语义模型整理
- 格式:ppt
- 大小:1.13 MB
- 文档页数:9

信息理解的语义量化模型及信度
信息理解的语义量化模型及信度
信息理解是人类信息处理的基础。
它是指人类从同一消息文本中获取关于消息主题的理解。
这种行为被称为自然语言处理(NLP),自然语言理解(NLU)或语义理解(SLU),这些方法都是使用计算机程序来识别和解释文本中的意思,这就要求计算机程序拥有一个能够准确和可靠地识别文本中的语义单元的机制。
自然语言处理旨在帮助人们从一篇文本中识别有价值的内容,以便可以以更有效的方式来理解文本的意义。
一个有效的自然语言处理系统必须具备以下条件:
1、语义量化模型:即系统必须能够以一种可量化的方式表达文本的含义,用于识别文本中的不同词汇和语法特征,并能够分析同义词、反义词和其他相关的信息结构。
2、信度:即系统必须能够评估解释文本的结果的可靠程度,以便让用户更容易地识别出文本中的真正的含义。
3、可扩展性:即系统必须具有可以应对不同类型的文本的解决方案,以使用户可以从多种形式的文本(例如,短信,聊天,微博等)中获取信息。
通过使用这些工具,开发者可以构建语义理解系统,以便更有效地理解文本的含义。
在这些系统中,开发者使用语义量化模型来识别文本的不同结构,同时也分析其中的词汇和句子的结构,以准确测量文本的含义。
接下来,系统将对获得的结果进行信度分析,以评估其
可靠性,以便能够使用户更有效率地理解文本的实际意义。

清华自然语义最大的模型
近日,清华大学发布了一款自然语义最大的模型,该模型名为“清华GPT”,共有2.6亿个参数,是目前全球最大的自然语义模型之一。
据清华大学计算机系教授介绍,该模型主要用于自然语言处理领域,可以自动回答问题、进行翻译、生成文章等任务。
与此前的模型相比,清华GPT在语义理解和表达上具有更高的精度和表现力,能够更好地处理自然语言中的复杂关系和语义歧义。
此外,该模型还拥有强大的学习能力,可以根据不同的任务和领域进行自适应调整和优化。
这意味着,清华GPT可以在多个领域中发挥作用,如智能客服、智能机器人、智能翻译等。
该模型的发布,标志着我国在人工智能领域取得了新的进展,也为我国的自然语言处理技术发展注入了新的动力。
未来,清华GPT有望为我国的人工智能应用开发和推广提供重要的支持和保障。
- 1 -。


室内场景的语义分割模型随着人工智能的快速发展,语义分割技术在图像处理领域扮演着重要的角色。
室内场景的语义分割模型是其中的一个重要应用,它能够将室内场景的图像进行像素级别的分类,从而实现对不同物体的精确识别和分割。
语义分割模型主要由两部分组成:编码器和解码器。
编码器负责将输入的图像进行特征提取和降维,将图像转化为高层次的语义特征表示;解码器则负责将编码后的特征图像还原为原始分辨率的语义分割图像。
这样,模型就能够准确地将图像中的每一个像素分类为不同的物体或背景。
在室内场景的语义分割模型中,常见的物体包括墙壁、地板、家具、电器等。
通过对这些物体进行语义分割,我们可以实现对室内场景的智能识别和理解。
例如,在室内导航系统中,语义分割模型可以帮助机器人识别出房间的不同区域,从而更好地完成导航任务。
在智能家居系统中,语义分割模型可以帮助智能助手识别出家具和电器的位置,从而实现更精准的语音控制。
为了训练一个准确可靠的室内场景的语义分割模型,需要大量的标注数据。
这些数据需要手动标注每一个像素的类别,包括墙壁、地板、家具等。
然后,通过使用深度学习算法,如卷积神经网络(CNN)或全卷积网络(FCN),可以对这些标注数据进行训练,从而得到一个高效准确的语义分割模型。
除了标注数据的质量外,模型的架构和参数也对语义分割的准确性和效率有着重要影响。
近年来,研究人员提出了许多改进的网络结构和算法,如U-Net、SegNet和DeepLab等。
这些模型在准确性和效率上都有很大的提升,能够更好地解决室内场景的语义分割问题。
然而,室内场景的语义分割仍然面临一些挑战。
首先,室内场景的复杂性使得物体之间存在遮挡和重叠的情况,这对分割算法提出了更高的要求。
其次,室内场景中的光照和视角变化也会对分割结果造成影响,需要进一步考虑如何提高模型的鲁棒性。
此外,语义分割模型的训练和推理过程需要大量的计算资源,如GPU和内存,对于资源受限的设备来说,还需要进一步优化算法和模型结构。

语义信息模型定义
语义信息模型定义
语义信息模型是一种描述语言或者说约定,它用语义术语对某个领域
或某个中心问题进行建模或者描述。
它通常用于描述信息或者知识的
含义以及它们如何与其他信息或者知识关联在一起。
该模型将信息或
者知识转换成了计算机可处理的形式,实现了关于信息或者知识的命名、描述、逻辑关系的存储和查询等基本操作。
语义信息模型可以采用不同的形式,包括本体、语义网等。
本体是一
个规范的、共同使用的元数据集合,描述特定领域的概念、术语和它
们之间的关系。
它描述了世界的各个方面,用于在不同应用和组织间
进行信息交换和知识共享。
语义网是一种互联的、链式的数据结构,
可以将信息资源和知识链接起来,形成一个全球性的信息共享平台。
语义信息模型的定义具有以下特点:
1. 明确且精准:语义信息模型通过使用标准化语义的概念、术语和关
系来建模和描述知识,具有精确的定义和明确的含义。
2. 强调关联:语义信息模型将重点放在信息或知识之间的关联性方面,而非单纯的以文本或关键字的形式呈现信息。
3. 通用性:语义信息模型可适用于各种领域,能够跨越不同的行业和
组织,以实现语义互操作性。
4. 与传统方法的区别:语义信息模型通过使用元数据、本体和语义网
等技术,与传统的文本搜索和关键字检索等方法不同。
总之,语义信息模型是一种描述语言,在知识共享、搜索引擎、企业本体实现等领域有着广泛的应用。
使用语义信息模型可以更好地将知识、信息、数据连接起来,从而提高数据的利用价值和效率。

语义分割是计算机视觉领域的一个重要任务,旨在将图像中的每个像素分配到不同的语义类别。
以下是一些常见的用于语义分割的模型:U-Net:U-Net是一种经典的全卷积网络,由编码器和解码器组成。
编码器负责提取图像的高级特征,而解码器则将特征映射恢复到与原始图像相同的分辨率。
U-Net具有良好的特征传递和上下文理解能力,常用于医学图像分割等任务。
FCN(Fully Convolutional Network):FCN是一种基于全卷积网络的语义分割模型。
FCN通过将传统的卷积神经网络转换为全卷积结构,可以输出与输入图像相同尺寸的像素级别预测结果。
它通过使用跳跃连接和上采样技术来融合不同尺度的特征信息。
DeepLab:DeepLab是一系列的语义分割模型,其中最著名的是DeepLabv3和DeepLabv3+。
DeepLab采用了空洞卷积(Dilated Convolution)来扩大感受野,以捕获更大范围的上下文信息。
同时,DeepLab还引入了空间金字塔池化(Spatial Pyramid Pooling)和条件随机场(Conditional Random Field)等技术,以进一步提高分割精度。
Mask R-CNN:Mask R-CNN是一种基于区域卷积神经网络(R-CNN)的语义分割模型。
它在R-CNN的基础上引入了额外的分割分支,使得模型能够同时预测目标的类别、边界框和像素级别的分割掩码。
Mask R-CNN常用于目标检测和语义分割的联合任务。
PSPNet(Pyramid Scene Parsing Network):PSPNet利用金字塔池化(Pyramid Pooling)的思想,以不同尺度的感受野来融合全局和局部信息。
它通过多尺度的特征表示提高了分割的准确性,并在分割任务中取得了优秀的性能。
这只是一小部分常见的语义分割模型,还有其他模型如ENet、BiSeNet、UNet++等也被广泛应用于语义分割任务中。

通用语义分割模型1.引言1.1 概述概述部分将对通用语义分割模型进行简要的介绍和概括。
通用语义分割模型是一种重要的计算机视觉模型,旨在将图像中的每个像素分类为特定的语义类别。
与传统的图像分类任务不同,语义分割模型能够更精细地理解图像,并为每个像素分配语义标签,从而实现对图像中不同物体和区域的精确识别。
通用语义分割模型的基本原理是利用深度神经网络进行像素级别的分类。
该模型通过学习从输入图像到语义分割标签的映射关系,从而实现对图像中每个像素的分类。
这种模型通常基于卷积神经网络(Convolutional Neural Network, CNN)进行设计,CNN可以有效地提取图像的特征,并利用这些特征进行像素级别的分类。
通用语义分割模型在近年来取得了巨大的进展,并在许多计算机视觉任务中发挥着重要作用。
例如,它可以应用于自动驾驶中的场景感知,在车辆识别、道路分割等方面发挥关键作用。
同时,在医学影像以及农业领域等其他应用中,通用语义分割模型也能够实现对不同结构和区域的精确识别。
本文旨在对通用语义分割模型进行深入探讨,并介绍其基本原理和应用领域。
在正文部分,将详细介绍通用语义分割模型的定义和原理,以及其在各个领域中的具体应用。
最后,结论部分将对整篇文章进行总结,并展望通用语义分割模型未来的发展方向。
通过本文的阐述,读者将能够全面了解通用语义分割模型的基本概念和应用前景。
1.2文章结构文章结构部分的内容应该对整篇文章的结构进行简单介绍和概述。
以下是可能的内容:文章结构部分旨在为读者提供对整篇长文的结构和组织方式的概览。
通过了解文章的结构,读者可以更好地理解文章的主要内容和论点,从而更有效地阅读和理解文章的内容。
本文的结构按照通用语义分割模型进行组织。
首先,在引言部分对本文的概述进行描述,包括概述、文章结构和目的。
接下来,在正文部分分为两个主要内容,分别是通用语义分割模型的定义和原理以及该模型在不同领域的应用。

语义解析大模型流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!语义解析大模型流程。
1. 预训练。
收集海量文本数据,包括各类语言、文档和知识库。

Elasticsearch 语义向量模型探究:从简到繁的理解1. 引言在当今大数据时代,搜索引擎技术已成为信息检索领域的关键。
Elasticsearch作为一款开源的分布式搜索和分析引擎,其语义向量模型引起了广泛关注。
本文将从简到繁地探讨Elasticsearch语义向量模型,帮助读者深入理解其应用和意义。
2. 什么是Elasticsearch语义向量模型Elasticsearch的语义向量模型是基于自然语言处理技术,通过将文本转换成向量形式来实现语义相似性计算和检索。
该模型利用深度学习技术,将文本信息映射为高维向量空间的位置,从而实现对文本语义的理解和相似性计算。
3. Elasticsearch语义向量模型的应用场景在搜索引擎领域,语义向量模型可以被广泛应用于文本相似度匹配、智能问答系统、内容推荐等场景。
在电商评台中,可以利用语义向量模型实现对商品描述的相似性匹配,从而提高搜索结果的准确性和用户体验。
4. Elasticsearch语义向量模型的实现原理语义向量模型的实现原理主要包括文本表示、相似性计算和模型训练三个方面。
通过词嵌入技术将文本信息转换为稠密向量表示;利用余弦相似度等方法进行相似性计算;通过深度学习模型进行向量空间的训练和优化,提高模型的表达能力和泛化能力。
5. Elasticsearch语义向量模型的优势与劣势语义向量模型具有高效的相似性计算能力和良好的泛化能力,可以有效解决传统搜索引擎在语义理解方面的局限性。
但与此模型训练和维护成本较高,对硬件资源和算法优化有一定要求。
6. 个人观点与总结Elasticsearch的语义向量模型有着广阔的应用前景和极大的商业价值,但在实际应用中需要充分考虑模型的性能和成本问题。
在不断的技术革新和优化中,相信Elasticsearch语义向量模型将会在搜索引擎领域发挥越来越重要的作用。
通过对Elasticsearch语义向量模型的深入探讨,相信读者能够更加全面、深刻和灵活地理解该概念,并在实际场景中更好地应用和实践。

文本语义相似度模型训练 python1. 简介文本语义相似度是自然语言处理领域的一个重要任务,它可以衡量两段文本之间的语义相似程度。
在很多应用中,如问答系统、信息检索和推荐系统中都会用到文本语义相似度。
在本篇文章中,我们将介绍如何使用python进行文本语义相似度模型的训练。
2. 文本语义相似度模型文本语义相似度模型的训练可以通过深度学习方法实现。
其中,常用的模型包括Siamese神经网络、BERT等。
这些模型可以学习文本之间的语义表征,从而实现判断文本语义相似度的任务。
3. 数据准备在训练文本语义相似度模型之前,我们需要准备大量的文本语料数据。
这些数据应该包括正向语义相似的文本对和负向语义相似的文本对,以便模型学习区分相似和不相似的文本。
还需要对文本数据进行预处理,如分词、去停用词和词向量化等。
4. 模型训练在python中,我们可以使用深度学习框架如TensorFlow或PyTorch来构建文本语义相似度模型。
通过构建Siamese神经网络或使用预训练的BERT模型,我们可以对准备好的文本数据进行训练。
在训练过程中,需要选择合适的损失函数和优化器来优化模型的参数。
5. 模型评估训练完成后,我们需要对模型进行评估。
通常,可以使用一些评估指标如准确度、精确度、召回率和F1值来评估模型的性能。
还需要使用测试集来验证模型对于未见过的文本数据的泛化能力。
6. 模型应用训练完成的文本语义相似度模型可以在实际应用中发挥作用。
可以用它来衡量两段问答文本的相似度,用于信息检索的排序和推荐系统的内容匹配等任务中。
7. 结语通过python,我们可以方便地使用深度学习框架来训练文本语义相似度模型。
希望本文能够对您在文本语义相似度模型训练方面有所帮助。
8. 模型优化和调参在训练文本语义相似度模型过程中,除了选择合适的损失函数和优化器外,还需要进行模型的优化和调参工作。
在Siamese神经网络中,可以尝试调整网络的深度、宽度和激活函数等参数,以获得更好的性能。
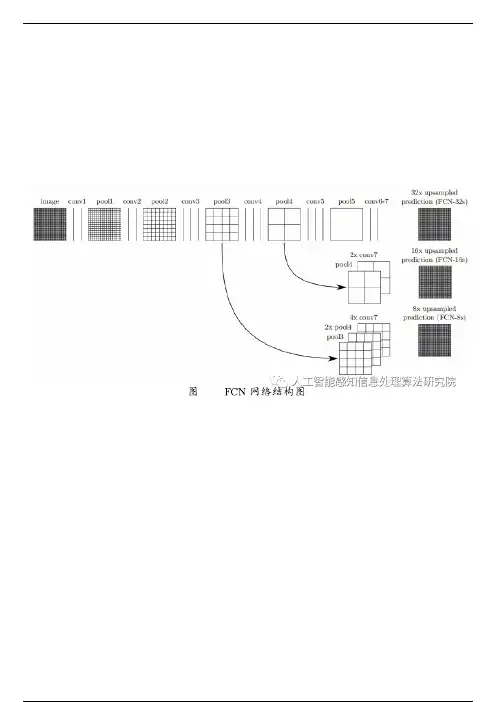
经典的基于 CNN 的图像语义分割模型有 FCN、SegNet、U-Net、PSPNet 和DeepLab,主要针对 FCN、SegNet 和 DeepLab 三个经典模型进行简要介绍。
FCN 之所以称为全卷积神经网络模型,是因为 FCN 去掉了图像分类网络中的全连接层,全连接层得到的是整张图像的分类结果,而图像语义分割是实现对每一个像素点的分类,因此去掉全连接层,且去掉全连接层后可使模型适应不同尺寸图像的输入,由于最后的特征图在提取特征过程中会丢失图像位置信息,即得到的特征图像素小于原图像,基于该问题,FCN 利用反卷积(Deconvolution)的方法对特征图进行上采样操作,将其恢复到原始图像尺寸,同时采用跳跃(Skip)结构对不同深度层的特征图进行融合,然后利用监督函数不断进行反向传播,调整学习参数,最后得到最优的参数模型。
FCN 的网络结构图如下:SegNet 是在 FCN 的基础上进行的改进,同时引入了预训练模型 VGG-16提取图像特征,SegNet 不同于 FCN,SegNet 采用的是对称的编码器-解码器结构,这种结构主要分为编码器和解码器两个部分,编码器采用 VGG-16模型对图像进行特征提取,如上图所示,每个编码器包含多层卷积操作、BN、ReLU 以及池化层,其中卷积操作采用的是 same padding方式,即图像大小不会发生改变,而池化层采用的是步长为 2 的2 × 2的最大池化,会降低图像分辨率,如图中所示,每一层编码器得到的特征图除了传入下一层编码器进行特征提取外,同时要传入对应层的解码器进行上采样,如此一来,有多少层编码器就会对应地有多少层解码器,最终解码器得到的特征图会输入到 SoftMax分类器中,继而得到最后的预测图。
DeepLab 模型是图像语义分割领域中非常经典的一个模型,包括 DeepLab V1、V2和V3 三个版本,由于 DeepLab V3 是在 DeepLab V2的基础上进行的改进,因此,本小节只简单介绍 DeepLab V1 和 DeepLab V2。
国内大模型中文语义理解能力排行榜国内大模型中文语义理解能力排行榜随着人工智能技术的不断发展,自然语言处理领域也迎来了一次次的革新。
其中,大模型的崛起成为了自然语言处理领域的重要里程碑。
在这个领域中,中文语义理解能力更是备受关注,因为这直接关系到人工智能在中文应用中的表现。
国内也出现了不少相关的语义理解能力排行榜,评估各大模型在中文语义理解上的表现。
本文将对国内大模型中文语义理解能力排行榜进行全面评估,并分享个人观点和理解。
一、国内大模型中文语义理解能力排行榜1. 百度开发的ERNIE2. 中科院计算所开发的CLUE3. 华为开发的BERT4. 必应开发的T-Brain5. 深度之眼团队开发的RoBERTa这些大模型在中文语义理解方面取得了不俗的成绩,不仅在学术界受到了认可,也在工业界有着广泛的应用。
它们的出现大大提升了自然语言处理的水平,也为中文语义理解能力排行榜增添了新的分量。
二、深度和广度的探讨在探讨国内大模型中文语义理解能力排行榜的深度和广度时,我们需要从模型的基本原理、具体应用场景、在中文语义理解方面的突破、以及未来的发展方向等多个方面进行全面评估。
1. 模型的基本原理在这部分,我们可以从模型的训练语料、预训练技术、微调技术等方面展开,详细讨论模型在中文语义理解中的效果和优势。
2. 具体应用场景大模型在中文语义理解方面的应用场景非常广泛,涉及到文本分类、命名实体识别、情感分析、机器翻译等多个领域。
通过实际案例的介绍,我们可以更加形象地展示大模型的价值。
3. 突破与发展优秀的大模型不仅需要在实验室中取得优异的实验结果,还需要在实际生产环境中有所突破。
在国内大模型中文语义理解能力排行榜中,我们可以详细探讨各大模型在实际应用中的表现,以及所取得的突破和进步。
4. 未来发展方向我们还可以展望国内大模型中文语义理解能力排行榜的未来发展方向,探讨如何进一步提升模型的中文语义理解能力,以及在更多领域中实现模型的落地应用。
技术标准语义识别大模型技术下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
此文下载后可定制随意修改,请根据实际需要进行相应的调整和使用。
并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Downloaded tips: This document is carefully compiled by the editor. I hope that after you download them, they can help you solve practical problems. The documents can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, our shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!《技术标准。
语义识别的大模型技术》。
语义通信和大模型1. 介绍语义通信是指通过语义理解和自然语言处理技术,实现人与机器之间的交流和沟通。
大模型是指在深度学习领域中,由大量参数组成的模型。
语义通信和大模型的结合,可以提升机器对人类语言的理解和生成能力,从而实现更加智能化的人机交互体验。
2. 语义通信的基本原理语义通信的基本原理是将自然语言转化为机器可以理解和处理的形式。
这涉及到自然语言理解和自然语言生成两个方面。
2.1 自然语言理解自然语言理解是指将人类语言转化为机器可以理解的形式。
其中一个关键技术是语义解析,即将自然语言句子转化为语义表示。
语义表示可以是逻辑形式、语义图或其他形式,用于表示句子的语义结构和含义。
另一个关键技术是命名实体识别和关系抽取,用于识别句子中的实体和实体之间的关系。
这可以帮助机器更好地理解句子中的含义和上下文。
2.2 自然语言生成自然语言生成是指将机器生成的语义表示转化为自然语言句子。
这包括句子的语法生成、语义合理性和流畅性等方面的处理。
生成的句子需要符合语法规则,并且能够准确地表达机器的意图和内容。
3. 大模型在语义通信中的应用大模型在语义通信中扮演着重要的角色。
大模型可以通过大量的参数和训练数据,提升机器对语义的理解和生成能力。
3.1 语义理解大模型可以通过训练大规模的语义理解模型,提升对句子的语义解析和命名实体识别的准确性。
大模型可以从海量的语料中学习到更丰富的语义知识,从而提高对句子的理解能力。
3.2 语义生成大模型可以通过训练大规模的语义生成模型,提升机器生成自然语言句子的质量和流畅度。
大模型可以学习到更多的语言模式和表达方式,从而生成更准确、更自然的句子。
3.3 对话系统大模型在对话系统中也有广泛的应用。
对话系统是一种基于语义通信的人机交互系统,大模型可以通过训练大规模的对话模型,提升系统的对话能力和交互体验。
4. 大模型的挑战和解决方案虽然大模型在语义通信中有很多优势,但也面临着一些挑战。
4.1 模型大小和计算资源需求大模型通常需要大量的参数和计算资源进行训练和推理,这对计算资源的要求较高。