
第5章 参数估计 ●1. 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。 (1) 样本均值的抽样标准差x σ等于多少? (2) 在95%的置信水平下,允许误差是多少? 解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, (1)样本均值的抽样标准差 x σσ5=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 σ Z 6×0.7906=1.5496。 ●2.某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。 (3) 假定总体标准差为15元,求样本均值的抽样标准误差; (4) 在95%的置信水平下,求允许误差; (5) 如果样本均值为120元,求总体均值95%的置信区间。 解:(1)已假定总体标准差为σ=15元, 则样本均值的抽样标准误差为 x σσ15=2.1429 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 σ Z 6×2.1429=4.2000。 (3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96, 这时总体均值的置信区间为 α/2 x Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。 ●3.某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时): 3.3 3.1 6.2 5.8 2.3 4.1 5.4 4.5 3.2 4.4 2.0 5.4 2.6 6.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.7 1.4 1.2 2.9 3.5 2.4 0.5 3.6 2.5
种猪现实育种值的估测 摘要: 取杭州市种猪试验场2000 2002 年共1 443 头长白猪个体性能测定资料, 用4 种方法估测了90 kg 体重校正背膘厚估计上代亲本公猪的育种值, 其中用25 头以上后裔平均值与同期群体平均值之差的2 倍定义为现实育种值。结果表明: 现实育种值的数值和方向与后裔测定育种值十分一致, 与一次测定值的育种值差很大, 现实育种值的方向与BLUP 值比较一致。现实育种值不受表型值的影响, 是猪真正育种值的最佳估计值。估测青年公猪的育种值, 用BLUP 法比较好。 关键词: 猪; 育种值; 现实育种值 种猪个体育种值的估测一直受到人们的重视, 估测的方法很多, 其中根据后裔成绩来估测其结果最可靠。但传统的后裔测定因世代间隔较长, 参加测定的供选公猪数受到限制, 供测子女头数有限, 故在改良速度上仍受到限制[ 1] , 现在已很少采用, 逐渐改用农场个体性能测定, 测定站集中性能测定, 同胞测定等来进行选种。性能测定的对象是种畜本身, 依据测定结果( 表现型) 进行选择, 它不同于传统的后裔测定, 但测定对象是上代亲本的后裔, 因此用性能测定的资料可对上代亲本进行间接后裔测定, 也可计算亲本个体育种值。有关这方面的研究和报导极少, 我们用杭州市种猪试验场性能测定站, 2000 2002年个体性能测定的资料, 取90 kg 体重校正背膘厚性状, 对上一代亲本公猪进行育种值的再估测, 因为它用两个实测群体平均值之差的2 倍进行估计, 为区别于其它方法估计的育种值, 故称为现实育种值。 1. 1 材料 取自杭州市种猪试验场2000-2002 年后备猪个体性能测定记录共1 443 头, 测定体重25~90 kg 。公猪每栏6 头, 群养单饲, 计算饲料利用率,母猪每栏5~ 6 头, 群养群饲。测定期的饲料营养水平保持各年度一致。专人管理, 由技术员测取各项数据, 背膘厚用B 超在胸腰结合部距背中线4~ 6 cm 处测定, 不同年份, 不同性别间的膘厚没有显著差异, 因此资料未作校正, 该场用约束指数进行选种, 要求背膘厚保持原有水平不变, 重点选择生长速度。配种原则为在控制后代个体近交系数于10% 以下, 实行全群随机交配。 1. 2 分析性状及平均值的计算 分析性状为达90 kg 体重校正背膘厚( 以下简称校正背膘厚) 。为了解本性状的后裔平均数变化规律, 按亲本公猪随机抽取5 头后裔为一增量, 计算1 次平均值, 最后1 次增量, 当后裔不足5 头时舍弃。 1. 3 育种值估测方法 ( 1) 个体本身一次记录估计育种值, 在本文中为性能测定育种值, 公式为: x A = ( PX - u ?) h2 ( 1) 式中A^ X : 亲本个体x 校正背膘厚育种值; PX : 亲本个体x 在性能测定时校正背膘 厚; u ?: 同期全群本性状平均值; h2: 校正背膘厚的遗传力为0. 36[ 2] 。 ( 2) BLUP 法 应用MTDFREML 程序估计亲本公猪性能测定时校正背膘厚性状的育种值。数学模型为: ijk y =u + i H + i G + ijk a + ijk e ( 2)
浅谈动物的育种值估计 摘要: 估计育种值是种猪选育的主要依据,而育种值估计的准确性直接影响猪群的遗传进展。随着育种理论和实践的不断发展,育种值的估计方法也不断的发展和更新,近年来由于数理统计,计算机科学,计算数学等学科领域的迅速发展以及生物技术在动物育种中的应用,动物育种值估计的方法发生了很大的变化,在未来的猪育种工作中,依靠经典理论和先进的科学技术提高育种值的准确度,依然是今后育种工作的重点。 关键词:数量性状选择指数繁殖效果遗传素质 在家畜育种中,实施选择的首要条件是估计出育种值。根据数量遗传理论,个体育种值的大小是选种的定量性标准。因此准确可靠的群体遗传参数和个体育种值是育种实践的必要条件。随着育种理论和实践的不断发展,育种值的估计方法也不断的发展和更新。由于数理统计、计算机科学、计算数学等学科的迅速发展以及生物技术在动物育种中的应用,动物育种值估计的方法发生了很大的变化。在未来的育种工作中,依靠经典理论和先进的科学技术提高育种值估计的准确度,依然是今后育种工作的重点。 家畜育种中大多数重要的经济性状都是数量性状,例如,产蛋数、蛋重、产奶量、乳脂率、瘦肉率、增重速度、饲料转化率、剪毛量等等。数量性状的复杂性在于其受环境影响大,要使数量性状获得较为稳定的遗传,区别遗传效应和环境效应的工作就非常重要。在遗传关系上,基因效应中能稳定遗传给后代的只有加性效应部分,而显性效应和上位效应只存在于特定的基因组合中,不能稳定遗传。因此基因的加性效应部分(即育种值部分)是育种工作的重要内容。而且就数量性状而言,每一个性状涉及的基因数目之大、基因型组合之多且各基因效应之微小,要单独研究每一个基因的加性效应及每一基因组合的互作效应在目前技术水平上尚难办到,因此要采用统计学方法对这些基因效应作总体分析。近半个世纪以来,各类主要家畜品种的改良所取得的进展超过了人类数百年来的成就,其根本原因就在于指导家畜育种工作的数量遗传学理论体系的建立和完善,并且有效应用于家畜育种实践。近几十年家畜生产水平的提高,很大程度上应归功于遗传参数和育种值估计准确度的提高。 育种工作的主要目的是为了不断改进畜群的遗传素质,培育优质、高产、满足一定社会需求的品种或品系。在育种工作中仅仅注意个别种畜的优越特性或通过各种科学技术手段育出个别的“超级家畜”还远远不够,因为畜群平均数的少量提高都远远胜过个别个体的特别优越。如果畜群或整个品种的水平很低,少数几头优良种畜在整个畜群或品种中很快的就被冲淡了。当然无可否认个别“超级家畜”也可用来促进群体的改进。每一项育种方案的制定都必须以准确、可靠的群体遗传参数为前提条件,遗传参数在个体遗传评定、预测选择反应、最优化育种规划的设计等方面都具有广泛
区间估计参数说明 1、从变量窗口中认识各个变量的含义 2、在已编辑好的数据中按Analyze――Descriptive Statistics――Explore,在弹出的窗口中, 左边的上部是各个变量名,右边分为三个部分,第一个是因变量窗口,即Dependent框。 第二个是分组变量窗口,即Factor。比如我们将班上的学生体重做分析,即体重为因变量窗口,性别为分组变量窗口。第三个为选择标识变量,当我们要寻找奇异值,即数值相对较大或者较小的值时,需要对数据标上标签,通常为序号。则要使用该变量值标识各观测值。 3、左边的下部,是Display栏,它分为三个选项:both:输出图形以及描述统计量,此为 系统默认。Statistics:只输出描述统计量。Plots:只输出图形。左边的下部也有三个选项,首先看Statistics,弹出的对话框有四个复选框,第一个为Descriptives,选中它即要求输出基本描述统计量。选择此项将输出平均数、中位数、众数、标准误、方差、极值、峰度、偏度等等。在Confidence intervals for mean均值的置信区间。在参数中键入不同的置信区间,可以得到不同的区间范围。常用的有90%、95%、99%。M-estimators为集中趋势的最大似然比的稳健估计,此项不要求掌握。Outliers 要求输出五个最大、最小值。Percentiles 要求输出百分位数。其次是Plots框,它分为三个部分,第一个为Boxplot 选择框,它要求作出各组因变量的并列箱图。第一项是:因变量按因素水平分组,各组因变量生成并列箱图,可以比较不同水平上的分布情况;第二项是:所有因变量生成一个并列箱图,可在同一水平上比较各因变量值的分布。第二个部分是Descriptive,包括茎叶图和直方图两种,我们选择直方图。下面的Normality plots with tests复选项,输出正态概率与离散正态概率图。Spread vs level with levene test 栏是方差齐次检验结果,不要求掌握。Option按钮,展开后有三个选项,分别表示在分析过程中,剔除带有缺失值的观测量(Exclude cases listwies)在分析中剔除中,不仅剔除缺失值还剔除那些与缺失值有成对关系的观测值(Exclude case pairwise)。分组变量中的缺失值将被单独分为一组。输出频数表时也包括缺失值组,但将标定出分组变量的缺失值(Report values)。 Levene检验:检验两个样本的数据是否具有相等方差时,虽然可以采用多种检测方法,但是多数都是基于数据必须服从正态分布这一假设,否则就失去数据检验的意义。Levene检验则较少依赖于正态性的假设,因而,它是等方差性检验的特别有效的方法。 Spread-level(幅度-水平)检验:幅度-水平图,是指框图的高度与各变量的水平或均值之间的关系。 正态性检验: 1、图示法: 偏态图:可以描绘这些点偏离直线的实际偏差,这种偏离直线的偏差则构成了偏态图。如果样本来自正态总体,这些点应该分布在一条过原点的水平线上,且没有任何模式;如果有一个明显的模式,则意味着总体并非正态分布。 正态概率图:对于正态概率图,每个观察值与其来自正态分布中的期望值组成数据点,这些数据点多数应落在一条直线上。 2、显著性水平检验法:
第五章 抽样调查及参数估计 5.1 抽样与抽样分布 5.2 参数估计的基本方法 5.3 总体均值的区间估计 5.4 总体比例的区间估计 5.5 样本容量的确定 一、简答题 1.什么是抽样推断?用样本指标估计总体指标应该满足哪三个标准才能被认为是优良的估计? 2.什么是抽样误差,影响抽样误差的主要因素有哪些? 3.简述概率抽样的五种方式 二、填空题 1.抽样推断是在 随机抽样 的基础上,利用样本资料计算样本指标,并据以推算 总体数量 特征的一种统计分析方法 。 2.从全部总体单位中随机抽选样本单位的方法有两种,即 重复 抽样和 不重复 抽样。 3.常用的抽样组织形式有 简单随机抽样 、 类型抽样 、等距抽样、 整群抽样 等四种。 4.影响抽样误差大小的因素有总体各单位标志值的差异程度、 抽样单位数的多少 、 抽样方法 和抽样调查的组织形式 。 5.总体参数区间估计必须具备估计值、 概率保证程度或概率度 、 抽样极限误差 等三个要素。 6.从总体单位数为N 的总体中抽取容量为n 的样本,在重复抽样和不重复抽样条件下,可能的样本个数分别是______________和_____________。 7.简单随机_抽样是最基本的抽样组织方式,也是其他复杂抽样设计的基础。 8.影响样本容量的主要因素包括总体各单位标志变异程度_、__允许的极限误差Δ的大小、_抽样方法_、抽样方式、抽样推断的可靠程度F(t)的大小等。 三、选择题 1.抽样调查需要遵守的基本原则是( B )。 A .准确性原则 B .随机性原则 C .代表性原则 D .可靠性原则 2.抽样调查的主要目的是( A )。 A .用样本指标推断总体指标 B .用总体指标推断样本指标 C .弥补普查资料的不足 D .节约经费开支 3.抽样平均误差反映了样本指标与总体指标之间的( B )。 A .实际误差 B .实际误差的平均数 C .可能的误差范围 D .实际的误差范围 4.对某种连续生产的产品进行质量检验,要求每隔一小时抽出10分钟的产品进行检验,这种抽查方式是( D ) 。 A .简单随机抽样 B .类型抽样 C .等距抽样 D .整群抽样 5.在其他情况一定的情况下,样本单位数与抽样误差之间的关系是( B )。 A .样本单位数越多,抽样误差越大 B .样本单位数越多,抽样误差越小 C .样本单位数与抽样误差无关 D .抽样误差是样本单位数的10% 6.用简单随机重复抽样方法抽取样本单位,如果要使抽样平均误差降低50%,那么样本n n N B N =!()!n N N A N n =-
第五章参数估计和假设检验的Stata实现本章用到的Stata命令有 例5-1 随机抽取某地25名正常成年男子,测得其血红蛋白含量如下: 146 7 125 142 7 128 140 1 7 144 151 117 118 该样本的均数为137.32g/L,标准差为10.63g/L,求该地正常成年男子血红蛋白含量总体均数的95%可信区间。 数据格式为
计算95%可信区间的Stata命令为: 结果为 该地正常成年男子血红蛋白含量总体均数的95%可信区间为(132.93~141.71) 例5-2 某市2005年120名7岁男童的身高X=123.62(cm),标准差s=4.75(cm),计算该市7岁男童总体均数90%的可信区间。 在Stata中有即时命令可以直接计算仅给出均数和标准差时的可信区间。 结果为: 该市7岁男童总体均数90%的可信区间(122.90~124.34)。 例5-3 为研究铅暴露对儿童智商(IQ)的影响,某研究调查了78名铅暴露(其血铅水平≥40 g/100ml)的6岁儿童,测得其平均IQ为88.02,标准差为12.21;同时选择了78名铅非暴露的6岁儿童作为对照,测得其平均IQ为92.89,标准
差为13.34。试估计铅暴露的儿童智商IQ的平均水平与铅非暴露儿童相差多少,并估计两个人群IQ的总体均数之差的95%可信区间。 本题也可以应用Stata的即时命令: 结果: 差值为4.86,差值的可信区间为0.81~8.90。 例5-4 为研究肿瘤标志物癌胚抗原(CEA)对肺癌的灵敏度,随机抽取140例确诊为肺癌患者,用CEA进行检测,结果呈阳性反应者共62人,试估计肺癌人群中CEA的阳性率。 Stata即时命令为 结果为 肺癌人群中CEA的阳性率为44.28%,可信区间为35.90%~52.82%。 例5-5 某医生用A药物治疗幽门螺旋杆菌感染者10人,其中9人转阴,试估计该药物治疗幽门螺旋杆菌感染者人群的转阴率。 Stata即时命令为
实验五 个体育种值的估计 一、 实习目的 进一步掌握估计育种值的原理和方法。 二、 估计育种值的方法 今有亲代、本身、同胞、后裔四种记录资料,先用计算单项资料育种值的方法,依次计算出A1、A2、A3、A4四个育种值。但因四种资料在育种上的重要程度不同,因此四个育种值还要进行必要的加权,然后才能合并成复合育种值。确定加权值的条件是:(1)四个加权系数素相干;(2)四个系数之和为1;(3)为了计算方便,对四个系数只取一位小数。为此,这四个系数只能是0.1、0.2、0.3、0.4,于是复合育种值的简化公式就是: 4 3214.03.02.01.0?A A A A x A +++= (1) 为了计算出A1、A2、A3、A4,需要就用下列公式: ?? ? ? ??? +-=+-=+-=+-=P h P P A P h P P A P h P P A P h P P A 2 4442 3332 2222 111)()()()( (2) 由公式(1)和(2)可得: 4 3214.03.02.01.0?A A A A x A +++= =P h P P h P P h P P h P P +-+-+-+-2 442 332 222 11)(4.0)(3.0)(2.0)(1.0
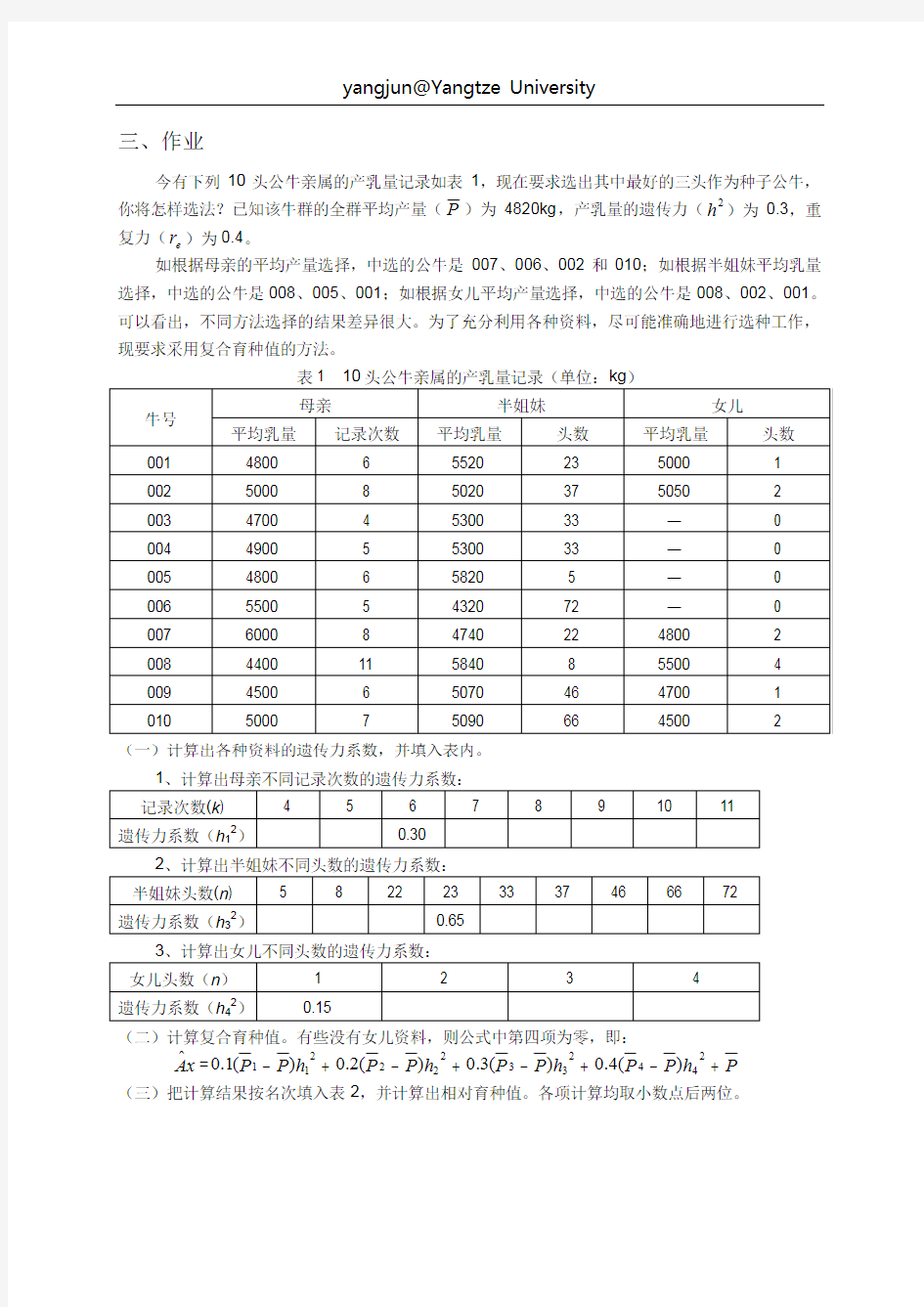
三、作业 今有下列10头公牛亲属的产乳量记录如表1,现在要求选出其中最好的三头作为种子公牛,你将怎样选法?已知该牛群的全群平均产量(P )为4820kg ,产乳量的遗传力(2 h )为0.3,重复力(e r )为0.4。 如根据母亲的平均产量选择,中选的公牛是007、006、002和010;如根据半姐妹平均乳量选择,中选的公牛是008、005、001;如根据女儿平均产量选择,中选的公牛是008、002、001。可以看出,不同方法选择的结果差异很大。为了充分利用各种资料,尽可能准确地进行选种工作,现要求采用复合育种值的方法。 (一)计算出各种资料的遗传力系数,并填入表内。 (二)计算复合育种值。有些没有女儿资料,则公式中第四项为零,即: x A ?=P h P P h P P h P P h P P +-+-+-+-24 4233222211)(4.0)(3.0)(2.0)(1.0 (三)把计算结果按名次填入表2,并计算出相对育种值。各项计算均取小数点后两位。
关与猪估计育种值相关的问题及解答 1、什么是估计育种值 估计育种值(EBV)是对动物遗传价值的估计。它表示的是父母的育种值。同时,估计育种值还是一个选择工具。某个性状具有最优秀的估计育种值,这个性状能够最大限度的遗传给后代。由于父母的基因只有一半传递给后代,因此预期的育种值是父母育种值的平均值。但是后代之间的育种值是差别很大的,主要取决于于后代继承了父母多少性状,导致后代的育种值比父母好或者比父母的差。由于这个原因,使得同窝兄妹之间的育种值差别很大。大量后代的平均遗传价值将等于他们父母的平均值。 2、加拿大遗传改良方案是如何计算估计育种值的 估计育种值是通过父亲和母亲以及亲属的性状获得的,或者从同期组中的公猪和母猪获得。这种方法称之为最佳线性无偏预测(BLUP),本方法将遗传性状、父母可用的信息、群体的遗传水平、遗传趋势、以及非遗传因素(如管理因素)都考虑进去。估计育种值不止依赖于父亲和母亲的性能,还依赖于相关相关动物的性状,例如祖代、同胞、后代。 3、估计育种值的表示 估计育种值的表示在性状的测定中有相同的单位。例如,背膘的估计育种值用毫米 需要注意的是,估计育种值的表示是相对的而不是绝对的(如:育种值允许在同期组内进行比较)。估计育种值表示的是在相同饲养环境下一个动物的后代比其它动物后代的性能更好或更差。例如,猪A的估计育种值为-10天,猪B的估计育种值为-6天,猪A比猪B好4天,它的后代的上市体重(100Kg)的平均日龄将比猪B缩短2天(它们估计育种值差值的一半)。可以看到,这里并没有说多少天可以到达上市体重,只是说在相同的饲养环境下猪A后代的生长速度会更快。 估计育种值作为选育的基础,反应的是不同品种中各种群的选育趋势。这个选育趋势包括了过去3年所有出生的猪和测定成绩。所有动物的估计育种值是在基础群的基础上进行表示的。例如,一个杜洛克公猪的估计育种值为-1mm和-6天,表示该头公猪预计比过去3年整个有测定记录的杜洛克种群的平均值要薄1mm和生长速度快6天。4、CCSI的估计育种值、场内的估计育种值和双亲的平均估计育种值的区别 除了CCSI的估计育种值,CCSI提供实时的场内估计育种值,而场内估计育种值是用猪双亲的最新的CCSI的估计育种计算的,并结合最近收集的体重和测定数据。场内估计