案例
通过构建虚拟变量,建立了分段线性回归模型,结果如下:
Variable Coefficient Std. Error t-Statistic Prob.
C -697.0977 944.8734 -0.737768 0.4673
GNI 0.132616 0.030143 4.399560 0.0002 (GNI-70142.5)*D1 -0.185777 0.111182 -1.670927 0.1067
(GNI-98000)*D2 0.230666 0.110988 2.078301 0.0477
(GNI-184088.6)*D3 -0.273652 0.075943 -3.603403 0.0013
(GNI-251483.2)*D4 0.458678 0.082565 5.555380 0.0000
R-squared 0.965855 Mean dependent var 10428.57
Adjusted R-squared 0.957976 S.D. dependent var 13612.43
S.E. of regression 2790.516 Akaike info criterion 18.89167
Sum squared resid 2.02E+08 Schwarz criterion 19.20911
Log likelihood -304.7126 F-statistic 122.5782
Durbin-Watson stat 2.989812 Prob(F-statistic) 0.000000
可决系数很大,拟合优度很高;F统计量的P值很小,模型显著性很强;T的P值很小,显著性很强,但第二个解释变量的p值较大,只能在0.10水平勉强通过。
8_3
(1)利用excel做方差分析,结果如下:
方差分析
差异源SS df MS F P-value F crit
组间 3.05E+08 1 3.05E+08 17.11138 9.91E-05 3.981896
组内 1.21E+09 68 17828696
总计 1.52E+09 69
F值较大,P值很小,城镇和农村这一因素对消费水平有显著影响。
(2)
C -378.5949 50.52334 -7.493464 0.0000
X1 1.996761 0.259904 7.682677 0.0000
R-squared 0.997087 Mean dependent var 3441.571
Adjusted R-squared 0.996905 S.D. dependent var 3709.172
S.E. of regression 206.3361 Akaike info criterion 13.57871
Sum squared resid 1362387. Schwarz criterion 13.71202
Log likelihood -234.6274 F-statistic 5477.540
Durbin-Watson stat 0.270419 Prob(F-statistic) 0.000000
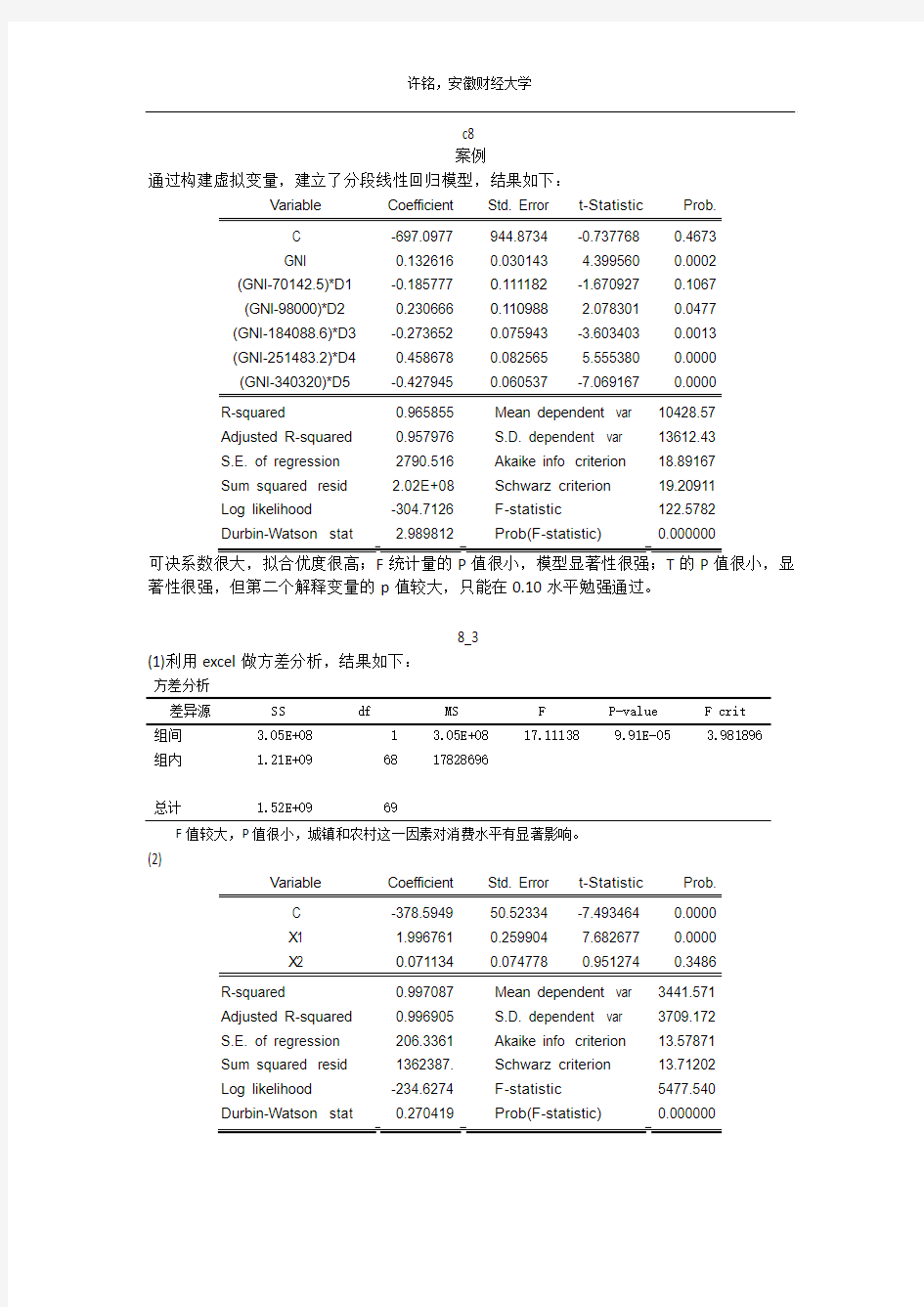
(1) 由能源消费的时间序列图,可以发现:在2000年后我国的能源消耗增长速度加快,故
设定虚拟变量d ,有
d ={0 t ≤20001 t >2000
简单线性模型:
Variable Coefficient Std. Error t-Statistic Prob. C -16460359 1114924. -14.76366 0.0000 T
8327.553
558.8520
14.90118
0.0000 R-squared
0.870611 Mean dependent var 153108.8 Adjusted R-squared 0.866690 S.D. dependent var 91453.42 S.E. of regression 33391.11 Akaike info criterion 23.72541 Sum squared resid 3.68E+10 Schwarz criterion 23.81429 Log likelihood -413.1947 F-statistic 222.0451 Durbin-Watson stat
0.061020 Prob(F-statistic)
0.000000
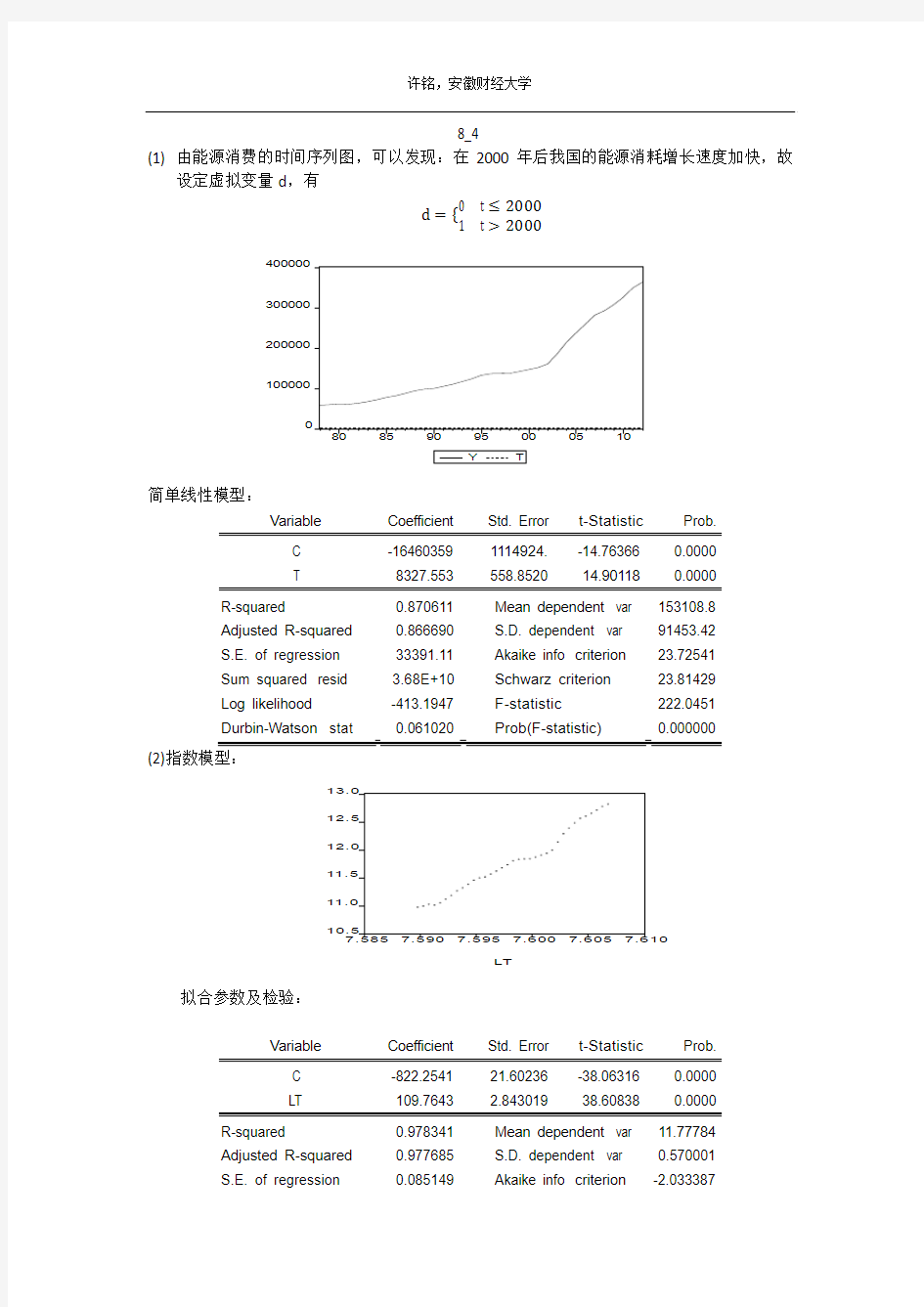
(2)指数模型:
拟合参数及检验:
Variable Coefficient Std. Error t-Statistic Prob. C -822.2541 21.60236 -38.06316 0.0000 LT
109.7643
2.843019
38.60838
0.0000 R-squared
0.978341 Mean dependent var 11.77784 Adjusted R-squared 0.977685 S.D. dependent var 0.570001 S.E. of regression
0.085149 Akaike info criterion
-2.033387
100000
200000
300000
400000
80
85
90
950005
10
10.5
11.011.512.0
12.5
13.0
7.585
7.5907.595
7.6007.6057.610
LT
L Y
Sum squared resid 0.239261 Schwarz criterion -1.944510
Log likelihood 37.58427 F-statistic 1490.607
Durbin-Watson stat 0.160793 Prob(F-statistic) 0.000000
有虚拟变量的线性模型:
C -12549532 1799724. -6.973031 0.0000
T 6358.489 904.8343 7.027241 0.0000
DD*T 25.37381 9.594945 2.644497 0.0126 R-squared 0.893817 Mean dependent var 153108.8
Adjusted R-squared 0.887180 S.D. dependent var 91453.42
S.E. of regression 30717.97 Akaike info criterion 23.58490
Sum squared resid 3.02E+10 Schwarz criterion 23.71822
Log likelihood -409.7357 F-statistic 134.6828
Durbin-Watson stat 0.171680 Prob(F-statistic) 0.000000
指数模型的拟合效果最好。
8_5
(1)首先,通过excel做有重复的双因素方差分析,结果如下:
方差分析
差异源SS df MS F P-value F crit
样本 1.35E+08 2 67374615 33.4505 1.15E-07 3.402826
列 4.48E+08 1 4.48E+08 222.2067 1.24E-13 4.259677
交互89518873 2 44759437 22.2224 3.46E-06 3.402826
内部48339805 24 2014159
总计7.2E+08 29
由F统计量可知,无论是学历还是是否管理层,都对各自和交互对工资有显著影响。设学历的虚拟变量和管理层的虚拟变量,其中e1代表本科学历,e2代表研究生学历,m代表管理层,做多元线性回归,结果如下:
C 8035.598 386.6893 20.78050 0.0000
X546.1840 30.51919 17.89641 0.0000
E1 3144.035 361.9683 8.685941 0.0000
E2 2996.210 411.7527 7.276723 0.0000
R-squared 0.956767 Mean dependent var 17270.20
Adjusted R-squared 0.952549 S.D. dependent var 4716.632
S.E. of regression 1027.437 Akaike info criterion 16.80984
Sum squared resid 43280719 Schwarz criterion 17.00861
Log likelihood -381.6264 F-statistic 226.8359
Durbin-Watson stat 2.236925 Prob(F-statistic) 0.000000
T统计值很大,各个变量的显著性都很强;DW统计值接近2,无自相关;若考虑交互作用,分别设本科生和管理层的乘积变量M1和研究生和管理层的乘积变量M2;做多元线性回归,
结果如下:
Variable Coefficient Std. Error t-Statistic Prob. C 9472.685 80.34365 117.9021 0.0000 X 496.9870 5.566415 89.28314 0.0000 E1 1381.671 77.31882 17.86978 0.0000 E2 1730.748 105.3339 16.43107 0.0000 M 3981.377 101.1747 39.35150 0.0000 M1 4902.523 131.3589 37.32158 0.0000 M2
3066.035
149.3304
20.53188
0.0000 R-squared
0.998823 Mean dependent var 17270.20 Adjusted R-squared 0.998642 S.D. dependent var 4716.632 S.E. of regression 173.8086 Akaike info criterion 13.29305 Sum squared resid 1178168. Schwarz criterion 13.57133 Log likelihood -298.7403 F-statistic 5516.596 Durbin-Watson stat
2.244104 Prob(F-statistic)
0.000000
无自相关。由残差图可见,误差较小,围绕0水平上下波动。模型拟合效果很好。
格兰杰因果检验
S does not Granger Cause M2
44
0.11809 0.88893 M2 does not Granger Cause S 0.85619 0.43261 X does not Granger Cause S
44 5.73103 0.00658 S does not Granger Cause X 0.25219 0.77835 S does not Granger Cause M1
44 1.85559 0.16990 M1 does not Granger Cause S 4.26486 0.02113 S does not Granger Cause M
44 0.75865 0.47508 M does not Granger Cause S 1.96170 0.15425 S does not Granger Cause E2
44 2.60713 0.08656 E2 does not Granger Cause S 0.86068 0.43075 S does not Granger Cause E1
44 1.17365 0.31992 E1 does not Granger Cause S
0.00643
0.99359
但是,通过格兰杰因果检验发现,虚拟变量对S 的影响多数不通过检验。
-1000
-5000500
10000
1500020000
25000300005
10
1520
25
30
35
4045
第五章练习题参考解答 练习题 5.1 设消费函数为 i i i i u X X Y +++=33221βββ 式中,i Y 为消费支出;i X 2为个人可支配收入;i X 3为个人的流动资产;i u 为随机误差 项,并且2 22)(,0)(i i i X u Var u E σ==(其中2 σ为常数) 。试回答以下问题: (1)选用适当的变换修正异方差,要求写出变换过程; (2)写出修正异方差后的参数估计量的表达式。 5.2 根据本章第四节的对数变换,我们知道对变量取对数通常能降低异方差性,但须对这种模型的随机误差项的性质给予足够的关注。例如,设模型为u X Y 21β β=,对该模型中的变量取对数后得如下形式 u X Y ln ln ln ln 21++=ββ (1)如果u ln 要有零期望值,u 的分布应该是什么? (2)如果1)(=u E ,会不会0)(ln =u E ?为什么? (3)如果)(ln u E 不为零,怎样才能使它等于零? 5.3 由表中给出消费Y 与收入X 的数据,试根据所给数据资料完成以下问题: (1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式; (2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。 Y X Y X Y X 55 80 152 220 95 140 65 100 144 210 108 145 70 85 175 245 113 150 80 110 180 260 110 160
79120135190125165 84115140205115180 98130178265130185 95140191270135190 90125137230120200 7590189250140205 741055580140210 1101607085152220 1131507590140225 12516565100137230 10814574105145240 11518080110175245 14022584115189250 12020079120180260 14524090125178265 13018598130191270 5.4由表中给出1985年我国北方几个省市农业总产值,农用化肥量、农用水利、农业劳动力、每日生产性固定生产原值以及农机动力数据,要求: (1)试建立我国北方地区农业产出线性模型; (2)选用适当的方法检验模型中是否存在异方差; (3)如果存在异方差,采用适当的方法加以修正。 地区农业总产值农业劳动力灌溉面积化肥用量户均固定农机动力(亿元)(万人)(万公顷)(万吨)资产(元)(万马力) 北京19.6490.133.847.5394.3435.3天津14.495.234.95 3.9567.5450.7河北149.91639 .0357.2692.4706.892712.6山西55.07562.6107.931.4856.371118.5内蒙古60.85462.996.4915.41282.81641.7辽宁87.48588.972.461.6844.741129.6吉林73.81399.769.6336.92576.81647.6黑龙江104.51425.367.9525.81237.161305.8山东276.552365.6456.55152.35812.023127.9河南200.022557.5318.99127.9754.782134.5陕西68.18884.2117.936.1607.41764 新疆49.12256.1260.4615.11143.67523.3 5.5表中的数据是美国1988研究与开发(R&D)支出费用(Y)与不同部门产品销售量
第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1 ②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2
案例 通过构建虚拟变量,建立了分段线性回归模型,结果如下: Variable Coefficient Std. Error t-Statistic Prob. C -697.0977 944.8734 -0.737768 0.4673 GNI 0.132616 0.030143 4.399560 0.0002 (GNI-70142.5)*D1 -0.185777 0.111182 -1.670927 0.1067 (GNI-98000)*D2 0.230666 0.110988 2.078301 0.0477 (GNI-184088.6)*D3 -0.273652 0.075943 -3.603403 0.0013 (GNI-251483.2)*D4 0.458678 0.082565 5.555380 0.0000 R-squared 0.965855 Mean dependent var 10428.57 Adjusted R-squared 0.957976 S.D. dependent var 13612.43 S.E. of regression 2790.516 Akaike info criterion 18.89167 Sum squared resid 2.02E+08 Schwarz criterion 19.20911 Log likelihood -304.7126 F-statistic 122.5782 Durbin-Watson stat 2.989812 Prob(F-statistic) 0.000000 可决系数很大,拟合优度很高;F统计量的P值很小,模型显著性很强;T的P值很小,显著性很强,但第二个解释变量的p值较大,只能在0.10水平勉强通过。 8_3 (1)利用excel做方差分析,结果如下: 方差分析 差异源SS df MS F P-value F crit 组间 3.05E+08 1 3.05E+08 17.11138 9.91E-05 3.981896 组内 1.21E+09 68 17828696 总计 1.52E+09 69 F值较大,P值很小,城镇和农村这一因素对消费水平有显著影响。 (2) C -378.5949 50.52334 -7.493464 0.0000 X1 1.996761 0.259904 7.682677 0.0000 R-squared 0.997087 Mean dependent var 3441.571 Adjusted R-squared 0.996905 S.D. dependent var 3709.172 S.E. of regression 206.3361 Akaike info criterion 13.57871 Sum squared resid 1362387. Schwarz criterion 13.71202 Log likelihood -234.6274 F-statistic 5477.540 Durbin-Watson stat 0.270419 Prob(F-statistic) 0.000000
思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议,
计量经济学作业第5章(含答案)
第5章习题 一、单项选择题 1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为() A. m B. m-1 C. m+1 D. m-k 2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。现以1991年为转折时期,设虚拟变 量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可以写作() A. B. C. D. 3.对于有限分布滞后模型 在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足() A. B. C. D. 4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( ) A. 增加1个 B. 减少1个 C. 增加2个 D. 减少2个 5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为() A.异方差问题 B. 多重共线性问题
C.序列相关性问题 D. 设定误差问题 6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为() A. 4 B. 3 C. 2 D. 1 7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(Y代表消费支出;X代表可支配收入;D 2、D 3 表示虚拟变量)() A. B. C. D. 二、多项选择题 1.以下变量中可以作为解释变量的有() A. 外生变量 B. 滞后内生变量 C. 虚拟变量 D. 先决变量 E. 内生变量 2.关于衣着消费支出模型为:,其中 Y i 为衣着方面的年度支出;X i 为收入, ? ? ? =女性 男性 1 2i D; ? ? ? =大学毕业及以上 其他 1 3i D 则关于模型中的参数下列说法正确的是() A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额 B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额 C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 三、判断题
《计量经济学》要点 一、单项选择题 知识点: 第一章 若干定义、概念 时间序列数据定义 横截面数据定义 1.同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据 B、时间序列数据 C、修匀数据 D、原始数据 2.同一时间,不同单位相同指标组成的观测数据称为( B ) A.原始数据B.横截面数据 C.时间序列数据D.修匀数据 变量定义(被解释变量、解释变量、内生变量、外生变量) 单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量); 3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 什么是解释变量、被解释变量? 从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。 在模型中,解释变量是变动的原因,被解释变量是变动的结果。 被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。 解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。 因此,被解释变量只能由内生变量担任,不能由非内生变量担任。 4.单方程计量经济模型中可以作为被解释变量的是( C ) A、控制变量 B、前定变量 C、内生变量 D、外生变量 5.单方程计量经济模型的被解释变量是(A ) A、内生变量 B、政策变量 C、控制变量 D、外生变量 6.在回归分析中,下列有关解释变量和被解释变量的说法正确的有(C) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 双对数模型中参数的含义; 7.双对数模型 01 ln ln ln Y X ββμ =++中,参数1 β的含义是(D ) A .X的相对变化,引起Y的期望值绝对量变化 B.Y关于X的边际变化 C.X的绝对量发生一定变动时,引起因变量Y 的相对变化率 D.Y关于X的弹性 8.双对数模型μ β β+ + =X Y ln ln ln 1 中,参数1 β的含义是( C ) A. Y关于X的增长率 B .Y关于X的发展速度 C. Y关于X的弹性 D. Y关于X 的边际变化 计量经济学研究方法一般步骤 四步12点 9.计量经济学的研究方法一般分为以下四个步骤( B ) A.确定科学的理论依据、模型设定、模型修定、模型应用 B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用 对计量经济模型应当进行哪些方面的检验? 经济意义检验:检验模型估计结果,尤其是参数
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常
第一章导论 一、单项选择题 1-6: CCCBCAC 二、多项选择题 ABCD;ACD;ABCD 三.问答题 什么是计量经济学? 答案见教材第3页 四、案例分析题 假定让你对中国家庭用汽车市场发展情况进行研究,应该分哪些步骤,分别如何分析?(参考计量经济学研究的步骤) 第一步:选取被研究对象的变量:汽车销售量 第二步:根据理论及经验分析,寻找影响汽车销售量的因素,如汽车价格,汽油价格,收入水平等 第三步:建立反映汽车销售量及其影响因素的计量经济学模型 第四步:估计模型中的参数; 第五步:对模型进行计量经济学检验、统计检验以及经济意义检验; 第六步:进行结构分析及在给定解释变量的情况下预测中国汽车销售量的未来值为汽车业的发展提供政策实施依据。 第二章简单线性回归模型 一、填空题 1、线性、无偏、最小方差性(有效性),BLUE。 2、解释变量;参数;参数。 3、随机误差项;随机误差项。 二、单项选择题 1-4:BBDA;6-11:CDCBCA 三、多项选择题 1.ABC; 2.ABC; 3.BC; 4.ABE; 5.AD; 6.BC 四、判断正误: 1. 错; 2. 错; 3. 对; 4.错; 5. 错; 6. 对; 7. 对; 8.错 五、简答题: 1.为什么模型中要引入随机扰动项? 答:模型是对经济问题的一种数学模型,在模型中,被解释变量是研究的对象,解释变量是其确定的解释因素,但由于实际问题的错综复杂,影响被解释变量的因素中,除了包括在模型中的解释变量以外,还有其他一些因素未能包括在模型中,但却影响被解释变量,我们把这类变量统一用随机误差项表示。随机误差项包含的因素有:
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
计量经济学 第一章导论 一节什么是计量经济学 统计学,经济学,数学的结合 二节研究步骤 一、模型假定 估计解释变量与被解释变量的关系,设置随机扰动项μ 二、估计参数 通过变量的样本观测值合理的估计总体模型的参数,是计量经济学的核心内容三、模型检验 (1)经济意义检验,检验所估计的模型与经济理论是否相符 (2)统计推断信息,检验参数估计值是否是抽样的偶然结果,需要运用数理统计中统计推断方法对模型及参数的统计可靠性作出说明 (3)计量经济学检验,t检验和F检验 检验模型是否符合计量经济学假定,如多重共线性,随机扰动项的自相关和异方差性 (4)模型预测检验 四、模型应用 三节变量参数数据与模型 一、变量 经济变量:在不同的时间或空间有不同状态,回去不同的数值且可观测 eg.居民家庭收入X和居民消费支出Y 分类: (1)流量与存量(2)解释变量/自变量与被解释变量/因变量(3)内生变量(由模型所决定的变量,是模型求解的结果)和外生变量(由模型以外决定的变量)二、参数的估计
所得到的参数估计值迎“尽可能接近总体参数真实值”原则 三、计量经济学中应用的数据 (1)时间序列数据 (2)截面数据 (3)面板数据 (4)虚拟变量数据 二章简单线性回归模型 一节回归分析与回归函数 一、相关分析与回归分析 (一)经济变量之间的相关关系 经济变量之间有两种关系,一种是确定性的函数关系,另一种是不确定的统计关系,也叫相关关系。 当一个或若干个变量x取一定值时,与之对应的另一个变量Y的值虽然不确定,但按照某种规律在一定范围内变化,称这种变量之间的关系为不确定的统计关系或相关关系。 分类 (1)简单相关关系/多重相关关系 (2)线性相关/非线性相关 (3)正相关/负相关 (4)完全相关/不相关
计量经济学作业第5章(含答案)
、单项选择题 1 ?对于一个含有截距项的计量经济模型,若某定性因素有 D. m-k 2 ?在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例 如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出 丫 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 [1 1991# WS D =< 量 r [O f 1毀坪以前,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。贝U 城镇居民线性消费函数的理论方程 可以写作( ) A. h 二几+耳扎+如)拓+斗 3. 对于有限分布滞后模型 在一定条件下,参数儿可近似用一个关于【的阿尔蒙多项式表示 ),其中多项式的阶数 m 必须满足( ) A .障匚上 B . m k C . D .用上上 4. 对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数 据就会( ) A.增加1个 B.减少1个 C.增加2个 D.减 少2个 5. 经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序 列相关性就转化为( ) A. m B. m-1 C. m+1 将其引入模型中,则需要引入虚拟变量个数为( m 个互斥的类型,为 ) B. C. Y 讦 A+ +"0+ 斗 D.
A.异方差冋 题 B.多重 共线性问题
问题 6. 将一年四个季度对因变量的影响引入到模型中(含截 距项),则需要引入虚 拟变量的个数为( ) A. 4 B. 3 C. 2 D. 1 7. 若 想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(丫代表消费支出;X 代表可支配收入;D 2、D 3表示虚拟变量) () A.Yj"+陆+野 B . 二、多项选择题 1. 以下变量中可以作为解释变量的有 ( ) A.外生变量 B.滞后内生变量 C.虚 拟变量 D.先决变量 E.内生变量 2. 关于衣着消费支出模型为:h 吗+叩左+必史+勺3工』』+ "逅+色,其中 丫为衣着万面的年度支出;X 为收入, 1 女性 "i 大学毕业及以上 D = : D 3i =J o 男性, 3i 其他 则关于模型中的参数下列说法正确的是( ) A. $表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出 (或少 支出)差额 B. 珂表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消 费支 出方面多支出(或少支出)差额 C. 5表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以 下文凭 者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消 费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 、判断题 1 ?通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容 C.序列相关性问题 D.设定误差 £ =坷++以叭JQ+舛 C. 】 D 丄吗皿吗+风+儿
第八章练习题及参考解答 8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型: 2.409.39ln 3.36((ln 7))i i i i Y X D X =-+-- (4.37) (0.857) (2.42) R 2=0.752 其中:X 是以美元计的人均收入;Y 是以年计的期望寿命; Sen 和Srivastava 认为人均收入的临界值为1097美元(ln10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。 括号内的数值为对应参数估计值的t-值。 1)解释这些计算结果。 2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释 依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时, ()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ?-+?+---==? -+=? 富国时 穷国时 表明贫富国之间的期望寿命存在差异。 2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。 3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命; 4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济
第五章习题2 根据经济理论建立计量经济模型 i i 10i X Y μββ++= 应用EViews 输出的结果如图1所示。 图1 用普通最小二乘法的估计结果如下: )29,...,2,1(707955.013179.58=+=∧ i X Y i i 利用上述结果计算残差∧ =i i i Y -Y e 。观察i e 的取值,好像随i X 的变化而变化,怀疑模型存在异方差性,下面通过等级相关系数和戈德菲尔特—夸特方法检验随机误差项的异方差性。 1.斯皮尔曼等级相关系数检验 按照斯皮尔曼等级相关检验的步骤,先将X 的样本观测值从小到大排列并划分等级,然后将i e 从小到大划分等级,计算i X 的等级与相应产生的i e 的等级的差i d 及2i d ,详见表1。 表1
计算等级相关系数 2334d 1 i 2i =∑= 0.42512329 -292334 6- 1N -N d 6- 1r 3 3 1i 2i =?==∑= 对等级相关系数进行检验,提出原假设与备择假设 ) ,(),(::28 1 0N 1-N 10N ~r 0 H 0H 10=≠=ρρ 构造Z 统计量 2.2495428*0.4251231 -N 1r Z ===
给定显著水平0.05=α,查正态分布表,得 1.96Z 2 =α因为 1.962.24954Z >=, 所以应拒绝原假设,接收备择假设,即等级相关系数显著,说明其随机误差项存在异方差性。 2. 戈德菲尔特—夸特方法检验 将X 的样本观测值按升序排列,Y 的样本观测值按原来与X 样本观测值的对应关系进行排列,略去中心7个数据,将剩下的22个样本观测值分成容量相等的两个子样本,每个子样本的样本观测值个数均为11。排列结果见表2。 用第一个子样本估计模型,得到的结果如图2所示: 图2
第二章 回归模型思考与练习参考答案 2.1参考答案 ⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。 现实经济中,这些假定难以成立。要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。 ⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。参数估计的均方误为 MSE ()i i b b ?=E ()2?i i b b -=D ()i b ?=()[]ii u 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。而参数估计的方差又源于总体方差。因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。 ⑶答:总体回归模型 ()i i i x y E y ε+= 样本回归模型i i i e y y +=? i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值() i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i y ?的偏差。 i e 在概念上类似于i ε,是对i ε的估计。 对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。 ⑷答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。 ()()()k k n R R k n Model Total k Model k m Error k Model F 111122--?-=---=--= 由02>??R F 可知,F 是2R 的单调增函数。对每一个临界值?F ,都可以找到一个2?R 与之对应,当22?>R R 时便有?>F F 。 ⑸答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。 ⑹答:如果模型通过了F 检验,则表明模型中所有解释变量对被解释变量的影响显著。但这并不说明多个解释变量的影响都是显著的。建模开始时,常根据先验知识尽可能找出影响被解释变量的所有因素,这样就可能会选择不重要的因素作为解释变量。对单个解释变量的显著性检验可以剔除这些不重要的影响因素。 ⑺答:考虑两个经济变量y 与x ,及一组观测值(){},,2,1,,n i y x i i =。
计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从