数据结构_二叉树_实验报告 北邮
- 格式:doc
- 大小:139.50 KB
- 文档页数:10


数据结构实验报告1. 实验目的和内容:掌握二叉树基本操作的实现方法2. 程序分析2.1存储结构链式存储2.程序流程2.3关键算法分析算法一:Create(BiNode<T>* &R,T data[],int i,int n)【1】算法功能:创建二叉树【2】算法基本思想:利用顺序存储结构为输入,采用先建立根结点,再建立左右孩子的方法来递归建立二叉链表的二叉树【3】算法空间时间复杂度分析:O(n)【4】代码逻辑:如果位置小于数组的长度则{ 创建根结点将数组的值赋给刚才创建的结点的数据域创建左子树,如果当前结点位置为i,则左孩子位置为2i创建右子树,如果当前结点位置为i,则右孩子位置为2i+1}否则R为空算法二:CopyTree(BiNode<T>*sR,BiNode<T>* &dR))【1】算法功能:复制构造函数【2】算法基本思想:按照先创建根结点,再递归创建左右子树的方法来实现。
【3】算法空间时间复杂度分析:O(n)【4】代码逻辑:如果源二叉树根结点不为空则{创建根结点调用函数自身,创建左子树调用函数自身,创建右子树}将该函数放在复制构造函数中调用,就可以实现复制构造函数算法三:PreOrder(BiNode<T>*R)【1】算法功能:二叉树的前序遍历【2】算法基本思想:这个代码用的是优化算法,提前让当前结点出栈。
【3】算法空间时间复杂度分析:O(n)【4】代码逻辑(伪代码)如果当前结点为非空,则{访问当前结点当前结点入栈将当前结点的左孩子作为当前结点}如果为空{则栈顶结点出栈则将该结点的右孩子作为当前结点}反复执行这两个过程,直到结点为空并且栈空算法四:InOrder(BiNode<T>*R)【1】算法功能:二叉树的中序遍历【2】算法基本思想:递归【3】算法空间时间复杂度分析:未知【4】代码逻辑:如果R为非空:则调用函数自身遍历左孩子访问该结点再调用自身访问该结点的右孩子算法五:LevelOrder(BiNode<T>*R)【1】算法功能:二叉树的层序遍历【2】算法基本思想:【3】算法空间时间复杂度分析:O(n)【4】代码逻辑(伪代码):如果队列不空{对头元素出队访问该元素若该结点的左孩子为非空,则左孩子入队;若该结点的右孩子为非空,则右孩子入队;}算法六:Count(BiNode<T>*R)【1】算法功能:计算结点的个数【2】算法基本思想:递归【3】算法空间时间复杂度分析:未知【4】代码逻辑:如果R不为空的话{调用函数自身计算左孩子的结点数调用函数自身计算右孩子的结点数}template<class T>int BiTree<T>::Count(BiNode<T>*R){if(R==NULL)return 0;else{int m=Count(R->lchild);int n=Count(R->rchild);return m+n+1;}}算法七:Release(BiNode<T>*R)【1】算法功能:释放动态内存【2】算法基本思想:左右子树全部释放完毕后再释放该结点【3】算法空间时间复杂度分析:未知【4】代码逻辑:调用函数自身,释放左子树调用函数自身,释放右子树释放根结点释放二叉树template<class T>void BiTree<T>::Release(BiNode<T>*R) {if(R!=NULL){Release(R->lchild);Release(R->rchild);delete R;}}template<class T>BiTree<T>::~BiTree(){Release(root);}int main(){BiTree<int> BTree(a,10);BiTree<int>Tree(BTree);BTree.PreOrder(BTree.root);cout<<endl;Tree.PreOrder(Tree.root);cout<<endl;BTree.InOrder(BTree.root);cout<<endl;Tree.InOrder(Tree.root);cout<<endl;BTree.PostOrder(BTree.root);cout<<endl;Tree.PostOrder(Tree.root);cout<<endl;BTree.LevelOrder(BTree.root);cout<<endl;Tree.LevelOrder(Tree.root);cout<<endl;int m=BTree.Count(BTree.root);cout<<m<<endl;return 0;}3.测试数据:int a[10]={1,2,3,4,5};1 2 4 5 31 2 4 5 34 25 1 34 5 2 3 11 2 3 4 554.总结:4.1:这次实验大多用了递归的算法,比较好理解。

数据结构实验报告二叉树《数据结构与算法》实验报告专业班级姓名学号实验项目实验三二叉树。
实验目的1、掌握用递归方法实现二叉树的遍历。
2、加深对二叉树的理解,逐步培养解决实际问题的编程能力。
题目:(1)编写二叉树的遍历操作函数。
①先序遍历,递归方法re_preOrder(TREE *tree)②中序遍历,递归方法re_midOrder(TREE *tree)③后序遍历,递归方法re_postOrder(TREE *tree)(2)调用上述函数实现先序、中序和后序遍历二叉树操作。
算法设计分析(一)数据结构的定义要求用c语言编写一个演示程序,首先建立一个二叉树,让用户输入一个二叉树,实现该二叉树的便利操作。
二叉树型存储结构定义为:typedef struct TNode{ char data;//字符型数据struct TNode *lchild,*rchild;//左右孩子指针}TNode,* Tree;(二)总体设计程序由主函数、二叉树建立函数、先序遍历函数、中序遍历函数、后序遍历函数五个函数组成。
其功能描述如下:(1)主函数:统筹调用各个函数以实现相应功能。
int main()(2)二叉树建立函数:根据用户意愿运用先序遍历建立一个二叉树。
int CreateBiTree(Tree &T)(3)先序遍历函数:将所建立的二叉树先序遍历输出。
void PreOrder(Tree T)(4)中序遍历函数:将所建立的二叉树中序遍历输出。
void InOrder(Tree T)(5)后序遍历函数:将所建立的二叉树后序遍历输出。
void PostOrder(Tree T)(三)各函数的详细设计:(1)建立一个二叉树,按先序次序输入二叉树中结点的值(一个字符),‘#’表示空树。
对T动态分配存储空间,生成根节点,构造左、右子树(2)编写先序遍历函数,依次访问根节点、左子结点、右子节点(3)编写中序遍历函数,依次访问左子结点、根节点、右子节点(4)编写后序遍历函数,依次访问左子结点、右子节点、根节点(5)编写主函数,调用各个函数,以实现二叉树遍历的基本操作。

实验报告课程名:数据结构(C语言版)实验名:二叉排序树姓名:班级:学号:撰写时间:一实验目的与要求1.掌握二叉排序树上进行插入和删除的操作2.利用 C 语言实现该操作二实验内容•对于一个线形表, 利用不断插入的方法, 建立起一株二叉排序树•从该二叉排序树中删除一个叶子节点, 一个只有一个子树的非叶子节,一个有两个子树的非叶子节点。
三实验结果与分析#include<>#include<>删结点是叶子结点,直接删除if(p->left == NULL && p->right == NULL){删结点只有左子树else if(p->left && !(p->right)){p->left->parent=p->parent;删结点只有右孩子else if(p->right && !(p->left)){p->right->parent=p->parent;删除的结点既有左孩子,又有右孩子//该结点的后继结点肯定无左子树(参考上面查找后继结点函数)//删掉后继结点,后继结点的值代替该结点else{//找到要删除结点的后继q=searchSuccessor(p);temp=q->key;//删除后继结点deleteNode(root,q->key);p->key=temp;}return 1;}//创建一棵二叉查找树void create(PNode* root,KeyType *keyArray,int length) {int i;//逐个结点插入二叉树中for(i=0;i<length;i++)inseart(root,keyArray[i]);}int main(void){int i;PNode root=NULL;KeyType nodeArray[11]={15,6,18,3,7,17,20,2,4,13,9}; create(&root,nodeArray,11);for(i=0;i<2;i++)deleteNode(&root,nodeArray[i]);printf("%d\n",searchPredecessor(root)->key);printf("%d\n",searchSuccessor(root)->key);printf("%d\n",searchMin(root)->key);printf("%d\n",searchMax(root)->key);printf("%d\n",search(root,13)->key);return 0;}图1:二叉树排序实验结果。


数据结构实验报告实验名称:__ 哈夫曼树________学生姓名:______ 蔡宇豪_________________班级:________ 2 5____________________ 班内序号:__________15__________________学号:_________2012210673___________________ 日期:________2013.11.24____________________2. 程序分析2.1 存储结构哈夫曼树结点的存储结构包括双亲域parent,左子树lchild,右子树rchild,还有字符word,权重weight,编码code对用户输入的信息进行统计,将每个字符作为哈夫曼树的叶子结点。
统计每个字符出现的次数作为叶子的权重,统计次数可以根据每个字符不同的ASCII码,根据叶子结点的权重建立一个哈夫曼树2.2 关键算法分析要实现哈夫曼解/编码器,就必须用二叉树结构建立起哈夫曼树,其中有4个关键算法,首先是初始化函数,统计每个字符的频度,并建立起哈夫曼树;然后是建立编码表,将每个字符的编码输出;再次就是编码算法,根据编码表对输入的字符串进行编码,并将编码后的字符串输出;最后是译码算法,利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
1.初始化函数int i,j;for(i=0;i<MAX;i++)a[i]=0; //先将a[]数组中每个值都赋为,不然程序会运行出错?for(i=0;s[i]!='\0';i++) //'\0'字符串结束标志{for(j=0;j<n;j++){if(s[i]==b[j]) //判断该字符是否已经出现过break;}if(j<n) //该字符出现过,对应计数器加一a[j]++;else//该字符为新字符,上面的循环全部运行完毕,j=n,记录到b[j]中,对应计数器加一{b[j]=s[i];a[j]++;n++; //出现的字符种类数加一}}//cout<<"共有"<<n<<"种字符,分别为:"<<endl;for(i=0;i<n;i++)cout<<b[i]<<"出现次数为:"<<a[i]<<endl;HTree=new HNode[2*n-1] ; //哈夫曼树初始化for(int i=0;i<2*n-1;i++){if(i<n){HTree[i].weight=a[i];}else{HTree[i].weight=0;}HTree[i].LChild=-1;HTree[i].RChild=-1;HTree[i].parent=-1;}int x,y,m1,m2; //x,y用于存放权值最小结点在数组中的下标for(int i=n;i<2*n-1;i++) //开始建哈夫曼树{//找出权值最小的结点m1=m2=MAX; //MAX=1000x=y=0;for(int j=0;j<i;j++){if(HTree[j].weight<m1&&HTree[j].parent==-1){m2=m1;m1=HTree[j].weight;x=j;}else if(HTree[j].weight < m2 && HTree[j].parent==-1){m2=HTree[j].weight;y=j;}}HTree[x].parent=HTree[y].parent=i;HTree[i].weight=HTree[x].weight+HTree[y].weight;HTree[i].LChild=x;HTree[i].RChild=y;HTree[i].parent=-1;2.生成编码表HCodeTable=new HCode[n];for(int i=0;i<n;i++){HCodeTable[i].data=b[i];int child=i;int parent=HTree[i].parent;int k=0;while(parent!=-1){if(child==HTree[parent].LChild)HCodeTable[i].code[k]='0';elseHCodeTable[i].code[k]='1';k++;child=parent;parent=HTree[child].parent;}HCodeTable[i].code[k]='\0';cout<<b[i]<<"的编码:";for(int j=k-1;j>=0;j--)cout<<HCodeTable[i].code[j];cout<<endl;}3.编码cout<<"编码后的字符串为:";while(*d!='\0'){for(int i=0;i<n;i++){if(b[i]==*d) //判断,每当出现一种时,就找到对应编码并输出{int k=strlen(HCodeTable[i].code);for(int j=k-1;j>=0;j--){*s=HCodeTable[i].code[j];cout<<*s;s++;}}}d++;}*s='\0';cout<<endl;【计算关键算法的时间、空间复杂度】关键算法A的时间复杂度为O(n),关键算法B的时间复杂度为O(n),关键算法C的时间复杂度为O(n),关键算法D的时间复杂度为O(n).2.3 其他程序完整代码:#include<iostream>using namespace std;const int MAX=1000;struct HNode{int weight;int parent;int LChild;int RChild;};struct HCode{char data;char code[200];};class Huffman{private:HNode *HTree; //哈夫曼树HCode *HCodeTable; //哈夫曼编码表char b[MAX]; //记录出现的字符int a[MAX]; //记录每个字符出现的次数,即权值static int n; //字符的种类数(静态变量)public:void init(char s[]); //初始化void init1(char s[]);void CreateCodeTable(); //创建编码表void Encoding(char *s,char *d); //编码void Decoding(char *s,char *d); //解码int count1() //算编码前长度{int q1=0;for(int i=0;i<n;i++){q1+=8*a[i];}return q1;}int count2() //算编码后长度{int q2=0;for(int i=0;i<n;i++){q2+=strlen(HCodeTable[i].code)*a[i];}return q2;}};int Huffman::n=0;void Huffman::init(char s[]){int i,j;for(i=0;i<MAX;i++)a[i]=0; //先将a[]数组中每个值都赋为,不然程序会运行出错?for(i=0;s[i]!='\0';i++) //'\0'字符串结束标志{for(j=0;j<n;j++){if(s[i]==b[j]) //判断该字符是否已经出现过break;}if(j<n) //该字符出现过,对应计数器加一a[j]++;else//该字符为新字符,上面的循环全部运行完毕,j=n,记录到b[j]中,对应计数器加一{b[j]=s[i];a[j]++;n++; //出现的字符种类数加一}}//cout<<"共有"<<n<<"种字符,分别为:"<<endl;for(i=0;i<n;i++)cout<<b[i]<<"出现次数为:"<<a[i]<<endl;HTree=new HNode[2*n-1] ; //哈夫曼树初始化for(int q=0;q<2*n-1;q++){if(q<n){HTree[q].weight=a[q];}else{HTree[q].weight=0;}HTree[q].LChild=-1;HTree[q].RChild=-1;HTree[q].parent=-1;}int x,y,m1,m2; //x,y用于存放权值最小结点在数组中的下标for(int w=n;w<2*n-1;w++) //开始建哈夫曼树{//找出权值最小的结点m1=m2=MAX; //MAX=1000x=y=0;for(int j=0;j<i;j++){if(HTree[j].weight<m1&&HTree[j].parent==-1){m2=m1;m1=HTree[j].weight;x=j;}else if(HTree[j].weight < m2 && HTree[j].parent==-1){m2=HTree[j].weight;y=j;}}HTree[x].parent=HTree[y].parent=w;HTree[w].weight=HTree[x].weight+HTree[y].weight;HTree[w].LChild=x;HTree[w].RChild=y;HTree[w].parent=-1;}}void Huffman::init1(char s[]){int i,j;for(i=0;i<MAX;i++)a[i]=0; //先将a[]数组中每个值都赋为,不然程序会运行出错?for(i=0;s[i]!='\0';i++) //'\0'字符串结束标志{for(j=0;j<n;j++){if(s[i]==b[j]) //判断该字符是否已经出现过break;}if(j<n) //该字符出现过,对应计数器加一a[j]++;else//该字符为新字符,上面的循环全部运行完毕,j=n,记录到b[j]中,对应计数器加一{b[j]=s[i];a[j]++;n++; //出现的字符种类数加一}}HTree=new HNode[2*n-1] ; //哈夫曼树初始化for(int e=0;e<2*n-1;e++){if(e<n){HTree[e].weight=a[e];}else{HTree[e].weight=0;}HTree[e].LChild=-1;HTree[e].RChild=-1;HTree[e].parent=-1;}int x,y,m1,m2; //x,y用于存放权值最小结点在数组中的下标,m1,m2用于存放两个无父结点且结点权值最小的两个结点for(int r=n;r<2*n-1;r++) //开始建哈夫曼树{//找出权值最小的结点m1=m2=MAX; //MAX=1000x=y=0;for(int j=0;j<r;j++){if(HTree[j].weight<m1&&HTree[j].parent==-1){m2=m1;//y=x;m1=HTree[j].weight;x=j;}else if(HTree[j].weight < m2 && HTree[j].parent==-1){m2=HTree[j].weight;y=j;}}HTree[x].parent=HTree[y].parent=r;HTree[r].weight=HTree[x].weight+HTree[y].weight;HTree[r].LChild=x;HTree[r].RChild=y;HTree[r].parent=-1;}}void Huffman::CreateCodeTable() //生成编码表{HCodeTable=new HCode[n];for(int i=0;i<n;i++){HCodeTable[i].data=b[i];int child=i;int parent=HTree[i].parent;int k=0;while(parent!=-1){if(child==HTree[parent].LChild)HCodeTable[i].code[k]='0';elseHCodeTable[i].code[k]='1';k++;child=parent;parent=HTree[child].parent;}HCodeTable[i].code[k]='\0';cout<<b[i]<<"的编码:";for(int j=k-1;j>=0;j--)cout<<HCodeTable[i].code[j];cout<<endl;}}void Huffman::Encoding(char *s,char *d) // 编码算法 //d为字符串{cout<<"编码后的字符串为:";while(*d!='\0'){for(int i=0;i<n;i++){if(b[i]==*d) //判断,每当出现一种时,就找到对应编码并输出{int k=strlen(HCodeTable[i].code);for(int j=k-1;j>=0;j--){*s=HCodeTable[i].code[j];cout<<*s;s++;}}}d++;}*s='\0';cout<<endl;}void Huffman::Decoding(char *s,char *d) //s为编码串{cout<<"解码后的字符串为:";while(*s!='\0'){int parent=2*n-1-1;while(HTree[parent].LChild!=-1){if(*s=='0')parent=HTree[parent].LChild;elseparent=HTree[parent].RChild;s++;}*d=HCodeTable[parent].data;cout<<*d;d++;}cout<<endl;void main(){int i=0;char d[MAX];char s[MAX];cout<<"请输入字符串:";while((d[i]=getchar())!='\n')i++;d[i]='\0';Huffman h;cout<<"哈夫曼功能:"<<endl;cout<<"1.统计字符种类及出现次数"<<endl;cout<<"2.数据的编码解码"<<endl;cout<<"3.分析压缩效果"<<endl;int q;for(;;){cout<<"请输入(1~3)"<<endl;cin>>q;bool x=0;switch (q){case 1:h.init(d);break;case 2:h.init1(d);h.CreateCodeTable();h.Encoding(s,d);h.Decoding(s,d);break;case 3:cout<<"编码前的长度为:"<<h.count1()<<endl;cout<<"编码后的长度为:"<<h.count2()<<endl;cout<<"压缩比为:"<<(h.count2()*1.0/h.count1())<<endl;break;default:cout<<"请输入选择!!!!!"<<endl;break;}}3.}程序运行结果分析输入:I love data Structure, I love Computer。

数据结构实验报告实验名称:实验三树——哈夫曼编/解码器学生姓名:班级:班内序号:学号:日期:2014年12月11日1.实验要求利用二叉树结构实现赫夫曼编/解码器。
基本要求:1、初始化(Init):能够对输入得任意长度得字符串s进行统计,统计每个字符得频度,并建立赫夫曼树2、建立编码表(CreateTable):利用已经建好得赫夫曼树进行编码,并将每个字符得编码输出。
3、编码(Encoding):根据编码表对输入得字符串进行编码,并将编码后得字符串输出。
4、译码(Decoding):利用已经建好得赫夫曼树对编码后得字符串进行译码,并输出译码结果。
5、打印(Print):以直观得方式打印赫夫曼树(选作)6、计算输入得字符串编码前与编码后得长度,并进行分析,讨论赫夫曼编码得压缩效果。
测试数据:I lovedata Structure, I loveputer。
I willtrymy best tostudy data Structure、提示:1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入得字符串中每个字符出现得次数统计频度,对没有出现得ﻩ字符一律不用编码。
2、程序分析2、1存储结构Huffman树给定一组具有确定权值得叶子结点,可以构造出不同得二叉树,其中带权路径长度最小得二叉树称为Huffman树,也叫做最优二叉树。
weightlchildrchild parent2-1-1-15-1-1-16-1-1-17-1-1-19-1-1-1weight lchild rchildparent 2-1-155-1-156-1-167-1-169-1-17701713238165482967-12、2 关键算法分析(1)计算出现字符得权值利用ASCII码统计出现字符得次数,再将未出现得字符进行筛选,将出现得字符及頻数存储在数组a[]中。
void Huffman::Init(){ﻩintnNum[256]= {0};//记录每一个字符出现得次数int ch = cin、get();int i=0;ﻩwhile((ch!='\r') && (ch!='\n'))ﻩ{ﻩﻩnNum[ch]++; //统计字符出现得次数ﻩstr[i++] = ch; //记录原始字符串ﻩch = cin、get(); //读取下一个字符ﻩ}str[i]='\0';n = 0;for ( i=0;i<256;i++)ﻩ{ﻩﻩif(nNum[i]>0) //若nNum[i]==0,字符未出现ﻩ{l[n] = (char)i;ﻩa[n] = nNum[i];n++;ﻩ}}}时间复杂度为O(1);(2)创建哈夫曼树:算法过程:Huffman树采用顺序存储---数组;数组得前n个结点存储叶子结点,然后就是分支结点,最后就是根结点;首先初始化叶子结点元素—循环实现;以循环结构,实现分支结点得合成,合成规则按照huffman树构成规则进行。

二叉树实验报告1. 引言二叉树是一种常用的数据结构,广泛应用于计算机科学和信息技术领域。
本实验旨在通过对二叉树的理解和实现,加深对数据结构与算法的认识和应用能力。
本报告将介绍二叉树的定义、基本操作以及实验过程中的设计和实现。
2. 二叉树的定义二叉树是一个有序树,其每个节点最多有两个子节点。
树的左子节点和右子节点被称为二叉树的左子树和右子树。
3. 二叉树的基本操作3.1 二叉树的创建在实验中,我们通过定义一个二叉树的节点结构来创建一个二叉树。
节点结构包含一个数据域和左右指针,用于指向左右子节点。
创建二叉树的过程可以通过递归或者迭代的方式来完成。
3.2 二叉树的插入和删除二叉树的插入操作是将新节点插入到树中的合适位置。
插入时需要考虑保持二叉树的有序性。
删除操作是将指定节点从树中删除,并保持二叉树的有序性。
在实验中,我们可以使用递归或者循环的方式实现这些操作。
3.3 二叉树的遍历二叉树的遍历是指按照某种次序访问二叉树的所有节点。
常见的遍历方式包括前序遍历、中序遍历和后序遍历。
前序遍历先访问根节点,然后按照左孩子-右孩子的顺序递归遍历左右子树。
中序遍历按照左孩子-根节点-右孩子的顺序递归遍历左右子树。
后序遍历按照左孩子-右孩子-根节点的顺序递归遍历左右子树。
3.4 二叉树的查找查找操作是指在二叉树中查找指定的值。
可以通过递归或者循环的方式实现二叉树的查找操作。
基本思路是从根节点开始,通过比较节点的值和目标值的大小关系,逐步向左子树或者右子树进行查找,直到找到目标节点或者遍历到叶子节点。
4. 实验设计和实现在本实验中,我们设计并实现了一个基于Python语言的二叉树类。
具体实现包括二叉树的创建、插入、删除、遍历和查找操作。
在实验过程中,我们运用了递归和迭代的方法实现了这些操作,并进行了测试和验证。
4.1 二叉树类的设计我们将二叉树的节点设计为一个类,其中包括数据域和左右子节点的指针。
另外,我们设计了一个二叉树类,包含了二叉树的基本操作方法。

数据结构上机实验报告二叉树问题陈冠豪20102105010101015二O一O年5月26号实验目的建立一棵二叉树,要求分别用递归和非递归方法实现二叉树的先序、中序和后序遍历。
实现代码:#ifndef TREE_H#define TREE_H#include <stdio.h> #include <malloc.h> #include <stack>#include <queue>#include <assert.h> using namespace std; typedefintElemType;typedef struct treeT {ElemType key;struct treeT* left;struct treeT* right; }treeT, *pTreeT;static void visit(pTreeT root){if (NULL != root){printf(" %d\n", root->key);}}static pTreeT BT_MakeNode(ElemType target){pTreeT pNode = (pTreeT) malloc(sizeof(treeT)); assert( NULL != pNode );pNode->key = target;pNode->left = NULL;pNode->right = NULL;return pNode;}pTreeT BT_Insert(ElemType target, pTreeT* ppTree) {pTreeT Node;assert( NULL != ppTree );Node = *ppTree;if (NULL == Node){return *ppTree = BT_MakeNode(target);}if (Node->key == target) //不允许出现相同的元素 {return NULL;}else if (Node->key > target) //向左{return BT_Insert(target, &Node->left);}else{return BT_Insert(target, &Node->right);}}void BT_PreOrder(pTreeT root){if (NULL != root){visit(root);BT_PreOrder(root->left);BT_PreOrder(root->right);}}void BT_PreOrderNoRec(pTreeT root) {stack<treeT *> s;while ((NULL != root) || !s.empty()) {if (NULL != root){visit(root);s.push(root);root = root->left;}else{root = s.top();s.pop();}}void BT_InOrder(pTreeT root){if (NULL != root){BT_InOrder(root->left);visit(root);BT_InOrder(root->right);}}void BT_InOrderNoRec(pTreeT root) {stack<treeT *> s;while ((NULL != root) || !s.empty()) {if (NULL != root){s.push(root);else{root = s.top();visit(root);s.pop();root = root->right;}}}void BT_PostOrder(pTreeT root) {if (NULL != root){BT_PostOrder(root->left); BT_PostOrder(root->right); visit(root);}}void BT_PostOrderNoRec(pTreeT root) {}void BT_LevelOrder(pTreeT root) {queue<treeT *> q;treeT *treePtr;assert( NULL != root );q.push(root);while (!q.empty()){treePtr = q.front();q.pop();visit(treePtr);if (NULL != treePtr->left){q.push(treePtr->left);}if (NULL != treePtr->right) {q.push(treePtr->right); }}}#endif#include <stdio.h>#include <stdlib.h>#include <time.h>#define MAX_CNT 5#define BASE 100void main(int argc, char *argv[]) {int i;char temp;pTreeT root = NULL;srand( (unsigned)time( NULL ) );printf("请输入元素:\nA.自动生成.\nB.手动输入.\n");do{temp=getchar();}while(!(temp=='A'||temp=='a'||temp=='B'||temp=='b'));if((temp)=='A'||(temp)=='a'){for (i=0; i<MAX_CNT; i++){BT_Insert(rand() % BASE, &root);}}else if((temp)=='B'||(temp)=='b'){printf("请输入元素,元素以#结尾\n");while((temp=getchar())!='#')BT_Insert(temp, &root);}//前序printf("PreOrder:\n");BT_PreOrder(root);printf("\n");printf("PreOrder no recursion:\n"); BT_PreOrderNoRec(root);printf("\n");//中序printf("InOrder:\n");BT_InOrder(root);printf("\n");printf("InOrder no recursion:\n"); BT_InOrderNoRec(root);printf("\n");//后序printf("PostOrder:\n");BT_PostOrder(root);printf("\n");//层序printf("LevelOrder:\n");BT_LevelOrder(root);printf("\n");}。
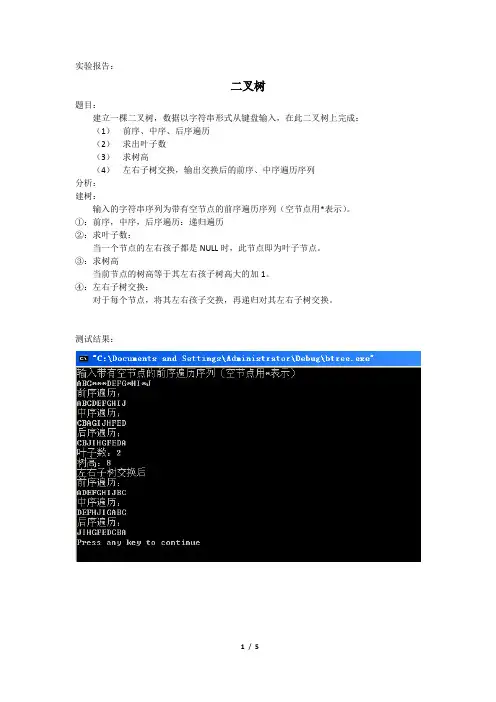
实验报告:二叉树题目:建立一棵二叉树,数据以字符串形式从键盘输入,在此二叉树上完成:(1)前序、中序、后序遍历(2)求出叶子数(3)求树高(4)左右子树交换,输出交换后的前序、中序遍历序列分析:建树:输入的字符串序列为带有空节点的前序遍历序列(空节点用*表示)。
①:前序,中序,后序遍历:递归遍历②:求叶子数:当一个节点的左右孩子都是NULL时,此节点即为叶子节点。
③:求树高当前节点的树高等于其左右孩子树高大的加1。
④:左右子树交换:对于每个节点,将其左右孩子交换,再递归对其左右子树交换。
测试结果:附:源码#include <iostream>#include <stdlib.h>using namespace std;struct Bintree{char data;Bintree* lchild;Bintree* rchild;};Bintree *head;int sp;/* 已知一棵二叉树的前序序列,建立这棵树*/ void CreateTree(Bintree *&p,char a[]){Bintree *temp;if(a[sp]!=0){if(a[sp]=='*'){p=NULL;sp++;return ;}p=new Bintree;p->data=a[sp++];CreateTree(p->lchild,a);CreateTree(p->rchild,a);}else p=NULL;}/* 求一棵树的高度*/int Depth(Bintree *&t){int lh , rh ;if( t == NULL ){return 0 ;}else{lh = Depth( t->lchild ) ;rh = Depth( t->rchild ) ;return ( lh > rh ? lh : rh ) + 1 ;}}/* 将二叉树的左右子树互换*/ void Exchange1(Bintree *&t){Bintree *temp;if(t){Exchange1(t->lchild);Exchange1(t->rchild);temp=t->lchild;t->lchild=t->rchild;t->rchild=temp;}}/* 按照前序递归遍历二叉树*/ void Preorder1(Bintree *&t){if(t!=NULL){printf("%c",t->data);Preorder1(t->lchild);Preorder1(t->rchild);}}/* 按照中序递归遍历二叉树*/ void Inorder1(Bintree *&t){if(t!=NULL){Inorder1(t->lchild);printf("%c",t->data);Inorder1(t->rchild);}}/* 按照后序递归遍历二叉树*/void Posorder1(Bintree *&t){if(t!=NULL){Posorder1(t->lchild);Posorder1(t->rchild);printf("%c",t->data);}}/* 递归法求叶子结点个数*/int Leaves_Num1(Bintree *&t){if(t){if(t->lchild==NULL&&t->rchild==NULL){return 1;}return Leaves_Num1(t->lchild)+Leaves_Num1(t->rchild);}return 0;}/*******************************************/int main (){char a[100];memset(a,0,sizeof(a));cout<<"输入带有空节点的前序遍历序列(空节点用*表示)"<<endl;cin>>a;sp=0;CreateTree(head,a);cout<<"前序遍历:"<<endl;Preorder1(head);cout<<endl;cout<<"中序遍历:"<<endl;Inorder1(head);cout<<endl;cout<<"后序遍历:"<<endl;Posorder1(head);cout<<endl;cout<<"叶子数:"<<Leaves_Num1(head)<<endl;cout<<"树高:"<<Depth(head)<<endl;cout<<"左右子树交换后"<<endl;Exchange1(head);cout<<"前序遍历:"<<endl;Preorder1(head);cout<<endl;cout<<"中序遍历:"<<endl;Inorder1(head);cout<<endl;cout<<"后序遍历:"<<endl;Posorder1(head);cout<<endl;return 0;}。

数据结构实习报告---二叉树二叉树一、需求分析1、设计任务建立一棵二叉树,数据以字符串形式从键盘输入。
在此二叉树上完成:(1)前序、中序、后序遍历(2)求出叶子数(3)求树高(4)左右子树交换,输出交换后的前序、中序遍历序列选做:(1)给出非递归的后序遍历(2)扩充为中序线索树,写出非递归的中序遍历(3)在两个数组中分别有前序和中序遍历序列,试建立该二叉树2、输入的形式和输出值的范围二叉树的建立:本程序的二叉树的建立函数时根据二叉树的前序排列生成的,但是其中子树为空地方用特殊符号“*”代替。
二叉树的输出值的范围:二叉树的输出是把二叉树各节点的值按遍历顺序输出的,本程序各节点的数据类型为字符型(可以在编译预处理修改)。
3、输出的形式二叉树的输出是根据二叉树的遍历顺序输出的(包括前序、中序和后序三种)把各节点地值输出。
4、程序所能达到的功能本程序能够实现对二叉树的一些简单操作,例如二叉树的各种遍历(包括二叉树的前序、中序和后序的递归遍历以及非递归遍历)、求二叉树的叶子数和高以及二叉树的左右子树交换。
5、测试数据(1)当为二叉树一时:(2)当为二叉树二时:二、概要设计1、树结点结构体typedef char DataType; struct TreeNode{DataType data;TreeNode *lchild,*rchild;};2、棧结点结构体struct StackNode{TreeNode* T_N;int Flag;};3、主程序流程主程序开始;调用CreateBiTree(TreeNode *&Tree)函数建立二叉树;依次调用前序、中序和后序递归及非递归遍历二叉树;计算二叉树的树叶和树高;交换二叉树的左右子树;依次用前序、中序和后序的递归和非递归方法遍历二叉树;主程序结束;三、详细设计(1)递归遍历的实现(以前序为例);算法为:先访问根结点,然后递归的访问左子树和右子树。
实验三二叉树的遍历一、实验目的1、熟悉二叉树的结点类型和二叉树的基本操作。
2、掌握二叉树的前序、中序和后序遍历的算法。
3、加深对二叉树的理解,逐步培养解决实际问题的编程能力。
二、实验环境运行C或VC++的微机。
三、实验内容1、依次输入元素值,以链表方式建立二叉树,并输出结点的值。
2、分别以前序、中序和后序遍历二叉树的方式输出结点内容。
四、设计思路1. 对于这道题,我的设计思路是先做好各个分部函数,然后在主函数中进行顺序排列,以此完成实验要求2.二叉树采用动态数组3.二叉树运用9个函数,主要有主函数、构建空二叉树函数、建立二叉树函数、访问节点函数、销毁二叉树函数、先序函数、中序函数、后序函数、范例函数,关键在于访问节点五、程序代码#include <stdio.h>#include <stdlib.h>#include <malloc.h>#define OK 1#define ERROR 0typedef struct TNode//结构体定义{-int data; //数据域struct TNode *lchild,*rchild; // 指针域包括左右孩子指针}TNode,*Tree;void CreateT(Tree *T)//创建二叉树按,依次输入二叉树中结点的值{int a;scanf("%d",&a);if(a==00) // 结点的值为空*T=NULL;else // 结点的值不为空{*T=(Tree)malloc(sizeof(TNode));if(!T){printf("分配空间失败!!TAT");exit(ERROR);}(*T)->data=a;CreateT(&((*T)->lchild)); // 递归调用函数,构造左子树CreateT(&((*T)->rchild)); // 递归调用函数,构造右子树}}void InitT(Tree *T)//构建空二叉树{T=NULL;}void DestroyT(Tree *T)//销毁二叉树{if(*T) // 二叉树非空{DestroyT(&((*T)->lchild)); // 递归调用函数,销毁左子树DestroyT(&((*T)->rchild)); // 递归调用函数,销毁右子树free(T);T=NULL;}}void visit(int e)//访问结点{printf("%d ",e);}-void PreOrderT(Tree *T,void(*visit)(int))//先序遍历T{if(*T) // 二叉树非空{visit((*T)->data); // 先访问根结点PreOrderT(&((*T)->lchild),visit); // 递归调用函数,先序遍历左子树PreOrderT(&((*T)->rchild),visit); // 递归调用函数,先序遍历右子树}}void InOrderT(Tree *T,void(*visit)(int)){if(*T){InOrderT(&((*T)->lchild),visit); // 递归调用函数,中序遍历左子树visit((*T)->data); // 访问根结点InOrderT(&((*T)->rchild),visit); // 递归调用函数,中序遍历右子树}}void PostOrderT(Tree *T,void(*visit)(int)){if(*T){PostOrderT(&((*T)->lchild),visit); // 递归调用函数,后序遍历左子树PostOrderT(&((*T)->rchild),visit); // 递归调用函数,序遍历右子树visit((*T)->data); // 访问根结点}}void example(){int i;printf("如果你想建立如图所示的二叉树\n");printf("\n");printf(" 1 \n");printf(" / \\ \n");printf(" 3 3 \n");printf(" / \\ \\ \n");printf(" 4 5 7 \n");printf("\n");printf("请输入:1 3 4 00 00 5 00 00 3 00 7 00 00\n");printf("\n按先序次序输入二叉树中结点的值(输入00表示节点为空)\n");for(i=0;i<71;i++)printf("*");printf("\n");}int main (){Tree T;printf("**************欢迎使用!**************潘俊达\n"); example();printf("\n请输入所要建立的二叉树:\n");CreateT(&T);InitT(&T);int i;printf("先序遍历二叉树:\n");PreOrderT(&T,visit);printf("\n");printf("\n中序遍历二叉树:\n");InOrderT(&T,visit);printf("\n");printf("\n后序遍历二叉树:\n");PostOrderT(&T,visit);printf("\n");system("PAUSE");return 0;}六、程序截图1.范例函数显示,并输入先序二叉树节点值2.先序遍历二叉树3.中序遍历二叉树3.后序遍历二叉树。
北京邮电大学软件学院2019-2020学年第1学期实验报告课程名称:算法与数据结构课程设计实验名称:树及其应用实验完成人:日期: 2019 年 11月 10 日一、实验目的树是一种应用极为广泛的数据结构,也是这门课程的重点。
它们的特点在于非线性。
广义表本质上是树结构。
本章实验继续突出了数据结构加操作的程序设计观点,但根据这两种结构的非线性特点,将操作进一步集中在遍历操作上,因为遍历操作是其他众多操作的基础。
遍历逻辑的(或符号形式的)结构,访问动作可是任何操作。
本次实验希望帮助学生熟悉各种存储结构的特征,以及如何应用树结构解决具体问题(即原理与应用的结合)。
二、实验内容必做内容1)二叉树的建立与遍历[问题描述]建立一棵二叉树,并对其进行遍历(先序、中序、后序),打印输出遍历结果。
[基本要求]从键盘接受输入(先序),以二叉链表作为存储结构,建立二叉树(以先序来建立),并采用递归算法对其进行遍历(先序、中序、后序),将遍历结果打印输出。
[测试数据]ABCффDEфGффFффф(其中ф表示空格字符)则输出结果为先序:ABCDEGF中序:CBEGDFA后序:CGBFDBA2)打印二叉树结构[问题描述]按凹入表形式横向打印二叉树结构,即二叉树的根在屏幕的最左边,二叉树的左子树在屏幕的下边,二叉树的右子树在屏幕的上边。
例如:[测试数据]由学生依据软件工程的测试技术自己确定。
注意测试边界数据,如空二叉树。
[实现提示](1)利用RDL遍历方法;(2)利用结点的深度控制横向位置。
选做内容采用非递归算法实现二叉树遍历。
三、实验环境Windows下利用vs 2019完成,语言c++四、实验过程描述首先构造Tree类,内含树的结构体BiTree,以及本实验所要用到的一些操作typedef struct BiTNode{TElemType data;int degree, depth, level; //度,高度,高度差struct BiTNode* lchild, * rchild; /* 左右孩子指针 */}BiTNode, * BiTree;实现相应功能:1、二叉树的建立与遍历构造二叉树:前序构造,先赋值,然后递归构造左子树,递归构造右函数BiTNode* Tree::CreatBiTree(BiTree T) {TElemType ch;cin >> noskipws >> ch; //不跳过空格if (ch == ' ')T = NULL; //输入空格表示空子树else {T = new BiTNode; //分配空间if(!T) //分配失败就退出throw new std::bad_alloc;T->degree = 0; //记录度(T)->data = ch;T->depth++; //度增加T->lchild=CreatBiTree(T->lchild); //递归创建左子树T->rchild=CreatBiTree(T->rchild); //递归创建右子树if (T->lchild != NULL)T->degree++; //有一个孩子度就加一if (T->rchild != NULL)T->degree++;}return T;}销毁二叉树:后序递归销毁左右子树(需要先查找到子树,销毁再销毁父亲树)void Tree::Release(BiTree T) {if (T != NULL) {Release(T->lchild); //递归销毁左子树Release(T->rchild); //递归销毁右子树delete T;}}//前序遍历void Tree::PreOrderTraverse(BiTree T, void(Tree::*Visit)(BiTree)) { if (T) /* T不空 */{(this->*Visit)(T); /* 先访问根结点 */PreOrderTraverse(T->lchild, Visit); /* 再先序遍历左子树 */PreOrderTraverse(T->rchild, Visit); /* 最后先序遍历右子树 */ }}//中序遍历void Tree::InOrderTraverse(BiTree T, void(Tree::*Visit)(BiTree)) {if (T){InOrderTraverse(T->lchild, Visit); /* 先中序遍历左子树 */(this->*Visit)(T); /* 再访问根结点 */InOrderTraverse(T->rchild, Visit); /* 最后中序遍历右子树 */ }}//后序遍历void Tree::PostOrderTraverse(BiTree T, void(Tree::*Visit)(BiTree)) {if (T){PostOrderTraverse(T->lchild, Visit); /* 先中序遍历左子树 */PostOrderTraverse(T->rchild, Visit); /* 最后中序遍历右子树 */(this->*Visit)(T); /* 再访问根结点 */}}//查找深度int Tree::TreeDepth(BiTree T) {int i, j;if (!T)return 0; /* 空树深度为0 */if (T->lchild)i = TreeDepth(T->lchild); /* i为左子树的深度 */elsei = 0;if (T->rchild)j = TreeDepth(T->rchild); /* j为右子树的深度 */elsej = 0;T->depth = i > j ? i + 1 : j + 1;return T->depth;}//得到层数void Tree::getLevel(BiTree T, int level){if (T){T->level = level;getLevel(T->lchild, level + 1); //得到左子树的层数,左子树根节点的层数比此节点多一getLevel(T->rchild, level + 1); //得到右子树的层数,右子树根节点的层数比此节点多一}}//非递归中序遍历void Tree::NoRecInOrderTraverse(BiTree T, void(Tree::*Visit)(BiTree)) {LinkedStack<BiTree> S;BiTree p = T;while (p || !S.isEmpty()) {if (p) {S.Push(p); //当节点不为空时就压栈,然后判断左孩子p = p->lchild;}else {p=S.Pop(); //返回到父节点(this->*Visit)(p); //访问p = p->rchild; //然后指向右节点}}}实验二:2、打印二叉树结构//中序遍历RDLvoid Tree::InOrderTraverseRDL(BiTree T, void(Tree::* Visit)(BiTree)) {if (T){InOrderTraverseRDL(T->rchild, Visit); /* 先中序遍历左子树 */(this->*Visit)(T); /* 再访问根结点 */InOrderTraverseRDL(T->lchild, Visit); /* 最后中序遍历右子树 */ }}//打印二叉树图形打印图形时,需要中序遍历RDL(先遍历右节点,再遍历右节点)。
《算法与数据结构》课程实验报告一、实验目的1、实现二叉树的存储结构2、熟悉二叉树基本术语的含义3、掌握二叉树相关操作的具体实现方法二、实验内容及要求1. 建立二叉树2. 计算结点所在的层次3. 统计结点数量和叶结点数量4. 计算二叉树的高度5. 计算结点的度6. 找结点的双亲和子女7. 二叉树前序、中序、后序遍历的递归实现和非递归实现及层次遍历8. 二叉树的复制9. 二叉树的输出等三、系统分析(1)数据方面:该二叉树数据元素采用字符char型,并且约定“#”作为二叉树输入结束标识符。
并在此基础上进行二叉树相关操作。
(2)功能方面:能够实现二叉树的一些基本操作,主要包括:1.采用广义表建立二叉树。
2.计算二叉树高度、统计结点数量、叶节点数量、计算每个结点的度、结点所在层次。
3.判断结点是否存在二叉树中。
4.寻找结点父结点、子女结点。
5.递归、非递归两种方式输出二叉树前序、中序、后序遍历。
6.进行二叉树的复制。
四、系统设计(1)设计的主要思路二叉树是的结点是一个有限集合,该集合或者为空,或者是由一个根节点加上两棵分别称为左子树和右子树、互不相交的二叉树组成。
根据实验要求,以及课上老师对于二叉树存储结构、基本应用的讲解,同时课后研究书中涉及二叉树代码完成二叉树模板类,并将所需实现各个功能代码编写完成,在建立菜单对功能进行调试。
(2)数据结构的设计二叉树的存储结构有数组方式和链表方式。
但用数组来存储二叉树有可能会消耗大量的存储空间,故在此选用链表存储,提高存储空间的利用率。
根据二叉树的定义,二叉树的每一个结点可以有两个分支,分别指向结点的左、右子树。
因此,二叉树的结点至少应包括三个域,分别存放结点的数据,左子女结点指针,右子女结点指针。
这将有利于查找到某个结点的左子女与右子女,但要找到它的父结点较为困难。
该实验采取二叉链表存储二叉树中元素,具体二叉树链表表示如下图所示。
图1二叉树的链表表示(3)基本操作的设计二叉树关键主要算法:利用广义表进行二叉树的建立。
《数据结构与数据库》实验报告实验题目二叉树的基本操作及运算一、需要分析问题描述:实现二叉树(包括二叉排序树)的建立,并实现先序、中序、后序和按层次遍历,计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目,以及二叉树常用运算。
问题分析:二叉树树型结构是一类重要的非线性数据结构,对它的熟练掌握是学习数据结构的基本要求。
由于二叉树的定义本身就是一种递归定义,所以二叉树的一些基本操作也可采用递归调用的方法。
处理本问题,我觉得应该:1、建立二叉树;2、通过递归方法来遍历(先序、中序和后序)二叉树;3、通过队列应用来实现对二叉树的层次遍历;4、借用递归方法对二叉树进行一些基本操作,如:求叶子数、树的深度宽度等;5、运用广义表对二叉树进行广义表形式的打印。
算法规定:输入形式:为了方便操作,规定二叉树的元素类型都为字符型,允许各种字符类型的输入,没有元素的结点以空格输入表示,并且本实验是以先序顺序输入的。
输出形式:通过先序、中序和后序遍历的方法对树的各字符型元素进行遍历打印,再以广义表形式进行打印。
对二叉树的一些运算结果以整型输出。
程序功能:实现对二叉树的先序、中序和后序遍历,层次遍历。
计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目。
对二叉树的某个元素进行查找,对二叉树的某个结点进行删除。
测试数据:输入一:ABC□□DE□G□□F□□□(以□表示空格),查找5,删除E预测结果:先序遍历ABCDEGF中序遍历CBEGDFA后序遍历CGEFDBA层次遍历ABCDEFG广义表打印A(B(C,D(E(,G),F)))叶子数3 深度5 宽度2 非空子孙数6 度为2的数目2 度为1的数目2查找5,成功,查找的元素为E删除E后,以广义表形式打印A(B(C,D(,F)))输入二:ABD□□EH□□□CF□G□□□(以□表示空格),查找10,删除B预测结果:先序遍历ABDEHCFG中序遍历DBHEAGFC后序遍历DHEBGFCA层次遍历ABCDEFHG广义表打印A(B(D,E(H)),C(F(,G)))叶子数3 深度4 宽度3 非空子孙数7 度为2的数目2 度为1的数目3查找10,失败。
数据结构实验报告实验名称:实验三树——哈夫曼编/解码器学生:班级:班序号:学号:日期:2014年12月11日1.实验要求利用二叉树结构实现赫夫曼编/解码器。
基本要求:1、初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树2、建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码输出。
3、编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
5、打印(Print):以直观的方式打印赫夫曼树(选作)6、计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
测试数据:I love data Structure, I love Computer。
I will try my best to study data Structure.提示:1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入的字符串中每个字符出现的次数统计频度,对没有出现的字符一律不用编码。
2. 程序分析2.1 存储结构Huffman树给定一组具有确定权值的叶子结点,可以构造出不同的二叉树,其中带权路径长度最小的二叉树称为Huffman树,也叫做最优二叉树。
weight lchild rchild parent 2-1-1-15-1-1-16-1-1-17-1-1-19-1-1-1weight lchild rchild parent2-1-155-1-156-1-167-1-169-1-17701713238165482967-12.2 关键算法分析(1)计算出现字符的权值利用ASCII码统计出现字符的次数,再将未出现的字符进行筛选,将出现的字符及頻数存储在数组a[]中。
void Huffman::Init(){int nNum[256]= {0}; //记录每一个字符出现的次数int ch = cin.get();int i=0;while((ch!='\r') && (ch!='\n')){nNum[ch]++; //统计字符出现的次数str[i++] = ch; //记录原始字符串ch = cin.get(); //读取下一个字符}str[i]='\0';n = 0;for ( i=0;i<256;i++){if (nNum[i]>0) //若nNum[i]==0,字符未出现{l[n] = (char)i;a[n] = nNum[i];n++;}}}时间复杂度为O(1);(2)创建哈夫曼树:算法过程:Huffman树采用顺序存储---数组;数组的前n个结点存储叶子结点,然后是分支结点,最后是根结点;首先初始化叶子结点元素—循环实现;以循环结构,实现分支结点的合成,合成规则按照huffman树构成规则进行。
一、【实验构思(Conceive)】(10%)(本部分应包括:描述实验实现的基本思路,包括所用到的离散数学、工程数学、程序设计、算法等相关知识)首先构造二叉树的存储结构,用data存储当前节点的值,分别用*lchild,*rchild 表示该节点的左右孩子。
然后应用BiTree Create函数,根据用户的输入构造二叉树,当输入#时表示没有孩子。
采用递归的思想构造Preorder,Inorder,Postorder函数,分别实现二叉树的先序,中序,和后序的遍历。
然后编写了Sumleaf,Depth函数,来求叶子节点的数目和二叉树的深度。
二、【实验设计(Design)】(20%)(本部分应包括:抽象数据类型的功能规格说明、主程序模块、各子程序模块的伪码说明,主程序模块与各子程序模块间的调用关系)二叉树的存储结构:typedef struct BiTNode{char data;struct BiTNode *lchild,*rchild;}BiTNode,*BiTree;子程序模块:BiTree Create(BiTree T){char ch;ch=getchar();if(ch=='#')T=NULL;else{if(!(T=(BiTNode *)malloc(sizeof(BiTNode))))printf("Error!");T->data=ch;T->lchild=Create(T->lchild);T->rchild=Create(T->rchild);}return T;}void Preorder(BiTree T){if(T){printf("%c",T->data);Preorder(T->lchild);Preorder(T->rchild);}}int Sumleaf(BiTree T){int sum=0,m,n;if(T){if((!T->lchild)&&(!T->rchild)) sum++;m=Sumleaf(T->lchild);sum+=m;n=Sumleaf(T->rchild);sum+=n;}return sum;}void Inorder(BiTree T) {if(T){Inorder(T->lchild); printf("%c",T->data); Inorder(T->rchild); }}void Postorder(BiTree T) {if(T){Postorder(T->lchild); Postorder(T->rchild); printf("%c",T->data); }}int Depth(BiTree T){int dep=0,depl,depr;if(!T)dep=0;else{depl=Depth(T->lchild);depr=Depth(T->rchild);dep=1+(depl>depr?depl:depr);}return dep;}主程序模块:int main(){BiTree T = 0;int sum,dep;printf("请输入你需要建立的二叉树\n");printf("例如输入序列ABC##DE#G##F###(其中的#表示空)\n并且输入过程中不要加回车\n输入完之后可以按回车退出\n");T=Create(T);printf("先序遍历的结果是:\n");Preorder(T);printf("\n");printf("中序遍历的结果是:\n");Inorder(T);printf("\n");printf("后序遍历的结果是:\n");Postorder(T);printf("\n");printf("统计的叶子数:\n");sum=Sumleaf(T);printf("%d",sum);printf("\n统计树的深度:\n");dep=Depth(T);printf("\n%d\n",dep);}三、【实现描述(Implement)】(30%)(本部分应包括:抽象数据类型具体实现的函数原型说明、关键操作实现的伪码算法、函数设计、函数间的调用关系,关键的程序流程图等,给出关键算法的时间复杂度分析。
北京邮电大学电信工程学院 第1页 2011级数据结构实验报告 实验名称: 实验三——二叉树 学生姓名: 班 级: 班内序号: 学 号: 日 期: 2012年12月3日 1.实验要求 1.1实验目的 通过选择下面两个题目之一进行实现,掌握如下内容: ➢ 掌握二叉树基本操作的实现方法 ➢ 了解赫夫曼树的思想和相关概念 ➢ 学习使用二叉树解决实际问题的能力 1.2实验内容 根据二叉树的抽象数据类型的定义,使用二叉链表实现一个二叉树。 二叉树的基本功能: 1、二叉树的建立 2、前序遍历二叉树 3、中序遍历二叉树 4、后序遍历二叉树 5、按层序遍历二叉树 6、求二叉树的深度 7、求指定结点到根的路径 8、二叉树的销毁 9、其他:自定义操作 编写测试main()函数测试线性表的正确性 北京邮电大学电信工程学院 第2页 2. 程序分析 2.1 存储结构
2.2 关键算法分析 (1) 创建一个二叉树 通过构造函数创建一个二叉树,构造函数通过调用函数creat()创建二叉树 关于函数creat()的伪代码:
1.定义根指针,输入节点储存的data,若输入“#”,则该节点为空; 2.申请一个新节点,判断它的父结点是否不为空,如果不为空在判断其为左或者右孩子,并把地址付给父结点,把data写入。
lchild data rchild 二叉树的结点结构
A ∧ B ∧ ∧ ∧ ∧ ∧ ∧ ∧ C D E F G
头指针root
二叉树的二叉链表存储示意图 北京邮电大学电信工程学院
第3页 char ch; BiNode *Q[100]; int front,rear; BiNode *root,*S; root=NULL; front=1;rear=0; cout<<("按层次输入二叉树虚结点输入'#',以'@'结束输入\n"); cin>>ch; while(ch!='@') { S=NULL; if(ch!='#') { S=new BiNode; S->data=ch; S->lchild=NULL; S->rchild=NULL; } rear++; Q[rear]=S; //结点入队 if(rear==1) root=S; else { while(Q[front]== NULL&&front{ front++; } if (front==rear) break; if(rear%2==0) Q[front]->lchild=S; //新结点为父结点的左孩子 else { Q[front]->rchild=S; //新结点为父结点的右孩子 front++; }
} cin>>ch; } return root; }
(2)前序遍历 北京邮电大学电信工程学院 第4页 伪代码: 1.设置递归边界条件:if root==null则停止递归 2. 打印起始节点的值,并先后在左子数右子数上递归调用打印函数 if(root==NULL) return; else{ cout
else{ InOrder(root->lchild); //中序递归遍历root的 左子树 cout
else{ PostOrder(root->lchild); //后序递归遍历root的左子树
PostOrder(root->rchild); //后序递归遍历root的右子树
cout } 时间复杂度:O(n) (5)层序遍历 1.队列Q及所需指针的定义和初始化 2.如果二叉树非空,将根指针入队 北京邮电大学电信工程学院 第6页 3.循环直到队列Q为空 3.1 q=队列Q的队头元素出队 3.2 访问节点q的数据域 cout if(!root) return 0; //空二叉子树深度为0 if(ldeep > rdeep) //ldeep就是每个“二叉树”的左子树深度。 return ldeep + 1; //rdeep就是每个“二叉树”的右子树深度。 时间复杂度:O(n) (7) 计算树的叶结点数 北京邮电大学电信工程学院 第7页 伪代码: 1.如果根节点是空的,则返回0; 2.如果有根节点,且左右结点均为空,则返回1; 3.其他情况则递归调用LeafNode函数遍历树,计算最左右支的结点和。 (8)计算树的总结点数 伪代码: 1.如果根节点是空的,则返回0; 2.其他情况则递归调用NodeCount函数,计算所有结点的和。 (9)输出指定结点到根结点的路径 伪代码: 1.建立一个存储路径结点结构,定义和初始化结构体的数组 2.当root不为空或top为0时,进入循环 3.当此时root所指的节点的数据不为指定数据时,将root指向它的左孩子 4.当此时root所指的节点的数据为指定数据时,访问其数据域并输出 struct stack //创建结构来存储路径结点 { BiNode *bt; int tag; }; root=root->lchild;//将指针root指向此时节点的左孩子 for(int i=top;i>=1;i--) 北京邮电大学电信工程学院 第8页 cout<<"→" 3. 程序运行结果 3.1测试主函数流程图: 开始 调用构造函数创建一棵树 前序遍历并输出结果 求树的深度并输出 中序遍历并输出结果 后序遍历并输出结果 层序遍历并输出结果 输入需要寻找路径的结点并输出路径 输出叶子结点的总数 输出总结点数 北京邮电大学电信工程学院 第9页 3.2测试条件 对如下二叉树: 补全后的二叉树: 按层序遍历的输入方法为:ABC#EFGH###I###J###@ 3.3程序运行结果为: 4. 总结 A B C E F G H I J A B C E F G H I J # # # # # # # # # # 北京邮电大学电信工程学院 第10页 1.本次实验内容相对基础,很多代码在书上都能找到,但是写程序的时候还是遇到了一些问题,特别是在参数传递方面很容易出错,因为本次实验的很多算法都依靠递归来实现,递归具有代码简洁但理解不易的特点,特别是在参数传递方面,要通过作图等方式才能搞清楚整个递归过程。 2.由于单单靠前序、中序、后序或者层序,都无法唯一确定的建立一个二叉树,所以课本上提供的算法是输入按一定规则补全后的二叉树,首先应该明白输入的规则,要不然程序运行也很容易出错。 3.本程序多了两个计算结点的函数,本来最开始想编一个打印树的函数,可是发现定位光标的位置实在非常有难度,而且采用本程序的存储结构好像很难实现,只好作罢,但是还是很希望能有机会编出来。 4.开始的时候也是写了按前序遍历创树的,用了简单的递归调用,但是发现输入会有许多不便。所以很希望可以按层输入,于是做了尝试,虽然代码可能写的不是很简单,但是终于实现了按层输入。在c++语言的编写中就应该使其有更好的实用性,并敢于尝试,不断改进。