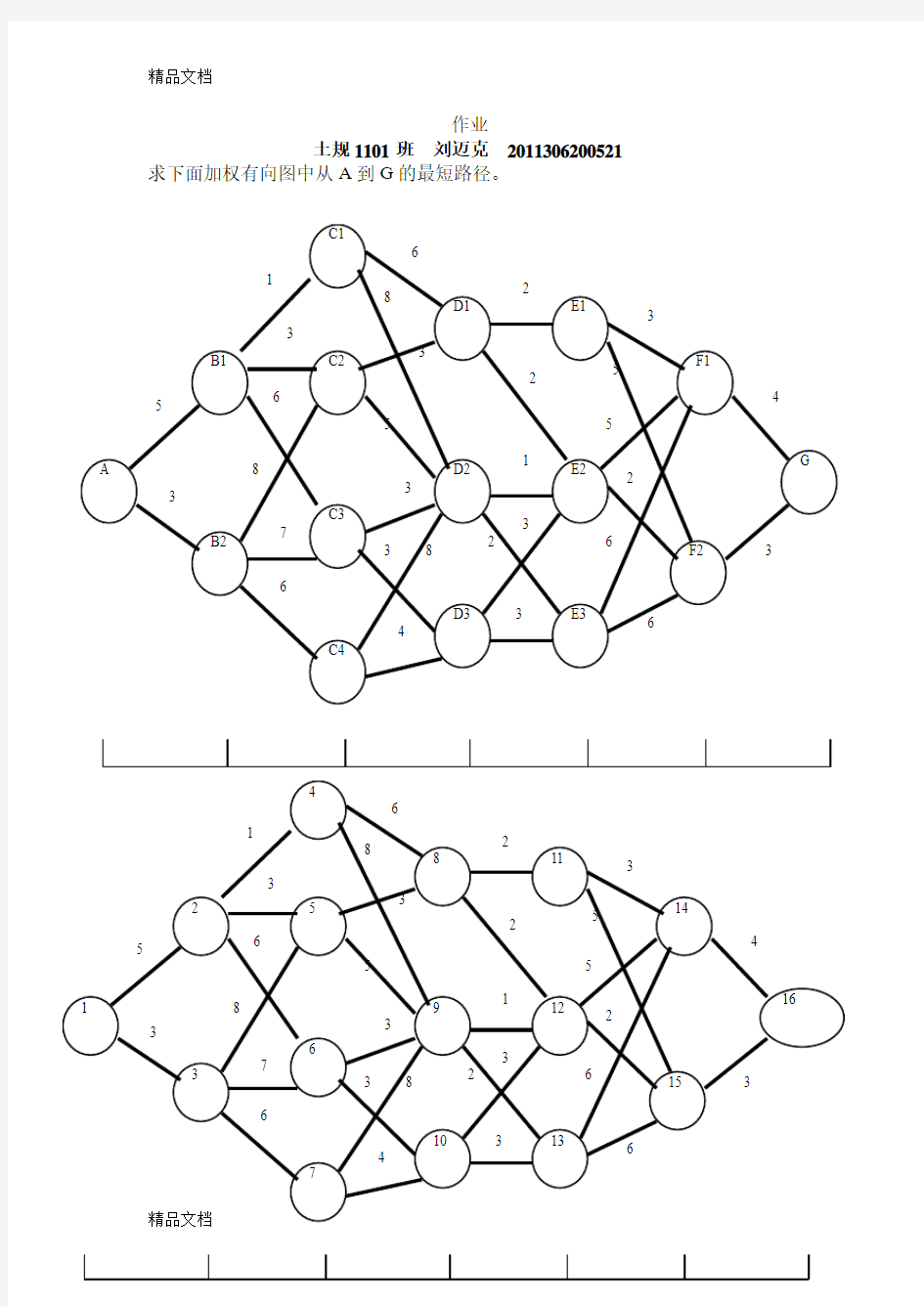

作业
土规1101班刘迈克2011306200521 求下面加权有向图中从A到G的最短路径。
A
B1
B2 C1
C2
C3
C4
D1
D2
D3
E1
E2
E3
F1
F2
G
5 3
1
3
6
8
7
6
6
5
8
3
3
3 8
4
2
2
2
1
3
3
3
5
5
2
6
6
4
3
1
2
3 4
5
6
7
8
9
10
11
12
13
14
15
16
5 3
1
3
6
8
7
6
6
5
8
3
3
3 8
4
2
2
2
1
3
3
3
5
5
2
6
6
4
3
解:
基本思路:
第一步:确定决策变量及其约束条件。
第二步:建立优化模型。
第三步:确定编码方法。
第四步:确定解码方法。
第五步:确定个体评价方法。
第六步:设计遗传算子。
选择运算使用比例选择算子;
交叉运算使用单点交叉算子;
变异运算使用基本位变异算子。
第七步:确定遗传算法的运行参数。
程序:
% n ---- 种群规模
% ger ---- 迭代次数
% pc ---- 交叉概率
% pm ---- 变异概率
% v ---- 初始种群(规模为n)
% f ---- 目标函数值
% fit ---- 适应度向量
% vx ---- 最优适应度值向量
% vmfit ---- 平均适应度值向量
clear all;
close all;
clc;
tic;
% 生成初始种群
%power=[0 5 3 100 100 100 100 100;
% 100 0 100 1 3 6 100 100;
% 100 100 0 100 8 7 6 100;
% 100 100 100 0 100 100 100 8;
% 100 100 100 100 0 100 100 5;
% 100 100 100 100 100 0 100 3;
% 100 100 100 100 100 100 0 3;
% 100 100 100 100 100 100 100 0];
power=[0 5 3 100 100 100 100 100 100 100 100 100 100 100 100 100; 100 0 100 1 3 6 100 100 100 100 100 100 100 100 100 100;
100 100 0 100 8 7 6 100 100 100 100 100 100 100 100 100;
100 100 100 0 100 100 100 6 8 100 100 100 100 100 100 100;
100 100 100 100 0 100 100 3 5 100 100 100 100 100 100 100;
100 100 100 100 100 0 100 100 3 3 100 100 100 100 100 100;
100 100 100 100 100 100 0 100 8 4 100 100 100 100 100 100;
100 100 100 100 100 100 100 0 100 100 2 2 100 100 100 100;
100 100 100 100 100 100 100 100 0 100 100 1 2 100 100 100;
100 100 100 100 100 100 100 100 100 0 100 3 3 100 100 100;
100 100 100 100 100 100 100 100 100 100 0 100 100 3 5 100;
100 100 100 100 100 100 100 100 100 100 100 0 100 5 2 100;
100 100 100 100 100 100 100 100 100 100 100 100 0 6 6 100;
100 100 100 100 100 100 100 100 100 100 100 100 100 0 100 4;
100 100 100 100 100 100 100 100 100 100 100 100 100 100 0 3;
100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 0]; [PM PN]=size(power);
n=80;
ger=200;
pc=0.7;
pm=0.02;
% 生成初始种群
v=init_population(n,PN);
v(:,1)=1;
v(:,PN)=1;
[N,L]=size(v);
disp(sprintf('Number of generations:%d',ger));
disp(sprintf('Population size:%d',N));
disp(sprintf('Crossover probability:%.3f',pc));
disp(sprintf('Mutation probability:%.3f',pm));
% 计算适应度,并画出图形
fit=short_road_fun(v,power);
figure(1);
grid on;
hold on;
plot(fit,'k*');
title('(a)染色体的初始位置');
xlabel('x');
ylabel('f(x)');
% 初始化
vmfit=[];
it=1;
vx=[];
%C=[];
% 开始进化
while it<=ger
%Reproduction(Bi-classist Selection)
vtemp=short_road_roulette(v,fit);
%Crossover
v=short_road_crossover(vtemp,pc);
%Mutation
M=rand(N,L)<=pm;
%M(1,:)=zeros(1,L);
v=v-2.*(v.*M)+M;
v(:,1)=1;
v(:,end)=1;
%Results
fit=short_road_fun(v,power);
[sol,indb]=min(fit);
v(1,:)=v(indb,:);
media=mean(fit);
vx=[vx sol];
vmfit=[vmfit media];
it=it+1;
end
%%%% 最后结果
disp(sprintf('\n')); %空一行
% 显示最优解及最优值
disp(sprintf('Shortroad is %s',num2str(find(v(indb,:))))); disp(sprintf('Mininum is %d',sol));
v(indb,:)
基于新的混合遗传算法的订单生产工序顺序相关的流水车 间调度问题研究 A novel hybrid genetic algorithm to solve the make-to-order sequence-dependent flow-shop scheduling problem Mohammad Mirabi ?S. M. T. Fatemi Ghomi ?F. Jolai 2013年5月29号收到该文献,2014年3月18号录取,2014年4月9日出版.作者(2014).这篇文章在开放存取的https://www.doczj.com/doc/23929156.html, 网站发表 摘要流水车间调度问题(FSP)用于处理m台机器n个工序的流水作业。尽管FSP是典 型的NP-hard问题,依然没有有效的算法以找到这个问题的最优解。为了减少库存,延迟和安装成本,在工作时间一定,序列相关的每台机器上解决流水车间调度排序问题,在这提出了一种有三个遗传算子的新型混合遗传算法(HGA)。该算法应用一种改进的方法来生成初始种群,并使用一种应用迭代交换过程改进初始解的改进启发式算法。我们认为订单式生产方式,工序间隔时间是基于最大安装成本的禁忌搜索算法的解。此外,与最近开发的启发式算法通过计算实验结果比较表明,该算法在解\的精度和效率方面表现出非常强的竞争力。 关键词:混合遗传算法流水作业调度序列相关 引言 流车间调度问题(FSP)作为在制造业研究的主要问题已经近七十年。在一个有M台机器的流水作业车间中有m个工位,每个工序又有一台或几台机器。此外,有n个工件在m个工位上依次加工。在经典的流水作业问题里,每个工位都有一台机器,这一领域的研究吸引了最多的人次。FSP的两个主要子问题是序列独立时间设置(SIST)和顺序相关时间设置(SDST)。SDST流水作业问题更具有现实意义,但是吸引的注意力却少得多,特别是2000年以前(Allahverdi等,2008) 在流水车间调度问题的目标是找到一个序列的机器加工的作业,以便一个给定的标准进行了优化。这里有n个工件在每台机器上操作的可能的顺序,以及(N!)*M个的可能处理顺序。流水作业调度的研究通常只参加置换序列,其中操作的处理顺序是所有机器。在这里,我们也采用这种限制。 最小化所有最大完工时间作业(成为完工期并通过的Cmax表示)是公知的,也是在文献M. Mirabi (&) Group of Industrial Engineering, Ayatollah Haeri University of Meybod, P.O. Box 89619-55133, Meybod, Iran e-mail: M.Mirabi@https://www.doczj.com/doc/23929156.html, S. M. T. Fatemi Ghomi Department of Industrial Engineering, Amirkabir University of Technology, P.O. Box 15916-34311, Tehran, Iran e-mail: Fatemi@aut.ac.ir F. Jolai Department of Industrial Engineering, College of Engineering, University of Tehran, P.O. Box 14395-515, Tehran, Iran
MATLAB遗传算法 一:遗传算法简介: 遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。它是现代有关智能计算中的关键技术。 二:遗传算法的基本步骤 a)初始化:设置进化代数计数器t=0,设置最大进化代数T,随机生成M个个体作为初始群体P(0)。 b)个体评价:计算群体P(t)中各个个体的适应度。 c)选择运算:将选择算子作用于群体。选择的目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个 体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的。
d)交叉运算:将交叉算子作用于群体。遗传算法中起核心作用的就是交叉算子。 e)变异运算:将变异算子作用于群体。即是对群体中的个体串的某些基因座上的基因值作变动。 群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。 f)终止条件判断:若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。 三:matlab实现 例子:f(x)=10*sin(5x)+7*cos(4x)x∈[0,10]将变量域[0,10]离散化为二值域[0,1023],x=0+10*b/1023。 1.初始化 initpop.m function pop=initpop(popsize,chromlength) pop=round(rand(popsize,chromlength));%rand随机产生每个单元为0或者1 行数(种群数量)为popsize,列数为chromlength(个体所含基因数)的矩阵, 2.计算目标函数值 2.1将二进制数转化为十进制数(1) decodebinary.m %产生[2^n2^(n-1)...1]的行向量,然后求和,将二进制转化为十进制function pop2=decodebinary(pop) [px,py]=size(pop)%Pop的行和列数 for i=1:px pop2(i)=0 for j=1:py pop2(i)=pop2(i)+2.^(py-j)*pop(i,j) end end 2.2将二进制编码转化为十进制数(2) Decodechrom.m %函数的功能是将染色体(或二进制编码)转换为十进制,参数spoint表示待解码的二进制串的
机器学习大作业Revised on November 25, 2020
题目:机器学习 授课老师:韩红 基于BP 神经网络的非线性函数拟合 摘要:BP(Back Propagation)神经网络是 1986年由 Rumelhart和 McCelland 提出的,它是一种误差按反向传播的多层前馈网络,是目前应用最广泛的神经网络模型之一。 BP神经网络具有非常强的非线性映射能力,能以任意精度逼近任意连续函数,因此在人工智能的许多领域都得到了广泛的应用。 通常,BP算法是通过一些学习规则来调整神经元之间的连接权值,在学习过程中,学习规则以及网络的拓扑结构不变。然而一个神经网络的信息处理功能不仅取决于神经元之间的连接强度,而且与网络的拓扑结构(神经元的连接方式)、神经元的输入输出特性和神经元的阈值有关,因而神经网络模型要加强自身的适应和学习能力,应该知道如何合理地自组织网络的拓扑结构,知道改变神经元的激活特性以及在必要时调整网络的学习参数等。 1 BP神经网络概述 BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理, 直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出, 则转入反向传播,根据预测误差调整网络权值和阈值,从而使B P神经网络预测输出不断逼近期望输出。BP神经网络的拓扑结构如图 图1中, X1, X2, …, X n是BP神经网络的输入值, Y1, Y2, …, Y m是BP神经网络的预测值,ωij和ωjk为BP神经网络权值。从图2可以看出, BP神经网络可以看成一个非线性函数, 网络输入值和预测值分别为该函数的自变量和因变量。当输入节
本科生毕业设计(论文) 论文题目:基于遗传算法的PID参数优化
毕业设计(论文)原创性声明和使用授权说明 原创性声明 本人郑重承诺:所呈交的毕业设计(论文),是我个人在指导教师的指导下进行的研究工作及取得的成果。尽我所知,除文中特别加以标注和致谢的地方外,不包含其他人或组织已经发表或公布过的研究成果,也不包含我为获得及其它教育机构的学位或学历而使用过的材料。对本研究提供过帮助和做出过贡献的个人或集体,均已在文中作了明确的说明并表示了谢意。 作者签名:日期: 指导教师签名:日期: 使用授权说明 本人完全了解大学关于收集、保存、使用毕业设计(论文)的规定,即:按照学校要求提交毕业设计(论文)的印刷本和电子版本;学校有权保存毕业设计(论文)的印刷本和电子版,并提供目录检索与阅览服务;学校可以采用影印、缩印、数字化或其它复制手段保存论文;在不以赢利为目的前提下,学校可以公布论文的部分或全部内容。 作者签名:日期:
学位论文原创性声明 本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品。对本文的研究做出重要贡献的个人和集体,均已在文中以明确方式标明。本人完全意识到本声明的法律后果由本人承担。 作者签名:日期:年月日 学位论文版权使用授权书 本学位论文作者完全了解学校有关保留、使用学位论文的规定,同意学校保留并向国家有关部门或机构送交论文的复印件和电子版,允许论文被查阅和借阅。本人授权大学可以将本学位论文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或扫描等复制手段保存和汇编本学位论文。 涉密论文按学校规定处理。 作者签名:日期:年月日 导师签名:日期:年月日
作业 土规1101班刘迈克2011306200521 求下面加权有向图中从A到G的最短路径。 A B1 B2 C1 C2 C3 C4 D1 D2 D3 E1 E2 E3 F1 F2 G 5 3 1 3 6 8 7 6 6 5 8 3 3 3 8 4 2 2 2 1 3 3 3 5 5 2 6 6 4 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 5 3 1 3 6 8 7 6 6 5 8 3 3 3 8 4 2 2 2 1 3 3 3 5 5 2 6 6 4 3
解: 基本思路: 第一步:确定决策变量及其约束条件。 第二步:建立优化模型。 第三步:确定编码方法。 第四步:确定解码方法。 第五步:确定个体评价方法。 第六步:设计遗传算子。 选择运算使用比例选择算子; 交叉运算使用单点交叉算子; 变异运算使用基本位变异算子。 第七步:确定遗传算法的运行参数。 程序: % n ---- 种群规模 % ger ---- 迭代次数 % pc ---- 交叉概率 % pm ---- 变异概率 % v ---- 初始种群(规模为n) % f ---- 目标函数值 % fit ---- 适应度向量 % vx ---- 最优适应度值向量 % vmfit ---- 平均适应度值向量 clear all; close all; clc; tic; % 生成初始种群 %power=[0 5 3 100 100 100 100 100; % 100 0 100 1 3 6 100 100; % 100 100 0 100 8 7 6 100; % 100 100 100 0 100 100 100 8; % 100 100 100 100 0 100 100 5; % 100 100 100 100 100 0 100 3; % 100 100 100 100 100 100 0 3; % 100 100 100 100 100 100 100 0]; power=[0 5 3 100 100 100 100 100 100 100 100 100 100 100 100 100; 100 0 100 1 3 6 100 100 100 100 100 100 100 100 100 100; 100 100 0 100 8 7 6 100 100 100 100 100 100 100 100 100;
网络教育学院 《数据挖掘》课程大作业 题目:题目一:Knn算法原理以及python实现 姓名: XXX 报名编号: XXX 学习中心:奥鹏XXX 层次:专升本 专业:计算机科学与技术 第一大题:讲述自己在完成大作业过程中遇到的困难,解决问题的思路,以及相关感想,或者对这个项目的认识,或者对Python与数据挖掘的认识等等,300-500字。 答: 数据挖掘是指从大量的数据中通过一些算法寻找隐藏于其中重要实用信息的过程。这些算法包括神经网络法、决策树法、遗传算法、粗糙集法、模糊集法、关联规则法等。在商务管理,股市分析,公司重要信息决策,以及科学研究方面都有十分重要的意义。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术,从大量数据中寻找其肉眼难以发现的规律,和大数据联系密切。如今,数据挖掘已经应用在很多行业里,对人们的生产生活以及未来大数据时代起到了重要影响。
第二大题:完成下面一项大作业题目。 2019秋《数据挖掘》课程大作业 注意:从以下5个题目中任选其一作答。 题目一:Knn算法原理以及python实现 要求:文档用使用word撰写即可。 主要内容必须包括: (1)算法介绍。 (2)算法流程。 (3)python实现算法以及预测。 (4)整个word文件名为 [姓名奥鹏卡号学习中心](如 戴卫东101410013979浙江台州奥鹏学习中心[1]VIP ) 答: KNN算法介绍 KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。若K=1,新数据被简单分配给其近邻的类。 KNN算法实现过程 (1)选择一种距离计算方式, 通过数据所有的特征计算新数据与
主程序:chap5_2.m %GA(Generic Algorithm) Program to optimize PID Parameters clear all; close all; global rin yout timef Size=30; CodeL=3; MinX(1)=zeros(1); MaxX(1)=20*ones(1); MinX(2)=zeros(1); MaxX(2)=1.0*ones(1); MinX(3)=zeros(1); MaxX(3)=1.0*ones(1); Kpid(:,1)=MinX(1)+(MaxX(1)-MinX(1))*rand(Size,1); Kpid(:,2)=MinX(2)+(MaxX(2)-MinX(2))*rand(Size,1); Kpid(:,3)=MinX(3)+(MaxX(3)-MinX(3))*rand(Size,1); G=100; BsJ=0; %*************** Start Running *************** for kg=1:1:G time(kg)=kg; %****** Step 1 : Evaluate BestJ ****** for i=1:1:Size Kpidi=Kpid(i,:); [Kpidi,BsJ]=chap5_2f(Kpidi,BsJ); BsJi(i)=BsJ; end [OderJi,IndexJi]=sort(BsJi); BestJ(kg)=OderJi(1); BJ=BestJ(kg); Ji=BsJi+1e-10; %Avoiding deviding zero fi=1./Ji; % Cm=max(Ji);
机器学习大作业 题目机器学习大报告 学院电子工程学院 专业 学生姓名 学号
目录 第一章机器学习的基本理论及算法 (3) 1.1机器学习的基本理论 (3) 1.1.1 机器学习的概念 (3) 1.1.2 机器学习的发展历程 (3) 1.1.3 机器学习的模型 (4) 1.2机器学习主要算法 (5) 1.2.1 决策树算法 (5) 1.2.2 人工神经网络 (6) 1.2.3贝叶斯学习算法 (7) 1.2.4 遗传算法 (8) 1.2.5 支持向量机 (9) 第二章支持向量机(SVM)原理 (11) 2.1 SVM的产生与发展 (11) 2.2 统计学习理论基础 (12) 2.3 SVM原理 (12) 2.3.1.最优分类面和广义最优分类面 (13) 2.3.2 SVM的非线性映射 (16) 2.3.3.核函数 (17) 第三章支持向量机的应用研究现状 (19) 3.1 应用概述 (19) 3.2支持向量机的应用 (19) 3.2.1 人脸检测、验证和识别 (19) 3.2.2说话人/语音识别 (20) 3.2.3 文字/手写体识别 (20) 3.2.4 图像处理 (20) 3.2.5 其他应用研究 (21) 第四章基于SVM的实例及仿真结果 (23) 4.1 16棋盘格数据分类 (23) 4.2 UCI中iris数据分类 (25)
第一章机器学习的基本理论及算法 1.1机器学习的基本理论 1.1.1 机器学习的概念 机器学习是人工智能的一个分支,是现代计算机技术研究一个重点也是热点问题。顾名思义,机器学习就是计算机模仿人类获取知识的模式,通过建立相应的模型,对外界输入通过记忆"归纳"推理等等方式,获得有效的信息和经验总结,进而不断的自我完善,提高系统的功能。目前,机器学习的定义尚不统一,不同专业背景的学者出于不同的立场,对于机器学习的看法是不同的。下面主要介绍两位机器学习专业研究者赋予机器学习的定义。兰利(https://www.doczj.com/doc/23929156.html,ngley)认为:“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。米切尔(T.M.Mitchell)在其著作《机器学习》中谈到“机器学习”关注的问题是“计算机程序如何随着经验积累自动提高自身的性能”,也就是主要指的是归纳学习,另外“分析学习和增强学习也是学习的一个不可或缺组成部分”。两位学者的观点类似,都把机器学习看成是计算机或人工智能的一个分支学科,都强调的是归纳学习算法。 机器学习在人工智能领域中是一个相对比较活跃的研究领域,其研究目的就是要促进机器像人样可以源源不断获取外界的知识,建立相关学习的理论,构建学习系统,并将这些发明应用于各个领域。 1.1.2 机器学习的发展历程 机器学习(machine learning)是继专家系统之后人工智能应用的又一重要研究领域,也是人工智能和神经计算的核心研究课题之一。作为人工智能研究的一个新崛起的分支,机器学习的发展历程大至可分为如下几个时期: (1)热烈时期:20 世纪50 年代的神经模拟和决策理论技术,学习系统在运行时很少具有结构或知识。主要是建造神经网络和自组织学习系统, 学习表现为阈值逻辑单元传送信号的反馈调整。 (2)冷静时期:20 世纪60 年代早期开始研究面向概念的学习, 即符号学习。
遗传算法在调节控制系统参数中的应用 【摘要】自动化控制系统多采用PID 控制器来调节系统稳定性和动态性,PID 的 Kp,Ki,Kd 参数需要合理选择方能达到目标。遗传算法是一种模拟生物进化寻求最优解的有效算法,本文通过利用GAbx 工具箱实现对控制电机的PID 进行参数优化,利用matlab 的仿真功能可以观察控制效果。 1. 直流伺服电机模型 1.1物理模型 图1 直流伺服电机的物理模型 αu ---电枢输入电压(V ) a R ---电枢电阻(Ω) S L ---电枢电感(H ) q u ---感应电动势(V ) g T ---电机电磁转矩(N m ?) J---转动惯量(2m kg ?) B---粘性阻尼系数(s m N ??) g i ---流过电枢的电流(A ) θ---电机输出的转角(rad ) 1.2传递函数 利用基尔霍夫定律和牛顿第二定律得出电机基本方程并进行拉布拉斯变换 ) ()()()()()()()()()()(2s s K s U K s I s T s Bs s Js s T s I s L R s I s U s U e q t a g g a a a a q a θθθ?=?=?+?=?+?=- 式中:t K 为电机的转动常数(m N ?)A ;e K 为感应电动势常数(s V ?)rad
图2 直流伺服电机模型方框图 消去中间变量得系统的开环传递函数: s K K B Js R s L K s U s s G C t a d t a ]))([() () ()(+++= = θ 系统参数如下:s m uN B m mg J ??=?=51.3,23.32 A m N K K uH L R e t a a )(03.0,75.2,4?===Ω= 2. PID 校正 图3 PID 校正 s K s K K s G d i p c ++ =)( Kp,Ki,Kd 为比例,积分,微分系数 令Kp=15、Ki=0.8 、Kd=0.6 M 文件:J=3.23E-6; B=3.51E-6; Ra=4; La=2.75E-6; Kt=0.03; num= Kt; den=[(J*La) ((J*Ra)+(La*B)) ((B*Ra)+Kt*Kt) 0]; t=0:0.001:0.2; step(num,den,t); Kp=15; Ki=0.8; Kd=0.6; numcf=[Kd Kp Ki]; dencf=[1 0]; numf=conv(numcf,num); denf=conv(dencf,den); [numc,denc]=cloop(numf,denf); t=0:0.001:0.04; step(numc,denc,t); matlab 进行仿真,我们可以看出不恰当的PID 参数并不能使系统达到控制系统的要求,
第一章 1.3 什么是人工智能?它的研究目标是什么? 人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 研究目标:人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。 1.7 人工智能有哪几个主要学派?各自的特点是什么? 主要学派:符号主义,联结主义和行为主义。 1.符号主义:认为人类智能的基本单元是符号,认识过程就是符号表示下的符号计算,从 而思维就是符号计算; 2.联结主义:认为人类智能的基本单元是神经元,认识过程是由神经元构成的网络的信息 传递,这种传递是并行分布进行的。 3.行为主义:认为,人工智能起源于控制论,提出智能取决于感知和行动,取决于对外界 复杂环境的适应,它不需要只是,不需要表示,不需要推理。 1.8 人工智能有哪些主要研究和应用领域?其中有哪些是新的研究热点? 1.研究领域:问题求解,逻辑推理与定理证明,自然语言理解,自动程序设计,专家系 统,机器学习,神经网络,机器人学,数据挖掘与知识发现,人工生命,系统与语言工具。 2.研究热点:专家系统,机器学习,神经网络,分布式人工智能与Agent,数据挖掘与 知识发现。 第二章 2.8 用谓词逻辑知识表示方法表示如下知识: (1)有人喜欢梅花,有人喜欢菊花,有人既喜欢梅花又喜欢菊花。 三步走:定义谓词,定义个体域,谓词表示 定义谓词 P(x):x是人 L(x,y):x喜欢y y的个体域:{梅花,菊花}。 将知识用谓词表示为: (?x)(P(x)→L(x, 梅花)∨L(x, 菊花)∨L(x, 梅花)∧L(x, 菊花)) (2) 不是每个计算机系的学生都喜欢在计算机上编程序。 定义谓词 S(x):x是计算机系学生
龙源期刊网 https://www.doczj.com/doc/23929156.html, 基于遗传算法的PID控制概述 作者:张亚飞 来源:《卷宗》2013年第08期 摘要:基于PID控制应用的广泛性,本文简要阐述了遗传算法理论的关键思想及其在PID 控制中的应用策略,并用Matlab软件对一个控制实例进行了仿真研究。 关键词:PID控制;遗传算法;Matlab仿真 0 引言 PID控制作为最早实用化的控制算法已有70多年历史,现在仍然是控制系统中应用最为 普遍的一种控制规律。它所涉及的算法和控制结构简单,实际经验以及理论分析都表明,这种控制规律对许多工业过程进行控制时,一般都能得到较为满意的控制效果。随着控制理论的 发展,尤其是人工智能研究的日趋成熟,许多先进的算法理论逐渐被应用到传统的PID控制中,并取得了更为优越的控制效果。本文就以传统PID控制和遗传算法理论为基础,简述了基于遗传算法整定的PID控制基本理论和方法。 1 PID控制 通过将偏差的比例(Proportional)、积分(Integral)、微分(Derivative)进行线性组合构成控制量,对被控对象进行控制,这种控制方法叫做PID控制。在自动控制发展的历程中,常规PID控制得到了广泛的应用,整个控制系统由常规PID控制器和被控对象组成,根据系统给定值r(t)与实际输出值y(t)存在的控制偏差e(t)=r(t)-y(t)组成控制规律。PID控制器将偏差e(t)的比例-积分-微分通过线性组合构成控制量,对被控对象进行控制。其基本控制规律为 式中,Kp为比例增益,Ti为积分时间常数,Td为微分时间常数,u(t)为控制量,e (t)为偏差。 2 遗传算法基本操作 遗传算法,简称GA(Genetic Algorithms),是由美国Michigan大学的Holland教授于上世纪六十年代率先提出的一种高效并行全局最优搜索方法。遗传算法是模拟达尔文生物进化论的自然选择和孟德尔遗传学机理的生物进化过程的计算模型,它将“优胜劣汰,适者生存”的生物进化理论引入优化参数形成的编码串联群体中,按所选择的适配值函数通过遗传中的复制、交叉和变异对种群个体进行筛选,并保留适配值高的种群个体,组成新的群体。新的群体既继承了上一代的种群信息,又包含有优于上一代的个体信息,这样周而复始,种群中个体的适应度不断提高,直到满足一定的特定条件而停止运算,从而得到最优解。
遗传、蚁群算法作业 1、利用遗传算法求出下面函数的极小值:z=2-exp[-(x2+y2)], x,y∈[-5,+5] 解: 第一步确定决策变量及其约束条件:x,y∈[-5,+5] 第二步建立优化模型:min z(x,y)=2-exp[-(x2+y2)] 第三步确定编码方法。用长度为50位的二进制编码串来表示决策变量x,y。第四步确定解码方法。解码时将50位长的二进制编码前25位转换为对应的十进制整数代码,记为x,后25位转换后记为y。 第五步确定个体评价方法。 第六步设计遗传算子。选择运算用比例选择算子,交叉运算使用单点交叉算子,变异运算使用基本位变异算子。 第七步确定遗传算法的运行参数。 实现代码: % n ---- 种群规模 % ger ---- 迭代次数 % pc ---- 交叉概率 % pm ---- 变异概率 % v ---- 初始种群(规模为n) % f ---- 目标函数值 % fit ---- 适应度向量 % vx ---- 最优适应度值向量 % vmfit ---- 平均适应度值向量 clear all; close all; clc; tic; n=30; ger=200; pc=0.65; pm=0.05; % 生成初始种群 v=init_population(n,50); [N,L]=size(v); disp(sprintf('Number of generations:%d',ger)); disp(sprintf('Population size:%d',N)); disp(sprintf('Crossover probability:%.3f',pc)); disp(sprintf('Mutation probability:%.3f',pm));
摘要:研究自动控制器参数整定问题,PID参数整定是自动控制领域研究的重要内容,系统参数选择决定控制的稳定性和快速性,也可保证系统的可靠性。传统的PID参数多采用试验加试凑的方式由人工进行优化,往往费时而且难以满足控制的实时要求。为了解决控制参数优化,改善系统性能,提出一种遗传算法的PID 参数整定策略。 在本文里,通过介绍了遗传算法的基本原理,并针对简单遗传算法在PID控制中存在的问题进行了分析,提出在不同情况下采用不同的变异概率的方法,并对其进行了实验仿真。结果表明,用遗传算法来整定PID参数,可以提高优化性能,对控制系统具有良好的控制精度、动态性能和鲁棒性。 关键词:PID控制器;遗传算法;整定PID 1 引言 传统的比例、积分、微分控制,即PID控制具有算法简单、鲁棒性好和可靠性高等优点,已经被广泛用于工业生产过程。但工程实际中,PID控制器的比例、积分和微分调节参数往往采用实验加试凑的方法由人工整定。这不仅需要熟练的技巧,往往还相当费时。更为重要的是,当被控对象特性发生变化,需要控制器参数作相应调整时,PID控制器没有自适应能力,只能依靠人工重新整定参数,由于经验缺乏,整定结果往往达不到最优值,难以满足实际控制的要求。考虑生产过程的连续性以及参数整定费事费力,这种整定实际很难进行。所以,人们从工业生产实际需要出发,基于常规PID控制器的基本原理,对其进行了各种各样的改进。近年来许多学者提出了基于各种智能算法的PID整定策略,如模糊PID,神经元网络PID等…,但这些先进算法都要求对被控对象有很多的先验知识,在实际应用中往往难于做到。随着计算技术的发展,遗传算法有了很大的发展。将遗传算法用于控制器参数整定,已成为遗传算法的重要应用之一。 本文介绍基于遗传算法的PID参数整定设计方法。这是一种寻求全局最优的控制器优化方法,且无需对目标函数微分,可提高参数优化效果,简化计算过程。仿真实例表明该方法与其他传统寻优方法相比,在优化效果上具有一定的优势。 2 遗传算法简介 2.1 遗传算法的基本原理 遗传算法是John H.Holland根据生物进化的模型提出的一种优化算法。自然选择学说是进化论的中心内容。根据进化论,生物的发展进化主要有三个原因:即遗传、变异和选择。遗传算法基于自然选择和基因遗传学原理的搜索方法,将“优胜劣汰,适者生存”的生物进化原理引入待优化参数形成的编码串群体中,按照一定的适应度函数及一系列遗传操作对各个体进行筛选,从而使适应度高的个体被保留下来,组成新的群体;新群体包含上一代的大量信息,并且引入了新的优于上一代的个体。这样周而复始,群体中各个体适应度不断提高,直至满足一定的极限条件。此时,群体中适应度最高的个体即为待优化问题的最优解。 遗传算法通过对参数空间编码并用随机选择作为工具来引导搜索过程朝着更高效的方向发展。正是由于遗传算法独特的工作原理,使它能够在复杂空间进行全局优化搜索,具有较强的鲁棒性。另外,遗传算法对于搜索空问,基本上不需要什么限制性的假设(如连续、可微及单峰等)。而其它优化算法,如解析法,往往只能得到局部最优解而非全局最优解,且需要目标函数连续光滑及可微;枚举
基于遗传优化算法对离散PID控制器参数的优化设计摘要 PID控制作为一种经典的控制方法,从诞生至今,历经数十年的发展和完善,因其优越的控制性能业已成为过程控制领域最为广泛的控制方法;PID控制器具有结构简单、适应性强、不依赖于被控对象的精确模型、鲁棒性较强等优点,其控制性能直接关系到生产过程的平稳高效运行,因此对PID控制器设计和参数整定问题的研究不但具有理论价值更具有很大的实践意义,遗传算法是一种借鉴生物界自然选择和自然遗传学机理上的迭代自适应概率性搜索算法。本论文主要应用遗传算法对PID调节器参数进行优化。 关键词:遗传优化算法PID控制器参数优化 1.前言 PID调节器是最早发展起来的控制策略之一,因为它所涉及的设计算法和控制结构都是简单的,并且十分适用于工程应用背景,此外PID控制方案并不要求精确的受控对象的数学模型,且采用PID控制的控制效果一般是比较令人满意的,所以在工业实际应用中,PID调节器是应用最为广泛的一种控制策略,也是历史最久、生命力最强的基本控制方式。调查结果表明: 在当今使用的控制方式中,PID型占84. 5% ,优化PID型占68%,现代控制型占有15%,手动控制型66%,人工智能(AI)型占0.6% 。如果把PID型和优化PID型二者加起来,则占90% 以上,这说明PID控制方式占绝大多数,如果把手动控制型再与上述两种加在一起,则占97.5% ,这说明古典控制占绝大多数。就连科学技术高度发达的日本,PID控制的使用率也高达84.5%。这是由于理论分析及实际运行经验已经证明了PID调节器对于相当多的工业过程能够起到较为满足的控制效果。它结构简单、适用面广、鲁棒性强、参数易于调整、在实际中容易被理解和实现、在长期应用中己积累了丰富的经验。特别在工业过程中,由于控制对象的精确数学模型难以建立,系统的参数又经常发生变化,运用现代控制理论分析综合要耗费很大的代价进行模型辨识,但往往不能达到预期的效果,所以不论常规调节仪表还是数
《人工智能及其应用大作业(一)》 题目:基本遗传算法及其在函数优化中的作用 学号: 姓名:
基本遗传算法及其在函数优化中的应用 摘要: 从遗传算法的编码、遗传算子等方面剖析了遗传算法求解无约束函数优化问题的一般步骤,并以一个实例说明遗传算法能有效地解决函数优化问题。本文利用基本遗传算法求解函数优化问题,选用f(x)=xsin(10πx)+2.0,取值范围在]2,1 [ 中,利用基本遗传算法求解两个函数的最优值,遗传算法每次100代,一共执行10次,根据运算结果分析得到最优解。 关键字:遗传算法选择交叉变异函数优化 1.前言 1.1基本概念 遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。遗传算法是一种群体型操作,该操作以群体中的所有个体为对象。选择(Selection)、交叉(Crossover)和变异(Mutation)是遗传算法的3个主要操作算子,它们构成了所谓的遗传操作(genetic operation),使遗传算法具有了其它传统方法所没有的特性。 1.2 遗传算法的特点 其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。 1.3遗传算法的应用 函数优化,组合优化,机器人智能控制,及组合图像处理和模式识别等。 2.基本遗传算法 2.1简单遗传算法的求解步骤 Step1:参数设置及种群初始化; Step2:适应度评价; Step3:选择操作; Step4:交叉操作; Step5:变异操作; Step6:终止条件判断,若未达到终止条件,则转到Step3; Step7:输出结果。 2.2停机准则
遗传算法与优化问题 一、问题背景与实验目的 遗传算法(Genetic Algorithm—GA),是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,它是由美国Michigan大学的J.Holland教授于1975年首先提出的。遗传算法作为一种新的全局优化搜索算法,以其简单通用、鲁棒性强、适于并行处理及应用范围广等显著特点,奠定了它作为21世纪关键智能计算之一的地位。 1.遗传算法的基本原理 遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程。它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体。这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代。后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程。群体的染色体都将逐渐适应环境,不断进化,最后收敛到一族最适应环境的类似个体,即得到问题最优的解。值得注意的一点是,现在的遗传算法是受生物进化论学说的启发提出的,这种学说对我们用计算机解决复杂问题很有用,而它本身是否完全正确并不重要(目前生物界对此学说尚有争议)。 (1)遗传算法中的生物遗传学概念 由于遗传算法是由进化论和遗传学机理而产生的直接搜索优化方法;故而在这个算法中要用到各种进化和遗传学的概念。 首先给出遗传学概念、遗传算法概念和相应的数学概念三者之间的对应关系。这些概念如下: 1个体——要处理的基本对象、结构,也就是可行解。 2群体——个体的集合,被选定的一组可行解。 3染色体——个体的表现形式,可行解的编码。 4基因——染色体中的元素编码中的元素。 5基因位——某一基因在染色体中的位置元素在编码中的位置。 6适应值——个体对于环境的适应程度,或在环境压力下的生存能力,可行解所对应的适应函数值。 7种群——被选定的一组染色体或个体根据入选概率定出的一组可行解。 8选择——从群体中选择优胜的个体,淘汰劣质个体的操作保留或复制适应值大的可行解,去掉小的可行解。 9交叉——一组染色体上对应基因段的交换,根据交叉原则产生的一组新解。 10交叉概率——染色体对应基因段交换的概率(可能性大小),闭区间[0,1]上的一个值,一般为0.65~0.90。 11变异——染色体水平上基因变化编码的某些元素被改变。 12变异概率——染色体上基因变化的概率(可能性大小),开区间(0,1)内的一个值, 一般为0.001~0.01。 13进化——适者生存个体进行优胜劣汰的进化,一代又一代地优化目标函数取到最大值,最优的可行解。 (2)遗传算法的步骤 遗传算法计算优化的操作过程就如同生物学上生物遗传进化的过程,主要有三个基本操作(或称为算子):选择(Selection)、交叉(Crossover)、变异(Mutation)。 遗传算法基本步骤主要是:先把问题的解表示成“染色体”,在算法中也就是以二进制编码的串,在执行遗传算法之前,给出一群“染色体”,也就是假设的可行解。然后,把这些假
智能控制大作业-遗传算法-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
智能控制与应用实验报告遗传算法控制器设计
一、 实验内容 考虑一个单连杆机器人控制系统,其可以描述为: 0.5sin()Mq mgl q y q τ +== 其中20.5M kgm =为杆的转动惯量,1m kg =为杆的质量,1l m =为杆长, 29.8/g m s =,q 为杆的角位置,q 为杆的角速度,q 为杆的角加速度, τ为系 统的控制输入。具体要求: 1.设计基于遗传算法的模糊控制器、神经网络控制器或PID 控制器(任选一)。 2.分析采用遗传算法前后的控制效果。 3.分析初始条件对寻优及对控制效果的影响。 4.分析系统在遗传算法作用下的抗干扰能力(加噪声干扰、加参数不确定)、抗非线性能力(加死区和饱和特性)、抗时滞的能力。 二、 对象模型建立 根据公式(1),令状态量 121 =,x q x x =得到系统状态方程为: 12121 0.5**sin() x x mgl x x M y x τ=-= = (1) 由此建立单连杆机器人的模型如下: function dy = robot(t, y, u) M = 0.5; m=1.0; l=1.0; g=9.8; dy = zeros(2,1); dy(1) = (u - 0.5*m*g*l*sin(y(2)))/M;
dy(2) = y(1); 三、 基于遗传算法的PID 控制器设计 仿真的采样时间为0.01s ,输入指令为阶跃信号。采用实数编码方式,算法中使用的样本为20个,交叉概率和变异概率分别为P c =0.8,P m =0.2,选择遗传进化代数为30代。PID 控制参数取值范围分别为:Kp 为[0,25],Ki 为[0,20] ,Kd 为[0,20]。 为获得满意的过渡过程动态特性,采用误差绝对值时间积分性能指标作为参数选择的最小目标函数。同时,为了防止控制能量过大,在目标函数中加入控制输入的平方项,得到最优指标为: 21230 =(()())u J e t u t dt t ωωω∞ ++?,式中,()e t 为系统误差,()u t 为控制器输 出,u t 为上升时间,123,,ωωω为权值。取1230.99,0.01, 2.5ωωω===。 遗传进化10代后,最优指标变化如图1所示,最优性能指标J= 51.9516,优化后的PID 参数为Kp= 18.0976,Ki= 16.8281,Kd= 4.6012。
题目: 利用遗传算法求shaffer ’s F6函数()()222222001.015.0sin 5.0),(y x y x y x f +?+-+- =的 最优解()100,100<<-y x 。 要求给出源代码,求出最优解和最优值,给出进化代数、种群规模、交叉率及变异率。 1 求解思路 在程序中将种群规模、进化代数、交叉率及变异率分别取为不同数值,发现计算结果将收敛到不同的极大点。该函数的根据下,x 和y 的取值可以得到无穷多个极大点。 首先需要建立一个文件在里面写上两个变量的最大值及最小值。即: -100 100 -100 100 在程序中取种群规模为50,进化代数为1500,交叉率为0.8,变异率为0.15,该函数的最优解为0=x ,0=y ,对应的最优值为1。实际上,对应于这个最优解,种群规模、进化代数、交叉率及变异率可以取多组不同数值。如:取种群规模为500,进化代数为1000,交叉率为0.8,变异率为0.15时仍可以得到这个最优解。 2程序的源代码 #include
#include