新浪微博分布式爬虫系统简介
- 格式:pptx
- 大小:326.95 KB
- 文档页数:12

基于Android系统的新浪微博客户端的设计与实现作者:王明超来源:《电脑知识与技术》2012年第33期摘要:该系统基于Android移动开发平台,使用Java语言开发,使系统具有良好的平台移植性和可扩展性。
新浪微博Android SDK为第三方微博应用提供了文档易用的微博API调用服务,使第三方微博客户端无需了解复杂的验证和API调用过程,就可以实现分享文字或者多媒体信息到新浪微博。
本系统包括四个模块:应用程序登录模块,主界面显示模块,微博浏览模块,用户模块。
在登录模块,用户可以使用授权配置和用户注册并且登录系统。
关键词:新浪微博开放平台;授权配置;微博API调用服务中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2012)33-7933-03每一个时代都会催生新的理念,每一个理念又会引领新的潮流,每一个潮流又注定会冲破原有的桎梏,创新是时代的特征,更是IT业的标志。
摩尔定律的持续实现使整个IT业的发展和更新令人手忙脚乱,而作为终端设备中数量级最大的手机,近年更是近乎脱胎换骨,在颠覆传统手机概念的同时,不断挖掘着自身的市场价值,也成为众多厂商利益角逐的角斗场[1]。
IOS在乔布斯的精心策划下一路高歌猛进,Android则凭着开源的方式开山劈路,Symbian和Black berry的旧有模式被不断蚕食,Windows Phone则在滞后的泥潭中继续挣扎。
手机终端多样化应用的不断出现,使其在近乎实现PC端功能的同时,也影响着PC的发展。
互联网领域,以Facebook为代表的SNS的突起更是激起新一轮的网络风波,而在国内,冲破众堵的新浪在其准确的定位和成功的推广策略下推出的新浪微博更是占据了先导地位,并逐渐进入大众生活,成为许多人的生活必需品。
近年来,新浪微博的邀请重点由明星、名人转向媒体工作者甚至政府工作者,为时事的发布和民政工作提供了更为多样、便捷的方式[2]。
于是,新浪微博手机客户端便应运而生,而作为市场占有率第一的Android平台下的新浪微博客户端更是拥有广泛的需求。


找工作也快两月了,感受颇多,最近看了一篇《怎样花两年时间去面试一个人》的博客,很有感触,将自己的想法写出来。
在找工作的两月中,自己从四大门户:新浪、搜狐、网易、腾讯到业界领先的百度,搜狗、淘宝以及行业巨头的微软;从几个人创业的阿甘网到几十个人美丽说、友录、微游半创业公司;从做浏览器的opera 到石油设备的哈里伯顿、斯伦贝谢到咨询的ThoughtWorks再到做游戏的金山网游,如果加上一些想不起的公司名,面试有二三十家,再加上一倍以上的笔试。
北京带“网”字的公司几乎被过了一圈。
从这一圈的经验,通过现在互联网公司招聘的漏洞,总结出一些可以在两月的时间内得到一家顶级互联网公司的offer的经验。
简单来说,成功100分的话,得分组成比例可以如下:1、50分的算法和C语言,2、15分的项目分,3、15分的知识面和扯淡分,4、10分的开发语言细节分,5、5分的其他。
首先很赞同文首博客中的观点,在短短的几轮面试以及校园招聘意义不大的一轮笔试,想选取一个人是很困难的,而且还很容易漏掉一些有实力的人,我敢保证连IDE都没启动过而进入顶级互联网公司的同学不在少数,不是怀疑这些同学的能力,只是说招这些同学对公司来说是一个极大的风险,纸上的程序永远不能变成产品,而且纸上写程序发现不了真正的问题,我加入的一些技术群中,一些我仰慕公司的员工不懂得求助百度,只会一有问题就摆到群上,让人作答,甚至有些工作相当时间的人不懂得如何断点调试。
好了,切入正题50分的算法和C语言题:假入你这两个比较好(非超牛),那么你就有50%以上的机会进入心仪的互联网公司,现在的校园招聘笔试和面试,不分公司和部门都是一窝蜂的考这两项,其实对于应届生来说,没有履历,没有工作对口方向知识的积累,而用人单位为了省事,经常就一套题,所以有不少想做前端的同学去忍受C指针和算法的折磨。
假如您的C语言不好,问题不大,翻出谭浩强的那个工科生必修的C教材,看了两个礼拜足够。

微博爬虫一天可以抓取多少条数据微博是一个基于用户关系信息分享、传播以及获取的平台。
用户可以通过WEB、WAP等各种客户端组建个人社区,以140字(包括标点符号)的文字更新信息,并实现即时分享。
微博作为一种分享和交流平台,十分更注重时效性和随意性。
微博平台上产生了大量的数据。
而在数据抓取领域,不同的爬虫工具能够抓取微博数据的效率是质量都是不一样的。
本文以八爪鱼这款爬虫工具为例,具体分析其抓取微博数据的效率和质量。
微博主要有三大类数据一、博主信息抓取采集网址:/1087030002_2975_2024_0采集步骤:博主信息抓取步骤比较简单:打开要采集的网址>建立翻页循环(点击下一页)>建立循环列表(直接以博主信息区块建立循环列表)>采集并导出数据。
采集结果:一天(24小时)可采集上百万数据。
微博爬虫一天可以抓取多少条数据图1具体采集步骤,请参考以下教程:微博大号-艺术类博主信息采集二、发布的微博抓取采集网址:采集步骤:这类数据抓取较为复杂,打开网页(打开某博主的微博主页,经过2次下拉加载,才会出现下一页按钮,因而需对步骤,进行Ajax下拉加载设置)>建立翻页循环(此步骤与打开网页步骤同理,当翻到第二页时,同样需要经过2次下来加载。
因而也需要进行Ajax下拉加载设置)>建立循环列表(循环点击每条微博链接,以建立循环列表)>采集并导出数据(进入每条微博的详情页,采集所需的字段,如:博主ID、微博发布时间、微博来源、微博内容、评论数、转发数、点赞数)。
采集结果:一天(24小时)可采集上万的数据。
微博爬虫一天可以抓取多少条数据图2具体采集步骤,请参考以下教程:新浪微博-发布的微博采集三、微博评论采集采集网址:https:///mdabao?is_search=0&visible=0&is_all=1&is_tag=0&profile_fty pe=1&page=1#feedtop采集步骤:微博评论采集,采集规则也比较复杂。


收稿日期:2019 11 19;修回日期:2019 12 27 基金项目:国家自然科学基金资助项目(61772081);科技创新服务能力建设—科研基地建设—北京实验室—国家经济安全预警工程北京实验室项目(PXM2018_014224_000010);国家重点研发计划课题(2018YFB1402901)作者简介:侯晋升(1994 ),男,山西太原人,硕士研究生,主要研究方向为中文信息处理;张仰森(1962 ),男(通信作者),山西运城人,教授,博导,博士(后),主要研究方向为中文信息处理、人工智能(zhangyangsen@163.com);黄改娟(1964 ),女,山西运城人,高级实验师,主要研究方向为智能信息处理;段瑞雪(1984 ),女,河北石家庄人,讲师,博士,主要研究方向为自然语言处理、意图理解、问答系统.基于多数据源的论文数据爬虫技术的实现及应用侯晋升1,张仰森1,2 ,黄改娟1,段瑞雪1,2(1.北京信息科技大学智能信息处理研究所,北京100101;2.国家经济安全预警工程北京实验室,北京100044)摘 要:在使用单个数据源进行论文数据采集的过程中,存在着数据全面性不足、数据采集速度因网站访问频率限制而受限等问题。
针对这些问题,提出了一个基于多数据源的论文数据爬虫技术。
首先,以知网、万方数据、维普网、超星期刊四大中文文献服务网站为数据源,针对检索关键词完成列表页数据的爬取与解析;然后通过任务调度策略,去除各数据源之间重复的数据,同时进行任务的均衡;最后采用多线程对各数据源进行论文详情信息的抓取、解析与入库,并构建网页进行检索与展示。
实验表明,在单个网页爬取与解析速度相同的情况下,该技术能够更加全面、高效地完成论文信息采集任务,证实了该技术的有效性。
关键词:网络爬虫;多源数据源;多线程;信息处理;数据展示中图分类号:TP391.1 文献标志码:A 文章编号:1001 3695(2021)02 037 0517 05doi:10.19734/j.issn.1001 3695.2019.11.0671ImplementationandapplicationofpaperdatacrawlertechnologybasedonmultipledatasourcesHouJinsheng1,ZhangYangsen1,2 ,HuangGaijuan1,DuanRuixue1,2(1.InstituteofIntelligentInformation,BeijingInformationScience&TechnologyUniversity,Beijing100101,China;2.NationalEconomicSecurityEarlyWarningEngineeringBeijingLaboratory,Beijing100044,China)Abstract:Therearemanyproblemsintheprocessofcollectingpaperdatausingsingledatasource,suchasinsufficientdatacomprehensivenessandlimiteddatacollectionspeedduetowebsiteaccessfrequencylimitation.Aimingattheseproblems,thispaperproposedapaperdatacrawlingtechnologyformulti datasources.Firstly,itusedthefourChinesedocumentserviceweb sites HowNet,WanfangData,Weipu,andChaoxingasdatasources,completedthetaskofcrawlingandparsinglistpagedataforthesearchkeywords.Thenitusedthetaskschedulingstrategytoremoverepeateddataandbalancethetasks.Finally,itusedmulti threadsforeachdatasourcetocrawl,parseandstorethedetailinformationofthepapers,andbuiltawebsiteforsearchanddisplay.Experimentsshowthatunderthesamecrawlingandparsingspeed,thistechnologycancompletethepaperinformationcollectiontaskmorecomprehensivelyandefficiently,whichprovestheeffectivenessofthistechnology.Keywords:Webcrawler;multipledatasource;multithreading;informationprocessing;datademonstration0 引言大数据技术从兴起之初到日益成熟,在各行各业都发挥出巨大的作用;借着大数据的东风而再一次焕发出生命力的人工智能领域近些年更是取得了一个又一个的重大突破,在科研与应用方面创造出了巨大的价值,人们逐渐意识到数据已是当下最重要的资源。

V10.0.001 0204SuperMap技术体系介绍SuperMap产品体系介绍超图集团介绍新型三维GIS技术031云原生GIS(C loud Native GIS)C 新型三维GIS(New T hree Dimension GIS)大数据GIS (B ig Data GIS)人工智能GIS (A I GIS)(2006年+)SuperMap GIS 10iEulerOSK-UXx86Power ARM MIPS SW-64龙芯申威飞腾CentOS深度中标麒麟数据库操作系统CPUUbuntu银河麒麟凝思华为鲲鹏华为欧拉普华人大金仓瀚高南大通用浪潮K-DB华为GaussDB HBasePostgreSQL MongoDBMySQLElasticsearch 阿里PolarDB达梦神舟通用湖南麒麟Android *元心*中兴*海光新云东方浪潮兆芯虚拟化技术容器化技术弹性伸缩负载均衡集群技术智能运维……四驾马车一体化分布式存储和计算微服务动态编排多云环境智能运维…云端一体化GIS产品云边端一体化GIS产品空间大数据技术经典空间数据技术分布式重构大数据GIS 技术体系…iObjects for SparkDSFiDesktop Java iServer iManager iMobileSparkSpark Streaming ElasticsearchPostgres-XL MongoDBHBaseVector Tiles TensorFlowiPortaliObjects Python……城市设计、CIM 、新型三维GIS 技术WebGL/VRBIM+GIS倾斜摄影三维分析(GPU )三维移动端三维渲染引擎二三维一体化GeoAI1AI for GIS2GIS for AI3融合AI 的帮助GIS 软件进行功能提升和完善将AI 的分析结果放到中,进行结果管理、空间可视化和分析。
2边缘GIS 服务器•SuperMap iEdge云GIS 服务器•SuperMap iServer •SuperMap iPortal •SuperMap iManagerWeb 端•SuperMap iClient JavaScript •SuperMap iClient Python•SuperMap iClient3D for WebGL移动端•SuperMap iMobile •SuperMap iTablet•SuperMap iMobile LitePC 端•SuperMap iObjects Java •SuperMap iObjects .NET •SuperMap iObjects C++•SuperMap iObjects Python •SuperMap iObjects for Spark •SuperMap iDesktopX •SuperMap iDesktop云边端10i 新增便捷易用的组件式开发平台大型全组件式GIS开发平台,提供跨平台、二三维一体化能力,适用于Java/.NET/C++开发环境。
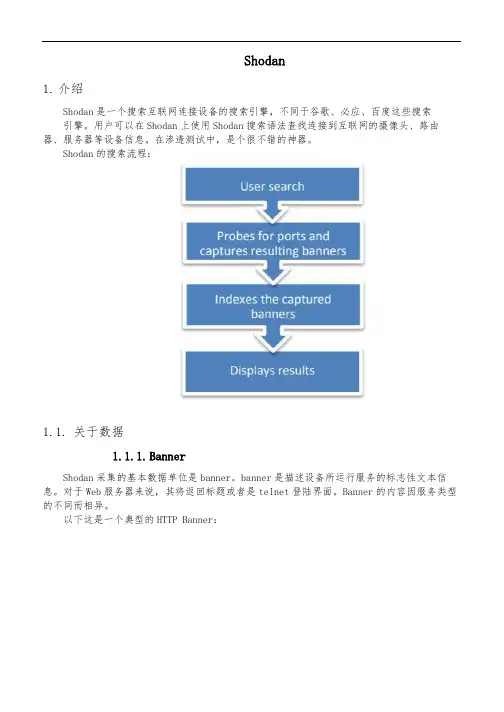
Shodan1.介绍Shodan是一个搜索互联网连接设备的搜索引擎,不同于谷歌、必应、百度这些搜索引擎。
用户可以在Shodan上使用Shodan搜索语法查找连接到互联网的摄像头、路由器、服务器等设备信息。
在渗透测试中,是个很不错的神器。
Shodan的搜索流程:1.1.关于数据1.1.1.BannerShodan采集的基本数据单位是banner。
banner是描述设备所运行服务的标志性文本信息。
对于Web服务器来说,其将返回标题或者是telnet登陆界面。
Banner的内容因服务类型的不同而相异。
以下这是一个典型的HTTP Banner:CODE: [ ]HTT 12OServer nginx 1.1.19Dat S , 0O 201002GContent Typ tex htm;charset uContent Length 646Connection kee alive上面的banner 显示该设备正在运行一个1.1.19版本的nginx Web 服务器软件下面是西门子S7工控系统协议的一个banner ,这次返回的banner完全不同,提供了大量的详细数据(有关的固件信息、序列号):CODE: [ ]Copyright Original Siemens EquipmentP nam S7_TurbineModule typ C3Unknown1)Boo LoaderModule E3BG0A.0.Basic Firmware.3.3.8Module nam C3Serial number o module D9U083642013Plant identificationBasic Hardware E3BG0A.0.注搜索的是联网设备运行服务的,不是单一的主机信息。
如果单暴露很多服务信息,在指定特定搜索内容的时候,搜索结果只会出现指定的内容,不会显示其他的服务信息。
1.1.2.设备元数据除了获取banner ,Shodan还可以获取相关设备的元数据,例如地理位置、主机名、操作系统等信息。


Pentaho Data Integration 完全自学手册(孟菲斯著)文档目录文档目录 (2)更新记录 (17)第一章.KETTLE 基础介绍 (18)1.1.核心组件 (18)1.2.组成部分 (18)1.3.概念模型 (19)1.3.1.Transformation(转换) (19)1.3.2.Steps(步骤) (20)1.3.3.Hops(节点连接) (20)1.3.4.Jobs(工作) (20)1.3.5.Variable(变量) (21)1.3.5.1.设置环境变量 (21)1.3.5.2.设置变量 (21)1.4.查看版本 (22)1.5.选项设置 (23)第二章.KETTLE 环境搭建 (25)2.1.单机部署 (25)2.1.1.下载kettle (25)2.1.2.安装kettle (25)2.1.3.运行Spoon (25)2.2.集群部署 (26)1. Carte简介 (26)2. Carte部署配置 (26)2.1 启动方法 (26)2.2 启动配置 (26)2.3 Carte xml文件配置详解 (27)2.3.1 slaveserver节点 (28)2.3.2 masters节点 (28)2.3.3 report_to_masters节点 (28)2.3.4 max_log_lines节点 (28)2.3.5 max_log_timeout_minutes节点 (28)2.3.6 object_timeout_minutes节点 (29)2.3.7 (*) repository节点 (29)3. Carte集群 (29)3.1 普通集群 (30)3.2 动态集群 (30)2.3.运行方式 (30)2.3.1.转换执行器Pan (30)2.3.1.2.Pan 实例讲解:Windows (31)2.3.1.3.Pan 实例讲解:Linux (31)2.3.2.任务执行器Kitchen (32)2.3.2.1.Kitchen 参数介绍 (32)2.3.2.2.Kitchen 实例讲解:Windows (33)2.3.2.3.Kitchen 实例讲解:Linux (34)2.4.定时任务 (35)2.4.1.Windows (35)2.4.2.Linux (35)第三章.KETTLE 基本功能 (40)3.1.新建转换 (40)3.1.1.方法1 (40)3.1.2.方法2 (40)3.1.3.方法3 (41)3.1.4.主对象树 (41)3.1.5.核心对象 (42)3.1.6.新建数据库连接 (42)3.2.转换实例 (43)3.2.1.转换实例1 (43)3.2.2.转换实例2 (43)3.3.新建作业 (44)3.3.1.方法1 (44)3.3.2.方法2 (44)3.3.3.方法3 (45)3.3.4.主对象树 (45)3.3.5.核心对象 (46)3.4.作业实例 (46)3.4.1.作业实例1 (46)3.4.2.作业实例2 (46)第四章.KETTLE 设计环境 (46)4.1.T RANSFORMATION:转换步骤(24-228) (46)4.1.1.Input:输入(38) (46)4.1.1.1.Csv file input (46)4.1.1.1.1.功能描述 (47)4.1.1.1.2.操作步骤 (47)4.1.1.1.3.实例讲解 (48)4.1.1.2.DataGrid (48)4.1.1.3.De-serialize from file:文件反序列化 (48)4.1.1.4.ESRI Shapefile Reader (48)4.1.1.5.Email messages input (48)4.1.1.6.Fixed file input (48)4.1.1.7.GZIP CSV Input (48)4.1.1.9.Generate random credit card numbers (48)4.1.1.10.Generate random value (49)4.1.1.11.Get File Names (49)4.1.1.12.Get Files Rows Count (49)4.1.1.13.Get SubFolder names (49)4.1.1.14.Get System Info:获取系统信息 (49)4.1.1.14.1.功能描述 (50)4.1.1.14.2.操作步骤 (51)4.1.1.14.3.实例讲解 (52)4.1.1.15.Get data from XML (53)4.1.1.16.Get repository names (53)4.1.1.17.Get table names (53)4.1.1.18.Google Analytics (53)4.1.1.19.HL7 Input (53)4.1.1.20.JSON Input (53)4.1.1.21.LDAP Input (53)4.1.1.22.LDIF Input (54)4.1.1.23.Load file content in memory (54)4.1.1.24.Microsoft Access input (54)4.1.1.25.Microsoft Excel Input (54)4.1.1.25.1.功能描述 (54)4.1.1.25.2.操作步骤 (54)4.1.1.25.2.1.指定文件名 (55)4.1.1.25.2.2.指定内容 (55)4.1.1.25.2.3.字段 (55)4.1.1.25.2.4.错误处理 (55)4.1.1.25.2.5.其他输出字段 (55)4.1.1.25.3.实例讲解 (55)4.1.1.26.Mondrian Input (55)4.1.1.27.OLAP Input (56)4.1.1.28.Property Input (56)4.1.1.29.RSS Input (56)4.1.1.30.S3 CSV Input (56)4.1.1.31.SAP Input (56)4.1.1.32.SAS Input (56)4.1.1.33.SalesForce Input (56)4.1.1.34.Table input:表输入 (56)4.1.1.34.1.功能描述 (56)4.1.1.34.2.操作步骤 (57)4.1.1.34.3.实例讲解 (58)4.1.1.35.Text file input:文本文件输入 (58)4.1.1.35.1.功能描述 (58)4.1.1.35.2.操作步骤 (58)4.1.1.35.2.2.从先前的步骤中接受文件名 (59)4.1.1.35.2.3.内容指定 (59)4.1.1.35.2.4.错误处理 (62)4.1.1.35.2.5.过滤 (63)4.1.1.35.2.6.字段 (64)4.1.1.35.2.7.其他输出字段 (65)4.1.1.35.3.格式化 (65)4.1.1.35.3.1.Number格式化 (65)4.1.1.35.3.2.Date格式化 (66)4.1.1.35.3.3.其它 (66)4.1.1.35.4.实例讲解 (67)4.1.1.36.XBase input:XBase输入 (67)4.1.1.36.1.功能描述 (67)4.1.1.37.XML Input Stream(StAX) (67)4.1.1.37.1.功能描述 (67)4.1.1.38.Yaml Input (69)4.1.2.Output:输出(22) (69)4.1.2.1.Automatic Documentation Output (69)4.1.2.2.Delete:删除 (69)4.1.2.2.1.功能描述 (69)4.1.2.2.2.操作步骤 (69)4.1.2.3.Insert / Update:插入/更新 (70)4.1.2.3.1.功能描述 (70)4.1.2.3.2.操作步骤 (71)4.1.2.4.JSON Output (72)4.1.2.5.LDAP Output (72)4.1.2.6.Mircosoft Access Output (72)4.1.2.7.Mircosoft Excel Output:Excel输出 (72)4.1.2.7.1.功能描述 (72)4.1.2.7.2.操作步骤 (72)4.1.2.8.Pentaho Reporting Output (75)4.1.2.9.Properties Output (75)4.1.2.10.RSS Output (75)4.1.2.11.S3 File Output (75)4.1.2.12.SQL File Output (75)4.1.2.13.Saleforce Delete (75)4.1.2.14.Saleforce Insert (75)4.1.2.15.Saleforce Update (75)4.1.2.16.Saleforce Upsert (75)4.1.2.17.Serialize to file (75)4.1.2.18.Synchronize after merge (76)4.1.2.19.Table output (76)4.1.2.19.1.功能描述 (76)4.1.2.20.Text file output:文本文件输出 (79)4.1.2.20.1.功能描述 (79)4.1.2.20.2.操作步骤 (80)4.1.2.21.Update:更新 (81)4.1.2.21.1.功能描述 (81)4.1.2.21.2.操作步骤 (82)4.1.2.22.XML Output (83)4.1.3.Transform:转换(26) (84)4.1.3.1.Add XML (84)4.1.3.2.Add a checksum (84)4.1.3.3.Add constants:增加常量 (84)4.1.3.3.1.功能描述 (84)4.1.3.3.2.操作步骤 (84)4.1.3.4.Add sequence (85)4.1.3.4.1.功能描述 (85)4.1.3.4.2.操作步骤 (85)4.1.3.5.Add value fields changing seqence (86)4.1.3.6.!Calculator:计算器 (86)4.1.3.6.1.功能描述 (87)4.1.3.6.2.操作步骤 (88)4.1.3.7.Closure Generator (89)4.1.3.8.Concat Fields (89)4.1.3.9.Get ID From slave server (89)4.1.3.10.Number range (89)4.1.3.11.Replace in string:字符串替换 (89)4.1.3.11.1.功能描述 (89)4.1.3.11.2.操作步骤 (89)4.1.3.12.!Row Normaliser:行转列 (90)4.1.3.12.1.功能描述 (90)4.1.3.12.2.操作步骤 (91)4.1.3.13.Row denormaliser:列转行 (92)4.1.3.13.1.功能描述 (92)4.1.3.13.2.操作步骤 (92)4.1.3.14.!Row flattener:行扁平化 (92)4.1.3.14.1.功能描述 (93)4.1.3.14.2.操作步骤 (93)4.1.3.15.!Select values:字段选择 (94)4.1.3.15.1.功能描述 (94)4.1.3.15.2.操作步骤 (95)4.1.3.16.Set field value (96)4.1.3.17.Set field value to a constant (96)4.1.3.18.Sort rows (96)4.1.3.18.1.功能描述 (96)4.1.3.19.Split Fields:拆分字段 (97)4.1.3.19.1.功能描述 (97)4.1.3.19.2.操作步骤 (97)4.1.3.20.Split Fields to rows (99)4.1.3.21.String operations (99)4.1.3.22.String cut:裁剪字符串 (99)4.1.3.22.1.功能描述 (99)4.1.3.22.2.操作步骤 (99)4.1.3.23.Unique rows:去除重复记录 (100)4.1.3.23.1.功能描述 (100)4.1.3.23.2.操作步骤 (100)4.1.3.25.!Value Mapper:值映射 (101)4.1.3.25.1.功能描述 (101)4.1.3.25.2.操作步骤 (101)4.1.3.26.XSL Transformation (103)4.1.4.Utility(15) (103)4.1.4.1.Change file encoding (103)4.1.4.2.Clone row (103)4.1.4.3.Delay row (103)4.1.4.4.Edit to xml (103)4.1.4.5.Execute a process (103)4.1.4.6.If field value is null (103)4.1.4.7.Mail (103)4.1.4.8.Metadata structure of stream (103)4.1.4.9.Null if:设置为空值 (103)4.1.4.9.1.功能描述 (103)4.1.4.10.Process files (104)4.1.4.11.Run SSH commands (104)4.1.4.12.Send message to Syslog (104)4.1.4.13.Table Compare (104)4.1.4.14.Write to log (104)4.1.4.15.Zip file (104)4.1.4.15.1.功能描述 (104)4.1.4.15.2.操作步骤 (104)4.1.5.Flow(16) (106)4.1.5.1.Abort:中止 (106)4.1.5.1.1.功能描述 (106)4.1.5.2.Annotate Stream (106)4.1.5.3.Append streams:追加流 (106)4.1.5.3.1.功能描述 (106)4.1.5.3.2.操作步骤 (106)4.1.5.4.Block this step unitil steps finish (107)4.1.5.5.Blocking Step:阻塞数据 (107)4.1.5.5.2.操作步骤 (107)4.1.5.6.Detect empty stream (108)4.1.5.7.Dummy (do nothing):空操作(什么也不做) (108)4.1.5.7.1.功能描述 (108)4.1.5.8.ETL Metadata Injection (109)4.1.5.9.!Filter rows: 过滤记录(过滤行) (109)4.1.5.9.1.功能描述 (109)4.1.5.9.2.操作步骤 (109)4.1.5.10.Identify last row in a stream (110)4.1.5.11.Java fileter (111)4.1.5.12.Job Executor (111)4.1.5.13.Prioritize streams (111)4.1.5.14.Single Threader (111)4.1.5.15.Switch / Case (111)4.1.5.15.1.功能描述 (111)4.1.5.15.2.操作步骤 (111)4.1.5.16.Transformation Executor (113)4.1.6.Scripting(9) (113)4.1.6.1.!Execute SQL script:执行SQL脚本 (113)4.1.6.1.1.功能描述 (113)4.1.6.1.2.操作步骤 (114)4.1.6.1.3.实例讲解 (115)4.1.6.2.Execute row SQL script:执行SQL脚本(字段流替换) (116)4.1.6.2.1.功能描述 (116)4.1.6.2.2.操作步骤 (116)4.1.6.3.Formula (117)4.1.6.4.!Modified Java Script Value (118)1)Transformation scripts (118)2)Transformation constants (118)3)Transformation functions (118)1)过滤Null字段 (119)2)字符串截取 (119)3)过滤记录行,控制转换流程 (119)4)使用java类库 (119)4.1.6.4.1.实例讲解 (124)4.1.6.5.Regex Evaluation (124)4.1.6.6.Rules Accumulator (124)4.1.6.7.Rules Executor (124)er Defined Java Class (124)er Defined Java Expression (124)4.1.7.BA Server(3) (125)4.1.7.1.Call endpoint (125)4.1.7.2.Get session varables (125)4.1.8.Lookup(15) (125)4.1.8.1.!Call DB Procedure:调用DB存储过程 (125)4.1.8.1.1.功能描述 (125)4.1.8.1.2.操作步骤 (125)4.1.8.2.Check if a column exists (127)4.1.8.3.Check if file is locked (127)4.1.8.4.Check if webservice is available (127)4.1.8.5.!Database join:数据库连接 (127)4.1.8.5.1.功能描述 (127)4.1.8.5.2.操作步骤 (127)4.1.8.6.!Database lookup:数据库查询 (128)4.1.8.6.1.功能描述 (129)4.1.8.6.2.操作步骤 (129)4.1.8.7.Dynamic SQL row (131)4.1.8.8.File exists (131)4.1.8.9.Fuzzy match (131)4.1.8.10.HTTP client (131)4.1.8.10.1.功能描述 (131)4.1.8.10.2.操作步骤 (131)4.1.8.11.HTTP Post (132)4.1.8.12.REST Client (132)4.1.8.13.Stream lookup (132)4.1.8.14.Table exists (132)4.1.8.15.Web services lookup (132)4.1.9.Joins(6) (133)4.1.9.1.!Join Rows(Cartesian product):记录关联(笛卡尔输出) (133)4.1.9.1.1.功能描述 (133)4.1.9.2.!Merge join (133)4.1.9.2.1.功能描述 (133)4.1.9.3.!Merge Rows (diff) (134)4.1.9.4.Multiway Merge Join (134)4.1.9.5.Sorted Merge (134)4.1.9.6.XML Join (134)4.1.10.Data Warehouse(2) (135)4.1.10.1.!Combination lookup/update (135)4.1.10.2.!Dimension lookup/update (135)4.1.11.Validation(4) (136)4.1.11.1.Credit card validator (136)4.1.11.2.Data Validator (136)4.1.11.3.Mail Validator (136)4.1.11.4.XSD Validator (136)4.1.12.!Statistics:统计(7) (136)4.1.12.1.Analytic Query (136)4.1.12.2.1.功能描述 (136)4.1.12.2.2.操作步骤 (136)4.1.12.3.Memory Group by (138)4.1.12.4.Output steps metrics (138)4.1.12.5.Reservoir Sampling (138)4.1.12.6.Sample rows (138)4.1.12.7.Univariate Statistics (138)4.1.13.Big Data(13) (138)4.1.13.1.Avro Input (138)4.1.13.2.Cassandra Input (138)4.1.13.3.Cassandra output (138)4.1.13.4.CouchDb Input (138)4.1.13.5.HBase Input (138)4.1.13.6.HBase Row Decoder (138)4.1.13.7.Hadoop File Input (138)4.1.13.8.Hadoop File Output (138)4.1.13.9.MapReduce Input (138)4.1.13.10.MapReduce output (139)4.1.13.11.MongoDB Input (139)4.1.13.12.MongoDB output (139)4.1.13.13.SSTable Output (139)4.1.14.Agile(2) (139)4.1.14.1.MonetDB Agile Mart (139)4.1.14.2.Table Agile mart (139)4.1.15.Cryptography(4) (139)4.1.15.1.PGP Decrypt stream (139)4.1.15.2.PGP Encrypt stream (139)4.1.15.3.Secret key generator (139)4.1.15.4.Symmetric Cryptography (139)4.1.16.Palo(4) (139)4.1.16.1.Palo Cell Input (139)4.1.16.2.Palo Cell Output (139)4.1.16.3.Palo Dim Input (140)4.1.16.4.Palo Dim Output (140)4.1.17.Open ERP(3) (140)4.1.17.1.OpenERP Object Delete (140)4.1.17.2.OpenERP Object Input (140)4.1.17.3.OpenERP Object OUtput (140)4.1.18.Job:作业(6) (140)4.1.18.1.Copy rows to result:复制记录到结果 (140)4.1.18.1.1.功能描述 (140)4.1.18.2.Get Variables:获取变量 (140)4.1.18.2.1.功能描述 (140)4.1.18.3.Get files from result:从结果获取文件 (141)4.1.18.3.1.功能描述 (141)4.1.18.3.2.操作步骤 (142)4.1.18.4.Get rows from result:从结果获取记录 (142)4.1.18.4.1.功能描述 (142)4.1.18.5.Set Variables:设置变量 (142)4.1.18.5.1.功能描述 (143)4.1.18.5.2.操作步骤 (143)4.1.18.6.Set files in result:复制文件到结果 (143)4.1.18.6.1.功能描述 (143)4.1.18.6.2.操作步骤 (143)4.1.19.!Mapping(4) (144)4.1.19.1.Mapping(sub-transformation) (144)4.1.19.2.Mapping input specification (144)4.1.19.3.Mapping output specitication (144)4.1.19.4.Simple Mapping(sub-transformation) (144)4.1.20.Bulk loading(11) (145)4.1.20.1.ElasticSearch Bulk Insert (145)4.1.20.2.Greenplum load (145)bright loader (145)4.1.20.4.Ingres VectorWise Bulk Loader (145)4.1.20.5.MonetDB Bulk Loader (145)4.1.20.6.MySQL Bulk loader (145)4.1.20.7.!Oracle Bulk loader (145)4.1.20.7.1.功能描述 (145)4.1.20.8.PostgresSQL Bulk loader (146)4.1.20.9.Teradata Fastload Bulk Loader (146)4.1.20.10.Teradata TPT Bulk loader (146)4.1.20.11.Vertica Bulk loader (146)4.1.21.Inline(3) (146)4.1.21.1.Injector: 记录注射器 (146)4.1.21.2.Socket reader: 套接字读入器 (147)4.1.21.2.1.功能描述 (147)4.1.21.3.Socket writer (147)4.1.22.Experimental(2) (148)4.1.22.1.SFTP Put (148)4.1.22.2.Script (148)4.1.23.Deprecated(4) (148)4.1.23.1.Example Step (148)4.1.23.2.Greenplum Bulk loader (148)4.1.23.3.LicidDB Streaming Loader (148)4.1.23.4.Old Text file input (148)4.1.24.History(9) (148)4.1.24.2.Table input (148)4.1.24.3.Text file output (148)4.1.24.4.Table output (148)4.1.24.5.Moding java Script Value (148)4.1.24.6.Add sequence (148)4.1.24.7.Generate Rows (149)4.1.24.8.Get System Info (149)4.1.24.9.Sort rows:行排序 (149)4.1.24.9.1.功能描述 (149)4.2.JOB:作业步骤(15-92) (149)4.2.1.General:通用(6) (149)4.2.1.1.Start:开始 (149)4.2.1.1.1.功能描述 (149)4.2.1.1.2.操作步骤 (150)4.2.1.2.Dummy:空操作 (150)4.2.1.2.1.功能描述 (150)4.2.1.3.OK (151)4.2.1.4.Job:作业 (151)4.2.1.4.1.功能描述 (151)4.2.1.4.2.操作步骤 (151)4.2.1.5.Set variables:设置变量 (152)4.2.1.5.1.功能描述 (152)4.2.1.6.Transformation (152)4.2.1.6.1.功能描述 (152)4.2.1.6.2.操作步骤 (153)4.2.1.7.Success (154)4.2.2.Mail:邮件(3) (154)4.2.2.1.Mail validator (154)4.2.2.2.Mail:发送邮件 (154)4.2.2.2.1.功能描述 (154)4.2.2.2.2.操作步骤 (154)4.2.2.3.Get mails from POP:接收邮件 (156)4.2.2.3.1.功能描述 (156)4.2.2.3.2.操作步骤 (156)4.2.3.File management(19) (158)4.2.3.1.Process result filenames (158)4.2.3.2.File Compare:比较文件 (158)4.2.3.2.1.功能描述 (158)4.2.3.2.2.操作步骤 (158)4.2.3.3.Create a folder:创建文件夹 (159)4.2.3.3.1.功能描述 (159)4.2.3.3.2.操作步骤 (159)4.2.3.4.Unzip file:解压ZIP文件 (159)4.2.3.4.2.操作步骤 (160)4.2.3.5.Delete file:删除文件 (161)4.2.3.5.1.功能描述 (161)4.2.3.5.2.操作步骤 (161)4.2.3.6.HTTP (162)4.2.3.7.Write to file (162)4.2.3.7.1.功能描述 (162)4.2.3.7.2.操作步骤 (162)4.2.3.8.Convert file between Windows and Unix (163)pare folders:比较文件夹 (163)4.2.3.9.1.功能描述 (163)4.2.3.9.2.操作步骤 (163)4.2.3.10.Zip file:压缩文件 (164)4.2.3.10.1.功能描述 (164)4.2.3.11.Copy Files (165)4.2.3.11.1.功能描述 (165)4.2.3.11.2.操作步骤 (165)4.2.3.12.Add filenames to result添加文件名到结果 (166)4.2.3.12.1.功能描述 (166)4.2.3.12.2.操作步骤 (166)4.2.3.13.Delete folders:删除文件夹 (167)4.2.3.13.1.功能描述 (167)4.2.3.13.2.操作步骤 (167)4.2.3.14.Delete filenames from result:在结果中删除文件名 (168)4.2.3.14.1.功能描述 (168)4.2.3.14.2.操作步骤 (168)4.2.3.15.Delete files:删除多个文件 (169)4.2.3.15.1.功能描述 (169)4.2.3.15.2.操作步骤 (169)4.2.3.16.Wait for file:等待文件 (170)4.2.3.16.1.功能描述 (170)4.2.3.16.2.操作步骤 (170)4.2.3.17.Move Files移动文件 (171)4.2.3.17.1.功能描述 (171)4.2.3.17.2.操作步骤 (171)4.2.3.18.Create file:创建文件 (171)4.2.3.18.1.功能描述 (172)4.2.3.18.2.操作步骤 (172)4.2.3.19.Copy or Move result filenames:根据结果复制或移动文件 (172)4.2.3.19.1.功能描述 (172)4.2.3.19.2.操作步骤 (173)4.2.4.Conditions(12) (174)4.2.4.1.Check webservice availability:检查WEB服务是否可用 (174)4.2.4.1.2.操作步骤 (174)4.2.4.2.Check files locked:判断是否有文件被锁定 (175)4.2.4.2.1.功能描述 (175)4.2.4.2.2.操作步骤 (175)4.2.4.3.Colums exist in a table:检查列在表中是否存在 (176)4.2.4.3.1.功能描述 (176)4.2.4.3.2.操作步骤 (176)4.2.4.4.Wait for (177)4.2.4.4.1.功能描述 (177)4.2.4.4.2.操作步骤 (177)4.2.4.5.Evaluate files metrics (177)4.2.4.6.Check Db connections (177)4.2.4.6.1.功能描述 (177)4.2.4.6.2.操作步骤 (178)4.2.4.7.File Exists:文件存在 (178)4.2.4.7.1.功能描述 (178)4.2.4.7.2.操作步骤 (178)4.2.4.8.Evaluate rows number in a table:判断标中行数 (178)4.2.4.8.1.功能描述 (178)4.2.4.8.2.操作步骤 (179)4.2.4.9.Checks if files exist:检查文件是否存在 (180)4.2.4.9.1.功能描述 (180)4.2.4.9.2.操作步骤 (180)4.2.4.10.Check if a folder is empty检查文件夹是否为空 (180)4.2.4.10.1.功能描述 (181)4.2.4.10.2.操作步骤 (181)4.2.4.11.Simple evaluation:简单评估 (181)4.2.4.11.1.功能描述 (181)4.2.4.11.2.操作步骤 (182)4.2.4.12.Table exists:表存在 (182)4.2.4.12.1.功能描述 (183)4.2.4.12.2.操作步骤 (183)4.2.5.Scripting(3) (183)4.2.5.1.Shell (183)4.2.5.1.1.功能描述 (183)4.2.5.1.2.操作步骤 (184)4.2.5.2.SQL (186)4.2.5.2.1.功能描述 (186)4.2.5.2.2.操作步骤 (186)4.2.5.3.JavaScript:Java脚本 (187)4.2.5.3.1.功能描述 (187)4.2.5.3.2.操作步骤 (188)4.2.6.Bulk loading(3) (190)4.2.6.1.BulkLoad form Mysql into file (190)4.2.6.2.BulkLoad into MSSQL (190)4.2.6.3.BulkLoad into Mysql (190)4.2.7.Big Data(10) (190)4.2.7.1.Oozie Job Execcutor (190)4.2.7.2.Hadoop Job Executor (190)4.2.7.3.Pig Script Executor (190)4.2.7.4.Amazon Hive Job Executor (190)4.2.7.5.Spark Submit (190)4.2.7.6.Sqoop Export (190)4.2.7.7.Sqoop Import (190)4.2.7.8.Pentaho Mapreduce (190)4.2.7.9.Hadoop Copy Files (190)4.2.7.10.Amazon EMR Job Executor (190)4.2.8.Modeling(2) (191)4.2.8.1.Build Model (191)4.2.8.2.Publish Model (191)4.2.9.XML(4) (191)4.2.9.1.XSD Validator (191)4.2.9.2.Check if XML file is well formed (191)4.2.9.3.XSL Transformation (191)4.2.9.4.DTD Validator (191)4.2.10.Utility(13) (191)4.2.10.1.Truncate tables (191)4.2.10.2.Display Msgbox Info (191)4.2.10.3.Wait for SQL (191)4.2.10.4.Abort job (192)4.2.10.5.Talend Job Execution (192)4.2.10.6.HL7 MLLP Acknowledge (192)4.2.10.7.Send Nagios passive check (192)4.2.10.8.Ping a host (192)4.2.10.9.Write To Log (192)4.2.10.10.Telnet a host (193)4.2.10.11.HL7 MLLP Input (193)4.2.10.12.Send information using Syslog (193)4.2.10.13.Send SNMP trap (193)4.2.11.Reposotory(2) (194)4.2.11.1.Export repository to XML file (194)4.2.11.2.Check if connected to repository (194)4.2.12.File transfer(8) (194)4.2.12.1.Get a file with FTP (194)4.2.12.1.1.功能描述 (195)4.2.12.1.2.操作步骤 (195)4.2.12.2.Put a file with FTP (197)4.2.12.2.1.功能描述 (198)4.2.12.2.2.操作步骤 (198)4.2.12.4.FTP Delete:删除FTP文件 (199)4.2.12.4.1.功能描述 (199)4.2.12.4.2.操作步骤 (199)4.2.12.5.Get a file with SFTP (199)4.2.12.5.1.功能描述 (199)4.2.12.5.2.操作步骤 (200)4.2.12.6.Put a file with SFTP (200)4.2.12.6.1.功能描述 (201)4.2.12.6.2.操作步骤 (201)4.2.12.7.Upload files to FTPS (201)4.2.13.File encryption(3) (202)4.2.13.1.Verify file signature with PGP (202)4.2.13.2.Decrypt files with PGP (202)4.2.13.3.Encrypt files with PGP (202)4.2.14.Palo(2) (202)4.2.14.1.Palo Cube Delete (202)4.2.14.2.Palo Cube Create (202)4.2.15.Deprecated(2) (202)4.2.15.1.MS Access Bulk Load (202)4.2.15.2.Example Job (202)更新记录第一章.Kettle 基础介绍1.1.核心组件Spoon是构建ETL Jobs和Transformations的工具。

陈伟星、李笑来名誉权纠纷二审民事判决书【案由】民事人格权纠纷人格权纠纷名誉权纠纷【审理法院】浙江省杭州市中级人民法院【审理法院】浙江省杭州市中级人民法院【审结日期】2020.09.14【案件字号】(2020)浙01民终2339号【审理程序】二审【审理法官】石清荣韦薇孔文超【审理法官】石清荣韦薇孔文超【文书类型】判决书【当事人】陈伟星;李笑来【当事人】陈伟星李笑来【当事人-个人】陈伟星李笑来【代理律师/律所】廖文燕、吴壮浙江六和律师事务所;方皛、卢文杰上海君悦律师事务所【代理律师/律所】廖文燕、吴壮浙江六和律师事务所方皛、卢文杰上海君悦律师事务所【代理律师】廖文燕、吴壮方皛、卢文杰【代理律所】浙江六和律师事务所上海君悦律师事务所【法院级别】中级人民法院【字号名称】民终字【原告】陈伟星【被告】李笑来【本院观点】李笑来对该段视频确为其直播内容并无异议,本院对该证据的真实性予以认可,但该视频仅为直播片段的截取,无法反映直播的完整内容,难以体现直播者真实的意思表示,故对陈伟星提交该证据的证明目的本院不予认可。
民事主体享有名誉权,任何人不得对他人的名誉权加以侵害。
陈伟星的案涉言论主要围绕李笑来在虚拟币领域的投融资行为展开,对于虚拟币投融资这一具有一定知识门槛的社会新生事物,客观上确能起到一定的舆论监督的作用,但舆论监督亦应遵循一定的边界,即行为人应对言论的内容尽到合理的核实义务,且不得使用侮辱性言辞贬损他人的名誉。
陈伟星作为具有一定社会知名度的主体,应当预见到其言论内容在网络中可能引发的效应。
【权责关键词】社会公共利益委托代理过错停止侵害排除妨碍消除危险返还财产恢复原状消除影响恢复名誉赔礼道歉自认合法性质证证明责任(举证责任)诉讼请求维持原判【指导案例标记】0【指导案例排序】0【本院查明】经审理,本院查明的事实与原审法院查明的事实一致。
【本院认为】本院认为,民事主体享有名誉权,任何人不得对他人的名誉权加以侵害。
编号:〔 〕字 号本科生毕业设计〔论文〕题目:姓名: 学号: 班级:二〇一二年六月微博客户端的设计开发计08-3班中国矿业大学本科生毕业设计姓名:学号:学院:计算机科学与技术专业:计算机科学与技术设计题目:微博客户端的设计开发专题:指导教师:徐慧职称:讲师2021 年6月徐州中国矿业大学毕业设计任务书学院计算机科学与技术专业年级计08级学生姓名任务下达日期:2021年1月10日毕业设计日期:2021 年1月4日至2021年6月10日毕业设计题目:微博客户端的设计开发毕业设计专题题目:毕业设计主要内容和要求:毕业设计的软件内容及要求:1.用户界面美观实用,便于各功能页面导航。
2.系统各功能模块要明确划分。
论文的内容及要求:1.论文对系统设计的思想进行详细描述,介绍整个软件开发过程。
2.进行系统需求分析,概要设计,详细设计,性能测试。
3.说明开发过程中遇到的问题极其解决方法。
4.最后写出软件开发的体会及收获。
5.严格按照软件工程要求的格式编写文档。
院长签字:指导教师签字:指导教师评语〔①根底理论及根本技能的掌握;②独立解决实际问题的能力;③研究内容的理论依据和技术方法;④取得的主要成果及创新点;⑤工作态度及工作量;⑥总体评价及建议成绩;⑦存在问题;⑧是否同意辩论等〕:成绩:指导教师签字:年月日指导教师评语〔①根底理论及根本技能的掌握;②独立解决实际问题的能力;③研究内容的理论依据和技术方法;④取得的主要成果及创新点;⑤工作态度及工作量;⑥总体评价及建议成绩;⑦存在问题;⑧是否同意辩论等〕:成绩:指导教师签字:年月日中国矿业大学毕业设计辩论及综合成绩摘要微博即MicroBlog,网上昵称围脖,是一种非正式的迷你型博客,是一个基于用户关系的信息分享、传播及获取平台。
用户可以通过WEB、WAP以及各种客户端组件个人社区,以140字左右的文字更新信息,并实现即时分享。
它是一种互动及传播性极快的工具,传播速度甚至比媒体还快。
Art-Net概述:Art-Net是一种基于TCP/IP协议栈的以太网协议。
目的在于使用标准的网络技术允许在广域内传递大量DMX512数据。
最新版本协议实现了许多新的功能,并简化了数据传输机制。
这些变化都是基于那些使用此协议的厂家反馈。
数据包地址:Art-Net3规范中,理论上最多为32768个数据包。
实际可传输数据包数量取决于网络物理层和分配使用量。
下面表格提供一个经验值。
每个DMX512数据包的端口地址被编码为一个15位数,如下表。
高字节被称为“网”。
这个是在Art-Net中被引入,之前为0。
该网具有用于每个节点的单一值。
低字节的高四位被称为子网地址,并设置为每个节点一个值。
低字节的第四位用于节点中定义独特DMX512数据包。
这意味着任何节点具有:1.一个“网络”开关。
2.一个“子网”开关3.一个“数据包”开关用于每个独特DMX512输入或输出。
产品设计者可以选择通过硬件或软件开关实现。
Credits:Any person or entity which implements Art-Net in their products shall include a user guide credit of: "Art-Net™ Designed by and Copyright Artistic Licenc e Holdings Ltd". 术语:节点(Node):一个设备使用Art-Net转换DMX512被称为一个节点。
端口地址(Port-Address):32768个地址中的其中一个地址可能写入到可控的DMX数据帧中。
端口地址是一个15位数包括Net+Sub-Net+Universe。
网络(Net):一组16个连续子网或256个连续数据包被称为网络,总共有128个网络。
子网(Sub-Net):一组16个连续的数据包被称为一个子网。
(不要与子网掩码混淆)。
数据包(Universe):一个512数据帧的DMX512信号被称为数据包。
Android系统开发编译环境配置主机系统:Ubuntu9.04(1)安装如下软件包sudo apt-get install git-coresudo apt-get install gnupgsudo apt-get install sun-java5-jdksudo apt-get install flexsudo apt-get install bisonsudo apt-get install gperfsudo apt-get install libsdl-devsudo apt-get install libesd0-devsudo apt-get install build-essentialsudo apt-get install zipsudo apt-get install curlsudo apt-get install libncurses5-devsudo apt-get install zlib1g-devandroid编译对java的需求只支持jdk5.0低版本,jdk5.0 update 12版本和java 6不支持。
(2)下载repo工具curl /repo >/bin/repochmod a+x /bin/repo(3)创建源代码下载目录:mkdir /work/android-froyo-r2(4)用repo工具初始化一个版本(以android2.2r2为例)cd /work/android-froyo-r2repo init -u git:///platform/manifest.git -b froyo初始化过程中会显示相关的版本的TAG信息,同时会提示你输入用户名和邮箱地址,以上面的方式初始化的是android2.2 froyo的最新版本,android2.2本身也会有很多个版本,这可以从TAG信息中看出来,当前froyo的所有版本如下:* [new tag] android-2.2.1_r1 -> android-2.2.1_r1* [new tag] android-2.2_r1 -> android-2.2_r1* [new tag] android-2.2_r1.1 -> android-2.2_r1.1* [new tag] android-2.2_r1.2 -> android-2.2_r1.2* [new tag] android-2.2_r1.3 -> android-2.2_r1.3* [new tag] android-cts-2.2_r1 -> android-cts-2.2_r1* [new tag] android-cts-2.2_r2 -> android-cts-2.2_r2* [new tag] android-cts-2.2_r3 -> android-cts-2.2_r3这样每次下载的都是最新的版本,当然我们也可以根据TAG信息下载某一特定的版本如下:repo init -u git:///platform/manifest.git -b android-cts-2.2_r3(5)下载代码repo syncfroyo版本的代码大小超过2G,漫长的下载过程。
介绍使用八爪鱼7.0采集新浪微博数据的方法采集网站:https:///1875781361/FhuTqwUjk?from=page_1005051875781361_profile&wvr=6&m od=weibotime&type=comment#_rnd1503315170479使用功能点:●Ajax滚动加载设置●分页列表详情页内容提取相关采集教程:百度搜索结果采集豆瓣电影短评采集58同城信息采集步骤1:创建采集任务1)进入主界面选择,选择自定义模式2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”采集新浪微博数据图23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容采集新浪微博数据图3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)在页面打开后,当下拉页面时,会发现页面有新的数据在进行加载采集新浪微博数据图4所以需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定采集新浪微博数据图52)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中, 选择“循环点击下一页”采集新浪微博数据图6由于页面使用了ajax加载技术,当采集时候,网站总需要重新加载,所以对翻页步骤需进行上面打开网页步骤中的设置采集新浪微博数据图7步骤3:采集微博内容●选中需要采集的微博时间,创建循环点击列表●进入微博页创建采集列表1)如图,移动鼠标选中列表中商家的名称,右键点击,需采集的内容会变成绿色然后点击“选中全部”采集新浪微博数据图8注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“循环点击每个链接”采集新浪微博数据图93)网页会跳转到详情页中,移动鼠标选中要采集的内容,右键点击,选择“采集该链接的文本”采集新浪微博数据图104)鼠标右键点击需要采集的文本字段,点击“选中全部”注意:鼠标放在提示框中的字段上会出现一个删除标识,点击即可删除该字段。