
基因表达谱测序
背景介绍
基因表达谱分析利用HiSeq 2000高通量测序平台对mRNA进行测序,获得10M读长为49nt的原始reads,每一个reads可以对应到相应的转录本,从而研究基因的表达差异情况。与转录组测序相比,基因表达谱分析要求的读长更短,测序通量更小,仅可用于基因表达差异的研究。该方法具有定量准、可重复性高、检测阈值宽、成本低等特点,能很好的替代以往的数字化表达谱分析。
技术路线
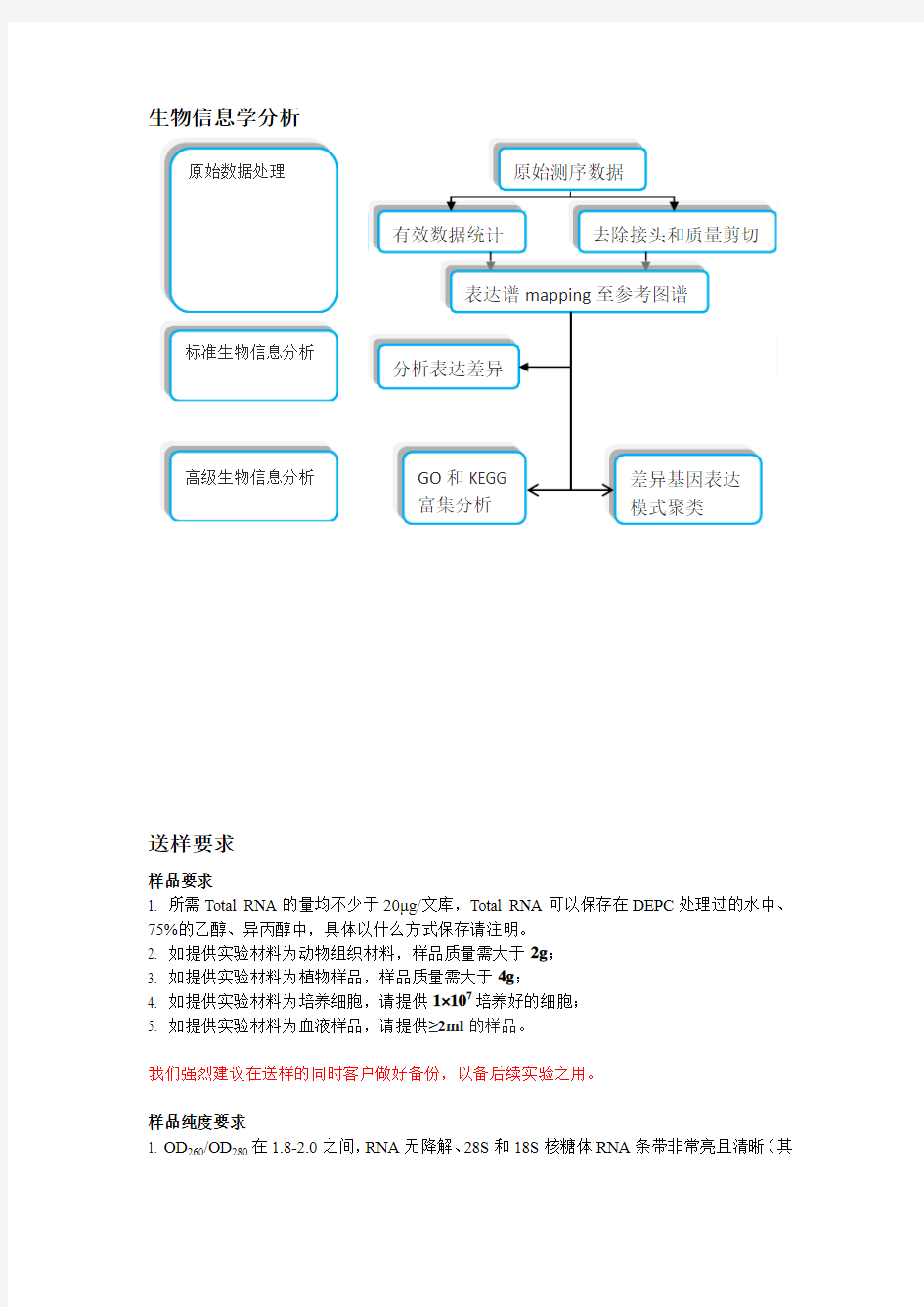
生物信息学分析
送样要求
样品要求
1. 所需Total RNA 的量均不少于
20μg/文库,Total RNA 可以保存在DEPC 处理过的水中、75%的乙醇、异丙醇中,具体以什么方式保存请注明。
2. 如提供实验材料为动物组织材料,样品质量需大于2g ;
3. 如提供实验材料为植物样品,样品质量需大于4g ;
4. 如提供实验材料为培养细胞,请提供1×107培养好的细胞;
5. 如提供实验材料为血液样品,请提供≥2ml 的样品。
我们强烈建议在送样的同时客户做好备份,以备后续实验之用。
样品纯度要求
1. OD 260/OD 280在1.8-
2.0之间,RNA 无降解、28S 和18S 核糖体RNA 条带非常亮且清晰(其
大小决定于用于抽提RNA的物种类型),28S的密度大约是18S的2倍;Agilent 2100检测仪分析RNA完整性数据RIN≥8。
2. 无蛋白质、基因组DNA污染,如有污染请去蛋白并进行DNase I处理。
请提供至少一种样品的凝胶电泳或者Agilent 2100检测仪检测图片,并注明其浓度、体积、OD260/OD280、溶剂名称、制备时间、物种来源以及特别备注。最终以我方定量、质检为准。
样品采集
为了保证提取RNA的完整性,确保后续实验的顺利进行,请务必确保样品的新鲜,对于如何确保样品的新鲜针对不同的样品获取材料的方法如下:
1. 动物组织:从活体上迅速的取下组织(切成黄豆粒大小的块状),每切成一个黄豆粒大小的块状立即放入液氮中,重复上述操作,直至足够提取总RNA的量;准备一个50ml的离心管,做相应的标记(样品名称、编号、客户姓名、时间),最好既在管盖上做好标记,也在管壁上做好相应的标记,先放入液氮中预冷2-3min,拿出离心管(离心管的下部分还是保持在液氮中),打开离心管的盖子,将液氮中黄豆粒大小的块状收集进离心管中。
2. 植物组织:
(1)如所采集的是果实、麦穗等体积偏大的样品,收集样品请参照1.动物组织取样方法;(2)如采集的是叶片等体积偏小的样品,请尽量采集嫩叶、幼芽等,每采集一片叶片立即放入液氮中,直至足够提取总RNA的量,后续操作请参照动物组织的采集。
(3)如是植物的花,在采集花骨朵的时候请尽量不要采集到花萼、叶片等,每采集一个花骨朵请立即放入液氮中,直至足够提取总RNA的量;后续操作请参照动物组织的采集。3. 如提供实验材料为菌丝体,请取500μl的菌液于1.5ml离心管中,离心去上清,剩余菌丝体放入液氮或干冰中,请提供不少于5管的菌丝体。
样品运输
从液氮中取出准备好的样品,请立即放入干冰中,并用干冰掩埋好样品。请填写完整订单,放入自封袋中与样品一起邮寄。为防止RNA的降解,请确保干冰的量足够运送到目的地。我们强烈建议在寄送RNA样品时将RNA保存在75%的乙醇或异丙醇中。
如是特殊样品,关于送样量和保存问题请与我们联系沟通,以便双方共同协商解决。
提供结果
根据客户需求,提供不同深度的信息分析结果。
科研基地学校的建设思路与策略 一、基本目标 基本目标是:本着“科研兴校、科研强师、科研促教”的办学理念,搭建管理有效、开放有序的科研平台,优化办学效益和丰富办学内涵,打造骨干引领、全员参与的科研格局,构建以校本研究为主要途径的学习型学校,造就一批研究型的教师,提升学校的核心竞争力。 在理论研究领域,主要以实验研究、比较研究为基础,关注现实情境中的复杂因果关联,理解、参与、反思现实的教育实践,努力实现理论与实践的深度结合。 在实践研究领域,采取有效措施扎实推进校本研究和合作研究,关注教师的专业发展和教育改革的实效,创造性地解决教育实践中的难点和焦点问题,从而改进学校的管理、教育与教学工作,培养专家型的学校管理者和教师。 二、基本原则 1.突出重点项目。以有效实施素质教育为核心,直接指向课堂,追求以减负增效为目的更为合理的教育教学行为、新课程实施及教学的创新、学生自主学习能力的培养等方面的研究。围绕教育改革和学校发展的中心工作,重点开展应用研究或开发研究。 2.突出实践需要。以分析和解决现实教育问题为出发点,以服务于教育科学决策和素质教育发展为方向,以应用价值为评价标准,为教育教学和教学管理注入活力,为学校的改革与发展提供基础与价值预设,促进学校办学特色和办学风格的形成。 3.突出校本研究。以学科组为单位,倡导教师的合作研究;鼓励研究范围微观、内容具体、切口小、周期短、易操作的小课题研究,重在引发教师的思考,激活教师的教育智慧和终身学习的冲动,培植其科研素养和创新热情,使教育教学进入更优化的状态。 三、建设举措
1、以管理网络为链条,激发管理效能 教育科研是一个多结构、多层次、多序列的复杂系统,学校教科研的组织网络是教育科研的基础工作。有效管理可为教育科研提供必须的物质条件,确保研究的科学性和有效性,促使科研制度的落实,有利于形成研究合力,确保教育科研活动按既定目标推进。 (1)成立由校长、分管副校长、教科处主任(副主任)、学科教研组长组成的学校教科研领导小组,形成教科研领导小组→教科研处(学术委员会→课题研究小组的层级化网络。 (2)在层级化管理系统中,学校课题领导小组以校长为核心,由主管副校长、科研处负责人、科研骨干教师组成,主要负责制定学校教育科研制度,审定课题研究方案,进行宏观的指导和监督,为课题研究提供各种必须的条件和支持;教科研处负责对各课题进行全程的指导、组织和全面的管理,开展各种研究活动;课题研究小组实行组长负责制,带领研究小组成员对相关的课题进行具体研究。三个层面都围绕着课题研究这个中心通过经常性的沟通实现互动式的管理,从而使课题研究的各项工作得到有效的执行。 (3)过程化管理是保证研究信度和效度的重要措施。一是在选题论证、立项申请、课题计划制定、计划实施、资料收集与分析、反思交流与总结、成果形成与应用、成果申报等整个过程由科研处实行全程跟踪管理和指导。二是切实做好课题实施的定期检查和评估工作,对各课题组的研究情况每学期进行两次检查和汇报,期未各负责人要填写好“新安中学中学阶段研究情况检查表”,由学校课题领导小组对研究情况进行评估,并将评估情况及时向各课题组反馈,以不断改善研究中存在的问题,提高研究的质量。过程化管理使课题研究真正做实、做好、有效。 2、以制度推动为保障,完善运行机制 制度的推动是教育科研发展的有效动力,是教育科研正常化、科学化的关键,是做好教育科研工作的根本保障。良好的教育科研制度包括规划制度、立项制度、学习制度、检查指导制度、经费使用制度、成果管理制度、目标考核制度、激励制度等。
全基因组表达谱分析方法(DGE)----基于新一代测序技术的 技术路线 该方法首先从每个mRNA的3’端酶切得到一段21bp的TAG片段(特异性标记该基因);然后通过高通量测序,得到大量的TAG序列,不同的TAG序列的数量就代表了相应基因的表达量;通过生物信息学分析得到TAG代表的基因、基因表达水平、以及样品间基因表达差异等信息。技术路线如下: 1、样品准备: a) 提供浓度≥300ng/ul、总量≥6ug、OD260/280为1.8~2.2的总RNA样品; 2、样品制备(见图1-1): a) 类似SAGE技术,通过特异性酶切的方法从每个mRNA的3’末端得到一段21bp 的特异性片段,用来标记该基因,称为TAG; b) 在TAG片段两端连接上用于测序的接头引物; 3、上机测序: a) 通过高通量测序每个样品可以得到至少250万条TAG序列; 4、基本信息分析: a) 对原始数据进行基本处理,得到高质量的TAG序列; b) 通过统计每个TAG序列的数量,得到该TAG标记的基因的表达量; c) 对TAG进行注释,建立TAG和基因的对应关系; d) 基因在正义链和反义链上表达量间的关系; e) 其它统计分析; 5、高级信息分析: a) 基因在样品间差异表达分析; b) 库容量饱和度分析;
c) 其它分析; 测序优势 利用高通量测序进行表达谱研究的优势很明显,具体如下: 1.数字化信号:直接测定每个基因的特异性表达标签序列,通过计数表达标签序列的数目来确定该基因的表达量,大大提高了定量分析的准确度。整体表达差异分布符合正态分布,不会因为不同批次实验引起不必要的误差。 2.可重复性高:不同批次的表达谱度量准确,能够更准确的进行表达差异分析。 3.高灵敏度:对于表达差异不大的基因能够灵敏的检测其表达差异;能够检测出低丰度的表达基因。 4.全基因组分析,高性价比:由于该技术不用事先设计探针,而是直接测序的方式,因此无需了解物种基因信息,可以直接对任何物种进行包括未知基因在内的全基因组表达谱分析,因此性价比很高。 5.高通量测序:已有数据表明,当测序通量达到200万个表达标签时,即可得到样本中接近全部表达基因的表达量数据,而目前每个样本分析可以得到300 万~600万个表达标签。
基因表达谱测序 背景介绍 基因表达谱分析利用HiSeq 2000高通量测序平台对mRNA进行测序,获得10M读长为49nt的原始reads,每一个reads可以对应到相应的转录本,从而研究基因的表达差异情况。与转录组测序相比,基因表达谱分析要求的读长更短,测序通量更小,仅可用于基因表达差异的研究。该方法具有定量准、可重复性高、检测阈值宽、成本低等特点,能很好的替代以往的数字化表达谱分析。 技术路线
生物信息学分析 送样要求 样品要求 1. 所需Total RNA 的量均不少于 20μg/文库,Total RNA 可以保存在DEPC 处理过的水中、75%的乙醇、异丙醇中,具体以什么方式保存请注明。 2. 如提供实验材料为动物组织材料,样品质量需大于2g ; 3. 如提供实验材料为植物样品,样品质量需大于4g ; 4. 如提供实验材料为培养细胞,请提供1×107培养好的细胞; 5. 如提供实验材料为血液样品,请提供≥2ml 的样品。 我们强烈建议在送样的同时客户做好备份,以备后续实验之用。 样品纯度要求 1. OD 260/OD 280在1.8- 2.0之间,RNA 无降解、28S 和18S 核糖体RNA 条带非常亮且清晰(其
大小决定于用于抽提RNA的物种类型),28S的密度大约是18S的2倍;Agilent 2100检测仪分析RNA完整性数据RIN≥8。 2. 无蛋白质、基因组DNA污染,如有污染请去蛋白并进行DNase I处理。 请提供至少一种样品的凝胶电泳或者Agilent 2100检测仪检测图片,并注明其浓度、体积、OD260/OD280、溶剂名称、制备时间、物种来源以及特别备注。最终以我方定量、质检为准。 样品采集 为了保证提取RNA的完整性,确保后续实验的顺利进行,请务必确保样品的新鲜,对于如何确保样品的新鲜针对不同的样品获取材料的方法如下: 1. 动物组织:从活体上迅速的取下组织(切成黄豆粒大小的块状),每切成一个黄豆粒大小的块状立即放入液氮中,重复上述操作,直至足够提取总RNA的量;准备一个50ml的离心管,做相应的标记(样品名称、编号、客户姓名、时间),最好既在管盖上做好标记,也在管壁上做好相应的标记,先放入液氮中预冷2-3min,拿出离心管(离心管的下部分还是保持在液氮中),打开离心管的盖子,将液氮中黄豆粒大小的块状收集进离心管中。 2. 植物组织: (1)如所采集的是果实、麦穗等体积偏大的样品,收集样品请参照1.动物组织取样方法;(2)如采集的是叶片等体积偏小的样品,请尽量采集嫩叶、幼芽等,每采集一片叶片立即放入液氮中,直至足够提取总RNA的量,后续操作请参照动物组织的采集。 (3)如是植物的花,在采集花骨朵的时候请尽量不要采集到花萼、叶片等,每采集一个花骨朵请立即放入液氮中,直至足够提取总RNA的量;后续操作请参照动物组织的采集。3. 如提供实验材料为菌丝体,请取500μl的菌液于1.5ml离心管中,离心去上清,剩余菌丝体放入液氮或干冰中,请提供不少于5管的菌丝体。 样品运输 从液氮中取出准备好的样品,请立即放入干冰中,并用干冰掩埋好样品。请填写完整订单,放入自封袋中与样品一起邮寄。为防止RNA的降解,请确保干冰的量足够运送到目的地。我们强烈建议在寄送RNA样品时将RNA保存在75%的乙醇或异丙醇中。 如是特殊样品,关于送样量和保存问题请与我们联系沟通,以便双方共同协商解决。 提供结果 根据客户需求,提供不同深度的信息分析结果。
基地建设方案 精品文档 基地建设方案 篇一:农业基地建设方案(略) 优农基地建设方案 项目名称:优农基地建设方案 项目性质:有机农物 项目业主:山西优农特色农产品展销有限公司 一、市场背景及可行性分析 发展无公害蔬菜能有效地提高蔬菜品质,保证蔬菜安全、优质、营养、保障人民的身体健康,提高人口素质是不可逆转的趋势。蔬菜是人们的必需品、消耗量大,随着人们生活水平的提高,人们对蔬菜也提出了更高的要求,由过去的数量型向质量型转变,品质优良、营养丰富、安全卫生,是今后人们对蔬菜需求的要求,无公害蔬菜、绿色蔬菜和有机蔬菜,正是应对了人们的消费心理和消费观念的变化。从全国来看,蔬菜生产的总量近乎饱和状态,但是,这只是低层次品种和数量的饱和,而无公害蔬菜、绿色蔬菜(A级、AA级绿色食品标准)和有机蔬菜供给量却远远不能满足日益增长的市场需求,消耗总量不断增加,市场容量大,发展空间广阔。目前市场上为数不多的无公害蔬菜、绿色蔬菜、有机蔬菜、保健型的蔬菜深受人们的欢迎,虽然价格偏高,但在超市、农贸市场都是抢手货,供不应求。利用无公害农产品加工的绿色食品是人们采购的优先选择,能带来较高的附 1 / 13 精品文档
加值和经济效益。按生态模式建设的无公害蔬菜,将推动我国绿色、有机、无公害食品的发展,将在国际市场上具有竞争优势,这是我国发展农产品的好机遇。蔬菜等农副产品生产均属劳动密集型产业,我国人多地少,农民有精耕细作的好传统,生产成本相对较低,加入WTO以后,蔬菜产品在国外市场竞争中居有利的地位,近年来我国蔬菜出口贸易稳步增长,我国蔬菜出口持续大幅增长,出口量年递增70万吨以上,2009年累计出口802(70万吨,比2000年增加482.40万吨,增长了1(67倍;出口额67(70亿美元,比2000年增长了1(74倍;2009年1—12月,出口802(7万吨,同比下降2(0,;出口额67(7亿美元,同比增长5(2,,呈量减额增态势。进口8(8万吨,同比下降15(3,;进口额1.0亿美元,同比下降10(9,。贸易顺差66(7亿美元,同比扩大5(5,。 山西是典型的为黄土广泛覆盖的山地高原,地势东北高西南低。境内大部分地区海拔在1500米以上,最高点为五台山主峰叶斗峰,海拔3061.1米,为华北最高峰,有“华北屋脊”之称;最低点在垣曲县境内西阳河入黄河处,海拔仅180米。高原内部起伏不平,河谷纵横,地貌类型复杂多样,有山地、丘陵、台地、平原,山多川少,四季分明,雨热同季,日照充足,光热气候资源丰富。由于地形十分复杂,山峦起伏,沟壑纵横,海拔高低悬殊,致使各地农业气候条件 2 / 13 精品文档 差异显著,形成富饶多样的农业气候类型,使农业生产具有强烈的地方性特点,丰富多样的气候类型,为农业开辟了广阔的前景,形成了一批具有鲜明特色的优势农产品。 二、整体构思 目前大部分农产品企业都采用“公司+农户”的模式,但毕竟产品非自己生产,在流程的把控及监管方面存在者难以弥补的漏洞,因此建议总体模式采用“公
基因表达谱芯片的数据分析(2012-03-13 15:25:58)转载▼ 标签:杂谈分类:生物信息 摘要 基因芯片数据分析的目的就是从看似杂乱无序的数据中找出它固有的规律, 本文根据数据分析的目的, 从差异基因表达分析、聚类分析、判别分析以及其它分析等角度对芯片数据分析进行综述, 并对每一种方法的优缺点进行评述, 为正确选用基因芯片数据分析方法提供参考. 关键词: 基因芯片; 数据分析; 差异基因表达; 聚类分析; 判别分析 吴斌, 沈自尹. 基因表达谱芯片的数据分析. 世界华人消化杂志2006;14(1):68-74 https://www.doczj.com/doc/0318940346.html,/1009-3079/14/68.asp 0 引言 基因芯片数据分析就是对从基因芯片高密度杂交点阵图中提取的杂交点荧光强度信号进行的定量分析, 通过有效数据的筛选和相关基因表达谱的聚类, 最终整合杂交点的生物学信息, 发现基因的表达谱与功能可能存在的联系. 然而每次实验都产生海量数据, 如何解读芯片上成千上万个基因点的杂交信息, 将无机的信息数据与有机的生命活动联系起来, 阐释生命特征和规律以及基因的功能, 是生物信息学研究的重要课题[1]. 基因芯片的数据分析方法从机器学习的角度可分为监督分析和非监督分析, 假如分类还没有形成, 非监督分析和聚类方法是恰当的分析方法; 假如分类已经存在, 则监督分析和判别方法就比非监督分析和聚类方法更有效率。根据研究目的的不同[2,3], 我们对基因芯片数据分析方法分类如下: (1)差异基因表达分析: 基因芯片可用于监测基因在不同组织样品中的表达差异, 例如在正常细胞和肿瘤细胞中; (2)聚类分析: 分析基因或样本之间的相互关系, 使用的统计方法主要是聚类分析; (3)判别分析: 以某些在不同样品中表达差异显著的基因作为模版, 通过判别分析就可建立有效的疾病诊断方法. 1 差异基因表达分析(difference expression, DE) 对于使用参照实验设计进行的重复实验, 可以对2样本的基因表达数据进行差异基因表达分
教科研基地汇报材料精 编W O R D版 IBM system office room 【A0816H-A0912AAAHH-GX8Q8-GNTHHJ8】
培育教科研文化发展内涵显特色 坚持在科学发展中不断超越 教育科研是深化教育改革的智力支持,是全面提高教学质量和效益的根本途径。是帮助教师树立新的教育理念,优化教育教学策略,推动学校内涵发展、科学发展的关键。回顾近几年来来我校教育科研的发展历程,我们在不断的探索中逐渐构建起适合学校发展的教育科研理论体系:以“科研兴教、科研立校、科研强师”为指导思想;以教科研“服务于学校发展,服务于教育教学改革,服务于教师专业提升”为工作定位,坚持三个不偏离:不偏离学校发展这一主题搞科研,不偏离教育教学这一中心搞科研,不偏离教师和学生这一主体搞科研实现两个科学:教法科学和学法科学;促进三个提高:教师课堂教学能力的提高,教师教研水平的提高;教师科研能力的提高;围绕五个突破:以实现学校精细化管理为突破,以网络辅助教学为突破,以校本课程开发、实施、管理、评价为突破,以德育方法的研究为突破,以信息技术与学科整合研究为突破;达到五个结合:学习与交流相结合,教研与科研相结合,学习与考核相结合,教育理论与教学实践相结合,普及与提高相结合。现把基地校挂牌以来教科研情况汇报如下: 一、基地校挂牌以来课题研究进展情况。 1、课题的基本概况: 《通过信息技术与学科教学整合,提高化学教学质量的研究》在2006年12月立为天津市电化教育馆“十一五”教育技术研究课题;《创设问题导入模式提高学生数学探究能力》等四个课题在2009年3月已被批准立为中央电化教育馆“十一五”全国教育技术研究重点课题《信息技术与学科教学有效整合的模式及应用方法体系研究》的子课题;
第24章 基因表达谱分析的生物信息学方法 思考与练习参考答案 1.据教材表24–3提供的数据信息可以构建一棵决策树,请利用最大信息增益方法写出如何选出根结点中用于分割的特征。 教材表24-3 天气情况与是否去打球的关系数据集 注:该信息表示根据天气情况决定是否出去打球,数据集共包含14个样本,两个类别信息(Yes 、No ),每个样本包含3 个特征信息(Outlook 、Temp 、Windy )。 解:计算用每一个特征进行分割时所获取的信息增益,取信息增益最大的那个特征作为分割特征,以Outlook 特征为例计算(参照练习图24-1) 练习图24-1 同Outlook 特征进行分割所获得的信息增益 )14 9 log 149145 log 145()(220+-=S H
)5 2 log 5253 log 53()(2211+-=S H 0)4 4 log 44()(212=-=S H )52 log 5253 log 53()(2213+-=S H )(14 5 )(144)(145)(1312111S H S H S H S H ++= infor-gain (Outlook )=)()(10S H S H - 同理,计算其他两个特征的信息增益,最后从三个值中选取最大的一个对应的特征作为根结点的分割特征。 2.请从https://www.doczj.com/doc/0318940346.html,/上下载一原始未经标准化的表达谱数据,并对该数据进行如下分析: (1)对数据进行标准化处理。 (2)对数据进行分类分析。 (3)分别对基因和样本进行聚类分析。 (4)选择特征基因。 (答案略)
实训基地建设方案 Document serial number【KK89K-LLS98YT-SS8CB-SSUT-SST108】
实验实训基地 建设方案 实验实训部 2005年2月 一、校内实践教学基地建设目标 校内实践教学基地的建设应围绕着培养学生具备高素质的技术应用性人才为目标,使之主要成为高职教育实施实践教学活动的重要场所和载体。其建设的指导思想为:根据专业教学要求,使专业实践教学具有相对稳定性,与之配套的基础设施具有先进性,教育效益、经济效益和社会效益具有示范性,管理模式和运作方式具有规范性,与理论教学和技术发展同步的结合具有紧密性。 1.基地建设的特点、功能与作用: 努力建设好校内实践教学基地,使之具备以下功能、特点与作用: (1).使基地成为高职教育培养应用性人才的教学基地。 根据高职教育的特点,要求学生在校期间就能完成就业岗位所需的岗位能力训练,校内实践教学基地不仅成为学生掌握基本专业技能的场所,还应加强现场模拟教学的组织与设计,提供一个与实际职业岗位相贴近的技能训练空间,让学生在有目标的实践训练前提下,通过一些设计性、探索性、开发性、工艺性和综合性等的模拟训练,使学生到达就业岗位后,不会对所处的环境,所遇到的工艺、技术、设备、生产组织管理等问题感到陌生,从而缩短了岗位适应期。同时培养并逐步使学生形成运用理论知识解决实际问题的专业技术应用能力,发现、分析和解决问题的方法能力,良好的工作品质和职业道德的个人能力以及与人协作、交往的社会能力,使之具备实践性强和有利于综合职业能力培养的特点。 (2).使基地成为科研项目开发的基地。
依据专业教学要求和专业发展的需要,以及科研的要求,投入必要的教学仪器与设备,并根据科技发展和技术工艺的更新,适时添置和更新仪器设备,注重不断提高仪器设备的现代科技含量;同时发挥学院科研人员和先进实验设备优势,鼓励教师参与技术创新、技术交流和技术转化,推动学院科研工作的发展。另一方面通过科研,教师也让学生早接触先进的仪器设备,早培养学生的科研意识和创新意识;通过基地全天开放,教师积极参与与科研,以科研带动教学,以教学促进科研,形成教学科研的有机结合,使之具备技术含量高新的特点。 (3).使基地成为行业技术、信息资源和培训的中心。 加强与企业的联合与协作,及时把行业的新技术、新材料、新工艺反馈到实践基地,使实践教育能及时体现出经济的发展与技术的进步,同时充分发挥基地高新设备的功能,开拓为社会提供技能鉴定、技能等级考核、材料检验检测、劳务培训、课题研究、产品开发等多方面的社会服务功能,使之具备开放性特点。 (4).使基地成为教学、科研、生产相结合的多功能基地。 充分发挥人、财、物优势,通过面向社会开放、与企业合作、为企业开展技术服务、新产品的开发与检测、与企业工程技术人员合作、对生产实际中遇到的难题进行研究、开发和解决等途径,使基地逐步形成在建设类行业中具有教学、科研、项目开发与产品生产的条件,使之具备产、学、研为一体的特点。 2、基地的实践教学、科研及生产的相互促进与开发 职业教育突出职业性特点,高等职业教育突出培养高技术应用性人才特点,而作为高职院校在办学过程中如何发挥实践教学基地的高新设备、科技优势和专业技术优势,把应用科技推向市场,把项目、产品的开发来引导市场。使教学、科研、生产三者相互促进,是每一高职院校在实践性教学基地的建设中所面临的一大重要课题。实践证明,产、学、研结合的途径,能使得教学、科研与生产相互联动与促进。有利于推进全面素质教育,有利于突出能力培养,有利于创新精神、科研意识的养成,有利于提高办学的教学效益、经济效益和社会效益。 基地产、学、研为一体开发的指导思想: (1).提高设备利用率,变纯教育投入为产出化投入。 充分利用基地的检验检测设备,开展对行业和社会的技术服务,使基地的材料检验检测中心成为行业区域性材料检测中心;其次结合当地经济发展趋势,投入相对超前的高、新、精、尖设备,既服务于教学,又通过对外开展技术服务、产品生产加工,把纯教育的投入为
基因表达谱数据 基因表达谱可以用一个矩阵来表示,每一行代表一个基因,每一列代表一个样本(如图1)。所有基因的表达谱数据在“gene_exp.txt ”文件中存储,第一列为基因的entrez geneid ,第2~61列是疾病样本的表达,第62~76列是正常样本的表达。 图1 基因表达谱的矩阵表示 寻找差异表达的基因: 原理介绍: 差异表达分析是目前比较常用的识别疾病相关miRNA 以及基因的方法,目前也有很多差异表达分析的方法,但比较简单也比较常用的是Fold change 方法。它的优点是计算简单直观,缺点是没有考虑到差异表达的统计显著性;通常以2倍差异为阈值,判断基因是否差异表达。Fold change 的计算公式如下: normal Disease x x c Fold = _ 即用疾病样本的表达均值除以正常样本的表达均值。 差异表达分析的目的:识别两个条件下表达差异显著的基因,即一个基因在两个条件中的表达水平,在排除各种偏差后,其差异具有统计学意义。我们利用一种比较常见的T 检验(T-test )方法来寻找差异表达的miRNA 。T 检验的主要原理为:对每一个miRNA 计算一个T 统计量来衡量疾病与正常情况下miRNA 表达的差异,然后根据t 分布计算显著性p 值来衡量这种差异的显著性,T 统计量计算公式如下: n s n s x x t normal Disease normal Disease miRNA //22+-= 对于得到的显著性p 值,我们需要进行多重检验校正(FDR ),比较常用的是BH 方法(Benjamini and Hochberg, 1995)。
RNA-Seq名词解释 1.index 测序的标签,用于测定混合样本,通过每个样本添加的不同标签进行数据区分,鉴别测序样品。 2.碱基质量值 (Quality Score或Q-score)是碱基识别(Base Calling)出错的概率的整数映射。碱基质量值越高 表明碱基识别越可靠,碱基测错的可能性越小。 3.Q30 碱基质量值为Q30代表碱基的精确度在99.9%。 4.FPKM(Fragments Per Kilobase of transcript per Million fragments mapped) 每1百万个map上的reads中map到外显子的每1K个碱基上的fragment个数。计算公式为 公式中,cDNA Fragments 表示比对到某一转录本上的片段数目,即双端Reads数目;Mapped Reads(Millions)表示Mapped Reads总数, 以10为单位;Transcript Length(kb):转录本长度,以kb个碱基为单位。 5.FC(Fold Change) 即差异表达倍数。 6.FDR(False Discovery Rate) 即错误发现率,定义为在多重假设检验过程中,错误拒绝(拒绝真的原(零)假设)的个数占所有被拒绝 的原假设个数的比例的期望值。通过控制FDR来决定P值的阈值。 7.P值(P-value) 即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的P 值,一般以P<0.05 为显著,P<0.01为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05或0.01。 8.可变剪接(Alternative splicing)
Bioinformatics Analysis of Next-Generation Sequencing Data – Epigenome and Chromatin Interactome 要点: Enhancers are marked by multiple modifications Characteristic histone methylation patterns at active genes 涉及的相关技术: NGS Epigenetics CHIP-Seq 3C NGS(Next-Generation Sequencing)的原理: 最近市面上出现了很多新一代测序仪产品,例如美国Roche Applied Science公司的454基因组测序仪、美国Illumina公司和英国Solexa technology公司合作开发的Illumina测序仪、美国Applied Biosystems公司的SOLiD测序仪、Dover/Harvard公司的Polonator测序仪以及美国Helicos公司的HeliScope单分子测序仪。所有这些新型测序仪都使用了一种新的测序策略——循环芯片测序法(cyclic-array sequencing),也可将其称为“新一代测序技术或者第二代测序技术”。所谓循环芯片测序法,简言之就是对布满DNA样品的芯片重复进行基于DNA的聚合酶反应(模板变性、引物退火杂交及延伸)以及荧光序列读取反应。2005年,有两篇论文曾对这种方法做出过详细介绍。与传统测序法相比,循环芯片测序法具有操作更简易、费用更低廉的优势,于是很快就获得了广泛的应用。 传统的Sanger测序法及新一代DNA测序技术工作流程图
真核mRNA测序是基于HiSeq平台,对真核生物特定组织或细胞在某个时期转录出来的所有mRNA进行测序,既可研究已知基因,亦能发掘新基因,全 面快速地获得mRNA序列和丰度信息。真核mRNA测序方法可以分为:有参考转录组、无参考转录组以及数字基因表达谱(DGE)三大类。 技术参数 案例解析 [案例一] mRNA和small RNA转录组揭示新合成异源六倍体小麦杂种 优势的动态部分同源调控 诺禾致源携手中国农业科学院作物科学研究所,利用转录组测序技术,对杂交亲本、新合成异源六倍体小麦的幼苗、穗和种子进行了mRNA和smallRNA测序及信息分析,发现新合成异源六倍体小麦绝大部分基因表现为12类基因表达模式,包括加性表达,少部分的基因表现为非加性,基因的非加性表现出非常强的发育时期特异性,与生长势密切相关;miRNA的丰度随着倍性的增加逐渐下降,新合成异源六倍体小麦中非加性表达的 miRNA也同样表现出亲本显性表 达,miRNA的表达敏感性与生长势和适应性密切相关。该研究揭示了不同倍性 非对等杂种优势的分子基础。 [案例二] 磷酸三(2,3-二氯丙基)酯(TDCPP)对四膜虫生长繁殖的 抑制作用与核糖体相关 诺禾携手华中农业大学,利用转录组测序和信息分析技术,研究了TDCPP处理组和对照组差异基因表达,并对差异表达基因进行KEGG通路分析,发现核糖体基因通路显著富集, 同时伴随胞浆和粗面内质网上核糖体数量减少体积增大。这些探索表明四膜虫可以作为TDCPP反应的生物指标,为后续研究TDCPP作用其他生物的毒理机制提供了新视角。 [案例三] 转录组揭示寄主植物与宿主之间进行RNA交换的机制 参考文献 菟丝子被称作勒死草,会用被称作吸根的专用器官穿透宿主组织与其建立联系,可以吸取宿主的水份与营养物质,也能吸取RNA(mRNA)分子。本研究分别选取菟丝子和拟南芥及番茄的共生体茎上的三段组织进行转录组学的研究,发现寄生植物与寄主之间mRNA的转移量很大且是一种双向转移的模式;两种宿主相比,更多的拟南芥RNA被转移到菟丝子植物之中,而且菟丝子与拟南芥之间较自由的交换,可表明调节菟丝子吸根选择性的机制可能是宿主特异性的,从而揭示了寄主与宿主之间进行RNA转移的遗传机制。 [1] Li A, Liu D, Wu J, et al . mRNA and small RNA transcriptomes reveal insights into dynamic homoeolog regulation of allopolyploid heterosis in nascent hexaploid wheat [J]. The Plant Cell, 2014: tpc. 114.124388.[2] Jing Li, John P , Giesy, Liqin Yu, et al . Effects of Tris (1,3-dichloro-2-propyl) Phosphate (TDCPP) in Tetrahymena Thermophila: Targeting the Ribosome. Scientific Reports. 2015, 5:10562. [3] Kim G, LeBlanc M L, et al . Genomic-scale exchange of mRNA between a parasitic plant and its hosts [J]. Science, 2014, 345(6198): 808-811. 图1 非加性表达miRNA与亲本显性表达miRNA的 等级聚类分析和两者的关联 图2 显著富集的KEGG通路 图3 菟丝子与拟南芥、番茄转移RNA和非转移RNA的表达和富集分析 样品要求文库类型测序策略数据量类型 分析内容 项目周期 真核有参转录组测序 真核无参转录组测序 6 Gb、8 Gb、10 Gb、12 Gb clean data 6 M clean reads 3 Gb clean data 项目数据至少12 Gb clean data 数字基因表达谱(DGE) HiSeq PE150 HiSeq PE150 HiSeq SE50HiSeq PE125普通转录组文库; 链特异性转录组文库 40天50天30天 35天(有参)45天(无参) RNA样品总量≥1.5 μg; RNA样品浓度≥50 ng/μL 参考基因组比对 新转录本预测可变剪切分析SNP/InDel分析 基因表达水平分析RNA-seq整体质量评估 转录因子注释GO/KEGG富集分析蛋白互作网络分析基因共表达网络构建可视化结果展示 参考转录组拼接 转录本/Unigene长度统计 基因功能注释NR,NT,Swiss Prot GO,KEGG,KOG Protein Family CDS预测分析SNP/SSR分析
基因表达谱芯片数据分析及其Bioconductor实现 1.表达谱芯片及其应用 表达谱DNA芯片(DNA microarrays for gene expression profiles)是指将大量DNA片段或寡核昔酸固定在玻璃、硅、塑料等硬质载体上制备成基因芯片,待测样品中的mRNA被提取后,通过逆转录获得cDNA,并在此过程中标记荧光,然后与包含上千个基因的DNA芯片进行杂交反应30min~20h后,将芯片上未发生结合反应的片段洗去,再对玻片进行激光共聚焦扫描,测定芯片上个点的荧光强度,从而推算出待测样品中各种基因的表达水平。用于硏究基因表达的芯片可以有两种:①cDNA芯片;② 寡核昔酸芯片。 cDNA芯片技术及载有较长片段的寡核昔酸芯片采用双色荧光系统:U前常用Cy3—dUTP (绿色)标记对照组mRNA, Cy5—dUTP (红色)标记样品组mRNAUl。用不同波长的荧光扫描芯片,将扫描所得每一点荧光信号值自动输入计?算机并进行信息处理,给出每个点在不同波长下的荧光强度值及其比值(ratio值),同时计算机还给出直观的显色图。在样品中呈高表达的基因其杂交点呈红色,相反,在对照组中高表达的基因其杂交点呈绿色,在两组中表达水平相当的显黄色,这些信号就代表了样品中基因的转录表达情况⑵。 基因芯片因具有高效率,高通量、高精度以及能平行对照研究等特点,被迅速应用于动、植物和人类基因的研究领域,如病原微生物毒力相关基因的。基因表达谱可直接检测mRNA的种类及丰度,可以同时分析上万个基因的表达变化,来揭示基因之间表达变化的相互关系。表达谱芯片可用于研究:①同一个体在同一时间里,不同基因的表达差异。芯片上固定的已知序列的cDNA或寡聚核昔酸最多可以达到30 000多个序列,与人类全基因组基因数相当,所以基因芯片一次反应儿乎就能够分析整个人的基因⑶。②同一个体在不同时间里,相同基因的表达差异。 ③不同个体的相同基因表达上的差异。利用基因芯片可以分析多个样本,同时筛选不同样本(如肿瘤组织、癌前病变和正常组织)之间差异表达的基因,这样可以避免了芯片间的变异造成的误差⑷。张辛燕⑸ 等将512个人癌基因和抑癌基因的cDNA用点样仪点在特制玻片上制成表达谱芯片,对正常人卵巢组织及卵巢癌组织基因表达的差异性进行比较研究,结果发现在卵巢癌组织中下调的基因有23个,上调的基因有15个,初步筛选出了卵巢癌相关基因。Lowe⑹等利用胰腺癌、问充质细胞癌等组织的cDNA制备基因芯片,筛选到胰腺癌细胞中高表达的基因,为医疗诊断、病理研究及新药设计 奠定基础。 2.表达谱芯片的数据处理技术
培育教科研文化发展内涵显特色 坚持在科学发展中不断超越 教育科研是深化教育改革的智力支持,是全面提高教学质量和效益的根本途径。是帮助教师树立新的教育理念,优化教育教学策略, 结合,普及与提高相结合。现把基地校挂牌以来教科研情况汇报如下: 一、基地校挂牌以来课题研究进展情况。 1、课题的基本概况:
《通过信息技术与学科教学整合,提高化学教学质量的研究》在2006年12月立为天津市电化教育馆“十一五”教育技术研究课题;《创设问题导入模式提高学生数学探究能力》等四个课题在2009年3月已被批准立为中央电化教育馆“十一五”全国教育技术研究重点课题《信息技术与学科教学有效整合的模式及应用方法体系研究》的 一次性通过2010年6月的中期汇报。 二、基地校挂牌以来开展教科研活动情况。 自基地校挂牌以来,我校以举办两届“新希望杯”论文年会,一届在2009年10月举行,一届在2010年3月举行,我校已制定详细的实施方案,以后固定在每年的3月份举行,作
为“北极星杯”论文年会的初选。我校在基地校挂牌以来,已举行四次科研讲座,请在教科研方面有丰富经验,负责学校教科研具体工作的老师为参与课题研究的老师做了《如何撰写课题实施方案》、《课题研究方法的运用》、《课题结题材料的收集和整理》、《如何做好中期汇报的相关工作》等讲座,收 在数学教学实践中的体验》等四篇论文获二等奖,《以提高教学质量为目的,进行信息技术与化学学科教学的整合》等六篇论文获三等奖。在2009年天津市“教育创新”论文凭选活动中有《优化高中地理教学过程提高课堂教学质量》等十篇论文获市级三等奖。在中国教育学会第22次学术年会论文评选中有《高中生
基因表达谱聚类分析 [ 文章来源:| 文章作者:| 发布时间:2006-12-21| 字体:[大中小] 学习过程可以采用从全局到局部的策略。采取这种策略时,学习初期可设定较大的交互作用半径R ,随着学习过程的不断推进,逐步减小R ,直至不考虑对邻近单元的影响。邻域的形状可以是正方形或者圆形。 KFM 的聚类结果与K 均值相似,它的优点是自动提取样本数据中的信息,同时也是一种全局的决策方法,能避免陷入局部最小,缺点在于必须实现人为设定类的数目与学习参数,而且学习时间较长。KFM 方法克服了K- 均值聚类的一些缺点:它应用类间的全局关系,能提供大数据集内相似性关系的综合看法,便于研究数据变量值的分布及发现类结构。而且,它具有更稳健更准确的特点,对噪声稳定,一般不依赖于数据分布的形状。 8.4.2.5 其它聚类方法 聚类方法是数据挖掘中的基本方法,数据挖掘的方法很多,在基因表达谱的分析中,除了以上常用方法外,还有一些其它的方法。由于对聚类结果尚没有一种有效的方法进行评价,尤其是对聚类结果的进一步生物学知识发现尚没有新的分析思路和成功应用,因此,科学家们在不断地研究一些新方法。这些方法有不同的原理,能够提取不同数据特征,有可能对具体的数据得到更有意义的结果,发现更多的生物学知识。这里,简单介绍这些方法的原理,更详细的介绍请参看相关文献。 (1)模糊聚类分析方法:这是一种模拟人类的思维方法,通过隶属度函数来反映某一对象属于某一类的程度。基本思路是计算两两基因表达谱之间的相似性程度,构建模糊相似矩阵,利用模糊数学中的传递闭包计算方法得到模糊等价矩阵,选择不同的置信水平从模糊等价矩阵中构建动态聚类图。对于特定的置信水平,可以实现对基因表达谱的分类。该方法的优点是利用了模糊数学中的隶属度概念,能够更好的反映基因表达谱之间的相互关系,而且它是一种全局的优化方法,与向量的顺序无关。 (2)模糊C均值算法:该方法同样将模糊数学中的隶属度概念引入到常用的K 均值聚类方法中。对于K 均值算法,一个基因表达谱所属的类只有一个,因此,它与各类别的关系要么是 1 ,要么是0 ,即属于或不属于某一类。而对于模糊 C 均值法,一个基因表达谱是否属于某一类,是以隶属度来确定第i 个样本属于第j 类的可能性。最终的聚类结果取决于分析的目的,可以根据最大隶属度来确定基因表达谱的分类,即一个基因表达谱只属于一类;但往往是确定隶属度的阈值,只要大于该阈值,就可以将基因表达谱划分为该类,这样的划分结果是一个基因表达谱可以属于多个类,这也是可以被生物学家接受的。模糊 C 均值法与K 均值法的实现过程基本相同,所不同的是对于
illumina 转录组测序简明实验流程一、实验基本流程图 mRNA Library Construction
二、mRNA建库流程 1.材料准备 1.2. 1.3.
2.样品准备和QC 选择质量合格的Total RNA作为mRNA测序的建库起始样品,其质量要求通过Agilent 2100 BioAnalyzer检测结果RIN≥7,28S和18S的RNA 的比值大于或等于1.5:1,起始量的要求范围是0.1∽1ug。用QUBIT RNA ASSAY KIT对起始的Total RNA进行准确定量。 3.建库实验步骤 3.1.mRNA纯化和片段化 3.1.1.mRNA纯化 纯化原理是用带有Oligod(T)的Beads对Total RNA中mRNA进行纯化。 3.1.2.mRNA片段化 3.2.1st Strand cDNA 合成 3.3.2nd Strand cDNA 合成 根据下表制备反应体系,然后在PCR仪上运行Program3,然后将第2链cDNA合成产物用144uL AMPure XP Beads进行纯化,最后用60μL的Nuclease free water进行重悬,取出 55.5μL以备下一步使用;
3.4.Perform End Repair/dA-tail 3.5.Adaptor Ligation 根据下表制备反应体系,然后在PCR仪上运行Program5、Program6,然后100uL AMPure XP Beads进行纯化后用52.5μL的Resuspension Buffer进行重悬,再用50uL AMPure XP Beads 3.6.PCR扩增 根据下表制备反应体系,然后在PCR仪上运行Program7,然后再45μL用AMPure XP Beads 进行纯化,最后用23μL的Resuspension Buffer进行重悬,取出20μL以备下一步使用;
龙源期刊网 https://www.doczj.com/doc/0318940346.html, 关于基因数据的统计学研究 作者:张燕 来源:《现代职业教育·高职高专》2018年第06期 [摘要] 贝叶斯网络有着很好的理论知识和清楚的知识表达形式,是统计学中不确定性研 究的一种重要方法,在数据挖掘中有着重要作用。将其引入基因数据的分析中,能较好地构建网络模型,分析各基因间的相互作用与影响,可广泛应用于生物学和肿瘤学的研究,观察疾病所引起的基因表达变化,并找出重要作用的变量基因。 [关键词] 基因数据;统计学;结构学习 [中图分类号] G648 [文献标志码] A [文章编号] 2096-0603(2018)16-0137-01 随着人类基因组序列草图的完成,有关功能基因组的研究在生命科学领域中占据越来越重要的地位。阐明基因选择性表达所依赖的调控信息及其相互作用的分子机制,成为揭示生命现象本质的核心问题,是功能组研究的重要内容。随着基因组学研究的深入展开,基因的表达调控研究已经从单个基因、线性的调控拓展到立体层面上多基因、基因簇乃至整个基因组的调控网络。如何有效地利用已有的基因组学数据,充分整合多学科的思路,建立新的试验系统和技术体系,阐明基因组表达的调控网络,分析基因之间的相互制约关系,已经成为功能基因组学领域内国际竞争的焦点。 贝叶斯网络方法将概率理论知识与图论结合,其有图形化表示、因果关系清晰以及不确定性推理等优点,本文将贝叶斯网络引入基因数据中并进行分析,从概率角度描述了各基因间的依赖关系,从而阐明了整个基因组之间的调控网络。 一、对基因数据的预处理 贝叶斯网络的结构学习是一个NP-Hard问题,而构建网络结构最常见的方法是在结点变量的顺序已经确定的情况下,采用局部搜索算法。在基因表达谱数据中,由于没有任何先验知识,本实验中对网络的构建使用的是K2算法,而K2算法需要预先知道网络变量的先后顺序,本文将重点介绍决策树算法,将ID3算法用于确定各结点的顺序。 二、结构学习 在建模之前需要完成的最后一步工作是需要把样本数据分成训练集和检验集,分别用于训练检验和模型检验。数据经过离散化之后,除去预留几个样本的各基因表达情况用作模型验证,其余的样本作为训练集导入实验软件matlab中。 在网络拓扑结构的构建过程中,最大父结点个数的设置问题直接影响了所得网络的规模与结构。随着父结点个数越多,所得的网络结构就越复杂,虽然能更多地揭示各结点之间的相互