java调用存储过程返回map组装List(含SqlServer存储过程)
- 格式:docx
- 大小:17.91 KB
- 文档页数:6

sqlserver存储过程调试方法SQL Server是一种常用的关系型数据库管理系统,它提供了存储过程的功能,可以在数据库中存储一段预编译的SQL代码,并在需要时进行调用。
存储过程通常用于执行复杂的数据库操作,提高数据库的性能和安全性。
在开发和调试存储过程时,我们需要一些方法来验证和调试代码的正确性。
本文将介绍一些常用的SQL Server 存储过程调试方法。
1. 使用PRINT语句输出调试信息在存储过程中,可以使用PRINT语句输出一些调试信息,例如变量的值、执行的步骤等。
通过在关键位置添加PRINT语句,可以观察存储过程执行过程中的中间结果,从而验证代码的正确性。
例如:```PRINT '开始执行存储过程'PRINT '变量@x的值为:' + CONVERT(VARCHAR(10), @x)```2. 使用SELECT语句输出结果集在存储过程中,可以使用SELECT语句返回结果集。
通过在存储过程中添加SELECT语句,可以观察查询结果并验证代码的正确性。
例如:```SELECT * FROM 表名 WHERE 条件```3. 使用TRY...CATCH块捕获异常在存储过程中,可以使用TRY...CATCH块来捕获异常并处理错误。
通过在TRY块中执行代码,在CATCH块中处理异常信息,可以更好地调试存储过程并处理潜在的错误。
例如:```BEGIN TRY-- 执行代码END TRYBEGIN CATCH-- 处理异常END CATCH```4. 使用SET NOEXEC语句暂停执行在存储过程中,可以使用SET NOEXEC语句来暂停执行。
通过在存储过程中添加SET NOEXEC语句,并将其设置为ON或OFF,可以控制存储过程的执行。
例如:```SET NOEXEC ON -- 暂停执行SET NOEXEC OFF -- 恢复执行```5. 使用SET SHOWPLAN_ALL语句显示执行计划在存储过程中,可以使用SET SHOWPLAN_ALL语句来显示执行计划。

在易语⾔中调⽤MSSQLSERVER数据库存储过程(Transact-SQL)⽅法总结作者:liigo⽇期:2010/8/25 Microsoft SQL SERVER 数据库存储过程,根据其输⼊输出数据,笼统的可以分为以下⼏种情况或其组合:⽆输⼊,有⼀个或多个输⼊参数,⽆输出,直接返回(return)⼀个值,通过output参数返回⼀个或多个值,返回⼀个记录集(recordset)。
⽆论哪⼀种情况,⽆论输⼊输出参数多复杂的存储过程,都可以在易语⾔中正确调⽤,准确的传⼊参数,并获取正确的输出数据。
下⾯我(liigo)分多种情况介绍在易语⾔中调⽤MS SQL SERVER数据库存储过程的详细⽅法,使⽤数据库操作⽀持库(eDatabase.fne)。
此前多有⼈说易语⾔⽆法调⽤数据库存储过程,或咨询调⽤存储过程的⽅法,因成此⽂。
⼀、调⽤“⽆输⼊输出数据”的存储过程 这是最简单的情况,执⾏⼀个简单的SQL语句就OK了,下⾯直接给出代码:数据库连接1.执⾏SQL (“exec dbproc”) 其中,“数据库连接1”是数据库操作⽀持库中“数据库连接”控件的实例,"exec" 表⽰调⽤存储过程,"dbproc"为被调⽤的存储过程的名称。
即使存储过程有返回值,在不想接收返回值的情况下,也可按这种⽅法调⽤。
⼆、调⽤“有⼀个或多个输⼊参数”的存储过程 ⼀个输⼊参数的情况(其中5为参数值,跟在存储过程名称之后,以空格分隔):数据库连接1.执⾏SQL (“exec dbproc_p1 5”) 两个输⼊参数的情况(其中3和6为参数值,之间以逗号分隔):数据库连接1.执⾏SQL (“exec dbproc_p2 3,6”)三、调⽤“返回记录集(recordset)”的存储过程 存储过程最后⼀条SQL语句为Select语句,通常将返回⼀个记录集(recordset)给调⽤者。
在易语⾔中,可通过数据库操作⽀持库中的“记录集”控件接收该记录集,具体代码如下图:易语⾔调⽤MSSQL存储过程 核⼼代码就是中间淡黄底⾊加亮的那⼀⾏(记录集1.打开),这⾏代码执⾏成功后,记录集1内容就是存储过程返回的recordset内容,通过⼀个简单的循环语句可以遍历所有记录。

sqlserver 存储过程循环table -回复在SQL Server中,存储过程是一组预编译的SQL语句的集合,它们可以被封装为一个单一的单元并在需要时被多次调用。
存储过程允许我们在数据库中执行一系列操作,并且可以接受参数来进行个性化的处理。
然而,有时候我们需要在存储过程中循环执行某个操作,这个操作可能需要针对一个表中的每一行执行,或者需要在某个条件为真时重复执行。
在这篇文章中,我们将探讨如何在SQL Server的存储过程中实现循环表操作。
首先,让我们考虑一个例子,假设我们有一张名为`Employee`的表,它包含员工的姓名和薪水两列。
我们想要编写一个存储过程,用于将每个员工的薪水增加10。
首先,我们需要创建一个存储过程来执行这个操作。
可以使用以下代码创建这个存储过程:sqlCREATE PROCEDURE IncreaseSalaryASBEGIN待填写的代码END接下来,我们需要在存储过程中使用循环来遍历`Employee`表中的每一行,并对薪水进行增加。
在SQL Server中,可以使用游标来实现这个目标。
游标是一种特殊的数据库对象,用于从结果集中逐行读取数据。
我们可以在存储过程中声明一个游标,并使用`OPEN`语句将其与查询结果关联起来。
然后,可以使用`FETCH NEXT`语句从游标中获取下一行数据。
在我们的例子中,我们将使用游标来遍历`Employee`表。
以下是将游标与查询结果集关联的代码示例:sqlDECLARE @EmployeeName VARCHAR(50)DECLARE @Salary DECIMAL(18,2)DECLARE employee_cursor CURSOR FORSELECT EmployeeName, SalaryFROM EmployeeOPEN employee_cursor接下来,我们需要使用`FETCH NEXT`语句从游标中获取下一行数据,并在每次循环中执行相应的操作。
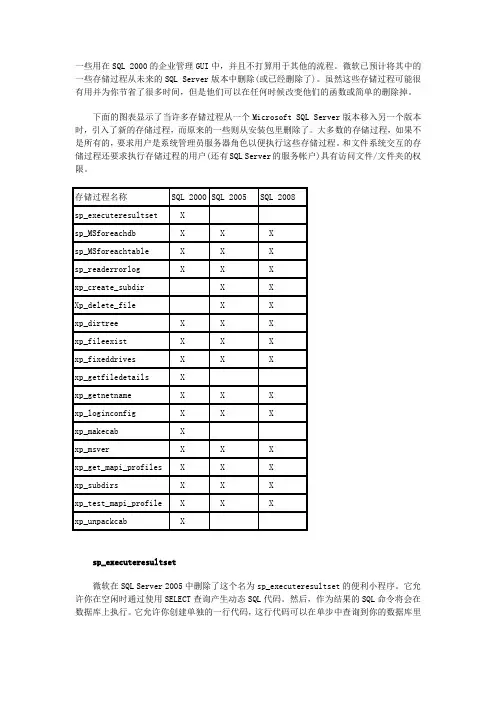
一些用在SQL 2000的企业管理GUI中,并且不打算用于其他的流程。
微软已预计将其中的一些存储过程从未来的SQL Server版本中删除(或已经删除了)。
虽然这些存储过程可能很有用并为你节省了很多时间,但是他们可以在任何时候改变他们的函数或简单的删除掉。
下面的图表显示了当许多存储过程从一个Microsoft SQL Server版本移入另一个版本时,引入了新的存储过程,而原来的一些则从安装包里删除了。
大多数的存储过程,如果不是所有的,要求用户是系统管理员服务器角色以便执行这些存储过程。
和文件系统交互的存储过程还要求执行存储过程的用户(还有SQL Server的服务帐户)具有访问文件/文件夹的权限。
sp_executeresultset微软在SQL Server 2005中删除了这个名为sp_executeresultset的便利小程序。
它允许你在空闲时通过使用SELECT查询产生动态SQL代码。
然后,作为结果的SQL命令将会在数据库上执行。
它允许你创建单独的一行代码,这行代码可以在单步中查询到你的数据库里的每一个表的记录数目(就像例子中所显示的)。
这是一个未公开的存储过程,而且无法知道它为什么被删除了。
但是,唉,这个便利的有用存储过程已经没有了。
exec sp_execresultset 'SELECT ''SELECT '''''' + name + '''''',count(*) FROM '' + namefrom sysobjectswhere xtype = ''U'''sp_MSforeachdb / sp_MSforeachtablesp_MSforeachdb / sp_MSforeachtable两个存储过程,sp_MSforeachdb和sp_MSforeachtable封装了一个指针。

mybatis查询返回List集合、map集合、List<Map>集合返回map类型1. xml中<select id="selectUser" resultType="java.util.HashMap"></select>2.Dao接⼝中Map<String,Object> selectUser();这种⽅式SQL只能返回⼀⾏记录或者没有返回,如果返回多⾏记录,则程序报错。
返回List<String>类型3. xml中<select id="selectUser" resultType="ng.String"></select>2.Dao接⼝中List<String> selectUser();这种⽅式可以返回多⾏记录,但是每⾏记录只有指定的⼀列数据。
返回List<Map>类型1.xml中<select id="selectUser" resultType="java.util.HashMap"></select>2.Dao接⼝中List<Map<String,Object>> selectUser ();这种⽅式可以返回指定的多⾏多列的记录。
返回List<指定对象>类型xml中:<resultMap id="baseResult" type="com.XXX.BscntrUnitInfoResult(对应对象)"><result column="unit_id" property="unitId" jdbcType="INTEGER" (字段映射关系)/><result column="unit_name" property="unitName"jdbcType="VARCHAR" /><result column="unit_type" property="unitType"jdbcType="INTEGER" /><result column="super_unit_id" property="superUnitId"jdbcType="INTEGER" /><result column="gis_start_x" property="gisStartX"jdbcType="FLOAT" /><result column="ext_top" property="extTop" jdbcType="DOUBLE" /></resultMap><select id="getBscntrUnitInfoListByName" resultMap="baseResult"></select>Dao接⼝中:public List<BscntrUnitInfoResult> getBscntrUnitInfoListByName();。


listbymap用法ListByMap用法详解ListByMap是一种常用的Java集合类,它可以将Map中的键值对转换为List中的元素。
在实际开发中,我们经常需要将Map中的数据转换为List,以便于进行排序、过滤、分页等操作。
ListByMap 就是为了解决这个问题而设计的。
ListByMap的使用方法非常简单,只需要调用它的静态方法listByMap即可。
该方法接受一个Map类型的参数,返回一个List 类型的结果。
下面是一个简单的示例:```Map<String, Integer> map = new HashMap<>();map.put("apple", 10);map.put("banana", 20);map.put("orange", 30);List<Map.Entry<String, Integer>> list = ListByMap.listByMap(map); ```上面的代码中,我们创建了一个Map对象,并向其中添加了三个键值对。
然后调用ListByMap的listByMap方法,将Map对象转换为List对象。
最终得到的List对象中包含了三个Map.Entry类型的元素,每个元素表示一个键值对。
ListByMap的返回结果是一个List<Map.Entry<K, V>>类型的对象,其中K表示键的类型,V表示值的类型。
List中的元素是按照Map 中的键值对顺序排列的。
如果需要按照值的大小进行排序,可以使用Collections.sort方法进行排序。
ListByMap还支持过滤操作。
可以通过传递一个Predicate对象来过滤List中的元素。
下面是一个示例:```Map<String, Integer> map = new HashMap<>();map.put("apple", 10);map.put("banana", 20);map.put("orange", 30);List<Map.Entry<String, Integer>> list = ListByMap.listByMap(map, entry -> entry.getValue() > 15);```上面的代码中,我们创建了一个Map对象,并向其中添加了三个键值对。

mybatis调⽤存储过程参数形式:Sql代码1. create procedure sptest.adder(in addend1 integer, in addend2 integer, out theSum integer)2. begin atomic3. set theSum = addend1 + addend2;4. end5. goXml代码1. <parameterMap type="map" id="testParameterMap">2. <parameter property="addend1" jdbcType="INTEGER" mode="IN"/>3. <parameter property="addend2" jdbcType="INTEGER" mode="IN"/>4. <parameter property="sum" jdbcType="INTEGER" mode="OUT"/>5. </parameterMap>6. lt;update id="adderWithParameterMap" parameterMap="testParameterMap" statementType="CALLABLE">7. {call sptest.adder(?, ?, ?)}8. </update>Java代码1. public void testAdderAsUpdateWithParameterMap() {2. SqlSession sqlSession = sqlSessionFactory.openSession();3. try {4. Map<String, Object> parms = new HashMap<String, Object>();5. parms.put("addend1", 3);6. parms.put("addend2", 4);7.8. SPMapper spMapper = sqlSession.getMapper(SPMapper.class);9.10. spMapper.adderWithParameterMap(parms);11. assertEquals(7, parms.get("sum"));12.13. parms = new HashMap<String, Object>();14. parms.put("addend1", 2);15. parms.put("addend2", 3);16. spMapper.adderWithParameterMap(parms);17. assertEquals(5, parms.get("sum"));18.19. } finally {20. sqlSession.close();21. }带输⼊输出参数的存储过程:sql代码:Sql代码1. create procedure sptest.getnames(in lowestId int, out totalrows integer)2. reads sql data3. dynamic result sets 14. BEGIN ATOMIC5. declare cur cursor for select * from s where id >= lowestId;6. select count(*) into totalrows from s where id >= lowestId;7. open cur;8. END9. goXml代码1. <select id="getNamesAndItems" statementType="CALLABLE"2. <select id="getNames" parameterType="java.util.Map" statementType="CALLABLE"3. resultMap="nameResult">4. {call sptest.getnames(5. #{lowestId,jdbcType=INTEGER,mode=IN},6. #{totalRows,jdbcType=INTEGER,mode=OUT})}7. </select>8. </select>Java代码1. public void testCallWithResultSet2_a1() {2. SqlSession sqlSession = sqlSessionFactory.openSession();3. try {4. SPMapper spMapper = sqlSession.getMapper(SPMapper.class);5.6. Map<String, Object> parms = new HashMap<String, Object>();7. parms.put("lowestId", 1);8. List<Name> names = spMapper.getNamesAnnotated(parms);9. assertEquals(3, names.size());10. assertEquals(3, parms.get("totalRows"));11. } finally {12. sqlSession.close();13. }14. }返回多个结果集sql代码:Sql代码1. create procedure sptest.getnamesanditems()2. reads sql data3. dynamic result sets 24. BEGIN ATOMIC5. declare cur1 cursor for select * from s;6. declare cur2 cursor for select * from sptest.items;7. open cur1;8. open cur2;9. END10. goXml代码1. <resultMap type="" id="nameResult">2. <result column="ID" property="id"/>3. <result column="FIRST_NAME" property="firstName"/>4. <result column="LAST_NAME" property="lastName"/>5. </resultMap>6.7. <resultMap type="org.apache.ibatis.submitted.sptests.Item" id="itemResult">8. <result column="ID" property="id"/>9. <result column="ITEM" property="item"/>10. </resultMap>11.12. <select id="getNamesAndItems" statementType="CALLABLE"13. resultMap="nameResult,itemResult">14. {call sptest.getnamesanditems()}15. </select>Java代码1. @Test2. public void testGetNamesAndItems() throws SQLException {3. SqlSession sqlSession = sqlSessionFactory.openSession();4. try {5. SPMapper spMapper = sqlSession.getMapper(SPMapper.class);6.7. List<List<?>> results = spMapper.getNamesAndItems();8. assertEquals(2, results.size());9. assertEquals(4, results.get(0).size());10. assertEquals(3, results.get(1).size());11. } finally {12. sqlSession.close();13. }14. }注意:上⾯就是⼏种常⽤的了。

SQLSERVER存储过程的操作与管理SQL Server 存储过程是一组预编译的SQL语句块,经过编译和存储在数据库服务器中以便反复使用。
存储过程可以接收参数并返回结果,可以实现复杂的逻辑处理,并且可以提高数据库的性能和安全性。
在本文中,我们将详细介绍SQL Server存储过程的操作与管理。
创建存储过程:在SQL Server中,创建存储过程使用CREATE PROCEDURE语句。
例如,以下是一个简单的创建存储过程的示例:```CREATE PROCEDURE sp_GetCustomersASBEGINSELECT * FROM CustomersEND```在这个例子中,我们创建了一个名为sp_GetCustomers的存储过程,它从Customers表中检索所有客户的数据。
执行存储过程:要执行存储过程,可以使用EXECUTE或EXEC语句,例如:```EXEC sp_GetCustomers```当我们执行存储过程sp_GetCustomers时,它将返回Customers表中的所有客户数据。
存储过程参数:存储过程可以接收参数来实现更加灵活和可复用的逻辑处理。
以下是一个带有参数的存储过程的示例:```CREATE PROCEDURE sp_GetCustomerByIdASBEGINEND```在这个例子中,我们创建了一个名为sp_GetCustomerById的存储过程,它接收一个整数类型的CustomerId参数,并根据该参数从Customers表中检索客户数据。
执行带参数的存储过程:要执行带参数的存储过程,可以在EXECUTE或EXEC语句后传递参数的值,例如:``````当我们执行存储过程sp_GetCustomerById,并传递CustomerId参数为1时,它将返回CustomerId为1的客户数据。
存储过程的输入输出参数:除了普通参数外,存储过程还可以具有输入输出参数。

Hibernate调用存储过程传参获取返回值简介Hibernate是一个流行的Java持久化框架,它提供了一种将Java对象映射到关系型数据库的方式。
在某些情况下,我们可能需要调用存储过程来执行一些复杂的数据库操作。
本文将介绍如何使用Hibernate调用存储过程,并传递参数和获取返回值。
准备工作在开始之前,我们需要完成以下准备工作:1.安装Java JDK和Hibernate框架。
2.配置Hibernate的数据库连接信息,包括数据库驱动、URL、用户名和密码等。
3.创建数据库存储过程,并确保它已经在数据库中正确地定义和测试。
Hibernate映射文件在使用Hibernate调用存储过程之前,我们需要创建一个Hibernate映射文件来定义存储过程的调用。
下面是一个示例的映射文件:<hibernate-mapping><sql-query name="callStoredProcedure" callable="true">{ call my_stored_procedure(:param1, :param2) }</sql-query></hibernate-mapping>在上面的示例中,我们定义了一个名为”callStoredProcedure”的SQL查询,其中”callable”属性被设置为”true”,表示这是一个调用存储过程的查询。
存储过程的调用语法是{ call procedure_name(:param1, :param2) },其中”:param1”和”:param2”是存储过程的输入参数。
调用存储过程一旦我们有了Hibernate映射文件,我们就可以在Java代码中使用Hibernate来调用存储过程。
下面是一个示例代码:Session session = HibernateUtil.getSessionFactory().getCurrentSession(); Transaction tx = session.beginTransaction();Query query = session.getNamedQuery("callStoredProcedure");query.setParameter("param1", value1);query.setParameter("param2", value2);query.executeUpdate();mit();在上面的示例中,我们首先获取Hibernate的Session对象,并开启一个事务。

SQL存储过程的语句(SQL存储过程)SQL语句集锦--语句功能--数据操作SELECT--从数据库表中检索数据⾏和列INSERT--向数据库表添加新数据⾏DELETE--从数据库表中删除数据⾏UPDATE--更新数据库表中的数据--数据定义CREATE TABLE--创建⼀个数据库表DROP TABLE--从数据库中删除表ALTER TABLE--修改数据库表结构CREATE VIEW--创建⼀个视图DROP VIEW--从数据库中删除视图CREATE INDEX--为数据库表创建⼀个索引DROP INDEX--从数据库中删除索引CREATE PROCEDURE--创建⼀个存储过程DROP PROCEDURE--从数据库中删除存储过程CREATE TRIGGER--创建⼀个触发器DROP TRIGGER--从数据库中删除触发器CREATE SCHEMA--向数据库添加⼀个新模式DROP SCHEMA--从数据库中删除⼀个模式CREATE DOMAIN --创建⼀个数据值域ALTER DOMAIN --改变域定义DROP DOMAIN --从数据库中删除⼀个域--数据控制GRANT--授予⽤户访问权限DENY--拒绝⽤户访问REVOKE--解除⽤户访问权限--事务控制COMMIT--结束当前事务ROLLBACK--中⽌当前事务SET TRANSACTION--定义当前事务数据访问特征--程序化SQLDECLARE--为查询设定游标EXPLAN --为查询描述数据访问计划OPEN--检索查询结果打开⼀个游标FETCH--检索⼀⾏查询结果CLOSE--关闭游标PREPARE--为动态执⾏准备SQL 语句EXECUTE--动态地执⾏SQL 语句DESCRIBE --描述准备好的查询---局部变量declare@id char(10)--set @id = '10010001'select@id='10010001'---全局变量---必须以@@开头--IF ELSEdeclare@x int@y int@z intselect@x=1@y=2@z=3if@x>@yprint'x > y'--打印字符串'x > y'else if@y>@zprint'y > z'else print'z > y'--CASEuse panguupdate employeeset e_wage =casewhen job_level = ’1’ then e_wage*1.08when job_level = ’2’ then e_wage*1.07when job_level = ’3’ then e_wage*1.06else e_wage*1.05end--WHILE CONTINUE BREAKdeclare@x int@y int@c intselect@x=1@y=1while@x<3beginprint@x--打印变量x 的值while@y<3beginselect@c=100*@x+@yprint@c--打印变量c 的值select@y=@y+1endselect@x=@x+1select@y=1end--WAITFOR--例等待1 ⼩时2 分零3 秒后才执⾏SELECT 语句waitfor delay ’01:02:03’select*from employee--例等到晚上11 点零8 分后才执⾏SELECT 语句waitfor time ’23:08:00’select*from employee***SELECT***select*(列名) from table_name(表名) where column_name operator valueex:(宿主)select*from stock_information where stockid =str(nid)stockname ='str_name'stockname like'% find this %'stockname like'[a-zA-Z]%'--------- ([]指定值的范围)stockname like'[^F-M]%'--------- (^排除指定范围)--------- 只能在使⽤like关键字的where⼦句中使⽤通配符)or stockpath ='stock_path'or stocknumber <1000and stockindex =24not stock***='man'stocknumber between20and100stocknumber in(10,20,30)order by stockid desc(asc) --------- 排序,desc-降序,asc-升序order by1,2--------- by列号stockname = (select stockname from stock_information where stockid =4) --------- ⼦查询--------- 除⾮能确保内层select只返回⼀个⾏的值,--------- 否则应在外层where⼦句中⽤⼀个in限定符select distinct column_name form table_name --------- distinct指定检索独有的列值,不重复select stocknumber ,"stocknumber +10" = stocknumber +10from table_nameselect stockname , "stocknumber" =count(*) from table_name group by stockname--------- group by 将表按⾏分组,指定列中有相同的值having count(*) =2--------- having选定指定的组select*from table1, table2where table1.id *= table2.id -------- 左外部连接,table1中有的⽽table2中没有得以null表⽰ table1.id =* table2.id -------- 右外部连接select stockname from table1union[all]----- union合并查询结果集,all-保留重复⾏select stockname from table2***insert***insert into table_name (Stock_name,Stock_number) value ("xxx","xxxx")value (select Stockname , Stocknumber from Stock_table2)---value为select语句***update***update table_name set Stockname = "xxx" [where Stockid = 3]Stockname =defaultStockname =nullStocknumber = Stockname +4***delete***delete from table_name where Stockid =3truncate table_name ----------- 删除表中所有⾏,仍保持表的完整性drop table table_name --------------- 完全删除表***alter table***--- 修改数据库表结构alter table database.owner.table_name add column_name char(2) null .....sp_help table_name ---- 显⽰表已有特征create table table_name (name char(20), age smallint, lname varchar(30))insert into table_name select ......... ----- 实现删除列的⽅法(创建新表)alter table table_name drop constraint Stockname_default ---- 删除Stockname的default约束***function(/*常⽤函数*/)***----统计函数----AVG--求平均值COUNT--统计数⽬MAX--求最⼤值MIN--求最⼩值SUM--求和--AVGuse panguselect avg(e_wage) as dept_avgWagefrom employeegroup by dept_id--MAX--求⼯资最⾼的员⼯姓名use panguselect e_namefrom employeewhere e_wage =(select max(e_wage)from employee)--STDEV()--STDEV()函数返回表达式中所有数据的标准差--STDEVP()--STDEVP()函数返回总体标准差--VAR()--VAR()函数返回表达式中所有值的统计变异数--VARP()--VARP()函数返回总体变异数----算术函数----/***三⾓函数***/SIN(float_expression) --返回以弧度表⽰的⾓的正弦COS(float_expression) --返回以弧度表⽰的⾓的余弦TAN(float_expression) --返回以弧度表⽰的⾓的正切COT(float_expression) --返回以弧度表⽰的⾓的余切/***反三⾓函数***/ASIN(float_expression) --返回正弦是FLOAT 值的以弧度表⽰的⾓ACOS(float_expression) --返回余弦是FLOAT 值的以弧度表⽰的⾓ATAN(float_expression) --返回正切是FLOAT 值的以弧度表⽰的⾓ATAN2(float_expression1,float_expression2)--返回正切是float_expression1 /float_expres-sion2的以弧度表⽰的⾓DEGREES(numeric_expression)--把弧度转换为⾓度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型RADIANS(numeric_expression) --把⾓度转换为弧度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型EXP(float_expression) --返回表达式的指数值LOG(float_expression) --返回表达式的⾃然对数值LOG10(float_expression)--返回表达式的以10 为底的对数值SQRT(float_expression) --返回表达式的平⽅根/***取近似值函数***/CEILING(numeric_expression) --返回>=表达式的最⼩整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型FLOOR(numeric_expression) --返回<=表达式的最⼩整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型ROUND(numeric_expression) --返回以integer_expression 为精度的四舍五⼊值返回的数据--类型与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型ABS(numeric_expression) --返回表达式的绝对值返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型SIGN(numeric_expression) --测试参数的正负号返回0 零值1 正数或-1 负数返回的数据类型--与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型PI() --返回值为π即3.1415926535897936RAND([integer_expression]) --⽤任选的[integer_expression]做种⼦值得出0-1 间的随机浮点数----字符串函数----ASCII() --函数返回字符表达式最左端字符的ASCII 码值CHAR() --函数⽤于将ASCII 码转换为字符--如果没有输⼊0 ~ 255 之间的ASCII 码值CHAR 函数会返回⼀个NULL 值LOWER() --函数把字符串全部转换为⼩写UPPER() --函数把字符串全部转换为⼤写STR() --函数把数值型数据转换为字符型数据LTRIM() --函数把字符串头部的空格去掉RTRIM() --函数把字符串尾部的空格去掉LEFT(),RIGHT(),SUBSTRING() --函数返回部分字符串CHARINDEX(),PATINDEX() --函数返回字符串中某个指定的⼦串出现的开始位置SOUNDEX() --函数返回⼀个四位字符码--SOUNDEX函数可⽤来查找声⾳相似的字符串但SOUNDEX函数对数字和汉字均只返回0 值DIFFERENCE() --函数返回由SOUNDEX 函数返回的两个字符表达式的值的差异--0 两个SOUNDEX 函数返回值的第⼀个字符不同--1 两个SOUNDEX 函数返回值的第⼀个字符相同--2 两个SOUNDEX 函数返回值的第⼀⼆个字符相同--3 两个SOUNDEX 函数返回值的第⼀⼆三个字符相同--4 两个SOUNDEX 函数返回值完全相同QUOTENAME() --函数返回被特定字符括起来的字符串/*select quotename('abc', '{') quotename('abc')运⾏结果如下----------------------------------{{abc} [abc]*/REPLICATE() --函数返回⼀个重复character_expression 指定次数的字符串/*select replicate('abc', 3) replicate( 'abc', -2)运⾏结果如下----------- -----------abcabcabc NULL*/REVERSE() --函数将指定的字符串的字符排列顺序颠倒REPLACE() --函数返回被替换了指定⼦串的字符串/*select replace('abc123g', '123', 'def')运⾏结果如下----------- -----------abcdefg*/SPACE() --函数返回⼀个有指定长度的空⽩字符串STUFF() --函数⽤另⼀⼦串替换字符串指定位置长度的⼦串----数据类型转换函数----CAST() 函数语法如下CAST() (<expression>AS<data_ type>[ length ])CONVERT() 函数语法如下CONVERT() (<data_ type>[ length ], <expression>[, style])select cast(100+99as char) convert(varchar(12), getdate())运⾏结果如下------------------------------ ------------199 Jan 152000----⽇期函数----DAY() --函数返回date_expression 中的⽇期值MONTH() --函数返回date_expression 中的⽉份值YEAR() --函数返回date_expression 中的年份值DATEADD(<datepart> ,<number> ,<date>)--函数返回指定⽇期date 加上指定的额外⽇期间隔number 产⽣的新⽇期DATEDIFF(<datepart> ,<number> ,<date>)--函数返回两个指定⽇期在datepart ⽅⾯的不同之处DATENAME(<datepart> , <date>) --函数以字符串的形式返回⽇期的指定部分DATEPART(<datepart> , <date>) --函数以整数值的形式返回⽇期的指定部分GETDATE() --函数以DATETIME 的缺省格式返回系统当前的⽇期和时间----系统函数----APP_NAME() --函数返回当前执⾏的应⽤程序的名称COALESCE() --函数返回众多表达式中第⼀个⾮NULL 表达式的值COL_LENGTH(<'table_name'>, <'column_name'>) --函数返回表中指定字段的长度值COL_NAME(<table_id>, <column_id>) --函数返回表中指定字段的名称即列名DATALENGTH() --函数返回数据表达式的数据的实际长度DB_ID(['database_name']) --函数返回数据库的编号DB_NAME(database_id) --函数返回数据库的名称HOST_ID() --函数返回服务器端计算机的名称HOST_NAME() --函数返回服务器端计算机的名称IDENTITY(<data_type>[, seed increment]) [AS column_name])--IDENTITY() 函数只在SELECT INTO 语句中使⽤⽤于插⼊⼀个identity column列到新表中/*select identity(int, 1, 1) as column_nameinto newtablefrom oldtable*/ISDATE() --函数判断所给定的表达式是否为合理⽇期ISNULL(<check_expression>, <replacement_value>) --函数将表达式中的NULL 值⽤指定值替换ISNUMERIC() --函数判断所给定的表达式是否为合理的数值NEWID() --函数返回⼀个UNIQUEIDENTIFIER 类型的数值NULLIF(<expression1>, <expression2>)--NULLIF 函数在expression1 与expression2 相等时返回NULL 值若不相等时则返回expression1 的值。
1、ACCESS调用SQL SERVER存储过程示例:Dim strS As String '定义一变量Dim adoconn As New ADODB.Connection 'Connection 对象代表了打开与数据源的连接。
Dim adocomm As New mand 'Command 对象定义了将对数据源执行的指定命令。
Dim ReturnValue As Integer '调用存储过程的返回值adoconn.ConnectionString = Adodc1.ConnectionString 'Adodc1为窗体中的ADO控件,并已成功连接数据库adoconn.OpenSet adocomm.ActiveConnection = adoconn '指示指定的 Command对象当前所属的Connection对象。
mandText = "doc_ProcName" '设置Command对象源。
mandType = adCmdStoredProc '通知提供者CommandText属性有什么,它可能包括Command对象的源类型。
设置这个属性优化了该命令的执行。
adocomm.Parameters(1) = "1"adocomm.Parameters(2) = "OutputParameters" 'OutputParameters可以为任意的字符串或数字adocomm.ExecuteReturnValue = adocomm.Parameters(0) '存储过程的返回值,返回0则成功执行。
strS = adocomm.Parameters(2) '把存储过程的输出参数的值赋给变量strS 字串42、本地表中数据写到SQL表中并且还要判断是否重复啊!用JET SQL、T-SQL都可以完成,看你熟悉哪种SQL。
SQLServer存储过程和触发器的区别存储过程存储过程是在⼤型数据库系统中,⼀组为了完成特定功能的SQL 语句集,存储在数据库中,经过第⼀次编译后再次调⽤不需要再次编译,⽤户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执⾏它。
存储过程是可以访问关系数据库的应⽤程序。
通常,存储过程⽤作验证数据和控制对数据库的访问。
如果某些数据处理操作需要执⾏多个SQL语句,则此类操作将作为存储过程实现。
调⽤存储过程时,必须使⽤CALL或EXECUTE语句。
存储过程可以返回结果(例如SELECT语句的结果)。
这些结果可以由其他存储过程或应⽤程序使⽤。
⽤于编写存储过程的语⾔通常⽀持控制结构,例如if,while,for等。
根据所使⽤的数据库系统,可以使⽤多种语⾔来实现存储过程。
优点:1允许模块化程序设计(创建⼀次多次使⽤)2允许更快执⾏3减少⽹络流量4更好的安全机制格式:DELIMITER //CREATE PROCEDURE 储存名([ IN ,OUT ,INOUT ]?参数名?数据类形…)BEGINSQL语句END //DELIMITER ;调⽤过程:⽤call 过程名()查看所有的存储过程show procedure status;查看创建的存储过程show create procedure 过程名;删除过程 drop procedure 过程名In 表⽰参数从外部传⼊到⾥⾯使⽤(过程内部使⽤)Out 表⽰参数从过程⾥边把数据保存到变量中,交给外部使⽤,所有传⼊的必须是变量如果说传⼊的out变量本⾝在外部有数据,那么在进⼊过程之后,第⼀件事就是被清空,设为nullInout 数据可以从外部传⼊到过程内部使⽤,同时内部操作之后,⼜会将数据返回给外部触发器触发器是特殊的存储过程,存储过程需要程序调⽤,⽽触发器会⾃动执⾏。
它⼜不同于存储过程,触发器主要是通过事件进⾏触发⽽被执⾏的,⽽存储过程可以通过存储过程名字⽽被直接调⽤。
ISSN 1009-3044 Computer Knowledge and Technology电脑知识与技术 Vo1.7,No.34,December 201 1.
探究SQL SERVER存储过程 白杨
E—mail:jsh@cccc.net.ca http://www.dnzs.net.ca Tel:+86—55 1—5690963 5690964
(呼伦贝尔学院计算机科学与技术学院,内蒙古海拉尔021008) 摘要:在数据库开发过程中,常会遇到复杂的业务逻辑和数据库操作,这时就需用存储过程来对其进行封装。文章主要对SQL SERVER存储过程进行了简单的概述,提出了创建存储过程的其他方法及注意的问题,并对存储过程的安全性保护以及存储过程 的的优化进行了剖析。 关键词:SQL Serve;存储过程;CLR;优化;安全性 中图分类号:TP311 文献标识码:A 文章编号:1009—3044(2011)34—8769—02 SQL Server Stored Procedure to Explore BAIYang (Computer Science and Technology Institute,Hunlunbeier University,Haflaer 021008,China) Abstract:In the database devdopment process,oRen encounter complex business logic and database operations,then use a stored proce— dure to carry on the package.This paper mainly on the SQL SERVER stored procedures for a simple overview,put forward to create a stored procedure to other methods and pay attention to the problem,and the storage process of security protection and storage process opti— mization are analyzed.
SQLserver实验五存储过程创建与应用存储过程是一种在数据库中预先定义的一组SQL语句的集合,通过一个名称来调用,并可以传递参数。
存储过程可以被多个用户或应用程序多次调用,这样可以减少重复的代码,并提高数据库的性能和安全性。
本文将详细介绍SQL Server中存储过程的创建和应用。
1.存储过程的创建在SQL Server中,通过CREATE PROCEDURE语句来创建存储过程。
语法如下:CREATE PROCEDURE procedure_name...ASBEGIN-- SQL statementsEND2.存储过程的应用存储过程可以用来执行一系列的SQL语句,包括查询、插入、更新和删除等操作。
通过执行存储过程,可以提高数据库的性能,并减少代码的重复。
2.1调用存储过程调用存储过程需要使用EXECUTE或EXEC关键字,后跟存储过程的名称和参数列表。
例如:EXECUTE procedure_name parameter1, parameter2, ...或者EXEC procedure_name parameter1, parameter2, ...2.2存储过程的参数存储过程可以定义输入参数、输出参数和返回值。
2.2.1输入参数:用来接收存储过程调用者传递的值。
在存储过程内部,可以使用这些参数进行各种操作。
例如:CREATE PROCEDURE get_customer_infoASBEGINSELECT * FROM CustomersEND在调用存储过程时,可以传递参数的值:EXEC get_customer_info 12.2.2输出参数:用来返回存储过程的计算结果。
在存储过程定义中,需要使用OUTPUT关键字来指定输出参数。
例如:CREATE PROCEDURE get_customer_countASBEGINEND在调用存储过程时,需要为输出参数提供一个变量来接收结果:2.2.3返回值:存储过程还可以定义返回值,用来表示执行的结果状态。
Action层 public ActionForward getProjectPayMoneyJsonByPayType(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response) throws Exception { JiLiangZhiFuService jiLiangZhiFuService = this.getServiceLocator().getJiLiangZhiFuService(); int year = Integer.parseInt(request.getParameter("year")); String data = jiLiangZhiFuService.getProjectPayMoneyJsonByPayType(year); response.setContentType("text/xml"); response.getWriter().write(data); response.getWriter().flush(); response.getWriter().close(); return null; }
Service层 public String getProjectPayMoneyJsonByPayType(int year){ double allTotal = 0; Map map = jiLiangZhiFuDao.getProjectPayMoneyByPayType(year); List dataItemList = SessionBean.getServiceLocator().getDataItemService().getAllDataItemByTypeId("payType"); Map map_ep = new HashMap(); map_ep.put("account_id", 2); map_ep.put("isSelectTwoStageProject", true); List engineeringPhaseList = SessionBean.getServiceLocator().getEngineeringPhaseService().getEngineeringPhaseList(map_ep).getData(); Map map_type = new HashMap(); StringBuilder sb = new StringBuilder(); sb.append(""+engineeringPhaseList.size()+""); for(EngineeringPhase engineeringPhase:engineeringPhaseList){ String ep_id = engineeringPhase.getEp_id(); sb.append(""); sb.append(""+ep_id+""); sb.append(""+engineeringPhase.getEp_name()+""); for(DataItem dataItem:dataItemList){ String di_id = dataItem.getId(); String r_key = ep_id + "," + di_id; if(map.containsKey(r_key)){ map_type.put(di_id, map_type.containsKey(di_id) ? (Double.parseDouble(map_type.get(di_id).toString()) + Double.parseDouble(map.get(r_key).toString())) : Double.parseDouble(map.get(r_key).toString())); sb.append("<"+di_id+">"+map.get(r_key)+""); } } //项目支付金额合计 sb.append(""+map.get(engineeringPhase.getEp_id())+""); allTotal += Double.parseDouble(map.get(engineeringPhase.getEp_id()).toString()); sb.append(""); } //某支付类别金额合计 sb.append(""); sb.append(""); sb.append("合计"); DecimalFormat df = new DecimalFormat("#.00"); for(DataItem dataItem:dataItemList){ sb.append("<"+dataItem.getId()+">"+String.format("%.2f", map_type.get(dataItem.getId()))+""); } //各项目累计合计 sb.append(""+String.format("%.2f", allTotal)+""); sb.append(""); sb.append(""); return sb.toString(); }
Dao层 public Map getProjectPayMoneyByPayType(final int year) { try { return (Map)this.getHibernateTemplate().execute( new HibernateCallback(){ public Object doInHibernate(Session session) throws HibernateException, SQLException { Connection con = session.connection(); Statement stmt = con.createStatement(); CallableStatement cs = con.prepareCall("{call proc_records(?)}"); cs.setInt(1, year); //ResultSet rs = stmt.executeQuery("{call proc_records}"); ResultSet rs = cs.executeQuery(); Map map = new HashMap(); while (rs.next()) { map.put(rs.getString(1), rs.getString(2)); } rs.close(); stmt.close(); return map; } } ); } catch ( org.springframework.dao.DataAccessException e) { throw new DataAccessException(e.getMessage(),e); } }
Sql: create procedure proc_records @year int as DECLARE @map_table table(r_key varchar(100),r_value varchar(50)) DECLARE @type_id varchar(40) DECLARE @type_name varchar(50) DECLARE @project_id varchar(40) DECLARE @project_name varchar(50) DECLARE @payTypeMoney numeric(16, 2) DECLARE @sumPayTypeMoney numeric(16, 2)
BEGIN set @payTypeMoney = 0 set @sumPayTypeMoney = 0 --查询项目列表 DECLARE project_cursor CURSOR for select ep_id,ep_name from AB_engineeringPhase where account_id='2' open project_cursor fetch next from project_cursor into @project_id,@project_name while @@FETCH_STATUS = 0 begin --查询项目支付类别 DECLARE projectType_cursor CURSOR for select id,name from T_DataItem where typeId = 'payType' order by sort asc open projectType_cursor fetch next from projectType_cursor into @type_id,@type_name while @@FETCH_STATUS = 0 begin --业务逻辑处理处理内层游标 --获取一个项目某一项支付类型的数据 --查询一个项目某一支付类别金额 select @payTypeMoney = sum(checkProjectPayMoney) from JiLiangZhiFu where projectId = @project_id and payType = @type_id and enterDate > CAST(@year as varchar(4)) and enterDate < CAST(@year+1 as varchar(4)) and type = 'outer' group by payType