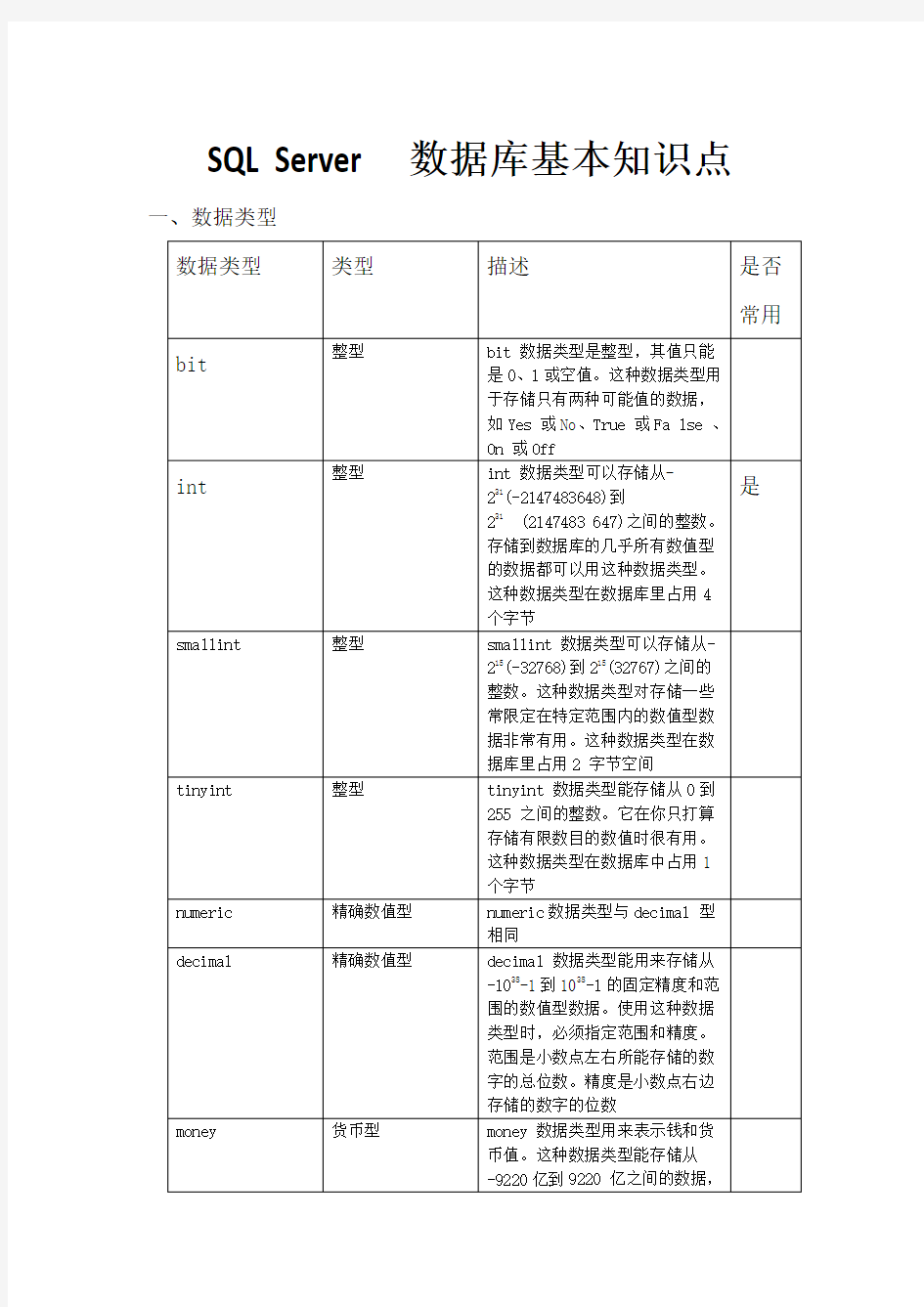

SQL Server 数据库基本知识点一、数据类型
二、常用语句 (用到的数据库Northwind)
查询语句
简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的
表或视图、以及搜索条件等。例如,下面的语句查询Customers 表中公司名称为“Alfreds Futterkiste”的ContactName字段和Address字段。
SELECT ContactName, Address
FROM Customers
WHERE CompanyName='Alfreds Futterkiste'
(一) 选择列表
选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。
1、选择所有列
例如,下面语句显示Customers表中所有列的数据:
SELECT *
FROM Customers
2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。
例如:
SELECT ContactName, Address
FROM Customers
3、更改列标题
在选择列表中,可重新指定列标题。定义格式为:
列标题 as 列名
列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题:
SELECT ContactName as 联系人名称, Address as地址
FROM Customers
4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认
为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。
SELECT DISTINCT(Country)
FROM Customers
5、限制返回的行数
使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT 时,说明n是
表示一百分数,指定返回的行数等于总行数的百分之几。
例如:
SELECT TOP 2 *
FROM Customers
SELECT TOP 20 PERCENT *
FROM Customers
(二)FROM子句
FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列
所属的表或视图。例如在Orders和Customers表中同时存在CustomerID列,在查询两个表中的CustomerID时应
使用下面语句格式加以限定:
select * from Orders,Customers
where Orders.CustomerID =Customers.CustomerID
在FROM子句中可用以下两种格式为表或视图指定别名:
表名 as 别名
表名别名
select * from Orders as a,Customers as b
where a.CustomerID =b.CustomerID
SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。
例如:
select * from Customers where CustomerID in (select CustomerID from Orders where EmployeeID=4)
此例中,将SELECT返回的结果集合给予一别名CustomerID,然后再从中检索数据。
(三) 使用WHERE子句设置查询条件
WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:select CustomerID from Orders where EmployeeID=4
WHERE子句可包括各种条件运算符:
比较运算符(大小比较):>、>=、=、<、<=、<>、!>、!<
范围运算符(表达式值是否在指定的范围):BETWEEN…AND…
NOT BETWEEN…AND…
列表运算符(判断表达式是否为列表中的指定项):IN (项1,项2……)
NOT IN (项1,项2……)
模式匹配符(判断值是否与指定的字符通配格式相符):LIKE、NOT LIKE
空值判断符(判断表达式是否为空):IS NULL、NOT IS NULL
逻辑运算符(用于多条件的逻辑连接):NOT、AND、OR
1、范围运算符例:age BETWEEN 10 AND 30相当于age>=10 AND age<=30
2、列表运算符例:country IN ('Germany','China')
3、模式匹配符例:常用于模糊查找,它判断列值是否与指定的字符串格式相匹配。可用于char、
varchar、text、ntext、datetime和smalldatetime等类型查询。
可使用以下通配字符:
百分号%:可匹配任意类型和长度的字符
插入语句
语法:Insert into 表(字段1,字段2,….字段n) values(值1,值2,….值n)
例如:Insert into Region(RegionID, RegionDescription)values(5,'Southern')
更新语句
语法:update 表 set 字段1 = 值1,字段2=值2,字段n=值n where 条件
如:
update Customers set ContactName='John',Address ='Avda. de la' where CustomerID='ALFKI'
where 条件同查询语句
删除语句
语法:delete from 表 where 条件
如:
delete from Customers where CustomerID='ALFKI'
where 条件同查询语句
清空表:
truncate table 表清空表中所有数据,表中如果有自增长字段,该字段在插入时会重新开始
注意:
由于更新语句与删除语句会更改表数据对公司业务主要表进行更新与删除操作时一定要先进行备份,然后进行操作
备份语句
select* into Customers20101019 from Customers
目标表(Customers20101019)不存在时会自动创建
三、存储过程
优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量
4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
语法
CREATE PROC[ EDURE ] [ owner. ] procedure_name [ ; number ]
[ { @parameter data_type }
[ VARYING ] [ = default ] [ OUTPUT ]
] [ ,...n ]
[ WITH
{ RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ]
[ FOR REPLICATION ]
AS sql_statement [ ...n ]
参数
owner
拥有存储过程的用户 ID 的名称。owner 必须是当前用户的名称或当前用户所属的角色的名称。
procedure_name
新存储过程的名称。过程名必须符合标识符规则,且对于数据库及其所有者必须唯一。
;number
是可选的整数,用来对同名的过程分组,以便用一条 DROP PROCEDURE 语句即可将同组的过程一起除去。例如,名为 orders 的应用程序使用的过程可以命名为 orderproc;1、orderproc;2 等。DROP PROCEDURE orderproc 语句将除去整个组。如果名称中包含定界标识符,则数字不应包含在标识符中,只应在 procedure_name 前后使用适当的定界符。
@parameter
过程中的参数。在 CREATE PROCEDURE 语句中可以声明一个或多个参数。用户必须在执行过程时提供每个所声明参数的值(除非定义了该参数的默认值,或者该值设置为等于另一个参数)。存储过程最多可以有 2.100 个参数。
使用 @ 符号作为第一个字符来指定参数名称。参数名称必须符合标识符的规则。每个过程的参数仅用于该过程本身;相同的参数名称可以用在其它过程中。默认情况下,参数只能代替常量,而不能用于代替表名、列名或其它数据库对象的名称。
data_type
参数的数据类型。除 table 之外的其他所有数据类型均可以用作存储过程的参数。但是,cursor 数据类型只能用于 OUTPUT 参数。如果指定 cursor 数据类型,则还必须指定VARYING 和 OUTPUT 关键字。对于可以是 cursor 数据类型的输出参数,没有最大数目的限制。
VARYING
指定作为输出参数支持的结果集(由存储过程动态构造,内容可以变化)。仅适用于游标参数。
default
参数的默认值。如果定义了默认值,不必指定该参数的值即可执行过程。默认值必须是常量或 NULL。如果过程将对该参数使用 LIKE 关键字,那么默认值中可以包含通配符(%、_、[] 和 [^])。
OUTPUT
表明参数是返回参数。该选项的值可以返回给 EXEC[UTE]。使用 OUTPUT 参数可将信息返回给调用过程。Text、ntext 和 image 参数可用作 OUTPUT 参数。使用 OUTPUT 关键字的输出参数可以是游标占位符。
如:
CREATE PROCEDURE CustOrdersDetail @OrderID int
AS
SELECT ProductName,
UnitPrice=ROUND(Od.UnitPrice, 2),
Quantity,
Discount=CONVERT(int, Discount * 100),
ExtendedPrice=ROUND(CONVERT(money, Quantity * (1 - Discount) * Od.UnitPrice), 2)
FROM Products P, [Order Details] Od
WHERE Od.ProductID = P.ProductID and Od.OrderID = @OrderID
GO
四:游标:
游标(Cursor)是处理数据的一种方法,为了查看或者处理结果集中的数据,游标提供了在结果集中一次以行或者多行前进或向后浏览数据的能力。我们可以把游标当作一个指针,它可以指定结果中的任何位置,然后允许用户对指定位置的数据进行处理。
1.声明游标
2.打开游标
3.读取游标数据
4.关闭游标
5.释放游标
常用于需要把多行的数据进行拼接处理
如:
declare @ContactName varchar(50)
declare @AllContactName varchar(5000)
set @AllContactName =’’
DECLARE GetContactName_Cursor CURSOR
FOR select ContactName from Customers where CustomerId = 'ALFKI'
OPEN GetContactName_Cursor
FETCH NEXT FROM GetContactName_Cursor into @ContactName
WHILE @@FETCH_STATUS = 0
BEGIN
set @ AllContactName= AllContactName+@ContactName
print @ AllContactName
FETCH NEXT FROM GetContactName_Cursor into @ContactName
END
CLOSE GetContactName_Cursor
DEALLOCATE GetContactName_Cursor
五:常用系统函数和变量:
系统变量:
select @@ERROR --返回最后执行的 Transact-SQL 语句的错误代码(integer) select @@IDENTITY --返回最后插入的标识值
Select USER_NAME() --返回用户数据库用户名
select @@ERROR --返回最后执行的 Transact-SQL 语句的错误代码
select @@CONNECTIONS --返回自上次SQL启动以来连接或试图连接的次数。
select GETDATE() --当前时间
select @@CPU_BUSY/100 --返回自上次启动SQL 以来 CPU 的工作时间,单位为毫秒
USE tempdb Select @@DBTS --为当前数据库返回当前 timestamp 数据类型的值。
这一 timestamp 值保证在数据库中是唯一的。
select @@IDENTITY --返回最后插入的标识值
Select @@IDLE --返回SQL自上次启动后闲置的时间,单位为毫秒
Select @@IO_BUSY --返回SQL自上次启动后用于执行输入和输出操作的时间,单位为毫秒
Select @@LANGID --返回当前所使用语言的本地语言标识符(ID)。
Select @@LANGUAGE --返回当前使用的语言名
Select @@LOCK_TIMEOUT --当前会话的当前锁超时设置,单位为毫秒。
Select @@MAX_CONNECTIONS --返回SQL上允许的同时用户连接的最大数。返回的数不必为当前配置的数值
EXEC sp_configure --显示当前服务器的全局配置设置
Select @@MAX_PRECISION --返回 decimal 和 numeric 数据类型所用的精度级别,即该服务器中当前设置的精度。默认最大精度38。
select @@OPTIONS --返回当前 SET 选项的信息。
Select @@PACK_RECEIVED --返回SQL自启动后从网络上读取的输入数据包数目。Select @@PACK_SENT --返回SQ自上次启动后写到网络上的输出数据包数目。Select @@PACKET_ERRORS --返回自SQL启动后,在SQL连接上发生的网络数据包错误数。
Select @@SERVERNAME --返回运行SQL服务器名称。
Select @@SERVICENAME --返回SQL正在其下运行的注册表键名
Select @@TIMETICKS --返回SQL服务器一刻度的微秒数
Select @@TOTAL_ERRORS --返回 SQL服务器自启动后,所遇到的磁盘读/写错误数。Select @@TOTAL_READ --返回 SQL服务器自启动后读取磁盘的次数。
Select @@TOTAL_WRITE --返回SQL服务器自启动后写入磁盘的次数。
Select @@TRANCOUNT --返回当前连接的活动事务数。
Select @@VERSION --返回SQL服务器安装的日期、版本和处理器类型。
系统函数:
1. 字符转换函数
LOWER()和UPPER()
LOWER()将字符串全部转为小写;UPPER()将字符串全部转为大写
STR() 把数值型数据转换为字符型数据。
2. 去空格函数
LTRIM() 把字符串头部的空格去掉。
RTRIM() 把字符串尾部的空格去掉。
3. 取子串函数
left()
LEFT (
返回character_expression 左起 integer_expression 个字符。
RIGHT()
RIGHT (
返回character_expression 右起 integer_expression 个字符。
SUBSTRING()
SUBSTRING (
返回从字符串左边第starting_ position 个字符起length个字符的部分。
4. 字符串比较函数
CHARINDEX()
返回字符串中某个指定的子串出现的开始位置。
PATINDEX()
返回字符串中某个指定的子串出现的开始位置。
5. 字符串操作函数
REPLACE()
返回被替换了指定子串的字符串。
SPACE()
返回一个有指定长度的空白字符串。
6. 数据类型转换函数
CAST()
CAST (
CONVERT()
CONVERT (
1)data_type为SQL Server系统定义的数据类型,用户自定义的数据类型不能在此使用。
2)length用于指定数据的长度,缺省值为30。
3)把CHAR或VARCHAR类型转换为诸如INT或SAMLLINT这样的INTEGER类型、结果必须是带正号或负号的数值。
4)TEXT类型到CHAR或VARCHAR类型转换最多为8000个字符,即CHAR或VARCHAR数据类型是最大长度。
5)IMAGE类型存储的数据转换到BINARY或VARBINARY类型,最多为8000个字符。
6)把整数值转换为MONEY或SMALLMONEY类型,按定义的国家的货币单位来处理,如人民币、美元、英镑等。
7)BIT类型的转换把非零值转换为1,并仍以BIT类型存储。
8)试图转换到不同长度的数据类型,会截短转换值并在转换值后显示“+”,以标识发生了这种截断。
9)用CONVERT()函数的style 选项能以不同的格式显示日期和时间。style 是将DATATIME 和SMALLDATETIME 数据转换为字符串时所选用的由SQL Server 系统提供的转换样式编号,不同的样式编号有不同的输出格式。
7. 日期函数
DATEADD()
DATEADD (
返回指定日期date 加上指定的额外日期间隔number 产生的新日期。
DATEDIFF()
DATEDIFF (
返回两个指定日期在datepart 方面的不同之处,即date2 超过date1的差距值,其结果值是一个带有正负号的整数值。
DATEPART()
DATEPART (
以整数值的形式返回日期的指定部分。此部分由datepart 来指定。
DATEPART (dd, date) 等同于DAY (date)
DATEPART (mm, date) 等同于MONTH (date)
DATEPART (yy, date) 等同于YEAR (date)
GETDATE()
以DATETIME 的缺省格式返回系统当前的日期和时间
(注:专业文档是经验性极强的领域,无法思考和涵盖全面,素材和资料部分来自网络,供参考。可复制、编制,期待你的好评与关注)
1、数据库基本语句 (1)表结构处理 创建一个表:cteate table 表名(列1 类型,列2 类型); 修改表的名字 alter table 旧表名 rename to 新表名 查看表结构 desc 表名(cmd) 添加一个字段 alter table 表名 add(列类型); 修改字段类型 alter table 表名 modify(列类型); 删除一个字段 alter table 表名 drop column列名; 删除表 drop table 表名 修改列名 alter table 表名 rename column 旧列名 to 新列名; (2)表数据处理 增加数据:insert into 表名 values(所有列的值); insert into 表名(列)values(对应的值); 更新语句:update 表 set 列=新的值,…[where 条件] 删除数据:delete from 表名 where 条件 删除所有数据,不会影响表结构,不会记录日志, 数据不能恢复--》删除很快: truncate table 表名 删除所有数据,包括表结构一并删除: drop table 表名 去除重复的显示:select distinct 列 from 表名 日期类型:to_date(字符串1,字符串2)字符串1是日期的字 符串,字符串2是格式 to_date('1990-1-1','yyyy-mm-dd')-->返回日期的 类型是1990-1-1 (3)查询语句 1)内连接 select a.*,b.* from a inner join b on a.id=b.parent_id
SQL Server 数据库基本知识点一、数据类型
二、常用语句 (用到的数据库Northwind) 查询语句 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。例如,下面的语句查询Customers 表中公司名称为“Alfreds Futterkiste”的ContactName字段和Address字段。 SELECT ContactName, Address FROM Customers WHERE CompanyName='Alfreds Futterkiste' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列 例如,下面语句显示Customers表中所有列的数据: SELECT * FROM Customers 2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT ContactName, Address FROM Customers 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题 as 列名 列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题: SELECT ContactName as 联系人名称, Address as地址 FROM Customers 4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 SELECT DISTINCT(Country) FROM Customers 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT 时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: SELECT TOP 2 * FROM Customers SELECT TOP 20 PERCENT * FROM Customers (二)FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在Orders和Customers表中同时存在CustomerID列,在查询两个表中的CustomerID时应 使用下面语句格式加以限定: select * from Orders,Customers where Orders.CustomerID =Customers.CustomerID 在FROM子句中可用以下两种格式为表或视图指定别名: 表名 as 别名 表名别名 select * from Orders as a,Customers as b where a.CustomerID =b.CustomerID SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如: select * from Customers where CustomerID in (select CustomerID from Orders where EmployeeID=4) 此例中,将SELECT返回的结果集合给予一别名CustomerID,然后再从中检索数据。 (三) 使用WHERE子句设置查询条件 WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:select CustomerID from Orders where EmployeeID=4
UNIT 1 四个基本概念 1.数据(Data):数据库中存储的基本对象 2.数据库的定义 :数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据集合 3.数据库管理系统(简称DBMS):位于用户与操作系统之间的一层数据管理软件(系统软件)。 用途:科学地组织和存储数据;高效地获取和维护数据 主要功能: 数据定义功能; 数据操纵功能; 数据库的运行管理; 数据库的建立和维护功能(实用程序) 4.数据库系统(Database System,简称DBS):指在计算机系统中引入数据库后的系统 数据库系统的构成 数据库 数据库管理系统(及其开发工具) 应用系统 数据库管理员(DBA)和用户 数据管理技术的发展过程 人工管理阶段 文件系统阶段 数据库系统阶段 数据库系统管理数据的特点如下 (1) 数据共享性高、冗余少;(2) 数据结构化;(3) 数据独立性高;(4) 由DBMS进行统一的数据控制功能 数据模型 用来抽象、表示和处理现实世界中的数据和信息的工具。通俗地讲数据模型就是现实世界数据的模拟。 数据模型三要素。 数据结构:是所研究的对象类型的集合,它是刻画一个数据模型性质最重要的方面;数据结构是对系统静态特性的描述 数据操作:对数据库中数据允许执行的操作及有关的操作规则;对数据库中数据的操作主要有查询和更改(包括插入、修改、删除);数据操作是对系统动态特性的描述 数据的约束条件:数据及其联系应该满足的条件限制 E-R图 实体:矩形框表示 属性:椭圆形(或圆角矩形)表示
联系:菱形表示 组织层数据模型 层次模型 网状模型 关系模型(用“二维表”来表示数据之间的联系) 基本概念: 关系(Relation) :一个关系对应通常说的一张表 元组(记录): 表中的一行 属性(字段):表中的一列,给每一个属性名称即属性名 分量:元组中的一个属性值,分量为最小单位,不可分 主码(Key):表中的某个属性组,它可以唯一确定一个元组。 域(Domain):属性的取值范围。 关系模式:对关系的描述。一般表示为:关系名(属性1,属性2,…,属性n)关系模型的数据完整性约束 实体完整性 参照完整性 用户定义的完整性 DBS三级模式结构: 外模式、概念模式、内模式(一个数据库只有一个内模式)
《数据库原理》知识点总结标准化文件发布号:(9312-EUATWW-MWUB-WUNN-INNUL-DQQTY-
目录未找到目录项。 一数据库基础知识(第1、2章) 一、有关概念 1.数据 2.数据库(DB) 3.数据库管理系统(DBMS) Access 桌面DBMS VFP SQL Server Oracle 客户机/服务器型DBMS MySQL DB2 4.数据库系统(DBS) 数据库(DB) 数据库管理系统(DBMS) 开发工具 应用系统 二、数据管理技术的发展 1.数据管理的三个阶段 概念模型 一、模型的三个世界 1.现实世界
2.信息世界:即根据需求分析画概念模型(即E-R图),E-R图与DBMS 无关。 3.机器世界:将E-R图转换为某一种数据模型,数据模型与DBMS相关。 注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2.属性: 3.关键词(码、key):能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 例:借书表(学号,姓名,书号,书名,作者,定价,借期,还期) 规定:学生一次可以借多本书,同一种书只能借一本,但可以多次续借。 4.实体型:即二维表的结构 例 student(no,name,sex,age,dept) 5.实体集:即整个二维表 三、实体间的联系: 1.两实体集间实体之间的联系 1:1联系 1:n联系 m:n联系 2.同一实体集内实体之间的联系 1:1联系 1:n联系 m:n联系 四、概念模型(常用E-R图表示) 属性: 联系: 说明:① E-R图作为用户与开发人员的中间语言。 ② E-R图可以等价转换为层次、网状、关系模型。 举例: 学校有若干个系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授 和副教授每人各带若干研究生。每个班有若干学生,每个学生选修若干课程,每门课程有若干学生选修。用E-R图画出概念模型。
目录未找到目录项。 一数据库基础知识(第1、2章) 一、有关概念 1.数据 2.数据库(DB) 3.数据库管理系统(DBMS) Access 桌面DBMS VFP SQL Server Oracle 客户机/服务器型DBMS MySQL DB2 4.数据库系统(DBS) 数据库(DB) 数据库管理系统(DBMS) 开发工具 应用系统 二、数据管理技术的发展 1.数据管理的三个阶段 概念模型 一、模型的三个世界 1.现实世界 2.信息世界:即根据需求分析画概念模型(即E-R图),E-R图与DBMS无关。 3.机器世界:将E-R图转换为某一种数据模型,数据模型与DBMS相关。
注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2.属性: 3.关键词(码、key):能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 例:借书表(学号,姓名,书号,书名,作者,定价,借期,还期) 规定:学生一次可以借多本书,同一种书只能借一本,但可以多次续借。 4.实体型:即二维表的结构 例student(no,name,sex,age,dept) 5.实体集:即整个二维表 三、实体间的联系: 1.两实体集间实体之间的联系 1:1联系 1:n联系 m:n联系 2.同一实体集内实体之间的联系 1:1联系 1:n联系 m:n联系 四、概念模型(常用E-R图表示) 属性: 联系: 说明:①E-R图作为用户与开发人员的中间语言。 ②E-R图可以等价转换为层次、网状、关系模型。 举例: 学校有若干个系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授和副教授每人各带若干研究生。每个班有若干学生,每个学生选修若干课程,每门课程有若干学生选修。用E-R图画出概念模型。
SQL SERVER性能优化综述 近期因工作需要,希望比较全面的总结下SQL SERVER数据库性能优化相关的注意事项,在 网上搜索了一下,发现很多文章,有的都列出了上百条,但是仔细看发现,有很多似是而非或 者过时(可能对SQL SERVER6.5以前的版本或者ORACLE是适用的)的信息,只好自己根据以 前的经验和测试结果进行总结了。 我始终认为,一个系统的性能的提高,不单单是试运行或者维护阶段的性能调优的任务,也不单单是开发阶段的事情,而是在整个软件生命周期都需要注意,进行有效工作才能达到的。所以我希望按照软件生命周期的不同阶段来总结数据库性能优化相关的注意事项。 一、分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能 性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。最好能 有各种需求的量化的指标。 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统)。 二、设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能 调优的过程—数据库设计。 在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效 率的代码,为整个系统的性能打下良好的基础。 以下是性能要求设计阶段需要注意的: 1、数据库逻辑设计的规范化 数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式: 第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。 第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组 成部分。消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。 第3规范: 一个非关键字段不能依赖于另一个非关键字段。消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。 更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三
、模型的三个世界 1 ?现实世界 3 ?机器世界:将 E-R 图转换为某一种数据模型,数据模型与 注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2 .属性: 3 .关键词:能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 4 .实体型:即二维表的结构 数据库系统概述 一、有关概念 1.数据 2 .数据库(DB ) 3 ?数据库管理系统 DBMS ) ccess 桌面DBMS SQL Server 客户机/服务器型 DBMS Oracle MySQL DB2 4 .数据库系统( DBS ) 厂数据库(DB ) J 数据库管理系统 幵发工具 DBMS ) 应用系统 二、数据管理技术的发展 1 ?数据管理的三个阶段 (1)人工管理阶段 (2)文件系统阶段 (3 )数据库系统阶段 概念模型 2 ?信息世界:即根据需求分析画概念模型(即 E-R 图),E-R 图与 DBMS 无关。 DBMS 相关。
5?实体集:即整个二维表三、实体间的联系:
1.两实体集间实体之间的联系 1:1 联系、 1:n 联系、 m :n 联系 2.同一实体集内实体之间的联系 1:1 联系、 1:n 联系、 m :n 联系 1.重要术语: 关系:一个关系就是一个二维表; 元组:二维表的一行,即实体; 关系模式:在实体型的基础上,注明主码。 关系模型:指一个数据库中全部二维表结构的集合。 数据库系统结构 数据库系统的 模式结构 三级模式 1.模式:是数据库中全体数据的逻辑结构和特征的描述。 ①模式只涉及数据库的结构;模式既不涉及应用程序,又不涉及数据库结构的存储; ② 外模式:是模式的一个子集,是与某一个应用程序有关的逻辑表示。 特点:一个应用程序只能使用一个外模式,但同一个外模式可为多个应用程序使用。 内模式:描述数据库结构的存储,但不涉及物理记录。 外模式 /模式映象:保证数据库的逻辑独立性; 模式 /内模式映象:保证数据库的物理独立性; 使数据库与应用系统完全分开,数据库改变时,应用系统不必改变。 数据的存取完全由 DBMS 管理,用户不必考虑存取路径。 数据库管理系统 DBMS 的功能:负责对数据库进行统一的管理与控制。 数据定义:即定义数据库中各对象的结构 数据操纵:包括对数据库进行查询、插入、删除、修改等操作。 数据控制:包括安全性控制、完整性控制、并发控制、数据库恢复。 一、层次模型: 用树型结构表示实体之间的联系。 二、网状模型: 用图结构表示实体之间的联系。 三、关系模型: 用二维表表示实体之间的联系。 数据模型 2. DBMS 的组成: DDL 4五 厶" 语言 DML 语言 2. 两级映象 3. 两级映象的意义 1.
目录 1.1.1 四个基本概念 (1) 数据(Data) (1) 数据库(Database,简称DB) (1) 长期储存在计算机内、有组织的、可共享的大量数据的集合、 (1) 基本特征 (1) 数据库管理系统(DBMS) (1) 数据定义功能 (1) 数据组织、存储和管理 (1) 数据操纵功能 (2) 数据库的事务管理和运行管理 (2) 数据库的建立和维护功能(实用程序) (2) 其它功能 (2) 数据库系统(DBS) (2) 1.1.2 数据管理技术的产生和发展 (3) 数据管理 (3)
数据管理技术的发展过程 (3) 人工管理特点 (3) 文件系统特点 (4) 1.1.3 数据库系统的特点 (4) 数据结构化 (4) 整体结构化 (4) 数据库中实现的是数据的真正结构化 (4) 数据的共享性高,冗余度低,易扩充、数据独立性高 (5) 数据独立性高 (5) 物理独立性 (5) 逻辑独立性 (5) 数据独立性是由DBMS的二级映像功能来保证的 (5) 数据由DBMS统一管理和控制 (5) 1.2.1 两大类数据模型:概念模型、逻辑模型和物理模型 (6) 1.2.2 数据模型的组成要素:数据结构、数据操作、数据的完整性约束条件. 7 数据的完整性约束条件: (7)
关系数据模型的优缺点 (8) 1.3.1 数据库系统模式的概念 (8) 型(Type):对某一类数据的结构和属性的说明 (8) 值(Value):是型的一个具体赋值 (8) 模式(Schema) (8) 实例(Instance) (8) 1.3.2 数据库系统的三级模式结构 (9) 外模式[External Schema](也称子模式或用户模式), (9) 模式[Schema](也称逻辑模式) (9) 内模式[Internal Schema](也称存储模式) (9) 1.3.3 数据库的二级映像功能与数据独立性 (9) 外模式/模式映像:保证数据的逻辑独立性 (10) 模式/内模式映象:保证数据的物理独立性 (10) 1.4 数据库系统的组成 (10) 数据库管理员(DBA)职责: (10)
浅谈优化SQLServer数据库服务器内存配置的策略 浅谈优化SQLServer数据库服务器内存配置的策略 作者:季广胜 言 农业银行总行1998年以来正式推广了新版网络版综合业务统计信息系统,该系统是基于WindowsNT4.0平台,采用客户/服务器模式,以Microsoft SQL Server为基础建立起来的大型数据库应用程序,系统界面友好、操作简便,计算、分析、检索功能非常强大,为保证农业银行系统及时进行纵向和横向业务数据采集、按照不同要求生成统计报表,进行全面业务活动分析提供了强有力的保障。但在这套程序的推广、维护中笔者发现系统有时运行速度较慢,特别是在Win95客户端操作时尤为严重,经过排除网线连接等硬件可能带来的影响后上述问题仍然存在。笔者经过仔细摸索,发现系统对硬、软件的要求较高,为充分发挥设计效能,达到最佳运作效果,需要对计算机硬、软件系统进行较为完备的性能测试与最佳配置,特别是内存配置的好坏对系统的运行速度具有决定性的作用。下面,笔者就如何优化SQLServer数据库服务器的内存配置提出一些认识和看法。 一、有关内存的基本概念 1 物理内存与虚拟内存 WindowsNT使用两类内存:物理内存与虚拟内存。
物理内存:作为RAM芯片安装在计算机内部的存储器。 虚拟内存:用于模拟RAM芯片功能的磁盘(硬盘)空间,其实质是通过将内存中当前没有使用的部分内容临时存储到磁盘上,使系统可以使用到比机器物理内存更多的内存。 2 分页和分页文件 WindowsNT系统通过使用磁盘空间使得对内存的需求得到部分缓解,从而使用到比物理内存更多内存的技术就称为“交换”或分页,也就是通常所说的虚拟内存技术。通常Windows NT 4.0系统安装时将在引导驱动器上设置一个大小为16MB的交换(分页)文件(pagefile.sys)。 二、优化Windows NT 4.0系统内存配置 在大多数情况下,为了充分发挥Windows NT 4.0系统效能,内存的作用比起处理器的处理能力更具有影响力,特别是在客户/服务器模式环境下更是如此,因为通常在这种环境下并不十分强调处理器的能力,相反却十分注重是否采用足够的内存来满足各个客户的应用需要。此外,为了获得容错功能和保护应用程序,保证应用程序高速运行、充分发挥设计功能都需要有足够多的内存,特别是工业绘图设计和各种工程应用程序更需要占用大量的内存来进行复杂的计算。 物理内存(RAM)方便快速的优点显而易见,但由于其价格昂贵,也就不可能做到多多益善了,因此通过合理优化内存配置、扩充虚拟
数据库基础知识试题 部门____________ __________ 日期_________ 得分__________ 一、不定项选择题(每题1.5分,共30分) 1.DELETE语句用来删除表中的数据,一次可以删除( )。D A .一行 B.多行 C.一行和多行 D.多行 2.数据库文件中主数据文件扩展名和次数据库文件扩展名分别为( )。C A. .mdf .ldf B. .ldf .mdf C. .mdf .ndf D. .ndf .mdf 3.视图是从一个或多个表中或视图中导出的()。A A 表 B 查询 C 报表 D 数据 4.下列运算符中表示任意字符的是( )。B A. * B. % C. LIKE D._ 5.()是SQL Server中最重要的管理工具。A A.企业管理器 B.查询分析器 C.服务管理器 D.事件探察器 6.()不是用来查询、添加、修改和删除数据库中数据的语句。D A、SELECT B、INSERT C、UPDATE D、DROP 7.在oracle中下列哪个表名是不允许的()。D A、abc$ B、abc C、abc_ D、_abc 8.使用SQL命令将教师表teacher中工资salary字段的值增加500,应该使用的命令 是()。D A、Replace salary with salary+500 B、Update teacher salary with salary+500 C、Update set salary with salary+500 D、Update teacher set salary=salary+500 9.表的两种相关约束是()。C
第一章:绪论 数据库(DB):长期存储在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定的数据模型组织、描述和存储,具有娇小的冗余度、交稿的数据独立性和易扩展性,并可为各种用户共享。 数据库管理系统(DBMS):位于用户和操作系统间的数据管理系统的一层数据管理软件。用途:科学地组织和存储数据,高效地获取和维护数据。包括数据定义功能,数据组织、存储和管理,数据操纵功能,数据库的事物管理和运行管理,数据库的建立和维护功能,其他功能。 数据库系统(DBS):在计算机系统中引入数据库后的系统,一般由数据库。数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。目的:存储信息并支持用户检索和更新所需的信息。 数据库系统的特点:数据结构化;数据的共享性高,冗余度低,易扩充;数据独立性高;数据由DBMS统一管理和控制。 概念模型实体,客观存在并可相互区别的事物称为实体。 属性,实体所具有的某一特性称为属性。 码,唯一标识实体的属性集称为码。 域,是一组具有相同数据类型的值的集合。 实体型,具有相同属性的实体必然具有的共同的特征和性质。 实体集,同一类型实体的集合称为实体集。 联系 两个实体型之间的联系一对一联系;一对多联系;多对多联系 关系模型关系,元组,属性,码,域,分量,关系模型 关系数据模型的操纵与完整性约束关系数据模型的操作主要包括查询,插入,删除和更新数据。这些操作必须满足关系完整性约束条件。关系的完整性约束条件包括三大类:实体完整性,参照完整性和用户定义的完整性。 数据库系统三级模式结构外模式,模式,内模式 模式:(逻辑模式)数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。一个数据库只有一个模式。
如何降低SQL Server 2005内存使用量与设置 我的数据库服务器内存为8G,现在资源管理器显示内存用到5G,可以肯定是sql server数据库吃内存原因。 MSSQL占用了太多的内存,而且还不断的增长;或者说已经设置了使用内存,可是它没有用到那么多,这是怎么一回事儿呢? MSSQL是怎样使用内存的: 最大的开销一般是用于数据缓存,如果内存足够,它会把用过的数据和觉得你会用到的数据统统扔到内存中,直到内存不足的时候,才把命中率低的数据给清掉。所以一般我们在看statistics io的时候,看到的physics read都是0。 其次就是查询的开销,一般地说,hash join是会带来比较大的内存开销的,而merge join 和nested loop的开销比较小,还有排序和中间表、游标也是会有比较大的开销的。 所以用于关联和排序的列上一般需要有索引。 再其次就是对执行计划、系统数据的存储,这些都是比较小的。 我们先来看数据缓存对性能的影响,如果系统中没有其它应用程序来争夺内存,数据缓存一般是越多越好,甚至有些时候我们会强行把一些数据pin在高速缓存中。但是如果有其它应用程序,虽然在需要的时候MSSQL会释放内存,但是线程切换、IO等待这些工作也是需要时间的,所以就会造成性能的降低。 方法:可以考虑增加内存,优化数据库和代码,设置MSSQL的最大内存使用等等。 max server memory 和min server memory,如何设置(2种) 1.通过SSMS界面中的服务器属性可以设置 2. --通过sp_configure设置 EXEC sp_configureN'min server memory (MB)',N'替换最小值' GO RECONFIGURE GO EXEC sp_configureN'max server memory (MB)',N'替换最大值' GO RECONFIGURE GO 如果没有其它应用程序,那么就不要限制MSSQL对内存的使用。 然后来看查询的开销,这个开销显然是越低越好,因为我们不能从中得到好处,相反,使用了越多的内存多半意味着查询速度的降低。所以我们一般要避免中间表和游标的使用,在经常作关联和排序的列上建立索引。 除了限制SQL使用内存之外,还可以优化数据库设计, 比如没有必要用char(100)的地方,就用varchar, 没有必要用int的地方就用smallint, tinyint, 没有必要用双字节nvarchar的地方,就用varchar, 这些都能有效减少读入内存的数据。 但如果有很多历史数据的话,很多人都不会去做的。 或者就是优化SQL代码。
数据库模型基础知识及数据库基础知识总结 数据库的4个基本概念 1.数据(Data):描述事物的符号记录称为数据。 2.数据库(DataBase,DB):长期存储在计算机内、有组织的、可共享的大量数据的集合。 3.数据库管理系统(DataBase Management System,DBMS 4.数据库系统(DataBase System,DBS) 数据模型 数据模型(data model)也是一种模型,是对现实世界数据特征的抽象。用来抽象、表示和处理现实世界中的数据和信息。数据模型是数据库系统的核心和基础。数据模型的分类 第一类:概念模型 按用户的观点来对数据和信息建模,完全不涉及信息在计算机中的表示,主要用于数据库设计现实世界到机器世界的一个中间层次 ?实体(Entity): 客观存在并可相互区分的事物。可以是具体的人事物,也可以使抽象的概念或联系 ?实体集(Entity Set): 同类型实体的集合。每个实体集必须命名。 ?属性(Attribute): 实体所具有的特征和性质。 ?属性值(Attribute Value): 为实体的属性取值。 ?域(Domain): 属性值的取值范围。 ?码(Key): 唯一标识实体集中一个实体的属性或属性集。学号是学生的码?实体型(Entity Type): 表示实体信息结构,由实体名及其属性名集合表示。如:实体名(属性1,属性2,…) ?联系(Relationship): 在现实世界中,事物内部以及事物之间是有联系的,这些联系在信息世界中反映为实体型内部的联系(各属性)和实体型之间的联系(各实体集)。有一对一,一对多,多对多等。 第二类:逻辑模型和物理模型 逻辑模型是数据在计算机中的组织方式
SQL Server使用2G以上内存设置方法 摘要 在32位的Windows 2003 Server中,进程内存被限制为2GB,而目前数据库服务器基本上都配置有4G内存甚至更多,因此如何有效利用多出的内存,是数据库服务器性能优化的重要部分。本文简要介绍了PAE和AWE的原理以及配置方法,使得32位的环境下可以突破2G这一瓶颈,从而提升数据库服务器的效率。 1.AWE简介 目前随着硬件成本的降低,一般的服务器具有4G以上的内存。可能很多人认为,如果使用Winows 2003 Server系统,最高可以支持4G内存。其实这么说并不准确,应该说32位机支持2^32=4G 的寻址空间,但实际上默认应用程序只能占用其中的2G内存,这一限制是32位操作系统架构引起的。传统意义上的32bit操作系统使用32bit的内存地址,这样寻址范围就已经被限制为4GB——4G也就是2的32次方,然而通常操作系统的设计上为了安全性的考虑,应用程序和内核所处的内存地址空间是互相独立的,也就是说,应用程序和内核各自能访问2GB的内存空间。虽然不同的操作系统实现具有不同的值,不过多数现在的操作系统在这一点上都很一致。 为了让程序突破2GB寻址的限制,近代Windows NT核心提供了一个变通的方案:4GB内存调整优化技术,通过这个技术,可以将用户模式的寻址空间扩大至3GB,这样核心寻址空间便被限制为1GB了,需要超大内存容量的应用程序可以从这个特性中获得性能改善,如SQL Server数据库这种类型。要使用这个4GB内存优化技术,用户需要在Windows Server操作系统的启动参数中加入/3GB 开关。 然而让用户模式程序能多寻址1GB毕竟还算是治标不治本,于是Microsoft 还在自己的操作系统中通过PAE 提高IA32 处理器处理大于 4 GB 的物理内存的能力。下列操作系统可以通过PAE 来利用大于 4 GB 的物理内存: Microsoft Windows 2000 Advanced Server
三、数据库的概念与用途 数据库的概念 什么是数据库呢当人们从不同的角度来描述这一概念时就有不同的定义(当然是描述性的)。例如,称数据库是一个“记录保存系统”(该定义强调了数据库是若干记录的集合)。又如称数据库是“人们为解决特定的任务,以一定的组织方式存储在一起的相关的数据的集合”(该定义侧重于数据的组织)。更有甚者称数据库是“一个数据仓库”。当然,这种说法虽然形象,但并不严谨。严格地说,数据库是“按照数据结构来组织、存储和管理数据的仓库”。在经济管理的日常工作中,常常需要把某些相关的数据放进这样“仓库”,并根据管理的需要进行相应的处理。例如,企业或事业单位的人事部门常常要把本单位职工的基本情况(职工号、姓名、年龄、性别、籍贯、工资、简历等)存放在表中,这张表就可以看成是一个数据库。有了这个“数据仓库”我们就可以根据需要随时查询某职工的基本情况,也可以查询工资在某个范围内的职工人数等等。这些工作如果都能在计算机上自动进行,那我们的人事管理就可以达到极高的水平。此外,在财务管理、仓库管理、生产管理中也需要建立众多的这种“数据库”,使其可以利用计算机实现财务、仓库、生产的自动化管理。 给数据库下了一个比较完整的定义:数据库是存储在一起的
相关数据的集合,这些数据是结构化的,无有害的或不必要的冗余,并为多种应用服务;数据的存储独立于使用它的程序;对数据库插入新数据,修改和检索原有数据均能按一种公用的和可控制的方式进行。当某个系统中存在结构上完全分开的若干个数据库时,则该系统包含一个“数据库集合”。 数据库的优点 人事基本档案 使用数据库可以带来许多好处:如减少了数据的冗余度,从而大大地节省了数据的存储空间;实现数据资源的充分共享等
期末复习顺便总结下,书本为高等教育出版社的《数据库系统概论》。 第一章知识点 数据库是长期储存之计算机内的、有组织的、可共享的大量数据的集合。?1,数据库数据特点P4 永久存储,有组织,可共享。?2,数据独立性及其如何保证P10,P34 逻辑独立性:用户的应用程序与数据库的逻辑结构互相独立。(内模式保证) 物理独立性:用户的应用程序与存储在磁盘上的数据库中的数据相互(外模式保证) 3,数据模型的组成要素P13 数据结构、数据操作、完整性约束。 4,用ER图来表示概念模型P17 实体、联系和属性。联系本身也是一种实体型,也可以有属性。 第二章 1,关系的相关概念(如关系、候选码、主属性、非主属性) P42-P44单一的数据结构----关系。现实世界的实体以及实体间的各种联系均用关系来表示。 域是一组具有相同数据类型的值的集合。 若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码 关系模式的所有属性组是这个关系模式的候选码,称为全码 若一个关系有多个候选码,则选定其中一个为主码 候选码的诸属性称为主属性 不包含在任何侯选码中的属性称为非主属性 2关系代数运算符P52
自然连接是在广义笛卡尔积R×S中选出同名属性上符合相等条件元组,再进行投影,去掉重复的同名属性,组成新的关系。 给定关系r(R)和s(S), S? R,则r ÷s是最大的关系t(R-S) 满足tx s?r 3,关系代数表达式 第三章
1,SQL的特点P79-P80 1. 综合统一 2. 高度非过程化 3. 面向集合的操作方式 4.以同一种语法结构提供多种使用方式 5. 语言简洁,易学易用 2,基本表的定义、删除和修改P84-P87 PRIMARY KEY PRIMARYKEY (Sno,Cno) UNIQUE FOREIGN KEY(Cpno) REFERENCES Course(Cno) ALTER TABLE <表名> [ ADD <新列名><数据类型>[完整性约束] ] [ DROP<完整性约束名>] [ALTER COLUMN<列名> <数据类型> ]; DROP TABLE<表名>[RESTRICT|CASCADE]; 3,索引的建立与删除P89-P90 CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…); 唯一索引UNIQUE、非唯一索引或聚簇索引CLUSTER
辽宁工业大学 《SQL server数据库设计实训》报告题目:餐饮管理系统 院(系): 软件学院 专业班级:电子商务(国际) 学号: 学生姓名: 指导教师:翟宝峰 教师职称:副教授 起止时间:2011.09.03-2011.09.14
设计任务及评语
目录 第1章设计目的与要求 (1) 1.1设计目的 (1) 1.2设计环境 (1) 1.3主要参考资料 (1) 1.4设计内容及要求 (1) 第2章设计内容 (2) 2.1数据库设计 (2) 2.1.1需求分析 (2) 2.1.2概念设计 (5) 2.1.3逻辑设计 (6) 2.1.4物理设计 (7) 2.1.5 数据库实现 (7) 2.2程序设计 (11) 2.2.1概要设计 (11) 2.2.2程序实现 (11) 第3章设计总结 (14) 参考文献 (15)
第1章设计目的与要求 1.1设计目的 本设计专题是软件工程类专业的有关管理信息系统设计开发的一个重要环节,是本专业学生必须学习和掌握的综合实践课程。 本实践课的主要目的是:(1)、掌握运用管理系统及数据库原理知识进行系统分析和设计的方法;(2)掌握关系数据库的设计方法;(3)掌握SQL Server 2000技术应用;(4)掌握简单的数据库应用程序编写方法;(5)理解C/S模式结构。 1.2设计环境 硬件:处理器,Intel Pentium 166 MHz以上,内存:512M 以上,硬盘空间:8G 以上 软件:Windows XP需要软件:Microsoft Visual Basic 6.0,Microsoft SQL Server 2000 1.3主要参考资料 1.《管理信息系统》黄梯云高等教育出版社 2.《数据库系统概论》萨师煊高等教育出版社 3.《SQL Server 2000 数据库应用系统开发技术》朱如龙编,机械工业出版社。 4.《SQL Server 2000 数据库应用系统开发技术实验指导》朱如龙编,机械工业出版社 1.4设计内容及要求 一、内容 1.要求根据管理信息系统及数据库设计原理,按照数据库系统设计的步骤和规范, 完成各阶段的设计内容。 2.需求分析具体实际,数据流图、数据字典、关系模型要正确规范 3.在sql server2000 上实现设计的数据库模型。 4.对应用程序进行概要设计。 5.用VB实现简单的应用程序编写。 二、要求 设计过程中,要严格遵守课程设计的时间安排,听从指导教师的指导。正确地完成上述内容,规范完整地撰写出课程设计报告。
数据库系统概论复习参考题 一、选择题 1、描述事物的符号记录称为:( B ) A) 信息 B) 数据 C) 记录 D) 记录集合 2、( A )是位于用户和操作系统之间的一层数据管理软件。 A) 数据库管理系统 B) 数据库系统C) 数据库 D) 数据库运用系统 3、在人工管理阶段,数据是( B )。 A) 有结构的 B) 无结构的 C) 整体无结构,记录有结构 D) 整体结构化的 4、在文件系统阶段,数据是(B )。 A) 无独立性 B) 独立性差 C) 具有物理独立性 D)有逻辑独立性 5、在数据库系统阶段,数据是(D )。 A) 有结构的 B) 无结构的 C) 整体无结构,记录内有结构 D) 整体结构化的 6、数据库系统阶段,数据( D )。 A) 具有物理独立性,没有逻辑独立性 B) 具有物理独立性和逻辑独立性 C) 独立性差D)具有高度的物理独立性和一定程度的逻辑独立性 7、(B )属于信息世界的模型,实际上是现实世界的一个中间层次。 A)数据模型 B)概念模型C) 物理模型 D) 关系模型 8、在对层次数据库进行操作时,如果删除双亲结点,则相应的子女结点值也被同时删除。这是有层次模型的( C )决定的。 A) 数据结构 B) 数据操作C)完整性约束 D) 缺陷 9、( A )是数据结构,关系操作集合和完整性约束三部分组成。 A)关系模型 B) 关系 C) 关系模式 D) 关系数据库 10、在关系模型中,一组具有相同数据类型的值的集合称为( D ) A) 关系 B) 属性 C) 分量 D)域 11、关系是------。( D ) A) 型 B) 静态的 C) 稳定的 D)关系模式的一个实例 12、数据结构设计中,用E—R图来描述信息结构但不涉及信息在计算机中的表示,这是数据库设计的( B )阶段。 A) 需求分析 B) 概念设计 C) 物理设计 D) 逻辑设计 13、非关系模型中数据结构的基本单位是( C )。 A) 两个记录型间的联系 B) 记录 C) 基本层次联系 D) 实体间多对多的联系 14、在数据模型的三要素中,数据的约束条件规定及其联系的( A ) 。 A) 制约规则 B) 动态特性 C) 静态特性 D) 数据结构 15、若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为( B )。 A) 唯一码 B) 候选码 C) 主属性 D) 外码 16、候选码中的属性成为( B )。 A) 复合属性 B) 主属性 C) 非主属性 D) 码属性 17、候选码中的属性成为( B ) A) 复合属性 B) 主属性 C) 非主属性 D) 码属性
SELECT查询包括条件项、内连接、分组汇总(含HAVING)、排序、简单子查询(不考EXIS TS)及一些输出选项。 数据库管理系统(DBMS)特点(1)数据结构化(2)数据共享性好、冗余度低、(3)数据独立性强(4)DBMS统一管理。 数据库(DB),就是相关联的数据的集合。 数据库系统(DBS),是指在计算机中引入数据库后的系统构成,由计算机软硬件、数据库、D BMS、应用程序以及数据库管理员(DBA)和数据库用户构成。 关系模型是一种数据模型关系模型中最重要的概念就是关系。关系(Relation),直观的看,就是由行和列组成的二维表,一个关系就是一张二维表。 关系中的一列称为关系的一个属性(Attribute),一行称为关系的一个元组(Tuple)。 组称为候选键(Candidate Key),从候选键中挑选一个作为该关系的主键(Primary Key)。一个关系中存放的另一个关系的主键称为外键(Foreign Key)。并不是任何的二维表都可以称为关系。关系具有以下特点: ?关系中的每一列属性都是原子属性,即属性不可再分; ?关系中的每一列属性都是同质的,即每一个元组的该属性取值都表示同类信息; ?关系中的属性间没有先后顺序; ?关系中元组没有先后顺序; ?关系中不能有相同的元组。 关系模型,就是对一个数据处理系统中所有数据对象的数据结构的形式化描述。将一个系统中所有不同的关系模式描述出来,就建立了该系统的关系模型。 关系数据库,是依据关系模型建立的数据库,是目前各类数据处理系统中最普遍采用的数据库类型。依照关系理论设计的DBMS,称为关系DBMS。数据库设计指:对于给定的应用环境,设计构造最优的数据库结构,建立数据库及其应用系统,使之能有效地存储数据,对数据进行操作和管理,以满足用户各种需求的过程。 联系有三种类型,转化为关系模式后,与其他关系模式可进行合并优化。 1:1的联系,一般不必要单独成为一个关系模式,可以将它与联系中的任何一方实体转化成的关系模式合并(一般与元组较少的关系合并)。 1:n的联系也没有必要单独作为一个关系模式,可将其与联系中的n方实体转化成的关系模式合并。 m:n的联系必须单独成为一个关系模式,不能与任何一方实体合并。