
第8章练习5
证明:对方程
ε
β
t
t
t
X Y
1+=两边同时减去
Y
t 1
-,得:εβ
t t t
t
Y
X Y
11
+-=?
-
然后对该式等号右边加上再减去一个X
t 1
-β
,得:
εβ
β
β
t t t t t t X
X
Y
X Y 11
1
1
+-+-=?---
()ε
β
βt
t t t
X Y
X 11
1
+--=--?
将第二个方程εαt t t
X X
21+?=?
-代入,得:
()()ε
εβ
αβt
t t t t t X Y X Y 11121+--+?=?--- ()ε
εββ
βαt
t
t t t X Y X
211
11
++--?
=---
()εαβδt
t t t X Y X +-+?=---1
1
1
1
其中,
βαα
=1
,1-=δ,εεεβt t t 21+=
第8章练习8
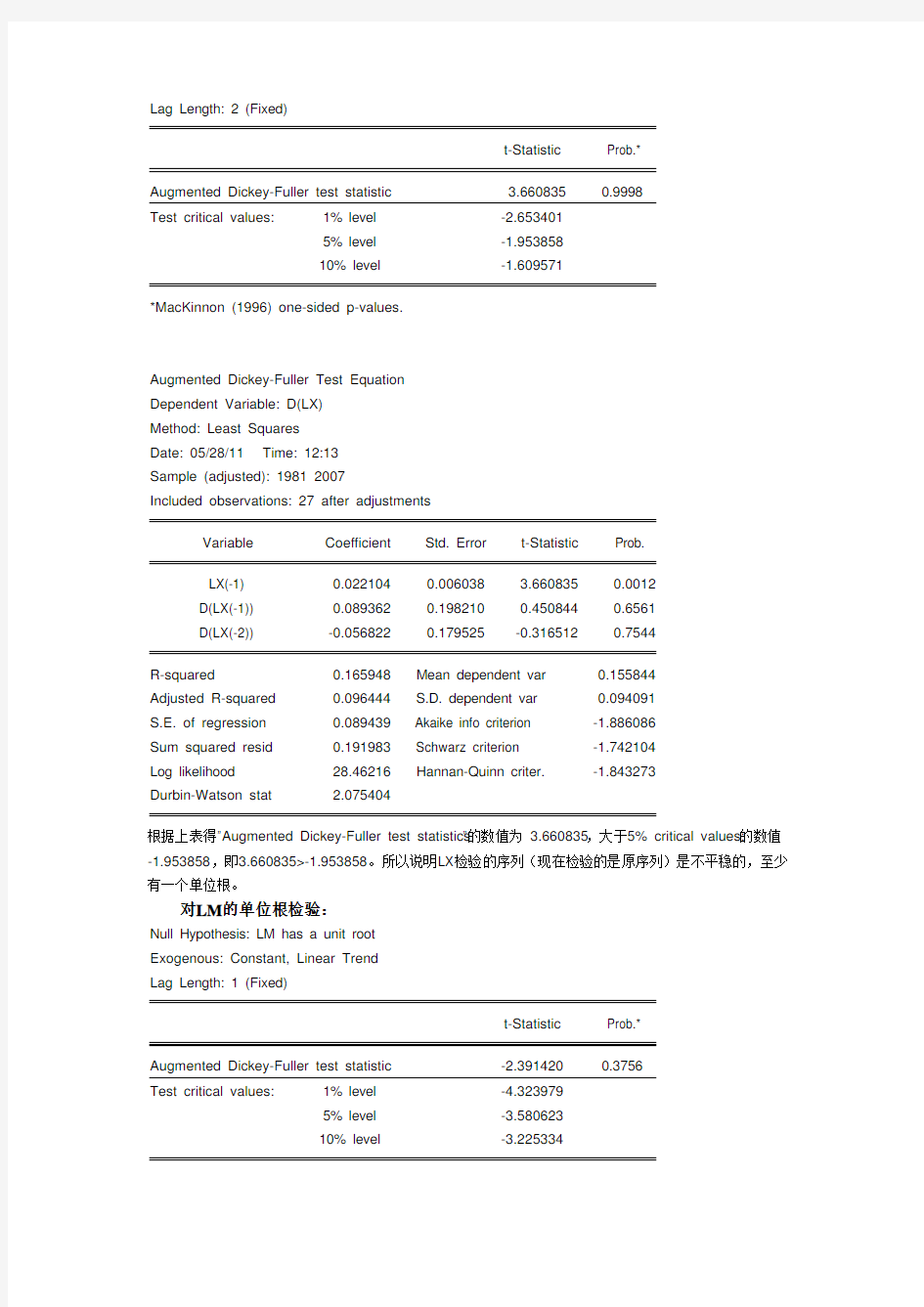
(1) 解:根据Eview 软件操作得:对1978-2007年中国货物进、出口额的自然对数系列
LX , LM 的单位根检验分别如下: 对LX 的单位根检验:
Null Hypothesis: LX has a unit root Exogenous: None
Lag Length: 2 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic 3.660835 0.9998
Test critical values: 1% level -2.653401
5% level -1.953858
10% level -1.609571
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(LX)
Method: Least Squares
Date: 05/28/11 Time: 12:13
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LX(-1) 0.022104 0.006038 3.660835 0.0012
D(LX(-1)) 0.089362 0.198210 0.450844 0.6561
D(LX(-2)) -0.056822 0.179525 -0.316512 0.7544
R-squared 0.165948 Mean dependent var 0.155844
Adjusted R-squared 0.096444 S.D. dependent var 0.094091
S.E. of regression 0.089439 Akaike info criterion -1.886086
Sum squared resid 0.191983 Schwarz criterion -1.742104
Log likelihood 28.46216 Hannan-Quinn criter. -1.843273
Durbin-Watson stat 2.075404
根据上表得”Augmented Dickey-Fuller test statistics”的数值为 3.660835,大于5% critical values:的数值-1.953858,即3.660835>-1.953858。所以说明LX检验的序列(现在检验的是原序列)是不平稳的,至少有一个单位根。
对LM的单位根检验:
Null Hypothesis: LM has a unit root
Exogenous: Constant, Linear Trend
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -2.391420 0.3756
Test critical values: 1% level -4.323979
5% level -3.580623
10% level -3.225334
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(LM)
Method: Least Squares
Date: 05/28/11 Time: 13:22
Sample (adjusted): 1980 2007
Included observations: 28 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LM(-1) -0.366456 0.153238 -2.391420 0.0250
D(LM(-1)) 0.413168 0.191216 2.160746 0.0409
C 1.767965 0.712477 2.481434 0.0205
@TREND(1978) 0.052495 0.020853 2.517424 0.0189
R-squared 0.261758 Mean dependent var 0.146821
Adjusted R-squared 0.169478 S.D. dependent var 0.131779
S.E. of regression 0.120094 Akaike info criterion -1.269523
Sum squared resid 0.346141 Schwarz criterion -1.079208
Log likelihood 21.77333 Hannan-Quinn criter. -1.211342
F-statistic 2.836560 Durbin-Watson stat 1.832088
Prob(F-statistic) 0.059412
根据上表得”Augmented Dickey-Fuller test statistics”的数值为 -2.391420,大于5% critical values:的数值-3.580623,即 -2.391420>-3.580623。所以说明LM检验的序列(现在检验的是原序列)是不平稳的,至少有一个单位根。
附:LX,LM的时间序列图如下:
(2)根据Eview软件操作得:
LX的单整性:
Null Hypothesis: D(LX) has a unit root
Exogenous: Constant
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.339047 0.0229
Test critical values: 1% level -3.699871
5% level -2.976263
10% level -2.627420
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(LX,2)
Method: Least Squares
Date: 05/28/11 Time: 13:07
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
D(LX(-1)) -0.802671 0.240389 -3.339047 0.0027
D(LX(-1),2) 0.006699 0.192327 0.034830 0.9725
C 0.124722 0.042553 2.931004 0.0073
R-squared 0.410284 Mean dependent var -0.001996
Adjusted R-squared 0.361141 S.D. dependent var 0.119873
S.E. of regression 0.095813 Akaike info criterion -1.748399
Sum squared resid 0.220323 Schwarz criterion -1.604418
Log likelihood 26.60339 Hannan-Quinn criter. -1.705586
F-statistic 8.348774 Durbin-Watson stat 1.994367
Prob(F-statistic) 0.001769
根据上面表格得”Augmented Dickey-Fuller test statistics”的数值为 -3.339047,小于5% critical values:的数值-2.976263,即 -3.339047<-2.976263,这就说明LX检验的序列(现在检验的是一次差分序列)是平稳的,所以LX序列为1阶单整序列。
LM的单整性:
Null Hypothesis: D(LM) has a unit root
Exogenous: Constant
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -5.027427 0.0004
Test critical values: 1% level -3.699871
5% level -2.976263
10% level -2.627420
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(LM,2)
Method: Least Squares
Date: 05/28/11 Time: 13:32
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
D(LM(-1)) -1.129241 0.224616 -5.027427 0.0000
D(LM(-1),2) 0.410044 0.175547 2.335808 0.0282
C 0.164725 0.040855 4.031969 0.0005
R-squared 0.520213 Mean dependent var -0.002081
Adjusted R-squared 0.480230 S.D. dependent var 0.170029
S.E. of regression 0.122583 Akaike info criterion -1.255623
Sum squared resid 0.360636 Schwarz criterion -1.111641
Log likelihood 19.95091 Hannan-Quinn criter. -1.212810
F-statistic 13.01108 Durbin-Watson stat 2.003569
Prob(F-statistic) 0.000149
根据上面表格得”Augmented Dickey-Fuller test statistics”的数值为-5.027427,小于5% critical values:的数值-2.976263,即 -5.027427<-2.976263,这就说明LM检验的序列(现在检验的是一次差分序列)是平稳的,所以LM序列为1阶单整序列。
(3).根据Eview软件操作得:
检验形式1:
Date: 05/28/11 Time: 13:50
Sample (adjusted): 1980 2007
Included observations: 28 after adjustments
Trend assumption: No deterministic trend
Series: LX LM
Lags interval (in first differences): 1 to 1
Unrestricted Cointegration Rank Test (Trace)
Hypothesized Trace 0.05
No. of CE(s) Eigenvalue Statistic Critical Value Prob.**
None * 0.385283 20.27831 12.32090 0.0019
At most 1 * 0.211508 6.653716 4.129906 0.0117
Trace test indicates 2 cointegrating eqn(s) at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegration Rank Test (Maximum Eigenvalue)
Hypothesized Max-Eigen 0.05
No. of CE(s) Eigenvalue Statistic Critical Value Prob.**
None * 0.385283 13.62459 11.22480 0.0186
At most 1 * 0.211508 6.653716 4.129906 0.0117
Max-eigenvalue test indicates 2 cointegrating eqn(s) at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegrating Coefficients (normalized by b'*S11*b=I):
LX LM
2.662861 -2.984473
6.889796 -6.895310
Unrestricted Adjustment Coefficients (alpha):
D(LX) -0.063612 0.000295
D(LM) -0.036742 0.056494
1 Cointegrating Equation(s): Log likelihood 49.93444
Normalized cointegrating coefficients (standard error in parentheses)
LX LM
1.000000 -1.120777
(0.02827)
Adjustment coefficients (standard error in parentheses)
D(LX) -0.169391
(0.04279)
D(LM) -0.097838
(0.06993)
根据上面表格得: 20.27831> 12.32090和 13.62459> 11.22480,,这说明了至少有一个协整关系存在。上述协整检验结果表明两个变量LX、LM之间存在协整关系。
检验形式2:
Date: 05/28/11 Time: 13:54
Sample (adjusted): 1980 2007
Included observations: 28 after adjustments
Trend assumption: No deterministic trend (restricted constant)
Series: LX LM
Lags interval (in first differences): 1 to 1
Unrestricted Cointegration Rank Test (Trace)
Hypothesized Trace 0.05
No. of CE(s) Eigenvalue Statistic Critical Value Prob.**
None * 0.478989 27.49647 20.26184 0.0042 At most 1 * 0.281100 9.240922 9.164546 0.0484
Trace test indicates 2 cointegrating eqn(s) at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegration Rank Test (Maximum Eigenvalue)
Hypothesized Max-Eigen 0.05
No. of CE(s) Eigenvalue Statistic Critical Value Prob.**
None * 0.478989 18.25555 15.89210 0.0209 At most 1 * 0.281100 9.240922 9.164546 0.0484
Max-eigenvalue test indicates 2 cointegrating eqn(s) at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegrating Coefficients (normalized by b'*S11*b=I):
LX LM C
-6.499892 7.331780 -3.773177
5.676638 -5.917603 2.649028
Unrestricted Adjustment Coefficients (alpha):
D(LX) 0.063655 0.023968
D(LM) -0.000144 0.072295
1 Cointegrating Equation(s): Log likelihood 52.24991
Normalized cointegrating coefficients (standard error in parentheses)
LX LM C
1.000000 -1.127985 0.580498
(0.02979) (0.20010)
Adjustment coefficients (standard error in parentheses)
D(LX) -0.413754
(0.10441)
D(LM) 0.000935
(0.17726)
根据上面表格得: 27.49647> 20.26184和18.25555> 15.89210,,这说明了至少有一个协整关系存在。上述协整检验结果表明两个变量LX、LM之间存在协整关系。
注:上面两种检验形式不同,但得到的结论是一样的。
(4)根据Eview软件操作得:
对其进行最小二乘法回归分析:
Dependent Variable: LM
Method: Least Squares
Date: 05/28/11 Time: 14:22
Sample: 1978 2007
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
C 0.503773 0.126081 3.995639 0.0004
LX 0.922623 0.018076 51.04170 0.0000
R-squared 0.989367 Mean dependent var 6.824200
Adjusted R-squared 0.988987 S.D. dependent var 1.238187
S.E. of regression 0.129939 Akaike info criterion -1.179166
Sum squared resid 0.472755 Schwarz criterion -1.085753
Log likelihood 19.68749 Hannan-Quinn criter. -1.149282
F-statistic 2605.255 Durbin-Watson stat 0.966431
Prob(F-statistic) 0.000000
对其进行加入LM滞后一期的最小二乘法回归分析:
Dependent Variable: LM
Method: Least Squares
Date: 05/28/11 Time: 14:25
Sample (adjusted): 1979 2007
Included observations: 29 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 0.319027 0.150002 2.126811 0.0431
LX 0.506574 0.170816 2.965621 0.0064
LM(-1) 0.455077 0.186703 2.437443 0.0219
R-squared 0.990355 Mean dependent var 6.897779
Adjusted R-squared 0.989613 S.D. dependent var 1.191488
S.E. of regression 0.121434 Akaike info criterion -1.281197
Sum squared resid 0.383401 Schwarz criterion -1.139752
Log likelihood 21.57735 Hannan-Quinn criter. -1.236898
F-statistic 1334.807 Durbin-Watson stat 1.227138
Prob(F-statistic) 0.000000
格兰杰因果关系检验:
滞后一阶:
Pairwise Granger Causality Tests
Date: 05/28/11 Time: 14:27
Sample: 1978 2007
Lags: 1
Null Hypothesis: Obs F-Statistic Prob.
LM does not Granger Cause LX 29 5.54910 0.0263
LX does not Granger Cause LM 0.99136 0.3286
根据上面表格可得:LM是LX的格兰杰原因的接受率是0.0263,LX不是LM的格兰杰原因的接受率是0.3286 滞后二阶:
Pairwise Granger Causality Tests
Date: 05/28/11 Time: 14:27
Sample: 1978 2007
Lags: 2
Null Hypothesis: Obs F-Statistic Prob.
LM does not Granger Cause LX 28 3.26580 0.0564
LX does not Granger Cause LM 1.94402 0.1659
根据上面表格可得:LM不是LX的格兰杰原因的接受率是0.0564,LX不是LM的格兰杰原因的接受率是:0.1659
ARMAj检验
Dependent Variable: LM
Method: Least Squares
Date: 05/28/11 Time: 15:37
Sample (adjusted): 1979 2007
Included observations: 29 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 0.319027 0.150002 2.126811 0.0431 LX 0.506574 0.170816 2.965621 0.0064 LM(-1)
0.455077
0.186703
2.437443
0.0219
R-squared 0.990355 Mean dependent var 6.897779 Adjusted R-squared 0.989613 S.D. dependent var 1.191488 S.E. of regression 0.121434 Akaike info criterion -1.281197 Sum squared resid 0.383401 Schwarz criterion -1.139752 Log likelihood 21.57735 Hannan-Quinn criter. -1.236898 F-statistic 1334.807 Durbin-Watson stat 1.227138 Prob(F-statistic) 0.000000
根据上面表格可得:=∧
?M
t
L
0.319+0.51M X
T t
L L
146.0-?+?
(2.13) (2.97) (2.44)
990355.02
=R
LM (1)=0.10 LM (2)=0.56
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
计量经济学题库Array一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学 C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量 C.被解释变量D.前定变量 4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据 C.时间序列数据D.横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量 C.滞后变量D.前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型 C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量 C.内生变量D.外生变量 9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型 B.设定模型→估计参数→检验模型→应用模型
第五章练习题参考解答 练习题 5.1 设消费函数为 i i i i u X X Y +++=33221βββ 式中,i Y 为消费支出;i X 2为个人可支配收入;i X 3为个人的流动资产;i u 为随机误差 项,并且2 22)(,0)(i i i X u Var u E σ==(其中2 σ为常数) 。试回答以下问题: (1)选用适当的变换修正异方差,要求写出变换过程; (2)写出修正异方差后的参数估计量的表达式。 5.2 根据本章第四节的对数变换,我们知道对变量取对数通常能降低异方差性,但须对这种模型的随机误差项的性质给予足够的关注。例如,设模型为u X Y 21β β=,对该模型中的变量取对数后得如下形式 u X Y ln ln ln ln 21++=ββ (1)如果u ln 要有零期望值,u 的分布应该是什么? (2)如果1)(=u E ,会不会0)(ln =u E ?为什么? (3)如果)(ln u E 不为零,怎样才能使它等于零? 5.3 由表中给出消费Y 与收入X 的数据,试根据所给数据资料完成以下问题: (1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式; (2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。 Y X Y X Y X 55 80 152 220 95 140 65 100 144 210 108 145 70 85 175 245 113 150 80 110 180 260 110 160
79120135190125165 84115140205115180 98130178265130185 95140191270135190 90125137230120200 7590189250140205 741055580140210 1101607085152220 1131507590140225 12516565100137230 10814574105145240 11518080110175245 14022584115189250 12020079120180260 14524090125178265 13018598130191270 5.4由表中给出1985年我国北方几个省市农业总产值,农用化肥量、农用水利、农业劳动力、每日生产性固定生产原值以及农机动力数据,要求: (1)试建立我国北方地区农业产出线性模型; (2)选用适当的方法检验模型中是否存在异方差; (3)如果存在异方差,采用适当的方法加以修正。 地区农业总产值农业劳动力灌溉面积化肥用量户均固定农机动力(亿元)(万人)(万公顷)(万吨)资产(元)(万马力) 北京19.6490.133.847.5394.3435.3天津14.495.234.95 3.9567.5450.7河北149.91639 .0357.2692.4706.892712.6山西55.07562.6107.931.4856.371118.5内蒙古60.85462.996.4915.41282.81641.7辽宁87.48588.972.461.6844.741129.6吉林73.81399.769.6336.92576.81647.6黑龙江104.51425.367.9525.81237.161305.8山东276.552365.6456.55152.35812.023127.9河南200.022557.5318.99127.9754.782134.5陕西68.18884.2117.936.1607.41764 新疆49.12256.1260.4615.11143.67523.3 5.5表中的数据是美国1988研究与开发(R&D)支出费用(Y)与不同部门产品销售量
计量经济学题库 计算与分析题(每小题10分) 1 X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 求判定系数和相关系数。 5.有如下表数据
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济 C.统计 D.测量
案例 通过构建虚拟变量,建立了分段线性回归模型,结果如下: Variable Coefficient Std. Error t-Statistic Prob. C -697.0977 944.8734 -0.737768 0.4673 GNI 0.132616 0.030143 4.399560 0.0002 (GNI-70142.5)*D1 -0.185777 0.111182 -1.670927 0.1067 (GNI-98000)*D2 0.230666 0.110988 2.078301 0.0477 (GNI-184088.6)*D3 -0.273652 0.075943 -3.603403 0.0013 (GNI-251483.2)*D4 0.458678 0.082565 5.555380 0.0000 R-squared 0.965855 Mean dependent var 10428.57 Adjusted R-squared 0.957976 S.D. dependent var 13612.43 S.E. of regression 2790.516 Akaike info criterion 18.89167 Sum squared resid 2.02E+08 Schwarz criterion 19.20911 Log likelihood -304.7126 F-statistic 122.5782 Durbin-Watson stat 2.989812 Prob(F-statistic) 0.000000 可决系数很大,拟合优度很高;F统计量的P值很小,模型显著性很强;T的P值很小,显著性很强,但第二个解释变量的p值较大,只能在0.10水平勉强通过。 8_3 (1)利用excel做方差分析,结果如下: 方差分析 差异源SS df MS F P-value F crit 组间 3.05E+08 1 3.05E+08 17.11138 9.91E-05 3.981896 组内 1.21E+09 68 17828696 总计 1.52E+09 69 F值较大,P值很小,城镇和农村这一因素对消费水平有显著影响。 (2) C -378.5949 50.52334 -7.493464 0.0000 X1 1.996761 0.259904 7.682677 0.0000 R-squared 0.997087 Mean dependent var 3441.571 Adjusted R-squared 0.996905 S.D. dependent var 3709.172 S.E. of regression 206.3361 Akaike info criterion 13.57871 Sum squared resid 1362387. Schwarz criterion 13.71202 Log likelihood -234.6274 F-statistic 5477.540 Durbin-Watson stat 0.270419 Prob(F-statistic) 0.000000
四、简答题(每小题5分) 令狐采学 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。 2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步调。4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的?6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么?8.总体回归模型与样本回归模型的区别与联系。 9.试述回归阐发与相关阐发的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质?11.简述BLUE 的含义。 12.对多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型:01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归阐发中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。16.罕见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或
都是或都不是。 ①t t t u x b b y ++=310②t t t u x b b y ++=log 10 ③t t t u x b b y ++=log log 10④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10②t t t u x b b b y ++=)(210 ③t t t u x b b y +=)/(10④t b t t u x b y +-+=)1(11 0 19.什么是异方差性?试举例说明经济现象中的异方差性。 20.产生异方差性的原因及异方差性对模型的OLS 估计有何影响。21.检验异方差性的办法有哪些? 22.异方差性的解决办法有哪些?23.什么是加权最小二乘法?它的基本思想是什么? 24.样天职段法(即戈德菲尔特——匡特检验)检验异方差性的基来源根基理及其使用条件。 25.简述DW 检验的局限性。26.序列相关性的后果。27.简述序列相关性的几种检验办法。 28.广义最小二乘法(GLS )的基本思想是什么?29.解决序列相关性的问题主要有哪几种办法? 30.差分法的基本思想是什么?31.差分法和广义差分法主要区别是什么? 32.请简述什么是虚假序列相关。33.序列相关和自相关的概念和规模是否是一个意思? 34.DW 值与一阶自相关系数的关系是什么?35.什么是多重共线
计量经济学题库 、单项选择题(每小题1分) 1?计量经济学是下列哪门学科的分支学科(C)O A.统计学 B.数学 C.经济学 D.数理统计学 2?计量经济学成为一门独立学科的标志是(B)。 A. 1930年世界计量经济学会成立 B. 1933年《计量经济学》会刊出版 C. 1969年诺贝尔经济学奖设立 D. 1926年计量经济学(EConOIniCS) —词构造出来 3.外生变量和滞后变量统称为(D)O A.控制变量B?解释变量 C.被解释变量 D.前定变量 4.横截面数据是指(A)O A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)O A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据 6.在计量经济模型中,由模型系统部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是(B )o A.生变量 B.外生变量 C.滞后变量 D.前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是(A )o A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量 经济模型 &经济计量模型的被解释变量一定是(C )o A.控制变量 B.政策变量 C.生变量 D.外生变量 9.下面属于横截面数据的是(D )o A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )0 A.设定理论模型一收集样本资料一估计模型参数一检验模型 B.设定模型一估计参数一检验模型一应用模型 C:个体设计f总体估计f估计模型f应用模型D.确定模型导向一确定变量及方程式一估计模型一应用模型 11.将生变量的前期值作解释变量,这样的变量称为( A.虚拟变量 B.控制变量 12.( B )是具有一定概率分布的随机变量, A.外生变量 B.生变量 13.同一统计指标按时间顺序记录的数据列称为( A.横截面数据 B.时间序列数据据 14?计量经济模型的基本应用领域有( A.结构分析、经济预测、政策评价 C.消费需求分析、生产技术分析、 15.变量之间的关系可以分为两大类, A.函数关系与相关关系 C.正相关关系和负相关关系 D )0 C.政策变量 它的数值由模型本身决定。 C.前定变量 B )0 C.修匀数据 A )0 B.弹性分析、D.季度分析、它们是(A 乘数分析、政策模拟年度分析、中长期分析 )o B.线性相关关系和非线性相关关系D.简单相关关系和复杂相关关系 D ?滞后变量D.滞后变量D.原始数
计量经济学作业第5章(含答案)
第5章习题 一、单项选择题 1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为() A. m B. m-1 C. m+1 D. m-k 2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。现以1991年为转折时期,设虚拟变 量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可以写作() A. B. C. D. 3.对于有限分布滞后模型 在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足() A. B. C. D. 4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( ) A. 增加1个 B. 减少1个 C. 增加2个 D. 减少2个 5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为() A.异方差问题 B. 多重共线性问题
C.序列相关性问题 D. 设定误差问题 6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为() A. 4 B. 3 C. 2 D. 1 7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(Y代表消费支出;X代表可支配收入;D 2、D 3 表示虚拟变量)() A. B. C. D. 二、多项选择题 1.以下变量中可以作为解释变量的有() A. 外生变量 B. 滞后内生变量 C. 虚拟变量 D. 先决变量 E. 内生变量 2.关于衣着消费支出模型为:,其中 Y i 为衣着方面的年度支出;X i 为收入, ? ? ? =女性 男性 1 2i D; ? ? ? =大学毕业及以上 其他 1 3i D 则关于模型中的参数下列说法正确的是() A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额 B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额 C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 三、判断题
《计量经济学》要点 一、单项选择题 知识点: 第一章 若干定义、概念 时间序列数据定义 横截面数据定义 1.同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据 B、时间序列数据 C、修匀数据 D、原始数据 2.同一时间,不同单位相同指标组成的观测数据称为( B ) A.原始数据B.横截面数据 C.时间序列数据D.修匀数据 变量定义(被解释变量、解释变量、内生变量、外生变量) 单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量); 3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 什么是解释变量、被解释变量? 从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。 在模型中,解释变量是变动的原因,被解释变量是变动的结果。 被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。 解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。 因此,被解释变量只能由内生变量担任,不能由非内生变量担任。 4.单方程计量经济模型中可以作为被解释变量的是( C ) A、控制变量 B、前定变量 C、内生变量 D、外生变量 5.单方程计量经济模型的被解释变量是(A ) A、内生变量 B、政策变量 C、控制变量 D、外生变量 6.在回归分析中,下列有关解释变量和被解释变量的说法正确的有(C) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 双对数模型中参数的含义; 7.双对数模型 01 ln ln ln Y X ββμ =++中,参数1 β的含义是(D ) A .X的相对变化,引起Y的期望值绝对量变化 B.Y关于X的边际变化 C.X的绝对量发生一定变动时,引起因变量Y 的相对变化率 D.Y关于X的弹性 8.双对数模型μ β β+ + =X Y ln ln ln 1 中,参数1 β的含义是( C ) A. Y关于X的增长率 B .Y关于X的发展速度 C. Y关于X的弹性 D. Y关于X 的边际变化 计量经济学研究方法一般步骤 四步12点 9.计量经济学的研究方法一般分为以下四个步骤( B ) A.确定科学的理论依据、模型设定、模型修定、模型应用 B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用 对计量经济模型应当进行哪些方面的检验? 经济意义检验:检验模型估计结果,尤其是参数
计量经济学题库一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是()。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有()。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指()。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
计量经济学题库、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指( D )。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
计量经济学作业第5章(含答案)
、单项选择题 1 ?对于一个含有截距项的计量经济模型,若某定性因素有 D. m-k 2 ?在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例 如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出 丫 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 [1 1991# WS D =< 量 r [O f 1毀坪以前,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。贝U 城镇居民线性消费函数的理论方程 可以写作( ) A. h 二几+耳扎+如)拓+斗 3. 对于有限分布滞后模型 在一定条件下,参数儿可近似用一个关于【的阿尔蒙多项式表示 ),其中多项式的阶数 m 必须满足( ) A .障匚上 B . m k C . D .用上上 4. 对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数 据就会( ) A.增加1个 B.减少1个 C.增加2个 D.减 少2个 5. 经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序 列相关性就转化为( ) A. m B. m-1 C. m+1 将其引入模型中,则需要引入虚拟变量个数为( m 个互斥的类型,为 ) B. C. Y 讦 A+ +"0+ 斗 D.
A.异方差冋 题 B.多重 共线性问题
问题 6. 将一年四个季度对因变量的影响引入到模型中(含截 距项),则需要引入虚 拟变量的个数为( ) A. 4 B. 3 C. 2 D. 1 7. 若 想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(丫代表消费支出;X 代表可支配收入;D 2、D 3表示虚拟变量) () A.Yj"+陆+野 B . 二、多项选择题 1. 以下变量中可以作为解释变量的有 ( ) A.外生变量 B.滞后内生变量 C.虚 拟变量 D.先决变量 E.内生变量 2. 关于衣着消费支出模型为:h 吗+叩左+必史+勺3工』』+ "逅+色,其中 丫为衣着万面的年度支出;X 为收入, 1 女性 "i 大学毕业及以上 D = : D 3i =J o 男性, 3i 其他 则关于模型中的参数下列说法正确的是( ) A. $表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出 (或少 支出)差额 B. 珂表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消 费支 出方面多支出(或少支出)差额 C. 5表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以 下文凭 者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消 费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 、判断题 1 ?通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容 C.序列相关性问题 D.设定误差 £ =坷++以叭JQ+舛 C. 】 D 丄吗皿吗+风+儿