基于Python的新浪微博爬虫研究
- 格式:doc
- 大小:53.50 KB
- 文档页数:4

新浪微博上有很多用户发布的社交信息数据,对于做营销或者运营行业的朋友来说,这些数据都非常的具有价值,比如做营销的同学可以根据微博的阅读量、转化量以及评论数等数据可以大致的判断这个人是否具有影响力,从而找到自身行业中的KOL。
另外像微博的评论数据,能反应出自身产品对于用户的口碑如何,利用爬虫采集数据,可以第一时间找到自身产品的缺点,从而进行改进。
那么,说了这么多,应该如何利用微博爬虫去采集数据呢。
步骤1:创建采集任务1)进入主界面,选择“自定义模式”2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”步骤2:创建翻页循环1)系统自动打开网页,进入微博页面。
在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
将当前微博页面下拉至底部,出现“正在加载中,请稍后”的字样。
等待约2秒,页面会有新的数据加载出来。
经过2次下拉加载,页面达到最底部,出现“下一页”按钮微博爬虫采集数据方法图3“打开网页”步骤涉及Ajax下拉加载。
打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“4次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”微博爬虫采集数据方法图4注意,这里的滚动次数、间隔时间,需要针对网站进行设置,可根据相关功能点教程进行学习:八爪鱼7.0教程——AJAX滚动教程八爪鱼7.0教程——AJAX点击和翻页教程/tutorial/ajaxdjfy_7.aspx?t=12)将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”微博爬虫采集数据方法图5此步骤同样涉及了Ajax下拉加载。
打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“4次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”微博爬虫采集数据方法图6步骤3:创建列表循环1)移动鼠标,选中页面里的第一条微博链接。
选中后,系统会自动识别页面里的其他相似链接。

2018年2月基于网络爬虫的新浪微博数据分析网站的建立赖敬之(东南大学信息科学与工程学院,江苏南京211189)【摘要】新浪微博作为国内最大的社交网站,蕴含着丰富的信息。
本文实现了一个微博数据分析网站,该网站的后端利用爬虫实时抓取数据并存储到redis 数据库中,前端利用ajax 轮询技术和数据可视化技术将统计分析后的数据展示到网页。
相对于直接调用新浪微博的API ,网络爬虫获取数据的方式有更大的灵活性,可以获取到的数据也相对较多,但是也存在一些限制,其中最大的阻碍就是新浪微博的反爬虫技术,本文也将对如何突破反爬虫限制进行探讨。
【关键词】新浪;爬虫;数据分析【中图分类号】TP391.3【文献标识码】A 【文章编号】1006-4222(2018)02-0073-021引言新浪微博,是一种以关注分享为模式的新兴社交媒体,其内容少、发布快、形式多样正好迎合了人们对信息实时的、准确的、多样的分享交流需求,因此受到广大用户的欢迎与喜爱,而微博本身一跃成为当代互联网领域新兴、火热的明星。
人们热衷在微博上获取最新资讯,表达自己观点,分享喜爱的事物。
因此,微博上蕴含了丰富的数据,具有重要的数据挖掘意义。
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
使用爬虫,可以方便、自动的获取海量数据,灵活性高。
本文首先介绍了新浪微博数据分析网站的整体思路,然后介绍如何使用爬虫获取新浪微博的数据,其中也对使用的反爬虫技术进行了介绍,最后本文探讨了如何将数据实时展示到前端,并对可视化的方法逐一进行了展示。
2整体架构整个网站分为三大部分:微博数据的爬取,微博数据存储,微博数据的展示,它们的关系如图1所示。
用户首先在前端输入需要爬取微博的URL 地址和cook ⁃ie ,点击开始爬取后,后端会向爬虫服务器发出一个启动爬虫请求,并把用户传入的cookie 当作redis 数据的键,把爬取的数据存入redis 数据库中。

微博爬虫研究与实现作者:范巍来源:《硅谷》2013年第22期摘要研究了微博爬虫程序的4个关键模块:模拟登录、页面抓取、页面解析、任务调度。
介绍了模拟登录的三种方法,通过账号密码登录、使用Cookie登录、使用第三方账号登录,并且探讨了三者登录方法的优缺点。
探讨了HTMLParser和正则表达式在解析微博页面时的运用方法和原则。
提出了微博搜索爬虫的任务调度基本算法并且在此基础上进行改进增加了任务调度优化算法。
在这些研究的基础上实现了一个微博搜索爬虫程序,该程序可以针对新浪微博和搜狐微博经关键词搜索的页面进行爬取。
关键词微博;搜索;爬虫;模拟登录中图分类号:TP309 文献标识码:A 文章编号:1671-7597(2013)22-0054-012006年,美国网站“Twitter”推出了微博客服务,Twitter作为一个边缘项目诞生。
2009年8月新浪推出微博产品,使用人数迅速增长,是目前最有影响力和最受关注的微博网站。
微博使用的人数越来越多影响越来越大,微博为反腐、揭露社会恶行、声张正义提供了良好的渠道,然而微博仅仅是一个工具,好人可以用它做好事,坏人也可能用它做坏事。
微博中不乏一些仇视社会的人或反动分子散步谣言蛊惑大众,影响社会稳定和谐。
因此有必要对微博中的敏感内容进行监控,及时掌握舆情动态做到早发现早纠正。
1 微博爬虫的结构和流程首先管理中心发布配置文件,任务调度模块读取配置文件并开启多个线程调用页面抓取模块,页面抓取模块首先模拟登录微博网站,然后从微博服务器端获取页面源代码,之后交给页面解析模块解析入库。
去重模块维护一个去重数据库,去重数据库中存储已爬取的最新微博的时间,任务调度模块根据该数据就可以避免重复爬取,页面解析模块也可以避免重复解析。
2 模拟登录搜狐微博的搜索页面只有用户登录之后才可以访问,因此如果不模拟登录爬虫程序虽然访问了正确的URL但是仍然爬不到想要的内容。
新浪微博的搜索页面虽然不需要登录就可以访问,但是新浪微博的搜索页面有访问频率限制机制,每个账号平均30s访问一次,超过这个频率就会返回验证码,通过使用多个账号可以提高爬取效率,而这也需要模拟登录。

python爬虫500条案例
以下是一些Python爬虫的案例,每个案例都可以爬取500条数据:1. 爬取豆瓣电影Top250的电影信息,包括电影名称、评分、导演和主演等信息。
2. 爬取知乎某个话题下的问题和回答,包括问题标题、回答内容和回答者信息等。
3. 爬取新浪微博某个用户的微博内容和点赞数,包括微博正文、发布时间和点赞数等。
4. 爬取天猫某个品牌的商品信息,包括商品名称、价格、销量和评价等。
5. 爬取百度百科某个词条的内容和参考资料,包括词条简介、基本信息和参考链接等。
6. 爬取中国天气网某个城市的天气情况,包括当前天气、未来七天的天气预报和空气质量等。
7. 爬取微信公众号某个账号的文章信息,包括文章标题、发布时间和阅读量等。
8. 爬取京东某个商品分类下的商品信息,包括商品名称、价格、评论数和销量等。
9. 爬取猫眼电影某个地区的电影票房排行榜,包括电影名称、票房和上映时间等。
10. 爬取汽车之家某个车型的用户评价,包括评价内容、评分和用户信息等。
以上只是一些常见的爬虫案例,你可以根据自己的兴趣和需求,选择合适的网站和数据进行爬取。
注意,在进行爬虫时要遵守网站的相关规定,避免对网站造成过大的负担。

基于网络爬虫的新浪微博数据获取方式研究作者:吕鹏辉来源:《电脑知识与技术》2017年第33期摘要:随着Web2.0时代的到来,微博正逐步成为公共信息传播的主流媒体,如何高效率地获取完整的微博数据显得极为重要。
该文以新浪微博的评论内容为研究对象,利用模拟登录[1]下网络爬虫、调用新浪微博API[2]以及通过微博手机版[3]中接口等三种方式进行数据采集,对比采集速率以及采集到的内容。
实验表明,在采集微博评论时可以使用新浪微博API获取关注用户最新微博ID,使用模拟登录的方式针对这些ID获取对应微博评论,在保证数据完整性的前提下实现了采集速率的最大化。
关键词:模拟登录;微博API;网络爬虫;数据采集中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)33-0009-041 概述21世纪是移动互联网迅猛发展的世纪,Facebook 、Twitter、新浪微博等一系列社交网络应运而生,使得人们获取信息的方式有了翻天覆地的变化。
同时,随着社交网络的用户量急剧增长,以交友、信息共享为目的的社交网络[4]迅速成为人们阐述观点、传播信息、推广营销的理想平台,因此,越来越多的研究人员参与其中来进行多方面内容的研究。
根据《第39次中国互联网络发展状况统计报告》中的数据显示,截止2016年12月,我国网民规模达7.31亿,相当于欧洲人口总量,互联网普及率达到53.2%。
中国互联网行业整体向规范化、价值化发展,同时,移动互联网推动消费模式共享化、设备智能化和场景多元化。
国内移动大数据服务商QuestMobile发布2016年度报告——“2016年度App价值榜”,数据显示,2016年12月,微博月活跃用户数再次实现46%的增长,在所有App中排名第8位,其中高价值用户比例高达76.3%,因此,微博数据研究是非常有意义的。
如何高效并准确地从社交网络中将所需要的信息检索出来十分重要,本文以新浪微博评论数据作为实验研究对象,所涉及实验均在Java语言环境下实现。

2019年第6期信息与电脑China Computer & Communication软件开发与应用基于Python 的微博情感分析系统设计王 欣 周文龙(武汉工程大学邮电与信息工程学院,湖北 武汉 430073)摘 要:微博是当今公众传播信息的主要媒介之一,获取和分析微博数据能帮助研究者及时了解舆情信息。
笔者以Python 语言在网络爬虫和情感分析中的应用为基础,提出了一种微博情感简易分析方案,并建立了一个完整的微博情感分析过程。
首先,应用Python 语言采集微博中需要调查的相关关键词;其次,使用SnowNLP 包对该数据进行情感分析并转换为数值和图像;最后,得出相关关键词之间的支持情况。
关键词:情感分析;微博;Python;SnowNLP中图分类号:TP393.092;TP181 文献标识码:A 文章编号:1003-9767(2019)06-076-03Design of Micro-blog Emotion Analysis System Based on PythonWang Xin, Zhou Wenlong(The College of Post and Telecommunication of WIT, Wuhan Hubei 430073, China)Abstract: Microblog is one of the main media for the public to disseminate information nowadays. Obtaining and analyzingmicroblog data can help researchers understand public opinion information in time. Based on the application of Python language in web crawler and emotional analysis, the author puts forward a simple emotional analysis scheme of micro-blog, and establishes a complete emotional analysis process of micro-blog. Firstly, we use Python language to collect the relevant keywords in microblog.Secondly, we use SnowNLP package to analyze the data and convert it into data and images. Finally, we get the support among the relevant keywords.Key words: emotional analysis; micro-blog; Python; SnowNLP0 引言文本情感分析(又称意见发掘、倾向分析等)指分析、处理、归纳和推理带有情感色彩的主观性文本的过程[1]。

毕业论文-基于Python的网络爬虫设计基于Python的网络爬虫设计一、引言网络爬虫是一种自动化的网页访问工具,可以按照预设的规则和目标从互联网上抓取数据。
Python作为一种功能强大的编程语言,因其易学易用和丰富的库支持,成为了网络爬虫设计的理想选择。
本文将探讨基于Python的网络爬虫设计,包括其基本原理、设计思路和实现方法。
二、网络爬虫的基本原理网络爬虫的基本原理是模拟浏览器对网页的访问行为。
它通过发送HTTP请求获取网页内容,然后解析这些内容并提取所需的数据。
爬虫在访问网页时需要遵守一定的规则,如避免重复访问、遵守Robots协议等。
三、基于Python的网络爬虫设计在Python中,有许多库可以用于网络爬虫的设计,如BeautifulSoup、Scrapy和Requests等。
以下是一个简单的基于Python的爬虫设计示例:1.安装所需的库:使用pip安装Requests和BeautifulSoup库。
2.发送HTTP请求:使用Requests库发送HTTP请求,获取网页内容。
3.解析网页内容:使用BeautifulSoup库解析网页内容,提取所需的数据。
4.数据存储:将提取到的数据存储到数据库或文件中,以供后续分析和利用。
四、案例分析:爬取某电商网站商品信息本案例将演示如何爬取某电商网站商品信息。
首先,我们需要确定爬取的目标网站和所需的数据信息。
然后,使用Requests 库发送HTTP请求,获取网页内容。
接着,使用BeautifulSoup 库解析网页内容,提取商品信息。
最后,将商品信息存储到数据库或文件中。
五、总结与展望基于Python的网络爬虫设计可以为我们的数据获取和分析提供便利。
然而,在设计和实现爬虫时需要注意遵守规则和避免滥用,尊重网站所有者的权益。
未来,随着互联网技术的发展和数据价值的提升,网络爬虫技术将会有更多的应用场景和发展空间。
我们可以期待更多的技术和工具的出现,以帮助我们更高效地进行网络爬虫的设计和实现。

新浪微博用户爬虫方法本文介绍使用八爪鱼爬虫软件采集微博用户信息的方法。
作为一个活跃的社交网路平台,微博具有大量用户,每个用户信息都十分有价值。
将需要的用户信息采集下来,对我们分析某项微博活动、某个微博事件极有助益。
本文将以采集关注某个博主的用户群体为例。
这些用户群体,我们一般称之为粉丝采集网站:https:///kaikai0818?topnav=1&wvr=6&topsug=1&is_hot=1本文仅以采集关注某个博主的用户群体为例。
微博上博主众多,大家可根据自身需要,更换不同博主的粉丝群体。
也可以通过其他渠道或页面,采集微博用户信息。
本文采集的粉丝群体字段为:粉丝ID、粉丝主页URL、关注人数、关注页URL、粉丝数、粉丝页URL、微博数、微博数URL、地址、简介、关注方式、光柱方式URL本文的采集分为两大部分:微博登录和粉丝信息采集一、微博登录二、某博主粉丝信息采集使用功能点:●文本输入登录方法(7.0版本)/tutorialdetail-1/srdl_v70.html●cookie登陆方法(7.0版本)/tutorialdetail-1/cookie70.html●AJAX滚动教程/tutorialdetail-1/ajgd_7.html●八爪鱼7.0教程——AJAX点击和翻页教程/tutorialdetail-1/ajaxdjfy_7.html一、微博登录步骤1:创建采集任务1)进入主界面,选择“自定义模式”,点击“立即使用”2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”步骤2:登录微博1)系统自动打开网页,进入微博首页。
在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击“登录”按钮,选择“循环点击该链接”,进入微博登录页面2)点击账号输入框,选择“输入文字”输入账号,点击“确定”3)点击密码输入框,选择“输入文字”输入密码,点击“确定”4)点击“登录”按钮,选择“点击该链接”5)系统会自动登录微博6)再次选中“打开网页”步骤,打开“高级选项”,打开“缓存设置”,勾选“打开网页时使用指定Cookie”点击如图位置,可查看此网页的Cookie7)八爪鱼会记住这个cookie状态,下次打开这个页面的时候,就会以登陆之后的状态打开注意:由于cookie是有生命周期的,这个周期多长时间取决于采集的网站。

28个python爬⾍项⽬,看完这些你离爬⾍⾼⼿就不远了互联⽹的数据爆炸式的增长,⽽利⽤ Python 爬⾍我们可以获取⼤量有价值的数据:1.爬取数据,进⾏市场调研和商业分析爬取知乎优质答案,筛选各话题下最优质的内容;抓取房产⽹站买卖信息,分析房价变化趋势、做不同区域的房价分析;爬取招聘⽹站职位信息,分析各⾏业⼈才需求情况及薪资⽔平。
2.作为机器学习、数据挖掘的原始数据⽐如你要做⼀个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。
3.爬取优质的资源:图⽚、⽂本、视频爬取商品(店铺)评论以及各种图⽚⽹站,获得图⽚资源以及评论⽂本数据。
掌握正确的⽅法,在短时间内做到能够爬取主流⽹站的数据,其实⾮常容易实现。
但建议你从⼀开始就要有⼀个具体的⽬标,在⽬标的驱动下,你的学习才会更加精准和⾼效。
这⾥给你⼀条平滑的、零基础快速⼊门的学习路径:1.了解爬⾍的基本原理及过程2.Requests+Xpath 实现通⽤爬⾍套路3.了解⾮结构化数据的存储4.应对特殊⽹站的反爬⾍措施5.Scrapy 与 MongoDB,进阶分布式下⾯给⼤家展⽰⼀些爬⾍项⽬:有些项⽬可能⽐较⽼了,不能⽤了,⼤家可以参考⼀下,重要的是⼀个思路,借鉴前⼈的⼀些经验,希望能帮到⼤家(1)微信公众号爬⾍地址:https:///Chyroc/WechatSogou基于搜狗微信搜索的微信公众号爬⾍接⼝,可以扩展成基于搜狗搜索的爬⾍,返回结果是列表,每⼀项均是公众号具体信息字典。
(2)⾖瓣读书爬⾍地址:https:///lanbing510/DouBanSpider可以爬下⾖瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可⽅便⼤家筛选搜罗,⽐如筛选评价⼈数>1000的⾼分书籍;可依据不同的主题存储到Excel不同的Sheet ,采⽤User Agent伪装为浏览器进⾏爬取,并加⼊随机延时来更好的模仿浏览器⾏为,避免爬⾍被封。

使用Python网络爬虫进行社交媒体舆情监测与分析社交媒体已成为人们获取信息、表达观点和进行互动的重要平台。
企业、政府和个人都对社交媒体上的舆情关注倍增,希望了解公众对于特定话题的看法和反应,以便作出相应的决策。
为了高效地进行社交媒体舆情监测与分析,Python网络爬虫成为一种有效的工具。
本文将介绍使用Python网络爬虫进行社交媒体舆情监测与分析的方法和步骤。
一、准备工作在开始使用Python网络爬虫进行社交媒体舆情监测与分析之前,我们需要准备一些基本的工具和素材。
首先,我们需要安装Python编程语言的开发环境,并确保环境的稳定和可靠。
其次,我们需要了解目标社交媒体平台的数据结构和访问接口。
每个平台都提供一定的API接口供开发者使用,我们可以通过API接口来获取所需的数据。
最后,我们还需要一些相关的库和模块,如Requests、BeautifulSoup等。
二、数据抓取数据抓取是使用Python网络爬虫进行社交媒体舆情监测与分析的第一步。
在这个过程中,我们需要使用Python编写脚本,通过API接口或者直接模拟用户访问,获取到所需的数据。
而后,我们可以选择将数据保存到本地文件或者直接存储到数据库中。
三、数据清洗与处理获取到的社交媒体数据通常存在一些冗余和噪声,这会对后续的舆情分析造成影响。
因此,数据清洗与处理至关重要。
我们可以使用Python的数据处理库,如Pandas和NumPy等,对数据进行清洗、筛选和重构。
在这个过程中,我们可以去除重复数据、删除无用信息、转换日期格式等。
四、舆情分析在清洗和处理数据之后,我们可以进行舆情分析。
舆情分析是指对获取到的社交媒体数据进行定量和定性的分析,以获取对特定话题的观点、情绪和趋势等信息。
这一步骤中,我们可以借助Python中的文本分析和情感分析库,如NLTK、TextBlob等,进行舆情分析。
五、可视化展示舆情数据的可视化展示是对舆情分析结果的直观呈现。
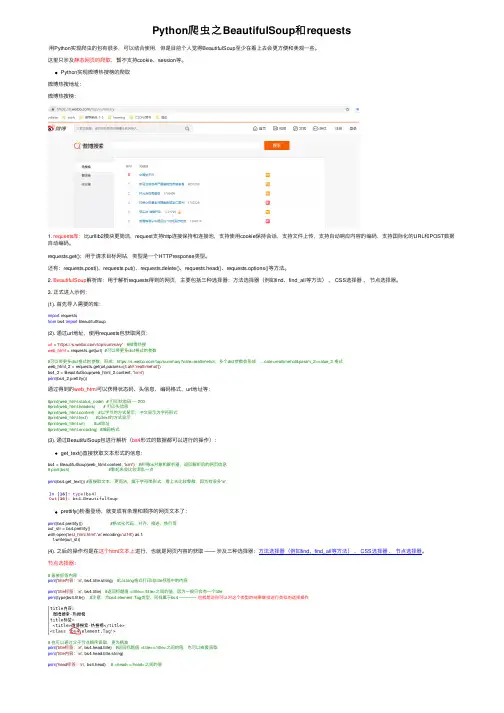
Python爬⾍之BeautifulSoup和requests⽤Python实现爬⾍的包有很多,可以结合使⽤,但是⽬前个⼈觉得BeautifulSoup⾄少在看上去会更⽅便和美观⼀些。
这⾥只涉及静态⽹页的爬取,暂不⽀持cookie、session等。
Python实现微博热搜榜的爬取微博热搜地址:微博热搜榜:1. requests库:⽐urllib2模块更简洁,request⽀持http连接保持和连接池,⽀持使⽤cookie保持会话,⽀持⽂件上传,⽀持⾃动响应内容的编码,⽀持国际化的URL和POST数据⾃动编码。
requests.get():⽤于请求⽬标⽹站,类型是⼀个HTTPresponse类型。
还有:requests.post()、requests.put()、requests.delete()、requests.head()、requests.options()等⽅法。
2. BeautifulSoup解析库:⽤于解析requests得到的⽹页,主要包括三种选择器:⽅法选择器(例如find、find_all等⽅法)、 CSS选择器、节点选择器。
3. 正式进⼊⽰例:(1). ⾸先导⼊需要的库:import requestsfrom bs4 import BeautifulSoup(2). 通过url地址,使⽤requests包获取⽹页:url = 'https:///top/summary'#微博热搜web_html = requests.get(url) #可以带更多dict格式的参数#可以带更多dict格式的参数,形成:https:///top/summary?cate=realtimehot,多个dict参数会形成:...cate=realtimehot¶m_2=value_2 格式web_html_2 = requests.get(url,params={'cate':'realtimehot'})bs4_2 = BeautifulSoup(web_html_2.content, 'lxml')print(bs4_2.prettify())通过得到的web_html可以获得状态码、头信息、编码格式、url地址等:#print(web_html.status_code) # 打印状态码 --- 200#print(web_html.headers) # 打印头信息#print(web_html.content) #以字节的⽅式显⽰,中⽂显⽰为字符形式#print(web_html.text) #以text的⽅式显⽰#print(web_html.url) #url地址#print(web_html.encoding) #编码格式(3). 通过BeautifulSoup包进⾏解析(bs4形式的数据都可以进⾏的操作):get_text()直接获取⽂本形式的信息:bs4 = BeautifulSoup(web_html.content, 'lxml') #声明bs对象和解析器,返回解析后的⽹页信息# print(bs4) #看起来会⽐较混乱⼀点print(bs4.get_text()) #直接取⽂本,更简洁,属于字符串形式,看上去⽐较零散,因为有很多'\n'prettify()粉墨登场,就变成有条理和顺序的⽹页⽂本了:print(bs4.prettify()) #格式化代码,对齐、缩进、换⾏等out_str = bs4.prettify()with open('test_html.html','w',encoding='utf-8') as f:f.write(out_str)(4). 之后的操作均是在这个html⽂本上进⾏,也就是⽹页内容的获取——涉及三种选择器:⽅法选择器(例如find、find_all等⽅法)、 CSS选择器、节点选择器。
毕业论文-基于Python的网络爬虫设计引言网络爬虫是指通过程序自动化的方式获取互联网上的信息,并将其存储或进行进一步处理的技术手段。
随着互联网的快速发展,网络爬虫在各行各业中的应用越来越广泛,涉及到数据采集、搜索引擎、电子商务等众多领域。
本篇论文旨在设计一个基于Python的网络爬虫,通过该爬虫能够从目标网站上获取所需的数据并进行相应的处理。
本文将介绍网络爬虫的基本原理、Python相关的爬虫库以及本文的设计方案和实现过程。
1. 概述本部分将简要介绍本文所设计的基于Python的网络爬虫的目标和功能。
该网络爬虫旨在实现以下功能: - 从指定的网站上获取数据; - 对获取的数据进行处理和分析; - 将处理后的数据存储到数据库中。
2. 网络爬虫的基本原理本部分将介绍网络爬虫的基本工作原理。
网络爬虫主要分为以下几个步骤: - 发送HTTP请求获取指定网页的HTML代码; - 解析HTML代码,提取所需的数据; - 对提取的数据进行处理和分析; - 存储处理后的数据。
3. Python相关的爬虫库本部分将介绍Python中常用的爬虫库,包括但不限于以下几个库: - Requests:用于发送HTTP请求并获取响应; - Beautiful Soup:用于解析HTML代码并提取所需的数据; - Scrapy:一个功能强大的网络爬虫框架,可以加速爬虫的开发和运行; - Selenium:用于模拟浏览器操作,可以解决JavaScript渲染的问题。
4. 设计方案和实现过程本部分将详细介绍本文所设计的基于Python的网络爬虫的具体方案和实现过程。
主要包括以下几个步骤: 1. 确定目标网站和爬取的数据类型; 2. 使用Requests库发送HTTP请求并获取网页的HTML代码; 3. 使用Beautiful Soup解析HTML代码并提取所需的数据; 4. 对提取的数据进行处理和分析,可以使用Python的数据处理库如Pandas等; 5. 将处理后的数据存储到数据库中,可以选用MySQL、MongoDB等数据库。
基于Python的新浪微博爬虫研究
作者:吴剑兰
来源:《无线互联科技》2015年第06期
摘要:对比新浪提供的API及传统的爬虫方式获取微博的优缺点,采用模拟登陆和网页解析技术,将获取的信息存入数据库中并进行分析。
基于Python设计实现了新浪微博爬虫程序,可以根据指定的关键词获取相应的微博内容及用户信息。
关键词:新浪微博;Python;爬虫
0 引言
自2009年8月新浪推出微博业务以来,微博逐渐地进入人们的日常生活中。
越来越多的人开始加入到社交网络中,与他人互动。
继新浪之后,腾讯、网易等也相继推出微博业务,但新浪做为国内微博界的“元老”,仍是广泛受到人们的欢迎。
如今,新浪微博用户已达5亿多人。
随着使用人数的直线上升,带来的是信息量的急剧膨胀。
每天都有数以万计的信息在奔流。
微博通过点赞,转发,评论功能将个人的声音快速放大到社会空间,将个人的行为放大成为社会行为。
作为网络新媒体的代表,微博用户产生的大量微博数据以及用户之间的互粉,转发等关系作为真实社会关系的一种写照,为社会网络研究提供了绝佳的研究数据。
基于微博的数据研究已成为当今社会科学和计算机科学研究的重点。
1 新浪API
API接口使用较为方便,通过一个接口就可以很方便得获取所需的信息,而无须了解具体实现过程。
但是新版的新浪API接口却有着很大的限制。
最主要的一点,如果要想获得某人的微博个人信息和发表的微博内容,就必须得到对方的授权许可。
新浪API使用OAuth2.0授权机制。
授权流程如图1所示。
其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,ResourceServer是API月艮务器。
首先应用需要先引导用户到某个地址,用户授权后得到access token,然后使用获取的access token来调用API,以此来得到用户的信息和微博的内容。
Access_token相当于是令牌,持有相应的令牌才能得到所需。
除此以外,access token还有授权有效期,对于测试应用来说只有一天的时间。
除了这些限制外,新浪API针对一个用户在使用一个应用的请求次数上还有限制。
对于测试授权来说,单个用户每个应用每小时只能请求150次。
这对于爬取微博信息来说是不够的。
正因为有如此诸多的不便,尽管API的实现对开发者是透明的,但笔者仍决定采用传统的模拟登陆方法,然后通过分析网页源代码来获取信息。
2 模拟登陆
新浪微博的内容只有在登陆后才可以获取。
通过firefox+httpfox分析网页版微博登陆方式可以发现主要分为+步骤:(1)浏览器向新浪的服务器发送了一个GET请求报文,用于获取servertime,nounce字段,这两个字段是随机字段,每次登陆都不相同,用于加密用户名和密码;(2)用BASE64算法加密用户名,用RSA算法加密密码,向登陆URL发送包含加密后的用户名和密码的POST请求;(3)新浪服务器收到请求后与信息库进行比对,如果比对成功则发送一条含重定向的应答报文,浏览器解析得到最终跳转到的URL,打开该URL后,自动将该信息写入COOKIES,登陆成功。
3 网页分析
以新浪官方的搜索平台为搜索入口,输入关键词后,构造相应url。
分析网页源代码,可以发现页面上的所有微博内容都在以
由此可见,存储在服务器上的源文件是“原生”的,而用户在浏览时,后台通过Javascript 程序处理这部分代码,将其生成xml格式代码,进而交给浏览器去解析。
Python的第三方库BeautifulSoup/lxml是Python的html/Xml解析器,可以很好地处理不规范的标记并生成剖析树。
Lxml库支持XPath规范,XPath是一种在xml文档中查找信息的语言,用于在xml文档中通过元素的属性进行导航,利用XPath可以方便在html文档中定位感兴趣的节点。
仔细观察可以发现,每条微博都以
作为起始,而其中的节点含有昵称,
节点含有微博内容,以此类推可以得到时间,转发数,评论数等信息。
对于获取微博用户个人的信息,也是使用与此相类似的方法。
通过分析用户个人主页的源代码,可以得到UID,和Page-id。
Page-id用于构建指向用户个人信息的URL地址,其格式为:’http:///p/’+page id+’/info’。
此即为要进行分析的URL地址。
对于获取用户发表的微博这块,有一个难点。
在使用浏览器浏览用户发表的微博时,一开始不会将一页上的所有微博都显示出来,而是当滚动到底部时自动加载,如此滚动加载两次才
能把一页上的微博都显示出来。
获取得到的网页源代码同样也是不完整的,只含有每页的前十条左右,必须进行手动滚动才能显示完整。
因此,可以采用发送HTTP请求的GET方法,构建相应的URL来模拟这一滚动过程。
4 关键词的提取
这个爬虫程序还有一个可以对爬取到的微博内容进行分析,提1取关键词的功能。
使用TF-IDF算法来实现。
TF-IDF算法的思想如下:为了提取关键词,一个容易想到的思路就是找到出现次数最多的词。
如果某个词很重要,它应该在其中多次出现,于是,进行“词频”(TF)统计。
但是,出现次数最多的词是“的”“是”“在”这一类词,这些词叫做“停用词”,对结果没有帮助,需要过滤掉。
过滤掉之后,可能会有多个词出现的次数一样多,但这并不意味着这些词的关键性是一样的。
因此,还需要一个重要性调整系数来衡量一个词是不是常见词。
如果某个词比较少见,但是它在其中多次出现,那么它就可能就是我们需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个“重要性”权重。
最常见的词给予最小的权重,较常见的词给予较小的权重,较少见的词给予较大的权重。
这个权重叫做“逆文档频率”(IDF),它的大小与一个词的常见程度成反比。
知道了“词频”(TF)和“逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。
某个词对文章的重要性越高,它的TF-IDF值就越大。
所以,排在最前面的几个词,就是关键词。
根据这一算法思想,爬虫程序可以根据爬取的一系列微博条目,获得这些条目的关键词。
5 结语
文章分析了新浪API的一些认证限制,新版的API需要被搜索用户提供相应的授权,因此采用传统爬虫的方式。
然后模拟登陆、网页分析、关键词提取等三个方面介绍了如何爬取新浪微博信息,研究用户登陆微博的过程,从网页源代码中构造利于分析的DOM树并提取所需信息,运用TF-IDF算法获取微博集中的关键词,最终实现了一个基于Python的新浪微博爬虫程序。