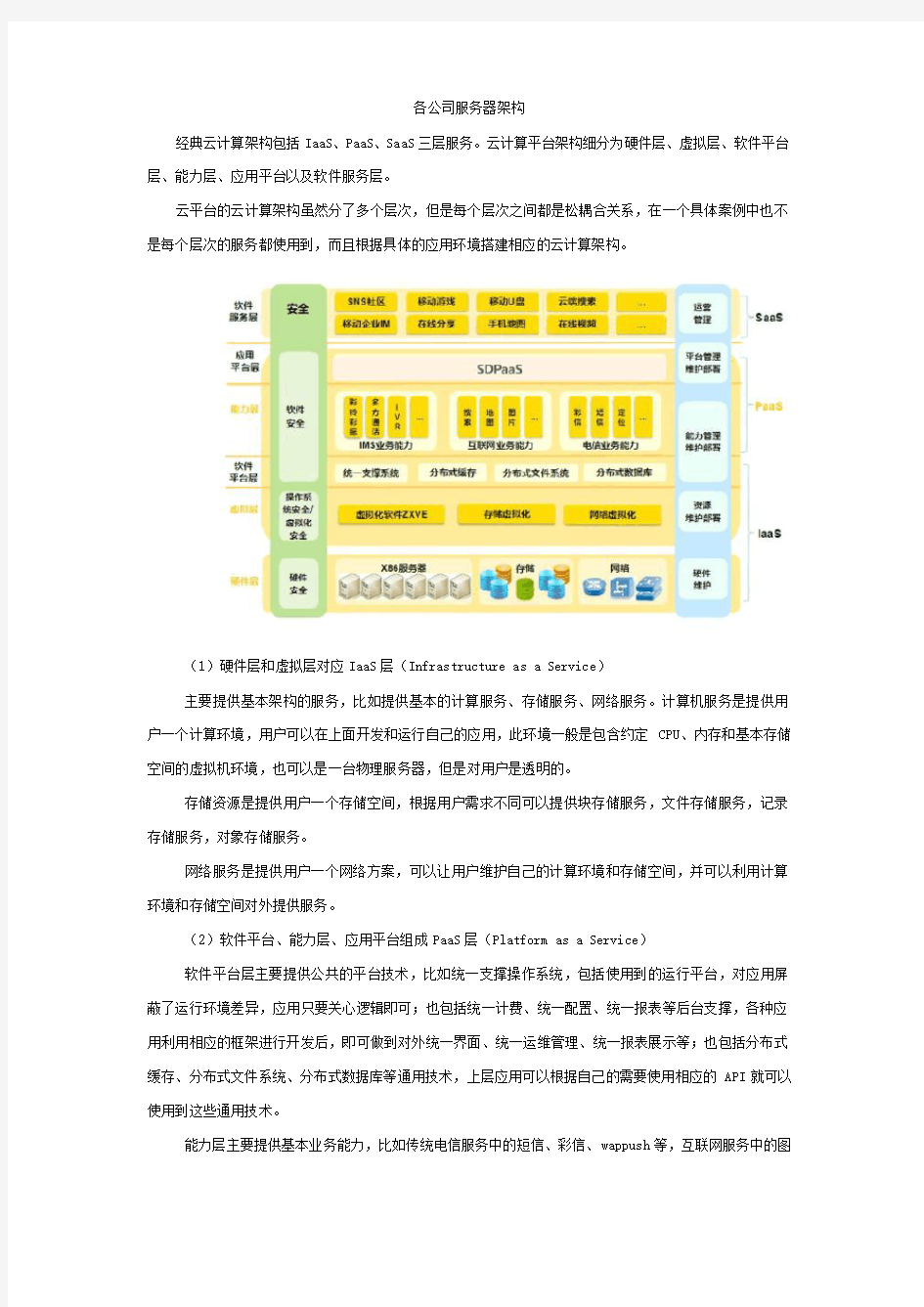

各公司服务器架构
经典云计算架构包括IaaS、PaaS、SaaS三层服务。云计算平台架构细分为硬件层、虚拟层、软件平台层、能力层、应用平台以及软件服务层。
云平台的云计算架构虽然分了多个层次,但是每个层次之间都是松耦合关系,在一个具体案例中也不是每个层次的服务都使用到,而且根据具体的应用环境搭建相应的云计算架构。
(1)硬件层和虚拟层对应IaaS层(Infrastructure as a Service)
主要提供基本架构的服务,比如提供基本的计算服务、存储服务、网络服务。计算机服务是提供用户一个计算环境,用户可以在上面开发和运行自己的应用,此环境一般是包含约定CPU、内存和基本存储空间的虚拟机环境,也可以是一台物理服务器,但是对用户是透明的。
存储资源是提供用户一个存储空间,根据用户需求不同可以提供块存储服务,文件存储服务,记录存储服务,对象存储服务。
网络服务是提供用户一个网络方案,可以让用户维护自己的计算环境和存储空间,并可以利用计算环境和存储空间对外提供服务。
(2)软件平台、能力层、应用平台组成PaaS层(Platform as a Service)
软件平台层主要提供公共的平台技术,比如统一支撑操作系统,包括使用到的运行平台,对应用屏蔽了运行环境差异,应用只要关心逻辑即可;也包括统一计费、统一配置、统一报表等后台支撑,各种应用利用相应的框架进行开发后,即可做到对外统一界面、统一运维管理、统一报表展示等;也包括分布式缓存、分布式文件系统、分布式数据库等通用技术,上层应用可以根据自己的需要使用相应的API就可以使用到这些通用技术。
能力层主要提供基本业务能力,比如传统电信服务中的短信、彩信、wappush等,互联网服务中的图
片、地图、天气预报等,随着IMS兴起,也提供IMS中的彩铃/彩像、IVR等能力。
(3)软件服务层对应SaaS层(Software as a Service )
软件服务层主要是对用户提供具体的服务,比如SNS社区、移动U盘、企业移动IM等。
一、Google的Google App Engine
Google App Engine是一款PaaS服务,它主要提供一个平台让用户在Google强大的基础设施上部署和运行应用程序,同时App Engine会根据应用所承受的负载来对应用所需的资源进行调整,并免去用户对应用和服务器等的维护工作,而且支持Java和Python这两种语言。
Google的云计算技术实际上是针对Google特定的网络应用程序而定制的。针对内部网络数据规模超大的特点,Google提出了一整套基于分布式并行集群方式的基础架构,利用软件的能力来处理集群中经常发生的节点失效问题。
从2003年开始,Google连续几年在计算机系统研究领域的最顶级会议与杂志上发表论文,揭示其内部的分布式数据处理方法,向外界展示其使用的云计算核心技术。从其近几年发表的论文来看,Google使用的云计算基础架构模式包括四个相互独立又紧密结合在一起的系统。包括Google建立在集群之上的文件系统Google File System,针对Google应用程序的特点提出的Map/Reduce编程模式,分布式的锁机制Chubby以及Google开发的模型简化的大规模分布式数据库BigTable。
Google File System 文件系统
为了满足Google迅速增长的数据处理需求,Google设计并实现了Google文件系统 (GFS,Google File System)。GFS与过去的分布式文件系统拥有许多相同的目标,例如性能、可伸缩性、可靠性以及可用性。然而,它的设计还受到Google应用负载和技术环境的影响。主要体现在以下四个方面:
1. 集群中的节点失效是一种常态,而不是一种异常。由于参与运算与处理的节点数目非常庞大,通常会使用上千个节点进行共同计算,因此,每时每刻总会有节点处在失效状态。需要通过软件程序模块,监视系统的动态运行状况,侦测错误,并且将容错以及自动恢复系统集成在系统中。
2. Google系统中的文件大小与通常文件系统中的文件大小概念不一样,文件大小通常以G字节计。另外文件系统中的文件含义与通常文件不同,一个大文件可能包含大量数目的通常意义上的小文件。所以,设计预期和参数,例如I/O操作和块尺寸都要重新考虑。
3. Google文件系统中的文件读写模式和传统的文件系统不同。在Google应用(如搜索)中对大部分文件的修改,不是覆盖原有数据,而是在文件尾追加新数据。对文件的随机写是几乎不存在的。对于这类巨大文件的访问模式,客户端对数据块缓存失去了意义,追加操作成为性能优化和原子性(把一个事务看做是一个程序。它要么被完整地执行,要么完全不执行)保证的焦点。
4. 文件系统的某些具体操作不再透明,而且需要应用程序的协助完成,应用程序和文件系统API的协同设计提高了整个系统的灵活性。例如,放松了对GFS一致性模型的要求,这样不用加重应用程序的负担,就大大简化了文件系统的设计。还引入了原子性的追加操作,这样多个客户端同时进行追加的时候,就不需要额外的同步操作了。
总之,GFS是为Google应用程序本身而设计的。据称,Google已经部署了许多GFS集群。有的集群拥有超过1000个存储节点,超过300T的硬盘空间,被不同机器上的数百个客户端连续不断地频繁访问着。
图1给出了Google File System的系统架构,一个GFS集群包含一个主服务器和多个块服务器,被多个客户端访问。文件被分割成固定尺寸的块。在每个块创建的时候,服务器分配给它一个不变的、全球惟一的64位块句柄对它进行标识。块服务器把块作为linux文件保存在本地硬盘上,并根据指定的块句柄和字节范围来读写块数据。为了保证可靠性,每个块都会复制到多个块服务器上,缺省保存三个备份。主服务器管理文件系统所有的元数据,包括名字空间、访问控制信息和文件到块的映射信息,以及块当前所在的位置。GFS客户端代码被嵌入到每个程序里,它实现了Google文件系统 API,帮助应用程序与主服务器和块服务器通信,对数据进行读写。客户端跟主服务器交互进行元数据操作,但是所有的数据操作的通信都是直接和块服务器进行的。客户端提供的访问接口类似于POSIX接口,但有一定的修改,并不完全兼容POSIX标准。通过服务器端和客户端的联合设计,Google File System能够针对它本身的应用获得最大的性能以及可用性效果。
Google文件系统(Google File System,GFS)是一个大型的分布式文件系统。它为Google云计算提供海量存储,并且与Chubby、MapReduce以及Bigtable等技术结合十分紧密,处于所有核心技术的底层。由于GFS并不是一个开源的系统,我们仅仅能从Google公布的技术文档来获得一点了解,而无法进行深入的研究。文献[1]是Google公布的关于GFS的最为详尽的技术文档,它从GFS产生的背景、特点、系统框架、性能测试等方面进行了详细的阐述。
当前主流分布式文件系统有RedHat的GFS[3](Global File System)、IBM的GPFS[4]、Sun的Lustre[5]等。这些系统通常用于高性能计算或大型数据中心,对硬件设施条件要求较高。以Lustre文件系统为例,它只对元数据管理器MDS提供容错解决方案,而对于具体的数据存储节点OST来说,则依赖其自身来解
决容错的问题。例如,Lustre推荐OST节点采用RAID技术或SAN存储区域网来容错,但由于Lustre自身不能提供数据存储的容错,一旦OST发生故障就无法恢复,因此对OST的稳定性就提出了相当高的要求,从而大大增加了存储的成本,而且成本会随着规模的扩大线性增长。
正如李开复所说的那样,创新固然重要,但有用的创新更重要。创新的价值,取决于一项创新在新颖、有用和可行性这三个方面的综合表现。Google GFS的新颖之处并不在于它采用了多么令人惊讶的技术,而在于它采用廉价的商用机器构建分布式文件系统,同时将GFS的设计与Google应用的特点紧密结合,并简化其实现,使之可行,最终达到创意新颖、有用、可行的完美组合。GFS使用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性问题,这样可以使得存储的成本成倍下降。由于GFS中服务器数目众多,在GFS中服务器死机是经常发生的事情,甚至都不应当将其视为异常现象,那么如何在频繁的故障中确保数据存储的安全、保证提供不间断的数据存储服务是GFS最核心的问题。GFS的精彩在于它采用了多种方法,从多个角度,使用不同的容错措施来确保整个系统的可靠性。
2.1.1 系统架构
GFS的系统架构如图2-1[1]所示。GFS将整个系统的节点分为三类角色:Client(客户端)、Master(主服务器)和Chunk Server(数据块服务器)。Client是GFS提供给应用程序的访问接口,它是一组专用接口,不遵守POSIX规范,以库文件的形式提供。应用程序直接调用这些库函数,并与该库链接在一起。Master是GFS的管理节点,在逻辑上只有一个,它保存系统的元数据,负责整个文件系统的管理,是GFS 文件系统中的“大脑”。Chunk Server负责具体的存储工作。数据以文件的形式存储在Chunk Server上,Chunk Server的个数可以有多个,它的数目直接决定了GFS的规模。GFS将文件按照固定大小进行分块,默认是64MB,每一块称为一个Chunk(数据块),每个Chunk都有一个对应的索引号(Index)。
图2-1 GFS体系结构
客户端在访问GFS时,首先访问Master节点,获取将要与之进行交互的Chunk Server信息,然后直接访问这些Chunk Server完成数据存取。GFS的这种设计方法实现了控制流和数据流的分离。Client与Master
之间只有控制流,而无数据流,这样就极大地降低了Master的负载,使之不成为系统性能的一个瓶颈。Client 与Chunk Server之间直接传输数据流,同时由于文件被分成多个Chunk进行分布式存储,Client可以同时
访问多个Chunk Server,从而使得整个系统的I/O高度并行,系统整体性能得到提高。
相对于传统的分布式文件系统,GFS针对Google应用的特点从多个方面进行了简化,从而在一定规模下达到成本、可靠性和性能的最佳平衡。具体来说,它具有以下几个特点。
1.采用中心服务器模式
GFS采用中心服务器模式来管理整个文件系统,可以大大简化设计,从而降低实现难度。Master管理了分布式文件系统中的所有元数据。文件划分为Chunk进行存储,对于Master来说,每个Chunk Server
只是一个存储空间。Client发起的所有操作都需要先通过Master才能执行。这样做有许多好处,增加新的Chunk Server是一件十分容易的事情,Chunk Server只需要注册到Master上即可,Chunk Server之间无任何关系。如果采用完全对等的、无中心的模式,那么如何将Chunk Server的更新信息通知到每一个Chunk Server,会是设计的一个难点,而这也将在一定程度上影响系统的扩展性。Master维护了一个统一的命名空间,同时掌握整个系统内Chunk Server的情况,据此可以实现整个系统范围内数据存储的负载均衡。由于只有一
个中心服务器,元数据的一致性问题自然解决。当然,中心服务器模式也带来一些固有的缺点,比如极易
成为整个系统的瓶颈等。GFS采用多种机制来避免Master成为系统性能和可靠性上的瓶颈,如尽量控制元数据的规模、对Master进行远程备份、控制信息和数据分流等。
2.不缓存数据
缓存(Cache)机制是提升文件系统性能的一个重要手段,通用文件系统为了提高性能,一般需要实现复杂的缓存机制。GFS文件系统根据应用的特点,没有实现缓存,这是从必要性和可行性两方面考虑的。从必要性上讲,客户端大部分是流式顺序读写,并不存在大量的重复读写,缓存这部分数据对系统整体性
能的提高作用不大;而对于Chunk Server,由于GFS的数据在Chunk Server上以文件的形式存储,如果对某块数据读取频繁,本地的文件系统自然会将其缓存。从可行性上讲,如何维护缓存与实际数据之间的一
致性是一个极其复杂的问题,在GFS中各个Chunk Server的稳定性都无法确保,加之网络等多种不确定因素,一致性问题尤为复杂。此外由于读取的数据量巨大,以当前的内存容量无法完全缓存。对于存储在Master 中的元数据,GFS采取了缓存策略,GFS中Client发起的所有操作都需要先经过Master。Master需要对其元数据进行频繁操作,为了提高操作的效率,Master的元数据都是直接保存在内存中进行操作。同时采用
相应的压缩机制降低元数据占用空间的大小,提高内存的利用率。
3.在用户态下实现
文件系统作为操作系统的重要组成部分,其实现通常位于操作系统底层。以Linux为例,无论是本地
文件系统如Ext3文件系统,还是分布式文件系统如Lustre等,都是在内核态实现的。在内核态实现文件系统,可以更好地和操作系统本身结合,向上提供兼容的POSIX接口。然而,GFS却选择在用户态下实现,主要基于以下考虑。
1)在用户态下实现,直接利用操作系统提供的POSIX编程接口就可以存取数据,无需了解操作系统
的内部实现机制和接口,从而降低了实现的难度,并提高了通用性。
2)POSIX接口提供的功能更为丰富,在实现过程中可以利用更多的特性,而不像内核编程那样受限。
3)用户态下有多种调试工具,而在内核态中调试相对比较困难。
4)用户态下,Master和Chunk Server都以进程的方式运行,单个进程不会影响到整个操作系统,从而可以对其进行充分优化。在内核态下,如果不能很好地掌握其特性,效率不但不会高,甚至还会影响到整个系统运行的稳定性。
5)用户态下,GFS和操作系统运行在不同的空间,两者耦合性降低,从而方便GFS自身和内核的单独升级。
4.只提供专用接口
通常的分布式文件系统一般都会提供一组与POSIX规范兼容的接口。其优点是应用程序可以通过操作系统的统一接口来透明地访问文件系统,而不需要重新编译程序。GFS在设计之初,是完全面向Google
的应用的,采用了专用的文件系统访问接口。接口以库文件的形式提供,应用程序与库文件一起编译,Google 应用程序在代码中通过调用这些库文件的API,完成对GFS文件系统的访问。采用专用接口有以下好处。 1)降低了实现的难度。通常与POSIX兼容的接口需要在操作系统内核一级实现,而GFS是在应用层实现的。
2)采用专用接口可以根据应用的特点对应用提供一些特殊支持,如支持多个文件并发追加的接口等。 3)专用接口直接和Client、Master、Chunk Server交互,减少了操作系统之间上下文的切换,降低了复杂度,提高了效率。
2.1.2 容错机制
1.Master容错
具体来说,Master上保存了GFS文件系统的三种元数据。
1)命名空间(Name Space),也就是整个文件系统的目录结构。
2)Chunk与文件名的映射表。
3)Chunk副本的位置信息,每一个Chunk默认有三个副本。
首先就单个Master来说,对于前两种元数据,GFS通过操作日志来提供容错功能。第三种元数据信息则直接保存在各个Chunk Server上,当Master启动或Chunk Server向Master注册时自动生成。因此当Master 发生故障时,在磁盘数据保存完好的情况下,可以迅速恢复以上元数据。为了防止Master彻底死机的情况,GFS还提供了Master远程的实时备份,这样在当前的GFS Master出现故障无法工作的时候,另外一台GFS Master可以迅速接替其工作。
2.Chunk Server容错
GFS采用副本的方式实现Chunk Server的容错。每一个Chunk有多个存储副本(默认为三个),分布存储在不同的Chunk Server上。副本的分布策略需要考虑多种因素,如网络的拓扑、机架的分布、磁盘的利用率等。对于每一个Chunk,必须将所有的副本全部写入成功,才视为成功写入。在其后的过程中,如
果相关的副本出现丢失或不可恢复等状况,Master会自动将该副本复制到其他Chunk Server,从而确保副本保持一定的个数。尽管一份数据需要存储三份,好像磁盘空间的利用率不高,但综合比较多种因素,加之磁盘的成本不断下降,采用副本无疑是最简单、最可靠、最有效,而且实现的难度也最小的一种方法。 GFS中的每一个文件被划分成多个Chunk,Chunk的默认大小是64MB,这是因为Google应用中处理的文件都比较大,以64MB为单位进行划分,是一个较为合理的选择。Chunk Server存储的是Chunk的副本,副本以文件的形式进行存储。每一个Chunk以Block为单位进行划分,大小为64KB,每一个Block
对应一个32bit的校验和。当读取一个Chunk副本时,Chunk Server会将读取的数据和校验和进行比较,如果不匹配,就会返回错误,从而使Client选择其他Chunk Server上的副本。
2.1.3 系统管理技术
严格意义上来说,GFS是一个分布式文件系统,包含从硬件到软件的整套解决方案。除了上面提到的GFS的一些关键技术外,还有相应的系统管理技术来支持整个GFS的应用,这些技术可能并不一定为GFS 所独有。
1.大规模集群安装技术
安装GFS的集群中通常有非常多的节点,文献[1]中最大的集群超过1000个节点,而现在的Google数据中心动辄有万台以上的机器在运行。因此迅速地安装、部署一个GFS的系统,以及迅速地进行节点的系统升级等,都需要相应的技术支撑。
2.故障检测技术
GFS是构建在不可靠的廉价计算机之上的文件系统,由于节点数目众多,故障发生十分频繁,如何在最短的时间内发现并确定发生故障的Chunk Server,需要相关的集群监控技术。
3.节点动态加入技术
当有新的Chunk Server加入时,如果需要事先安装好系统,那么系统扩展将是一件十分烦琐的事情。如果能够做到只需将裸机加入,就会自动获取系统并安装运行,那么将会大大减少GFS维护的工作量。
4.节能技术
有关数据表明,服务器的耗电成本大于当初的购买成本,因此Google采用了多种机制来降低服务器的能耗,例如对服务器主板进行修改,采用蓄电池代替昂贵的UPS(不间断电源系统),提高能量的利用率。Rich Miller 在一篇关于数据中心的博客文章中表示,这个设计让 Google 的 UPS 利用率达到99.9%,而一般数据中心只能达到92%~95%。
MapReduce分布式编程环境
为了让内部非分布式系统方向背景的员工能够有机会将应用程序建立在大规模的集群基础之上,Google还设计并实现了一套大规模数据处理的编程规范Map/Reduce系统。这样,非分布式专业的程序编写人员也能够为大规模的集群编写应用程序而不用去顾虑集群的可靠性、可扩展性等问题。应用程序编写人员只需要将精力放在应用程序本身,而关于集群的处理问题则交由平台来处理。
Map/Reduce通过"Map(映射)"和"Reduce(化简)"这样两个简单的概念来参加运算,用户只需要提供自己的Map函数以及Reduce函数就可以在集群上进行大规模的分布式数据处理。
据称,Google的文本索引方法,即搜索引擎的核心部分,已经通过Map Reduce的方法进行了改写,获得了更加清晰的程序架构。在Google内部,每天有上千个Map Reduce的应用程序在运行。
1、介绍
在过去的5年里,包括本文作者在内的Google的很多程序员,为了处理海量的原始数据,已经实现了数以百计的、专用的计算方法。这些计算方法用来处理大量的原始数据,比如,文档抓取(类似网络爬虫的程序)、Web请求日志等等;也为了计算处理各种类型的衍生数据,比如倒排索引、Web文档的图结构的各种表示形势、每台主机上网络爬虫抓取的页面数量的汇总、每天被请求的最多的查询的集合等等。大多数这样的数据处理运算在概念上很容易理解。然而由于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有将这些计算分布在成百上千的主机上。如何处理并行计算、如何分发数据、如何处理错误?所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理。
为了解决上述复杂的问题,我们设计一个新的抽象模型,使用这个抽象模型,我们只要表述我们想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装在了一个库里面。设计这个抽象模型的灵感来自Lisp和许多其他函数式语言的Map和Reduce的原语。我们意识到我们大多数的运算都包含这样的操作:在输入数据的―逻辑‖记录上应用Map操作得出一个中间key/value pair集合,然后在所有具有相同key值的value值上应用Reduce操作,从而达到合并中间的数据,得到一个想要的结果的目的。使用MapReduce模型,再结合用户实现的Map和Reduce函数,我们就可以非常容易的实现大规模并行化计算;通过MapReduce模型自带的―再次执行‖(re-execution)功能,也提供了初级的容灾实现方案。
这个工作(实现一个MapReduce框架模型)的主要贡献是通过简单的接口来实现自动的并行化和大规模的分布式计算,通过使用MapReduce模型接口实现在大量普通的PC机上高性能计算。
第二部分描述基本的编程模型和一些使用案例。第三部分描述了一个经过裁剪的、适合我们的基于集群的计算环境的MapReduce实现。第四部分描述我们认为在MapReduce编程模型中一些实用的技巧。第五部分对于各种不同的任务,测量我们MapReduce实现的性能。第六部分揭示了在Google内部如何使用MapReduce作为基础重写我们的索引系统产品,包括其它一些使用MapReduce的经验。第七部分讨论相关的和未来的工作。
2、编程模型
MapReduce编程模型的原理是:利用一个输入key/value pair集合来产生一个输出的key/value pair集合。MapReduce库的用户用两个函数表达这个计算:Map和Reduce。
用户自定义的Map函数接受一个输入的key/value pair值,然后产生一个中间key/value pair值的集合。MapReduce库把所有具有相同中间key值I的中间value值集合在一起后传递给reduce函数。
用户自定义的Reduce函数接受一个中间key的值I和相关的一个value值的集合。Reduce函数合并这些value值,形成一个较小的value值的集合。一般的,每次Reduce函数调用只产生0或1个输出value值。通常我们通过一个迭代器把中间value值提供给Reduce函数,这样我们就可以处理无法全部放入内存中的大量的value值的集合。
2.1、例子
例如,计算一个大的文档集合中每个单词出现的次数,下面是伪代码段:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, ―1″);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Map函数输出文档中的每个词、以及这个词的出现次数(在这个简单的例子里就是1)。Reduce函数把Map 函数产生的每一个特定的词的计数累加起来。
另外,用户编写代码,使用输入和输出文件的名字、可选的调节参数来完成一个符合MapReduce模型规范的对象,然后调用MapReduce函数,并把这个规范对象传递给它。用户的代码和MapReduce库链接在一起(用C++实现)。附录A包含了这个实例的全部程序代码。
2.2、类型
尽管在前面例子的伪代码中使用了以字符串表示的输入输出值,但是在概念上,用户定义的Map和Reduce 函数都有相关联的类型:
map(k1,v1) ->list(k2,v2)
reduce(k2,list(v2)) ->list(v2)
比如,输入的key和value值与输出的key和value值在类型上推导的域不同。此外,中间key和value 值与输出key和value值在类型上推导的域相同。
(译者注:原文中这个domain的含义不是很清楚,我参考Hadoop、KFS等实现,map和reduce都使用了泛型,因此,我把domain翻译成类型推导的域)。
我们的C++中使用字符串类型作为用户自定义函数的输入输出,用户在自己的代码中对字符串进行适当的类型转换。
2.3、更多的例子
这里还有一些有趣的简单例子,可以很容易的使用MapReduce模型来表示:
?分布式的Grep:Map函数输出匹配某个模式的一行,Reduce函数是一个恒等函数,即把中间数据复制到输出。
?计算URL访问频率:Map函数处理日志中web页面请求的记录,然后输出(URL,1)。Reduce函数把相同URL的value值都累加起来,产生(URL,记录总数)结果。
?倒转网络链接图:Map函数在源页面(source)中搜索所有的链接目标(target)并输出为(target,source)。Reduce函数把给定链接目标(target)的链接组合成一个列表,输出(target,list(source))。
?每个主机的检索词向量:检索词向量用一个(词,频率)列表来概述出现在文档或文档集中的最重要的一些词。Map函数为每一个输入文档输出(主机名,检索词向量),其中主机名来自文档的URL。Reduce 函数接收给定主机的所有文档的检索词向量,并把这些检索词向量加在一起,丢弃掉低频的检索词,输出一个最终的(主机名,检索词向量)。
?倒排索引:Map函数分析每个文档输出一个(词,文档号)的列表,Reduce函数的输入是一个给定词的所有(词,文档号),排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它以一种简单的算法跟踪词在文档中的位置。
?分布式排序:Map函数从每个记录提取key,输出(key,record)。Reduce函数不改变任何的值。这个运算依赖分区机制(在4.1描述)和排序属性(在4.2描述)。
3、实现
MapReduce模型可以有多种不同的实现方式。如何正确选择取决于具体的环境。例如,一种实现方式适用于小型的共享内存方式的机器,另外一种实现方式则适用于大型NUMA架构的多处理器的主机,而有的实现方式更适合大型的网络连接集群。
本章节描述一个适用于Google内部广泛使用的运算环境的实现:用以太网交换机连接、由普通PC机组成的大型集群。在我们的环境里包括:
1.x86架构、运行Linux操作系统、双处理器、2-4GB内存的机器。
2.普通的网络硬件设备,每个机器的带宽为百兆或者千兆,但是远小于网络的平均带宽的一半。(译者注:这里需要网络专家解释一下了)
3.集群中包含成百上千的机器,因此,机器故障是常态。
4.存储为廉价的内置IDE硬盘。一个内部分布式文件系统用来管理存储在这些磁盘上的数据。文件系统通过数据复制来在不可靠的硬件上保证数据的可靠性和有效性。
5.用户提交工作(job)给调度系统。每个工作(job)都包含一系列的任务(task),调度系统将这些任务调度到集群中多台可用的机器上。
3.1、执行概括
通过将Map调用的输入数据自动分割为M个数据片段的集合,Map调用被分布到多台机器上执行。输入的数据片段能够在不同的机器上并行处理。使用分区函数将Map调用产生的中间key值分成R个不同分区(例如,hash(key) mod R),Reduce调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指定。
图1展示了我们的MapReduce实现中操作的全部流程。当用户调用MapReduce函数时,将发生下面的一系列动作(下面的序号和图1中的序号一一对应):
1.用户程序首先调用的MapReduce库将输入文件分成M个数据片度,每个数据片段的大小一般从16MB 到64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量的程序副本。(alex:copies of the program还真难翻译)
2.这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是worker程序,由master分配任务。
有M个Map任务和R个Reduce任务将被分配,master将一个Map任务或Reduce任务分配给一个空闲的worker。
3.被分配了map任务的worker程序读取相关的输入数据片段,从输入的数据片段中解析出key/value pair,然后把key/value pair传递给用户自定义的Map函数,由Map函数生成并输出的中间key/value pair,并缓存在内存中。
4.缓存中的key/value pair通过分区函数分成R个区域,之后周期性的写入到本地磁盘上。缓存的key/value pair在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。
5.当Reduce worker程序接收到master程序发来的数据存储位置信息后,使用RPC从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据后,通过对key进行排序后使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的Reduce任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
6.Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这个key值和它相关的中间value值的集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。
7.当所有的Map和Reduce任务都完成之后,master唤醒用户程序。在这个时候,在用户程序里的对MapReduce调用才返回。
在成功完成任务之后,MapReduce的输出存放在R个输出文件中(对应每个Reduce任务产生一个输出文件,文件名由用户指定)。一般情况下,用户不需要将这R个输出文件合并成一个文件–他们经常把这些文件作为另外一个MapReduce的输入,或者在另外一个可以处理多个分割文件的分布式应用中使用。
3.2、Master数据结构
Master持有一些数据结构,它存储每一个Map和Reduce任务的状态(空闲、工作中或完成),以及Worker 机器(非空闲任务的机器)的标识。
Master就像一个数据管道,中间文件存储区域的位置信息通过这个管道从Map传递到Reduce。因此,对于每个已经完成的Map任务,master存储了Map任务产生的R个中间文件存储区域的大小和位置。当Map任务完成时,Master接收到位置和大小的更新信息,这些信息被逐步递增的推送给那些正在工作的Reduce任务。
3.3、容错
因为MapReduce库的设计初衷是使用由成百上千的机器组成的集群来处理超大规模的数据,所以,这个库必须要能很好的处理机器故障。
worker故障
master周期性的ping每个worker。如果在一个约定的时间范围内没有收到worker返回的信息,master
将把这个worker标记为失效。所有由这个失效的worker完成的Map任务被重设为初始的空闲状态,之后这些任务就可以被安排给其他的worker。同样的,worker失效时正在运行的Map或Reduce任务也将被重新置为空闲状态,等待重新调度。
当worker故障时,由于已经完成的Map任务的输出存储在这台机器上,Map任务的输出已不可访问了,因此必须重新执行。而已经完成的Reduce任务的输出存储在全局文件系统上,因此不需要再次执行。
当一个Map任务首先被worker A执行,之后由于worker A失效了又被调度到worker B执行,这个―重新执行‖的动作会被通知给所有执行Reduce任务的worker。任何还没有从worker A读取数据的Reduce任
务将从worker B读取数据。
MapReduce可以处理大规模worker失效的情况。比如,在一个MapReduce操作执行期间,在正在运行的集群上进行网络维护引起80台机器在几分钟内不可访问了,MapReduce master只需要简单的再次执行那些不可访问的worker完成的工作,之后继续执行未完成的任务,直到最终完成这个MapReduce操作。
master失败
一个简单的解决办法是让master周期性的将上面描述的数据结构(译者注:指3.2节)的写入磁盘,即检查点(checkpoint)。如果这个master任务失效了,可以从最后一个检查点(checkpoint)开始启动另一个master进程。然而,由于只有一个master进程,master失效后再恢复是比较麻烦的,因此我们现在的实现是如果master失效,就中止MapReduce运算。客户可以检查到这个状态,并且可以根据需要重新执行MapReduce操作。
在失效方面的处理机制
(译者注:原文为”semantics in the presence of failures”)
当用户提供的Map和Reduce操作是输入确定性函数(即相同的输入产生相同的输出)时,我们的分布式实现在任何情况下的输出都和所有程序没有出现任何错误、顺序的执行产生的输出是一样的。
我们依赖对Map和Reduce任务的输出是原子提交的来完成这个特性。每个工作中的任务把它的输出写到私有的临时文件中。每个Reduce任务生成一个这样的文件,而每个Map任务则生成R个这样的文件(一个Reduce任务对应一个文件)。当一个Map任务完成的时,worker发送一个包含R个临时文件名的完
成消息给master。如果master从一个已经完成的Map任务再次接收到到一个完成消息,master将忽略这个消息;否则,master将这R个文件的名字记录在数据结构里。
当Reduce任务完成时,Reduce worker进程以原子的方式把临时文件重命名为最终的输出文件。如果同
一个Reduce任务在多台机器上执行,针对同一个最终的输出文件将有多个重命名操作执行。我们依赖底
层文件系统提供的重命名操作的原子性来保证最终的文件系统状态仅仅包含一个Reduce任务产生的数据。
使用MapReduce模型的程序员可以很容易的理解他们程序的行为,因为我们绝大多数的Map和Reduce 操作是确定性的,而且存在这样的一个事实:我们的失效处理机制等价于一个顺序的执行的操作。当Map 或/和Reduce操作是不确定性的时候,我们提供虽然较弱但是依然合理的处理机制。当使用非确定操作的时候,一个Reduce任务R1的输出等价于一个非确定性程序顺序执行产生时的输出。但是,另一个Reduce 任务R2的输出也许符合一个不同的非确定顺序程序执行产生的R2的输出。
考虑Map任务M和Reduce任务R1、R2的情况。我们设定e(Ri)是Ri已经提交的执行过程(有且仅有一个这样的执行过程)。当e(R1)读取了由M一次执行产生的输出,而e(R2)读取了由M的另一次执行产生的输出,导致了较弱的失效处理。
3.4、存储位置
在我们的计算运行环境中,网络带宽是一个相当匮乏的资源。我们通过尽量把输入数据(由GFS管理)存储在集群中机器的本地磁盘上来节省网络带宽。GFS把每个文件按64MB一个Block分隔,每个Block保存在多台机器上,环境中就存放了多份拷贝(一般是3个拷贝)。MapReduce的master在调度Map任务时会考虑输入文件的位置信息,尽量将一个Map任务调度在包含相关输入数据拷贝的机器上执行;如果上述努力失败了,master将尝试在保存有输入数据拷贝的机器附近的机器上执行Map任务(例如,分配到一个和包含输入数据的机器在一个switch里的worker机器上执行)。当在一个足够大的cluster集群上运行大型MapReduce操作的时候,大部分的输入数据都能从本地机器读取,因此消耗非常少的网络带宽。
3.5、任务粒度
如前所述,我们把Map拆分成了M个片段、把Reduce拆分成R个片段执行。理想情况下,M和R应当比集群中worker的机器数量要多得多。在每台worker机器都执行大量的不同任务能够提高集群的动态的
负载均衡能力,并且能够加快故障恢复的速度:失效机器上执行的大量Map任务都可以分布到所有其他的worker机器上去执行。
但是实际上,在我们的具体实现中对M和R的取值都有一定的客观限制,因为master必须执行O(M+R)
次调度,并且在内存中保存O(M*R)个状态(对影响内存使用的因素还是比较小的:O(M*R)块状态,大概每对Map任务/Reduce任务1个字节就可以了)。
更进一步,R值通常是由用户指定的,因为每个Reduce任务最终都会生成一个独立的输出文件。实际使
用时我们也倾向于选择合适的M值,以使得每一个独立任务都是处理大约16M到64M的输入数据(这样,上面描写的输入数据本地存储优化策略才最有效),另外,我们把R值设置为我们想使用的worker机器
数量的小的倍数。我们通常会用这样的比例来执行MapReduce:M=200000,R=5000,使用2000台worker 机器。
3.6、备用任务
影响一个MapReduce的总执行时间最通常的因素是―落伍者‖:在运算过程中,如果有一台机器花了很长的时间才完成最后几个Map或Reduce任务,导致MapReduce操作总的执行时间超过预期。出现―落伍者‖
的原因非常多。比如:如果一个机器的硬盘出了问题,在读取的时候要经常的进行读取纠错操作,导致读
取数据的速度从30M/s降低到1M/s。如果cluster的调度系统在这台机器上又调度了其他的任务,由于CPU、内存、本地硬盘和网络带宽等竞争因素的存在,导致执行MapReduce代码的执行效率更加缓慢。我们最
近遇到的一个问题是由于机器的初始化代码有bug,导致关闭了的处理器的缓存:在这些机器上执行任务
的性能和正常情况相差上百倍。
我们有一个通用的机制来减少―落伍者‖出现的情况。当一个MapReduce操作接近完成的时候,master调
度备用(backup)任务进程来执行剩下的、处于处理中状态(in-progress)的任务。无论是最初的执行进程、还是备用(backup)任务进程完成了任务,我们都把这个任务标记成为已经完成。我们调优了这个机制,通常只会占用比正常操作多几个百分点的计算资源。我们发现采用这样的机制对于减少超大
MapReduce操作的总处理时间效果显著。例如,在5.3节描述的排序任务,在关闭掉备用任务的情况下要多花44%的时间完成排序任务。
4、技巧
虽然简单的Map和Reduce函数提供的基本功能已经能够满足大部分的计算需要,我们还是发掘出了一些有价值的扩展功能。本节将描述这些扩展功能。
4.1、分区函数
MapReduce的使用者通常会指定Reduce任务和Reduce任务输出文件的数量(R)。我们在中间key上使用分区函数来对数据进行分区,之后再输入到后续任务执行进程。一个缺省的分区函数是使用hash方法(比如,hash(key) mod R)进行分区。hash方法能产生非常平衡的分区。然而,有的时候,其它的一些分区函数对key值进行的分区将非常有用。比如,输出的key值是URLs,我们希望每个主机的所有条目保持在同一个输出文件中。为了支持类似的情况,MapReduce库的用户需要提供专门的分区函数。例如,使用―hash(Hostname(urlkey)) mod R‖作为分区函数就可以把所有来自同一个主机的URLs保存在同一个输出文件中。
4.2、顺序保证
我们确保在给定的分区中,中间key/value pair数据的处理顺序是按照key值增量顺序处理的。这样的顺序保证对每个分成生成一个有序的输出文件,这对于需要对输出文件按key值随机存取的应用非常有意义,对在排序输出的数据集也很有帮助。
4.3、Combiner函数
在某些情况下,Map函数产生的中间key值的重复数据会占很大的比重,并且,用户自定义的Reduce函数满足结合律和交换律。在2.1节的词数统计程序是个很好的例子。由于词频率倾向于一个zipf分布(齐夫分布),每个Map任务将产生成千上万个这样的记录
Combiner函数在每台执行Map任务的机器上都会被执行一次。一般情况下,Combiner和Reduce函数是一样的。Combiner函数和Reduce函数之间唯一的区别是MapReduce库怎样控制函数的输出。Reduce 函数的输出被保存在最终的输出文件里,而Combiner函数的输出被写到中间文件里,然后被发送给Reduce任务。
部分的合并中间结果可以显著的提高一些MapReduce操作的速度。附录A包含一个使用combiner函数的例子。
4.4、输入和输出的类型
MapReduce库支持几种不同的格式的输入数据。比如,文本模式的输入数据的每一行被视为是一个
key/value pair。key是文件的偏移量,value是那一行的内容。另外一种常见的格式是以key进行排序来存储的key/value pair的序列。每种输入类型的实现都必须能够把输入数据分割成数据片段,该数据片段能够由单独的Map任务来进行后续处理(例如,文本模式的范围分割必须确保仅仅在每行的边界进行范围分割)。虽然大多数MapReduce的使用者仅仅使用很少的预定义输入类型就满足要求了,但是使用者依然可以通过提供一个简单的Reader接口实现就能够支持一个新的输入类型。
Reader并非一定要从文件中读取数据,比如,我们可以很容易的实现一个从数据库里读记录的Reader,或者从内存中的数据结构读取数据的Reader。
类似的,我们提供了一些预定义的输出数据的类型,通过这些预定义类型能够产生不同格式的数据。用户采用类似添加新的输入数据类型的方式增加新的输出类型。
4.5、副作用
在某些情况下,MapReduce的使用者发现,如果在Map和/或Reduce操作过程中增加辅助的输出文件会比较省事。我们依靠程序writer把这种―副作用‖变成原子的和幂等的(译者注:幂等的指一个总是产生相同结果的数学运算)。通常应用程序首先把输出结果写到一个临时文件中,在输出全部数据之后,在使用系统级的原子操作rename重新命名这个临时文件。
如果一个任务产生了多个输出文件,我们没有提供类似两阶段提交的原子操作支持这种情况。因此,对于会产生多个输出文件、并且对于跨文件有一致性要求的任务,都必须是确定性的任务。但是在实际应用过程中,这个限制还没有给我们带来过麻烦。
4.6、跳过损坏的记录
有时候,用户程序中的bug导致Map或者Reduce函数在处理某些记录的时候crash掉,MapReduce操作无法顺利完成。惯常的做法是修复bug后再次执行MapReduce操作,但是,有时候找出这些bug并修复它们不是一件容易的事情;这些bug也许是在第三方库里边,而我们手头没有这些库的源代码。而且在很多时候,忽略一些有问题的记录也是可以接受的,比如在一个巨大的数据集上进行统计分析的时候。我们提供了一种执行模式,在这种模式下,为了保证保证整个处理能继续进行,MapReduce会检测哪些记录导致确定性的crash,并且跳过这些记录不处理。
每个worker进程都设置了信号处理函数捕获内存段异常(segmentation violation)和总线错误(bus error)。在执行Map或者Reduce操作之前,MapReduce库通过全局变量保存记录序号。如果用户程序触发了一个系统信号,消息处理函数将用―最后一口气‖通过UDP包向master发送处理的最后一条记录的序号。当master看到在处理某条特定记录不止失败一次时,master就标志着条记录需要被跳过,并且在下次重新执行相关的Map或者Reduce任务的时候跳过这条记录。
4.7、本地执行
调试Map和Reduce函数的bug是非常困难的,因为实际执行操作时不但是分布在系统中执行的,而且通常是在好几千台计算机上执行,具体的执行位置是由master进行动态调度的,这又大大增加了调试的难度。
为了简化调试、profile和小规模测试,我们开发了一套MapReduce库的本地实现版本,通过使用本地版本的MapReduce库,MapReduce操作在本地计算机上顺序的执行。用户可以控制MapReduce操作的执行,可以把操作限制到特定的Map任务上。用户通过设定特别的标志来在本地执行他们的程序,之后就可以很容易的使用本地调试和测试工具(比如gdb)。
4.8、状态信息
master使用嵌入式的HTTP服务器(如Jetty)显示一组状态信息页面,用户可以监控各种执行状态。状态信息页面显示了包括计算执行的进度,比如已经完成了多少任务、有多少任务正在处理、输入的字节数、中间数据的字节数、输出的字节数、处理百分比等等。页面还包含了指向每个任务的stderr和stdout文件的链接。用户根据这些数据预测计算需要执行大约多长时间、是否需要增加额外的计算资源。这些页面也可以用来分析什么时候计算执行的比预期的要慢。
另外,处于最顶层的状态页面显示了哪些worker失效了,以及他们失效的时候正在运行的Map和Reduce 任务。这些信息对于调试用户代码中的bug很有帮助。
4.9、计数器
MapReduce库使用计数器统计不同事件发生次数。比如,用户可能想统计已经处理了多少个单词、已经索引的多少篇German文档等等。
为了使用这个特性,用户在程序中创建一个命名的计数器对象,在Map和Reduce函数中相应的增加计数器的值。例如:
Counter* uppercase;
uppercase = GetCounter(―uppercase‖);
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, ―1″);
这些计数器的值周期性的从各个单独的worker机器上传递给master(附加在ping的应答包中传递)。master 把执行成功的Map和Reduce任务的计数器值进行累计,当MapReduce操作完成之后,返回给用户代码。
计数器当前的值也会显示在master的状态页面上,这样用户就可以看到当前计算的进度。当累加计数器的值的时候,master要检查重复运行的Map或者Reduce任务,避免重复累加(之前提到的备用任务和失效后重新执行任务这两种情况会导致相同的任务被多次执行)。
有些计数器的值是由MapReduce库自动维持的,比如已经处理的输入的key/value pair的数量、输出的key/value pair的数量等等。
计数器机制对于MapReduce操作的完整性检查非常有用。比如,在某些MapReduce操作中,用户需要确保输出的key value pair精确的等于输入的key value pair,或者处理的German文档数量在处理的整个文档数量中属于合理范围。
5、性能
本节我们用在一个大型集群上运行的两个计算来衡量MapReduce的性能。一个计算在大约1TB的数据中进行特定的模式匹配,另一个计算对大约1TB的数据进行排序。
这两个程序在大量的使用MapReduce的实际应用中是非常典型的—一类是对数据格式进行转换,从一种表现形式转换为另外一种表现形式;另一类是从海量数据中抽取少部分的用户感兴趣的数据。
5.1、集群配置
所有这些程序都运行在一个大约由1800台机器构成的集群上。每台机器配置2个2G主频、支持超线程的Intel Xeon处理器,4GB的物理内存,两个160GB的IDE硬盘和一个千兆以太网卡。这些机器部署在一个两层的树形交换网络中,在root节点大概有100-200GBPS的传输带宽。所有这些机器都采用相同的部署(对等部署),因此任意两点之间的网络来回时间小于1毫秒。
在4GB内存里,大概有1-1.5G用于运行在集群上的其他任务。测试程序在周末下午开始执行,这时主机的CPU、磁盘和网络基本上处于空闲状态。
5.2、GREP
这个分布式的grep程序需要扫描大概10的10次方个由100个字节组成的记录,查找出现概率较小的3个字符的模式(这个模式在92337个记录中出现)。输入数据被拆分成大约64M的Block(M=15000),整个输出数据存放在一个文件中(R=1)。
图2显示了这个运算随时间的处理过程。其中Y轴表示输入数据的处理速度。处理速度随着参与MapReduce计算的机器数量的增加而增加,当1764台worker参与计算的时,处理速度达到了30GB/s。
当Map任务结束的时候,即在计算开始后80秒,输入的处理速度降到0。整个计算过程从开始到结束一共花了大概150秒。这包括了大约一分钟的初始启动阶段。初始启动阶段消耗的时间包括了是把这个程序传送到各个worker机器上的时间、等待GFS文件系统打开1000个输入文件集合的时间、获取相关的文件本地位置优化信息的时间。
5.3、排序
排序程序处理10的10次方个100个字节组成的记录(大概1TB的数据)。这个程序模仿TeraSort benchmark[10]。
排序程序由不到50行代码组成。只有三行的Map函数从文本行中解析出10个字节的key值作为排序的key,并且把这个key和原始文本行作为中间的key/value pair值输出。我们使用了一个内置的恒等函数作为Reduce操作函数。这个函数把中间的key/value pair值不作任何改变输出。最终排序结果输出到两路复制的GFS文件系统(也就是说,程序输出2TB的数据)。
如前所述,输入数据被分成64MB的Block(M=15000)。我们把排序后的输出结果分区后存储到4000个文件(R=4000)。分区函数使用key的原始字节来把数据分区到R个片段中。
在这个benchmark测试中,我们使用的分区函数知道key的分区情况。通常对于排序程序来说,我们会增加一个预处理的MapReduce操作用于采样key值的分布情况,通过采样的数据来计算对最终排序处理的分区点。
图三(a)显示了这个排序程序的正常执行过程。左上的图显示了输入数据读取的速度。数据读取速度峰值会达到13GB/s,并且所有Map任务完成之后,即大约200秒之后迅速滑落到0。值得注意的是,排序程序输入数据读取速度小于分布式grep程序。这是因为排序程序的Map任务花了大约一半的处理时间和I/O 带宽把中间输出结果写到本地硬盘。相应的分布式grep程序的中间结果输出几乎可以忽略不计。
左边中间的图显示了中间数据从Map任务发送到Reduce任务的网络速度。这个过程从第一个Map任务完成之后就开始缓慢启动了。图示的第一个高峰是启动了第一批大概1700个Reduce任务(整个MapReduce分布到大概1700台机器上,每台机器1次最多执行1个Reduce任务)。排序程序运行大约300秒后,第一批启动的Reduce任务有些完成了,我们开始执行剩下的Reduce任务。所有的处理在大约600秒后结束。
左下图表示Reduce任务把排序后的数据写到最终的输出文件的速度。在第一个排序阶段结束和数据开始写入磁盘之间有一个小的延时,这是因为worker机器正在忙于排序中间数据。磁盘写入速度在2-4GB/s
持续一段时间。输出数据写入磁盘大约持续850秒。计入初始启动部分的时间,整个运算消耗了891秒。这个速度和TeraSort benchmark[18]的最高纪录1057秒相差不多。
还有一些值得注意的现象:输入数据的读取速度比排序速度和输出数据写入磁盘速度要高不少,这是因为我们的输入数据本地化优化策略起了作用—绝大部分数据都是从本地硬盘读取的,从而节省了网络带宽。排序速度比输出数据写入到磁盘的速度快,这是因为输出数据写了两份(我们使用了2路的GFS文件系统,
常见浏览器对比 常见的浏览器有Internet Explorer (IE浏览器的衍生浏览器比较多:它们以IE为内核,然后优化外观,增加部分功能。常见的有:360浏览器、世界之窗浏览器、傲游浏览器(双内核)、搜狗浏览器(双内核)、TT浏览器。)Firefox浏览器、Chrome浏览器、Opera 浏览器、Safari浏览器。 近日,美国著名的市场调查公司StatCounter发布了四月份全球浏览器排行榜前五名。在全球范围内,IE排名第一,Firefox位居第二,排行三四五名的依次分别为Chrome、Safari 和Opera;在我国,IE以绝对的优势胜出位列第一,排名第二的是Chrome,三四五名则分别为 Maxthon、Firefox和Safari,它们的市场份额分别如下: 全球范围内: 1. IE - 44.58% 2. Firefox - 29.67% 3. Chrome - 18.24% 4. Safari - 5.05% 5. Opera - 1.92% 6. Other - 0.55% 我国: 1. IE - 87.35% 2. Chrome - 4.41% 3. Maxthon - 3.79% 4. Firefox - 3.28% 5. Safari - 0.61% 6. Other - 0.56% 一主流浏览器介绍 1、IE浏览器 IE浏览器是微软公司(Microsoft)出品的老牌浏览器:诞生于1995年。现在市场占有率排名第一。自2004年以来市场占有率开始下滑。我们现在一般所见的IE版 IE6,IE7,IE8,IE9。 由于最初是靠和Windows捆绑获得市场份额,且不断爆出重大安全漏洞,本身执行效率不高,不支持W3C标准,Internet Explorer一直被人诟病,但不得不承认它为互联网的发展做出了贡献。 内核:IE浏览器使用Trident的内核,该内核程序在1997年的IE4中首次被采用,是微软在Mosaic代码的基础之上修改而来的,并沿用到目前的IE9。Trident实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用IE内核而非IE的浏览器涌现。由于微软很长时间都并没有更新Trident内核,这导致了两个后果:一是Trident内核曾经几乎与W3C标准脱节(2005年),二是Trident内核的大量 Bug等安全性问题没有得到及时解决 IEInternet Explorer是一款招致非常多批评的网页浏览器,大部分批评都集中在其安全架构以及对开放标准的支持程度上。Internet Explorer 最主要都是被批评其安全性。很多间谍软件,广告软件及电脑病毒横行网络是因为 Internet Explorer 的安全漏洞及安全
百万用户在线网络游戏服务器架构实现 一、前言 事实上100万游戏服务器,在面对大量用户访问、高并发请求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高效率的编程语言、高性能的数据库、还有高性能的架构模型。但是除了这几个方面,还没法根本解决面临的高负载和高并发问题。 当然用户不断地追求更高的机器性能,而升级单一的服务器系统,往往造成过高的投入和维护成本,性价比大大低于预期。同时全天候的可用性的要求也不能满足要求,如果服务器出现故障则该项服务肯定会终止。所以单独追求高性能的服务器不能满足要求,目前基本的解决方案是使用集群技术做负载均衡,可以把整体性能不高的服务器做成高可扩展性,高可用性,高性能的,满足目前的要求。 目前解决客户端和服务器进行底层通讯的交互的双向I/O模型的服务器的成熟方案。 1.windows下,比较成熟的技术是采用IOCP,完成端口的服务器模型。 2.Linux下,比较成熟的技术是采用Epoll服务器模型, Linux 2.6内核中提供的System Epoll 为我们提供了一套完美的解决方案。 目前如上服务器模型是完全可以达到5K到20K的同时在线量的。但5K这样的数值离百万这样的数值实在相差太大了,所以,百万人的同时在线是单台服务器肯定无法实现的。 而且目前几个比较成熟的开发框架,比如ICE,ACE等。这样,当采用一种新的通信技术来实现通信底层时,框架本身就不用做任何修改了(或修改很少),而功能很容易实现,性能达到最优。目前采用的ace框架个不错的选择方案,可以不受操作系统的影响,移植比较方便。 对于数据库选择可有许多成熟的方案,目前大多数选择的mysql Master/slave模式,以及oracle RAC方案。基本可以满足目前的要求,但具体的瓶颈不是在数据库本身,应该还是硬件磁盘I/O的影响更大些。建议使用盘阵。这有其他成熟的方案,比如采用NAS解决分布数据存储。 其实最为关键的是服务器的架构和实现,数据流量的负载均衡,体系的安全性,关键影响度,共享数据的处理等等多个方面对100万用户的数据处理有影响,所以都要全面的考虑。 二、高性能的服务器 1.网络环境 目前采用Client/Server架构来开发网络游戏,客户端和服务器一般通过TCP/UDP协议进
一.服务器概述 服务器是指在局域网中,一种运行管理软件以控制对网络或网络资源(磁盘驱动器、打印机等)进行访问的计算机,并能够为在网络上的计算机提供资源使其犹如工作站那样地进行操作。从广义上讲,服务器是指网络中能对其它机器提供某些服务的计算机系统(如果一个PC对外提供ftp服务,也可以叫服务器)。从狭义上讲,服务器是专指某些高性能计算机,能通过网络,对外提供服务。相对于普通PC来说,稳定性、安全性、性能等方面都要求更高,因此在CPU、芯片组、内存、磁盘系统、网络等硬件和普通PC 有所不同。 服务器作为网络的节点,存储、处理网络上80%的数据、信息,因此也被称为网络的灵魂。做一个形象的比喻:服务器就像是邮局的交换机,而微机、笔记本、PDA、手机等固定或移动的网络终端,就如散落在家庭、各种办公场所、公共场所等处的电话机。日常的生活、工作中的电话交流、沟通,必须经过交换机,才能到达目标电话;同样如此,网络终端设备如家庭、企业中的微机上网,获取资讯,与外界沟通、娱乐等,也必须经过服务器,因此也可以说是服务器在“组织”和“领导”这些设备。 服务器的构成与微机基本相似,有处理器、硬盘、内存、系统总线等,它们是针对具体的网络应用特别制定的,因而服务器与微机在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面存在差异很大。 服务器的功能: 提供服务 - IP 地址 将一种资源共享给多个请求者 - 数据库 将一种设备共享给多个请求者 - 打印机 为其他系统开放网关 - Web 提供处理能力 - 数字 存储内容 - 数据
二.服务器的主要分类 服务器往往被用于运行企业或个人的关键业务,所以对其性能与可靠性方面的要求会远远高于桌面电脑。一般来说服务器的CPU、内存、网络、存储都会使用企业级部件。譬如相比桌面电脑常用的Intel 酷睿系列CPU,服务器的CPU往往会采用性能更稳定强大的Intel至强(Xeon)系列或者IBM的Power系列。而内存也会采用带有诸如ECC效验等自恢复功能的高速企业级内存。为了满足特定的业务需求,不同种类的服务器又会在网络、存储、内存、显卡等方面进行强化。如电信行业采用的服务器往往会配备高速网卡以配合高速交换机;数据仓库应用中的服务器往往会配备高速光纤卡以便通过光纤接口(Fabric Channel)与存储网络配合。 按照体系架构来区分,服务器主要分为两类: 非x86服务器:包括大型机、小型机和UNIX服务器,它们是使用RISC(精简指令集)或EPIC处理器,并且主要采用UNIX和其它专用操作系统的服务器,精简指令集处理器主要有IBM公司的POWER和PowerPC处理器,SUN与富士通公司合作研发的SPARC处理器、EPIC处理器主要是HP与Intel合作研发的安腾处理器等。这种服务器价格昂贵,体系封闭,但是稳定性好,性能强,主要用在金融、电信等大型企业的核心系统中。 x86服务器:又称CISC(复杂指令集)架构服务器,即通常所讲的PC服务器,它是基于PC机体系结构,使用Intel或其它兼容x86指令集的处理器芯片和Windows操作系统的服务器,如IBM的System x 系列服务器、HP的Proliant 系列服务器等。价格便宜、兼容性好、稳定性差、不安全,主要用在中小企业和非关键业务中。 CISC型CPU CISC是英文“Complex Instruction Set Computer”的缩写,中文意思是“复杂指令集”,它是指英特尔生产的x86(intel CPU的一种命名规范)系列CPU及其兼容CPU(其他厂商如AMD,VIA等生产的CPU),它基于PC机(个人电脑)体系结构。这种CPU一般都是 32位的结构,可称为IA-32 CPU。(IA: Intel Architecture,Intel架构)。CISC型CPU目前主要有intel的服务器CPU和AMD的服务器CPU两类。 RISC型CPU RISC 是英文“Reduced Instruction Set Computing ” 的缩写,中文意思是“精简指令集”。它是在CISC(Complex Instruction Set Computer)指令系统基础上发展起来的,相对于CISC型CPU ,RISC型CPU不仅精简了指令系统,还采用了一种叫做“超标量和超流水线结构”,架构在同等频率下,采用RISC架构的CPU比CISC架构的CPU性能高很多,这是由CPU的技术特征决定的。RISC型CPU与Intel和AMD的CPU在软件和硬件上都不兼容。
游戏服务器系统设计 1.1 服务器架构分类 服务器组的架构一般分为两种:第一种是带网关服务器的服务器架构;第二种是不带网关服务器的服务器架构,这两种方案各有利弊。在给出服务器架构设计之前,先对这两种设计方案进行详细的探讨。所谓网关服务器,其实是Gate 服务器,比如LoginGate、GameGate 等。网关服务器的主要职责是将客户端和游戏服务器隔离,客户端程序直接与这些网关服务器通信,并不需要知道具体的游戏服务器内部架构,包括它们的IP、端口、网络通信模型(完成端口或Epoll)等。客户端只与网关服务器相连,通过网关服务器转发数据包间接地与游戏服务器交互。同样地,游戏服务器也不直接和客户端通信,发给客户端的协议都通过网关服务器进行转发。 1.2 服务器架构设计 根据网络游戏的规模和设计的不同,每组服务器中服务器种类和数量是不尽相同的。本系统设计出的带网关服务器的服务器组架构如图1 所示。 图1 带网关服务器的服务器架构设计方案 该设计有以下几点好处: (1)作为网络通信的中转站,负责维护将内网和外网隔离开,使外部无法直接访问内部服
务器,保障内网服务器的安全,一定程度上较少外挂的攻击。 (2)网关服务器负责解析数据包、加解密、超时处理和一定逻辑处理,这样可以提前过滤掉错误包和非法数据包。 (3)客户端程序只需建立与网关服务器的连接即可进入游戏,无需与其它游戏服务器同时建立多条连接,节省了客户端和服务器程序的网络资源开销。 (4)在玩家跳服务器时,不需要断开与网关服务器的连接,玩家数据在不同游戏服务器间的切换是内网切换,切换工作瞬间完成,玩家几乎察觉不到,这保证了游戏的流畅性 和良好的用户体验。 虽然网关服务器带来上述好处,但是,还需要注意以下可能导致负面效果的两个情况:如何避免网关服务器成为高负载情况下的通讯瓶颈问题以及由于网关的单节点故障导致整组服务器无法对外提供服务的问题。上述两个问题可以采用“多网关”技术加以解决。顾名思义,“多网关”就是同时存在多个网关服务器,比如一组服务器可以配置三台GameGate。当负载较大时,可以通过增加网关服务器来增加网关的总体通讯流量,当一台网关服务器宕机时,它只会影响连接到本服务器的客户端,其它客户端不会受到任何影响。从图1 的服务器架构图可以看出,一组服务器包括LoginGate、LoginServer、GameGate、GameServer、DBServer和MServer 等多种服务器。LoginGate 和GameGate 就是网关服务器,一般一组服务器会配置3 台GameGate,因为稳定性对于网络游戏运营来说是至关重要的,而服务器宕机等突发事件是游戏运营中所面临的潜在风险,配置多台服务器可以有效地降低单个服务器宕机带来的风险。另外,配置多台网关服务器也是进行负载均衡的有效手段之一。其中,各种服务器的主要功能和彼此之间的数据交互情况如下。 (1)LoginGate LoginGate 主要负责在玩家登录时维护客户端与LoginServer 之间的网络连接与通讯,对LoginServer 和客户端的通信数据进行加解密、校验。 (2)LoginServer LoginServer 主要功能是验证玩家的账号是否合法,只有通过验证的账号才能登录游戏。从架构图可以看出,DBServer 和GameServer 会连接LoginServer。玩家登录基本流程是,客户端发送账号和密码到LoginServer 验证,如果验证通过,LoginServer 会给玩家分配一个SessionKey,LoginServer 会把这个SessionKey 发送给客户端、DBServer和GameServer,在后续的选择角色以后进入游戏过程中,DBServer 和GameServer 将验证SessionKey 合法性,如果和客户端携带的SessionKey 不一致,将无法成功获取到角色或者进入游戏。 (3)GameGate GameGate(GG)主要负责在用户游戏过程中负责维持GS与客户端之间的网络连接和通讯,对GS 和客户端的通信数据进行加解密和校验,对客户端发往GS 的用户数据进行解析,过滤错误包,对客户端发来的一些协议作简单的逻辑处理,其中包括游戏逻辑中的一些超时判断。在用户选择角色过程中负责维持DBServer 与客户端之间的网络连接和通讯,对DBServer 和客户端的通信数据进行加解密和校验,对客户端发往DBServer 的用户数据做简单的分析。维持客户端与MServer 之间的网络连接与通讯、加解密、数据转发和简单的逻辑处理等。(4)GameServer GameServer(GS)主要负责游戏逻辑处理。在软件架构层面,本系统将游戏的众多系统设计成GS 的子系统或模块,它们共同处理整个游戏世界逻辑的运算。游戏逻辑包括角色进入与退出游戏、跳GS 以及各种逻辑动作(比如行走、说话和攻击等)。由于整个游戏世界有许多游戏场景,在该架构中一组服务器有3 台GS 共同负责游戏逻辑处理,每台游戏服务器负 责一部分地图的处理,这样不仅降低了单台服务器的负载,而且降低了GS 宕机带来的风险。玩家角色信息里会保持玩家上次退出游戏时的地图编号和所在GS 编号,这样玩家再次登录
2月27日在上一篇关于ARM和x86在数据中心应用的较量,已经不是一个新话题了。我们经常看到功耗、性能数字,以及应用软件和生态系统丰富程度的讨论。《华为UDS对象存储:ARM自组织硬盘满足CERN功耗》一文里面,笔者曾经提到“功耗和成本正是UDS使用ARM而不是Intel Atom等处理器的原因,据了解华为此前在这一系列的产品中使用过Atom。” 现在我想以大型用户的实际研发和部署进度为切入点,继续谈谈ARM和x86之间各自的优势,以及可能存在的不足。 本文的两个主要论点是:ARM在用于数据中心的SoC方面,目前相对于x86的功能和集成度有一定优势;另外百度与Facebook主导的Open Compute Project(开放计算项目),其存储(服务器)设计的密度和灵活性也有些差别。那为什么标题中还说两家“异曲同工”呢?先来看看百度的情况。 百度ARM云存储支持纯x86/ARM,或两者混布 ChinaByte比特网:关于百度的ARM云存储节点,是否方便透露使用了来自哪家的处理器?系统来自哪个ODM? 以我的了解,华为UDS对象存储(云存储)也使用了ARM,在存储节点上每颗ARM (应该是单核)对应一个硬盘,而管理(元数据)节点仍然是x86。 我看到百度也是每个ARM核心对应一个硬盘,因此想了解下整套系统的组成,是否也需要x86的管理节点搭配使用?ARM在这里是什么样的角色(承担着哪些处理工作)? 百度:我们与ARM、Marvell 等业界领导者共同设计开发了这款ARM 云存储服务器,并拥有相关专利。完整的系统架构不方便透露。可以明确的是,我们的这套系统可以支持纯X86,或者纯ARM,或者两者混布。 点评:我想这个答复还算简单清楚,下面再看看实物照片:
未来网络体系架构的发展趋势 华南师大学计算机学院 中文摘要 随着计算机技术和互联网业务的蓬勃发展,面对用户对当前网络提出的越来越多的需求,传统的因特网架构开始遇到瓶颈,包括管控性、可扩展性、安全性和移动性等一系列问题。网络业务和应用的进一步扩展受到限制,促使互联网向下一代网络迈进和发展。 本文将概括在未来网络领域的研究现状,归纳当前网络存在的一系列问题,并根据“改良式”和“改革式”的两条研究路线对部分研究成果进行介绍。在此基础上,文章将对未来网络的研究进展做出总结,并结合当前存在的问题对提出对未来网络的展望。 关键词:因特网架构,未来网络,改良式,改革式
目录 中文摘要 0 Abstract.............................................................. 错误!未定义书签。 1 引言 (2) 2 传统网络存在的问题 (3) 3 国外研究现状 (4) 3.1 美国的GENI、FIND和FLA (4) 3.2 欧盟新一代互联网研究计划FIRE (4) 3.3 我国下一代互联网基础理论研究现状 (5) 3.4 其他国家在该领域的研究现状 (5) 4 改良式的未来网络研究 (6) 4.1 下一代IP协议IPv6 (6) 4.1.1 IPv6产生背景 (6) 4.1.2 IPv6介绍 (6) 4.1.3 IPv6的优点 (8) 4.2 Loc/ID Split名址分离网络体系 (9) 4.2.1 名址分离网络体系产生背景 (9) 4.2.2 LISP名址分离网络协议介绍 (9) 4.2.3 LISP的移动性扩展 (10) 4.2.3 LISP的移动性扩展 (10) 5 改革式的未来网络研究 (11) 5.1 NDN命名数据网络 (11) 5.1.1 NDN命名数据网络产生背景 (11) 5.1.2 NDN网络的体系结构 (11) 5.1.3 NDN体系架构具备优点 (14) 5.2 SDN软件定义网络 (15) 5.2.1 SDN软件定义网络诞生背景 (15) 5.2.2 SDN网络体系架构介绍 (15) 5.2.3 OpenFlow协议介绍 (16) 5.2.4 软件定义网络的优点 (17) 6 未来网络的发展 (18) 6.1 革命式和改良式架构的关系 (18) 6.2 未来互联网的体系结构应遵循简单开放原则 (18) 6.3 未来互联网体系结构应嵌安全等安全需求 (18) 6.4 未来互联网体系结构将更多的面向服务 (19) 6.5 未来互联网体系结构将更具有智能化特征 (19) 7 总结 (20) 参考文献 (21)
从整体来看,Google的云计算平台包括了如下的技术层次。 ●网络系统:包括外部网络(Exterior Network) ,这个外部网络并不是指运营商自己的骨干网,也是指在Google 云计算服务器中心以外,由Google 自己搭建的由于不同地区/国家,不同应用之间的负载平衡的数据交换网络。内部网络(Interior Network),连接各个Google自建的数据中心之间的网络系统。 ●硬件系统:从层次上来看,包括单个服务器、整合了多服务器机架和存放、连接各个服务器机架的数据中心(IDC)。 ●软件系统:包括每个服务器上面的安装的单机的操作系统经过修改过的Redhat Linux。Google 云计算底层软件系统(文件系统GFS、并行计算处理算法Mapreduce、并行数据库Bigtable,并行锁服务Chubby Lock,云计算消息队列GWQ) ●Google 内部使用的软件开发工具Python、Java、C++ 等 ●Google 自己开发的应用软件Google Search 、Google Email 、Google Earth 外部网络系统介绍 当一个互联网用户输入的时候,这个URL请求就会发到Google DNS 解析服务器当中去,Google 的DNS 服务器会根据用户自身的IP 地址来判断,这个用户请求是来自哪个国家、哪个地区。根据不同用户的IP地址信息,解析到不同的Google的数据中心。 进入第一道防火墙,这次防火墙主要是根据不同端口来判断应用,过滤相应的流量。如果仅仅接受浏览器应用的访问,一般只会开放80 端口http,和443 端口https (通过SSL加密)。将其他的来自互联网上的非Ipv4 /V6 非80/443 端口的请求都放弃,避免遭受互联网上大量的DOS 攻击。 在大量的web 应用服务器群(Web Server Farm)前,Google使用反向代理(Reverse Proxy)的技术。反向代理(Reverse Proxy)方式是指以代理服务器来接受internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给Internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
浅谈数据中心网络架构的发展 一、传统数据中心网络架构 数据中心前端计算网络主要由大量的二层接入设备及少量的三层设备组成,传统上是标准的三层结构(如图1所示): 图1 传统数据中心网络三层架构 传统的网络模型在很长一段时间内,支撑了各种类型的数据中心,但随着互联网的发展以及企业IT信息化水平的提高,新的应用类型及数量急剧增长。随着数据中心规模的不断膨胀,以及虚拟化、云计算等新技术的不断发展,仅仅使用传统的网络技术越来越无法适应业务发展的需要。在互联网领域,这一点表现的尤为明显。 二、数据中心网络的新变化 截至2013年12月,中国网民规模达6.18亿,全年共计新增网民5358万人,互联网普及率为45.8%。大量网民的涌入必然带来网络流量的急剧膨胀。对于互联网企业,承载具体应用的数据中心的计算资源及网络节点常常满负荷运转;而
对于传统企业,随着自身业务量的增加,以及各类业务互联网化的需求,对数据中心的整体的吞吐量也提出了新的要求。 服务器万兆网络接入渐成主流 受成本、以及技术成熟度制约,传统数据中心以千兆接入为主。随着CPU 计算能力的不断提高,目前主流的服务器处理性能,已经超出了千兆网卡的输出能力。同时,FC存储网络与IP网络的融合,也要求IP网络的接入速率达到FC 的性能要求。当仅仅通过链路聚合、增加等价路径等技术手段已经无法满足业务对网络性能的需求时,提高网络端口速率成为必然之选。 万兆以太网从起步到目前逐渐成为应用主流,延续了以太网技术发展的主基调,凭借其技术优势,替代其他网络接入技术,成为高性能网络的不二选择。目前新的数据中心,万兆网络接入已成为事实上的标准。 数据中心流量模型发生显著变化 传统的数据中心内,服务器主要用于对外提供业务访问,不同的业务通过安全分区及VLAN隔离。一个分区通常集中了该业务所需的计算、网络及存储资源,不同的分区之间或者禁止互访,或者经由核心交换通过三层网络交互,数据中心的网络流量大部分集中于南北向。 在这种设计下,不同分区间计算资源无法共享,资源利用率低下的问题越来越突出。通过虚拟化技术、云计算管理技术等,将各个分区间的资源进行池化,实现数据中心内资源的有效利用。而随着这些新技术的兴起和应用,新的业务需求如虚拟机迁移、数据同步、数据备份、协同计算等在数据中心内开始实现部署,数据中心内部东西向流量开始大幅度增加。 物理二层向逻辑二层转变 在虚拟化初期,虚拟机管理及迁移主要依靠物理的网络,由于迁移本身要求二层网络,因此数据中心内部东西向流量主要是二层流量。为增加二层物理网络的规模,并提高链路利用率,出现了TRILL、SPB等大二层网络技术。
服务器架构方案 项目名称:北京大地腾农网络科技有限公司服务器架构方案主管部门:技术部 建设地点:北京市朝阳区广播电视学校机房 编写时间:2009年10月
目录 系统 软件 拓扑图 基本需求基本思路技术实现流量考虑服务器配置方案的好处
系统: CENTOS 5.0 WINDOWS 2003 软件: Apache2.0以上版本——jk_mod模块Tomcat6.0以上版本 IPtables防火墙 FTP软件 Winmail邮箱 SQL Server 2000 拓扑图:
基本需求: 1、高可用性:将停止服务时间降低到最低甚至是不间断服务。 2、可扩展性:随着访问的增加,系统具备良好的伸缩能力。 3、高性能高可靠性:经过优化的体系结构及合理的备份策略。 4、安全性:结构上的安全及主机的安全策略。 基本思路: 1、对于访问频繁,用户量大的对象采用网站、视频资源负载均衡 到多台服务器上来提高可用性,当然其中一台服务器出现问题,其他服务器将提供网站、视频资源服务。图中(WEB网站集 群服务器与资源服务器集群) 2、可护展性:将网站服务器后期有新的项目增加时可以通过虚拟 机增加新的网站项目。用户量大的时候,可以考虑做负载均衡。 或者是软件集群。(WEB网站集群服务器) 3、高性能高可靠性:通过(WEB网站集群、资源集群)大大提 高了网站的性能,也合理的解决网站、资源的备份策略。数据 库的备份可以安时间段进行定时备份,并将备份文件上传到 FTP服务器。 4、安全性:结构上的安全及于硬件防火墙、IPS入侵检测与防御 系统的安全策略。 技术现实 1、防火墙:由于internet上每天都有上百万人在那里收集信 息、交换信息不,避免不了有人搞破坏。这样就要求我们用防
网络游戏的常用体系结构 网络游戏都是借助于互联网运作的,要实现网络游戏同步的第一步就是设计出高效的网络体系结构。数据信息传输的过程中,网络底层协议影响着信息传输的可靠性和准确性,因此网络协议的选择也是必须加以重视的问题。而影响网络游戏同步的各种因素正是我们为解决同步的突破口。 1 C/S模式的体系结构 大多MMOG游戏都采用C/S的网络体系结构,该体系结构如图1所示: 服务器 图1 基于C/S的网络游戏结构 在此结构中服务端的作用是担任中心服务器的角色,每个连接到此服务端的客户端需要更新或发出新的消息时,服务端接收到客户端传来的数据信息后,根据逻辑进行相应的处理后把消息广播到相应的客户端玩家,对于客户端来说,相互之间不能直接通信,他们都要通过服务器的间接传递才能收到另外客户端发来的数据信息。 在服务器端存放整个网络游戏的世界原型,而玩家只能在客户端进入这个世界,观察里面的动态和情况,在游戏世界里互相沟通、交流、做出不同的回应或攻击。这样客户端就不能篡改游戏的状态,但是同时也会把所有的任务都交给服务端,服务器就需要承载更多的压力。C/S结构的优点是能够很好的保证游戏状态的一致性,这是因为整个游戏世界的原型和数据都保存在服务端,而客户端的操作都需要经过服务端的处理,这样游戏状态要经过服务端的统一分析和处理,客户端的非法操作就无法执行,这样就有效的防止了玩家的作弊。该结构的缺点是容易造成系统的瓶颈,这是由于中心服务器的负载过重导致的。而服务器的瘫痪就会导致整个游戏的瘫痪。该结构的另一个缺点是客户端的升级十分困难,每次游戏升级都要下载庞大的客户端软件。尤其对于带宽小的用户更是一件十分不容易的事情。因此在设计游戏时,客户端更新程序的下载应适当缩减。 2 P2P体系结构 P2P体系结构[3],又称对等通信结构,该结构也是应用比较广泛的一种结构,
各公司服务器架构 经典云计算架构包括IaaS、PaaS、SaaS三层服务。云计算平台架构细分为硬件层、虚拟层、软件平台层、能力层、应用平台以及软件服务层。 云平台的云计算架构虽然分了多个层次,但是每个层次之间都是松耦合关系,在一个具体案例中也不是每个层次的服务都使用到,而且根据具体的应用环境搭建相应的云计算架构。 (1)硬件层和虚拟层对应IaaS层(Infrastructure as a Service) 主要提供基本架构的服务,比如提供基本的计算服务、存储服务、网络服务。计算机服务是提供用户一个计算环境,用户可以在上面开发和运行自己的应用,此环境一般是包含约定CPU、内存和基本存储空间的虚拟机环境,也可以是一台物理服务器,但是对用户是透明的。 存储资源是提供用户一个存储空间,根据用户需求不同可以提供块存储服务,文件存储服务,记录存储服务,对象存储服务。 网络服务是提供用户一个网络方案,可以让用户维护自己的计算环境和存储空间,并可以利用计算环境和存储空间对外提供服务。 (2)软件平台、能力层、应用平台组成PaaS层(Platform as a Service) 软件平台层主要提供公共的平台技术,比如统一支撑操作系统,包括使用到的运行平台,对应用屏蔽了运行环境差异,应用只要关心逻辑即可;也包括统一计费、统一配置、统一报表等后台支撑,各种应用利用相应的框架进行开发后,即可做到对外统一界面、统一运维管理、统一报表展示等;也包括分布式缓存、分布式文件系统、分布式数据库等通用技术,上层应用可以根据自己的需要使用相应的API就可以使用到这些通用技术。 能力层主要提供基本业务能力,比如传统电信服务中的短信、彩信、wappush等,互联网服务中的图
Unity3D游戏开发之网络游戏服务器架构设计培训 (如何做一名好主程) 今天给大家讲一下如何做一个好的主程 入手 假如,我现在接手一个新项目,我的身份还是主程序。在下属人员一一到位之前,在和制作人以及主策划充分沟通后,我需要先独自思考以下问题: 1、服务器跑在什么样的操作系统环境下? 2、采用哪几种语言开发?主要是什么? 3、服务器和客户端以什么样的接口通讯? 4、采用哪些第三方的类库? 除了技术背景之外,考虑这些问题的时候一定要充分考虑项目需求和所能拥有的资源。 我觉得,先不要想一组需要几台机器各有什么功能这样的问题,也不要想需要多少个daemon 进程。假设就一台服务器,就一个进程,把所需要的资源往最小了考虑,把架构往最简单的方向想,直到发现,“哦,这么做无法满足策划要求的并发量”,再去修改设计方案。 操作系统:越单一越好。虽然FreeBSD的网络性能更好、虽然Solaris非常稳定,但选什么就是什么,最好别混着来。前端是FreeBSD,后端是Solaris,运营的人会苦死。也不要瞧不起用Windows的人,用Windows照样也能支持一组一万人在线,总之,能满足策划需求,好招程序员,运营成本低是要点。不同的操作系统有不同的特性,如果你真的对它们都很熟悉,那么必定能找到一个理由,一个足够充分的理由让你选择A而不是B而不是C。但做决策的时候要注意不要因小失大。 Programming Language:传统来说,基本都是C/C++。但是你也知道,这东西门槛很高,好的C/C++程序员很难招。用Perl/Python/Lua行不行?当然可以。但是纯脚本也不好,通常来说是混合着来。你要明白哪些是关键部分,我是说执行次数最多的地方而不是说元宝,这些必须用性能高的语言实现(比如C/C++比如Java),其它像节日活动这样很久才执行一次的,随便吧。脚本的好处是,可以快速搭原型。所以,尽早的,在你做完基本的地图和战斗模块之后,立马跑机器人测试吞吐量。这时候项目开发进度还不到10%,不行就赶紧改。 此处特别举个例子就是Java GC的问题。既然你要用java,而jvm需要通过执行garbage collection来回收内存,而garbage collection会使整个应用停顿,那你不妨试一试,内存在达到峰值的时候会停多久?策划可以接受吗?如果不可以,你可以采用其它的GC策略再试一试。这个问题应该不是Java独有的。网游和网站应用相比它很注重流畅性。这是你务必需要考虑的。 至于选择什么样的脚本语言,以及脚本在你的游戏中究竟是占80%还是20%?需要根据需求来看。有没有游戏完全不用脚本?有。有没有游戏滥用脚本?也有。如果你引入脚本的目的是因为策划不会C/C++而你希望策划能自己独立实现更多的游戏功能。你希望策划去写脚本?脚本也是程序,策划写的脚本难道就比程序员写脚本好?还是因为策划工资便宜?策划
网络服务器架构概述 针对校园服务器而言,经过一个学期长时间的运行,服务器中的各种系统已经紊乱,这时恐怕就得重新安装操作系统或应用软件了。以下我们将讲解软件维护过程中所需注意的一些问题。 安装前的准备 在进行操作系统维护之前需要将必要的数据备份出来。备份的方法可以使用额外的硬盘,也可以将数据用刻录机备份出来。另外,在重新安装系统之前,需要检查硬件是否工作正常,从网上下载最新的硬件驱动程序安装盘(光盘或软盘),否则系统很可能将无法安装成功。尤其是某些RAID卡的驱动程序,一定是要有软盘介质的支持,因为在安装操作系统时会要求你插入驱动盘。 操作系统的安装 在确认万事俱备之后,就可以重新安装操作系统了。首先需要将硬盘格式化,用操作系统的启动盘启动系统之后,运行格式化命令就可以了。如果有必要,可以重新把硬盘分区,但是千万不要进行低级格式化硬盘,除非确认硬盘有坏道。 在格式化硬盘之后,就把操作系统安装上,安装操作系统的具体操作过程这里就不再讲了。安装完操作系统之后,再把显卡、网卡、SCSI卡、主板等设备的驱动程序安装上,使操作系统正常运行就可以了。 另外,需要提醒一下,在安装完操作系统之后,记住一定要下载并安装最新的操作系统的补丁,这样就能够保证服务器的安全漏洞是最少的。 网络服务的设置和启动 仅仅安装完操作系统是不行的,此时的服务器还没有提供各种网络服务,因此需要对服务器进行一系列的设置。下面介绍几种特别重要的网络服务。 1、DNS服务 DNS(域名解析系统)是基于TCP/IP的网络中最重要的网络服务之一,最主要的作用是提供主机名到IP地址的解析服务。在Windows 2000 Server组成的网络中,DNS服务居于核心地位,如果没有DNS,Windows 2000网络将无法工作。所以在Windows 2000网络中,至少要有一台DNS服务器。 2、域控制器
从性能角度来看,处理器、内存和I/O这三个子系统在服务器中是最重要的,它们也是最容易出现性能瓶颈的地方。目前市场上主流的服务器大多使用英特尔Nehalem、Westmere微内核架构的三个家族处理器:Nehalem-EP,Nehalem-EX 和Westmere-EP。下表总结了这些处理器的主要特性: 在本文中,我们将分别从处理器、内存、I/O三大子系统出发,带你一起来梳理和了解最新英特尔架构服务器的变化和关键技术。 一、处理器的演变 现代处理器都采用了最新的硅技术,但一个单die(构成处理器的半导体材料块)上有数百万个晶体管和数兆存储器。多个die组织到一起就形成了一个硅晶片,每个die都是独立切块,测试和用陶瓷封装的,下图显示了封装好的英特尔至强5500处理器外观。 图 1 英特尔至强5500处理器 插座 处理器是通过插座安装到主板上的,下图显示了一个英特尔处理器插座,用户可根据自己的需要,选择不同时钟频率和功耗的处理器安装到主板上。
图 2 英特尔处理器插座 主板上插座的数量决定了最多可支持的处理器数量,最初,服务器都只有一个处理器插座,但为了提高服务器的性能,市场上已经出现了包含2,4和8个插座的主板。 在处理器体系结构的演变过程中,很长一段时间,性能的改善都与提高时钟频率紧密相关,时钟频率越高,完成一次计算需要的时间越短,因此性能就越好。随着时钟频率接近4GHz,处理器材料物理性质方面的原因限制了时钟频率的进一步提高,因此必须找出提高性能的替代方法。 核心 晶体管尺寸不断缩小(Nehalem使用45nm技术,Westmere使用32nm技术),允许在单块die上集成更多晶体管,利用这个优势,可在一块die上多次复制最基本的CPU(核心),因此就诞生了多核处理器。
从传统网络架构到SDN化演进方案甜橙金融数据中心演进之路
前言: 网络世界每一次技术变革都需要大量时间来验证,虽然更多的技术达人对于新技术的接受能力在不断提高,但新技术的普及和应用依然需要花费大量时间。企业在发展过程中缩减预算的需求不断扩大,企业员工则通过自动化的维护平台设施来简化操作步骤,而网络世界的争论点主要集中在如何从使软件定义网络与网络虚拟化的新架构代替传统以太网架构。 STP架构网络的替代品Fabrics具有可扩展、高带宽的架构。对于SDN来说,SDN可能不像一个产品,更像一种架构。首先我们来看一下SDN与传统网络架构的区别: 一、传统数据中心网络架构逐渐落伍 在传统的大型数据中心,网络通常是三层结构。架构模型包含了以下三层: ?Access Layer(接入层):接入层位与网络的最底层,负责所有终端设备的接入工作,并确保各终端设备可以通过网络进行数据包的传递。 ?Aggregation Layer(汇聚层):汇聚层位于接入层和核心层之间。该层可以通过实现ACL 等其他过滤器来提供区域的定义。 ?Core Layer(核心层):又被称为网络的骨干。该层的网络设备为所有的数据包包提供高速转发,通过L3路由网络将各个区域进行连接,保证各区域内部终端设备的路由可达。
一般情况下,传统网络还存在着一些优点: ?精确的过滤器/策略创建和应用:由于区域、终端地址网段明确,可以精细控制网络策略,保证流量的安全。 ?稳定的网络:区域的明确划分,网络设备的稳定架构,使网络更具有稳定性。 ?广播域的有效控制:由于三层架构中间采用L3模式设计,有效控制广播域的大小。 传统网络架构虽然稳定,但随着技术的不断发展,应用不断的多元化以及对业务的高冗余化的需求,暴露出了一些传统网络的弊端。
图片服务器分离 1介绍 现在很多的网站上都会用到大量的图片,而图片是网页传输中占主要的数据量,也是影响网站性能的主要因素。因此很多网站都会将图片存储从网站中分离出来,另外架构一个或多个服务器来存储图片,将图片放到一个虚拟目录中,而网页上的图片都用一个URL 地址来指向这些服务器上的图片的地址,这样的话网站的性能就明显提高了,图片服务器(ImageServer)的概念也就产生了。 1.1图片服务器的优势 1,分担Web服务器的I/O负载-将耗费资源的图片服务分离出来,提高服务器的性能和稳定性。 2,能够专门对图片服务器进行优化-为图片服务设置有针对性的缓存方案,减少带宽成本,提高访问速度。 3,提高网站的可扩展性-通过增加图片服务器,提高图片吞吐能力。 1.2图片服务器的注意事项 1,选择适合图片存储的物理介质和文件系统 2,使用物理上独立的服务器 3,如果拥有多台图片服务器,要考虑服务器之间的图片同步问题 4,使用独立域名 5,制定合理的缓存策略 6,使用图片处理模块对用户上传的图片进行再加工 1.3图片服务器的架构 图片是网站中必不可少的一个组成部分,随着网站的不断发展,对图片的处理也将随着访问的增长,图片的增加提出不断改进的需求,网站初期,所有的一切都从简图片所存在的位置通常会在站点下的Images文件夹。 随着访问的增加,IIS压力的增大,开始做拆分,将图片文件夹作为单独站点提取出来如http://images.***.com/(可能根据需要会拆分成多个图片服务器,与具体业务环境相关),拆分之后很好的将单个IIS应用池的压力分担到2个乃至多个上,大大提高访问瓶颈。随着访问的进一步增加,服务器压力已经无法支撑,这时我们需要将图片站点作为独立服务器存在。在访问图片的过程中,我们可能会面临一个图片有多个图片尺寸的需求,前期我们通常会在保存页面的过程中保存我们需要的各个尺寸图片,但随着所需尺寸的不同,保存图片时需要的尺寸越来越多,这时我们如何应对? IIS服务器的并发访问意味着随着用户的进一步增加,我们单台图片服务器已经不足以应对了,此时我们如何进一步扩展?
第一章网站发展历史与基础概念 1.1 网站的诞生与发展 因特网起源于美国国防部高级研究计划管理局建立的阿帕网。网站(Website)开始是指在因特网上,根据一定的规则,使用HTML等工具制作的用于展示特定内容的相关网页的集合。简单地说,网站是一种通讯工具,人们可以通过网站来发布自己想要公开的资讯,或者利用网站来提供相关的网络服务。人们可以通过网页浏览器来访问网站,获取自己需要的资讯或者享受网络服务。 在因特网的早期,网站还只能保存单纯的文本。经过几年的发展,当万维网出现之后,图像、声音、动画、视频,甚至3D技术等多媒体资源开始在因特网上流行起来,网站也慢慢地发展成我们现在看到的图文并茂的样子,即基于HTTP协议(超文本传输协议)的多媒体资源展示与共享。 在信息技术飞速发展的今天,通过综合运用软件开发技术、多媒体技术、网页呈现技术、数据库技术以及矢量动画技术,使得现代网站拥有丰富多彩的功能和用户UI。 目前互联网已经来到了Web3.0的时代,大量复杂的富浏览器端功能在网站中得到应用。给网站的发展和推广带来新的活力和机遇。 1.2 与网站相关的概念 ●域名(Domain Name) 域名是由一串用点分隔的字母组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置),目前域名已经成为互联网的品牌、网上商标保护必备的产品之一。 域名与IP地址一一对应,用于在互联网上区分开各个主机。 扩展学习:域名域名分类 ●域名分类 ●常用国家地区代码
●空间(虚拟主机 Virtual Machine) 虚拟主机也叫“网站空间”,就是把一台运行在互联网上的服务器划分成多个“虚拟”的服务器,每一个虚拟主机都具有独立的域名和完整的Internet服务器(支持WWW、FTP、E-mail等)功能。这种技术极大的促进了网络技术的应用和普及。租用主机也成了网络时代新的经济形式。扩展学习:虚拟主机 ●界面与程序(UI、Program) 网站的界面与后台程序是网站外貌、风格和功能的集中体现,是网站的核心组成部分。界面和程序的实现需要综合运用多种技术,如HTML、XHTML、Css、 Javascript、XML、Flash、Sliverlight、Jsp、.Net等。 ●通信协议(Communication protocol) 所有的需要互通信息的机器或设备都要采用通用的通信标准。类似于不同国家的人要交流时讲述同一种语言。网络通信协议为连接不同操作系统和不同硬件体系结构的互联网络引提供通信支持,是一种网络通用语言。 ●常见的网络通信协议 ◆ TCP/IP协议(Transmission Control Protocol/Internet Protocol,传输控制协议 /网际协议) ◆HTTP协议(Hypertext Transfer Protocol,超文本传输协议) ◆SMTP协议(Simple Mail Transfer Protocol,简单邮件传输协议) ◆POP3协议(Post Office Protocol 3,电子邮件协议的第3个版本) 第二章网站建设的目标、原则与规划 2.1 明确网站建设的目标 常见的网站建设目标: