”。
(4) 利用SQL*Plus或iSQL*Plus为企业表创建视图,视图名为“business_view”。
create or replace view business_view as
select *
from business;
5.查看视图
(1) 利用企业管理器查看“ygbx_user”方案下的视图。
(2) 利用企业管理器查看“consume_view”视图的信息。
Desc consume_view;
(3) 利用SQL*Plus或iSQL*Plus查看“card_view”视图的子查询语句。
(4) 利用SQL*Plus或iSQL*Plus显示“insurance_view”视图的信息。
6.视图数据的更新
(1) 利用SQL*Plus或iSQL*Plus向“business_view”插入一个记录,企业编号为
“B1902879701”,企业名称为“格林制药”,企业类型为“企业”,企业地址为“鸭绿江街98号”,联系电话为“84692315”。
insert into business_view
values('1902879701','格林制药','企业','鸭绿江街98号','84692315');
(2) 利用SQL*Plus或iSQL*Plus查看“business”表是否有变化。
7.删除视图
(1) 利用企业管理器删除“business_view”视图。
Drop view business_view;
(2) 利用企业管理器删除“card_view”视图。
(3) 利用SQL*Plus或iSQL*Plus删除“consume_view”视图。
(4) 利用SQL*Plus或iSQL*Plus删除“insurnce_view”视图。
8.创建同义词
(1) 利用企业管理器创建企业表同义词,名为“qyb”。
create or replace synonym qyb for sys.business;
(2) 利用SQL*Plus或iSQL*Plus创建医保卡表的同义词,名为“ybk”。9.查询同义词
(1) 利用企业管理器查看同义词“qyb”。
select * from qyb;
(2) 利用SQL*Plus或iSQL*Plus查看同义词“ybk”。
10.删除同义词
(1) 利用企业管理器删除同义词“qyb”。
drop synonym qyb;
(2) 利用SQL*Plus或iSQL*Plus删除同义词“ybk”。
11.创建序列
(1) 利用企业管理器创建序列,该序列最大值为“28000”,最小值为“60”,步长为“1”,可循环,序列名为“ygbx_seq1”。
CREATE SEQUENCE ygbx_seq1
START WITH 60
INCREMENT BY 1
MAXVALUE 28000
CYCLE;
(2) 利用SQL*Plus或iSQL*Plus创建序列,该序列最大值无限制,最小值为“1”,步长为“10”,序列名为“ygbx_seq2”。
12.查询序列
(1) 利用企业管理器查看序列“ygbx_seq1”。
(2) 利用SQL*Plus或iSQL*Plus查看同义词“ygbx_seq2”。
13.修改序列
(1) 利用企业管理器修改序列“ygbx_seq1”,将该序列最大值设为“82000”,最小值设为“100”,步长设为“5”。
minvalue 100
alter sequence ygbx_seq1
INCREMENT BY 5
MAXVALUE 82000
CYCLE;
(2) 利用SQL*Plus或iSQL*Plus修改序列“ygbx_seq2”,将该序列最大值设为“1000”。
14.删除序列
(1) 利用企业管理器删除序列“ygbx_seq1”。
drop sequence ygbx_seq1;
(2) 利用SQL*Plus或iSQL*Plus删除序列“ygbx_seq2”。
1.视图的概述 视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。视图将一个查询的结果作为一个表来使用,因此视图可以被看作是存储的查询或一个虚拟表。视图来源于表,所有对视图数据的修改最终都会被反映到视图的基表中,这些修改必须服从基表的完整性约束,并同样会触发定义在基表上的触发器。(Oracle支持在视图上显式的定义触发器和定义一些逻辑约束) 2.视图的存储 与表不同,视图不会要求分配存储空间,视图中也不会包含实际的数据。视图只是定义了一个查询,视图中的数据是从基表中获取,这些数据在视图被引用时动态的生成。由于视图基于数据库中的其他对象,因此一个视图只需要占用数据字典中保存其定义的空间,而无需额外的存储空间。 3.视图的作用 用户可以通过视图以不同形式来显示基表中的数据,视图的强大之处在于它能够根据不同用户的需要来对基表中的数据进行整理。视图常见的用途如下: 通过视图可以设定允许用户访问的列和数据行,从而为表提供了额外的安全控制 隐藏数据复杂性 视图中可以使用连接(join),用多个表中相关的列构成一个新的数据集。此视图就对用户隐藏了数据来源于多个表的事实。 简化用户的SQL 语句 用户使用视图就可从多个表中查询信息,而无需了解这些表是如何连接的。 以不同的角度来显示基表中的数据 视图的列名可以被任意改变,而不会影响此视图的基表 使应用程序不会受基表定义改变的影响 在一个视图的定义中查询了一个包含4 个数据列的基表中的3 列。当基表中添加了新的列后,由于视图的定义并没有被影响,因此使用此视图的应用程序也不会被影响。 保存复杂查询 一个查询可能会对表数据进行复杂的计算。用户将这个查询保存为视图之后,每次进行类似计算只需查询此视图即可。
Oracle创建视图 在本练习中,将在HR模式中练习如何创建视图,查询视图的定义,并对视图进行更新。 (1)创建一个视图EMPLOYEES_IT,该视图是基于HR模式中的EMPLOYEES表,并且该视图只包括那些部门为IT的员工信息。在创建视图时使用WITH CHECK OPTION,防止更新视图时,输入非IT部门的员工信息。 create or replace view employees_it as select * from employees where department_id =( select department_id from departments where departments.department_name='IT') with check option; (2)创建一个联接视图EMP_DEPT,它包含EMPLOYEES表中的列和DEPARTMENTS 表中的DNAME列。 create or replace view emp_dept as select t1.employee_id,t1.first_name,https://www.doczj.com/doc/313447939.html,st_name,t1.email, t1.phone_number,t1.hire_date,t1.job_id,t1.salary,t2.department_name from employees t1,departments t2 where t1.department_id=t2.department_id with check option; (3)Oracle针对创建的视图,只在数据字典中存储其定义。输入并执行如下的语句查看创建的视图定义: select text from user_views where view_name=UPPER('emp_dept'); (4)查看视图各个列是否允许更新。 col owner format a20 col table_name format a20 col column_name format a20 select * from user_updatable_columns where table_name=UPPER('emp_dept');
龙源期刊网 https://www.doczj.com/doc/313447939.html, Oracle索引分析与查询优化 作者:崔黎明志远李婧 来源:《数字技术与应用》2016年第07期 摘要:Oracle是目前国内在大型数据存储中用得比较多的一种关系型数据库,磁盘阵列技术(RAID)和集群技术(RAC)的运用,使Oracle在处理数据效率和数据安全上有非常大的提高,在国内交通、电力,通信和金融等重要领域都有广泛的用途。本文基于Oracle 11g版本,对Rowid和索引的原理机制做出分析,并论述利用这些原理对大型数据表查询的优化。 关键词:Oracle Rowid 索引查询 中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2016)07-0234-02 在逻辑上,Oracle是由多个表空间构成的,在新建一个表空间的时候,必须指定存储的文件,可以指向多个存储在不同磁盘上的数据。表空间下面分为段、区、块。新建一张表的时候,Oracle数据库就会为它创建一个段。所谓区就是指连续的块(block)构成的空间,一般区包含8个空块,block是Oracle数据库最小的数据空间,一般为8k或16k,当开始往这个表中插入数据的时候,Oralce数据库会自动为这个表分配一个区,并把数据不断往此区进行填充,当数据填满此区后,Oralce数据库会重新为该表分配一个区而不是一个段。实际上,对于我们不同的查询过程中,就是通过一些谓词过滤条件,从对应的数据块中获取正确的一行数据或多行数据。如何快速定位到该数据行,是一个数据库学习者不断探索的方向。 1 Rowid 1.1 简介 从字面上理解是行标识的意思,它是Oracle数据库中数据表的一个伪列,用于存放该表中每一行数据的地址,在8i版本之前,Oracle采用受限制的rowid,它是由数据文件编号,块编号和数据在该块内的偏移量这三个部分构成,长度为6个字节,因此在8i之前的版本中,每 个数据库最多可以包含1022个文件,每个文件最多能有4m个数据块,而每个数据库最多能 存储64k条记录。为了突破长度的限制和解决其他一些缺陷,Oracle数据库引入了这样一个概念:相对文件号。它的主要特点是改变之前rowid中数据文件编号是整个数据库范围组成的表空间,即文件编号为5的文件不再是数据库中编号为5的数据文件,而是表空间中对应编号的数据文件。如下图1所示为Oracle11g中一个普通表的rowid。 从该图1中可以看到rowid共有18位,分为四部分,格式为:AAAAAABBBCCCCCCDDD,其中AAAAAA六位表示dataobjectid,根据这个id可以确定该行数据在哪个段中;BBB三位表示相对文件号,通过这个字段号可以用来确定该行数据的绝 对文件号;CCCCCC六位表示datablocknumber,它是相对于datafile的编号;最后三位DDD
ORACLE常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not nul l],..) 根据已有的表创建新表: A:select * into table_new from table_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only<仅适用于Oracle> 5、说明:删除表 drop table tablename
6、说明:增加一个列,删除一个列 A:alter table tabname add column col type B:alter table tabname drop column colname 注:DB2DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、添加主键: Alter table tabname add primary key(col) 删除主键: Alter table tabname drop primary key(col) 8、创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、创建视图:create view viewname as select statement 删除视图:drop view viewname 10、几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、几个高级查询运算词 A:UNION 运算符 UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。 B:EXCEPT 运算符 EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。 C:INTERSECT 运算符 INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。 注:使用运算词的几个查询结果行必须是一致的。 12、使用外连接
oracle中以dba_、user_、v$_、all_、session_、index_开头的常用表和视图(https://www.doczj.com/doc/313447939.html,/gzz%5Fgzz/blog/item/1f6ef92a67599392033bf6de.html) 2009年08月10日星期一 17:06 oracle中以dba_、user_、v$_、all_、session_、index_开头的常用表和视图dba_开头 dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space 数据库空闲空间信息 dba_profiles 数据库用户资源限制信息 dba_sys_privs 用户的系统权限信息 dba_tab_privs 用户具有的对象权限信息 dba_col_privs 用户具有的列对象权限信息 dba_role_privs 用户具有的角色信息 dba_audit_trail 审计跟踪记录信息 dba_stmt_audit_opts 审计设置信息 dba_audit_object 对象审计结果信息 dba_audit_session 会话审计结果信息 dba_indexes 用户模式的索引信息 user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息 user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 关于这个还涉及到两个常用的例子如下: 1、oracle中查询某个字段属于哪个表 Sql代码 select table_name,owner from dba_tab_columns t where t.COLUMN_NAME like upper('%username%'); select table_name,owner from dba_tab_columns t where t.COLUMN_NAME like
fnd_user 系统用户表 fnd_application 应用信息表 FND_PROFILE_OPTIONS_VL 系统配置文件 fnd_menus 菜单 fnd_menu_entries_tl FND_NEW_MESSAGES 消息表 FND_FORM 表单表 FND_CONCURRENT_PROGRAMS_VL 并发程序视图 FND_CONCURRENT_PROGRAMS_TL FND_CONCURRENT_PROGRAMS FND_DESCR_FLEX_COL_USAGE_VL FND_DESCR_FLEX_COL_USAGE_TL FND_DESCR_FLEX_COLUMN_USAGES FND_EXECUTABLES_FORM_V 可执行并发程序视图FND_EXECUTABLES_TL FND_EXECUTABLES FND_DESCRIPTIVE_FLEXS FND_CONC_REQ_SUMMARY_V 并发请求视图FND_CONCURRENT_REQUESTS FND_RESPONSIBILITY 职责表
FND_RESPONSIBILITY_VL 职责FND_USER_RESP_GROUPS 用户职责 fnd_flex_value_sets 值集表 FND_FLEX_VALUES FND_IREP_ALL_INTERFACES 接口表 FND_IREP_CLASSES Fnd_Irep_Classes_Tl fnd_territories_vl 国家视图 fnd_log_messages 日志表 fnd_form_functions 功能 FND_DOCUMENT_SEQUENCES 单据序列 FND_DOC_SEQUENCE_ASSIGNMENTS 序列分配 fnd_id_flexs 关键弹性域定义表 FND_ID_FLEX_STRUCTURES 弹性域结构表 FND_ID_FLEX_SEGMENTS 弹性域段表 fnd_descriptive_flexs 描述性弹性域属性表 FND_DESCR_FLEX_CONTEXTS 弹性域列类别表 FND_DESCR_FLEX_COLUMN_USAGES 弹性域列类别属性表FND_FLEX_VALUE_SETS 值集表 FND_FLEX_VALUES 值表 Fnd_Flex_Values_Tl 值描述表
oracle视图总结(转) 视图简介: 视图是基于一个表或多个表或视图的逻辑表,本身不包含数据,通过它可以对表里面的数据进行查询和修改。视图基于的表称为基表。视图是存储在数据字典里的一条select语句。通过创建视图可以提取数据的逻辑上的集合或组合。 视图的优点: 1.对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。 2.用户通过简单的查询可以从复杂查询中得到结果。 3.维护数据的独立性,试图可从多个表检索数据。 4.对于相同的数据可产生不同的视图。 视图的分类: 视图分为简单视图和复杂视图。 两者区别如下: 1.简单视图只从单表里获取数据,复杂视图从多表获取数据; 2.简单视图不包含函数和数据组,复杂视图包含; 3.简单视图可以实现DML操作,复杂视图不可以。 视图的创建: CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name [(alias[, alias]...)] AS subquery [WITH CHECK OPTION [CONSTRAINT constraint]] [WITH READ ONLY] 其中: OR REPLACE:若所创建的试图已经存在,ORACLE自动重建该视图; FORCE:不管基表是否存在ORACLE都会自动创建该视图; NOFORCE:只有基表都存在ORACLE才会创建该视图: alias:为视图产生的列定义的别名; subquery:一条完整的SELECT语句,可以在该语句中定义别名; WITH CHECK OPTION :插入或修改的数据行必须满足视图定义的约束; WITH READ ONLY :该视图上不能进行任何DML操作。 例如: Sql代码 1.CREATE OR REPLACE VIEW dept_sum_vw 2.(name,minsal,maxsal,avgsal)
Oracle常用数据字典表(系统表或系统视图)及查询SQL 2014年12月15日?数据库?共4187字?暂无评论?阅读861 次 文章目录 ?数据字典分类 ?dba_开头 ?user_开头 ?v$开头 ?all_开头 ?session_开头 ?index_开头 ?伪表 ?数据字典常用SQL查询 数据字典是Oracle存放有关数据库信息的地方,其用途是用来描述数据的。比如一个表的创建者信息,创建时间信息,所属表空间信息,用户访问权限信息的视图等。 数据字典系统表,保存在system表空间中。查询所有数据字典可用语句“select * from dictionary;”。 数据字典分类 数据字典主要可分为四部分: 1)内部RDBMS表:x$*,用于跟踪内部数据库信息,维持DB的正常运行。是加密命名的,不允许sysdba以外的用户直接访问,显示授权不被允许。
2)数据字典表:*$,如tab$,obj$,ts$等,用来存储表、索引、约束以及其他数据库结构的信息。 3)动态性能视图:gv$*,v$*,记录了DB运行时信息和统计数据,大部分动态性能视图被实时更新以反映DB当前状态。 4)数据字典视图:user_*、all_*、dba_*,在非Sys用户下,我们访问的都是同义词,而不是V$视图或GV视图。 数据库启动时,动态创建x$,在X$基础上创建GV$,在GV$基础上创建V$X$表-->GV$(视图)--->V$(视图)。 数据字典视图可分为静态数据字典视图和动态数据字典视图。 静态数据字典是指在用户访问数据字典时内容不会发生改变。这类数据字典主要是由表和视图组成,应该注意的是,数据字典中的表是不能直接被访问的,但是可以访问数据字典中的视图。 静态数据字典中的视图分为三类,它们分别由三个前缀够成:user_*(该用户方案对象的信息)、all_*(该用户可以访问的所有对象的信息)、dba_*(全部数据库对象的信息)。 动态数据字典是Oracle包含的一些潜在的由系统管理员如SYS维护的表和视图,由于当数据库运行的时候它们会不断进行更新,所以称它们为动态数据字典。这些视图提供了关于内存和磁盘的运行情况,所以我们只能对其进行只读访问而不能修改它们。Oracle中这些动态性能视图都是以v$开头的视图,比如v$access。 dba_开头 dba_users数据库用户信息
Oracle DBA 常用视图 ☆dba_开头..... dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space 数据库空闲空间信息dba_profiles 数据库用户资源限制信息dba_sys_privs 用户的系统权限信息 dba_tab_privs 用户具有的对象权限信息dba_col_privs 用户具有的列对象权限信息dba_role_privs 用户具有的角色信息 dba_audit_trail 审计跟踪记录信息 dba_stmt_audit_opts 审计设置信息 dba_audit_object 对象审计结果信息 dba_audit_session 会话审计结果信息dba_indexes 用户模式的索引信息
☆user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 user_constraints 用户的对象约束信息 user_sys_privs 当前用户的系统权限信息 user_tab_privs 当前用户的对象权限信息 user_col_privs 当前用户的表列权限信息 user_role_privs 当前用户的角色权限信息 user_indexes 用户的索引信息 user_ind_columns 用户的索引对应的表列信息user_cons_columns 用户的约束对应的表列信息user_clusters 用户的所有簇信息 user_clu_columns 用户的簇所包含的内容信息user_cluster_hash_expressions 散列簇的信息 ☆v$开头 v$database 数据库信息 v$datafile 数据文件信息 v$controlfile 控制文件信息 v$logfile 重做日志信息
总结ORACLE系统视图及表大全: dba_开头..... dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space数据库空闲空间信息 dba_profiles 数据库用户资源限制信息 dba_sys_privs 用户的系统权限信息 dba_tab_privs用户具有的对象权限信息dba_col_privs用户具有的列对象权限信息dba_role_privs用户具有的角色信息 dba_audit_trail审计跟踪记录信息 dba_stmt_audit_opts审计设置信息 dba_audit_object 对象审计结果信息 dba_audit_session会话审计结果信息 dba_indexes用户模式的索引信息 user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 user_constraints 用户的对象约束信息 user_sys_privs 当前用户的系统权限信息
user_tab_privs 当前用户的对象权限信息 user_col_privs 当前用户的表列权限信息 user_role_privs 当前用户的角色权限信息 user_indexes 用户的索引信息 user_ind_columns用户的索引对应的表列信息 user_cons_columns 用户的约束对应的表列信息 user_clusters 用户的所有簇信息 user_clu_columns 用户的簇所包含的内容信息 user_cluster_hash_expressions 散列簇的信息 v$开头 v$database 数据库信息 v$datafile 数据文件信息 v$controlfile控制文件信息 v$logfile 重做日志信息 v$instance 数据库实例信息 v$log 日志组信息 v$loghist 日志历史信息 v$sga 数据库SGA信息 v$parameter 初始化参数信息 v$process 数据库服务器进程信息 v$bgprocess 数据库后台进程信息 v$controlfile_record_section 控制文件记载的各部分信息v$thread 线程信息 v$datafile_header 数据文件头所记载的信息 v$archived_log归档日志信息 v$archive_dest 归档日志的设置信息 v$logmnr_contents 归档日志分析的DML DDL结果信息v$logmnr_dictionary 日志分析的字典文件信息 v$logmnr_logs 日志分析的日志列表信息 v$tablespace 表空间信息
ORACLE数据字典与视图 当ORACLE数据库系统启动后,数据字典总是可用,它驻留在SYSTEM表空间中,所有权属于sys(DBA)用户。 数据字典包含数据库中所有模式对象(包括表、视图、索引、聚簇、同义词、序列、过程、函数、包、触发器等)的定义、列的默认值、完整性约束的定义、用户的权限和角色信息、存储空间分配情况、审计信息、字符集信息等数据库信息。 为了方便用户查询,在数据字典表上建立了数据字典视图集。视图集分为三种,这些视图包含有类似信息,彼此以前缀相区别,前缀为USER、ALL和DBA。 ▽前缀为USER_的视图,为用户视图,是在用户的模式内,包含当前用户所拥有的全部对象信息。如:USER_OBJECTS视图包含当前用户所建立的对象信息。 ▽前缀为ALL_的视图,为扩展的用户视图,除包含当前用户所拥有的全部对象信息以外,还包含公共帐号和显式授权用户所拥有的全部模式对象信息。如:ALL_USERS。 ▽前缀为DBA_的视图,为DBA的视图,包含整个数据库的所有用户所拥有的所有对象信息,而不局限于部分用户。如:DBA_USERS视图包含数据库中所有用户信息。只有DBA用户或被授予select_any_dictionary系统权限的用户才能够访问DBA视图。 在数据库ORACLE还维护了一组虚表(virtual table),记录当前数据库的活动情况和性能参数,这些表称为动态性能表。动态性能表的拥有者为SYS用户,名字均以V_$或GV_$为前缀。动态性能表不是真正的表,许多用户不能直接存取。DBA可通过查询这些表,了解系统运行状况、诊断和解决系统运行中出现的问题。DBA可以建立视图,给其它用户授予存取视图权。为了便于访问,Oracle在动态性能表的基础上建立了公用同义词,这些同义词的名字以V_$开头。如V_$BGPROCESS视图记录Oracle后台进程信息。 Sys帐号进去在视图下可见全部数据字典。其它帐号只能通过SQL语句查询 ORACLE数据字典与视图(部分,不全) 视图名说明
Oracle视图中建立索引的注意事项 在视图上创建索引需要三个条件: 一、视图必须绑定到架构。 要做到这点,在 CREATE VIEW 语句中,必须加上 WITH SCHEMABINDING,如果是使用企业管理器,则在设计界面的空白处点击右键,属性,选中“绑定到架构”。 二、索引必须是唯一索引。 要做到这点,在 CREATE INDEX 中必须指定 UNIQUE。 三、索引必须是聚集索引。 要做到这点,在 CREATE INDEX 中必须指定 CLUSTERED。 例: CREATE VIEW viewFoo WITH SCHEMABINDING AS SELECT id... CREATE UNIQUE CLUSTERED INDEX index_viewFoo ON viewFoo(id) 在视图上创建聚集索引之前,该视图必须满足下列要求: 当执行 CREATE VIEW 语句时,ANSI_NULLS 和 QUOTED_IDENTIFIER 选项必须设置为 ON。OBJECTPROPERTY 函数通 过 ExecIsAnsiNullsOn 或 ExecIsQuotedIdentOn 属性为视图报告此信息。 为执行所有 CREATE TABLE 语句以创建视图引用的表,ANSI_NULLS 选项必须设置为 ON。 视图不能引用任何其它视图,只能引用基表。 视图引用的所有基表必须与视图位于同一个数据库中,并且所有者也与视图相同。 必须使用 SCHEMABINDING 选项创建视图。SCHEMABINDING 将视图绑定到基础基表的架构。 必须已使用 SCHEMABINDING 选项创建了视图中引用的用户定义的函数。 表和用户定义的函数必须由 2 部分的名称引用。不允许使用 1 部分、3 部分和 4 部分的名称。
oracle数据库中的表与视图 Oracle数据库数据对象中最基本的是表和视图,其他还有约束、序列、函数、存储过程、包、触发器等。对数据库的操作可以基本归结为对数据对象的操作,理解和掌握Oracle数据库对象是学习Oracle的捷径。 表和视图 Oracle中表是数据存储的基本结构。ORACLE8引入了分区表和对象表,ORACLE8i 引入了临时表,使表的功能更强大。视图是一个或多个表中数据的逻辑表达式。本文我们将讨论怎样创建和管理简单的表和视图。 管理表 表可以看作有行和列的电子数据表,表是关系数据库中一种拥有数据的结构。用CREATE TABLE语句建立表,在建立表的同时,必须定义表名,列,以及列的数据类型和大小。例如: CREATE TABLE products ( PROD_ID NUMBER(4), PROD_NAME VAECHAR2(20), STOCK_QTY NUMBER(5,3) ); 这样我们就建立了一个名为products的表,关键词CREATE TABLE后紧跟的表名,然后定义了三列,同时规定了列的数据类型和大小。 在创建表的同时你可以规定表的完整性约束,也可以规定列的完整性约束,在列上普通的约束是NOT NULL,关于约束的讨论我们在以后进行。 在建立或更改表时,可以给表一个缺省值。缺省值是在增加行时,增加的数据行中某一项值为null时,oracle即认为该值为缺省值。 下列数据字典视图提供表和表的列的信息: . DBA_TABLES . DBA_ALL_TABLES
. USER_TABLES . USER_ALL_TABLES . ALL_TABLES . ALL_ALL_TABLES . DBA_TAB_COLUMNS . USER_TAB_COLUMNS . ALL_TAB_COLUMNS 表的命名规则 表名标识一个表,所以应尽可能在表名中描述表,oracle中表名或列名最长可以达30个字符串。表名应该以字母开始,可以在表名中包含数字、下划线、#、$等。 从其它表中建立表 可以使用查询从基于一个或多个表中建立表,表的列的数据类型和大小有查询结果决定。建立这种形式的表的查询可以选择其他表中所有的列或者只选择部分列。在CREATE TABLE语句中使用关键字AS,例如: SQL>CREATE TABLE emp AS SELECT * FROM employee TABLE CREATED SQL> CREATE TABLE Y AS SELECT * FROM X WHERE no=2 需要注意的是如果查询涉及LONG数据类型,那么CREATE TABLE....AS SELECT....将不会工作。 更改表定义 在建立表后,有时候我们可能需要修改表,比如更改列的定义,更改缺省值,增加新列,删除列等等。ORACLE使用ALTER TABLE语句来更改表的定义 1、增加列 语法: ALTER TABLE [schema.] table_name ADD column_definition
◆dba_开头 dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space 数据库空闲空间信息 dba_profiles 数据库用户资源限制信息dba_sys_privs 用户的系统权限信息 dba_tab_privs 用户具有的对象权限信息dba_col_privs 用户具有的列对象权限信息dba_role_privs 用户具有的角色信息 dba_audit_trail 审计跟踪记录信息 dba_stmt_audit_opts 审计设置信息
dba_audit_object 对象审计结果信息 dba_audit_session 会话审计结果信息 dba_indexes 用户模式的索引信息 ◆user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 user_constraints 用户的对象约束信息 user_sys_privs 当前用户的系统权限信息 user_tab_privs 当前用户的对象权限信息 user_col_privs 当前用户的表列权限信息 user_role_privs 当前用户的角色权限信息user_indexes 用户的索引信息 user_ind_columns 用户的索引对应的表列信息user_cons_columns 用户的约束对应的表列信息user_clusters 用户的所有簇信息
查看oracle 10g 视图 您正在看的ORACLE教程是:查看oracle 10g 视图。查看oracle 10g 视图 1、查看数据库的名字和归档状态 SQL> select name,log_mode from v$database; NAME LOG_MODE --------- ------------ HB130000 ARCHIVELOG 2、查看数据库的instance名字和状态 SQL> select instance_name,status from v$instance; INSTANCE_NAME STATUS ---------------- ------------ hb130000 OPEN 3、查看表空间名称、状态和管理方式
SQL> select tablespace_name,status,extent_management from dba_tablespaces; TABLESPACE_NAME STATUS EXTENT_MAN ------------------------------ --------- ---------- SYSTEM ONLINE LOCAL UNDOTBS1 ONLINE LOCAL SYSAUX ONLINE LOCAL TEMP ONLINE LOCAL USERS ONLINE LOCAL GFB ONLINE LOCAL YSZX130000002004 ONLINE LOCAL RMAN ONLINE LOCAL 8 rows selected. 4、查看控制文件的位置和名字 SQL> select name from v$controlfile; NAME /oracle/app/oracle/OraHome/dbs/hb130000/control01.ctl /oradata/hb130000/control02.ctl
DBA_TABLES、ALL_TABLES以及USER_TABLES此三个视图可以用来查询ORACLE中关系表信息,它们之间的关系和区别有: DBA_TABLES >= ALL_TABLES >= USER_TABLES DBA_TABLES意为DBA拥有的或可以访问的所有的关系表。 ALL_TABLES意为某一用户拥有的或可以访问的所有的关系表。 USER_TABLES意为某一用户所拥有的所有的关系表。 由上可知,当某一用户本身就为数据库DBA时,DBA_TABLES与ALL_TABLES等价。此规律可以类推至Oracle中其它类似名称的视图。 需要注意的是在ORACLE数据库中大小写是敏感的,而此三表中数据默认都是大写的,所以在进行查询的时候注意小写的数据可能会造成数据无法查到。 一.Oracle表明细及说明 1.dba_开头表 dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space 数据库空闲空间信息 dba_profiles 数据库用户资源限制信息 dba_sys_privs 用户的系统权限信息 dba_tab_privs 用户具有的对象权限信息 dba_col_privs 用户具有的列对象权限信息 dba_role_privs 用户具有的角色信息 dba_audit_trail 审计跟踪记录信息
具体的Oracle参数视图实践(1) 2010-04-19 10:20 佚名 CSDN博客字号: | 一般情况下Oracle数据库是不带参数的视图。有时,我们想使用Oracle参数视图,可以给我们方便查询数据。下面就来简单介绍下。 AD: 一般情况下Oracle数据库是不带参数的视图。有时,我们想使用Oracle参数视图,可以给我们方便查询数据。 比如,眼下我面对这这样一个问题:要打印一张报表,报表的数据源是Oracle视图。现在,随着数据量的增大,打印报表的速度越来越慢了。所以首先想到了如何优化视图,视图的基表为3张表,表A几百条数据,表B大约3万条数据,表C大约60万条数据,其中表C每月大约增加3万条数据,视图的SCRIPTS大概是这个样子: 1.CREATE OR REPLACE VIEW M_VIEW 2.(COL1,COL2,COL3) 3.AS 4.SELECT COL1,COL2,COL3 FROM A,B,C WHERE https://www.doczj.com/doc/313447939.html,=GET_A_NAME(B.ID) AND B.ID = C.ID; 其中,GET_A_NAME()为已定义好的根据B表ID查询其对应的A表NAME的方法。各基表中都已建立了索引,考虑到打印报表时值需要指定月份的数据,所以,想到能不能在视图中限定C.TIME=指定的时间,这样数据量就会大大下降,只需要C表中大约3万条数据。但是,问题是,Oracle中视图是不能带参数的。有问题,就有办法,用变通的办法,看招: 方案1:利用全局变量。 用全局变量做什么?改一下Oracle参数视图: 1.CREATE OR REPLACE VIEW M_VIEW 2.(COL1,COL2,COL3) 3.AS 4.SELECT COL1,COL2,COL3 FROM A,B,C WHERE https://www.doczj.com/doc/313447939.html,=GET_A_NAME(B.ID) AND B.ID = C.ID AND C.TIME=全局变量;
Oracle 显示索引信息 为了显示Oracle索引的信息,Oracle提供了一系列的数据字典视图。通过查询这些数据字典视图,用户可以了解索引的各方面信息。 1.显示表的所有索引 索引是用于加速数据存储的数据库对象。通过查询数据字典视图DBA_INDEXES,可以显示数据库的所有索引;通过查询数据字典视图ALL_INDEXES,可以显示当前用户可访问的所有索引;查询数据字典视图USER_INDEXES,可以显示当前用户的索引信息。下面以显示SCOTT用户EMP表的所有索引为例,说明使用数据字典视图DBA_INDEXES的方法: SQL> connect system/password 已连接。 SQL> select index_name,index_type,uniqueness 2 from dba_indexes 3 where owner='SCOTT' and table_name='EMP'; INDEX_NAME INDEX_TYPE UNIQUENES ------------------------------ --------------------------- --------- EMP_ENAME_INDEX NORMAL NONUNIQUE EMP_JOB_BMP BITMAP NONUNIQUE IDX_ENAME FUNCTION-BASED NORMAL NONUNIQUE PK_EMP NORMAL/REV UNIQUE 如上所示,INDEX_NAME用于标识索引名。INDEX_TYPE用于标识索引类型:NORMAL表示普通B树索引;REV表示反向键索引;BITMAP表示位图索引;FUNCTION 表示基于函数的索引。UNIQUENESS用于标识索引的惟一性;OWNER用于标识对象的所有者;TABLE_NAME用于标识表名。 2.显示索引列 创建索引时,需要提供相应的表列。通过查询数据字典视图DBA_IND_COLUMNS,可以显示所有索引的表列信息;通过查询数据字典视图ALL_IND_COLUMNS,可以显示当前用户可访问所有索引的表列信息;通过查询数据字典视图USER_IND_COLUMNS,可以显示当前用户索引的表列信息。 例如,下面的语句将显示SCOTT用户的PK_EMP索引列信息: SQL> col column_name format a20 SQL> select column_name,column_position,column_length 2 from user_ind_columns 3 where index_name='PK_EMP'; COLUMN_NAME COLUMN_POSITION COLUMN_LENGTH -------------------- ---------------------------- ------------- EMPNO 1 22 如上所示,COLUMN_NAME用于标识索引列的名称;COLUMN_POSITION用于标识列在索引中的位置;COLUMN_LENGTH用于标识索引列的长度。