
1ORACLE数据库简介
一、概论
ORACLE 是以高级结构化查询语言(SQL)为基础的大型关系数据库,通俗地讲它是用方便逻辑管理的语言操纵大量有规律数据的集合。是目前最流行的客户/服务器(CLIENT/SERVER)体系结构的数据库之一。
二、特点
1、ORACLE7.X以来引入了共享SQL和多线索服务器体系结构。这减少了ORACLE 的资源占用,并增强了ORACLE的能力,使之在低档软硬件平台上用较少的资源就可以支持更多的用户,而在高档平台上可以支持成百上千个用户。
2、提供了基于角色(ROLE)分工的安全保密管理。在数据库管理功能、完整性检查、安全性、一致性方面都有良好的表现。
3、支持大量多媒体数据,如二进制图形、声音、动画以及多维数据结构等。
4、提供了与第三代高级语言的接口软件PRO*系列,能在C,C++等主语言中嵌入
SQL语句及过程化(PL/SQL)语句,对数据库中的数据进行操纵。加上它有许多优秀的前台开发工具如 POWER BUILD、SQL*FORMS、VISIA BASIC 等,可以快速开发生成基于客户端PC 平台的应用程序,并具有良好的移植性。
5、提供了新的分布式数据库能力。可通过网络较方便地读写远端数据库里的数据,并有对称复制的技术。
三、存储结构
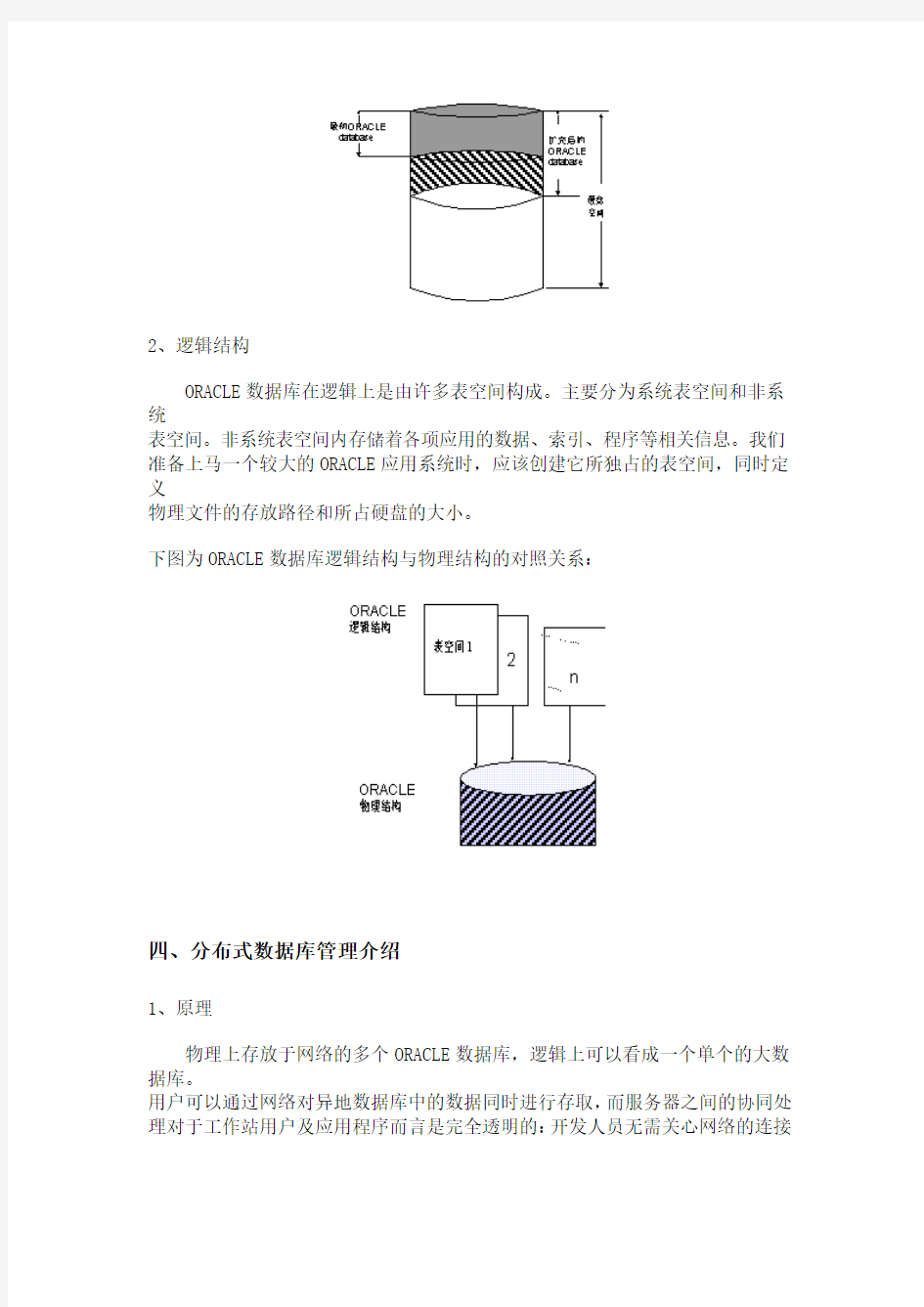
1、物理结构
ORACLE数据库在物理上是存储于硬盘的各种文件。它是活动的,可扩充的,随着
数据的添加和应用程序的增大而变化。
下图为ORACLE数据库扩充前后在硬盘上存储结构的示意图:
2、逻辑结构
ORACLE数据库在逻辑上是由许多表空间构成。主要分为系统表空间和非系统
表空间。非系统表空间内存储着各项应用的数据、索引、程序等相关信息。我们准备上马一个较大的ORACLE应用系统时,应该创建它所独占的表空间,同时定义
物理文件的存放路径和所占硬盘的大小。
下图为ORACLE数据库逻辑结构与物理结构的对照关系:
四、分布式数据库管理介绍
1、原理
物理上存放于网络的多个ORACLE数据库,逻辑上可以看成一个单个的大数据库。
用户可以通过网络对异地数据库中的数据同时进行存取,而服务器之间的协同处理对于工作站用户及应用程序而言是完全透明的:开发人员无需关心网络的连接
细节、无需关心数据在网络接点中的具体分布情况、也无需关心服务器之间的协调工作过程。
下图为ORACLE分布式数据库原理示意图:
2、过程
由网络相连的两个ORACLE数据库之间通过数据库链接(DB-LINKS)建立访问机制,
相当于一方以另一方的某用户远程登录所做的操作。但ORACLE采用的一些高级管理
方法,如同义词(SYNONME)等使我们觉察不到这个过程,似乎远端的数据就在本地。
数据库复制技术包括:实时复制、定时复制、储存转发复制。对复制的力度而言,有整个数据库表的复制,表中部分行的复制。在复制的过程中,有自动冲突检测和
解决的手段。
2.ORACLE的日志管理
2002-10
ORACLE数据库的日志文件
$ORACLE_BASE/admin/orasid/bdump/alert_orasid.log记录了重作日志的转换,
数据库启动和关闭,数据库结构的改变,回退段的修改,死锁,内部错误等信息.
数据库管理员需要检查这个文件有无ORA-错误并定期地对这个日志文件进行存档整理。
在UNIX下可以用grep命令把alert_orasid.log里出现的错误保存到另一个文件。然后去找原因。
$grep ORA- alert_orasid.log > error.log
大家都知道,文件越大,其打开和读写的开销越大。如果日志文件太大了(超过5M), 需要对它截断处理。
直接删除它,让ORACLE重新生成不是好的方法。因为ORACLE是通过一个指向文件的指针进行写操作。
在数据库运行时删除了这个文件, ORACLE仍然用原来的文件指针进行写操作,有可能写一个不存在的文件
导致硬盘空间占用。
我们要采用以下的方法:
$tail -100 $ORACLE_BASE/admin/orasid/bdump/alert_orasid.log > /tmp/oracle_temp.log
$cp /tmp/oracle_temp.log
$ORACLE_BASE/admin/orasid/bdump/alert_orasid.log
$rm /tmp/oracle_temp.log
对日志文件进行截断处理。
listener的日志文件$ORACLE_HOME/network/log/listener.log记录了通过listener处理的网络请求
信息,它包含客户端请求的时间,连接方式(专用或共享),连接程序,网络协议,主机名,网络端口号等信息。
我们也需要周期地截断它,方法是先停止listener记日志的工作:
$lsnrctl set log_status off
然后进行文件处理( 把原来的日志保存到备份文件夹, 使原来的listener.log置空 )
$cp $ORACLE_HOME/network/log/listener.log
$ORACLE_BACKUP/network/log/listener_1.log
$cp /dev/null $ORACLE_HOME/network/log/listener.log
文件操作完成后,打开listener记日志的工作:
$lsnrctl set log_status on
如果你会写简单的shell程序,可以把上面的步骤固化成一个脚本,定一个时间表, 让操作系统去做。
下面是我写的一个按天分割保存listener.log的文件
auto_listener.sh
-------------------------------------------------------------------------------------
rq=` date +"%d" `
cp $ORACLE_HOME/network/log/listener.log
$ORACLE_BACKUP/network/log/listener_$rq.log
su - oracle -c "lsnrctl set log_status off"
cp /dev/null $ORACLE_HOME/network/log/listener.log
su - oracle -c "lsnrctl set log_status on"
-------------------------------------------------------------------------------------
你可以根据自己的情况定义环境变量ORACLE_HOME,ORACLE_BACKUP或者直接改成实际的目录就可以让
操作系统root用户23:59分运行这个shell脚本完成日志文件的分割处理。
3ORACLE SGA 的分配
2002-05 余枫
ORACLE 8.0.X 版本
SGA=((db_block_buffers * block
size)+(shared_pool_size+large_pool_size+log_buffers)+1MB
ORACLE 8.1.X 版本
SGA=((db_block_buffers * block
size)+(shared_pool_size+large_pool_size+java_pool_size+log_buffers)+1 MB
理论上SGA可占OS系统物理内存的1/2——1/3,我们可以根据需求调整
我推荐SGA=0.45*(OS RAM)
假设服务器运行ORACLE 8.1.X 版本, OS系统内存为2G MEM, db_block_size 是8192 bytes,
除了运行ORACLE数据库外, 没有其它的应用程序或服务器软件.
这样SGA合计约为921M ( 0.45*2048M ),
设shared_pool_size 250M (250*1024*1024 bytes)
设database buffer cache 620M (79360*8192 bytes)
initorasid.ora文件里具体各参数如下:
shared_pool_size = 262144000
# 250 M
(说明:如果程序没有采用绑定变量的方法,繁忙的系统可以把
shared_pool_size设到350M--400M
Tom Kyte 说所有未绑定变量的SQL都是坏的SQL, 他拒绝这样的SQL运行在他管理的数据库中。)
db_block_buffers = 79360
# 620 M
log_buffer = 524288
# 512k (128K*CPU个数)
large_pool_size = 31457280
# 30 M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288
# MTS 时 sort_area_retained_size = sort_area_size
SUN Solaris 里/etc/system 文件里的几个参数同样跟内存分配有关
ORACLE 安装时缺省的设置:
建议修改的设置:
set shmsys:shminfo_shmmax=4294967295
set shmsys:shminfo_shmmin=1
set shmsys:shminfo_shmmni=100
set shmsys:shminfo_shmseg=15
set semsys:seminfo_semmns=200
set semsys:seminfo_semmni=70
set ulimit=3000000
set semsys:seminfo_semmni=315
set semsys:seminfo_semmsl=300
set semsys:seminfo_semmns=630
set semsys:seminfo_semopm=315
set semsys:seminfo_semvmx=32767
set shmsys:shminfo_shmmax=4294967295
set shmsys:shminfo_shmmni=315
set shmsys:shminfo_shmseg=10
set shmsys:shminfo_shmmin=1
其中这些参数的含义
shmmax - 共享内存段的最大字节数,建议设大点,甚至可以大过物理内存的字节数
shmmin - 共享内存段的最小尺寸. shmmni - 共享内存段的最大数目.
shmseg - 每个进程可分配的最大共享内存段数目.
shmall - 最大的并发共享内存段数目,比SGA 还要大.
semmns - 信号灯的最大数量,跟ORACLE 的PROCESS 数有关. semmsl - 每个信号灯集合中最多的信号灯数目.
4 简析REDO LOGFILE
2001-11
我们知道Oracle 里联机日志文件(Online redo logfile)循环记录了数据库所有的事务(transaction)。 它的大小、个数和存储位置对数据库性能和恢复也是有重要影响的。本文总结一下关于redo logfile 的一些
内容。
一、redo logfile的简单介绍
它一般有大小相同的一组文件构成。我们可以查看数据库视图v$logfile 知道它的个数和存储位置。
SVRMGRL> select * from v$logfile;
查看数据库视图v$log知道它当前的状态。
SVRMGRL> select * from v$log;
一个时间只有一组logfile group是工作状态(current), redo logfile 满了后会自动切换到下一个
logfile group, 如果数据库是归档方式同时写到归档日志文件。这些文件不能用常规的文本编辑器查看,
它以特定的格式存放, 只有数据库或者专门的软件可以看懂它。
redo logfile的最大数目是在创建数据库时指明的。如果你想知道当前数据库redo logfile的最大数值
是多少,重新生成控制文件, 就可以知道。
SVRMGRL>alter database backup controlfile to trace;
这条语句会在$ORACLE_BASE/admin/dbname/udump/路径下生成当前时间的一个*.trc文件, 也就是数据库
的控制文件, 用文本编辑器, 即可看到数据库创建时用的一些参数, 包括redo logfile的最大数(maxlogfiles)。
二、 redo logfile的大小和位置对数据库性能的影响
如果用ORACLE的安装向导创建的典型数据库, 它的redo logfile大小为500K, 这基本上是不能满足典型的
OLTP应用的, 在数据库日志文件(alert_orasid.log)里会记录着频繁的log switch。ORACLE推荐log switch
时间最好在15--30分钟之间, 所以redo logfile的大小由数据库DML操作数据的大小决定其最佳大小。
redo logfile最好有多个存储位置, 多组成员, 使数据库恢复时有更多的选择。
典型的OLTP应用,redo logfile大小可以为16M。当然繁忙的数据库, 例如当今的门户网站, 这个值可以达
到100M以上.
如果你发现当前数据库日志文件里log switch的时间偏大或者偏小,不要紧。ORACLE提供了在数据库联机状
态来改变redo logfile大小的方法。
三、在联机状态改变redo logfile大小的方法
假如原来有3个小的redo log file, 下面是UNIX环境下的一个例子: 第一步: 往数据库添加三个大的redo logfile
SVRMGRL>ALTER DATABASE ADD LOGFILE GROUP 4
('/opt/oradata/app/redo04.log',
'/ora_bak/oradata2/redolog/redo04.log') size 16M reuse;
SVRMGRL>ALTER DATABASE ADD LOGFILE GROUP 5
('/opt/oradata/app/redo05.log',
'/ora_bak/oradata2/redolog/redo05.log') size 16M reuse;
SVRMGRL>ALTER DATABASE ADD LOGFILE GROUP 6
('/opt/oradata/app/redo06.log',
'/ora_bak/oradata2/redolog/redo06.log') size 16M reuse;
第二步: 手工地做log switch, 使新建的redo logfile起作用.
SVRMGRL>alter system switch logfile;
此操作可以执行一到几次, 使旧的redo logfile成invalid状态.
第三步: 删除原来旧的redo logfile.
SVRMGRL>alter database drop logfile group 1;
SVRMGRL>alter database drop logfile group 2;
SVRMGRL>alter database drop logfile group 3;
四、跟redo logfile有关的其它数据库参数
1、log_buffer
log_buffer是ORACLE SGA的一部分, 所有DML命令修改的数据块先放在log_buffer里, 如果满了或者
到了check_point时候通过lgwr后台进程写到redo logfile
里去。它不能设得太大,这样在意
外发生时会丢失很多改变过的数据。它最好不要大于512K或者128K*CPU 个数。
我们可以用下面的SQL语句检测log_buffer使用情况:
SVRMGRL> select
https://www.doczj.com/doc/2f8466042.html,,rbar.value,https://www.doczj.com/doc/2f8466042.html,,re.value,(rbar.value*100)/re.value||'%' "radio"
from v$sysstat rbar,v$sysstat re
where https://www.doczj.com/doc/2f8466042.html,='redo buffer allocation retries'
and https://www.doczj.com/doc/2f8466042.html,='redo entries';
这个比率小于1%才好,否则增加log_buffer的大小
2、log_checkpoint_interval
Oracle8.1 版本后log_checkpoint_interval指的是两次checkpoint
之间操作系统数据块的个数。
checkpoint时Oracle把内存里修改过的数据块用DBWR写到物理文件,用LGWR写到日志和控制文件。
一般UNIX操作系统的数据块为 512 bytes。
从性能优化来说 log_checkpoint_interval = redo logfile size bytes / 512 bytes
3、log_checkpoint_timeout
Oracle8.1 版本后log_checkpoint_timeout指的是两次checkpoint之间时间秒数。
Oracle建议不用这个参数来控制,因为事务(transaction)大小不是按时间等量分布的。
log_checkpoint_timeout = 0
log_checkpoint_timeout = 900
赛迪网采用了本篇文章, 不过灰框里有一些编辑错误
5ORACLE用户连接的管理
用系统管理员,查看当前数据库有几个用户连接:
SQL> select username,sid,serial# from v$session;
如果要停某个连接用
SQL> alter system kill session 'sid,serial#';
如果这命令不行,找它UNIX的进程数
SQL> select pro.spid from v$session ses,v$process pro where ses.sid=21 and ses.paddr=pro.addr;
说明:21是某个连接的sid数
然后用 kill 命令杀此进程号。
6如何增加ORACLE连接数
2000-05
ORACLE的连接数(sessions)与其参数文件中的进程数(process)有关,它们的关系如下:
sessions=(1.1*process+5)
但是我们增加process数时,往往数据库不能启动了。这因为我们还漏调了一个unix系统参数:它是/etc/system/ 中semmns,这是unix系统的信号量参数。每个process会占用一个信号量。semmns调整后,
需要重新启动unix操作系统,参数才能生效。不过它的大小会受制于硬件的内存或ORACLE SGA。范围
可从200——2000不等。
semmns的计算公式为:SEMMNS>processes+instance_processes+system
processes=数据库参数processes的值
instance_processes=5(smon,pmon,dbwr,lgwr,arch)
system=系统所占用信号量。系统所占用信号量可用下列命令查出:#ipcs -sb 其中列NSEMS显示系统已占用信号量。
其它一些跟连接有关的参数,如 licence_max_sessions,
licence_sessions_warning 等默认设置都为
零,也就是没有限制。我们可以放心大胆地使用数据库了。
7ORACLE逻辑备份的SH文件
完全备份的SH文件:exp_comp.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=complete
file=/oracle/export/db_comp$rq.dmp"
累计备份的SH文件:exp_cumu.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=cumulative
file=/oracle/export/db_cumu$rq.dmp"
增量备份的SH文件: exp_incr.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=incremental
file=/oracle/export/db_incr$rq.dmp"
root用户crontab文件
/var/spool/cron/crontabs/root增加以下内容
0 2 1 * * /oracle/exp_comp.sh
30 2 * * 0-5 /oracle/exp_incr.sh
45 2 * * 6 /oracle/exp_cumu.sh
当然这个时间表可以根据不同的需求来改变的,这只是一个例子。
8改数据库的启动方式为archive归档方式
2000-12
1、先按正常方式关闭数据库
然后
%svrmgrl
SVRMGRL>connect internal
SVRMGRL>startup mount [database_name];
SVRMGRL>alter database [database_name] archivelog;
SVRMGRL>archive log list;
SVRMGRL>alter database open;
2、设置数据库开启后自动启动archive进程
改参数文件initoraid.ora
中 log_archive_start=true
log_archive_dest=directory or device name
log_archive_format=filename format
再重新启动数据库,即可
3、注意事项
有足够的资源存放归档日志文件
定一个热备份计划,定期删除归档日志文件
9ORACLE的分布式管理
1999-12
物理上存放于网络的多个ORACLE数据库,逻辑上可以看成一个单个的大数
据库。用户可以通过网络对异地数据库中的数据同时进行存取,而服务器之间的协同处理对于工作站用户及应用程序而言是完全透明的:开发人员无需关心网络的链接细节、无需关心数据在网络接点中的具体分布情况、也无需关心服务器之间的协调工作过程。
数据库之间的链接建立在DATABASE LINK上。要创建一个DB LINK,必须先
在每个数据库服务器上设置链接字符串。
例如,深圳SUN平台ORACLE数据库,在/var/opt/oracle/tnsnames.ora 中有以下
一条和北京的数据库链接tobeijing,格式如下:
链接字符串的设置说明
tobeijing=(description=database link名称:tobeijing (address=(protocol=tcp)采用tcp/ip协议
(host=https://www.doczj.com/doc/2f8466042.html,)欲链接主机名称或IP地址(port=1521))网络端口1521 (connect_data=(sid=oracle7)))安装ORACLE采用的sid
然后进入系统管理员SQL>操作符下,运行命令:
SQL>create public database link beijing connect to scott identified by tiger using 'tobeijing';
则创建了一个以scott用户和北京数据库的链接beijing,我们查询北京的scott 数据:
SQL>select * from emp@beijing;
这样就可以把深圳和北京scott用户的数据做成一个整体来处理。
为了使有关分布式操作更透明,ORACLE数据库里有同义词的对象synonym SQL>create synonym bjscottemp for emp@beijing;
于是就可以用bjscottemp来替代带@符号的分布式链接操作emp@beijing。查看所有的数据库链接,进入系统管理员SQL>操作符下,运行命令:SQL>select owner,object_name from dba_objects where
object_type='DATABASE LINK';
建ORACLE快照日志:
SQL>create snapshot log on table3 with primary key;
建快照:
SQL>create snapshot table3beijing refresh force start with sysdate next sysdate+1/24 with primary key as select * from
table3@beijing;
ORACLE的快照刷新方式refresh有三种:
fast快速刷新,用snapshot log,只更新时间段变动部分complete完全刷新,运行SQL语句
force自动判断刷新,介于fast和complete之间
10监控数据库性能的SQL
1. 监控事例的等待
select event,sum(decode(wait_Time,0,0,1)) "Prev",
sum(decode(wait_Time,0,1,0)) "Curr",count(*) "Tot"
from v$session_Wait
group by event order by 4;
2. 回滚段的争用情况
select name, waits, gets, waits/gets "Ratio"
from v$rollstat a, v$rollname b
where https://www.doczj.com/doc/2f8466042.html,n = https://www.doczj.com/doc/2f8466042.html,n;
3. 监控表空间的 I/O 比例
select df.tablespace_name name,df.file_name "file",f.phyrds pyr,
f.phyblkrd pbr,f.phywrts pyw, f.phyblkwrt pbw
from v$filestat f, dba_data_files df
where f.file# = df.file_id
order by df.tablespace_name;
4. 监控文件系统的 I/O 比例
select substr(a.file#,1,2) "#", substr(https://www.doczj.com/doc/2f8466042.html,,1,30) "Name",
a.status, a.bytes,
b.phyrds, b.phywrts
from v$datafile a, v$filestat b
where a.file# = b.file#;
5.在某个用户下找所有的索引
select user_indexes.table_name, user_indexes.index_name,uniqueness, column_name from user_ind_columns, user_indexes
where user_ind_columns.index_name = user_indexes.index_name
and user_ind_columns.table_name = user_indexes.table_name
order by user_indexes.table_type, user_indexes.table_name,
user_indexes.index_name, column_position;
6. 监控 SGA 的命中率
select a.value + b.value "logical_reads", c.value "phys_reads",
round(100 * ((a.value+b.value)-c.value) / (a.value+b.value)) "BUFFER HIT RATIO" from v$sysstat a, v$sysstat b, v$sysstat c
where a.statistic# = 38 and b.statistic# = 39
and c.statistic# = 40;
7. 监控 SGA 中字典缓冲区的命中率
select parameter, gets,Getmisses , getmisses/(gets+getmisses)*100 "miss ratio", (1-(sum(getmisses)/ (sum(gets)+sum(getmisses))))*100 "Hit ratio"
from v$rowcache
where gets+getmisses <>0
group by parameter, gets, getmisses;
8. 监控 SGA 中共享缓存区的命中率,应该小于1%
select sum(pins) "Total Pins", sum(reloads) "Total Reloads",
sum(reloads)/sum(pins) *100 libcache
from v$librarycache;
select sum(pinhits-reloads)/sum(pins) "hit radio",sum(reloads)/sum(pins) "reload percent"
from v$librarycache;
9. 显示所有数据库对象的类别和大小
select count(name) num_instances ,type ,sum(source_size) source_size ,
sum(parsed_size) parsed_size ,sum(code_size) code_size ,sum(error_size)
error_size,
sum(source_size) +sum(parsed_size) +sum(code_size) +sum(error_size) size_required from dba_object_size
group by type order by 2;
10. 监控 SGA 中重做日志缓存区的命中率,应该小于1%
SELECT name, gets, misses, immediate_gets, immediate_misses,
Decode(gets,0,0,misses/gets*100) ratio1,
Decode(immediate_gets+immediate_misses,0,0,
immediate_misses/(immediate_gets+immediate_misses)*100) ratio2
FROM v$latch WHERE name IN ('redo allocation', 'redo copy');
11. 监控内存和硬盘的排序比率,最好使它小于 .10,增加 sort_area_size
SELECT name, value FROM v$sysstat WHERE name IN ('sorts (memory)', 'sorts (disk)');
12. 监控当前数据库谁在运行什么SQL语句
SELECT osuser, username, sql_text from v$session a, v$sqltext b
where a.sql_address =b.address order by address, piece;
13. 监控字典缓冲区
SELECT (SUM(PINS - RELOADS)) / SUM(PINS) "LIB CACHE" FROM V$LIBRARYCACHE;
SELECT (SUM(GETS - GETMISSES - USAGE - FIXED)) / SUM(GETS) "ROW CACHE" FROM
V$ROWCACHE;
SELECT SUM(PINS) "EXECUTIONS", SUM(RELOADS) "CACHE MISSES WHILE EXECUTING" FROM V$LIBRARYCACHE;
后者除以前者,此比率小于1%,接近0%为好。
SELECT SUM(GETS) "DICTIONARY GETS",SUM(GETMISSES) "DICTIONARY CACHE GET MISSES" FROM V$ROWCACHE
14. 找ORACLE字符集
select * from sys.props$ where name='NLS_CHARACTERSET';
15. 监控 MTS
select busy/(busy+idle) "shared servers busy" from v$dispatcher;
此值大于0.5时,参数需加大
select sum(wait)/sum(totalq) "dispatcher waits" from v$queue where
type='dispatcher';
select count(*) from v$dispatcher;
select servers_highwater from v$mts;
servers_highwater接近mts_max_servers时,参数需加大
16. 碎片程度
select tablespace_name,count(tablespace_name) from dba_free_space group by tablespace_name
having count(tablespace_name)>10;
alter tablespace name coalesce;
alter table name deallocate unused;
create or replace view ts_blocks_v as
select tablespace_name,block_id,bytes,blocks,'free space' segment_name from
dba_free_space
union all
select tablespace_name,block_id,bytes,blocks,segment_name from dba_extents;
select * from ts_blocks_v;
select tablespace_name,sum(bytes),max(bytes),count(block_id) from dba_free_space group by tablespace_name;
查看碎片程度高的表
SELECT segment_name table_name , COUNT(*) extents
FROM dba_segments WHERE owner NOT IN ('SYS', 'SYSTEM') GROUP BY segment_name
HAVING COUNT(*) = (SELECT MAX( COUNT(*) ) FROM dba_segments GROUP BY segment_name);
17. 表、索引的存储情况检查
select segment_name,sum(bytes),count(*) ext_quan from dba_extents where
tablespace_name='&tablespace_name' and segment_type='TABLE' group by
tablespace_name,segment_name;
select segment_name,count(*) from dba_extents where segment_type='INDEX' and owner='&owner'
group by segment_name;
18、找使用CPU多的用户session
12是cpu used by this session
select a.sid,spid,status,substr(a.program,1,40)
prog,a.terminal,osuser,value/60/100 value
from v$session a,v$process b,v$sesstat c
where c.statistic#=12 and c.sid=a.sid and a.paddr=b.addr order by value desc; 11用自动ftp提高工作效率
2003-01
前段时间继续看从https://www.doczj.com/doc/2f8466042.html,下载的书《LINUX与UNIX Shell 编程指南》,不经意的发现有一个写成
自动FTP的SHELL脚本,结合数据库的系统管理,它有很多用途,可以提高你的工作效率。
用途1: 把数据库的逻辑备份或者其它关键的文件传到另一个地区,实现远端备份。
( 例如:从北京机房的传到上海机房。)
auto_ftp.sh 内容如下:
#!/usr/bin/sh
ftp -i -n 192.168.0.253 < user username password bin put /oracle_backup/exp/user1.dmp.Z /bk/oracle_bak/dmp/user1.dmp.Z put /oracle_backup/exp/user2.dmp.Z /bk/oracle_bak/dmp/user2.dmp.Z quit FTPIT 你可以根据实际情况修改斜体字的内容: 目标服务器的IP地址,ftp用户名和密码,put或者get传递方式,源目录文件和目标目录文件。 用途2: 使远端节点间有规律的数据库导出并导入的工作自动进行。 按时间顺序在源服务器执行exp_tables.sh,然后auto_ftp_tables.sh。 接着在目标服务器执行drop_tables.sh,最后imp_tables.sh。 如何设置时间表并自动执行,请参看UNIX下让ORACLE定时执行*.sql 文件。 用途3: 把自动生成的压缩格式的报表文件传到Linux邮件服务器,由机器自动给相关人员发EMAIL。 auto_mail.sh 内容如下: $(cat mail.txt; uuencode report1.txt report2.txt ) | mail maggiefengyu@https://www.doczj.com/doc/2f8466042.html, 说明:mail.txt为邮件正文的内容,report1.txt.Z report2.txt.Z为邮件的两个附件, maggiefengyu@https://www.doczj.com/doc/2f8466042.html,为邮件的收件人。 12定期分析数据库对象的脚本 2002-12 Oracle参数优化参考 分析评价Oracle数据库性能主要有数据库吞吐量、数据库用户响应时间两项指标。数据库用户响应时间又可以分为系统服务时间和用户等待时间两项,即: 数据库用户响应时间=系统服务时间+用户等待时间 因此,获得满意的用户响应时间有两个途径:一是减少系统服务时间,即提高数据库的吞吐量;二是减少用户等待时间,即减少用户访问同一数据库资源的冲突率。 数据库性能优化包括如下几个部分: 1. 调整数据结构的设计这一部分在开发信息系统之前完成,程序员需要考虑是否使用Oracle数据库的分区功能,对于经常访问的数据库表是否需要建立索引等。 2. 调整应用程序结构设计这一部分也是在开发信息系统之前完成的。程序员在这一步需要考虑应用程序使用什么样的体系结构,是使用传统的Client/Server两层体系结构,还是使用Browser/Web/Database的三层体系结构。不同的应用程序体系结构要求的数据库资源 3. 调整数据库SQL语句应用程序的执行最终将归结为数据库中的SQL语句执行,因此SQL语句的执行效率最终决定了Oracle数据库的性能。 Oracle公司推荐使用Oracle语句优化器(Oracle Optimizer)和行锁管理器(Row-Level Manager)来调整优化SQL语句。 4. 调整服务器内存分配内存分配是在信息系统运行过程中优化配置的。数据库管理员根据数据库的运行状况不仅可以调整数据库系统全局区(SGA区)的数据缓冲区、日志缓冲区和共享池的大小,而且还可以调整程序全局区(PGA区)的大小。 5. 调整硬盘I/O 这一步是在信息系统开发之前完成的。数据库管理员可以将组成同一个表空间的数据文件放在不同的硬盘上,做到硬盘之间I/O 负载均衡。 6. 调整操作系统参数例如:运行在Unix操作系统上的 Oracle数据库,可以调整Unix数据缓冲区的大小、每个进程所能使用的内存大小等参数。 下面为一些参数调优参考: 一、db_file_multiblock_read_count: oracle读取数据有两种方式: 1) 通过rowid(即索引扫描) 2) 通过全表扫描 如果是全表扫描时,oracle会一次读取多个blocks,每次读取的块数将受初始化参数db_file_multiblock_read_count和操作系统的I/o缓冲区大小的限制。 设置DB_FILE_MULTIBLOCK_READ_COUNT以充分利用操作系统I/O缓冲区的大小。应考虑 ORACLE 选择 B52X0001ORACLE7数据库中,命令lsnrctl start用到的参数文件是:() A、tnsnames.ora B、sqlnet.ora C、listener.ora D、以上都不对 正确答案:C B52X0002在将格式化的文本文件导入ORACLE时我们经常采用的是SQLLOAD命令,请选择正确的写法() A、sqlldr username/password control=data_file B、sqlldr username/password rows=128control=data_file C、sqlldr username/password control=data_file rows=64 D、sqlldr username/password control=data_file.ctl 正确答案:D B52X0003在Oracle维护过程中,第一步应查看数据库管理系统的运行日志,其日值文件名为:() A、error_'SID'.log B、Alert_'SID'.log C、trace_'SID'.log E、logtail_'SID'.log 正确答案:B B52X0004SGA(System Global Area)是ORACLE系统为实例分配的一组共享缓冲存储区,SGA分为几个部分。() A、4 B、5 C、6 D、7 正确答案:A库缓冲区、数据字典缓冲区、数据块高速缓冲区、重做日志缓冲区 B52X0005Oracle逻辑结构可分解为:表空间、数据库块、物理块、分类段、范围。它们之间的大小关系正确的是() A、表空间≥范围≥分类段≥数据库块≥物理块 B、表空间≥范围≥分类段≥物理块≥数据库块 C、表空间≥数据库块≥物理块≥分类段≥范围 D、表空间≥分类段≥范围≥数据库块≥物理块 正确答案:D B52X0006ORACLE中模式为模式对象的集合,为一个数据库用户所占有,模式名为与该用户名同名,下列属于模式对象的有() A、表 B、视图 C、快照 D、用户环境文件 Oracle 数据库基础 数据库是我们安装完产品后建立的,可以在同一台主机上存在8i,9i,10g,11g等多个数据库产品,一套产品可以建立多个数据库,每个数据库是独立的。每个数据库都有自己的全套相关文件,有各自的控制文件、数据文件、重做日志文件、参数文件、归档文件、口令文件等等。 其中控制文件、数据文件、重做日志文件、跟踪文件及警告日志(trace files,alert files)属于数据库文件; 参数文件(parameter file)口令文件(password file)是非数据库文件 我们的表存储在数据库中 数据库不能直接读取 我们通过实例(instance)来访问数据库 数据库实例 实例由内存和后台进程组成 实例是访问数据库的方法 初始化参数控制实例的行为 一个实例只能连接一个数据库 启动实例不需要数据库 产品安装好 有初始化参数文件 就可以启动实例 与是否存在数据库无关 实例内存分为SGA 和PGA SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle 服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写。 PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA正相反,PGA 是只被一个进程使用的区域,PGA 在创建进程时分配,在终止进程时回收. 后台进程是实例和数据库的联系纽带 分为核心进程和非核心进程 当前后台进程的查看 SQL> select name,description from v$bgprocess where paddr<>'00'; NAME DESCRIPTION Oracle主要配置文件: Profile文件,oratab文件, 数据库实例初始化文件initSID.ora, listener.ora文件, sqlnet.ora文件, tnsnames.ora文件 Oracle主要配置文件介绍 一、/etc/profile 文件 系统级的环境变量一般在/etc/profile 文件中定义在 CAMS系统与数据库,相关的环境变量就定义在/etc/profile 文件中如下所示: export ORACLE_BASE=/u01/app/oracle export ORACLE_HOME=$ORACLE_BASE/product/8.1.7 export PATH=$PATH:$ORACLE_HOME/bin export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib export ORACLE_SID=cams export ORACLE_TERM=vt100 export ORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/data export NLS_LANG=AMERICAN.ZHS16CGB231280 说明: 1、配置上述环境变量要注意定义的先后顺序如: 定义 ORACLE_HOME时用到了ORACLE_BASE,那么ORACLE_HOME的定义应该在ORACLE_BASE之后 2、使用中文版 CAMS 环境变量 NLS_LANG 的值应该设置为AMERICAN.ZHS16CGB231280 如上所示在使用英文版 CAMS时可以不设置NLS_LANG 即去掉export NLS_LANG=... ... 那一行,也可以设置NLS_LANG 的值为AMERICAN_https://www.doczj.com/doc/2f8466042.html,7ASCII 二、/etc/oratab 文件 /etc/oratab 文件描述目前系统中创建的数据库实例以及是否通过 dbstart 和dbshut 来控制该实例的启动与关闭如下所示忽略以#开头的注释部分 : cams:/u01/app/oracle/product/ 其中 cams 为实例 ID /u01/app/oracle/product/ ORACLE_HOME目录 Y表示允许使用 dbstart和 dbshut 启动和关闭该实例数据库如果设置为 N 表示不通过 dbstart 和 dbshut 启动和关闭实例数据库 CAMS 系统要求在安装完 ORACLE 后要求将该参数修改为 Y 以保证 ORACLE 数据库自启动和关闭 三、数据库实例初始化文件 initSID.ora 一、选择题(40分) 1.Oracle发出下列select语句: SQL> select , , 2 from emp e, dept d 3 where = 4 and substr, 1, 1) = ‘S’; 下列哪个语句是Oracle数据库中可用的ANSI兼容等价语句 A.select empno, ename, loc from emp join dept on = where substr, 1, 1) = ‘S’; B.select empno, ename, loc from emp, dept on = where substr, 1, 1) = ‘S’; C.select empno, ename, loc from emp join dept where = and substr, 1, 1) = ‘S’; D.select empno, ename, loc from emp left join dept on = and substr, 1, 1) = ‘S’; 2.下列哪个选项表示Oracle中select语句的功能 A.可以用select语句改变Oracle中的数据 B.可以用select语句删除Oracle 中的数据 C.可以用select语句和另一个表的内容生成一个表 D.可以用select语句对表截断 3.你要操纵Oracle数据,下列哪个不是SQL命令 A.select * from dual; B.set define C.update emp set ename = 6543 where ename = ‘SMITHERS’; D.create table employees(empid varchar2(10) primary key); 4.你要在Oracle中定义SQL查询。下列哪个数据库对象不能直接从select语句中引用 1、数据库基本语句 (1)表结构处理 创建一个表:cteate table 表名(列1 类型,列2 类型); 修改表的名字 alter table 旧表名 rename to 新表名 查看表结构 desc 表名(cmd) 添加一个字段 alter table 表名 add(列类型); 修改字段类型 alter table 表名 modify(列类型); 删除一个字段 alter table 表名 drop column列名; 删除表 drop table 表名 修改列名 alter table 表名 rename column 旧列名 to 新列名; (2)表数据处理 增加数据:insert into 表名 values(所有列的值); insert into 表名(列)values(对应的值); 更新语句:update 表 set 列=新的值,…[where 条件] 删除数据:delete from 表名 where 条件 删除所有数据,不会影响表结构,不会记录日志, 数据不能恢复--》删除很快: truncate table 表名 删除所有数据,包括表结构一并删除: drop table 表名 去除重复的显示:select distinct 列 from 表名 日期类型:to_date(字符串1,字符串2)字符串1是日期的字 符串,字符串2是格式 to_date('1990-1-1','yyyy-mm-dd')-->返回日期的 类型是1990-1-1 (3)查询语句 1)内连接 select a.*,b.* from a inner join b on a.id=b.parent_id 期末考试卷(卷) 课程名称:数据库考试方式:开卷()闭卷(√) 、本试卷共4 页,请查看试卷中是否有缺页。 2、考试结束后,考生不得将试卷、答题纸带出考场。 1、以下(a )内存区不属于SGA。 A.PGA B.日志缓冲区 C.数据缓冲区 D.共享池 2、d )模式存储数据库中数据字典的表和视图。 (A.DBA B.SCOTT C.SYSTEM D.SYS 3、Oracle 中创建用户时,在若未提及DEFAULT TABLESPACE 关键字,Oracle 就将 c )则(表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS 4、a )服务监听并按受来自客户端应用程序的连接请求。(A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer 5、b )函数通常用来计算累计排名、移动平均数和报表聚合等。(A.汇总B.分析C.分组D.单行 6、b)SQL 语句将为计算列SAL*12 生成别名Annual Salary (A.SELECT ename,sal*12 …Annual Salary? FROM emp; B.SELECT ename,sal*12 “Annual Salary” FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM emp; 7、锁用于提供(b )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 8、( c )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 9、带有( b )子句的SELECT 语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH ORACLE常用命令 一、ORACLE的启动和关闭 1、在单机环境下 要想启动或关闭ORACLE系统必须首先切换到ORACLE用户,如下 su - oracle a、启动ORACLE系统 oracle>svrmgrl SVRMGR>connect internal SVRMGR>startup SVRMGR>quit b、关闭ORACLE系统 oracle>svrmgrl SVRMGR>connect internal SVRMGR>shutdown SVRMGR>quit 启动oracle9i数据库命令: $ sqlplus /nolog SQL*Plus: Release 9.2.0.1.0 - Production on Fri Oct 31 13:53:53 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. SQL> connect / as sysdba Connected to an idle instance. SQL> startup^C SQL> startup ORACLE instance started. 2、在双机环境下 要想启动或关闭ORACLE系统必须首先切换到root用户,如下 su -root a、启动ORACLE系统 hareg -y oracle b、关闭ORACLE系统 hareg -n oracle Oracle数据库有哪几种启动方式 说明: 有以下几种启动方式: 1、startup nomount 非安装启动,这种方式启动下可执行:重建控制文件、重建数据库 读取init.ora文件,启动instance,即启动SGA和后台进程,这种启动只需要init.ora文件。 2、startup mount dbname 安装启动,这种方式启动下可执行: 数据库日志归档、 数据库介质恢复、 使数据文件联机或脱机, 重新定位数据文件、重做日志文件。 执行“nomount”,然后打开控制文件,确认数据文件和联机日志文件的位置, 但此时不对数据文件和日志文件进行校验检查。 3、startup open dbname 先执行“nomount”,然后执行“mount”,再打开包括Redo log文件在内的所有数据库文件,这种方式下可访问数据库中的数据。 4、startup,等于以下三个命令 startup nomount alter database mount alter database open 5、startup restrict 约束方式启动 这种方式能够启动数据库,但只允许具有一定特权的用户访问 非特权用户访问时,会出现以下提示: ERROR: ORA-01035: ORACLE 只允许具有RESTRICTED SESSION 权限的用户使用 6、startup force 强制启动方式 请将下列试题的正确答案写在答题栏里。(每小题2分) 1.当Oracle服务器启动时,下列哪种文件不是必须的()。 A.数据文件 B.控制文件 C.日志文件 D.归档日志文件 2.在Oracle中,当用户要执行SELECT语句时,下列哪个进程从磁盘获得用户需要的数据()。 A.用户进程 B.服务器进程 C.日志写入进程(LGWR D.检查点进程(CKPT) 3.在Oracle中,一个用户拥有的所有数据库对象统称为()。 A.数据库 B.模式 C.表空间 D.实例 4.在Oracle中,有一个教师表teacher的结构如下: ID NUMBER(5) NAME V ARCHAR2(25) EMAIL VARCHAR2(50) 下面哪个语句显示没有Email地址的教师姓名()。 A.SELECT name FROM teacher WHERE email = NULL; B.SELECT name FROM teacher WHERE email <> NULL; C.SELECT name FROM teacher WHERE email IS NULL; D.SELECT name FROM teacher WHERE email IS NOT NULL; 5.在Oracle数据库的逻辑结构中有以下组件: A 表空间 B 数据块 C 区 D 段 这些组件从大到小依次是()。 A.A→B→C→D B.A→D→C→B C.A→C→B→D D.D→A→C→B 6.在Windows操作系统中,Oracle的()服务监听并接受来自客户端应用程序的连接请求。 A.OracleHOME_NAMETNSListener constraint pk_spj primary key (sno,pno,jno), constraint fk_spj_sno foreign key (sno) references s(sno), constraint fk_spj_pno foreign key (pno) references p(pno), constraint fk_spj_jno foreign key (jno) references j(jno) 实验二游标和函数 1、定义一个游标完成显示所有供应商名。 declare v_sname s.sname%type; cursor cursor_sname is select sname from s; begin for curso in cursor_sname loop dbms_output.put_line(curso.sname); end loop; end; 2、定义、调用一个简单函数:查询返回指定供应商编号的供应商名及其供应零件总数量。create or replace function fun(f_sno in s.sno%type,f_sname out s.sname%type) return number as f_qty number; begin SELECT s.sname,sum(qty) into f_sname,f_qty from s,spj WHERE s.sno=spj.sno GROUP BY s.sname,spj.sno having spj.sno=f_sno; return f_qty; end; declare v_sno s.sno%type:='&sno'; v_sname s.sname%type; v_qty spj.qty%type; begin v_qty:=fun(v_sno,v_sname); dbms_output.put_line(v_sname||v_qty); end; 3、定义一个函数:对于给定的供应商号,判断是否存在,若存在返回0,否则返回-1。写一段程序调用此函数,若供应商号存在则在spj插入一元组。 1ORACLE数据库简介 一、概论 ORACLE 是以高级结构化查询语言(SQL)为基础的大型关系数据库,通俗地讲它是用方便逻辑管理的语言操纵大量有规律数据的集合。是目前最流行的客户/服务器(CLIENT/SERVER)体系结构的数据库之一。 二、特点 1、ORACLE7.X以来引入了共享SQL和多线索服务器体系结构。这减少了ORACLE 的资源占用,并增强了ORACLE的能力,使之在低档软硬件平台上用较少的资源就可以支持更多的用户,而在高档平台上可以支持成百上千个用户。 2、提供了基于角色(ROLE)分工的安全保密管理。在数据库管理功能、完整性检查、安全性、一致性方面都有良好的表现。 3、支持大量多媒体数据,如二进制图形、声音、动画以及多维数据结构等。 4、提供了与第三代高级语言的接口软件PRO*系列,能在C,C++等主语言中嵌入 SQL语句及过程化(PL/SQL)语句,对数据库中的数据进行操纵。加上它有许多优秀的前台开发工具如 POWER BUILD、SQL*FORMS、VISIA BASIC 等,可以快速开发生成基于客户端PC 平台的应用程序,并具有良好的移植性。 5、提供了新的分布式数据库能力。可通过网络较方便地读写远端数据库里的数据,并有对称复制的技术。 三、存储结构 1、物理结构 ORACLE数据库在物理上是存储于硬盘的各种文件。它是活动的,可扩充的,随着 数据的添加和应用程序的增大而变化。 下图为ORACLE数据库扩充前后在硬盘上存储结构的示意图: 2、逻辑结构 ORACLE数据库在逻辑上是由许多表空间构成。主要分为系统表空间和非系统 表空间。非系统表空间内存储着各项应用的数据、索引、程序等相关信息。我们准备上马一个较大的ORACLE应用系统时,应该创建它所独占的表空间,同时定义 物理文件的存放路径和所占硬盘的大小。 下图为ORACLE数据库逻辑结构与物理结构的对照关系: 四、分布式数据库管理介绍 1、原理 物理上存放于网络的多个ORACLE数据库,逻辑上可以看成一个单个的大数据库。 用户可以通过网络对异地数据库中的数据同时进行存取,而服务器之间的协同处理对于工作站用户及应用程序而言是完全透明的:开发人员无需关心网络的连接 oracle工作原理 (2007-05-18 08:47:40) 转载▼ 分类:计算机技术 第一篇Oracle架构总览 先让我们来看一张图 这张就是Oracle 9i的架构全图。看上去,很繁杂。是的,是这样的。现在让我们来梳理一下: 一、数据库、表空间、数据文件 1.数据库 数据库是数据集合。Oracle是一种数据库管理系统,是一种关系型的数据库管理系统。 通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。也即物理数据、内存、操作系统进程的组合体。 数据库的数据存储在表中。数据的关系由列来定义,即通常我们讲的字段,每个列都有一个列名。数据以行(我们通常称为记录)的方式存储在表中。表之间可以相互关联。以上就是关系模型数据库的一个最简单的描述。 当然,Oracle也是提供对面象对象型的结构数据库的最强大支持,对象既可以与其它对象建立关系,也可以包含其它对象。关于OO型数据库,以后利用专门的篇幅来讨论。一般情况下我们的讨论都基于关系模型。 2.表空间、文件 无论关系结构还是OO结构,Oracle数据库都将其数据存储在文件中。数据库结构提供对数据文件的逻辑映射,允许不同类型的数据分开存储。这些逻辑划分称作表空间。 表空间(tablespace)是数据库的逻辑划分,每个数据库至少有一个表空间(称作SYSTEM表空间)。 为了便于管理和提高运行效率,可以使用一些附加表空间来划分用户和应用程序。例如:USER表空间供一般用户使用,RBS表空间供回滚段使用。一个表空间只能属于一个数据库。 每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。在Oracle7.2以后,数据文件创建可以改变大小。创建新的表空间需要创建新的数 据文件。 数据文件一旦加入到表空间中,就不能从这个表空间中移走,也不能与其它表空间发生联系。 如果数据库存储在多个表空间中,可以将它们各自的数据文件存放在不同磁盘上来对其进行物理分割。在规划和协调数据库I/O请求的方法中,上述的数据分割是一种很重要的方法。数据库、表空间、文件之间的关系如下图所示: 二、数据库实例 为了访问数据库中的数据,Oracle使用一组所有用户共享的后台进程。此外,还有一些存储结构(统 称为System Gloabl Area,即SGA),用来存储最近从数据库查询的数据。数据块缓存区和SQL共享池(Shared SQL Pool)是SGA的最大部分,一般占SGA内存的95%以上。通过减少对数据文件的I/O次数,这些存储区域可以改善数据库的性能。 数据库实例(instance)也称作服务器(server),是用来访问数据库文件集的存储结构及后台进程的集合。一个数据库可以被多个实例访问(这是Oracle并行服务器选项)。实例与数据库的关系如下图所示: 决定实例大小及组成的参数存储的init.ora文件中(在9i中是spfile)。实例启动时需要读这个文件,并且在运行时可以由数据库管理员修改。对该文件的任何修改都只有在下一次启动时才启作用。实例的init.ora文件件通常包含实例的名字:如果一个实例名为orcl,那么init.ora文件通常被命名为initorcl.ora。另一个配置文件config.ora用来存放在数据库创建后就不再改变的变量值(如数据库的块 大小)。实例的config.ora文件通常也包含该实例的名字:如果实例的名字为orcl,则config.ora一般 将被命名为configorcl.ora。为了便于使用config.ora文件的设置值,在实例的init.ora文件中,该文件必须通过IFILE参数作为包含文件列出。 oracle数据库期末考试试题及答案 A1、以下()内存区不属于SGA。 A.PGA B.日志缓冲区C.数据缓冲区D.共享池 D2、()模式存储数据库中数据字典的表和视图。 A.DBA B.SCOTT C.SYSTEM D.SYS C3、在Oracle中创建用户时,若未提及DEFAULT TABLESPACE 关键字,则Oracle就将()表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS A4、()服务监听并按受来自客户端应用程序的连接请求。A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer B5、()函数通常用来计算累计排名、移动平均数和报表聚合等。A.汇总B.分析C.分组D.单行 B6、()SQL语句将为计算列SAL*12生成别名Annual Salary A.SELECT ename,sal*12 ‘Annual Salary' FROM emp; B.SELECT ename,sal*12 “Annual Salary”FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM 12 / 1 emp; B7、锁用于提供( )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 C8、( )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 B9、带有( )子句的SELECT语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH C10、使用( )命令可以在已分区表的第一个分区之前添加新分区。A.添加分区B.截断分区 C.拆分分区D.不能在第一个分区前添加分区 C11、( )分区允许用户明确地控制无序行到分区的映射。 A.散列B.范围C.列表D.复合 C12、可以使用()伪列来访问序列。 A.CURRVAL和NEXTVAL B.NEXTVAL和PREVAL C.CACHE和NOCACHE D.MAXVALUE和MINVALUE oracle数据库是一种大型数据库系统,一般应用于商业,政府部门,它的功能很强大,能够处理大批量的数据,在网络方面也用的非常多。不过,一般的中小型企业都比较喜欢用SQL数据库系统,它的操作很简单,功能也非常齐全。只是比较oracle 数据库而言,在处理大量数据方面有些不如。 Oralce数据库的发展历程 Oralce数据库简介 Oracle简称甲骨文,是仅次于微软公司的世界第二大软件公司,该公司名称就叫Oracle。该公司成立于1979年,是加利福尼亚州的第一家在世界上推出以关系型数据管理系统(RDBMS)为中心的一家软件公司。 Oracle不仅在全球最先推出了RDBMS,并且事实上掌握着这个市场的大部分份额。现在,他们的RDBMS被广泛应用于各种操作环境:Windows NT、基于UNIX系统的小型机、IBM大型机以及一些专用硬件操作系统平台。 事实上,Oracle已经成为世界上最大的RDBMS供应商,并且是世界上最主要的信息处理软件供应商。由于Oracle公司的RDBMS都以Oracle为名,所以,在某种程度上Oracle己经成为了RDBMS的代名词。 Oracle数据库管理系统是一个以关系型和面向对象为中心管理数据的数据库管理软件系统,其在管理信息系统、企业数据处理、因特网及电子商务等领域有着非常广泛的应用。因其在数据安全性与数据完整性控制方面的优越性能,以及跨操作系统、跨硬件平台的数据互操作能力,使得越来越多的用户将Oracle作为其应用数据的处理系统。 Oracle数据库是基于“客户端/服务器”模式结构。客户端应用程序执行与用户进行交互的活动。其接收用户信息,并向“服务器端”发送请求。服务器系统负责管理数据信息和各种操作数据的活动。 Oracle数据库有如下几个强大的特性: 支持多用户、大事务量的事务处理 数据安全性和完整性的有效控制 支持分布式数据处理 可移植性很强 Oracle大体上分两大块,一块是应用开发,一块是系统管理。 开发主要是写存储过程、触发器什么的,还有就是用Oracle的Develop工具做form。有点类似于程序员,需要有较强的逻辑思维和创造能力。管理则需要对Oracle 数据库的原理有深刻的认识,有全局操纵的能力和紧密的思维,责任较大,因为一个小的失误就会丢失整个数据库,相对前者来说,后者更看重经验。 Oracle数据库服务器: Oracle数据库包括Oracle数据库服务器和客户端 Oracle Server是一个对象一关系数据库管理系统。它提供开放的、全面的、和集成的信息管理方法。每个Server由一个 Oracle DB和一个 Oracle Server实例组成。它具有场地自治性(Site Autonomy)和提供数据存储透明机制,以此可实现数据存储透明性。每个 Oracle数据库对应唯一的一个实例名SID,Oracle数据库服务器启动后,一般至少有以下几个用户:Internal,它不是一个真实的用户名,而是具有SYSDBA优 1、判断题,正确请写写"T",错误请写写"F", 1、oracle数据库系统中,启动数据库的第一步是启动一个数据库实例。( T ) 2、Oracle服务器端的监听程序是驻留在服务器上的单独进程,专门负责响应客户机的连接请求。( F) 3、oracle数据库中实例和数据库是一一对应的(非ORACLE并行服务,非集群)。( T) 4、系统全局区SGA 是针对某一服务器进程而保留的内存区域,它是不可以共享的。( F ) 5、数据库字典视图ALL_***视图只包含当前用户拥有的数据库对象信息。( F ) 8、数据字典中的内容都被保存在SYSTEM表空间中。( T ) 9、HAVING后面的条件中可以有聚集函数,比如SUM(),AVG()等, WHERE 后面的条件中也可以有聚集函数。( F ) 10、"上海西北京" 可以通过like ‘%上海_’查出来。( F ) 11、表空间是oracle 最大的逻辑组成部分。Oracle数据库由一个或多个表空间组成。一个表空间由一个或多个数据文件组成,但一个数据文件只能属于一个表空间。( T ) 12、表空间分为永久表空间和临时表空间两种类型。( T ) 13、truncate是DDL操作,不能 rollback。( T ) 14、如果需要向表中插入一批已经存在的数据,可以在INSERT语句中使用WHERE语句。( F ) 15、Oracle数据库中字符串和日期必须使用双引号标识。( F ) 16、Oracle数据库中字符串数据是区分大小写的。( T ) 17、Oracle数据库中可以对约束进行禁用,禁用约束可以在执行一些特殊操作时候保证操作能正常进行。( F ) 18、为了节省存储空间,定义表时应该将可能包含NULL值的字段放在字段列表的末尾。( T ) 20、在连接操作中,如果左表和右表中不满足连接条件的数据都出现在结果中,那么这种连接是全外连接。( T ) 21、自然连接是根据两个表中同名的列而进行连接的,当列不同名时,自然连接将失去意义。( T ) 23、PL/SQL代码块声明区可有可无。( T ) 24、隐式游标与显式游标的不同在于显式游标仅仅访问一行,隐式的可以访问多行。( F ) 课程报告(20 15 -20 16 学年第 1 学期) 报告题目(与Oracle有关的某一方面知识介绍,一级标题,三号字,宋体,居中,加粗) 一、目的与要求(二级标题,四号字,宋体,顶格,加粗) (正文小四号字,宋体) 二、设计内容等(字数3000字以上) 1、(三级标题,小四号字,宋体,顶格,加粗) (正文小四号字,宋体) 参考文献(至少列出三个,标题五号,宋体,加粗,居中) 参考文献内容(五号、宋体;英文用五号,Times New Roman) 其他格式要求: (A4纸):左边距:25mm,右边距:25mm,上边距:30mm,下边距:25mm,页眉边距:23mm,页脚边距:18mm 字符间距:标准 行距:倍 左侧装订 可加附页。此处要求写报告时删去。 上交时间:12月4日。 oracle数据库性能优化 一、目的与要求: oracle数据库性能优化对于保证系统安全,信息安全,业务正常运作具有重要影响。全文首先简要介绍了oracle数据库及特点,然后对数据库性能的评价指标做出一般性概述。随后从CPU利用和内存分配这两方面阐述了数据库性能优化的主要方向。最后介绍了oracle数据库应用系统性能优化技术,即sql语句优化,oracle内存调整,oracle 表空间调整。 信息化系统都基于数据库而运行,而数据库系统性能又最大程度的决定着应用系统的性能。大多数数据库系统在运行一段时间后都会存在一定的性能问题,主要涉及数据库硬件、数据库服务器、数据库内存、应用程序、操作系统、数据库参数等方面。因此,基于数据库系统的性能调整与优化对于整个系统的正常运行起着至关重要的作用。 二、设计内容: 1 oracle数据库及特点 oracle是一个功能极其强大的数据库系统。它起始于七十年代末的关系型数据库技术。这种类型数据库的关键是怎样理解数据间的关系,然后构造反映这些关系的信息库。oracle成功的将关系型数据库转移到桌面计算机上,提供了一个完整的客户/服务器体系结构的商用DBMs。同时它利用SQL*NET软件层,与多种操作系统支持通信协议相配合,为oracle关系型数据库提供分布式环境,可以实现单点更新,多点查询。Oracle数据库已经被用于各种大型信息系统中,特别是诸如银行,保险,烟草,石油等大数据量,对安全性要求较高的企业。其特点主要体现在: 1)支持大数据库、多用户的高性能事务处理Oracle支持最大数据库(几百TB),可充分利用硬件设备。支持大量用户同时在同一数据上执行各种应用,并使数据争用最小,保证数据的一致性[1]。 2)硬件环境独立。Oracle具有良好的硬件环境独立性,支持各种类型的大型,中型,小型和微机系统。 3)遵守数据存取语言、操作系统、用户接口和网络通信协议的工业标准。 4)较好的安全性和完整控制。Oracle有用户鉴别、特权)、角色、触发器、日志、后备等功能,有效地保证了数据存取的安全性和完整性以及并发控制和数据的回复。 5)具有可移植性、可兼容性与可连接性oracle不仅可以在不同型号的机器上运行,而且可以在同一厂家的不同操作系统支持下运行。具有操作系统的独立性。 2 数据库系统性能评价指标 主要从以下几个方面进行: 1)系统吞吐量。吞吐量是指单位时间内数据库完成的SQL语句数目,以每秒钟的事务量(tps)表示。提高系统吞吐量可以通过减少服务时间在同样的资源环境下做更多的工作或通过减少总的响应时间使工作做得更快这两种方法来实现。 2)用户响应时间。响应时间是指用户从提交SQL语句开始到获得结果集的第一行所需要的时间,是应用做出反应的时间,以毫秒或秒表示。响应时间可以分为系统服务时间(CPU时间)和用户等待时间两项。也就是说,要获得满意的用户响应时间有两个 ORACLE 数据库管理系统介绍 的特点: 可移植性 ORACLE采用C语言开发而成,故产品与硬件和操作系统具有很强的独立性。从大型机到微机上都可运行ORACLE的产品。可在UNIX、DOS、Windows等操作系统上运行。可兼容性由于采用了国际标准的数据查询语言SQL,与IBM的SQL/DS、DB2等均兼容。并提供读取其它数据库文件的间接方法。 可联结性对于不同通信协议,不同机型及不同操作系统组成的网络也可以运行ORAˉCLE数据库产品。 的总体结构 (1)ORACLE的文件结构一个ORACLE数据库系统包括以下5类文件:ORACLE RDBMS的代码文件。 数据文件一个数据库可有一个或多个数据文件,每个数据文件可以存有一个或多个表、视图、索引等信息。 日志文件须有两个或两个以上,用来记录所有数据库的变化,用于数据库的恢复。控制文件可以有备份,采用多个备份控制文件是为了防止控制文件的损坏。参数文件含有数据库例程起时所需的配置参数。 (2)ORACLE的内存结构一个ORACLE例程拥有一个系统全程区(SGA)和一组程序全程区(PGA)。 SGA(System Global Area)包括数据库缓冲区、日志缓冲区及 共享区域。 PGA(Program Global Area)是每一个Server进程有一个。一个Server进程起动时,就为其分配一个PGA区,以存放数据及控制信息。 (3)ORACLE的进程结构ORACLE包括三类进程: ①用户进程用来执行用户应用程序的。 ②服务进程处理与之相连的一组用户进程的请求。 ③后台进程 ORACLE为每一个数据库例程创建一组后台进程,它为所有的用户进程服务,其中包括: DBWR(Database Writer)进程,负责把已修改的数据块从数据库缓冲区写到数据库中。LGWR(Log Writer)进程,负责把日志从SGA中的缓冲区中写到日志文件中。 SMON(System Moniter)进程,该进程有规律地扫描SAG进程信息,注销失败的数据库例程,回收不再使用的内存空间。PMON(Process Moniter)进程,当一用户进程异常结束时,该进程负责恢复未完成的事务,注销失败的用户进程,释放用户进程占用的资源。 ARCH(ARCHIVER)进程。每当联机日志文件写满时,该进程将其拷贝到归档存储设备上。另外还包括分布式DB中事务恢复进程RECO 和对服务进程与用户进程进行匹配的Dnnn进程等。 的逻辑结构 构成ORACLE的数据库的逻辑结构包括: (1)表空间 oracle数据库巡检内容 1.检查数据库基本状况 在本节中主要对数据库的基本状况进行检查,其中包含:检查Oracle实例状态,检查Oracle服务进程,检查Oracle监听进程,共三个部分。 SQL> select instance_name,host_name,startup_time,status,database_status from v$instance; INSTANCE_NAME HOST_NAME STARTUP_TIME STATUS DATABASE_STATUS ---------------- ------------------- -------------------- ---------- ------------ ---- CKDB AS14 2009-5-7 9:3 OPEN ACTIVE 其中“STATUS”表示Oracle当前的实例状态,必须为“OPEN”;“DATABASE_STATUS”表示Oracle当前数据库的状态,必须为“ACTIVE”。 SQL> select name,log_mode,open_mode from v$database; NAME LOG_MODE OPEN_MODE --------- ------------ ----------------- CKDB ARCHIVELOG READ WRITE 其中“LOG_MODE”表示Oracle当前的归档方式。“ARCHIVELOG”表示数据库运行在归档模式下,“NOARCHIVELOG”表示数据库运行在非归档模式下。在我们的系统中数据库必须运行在归档方式下。 $ps -ef|grep ora_|grep -v grep&&ps -ef|grep ora_|grep -v grep|wc –loracle参数优化参考
ORACLE试题
Oracle数据库基础
解析Oracle数据库中配置文件
Oracle测试题
Oracle数据库基本知识点
ORACLE数据库期末考试题目及答案
Oracle数据库测试人员必知
Oracle数据库试题
Oracle数据库试题
ORACLE数据库简介
oracle数据库工作原理
oracle数据库期末考试试题及复习资料
Oracle数据库简介
Oracle数据库基础题库【含答案】
Oracle数据库技术课程报告
ORACLE数据库管理系统介绍
oracle数据库巡检内容
相关主题
文本预览