SQL数据库集群方案
- 格式:ppt
- 大小:1.15 MB
- 文档页数:15


SqlServer 2014 AlaysOn 集群搭建目录SqlServer 2014 AlaysOn 集群搭建 (1)一、环境设置 (1)1、服务器: (1)2、操作系统: (2)3、数据库版本: (2)二、建立域服务器 (2)1、添加AD域角色 (2)2、建alwayson域 (3)3、创建域管理账户 (8)4、master、slave加入域 (11)三、安装故障转移集群 (12)1、Master、Slave均安装故障转移集群 (12)2、在master 创建集群 (12)四、配置故障转移集群 (17)1、domainserver 配置共享文件夹 (17)2、配置仲裁 (18)五、配置SQL账户 (20)1、修改数据库SQL代理服务和SQL 引擎服务为域账户 (20)2、添加域账户为sql登录用户,并给予sysadmin权限 (21)六、配置sqlserver AlwaysOn (23)1、启用AlwaysOn可用性组 (23)2、查看有用性 (23)3、创建AlwaysOn可用性组 (24)七、添加监听器 (30)一、环境设置1、服务器:2、操作系统:WindowsServer 2008 R2 Enterprise3、数据库版本:SQLserver 2014二、建立域服务器在DomainServer服务器上建立域服务,并把Master、Slave加入域。
1、添加AD域角色下一步,下一步默认安装。
2、建alwayson域安装域角色完成后,点击域服务安装向导点击下一步默认安装直到完成后重启服务器。
3、创建域管理账户再将此域用户加入域计算机组和域管理员组:4、master、slave加入域三、安装故障转移集群1、Master、Slave均安装故障转移集群2、在master 创建集群建立集群需要注销集群节点计算机,然后使用域用户登录把服务器添加进集群:若有以下错误、请检查对应服务器是否安装故障转移集群或者当前登录用户是否为管理员默认选项下一步直到验证验证通过后、设置集群虚拟IP、IP地址不能和已有IP冲突四、配置故障转移集群1、domainserver 配置共享文件夹需要对share目录授权集群账户写的权限否则会出现以下错误:2、配置仲裁配置成功后共享文件夹如图:五、配置SQL账户1、修改数据库SQL代理服务和SQL 引擎服务为域账户登录每一台SQLserver服务器,打开服务管理器,先修改SQL代理的启动账户为域用户,然后再修改SQL 引擎的启动账户为域用户2、添加域账户为sql登录用户,并给予sysadmin权限用sa登录后添加SQL登录用户,跟SQL 服务添加启动账户的步骤一样,将域用户添加为登录用户六、配置sqlserver AlwaysOn1、启用AlwaysOn可用性组打开每一台服务器的SQL Server配置管理器、启用AlwaysOn 可用性组2、查看有用性SELECT * FROM sys.dm_hadr_cluster_members;3、创建AlwaysOn可用性组在master创建数据库TestDB。
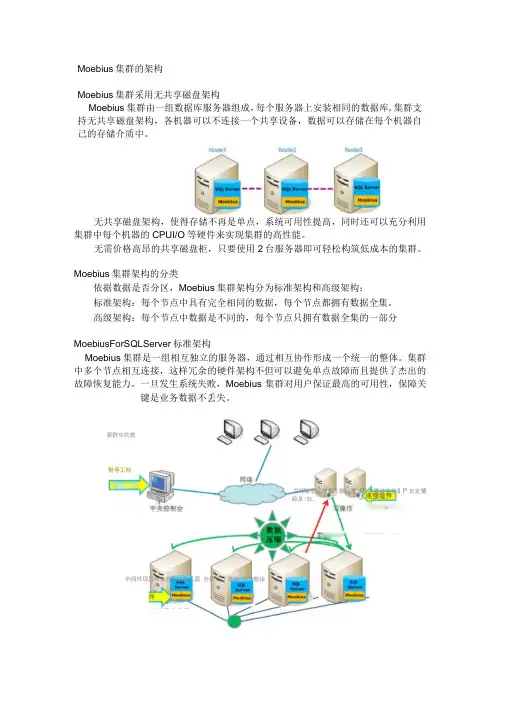
Moebius集群的架构Moebius集群采用无共享磁盘架构Moebius集群由一组数据库服务器组成,每个服务器上安装相同的数据库,集群支持无共享磁盘架构,各机器可以不连接一个共享设备,数据可以存储在每个机器自己的存储介质中。
无共享磁盘架构,使得存储不再是单点,系统可用性提高,同时还可以充分利用集群中每个机器的CPUI/O等硬件来实现集群的高性能。
无需价格高昂的共享磁盘柜,只要使用2台服务器即可轻松构筑低成本的集群。
Moebius集群架构的分类依据数据是否分区,Moebius集群架构分为标准架构和高级架构:标准架构:每个节点中具有完全相同的数据,每个节点都拥有数据全集。
高级架构:每个节点中数据是不同的,每个节点只拥有数据全集的一部分MoebiusForSQLServer标准架构Moebius集群是一组相互独立的服务器,通过相互协作形成一个统一的整体。
集群中多个节点相互连接,这样冗余的硬件架构不但可以避免单点故障而且提供了杰出的故障恢复能力。
一旦发生系统失败,Moebius集群对用户保证最高的可用性,保障关键是业务数据不丢失。
要群中的善管停工舄耳鳄常学接内五”第匕亳JT主量过壶按】P击定矍薛某/白,中间件现片布主在故据卑工面.分析SU遹句.同步数指Moebius集群标准架构一个集群数据库可以看作是一个被多个应用实例访问的单一数据库。
在Moebius 集群中,每个SQLServer实例在各自的服务器上运行。
随着应用的增加,当需要添加额外的资源时,可以在不停机的情况下很容易地增加节点。
标准架构中间件工作原理中间件驻留在每个机器的数据库中,监测数据库内数据的变化,并将变化的数据同步到其它数据库中。
数据同步完成后客户端才会得到响应,同步过程是并发完成的,因此同步到多个数据库和同步到一个数据库的时间基本相等;另外同步过程是在事务环境下完成的,保证了多份数据的数据一致性。
正因为中间件宿主在数据库中,所以中间件不但能知道数据的变化,而且知道引起数据变化的SQL语句,根据SQL语句的类型智能地采取不同的数据同步策略以保证数据同步成本的最小化:1, 数据条数很少,数据内容也不大,则直接同步数据。

postgres 集群方案PostgreSQL是一种开源的关系型数据库管理系统,常用于处理大规模的数据和高并发的应用。
在某些场景下,单个PostgreSQL服务器无法满足业务需求,这时候就需要考虑搭建PostgreSQL集群来提高数据库的性能和可用性。
本文将介绍一个基于物理复制和逻辑复制的PostgreSQL集群方案。
一、物理复制方案物理复制是指在数据库级别复制数据,将主数据库的所有物理文件复制到一个或多个从数据库中。
这种方案适合于数据量较大,对数据一致性要求较高的场景。
1. Master-Slave模式在Master-Slave模式下,一个主数据库(Master)负责处理写入操作,而一个或多个从数据库(Slave)复制主数据库的数据,并可用于读取操作。
当主数据库故障时,可以手动将一个从数据库切换为主数据库,以保证系统的可用性。
2. Master-Multi-Slave模式Master-Multi-Slave模式是在Master-Slave模式的基础上进行扩展的一种方案,即一个主数据库和多个从数据库,所有从数据库都复制主数据库的数据。
这样可以更好地分担读取压力,并提高系统的读取性能。
二、逻辑复制方案逻辑复制是指在逻辑级别复制数据,将主数据库的逻辑数据更改操作复制到一个或多个从数据库中。
这种方案适合于对数据一致性要求不是特别高,但对数据同步速度要求较高的场景。
1. 发布/订阅模式在发布/订阅模式下,主数据库将更改操作发布到订阅者,然后订阅者将这些操作应用到自己的数据库中。
该模式可以实现多个从数据库订阅主数据库的更改操作,从而提高系统的扩展性。
2. 逻辑复制插件模式逻辑复制插件模式是通过在主数据库上安装逻辑复制插件,将更改操作发送到从数据库。
这种模式与发布/订阅模式相似,但更加灵活,可以根据需求选择合适的插件和配置。
三、高可用性方案除了上述的复制方案外,提高数据库的可用性也是构建PostgreSQL 集群的重要目标之一。

postgres 集群方案PostgreSQL是一种强大的开源关系数据库管理系统,广泛应用于各种规模的企业和组织中。
为了提高系统的可用性和性能,许多组织选择使用PostgreSQL集群方案。
本文将介绍不同的PostgreSQL集群方案及其优缺点。
一、背景介绍在讨论PostgreSQL集群方案之前,我们先来了解一下什么是集群。
集群是将多台计算机连接在一起,以实现高可用性、负载均衡和容灾恢复等目标的系统。
对于PostgreSQL来说,集群可以提供高可用性和性能扩展的解决方案。
二、主从复制方案主从复制是最常见的PostgreSQL集群方案之一。
在主从复制中,有一个主数据库服务器和多个从数据库服务器。
主服务器接收写操作并将其复制到从服务器。
从服务器可以处理读请求,并在主服务器不可用时接管主服务器的角色。
主从复制方案具有以下优点:1. 可用性:当主服务器发生故障时,从服务器可以自动切换为主服务器,从而实现高可用性。
2. 扩展性:可以通过增加从服务器来扩展读操作的处理能力。
然而,主从复制方案也有一些限制:1. 读写分离:只有主服务器可用于写操作,从服务器只能用于读操作。
2. 数据一致性:主从复制方案无法保证从服务器与主服务器之间的数据实时同步,可能会出现数据延迟。
三、多主复制方案多主复制方案是一种改进的主从复制方案,它克服了主从复制方案的读写分离问题。
在多主复制中,每个数据库服务器都可以同时接收读和写操作,从而实现了读写分离。
多主复制方案具有以下优点:1. 读写分离:每个数据库服务器都可以用于读和写操作,提高了系统的整体性能。
2. 高可用性:当某个数据库服务器发生故障时,其他数据库服务器可以继续提供服务。
但是,多主复制方案也存在一些问题:1. 数据冲突:多个数据库服务器同时接收写操作可能会导致数据冲突,需要采取相应的冲突解决策略。
2. 配置复杂:多主复制方案的配置相对于主从复制来说更加复杂,需要仔细规划和管理。

南宁海关信息系统基础平台数据库群集实施报告2016年9月13号目录1 MS SQL数据库群集 (4)1.1 项目概述 (4)1.2 SQL群集拓朴图 (5)1.2.1 运行网SQL群集拓朴图 (5)1.2.2管理网SQL群集拓朴图 (6)1.3 SQL群集配置信息 (7)1.3.1 运行网SQL群集配置表 (7)1.3.2管理网SQL群集配置 (8)1.4 SQL群集安装配置 (9)1.4.1 网络配置 (9)1.4.2 两台服务器功能及角色安装 (13)1.4.3 Win2008集群验证和配置 (14)1.4.4 添加MSDTC的集群资源 (17)1.4.5添加Framework3.5 SP1功能 (19)1.4.6优化网络配置 (25)1.5安装SQLServer2008集群 (27)1.5.1安装第一个集群节点 (27)1.5.2添加第二个集群节点 (35)1.5.3 验证SQL2008群集 (39)2Oracle RAC高可用群集 (45)2.1 项目概述 (45)2.2Oracle群集拓朴图 (45)2.3 Oracle群集配置信息 (46)2.3.1系统及数据库版本 (46)2.3.2 主机IP地址 (46)2.3.3共享存储配置 (46)2.3.4安装目录配置 (47)2.4 Oracle RAC安装 (47)2.4.1准备系统环境 (47)2.4.2Oracle Grid安装 (50)2.4.3Oracle RAC软件安装 (67)2.4.4安装PSU补丁集 (79)2.5创建Oracle RAC数据库 (80)2.5Oracle RAC管理及维护 (95)2.5.1数据库集群操作 (95)2.5.2数据库表空间操作 (96)3 MS SQL数据库整合情况列表 (97)3.1 运行网SQL集群数据库 (97)3.2管理网SQL集群数据库 (98)1 MS SQL数据库群集1.1 项目概述目前南宁海关在用数据库主要有SQL 2000, SQL 2005, SQL2008等多个版本,存在单点故障或者资源利用率不均衡的问题。
mysql8集群搭建1.下载必要的rpm包我系统是centos 7 的所以选择红帽的操作系统2.安装mysql 先⽤sudo root运⾏,我这是直接su root切换了root⽤户yum remove mariadb-libsrpm -ivh mysql-community-common-8.0.20-1.el7.x86_64.rpmrpm -ivh mysql-community-libs-8.0.20-1.el7.x86_64.rpmrpm -ivh mysql-community-client-8.0.20-1.el7.x86_64.rpmrpm -ivh mysql-community-server-8.0.20-1.el7.x86_64.rpm3.启动mysqlservice mysqld start4.查看密码grep 'temporary password' /var/log/mysqld.log5.修改密码mysql -uroot -p 输⼊密码#Root_123456 是新密码,如果出现ERROR 1819 (HY000): Your password does not satisfy the current policy requirements 是因为密码太简单,要改成带特殊字符的复杂密码alter user 'root'@'localhost' IDENTIFIED BY '#Root_123456';修改成功6:设置允许远程登录use mysql;update user set host='%' where user = 'root';然后重启mysqlservice mysqld restart7.搭建集群 准备三台集群修改hosts⽂件vi /etc/hosts192.168.10.11 linux1192.168.10.12 linux2192.168.10.13 linux3 设置免密ssh-keygen -t rsassh-copy-id linux1ssh-copy-id linux2ssh-copy-id linux3 设置远程登录并且刷新grant all privileges on *.* to 'root'@'%' with grant option;flush privileges;安装 mysqlshrpm -ivh mysql-shell-8.0.20-1.el7.x86_64.rpm登录linux2安装mysql8在linux2/linu3从linux1 拷贝所有rpm包到本地scp -r linux1:/opt/software/ /opt/software/然后安装然后⽤mysqlsh搭建shell.connect('root@linux1:3306')dba.configureLocalInstance()shell.connect('root@linux2:3306')dba.configureLocalInstance()shell.connect('root@linux3:3306')dba.configureLocalInstance()shell.connect('root@linux1:3306')var cluster=dba.createCluster("MySQL_Cluster")如果不想⽤root⽤户,建议⽤root⽤户set sql_log_bin=0;create user rpl_user@'%' identified by '#Root_123456';grant replication slave,replication client on *.* to rpl_user@'%'; create user rpl_user@'127.0.0.1' identified by '#Root_123456';grant replication slave,replication client on *.* to rpl_user@'127.0.0.1'; create user rpl_user@'localhost' identified by '#Root_123456';grant replication slave,replication client on *.* to rpl_user@'localhost'; set sql_log_bin=1;change master tomaster_user='rpl_user',master_password='#Root_123456'for channel 'group_replication_recovery';install plugin group_replication soname 'group_replication.so';set global group_replication_bootstrap_group=on;start group_replication;set global group_replication_bootstrap_group=off; 关闭防⽕墙# 关闭防⽕墙systemctl stop firewalld.service# 禁⽤防⽕墙systemctl disable firewalld.servicevi /etc/selinux/configSELINUX=disabled安装mysql-routerrpm -ivh mysql-router-community-8.0.20-1.el7.x86_64.rpmvim /etc/mysqlrouter/mysqlrouter.conf[DEFAULT]logging_folder = /var/log/mysqlrouterruntime_folder = /var/run/mysqlrouterconfig_folder = /etc/mysqlrouter[logger]level = INFO[routing:read_write]bind_address = 192.168.10.11bind_port = 7001mode = read-writedestinations = linux1:3306,linux2:3306protocol=classicmax_connections=1024[routing:read_only]bind_address = 192.168.10.11bind_port = 7002mode = read-onlydestinations = linux1:3306,linux2:3306protocol=classicmax_connections=1024# If no plugin is configured which starts a service, keepalive# will make sure MySQL Router will not immediately exit. It is# safe to remove once Router is configured.[keepalive]interval = 60 重启mysqlroutersystemctl restart mysqlrouter。

MySQL集群部署与配置指南引言MySQL是一种开源的关系型数据库管理系统,被广泛应用于各种应用程序中。
在处理大规模数据和高并发访问时,单个MySQL服务器可能无法满足需求。
为了提高性能和可用性,使用MySQL集群来部署和配置数据库是一个不错的选择。
本文将详细介绍MySQL集群部署和配置的指南,帮助读者了解集群的概念,并提供一些实用的技巧。
1. 集群概述1.1 什么是MySQL集群MySQL集群是指由多个MySQL服务器组成的集合,通过共享数据和负载均衡来提供高性能和高可用性。
集群中的每个节点都存储相同的数据,并且可以处理来自客户端的查询请求。
如果其中一个节点发生故障,其他节点将继续提供服务,确保数据的有效性和可访问性。
1.2 集群的优势MySQL集群具有以下优势:- 高可用性:即使其中一个节点发生故障,其他节点也可以继续提供服务,避免了单点故障的风险。
- 负载均衡:通过将查询请求分发到不同的节点上,集群可以平衡负载,提高整个系统的性能。
- 扩展性:可以根据需求增加或减少集群节点,以应对不断增长的数据和用户访问量。
- 数据冗余:通过复制数据到多个节点,可以提供数据的冗余备份,避免数据丢失的风险。
2. 部署MySQL集群2.1 硬件要求部署MySQL集群需要考虑以下硬件要求:- 多台服务器:每个节点都需要一个独立的服务器来承载MySQL服务。
- 网络连接:节点之间需要可靠的网络连接,以便进行数据同步和通信。
2.2 软件要求部署MySQL集群还需要满足以下软件要求:- MySQL数据库:每个节点都需要安装并配置MySQL数据库。
- 集群管理软件:可以使用各种集群管理软件,如MySQL Cluster、Galera Cluster或Percona XtraDB Cluster等。
2.3 数据同步配置为了保持每个节点上的数据一致性,需要配置数据同步机制。
可以使用MySQL的复制功能来实现数据同步。
具体步骤如下:- 在一个节点上设置为主节点(master),并启用二进制日志功能。
SQL server 2008 集群DTC配置一、准备二、配置过程AD_Server配置在AD_server安装AD服务器后,如下图在AD_Server中服务器管理器中,选择角色-ACTIVE DIRECTORY-ACTIVE -USER中选择新建用户,分别创建两个用户名,分别为admin1和admin2,密码均为123_jpe_123,勾选密码永不过期,接下在我们在PC2上登录时帐号应为gdgzjp\admin1,PC3为gdgzjp\admin2,密码仍为123_jpe_123,如下我们在进行远程操控的时候,应在SQL_Serve1及SQL_Server2上分别添加一个远程登录用户admin1和admin2在storage_server上安装startwind1、首先在storage_server上启动MS iSCSI服务,如下图2、安装成功,打开startwind ,如下图3、选择starwind server,右键add host验证方式Use Basic authentication4、右键connect ,输入用户名root,密码starwind(V.5 以后root 的密码都是starwind),进入如下图接下来添加target。
输入一个target名称。
选择存储的介质类型,分别是硬盘,光驱,磁带,这里选硬盘harddisk。
选择设备的介质类型,分别是物理,基本虚拟,高级虚拟,这里选第二个,这里只讲基本的概念。
下一步选第一个image file device。
下一步分别是挂载已经存在的虚拟硬盘,创建新的虚拟硬盘,创建新的基于快照和CDP的虚拟硬盘,选第二个。
虚拟硬盘路径、大小、是否压缩、是否加密。
支持功能模式,Asynchronous Replication等等。
设置缓存模式。
创建完成。
下面讲一下扩展空间操作,右击imagefile1,extend image size。
填写要扩展的空间。

安装版本:mysql cluster 7.2.6操作系统centos6.2 (X64)软件名称mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz管理节点数据节点SQL节点在IP 10.8.10.38(master)数据节点SQL节点在IP 10.8.10.35首先,检查系统是否装载了mysql使用命令rpm -qa|grep -i mysql如果有显示全部卸载,如果没有说明没有安装mysqlrpm -e MySQL-python-1.2.3-0.3.c1.1.el6.x86_64rpm -e mysql-5.1.52-1.el6_0.1.x86_64rpm -e mysql-connector-odbc-5.1.5r1144-7.el6.x86_64rpm -e mysql-libs-5.1.52-1.el6_0.1.x86_64 –nodeps删除frm –fr /etc/ftar -zxvf mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz解压完成后运行mv mysql-cluster-gpl-7.2.6-linux2.6-x86_64 /usr/local/mysql添加用户mysqluseradd mysqlchown -R mysql:mysql /usr/local/mysql/进入安装脚本路径cd /usr/local/mysql/scripts/带参数运行安装程序./mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data &注意:&不带此符号,安装程序容易不进行安装,而且报错拷贝ndb_mgm ndb_mgmd 文件到/usr/local/bin/cp -fr /usr/local/mysql/bin/ndb_mgm* /usr/local/bin/创建mysql-cluster文件夹mkdir /var/lib/mysql-cluster创建config.ini文件vi /var/lib/mysql-cluster/config.ini文件内容[NDBD DEFAULT]NoOfReplicas: 1 #定义在Cluster环境中相同数据的份数最大为4# Data Memory, Index Memory, and String Memory #DataMemory: 500M #分配的数据内存大小IndexMemory: 250M #设定用于存放索引(非主键)数据的内存段大小#一个NDB节点能存放的数据量是会受到DataMemory和IndexMemory两个参数设置的约束,#两者任何一个达到限制数量后,都无法再增加能存储的数据量。

搭建SQLserverAwaysOn集群1.环境系统:windows server 2012 R2数据库版本:SQL server 2012三台服务器,IP分别是:10.10.10.111,10.10.10.112,10.10.10.1132.安装数据库2.1、三个集群节点都需先安装.NET Framework3.5(在Windows Server 2012 R2中使⽤添加功能来安装)。
报错并解决:解决:双击系统IOS镜像⽂件,在找到:sources\sxs ,指定到备⽤源路径,如下图。
2.2、三台服务器分别以administrator管理员账号登录系统,安装单实例数据库,SQL server安装⽐较简单,下⼀步--下⼀步--就⾏了。
如果实在不会,请参考之前的⽂章《》。
3.配置域控服务器我的域控是由专门的系统管理⼈员配置的,没有亲⾃动⼿,若有需要,请参考《》。
4.配置故障转移集群4.1、administrator⽤户安装故障转移集群,三个节点都同时安装故障转移集群服务4.2、三个节点都安装完故障转移集群之后,在其中⼀个节点上进⾏注销操作,然后使⽤DCADMIN这个域⽤户登录计算机。
域⽤户必须在域计算机组和域管理员组,否则创建集群时会报错:4.3、打开故障转移集群管理器4.4、在“选择服务器或群集”界⾯中,单击“浏览”按钮将所有要加⼊群集的服务器添加进来,然后单击“下⼀步”按钮。
三个节点的域控服务器都选上。
4.5、在验证配置向导中最好选择运⾏所有测试,进⾏全部检测就可以查看到服务器之间建⽴群集的所有设置,包括⽹络、共享磁盘、操作系统等。
可以查看⼀下报告报告⾥⾯⼀定不能出现失败,否则你需要检查是什么问题导致失败,失败是建⽴不了故障转移集群的出现警告要看情况,对于存储的警告,由于⽬前为⽌没有添加任何的存储设备,这⾥可以忽略,还有⽹络警告由于各个节点只有⼀个⽹卡,正常来说还需要⼀个⼼跳⽹卡,所以这⾥会出现警告,由于实验环境这个警告可以忽略集群报告会存放在这个路径下C:\Windows\Cluster\Reports4.6、点击完成4.7、创建集群向导4.8、输⼊集群名称和vip(VIP是随便输⼊的没有使⽤的IP。
数据库之MySQL集群⽅案策略(⼀)零、为什么需要群集? 在现在的科技环境下,我们的项⽬中往往会处理越来越多的数据量,随着数据量的递增,单⼀的数据库已经⽆法满⾜我们的业务要求,因此为了解决这⼀系列的数据库瓶颈,我们有了集群的搭建⽅案。
⼀、MySQL版本 引擎对⽐: 1、myisam没有事务⽀持 MariaDB针对MyISAM改进,Aria占⽤空间⼩,并且允许在系统之间轻松进⾏复制。
2、innodb提供事务⽀持,innodb在做任何操作时,会做⼀个⽇志操作,便于恢复。
它是MariaDB 10.2(以及MySQL)的默认存储引擎。
3、xtradb是innodb存储引擎的增强版本,拥有更⾼性能。
MariaDB在10.0.9版本起使⽤XtraDB来代替MySQL的InnoDB。
在MariaDB 10.1之前XtraDB是最佳选择,它是InnoDB的性能增强分⽀,并且是MariaDB 10.1之前的默认引擎。
版本对⽐: 1、Percona提供了⾼性能XtraDB引擎,还提供了PXC⾼可⽤解决⽅案,并且附带了percona-toolkit等DBA管理⼯具箱。
2、MariaDB在10.2.6版本⾥移除Percona XtraDB,换回默认InnoDB,现在10.5默认是InnoDB。
综合多年使⽤经验和性能对⽐,⾸选Percona分⽀,其次是MariaDB,如果你不想冒险,那就选择MYSQL官⽅版本。
推荐MariaDB⼆、Mysql群集⽅案 ⽅案⼀:共享存储 ⼀般共享存储采⽤⽐较多的是 SAN/NAS ⽅案。
SAN:共享存储,主库从库⽤的⼀个存储。
SAN的概念是允许存储设施和解决器(服务器)之间建⽴直接的⾼速连接,通过这种连接实现数据的集中式存储。
优点: 1、保证数据的强⼀致性; 2、与mysql解耦,不会由于mysql的逻辑错误发⽣数据不⼀致的情况; 缺点: 1、SAN价格昂贵; ⽅案⼆:操作系统实时数据块复制 这个⽅案的典型场景是 DRBD,DRBD架构(MySQL+DRBD+Heartbeat) DRDB:这是linux内核板块实现的快级别的同步复制技术。
postgres 集群方案PostgreSQL是一种功能强大的开源数据库管理系统,经常在企业中被用于存储和管理大量的数据。
为了提高数据库的可用性和性能,许多企业选择使用PostgreSQL集群方案。
本文将探讨PostgreSQL集群的不同方案和实施细节。
一、什么是PostgreSQL集群PostgreSQL集群是指将多个数据库服务器连接在一起以实现数据的高可用性、负载均衡和容错能力。
集群方案主要通过数据复制和负载均衡策略来实现高可用性和性能的提升。
二、PostgreSQL集群方案的选项1. 数据复制方案数据复制是实现PostgreSQL高可用性的关键技术之一。
常用的数据复制方案有:- 流复制(Streaming Replication):通过将主数据库的事务日志发送给备用数据库,实现数据的实时复制。
- 逻辑复制(Logical Replication):通过将逻辑变更记录分发给备用数据库,实现数据的复制。
- 物理复制(Physical Replication):基于块级别的复制,将主数据库的物理块复制到备用数据库中。
2. 负载均衡方案负载均衡是指将客户端请求均匀分配到不同的数据库服务器上,以提高系统的整体性能和并发能力。
常见的负载均衡方案有: - 数据库代理(Database Proxy):通过在应用程序和数据库之间插入代理层,实现请求的分发和负载均衡。
- 服务端连接池(Server-side Connection Pooling):通过共享和管理数据库连接,实现请求的均衡分配。
三、实施PostgreSQL集群方案的步骤和注意事项1. 规划集群拓扑根据业务需求和性能要求,确定集群的拓扑结构,包括主备关系、备份节点的数量以及负载均衡节点的位置。
2. 配置数据复制根据选择的数据复制方案,配置主备数据库之间的复制关系,并确保数据的一致性和可靠性。
同时,考虑到复制的延迟和性能影响。
3. 部署负载均衡根据选择的负载均衡方案,部署负载均衡节点以实现请求的分发和负载均衡。
SQL Server数据库热备方案三篇篇一:SQL Server数据库热备方案SQL Server数据库的高可用性方案主要有数据库镜像、日志传送、复制和故障转移群集等四种,本文基于自动灾难恢复的出发点,推荐故障转移群集和数据库镜像两种方案。
如遇高安全性、高性能的复杂情况,可多种方案组合使用,如故障转移群集+复制、数据库镜像+复制、数据库镜像+日志传送等。
故障转移群集方案方案说明应用服务器1应用服务器2SQL Server故障转移群集示意图1.Windows故障转移群集作为平台,其上运行SQL Server故障转移群集2.Windows故障转移群集对外提供虚拟IP,SQL Server群集对外提供群集实例名3.SQL Server群集中多个节点数据库共享1套数据库存储,确保数据一致性4.SQL Server群集中只有1个节点为活动状态,独占控制存储,对外提供数据库服务5.当前活动节点发生故障宕机,群集自动选择转移节点并切换至该数据库(状态切换为活动,开始独占存储,对外提供服务)6.多个节点须在同一个子网内,如有跨网段情况,需组VLAN。
软件需求⏹Windows Server操作系统(建议20XX及以上版本)⏹Active Directory服务⏹域DNS服务器⏹故障转移群集服务⏹SQL Server数据库硬件需求⏹域主控服务器⏹DNS服务器(可合并至主控服务器)⏹故障转移群集节点数据库(1个活动节点+1或多个转移节点)⏹存储:共享存储,视成本而定⏹网络:✓群集节点至少需要2块网卡:数据库服务+心跳。
根据存储类型确定是否需要额外网卡。
windows故障转移群集对外提供虚拟群集IP可见,SQL故障群集实例提供虚拟群集实例名称供应用程序访问。
数据库镜像方案方案说明应用服务器2应用服务器1SQL Server数据库镜像示意图1.见证服务器轮询验证主体数据库与镜像数据库的状态2.正常情况下,主体数据库提供对外服务,镜像数据库不可用,两台数据库间进行数据同步3.当见证服务器发现主体数据库断开连接,且见证服务器与镜像服务器连接正常,则启动故障转移。
Docker部署SQLServer2019AlwaysOn集群的实现⽬录Docker部署Always on集群安装Docker架构准备相关容器镜像操作系统开始配置-容器步骤1:创建Dockerfile步骤2:编译镜像步骤3:创建容器步骤4:启动容器步骤5:SSMS连接MSSQL配置-数据库步骤1:连接主库-sqlNode1步骤2:连接从库-sqlNode2和sqlNode3步骤3:所有节点步骤4:创建⾼可⽤组测试参考连接Docker部署Always on集群SQL Server在2016年开始⽀持Linux。
随着2017和2019版本的发布,它开始⽀持Linux和容器平台上的HA/DR、Kubernetes 和⼤数据集群解决⽅案。
在本⽂中,我们将在3个节点的Docker容器上安装SQL Server 2019,并创建AlwaysOn可⽤性组。
我们的⽬标是使⽤单个配置⽂件快速准备好环境。
因此,开发⼈员或测试团队可以快速执⾏诸如兼容性、连通性、代码功能等测试。
在本节中,我们将⾸先准备⼀个基于Ubuntu的映像,以便能够在容器上安装可⽤性组。
然后我们将执⾏必要的安装。
重要提⽰:不建议在⽣产环境中执⾏操作。
安装是在Ubuntu 18.04上执⾏的。
安装Docker安装Docker就不介绍了,⾃⾏安装即可.架构主机名IP端⼝⾓⾊sqlNode1宿主机IP1501:1433主sqlNode2宿主机IP1502:1433副本sqlNode3宿主机IP1503:1433副本端⼝表⽰:外⽹端⼝:内⽹端⼝准备相关容器镜像拉取操作系统和数据库的Docker镜像,如下操作系统docker pull ubuntu:18.04SQL Server 2019docker pull /mssql/server:2019-latest可通过docker images来查看已下载的镜像信息。
开始配置-容器环境准备完毕后,开始正式的配置安装。
一、基础环境:1、 四台服务器(1台AD 、2台SQL 服务器、1台iscsi 存储服务器),2、9个IP (1个AD 的IP 、2个SQL 服务器的IP 、1个iscsi 存储服务器的IP 、1个SQL 集群的IP 、1个DTC 的IP 、1个集群的IP 、2个心跳线的IP)三、准备工作:1、安装Windows2008R2的系统,并将服务器的补丁升至最新。
2、SQL2008数据库软件一套。
3、创建一台iscsi 服务器,并安装iscsi 服务插件,创建虚拟磁盘及iscsi 目标。
(iscsi 服务需要去官网下载)4、安装windows2008R2的域环境,并将数据库服务器加入域环境,对入域后的SQL 服务器进行补丁升级,补丁升级完成后,重启服务器。
5、分别给SQL 数据库服务器添加虚拟共享磁盘。
6、安装windows 集群故障转移及DTC 。
7、添加数据库故障集群及数据库故障节点。
四、安装步骤详解:A 、创建iscsi 虚拟磁盘服务器(1、先装RAID5,2、安装iscsi 服务,3、连接iscsi 虚拟磁盘);(一、创建RAID-5的硬盘)1、打开服务器管理器,选择存储,找到磁盘管理,会看到以下的磁盘没有联机。
Windows_2008_R2+SQL_2008 集群环境搭建2、将所有的磁盘联机及初始化硬盘。
3、将磁盘做成‘RAID-5’4、添加raid-5的硬盘数量及设置空间量。
5、添加完的及设置完空间的状态。
6、为RAID-5分配磁盘驱动号。
7、为RAID-5进行格式化。
7、为RAID-5进行格式化。
8、设置RAID-5完成。
9、点击完成后,会出现此提示框,选择‘是’二、安装iscsi服务,并创建虚拟磁盘1、运行安装iscsi程序压缩包,将包解压到默认位置。
1、运行安装iscsi程序压缩包,将包解压到默认位置。
2、找到解压后的文件夹,点击运行,开始安装。
3、安装后,点击开始,找到‘Micrsoft iscsi Software Target’并打开。
在VMWare 中配置SQL Server 2005 N + 1 群集(一) 环境1.实验环境Vmware Server 1.0.6SQL Server 2005 企业版Host OS:Windows Server 2003 企业版Guest OS:Windows Server 2003 企业版1.1背景所谓N+1的SQL Server群集,主要是以节约成本为出发点的一种群集方案。
一般的SQL Serv er群集,每个SQL Server服务至少有两个结点,一个提供服务,另一个备用。
而N+1的SQL Server群集,是多个SQL Server共享一台备用服务器。
这样,如果有两个SQ L Server服务,则只需要2(提供服务的服务器)+1(备用服务器)=3台服务器。
一般来说,多台服务器同时出故障的可能性比较小,所以N+1的SQL Server群集在保证了高可用性的前提下,有最大程度的节约成本。
本示例演示配置2+1的SQL Server 2005群集。
1.2拓扑图1.3系统配置1.3.1D omainOS: Windows Server 2003企业版Role: Domain Controller、DNS ServerServer Name: DomainDomain: IP - Public: 192.168.0.1mask - Public: 255.255.255.0DNS - Public: 192.168.0.11.3.2ClusterCluster Name: ClusterSQLIP: 192.268.0.2011.3.3Cluster Node 1OS: Windows Server 2003企业版Role: Member ServerServer Name: SQLClusterNode1IP - Public: 192.168.0.101mask - Public: 255.255.255.0DNS - Public: 192.168.0.1IP - Prive 192.168.1.101 (Heartbeat连接)mask - Prive: 255.255.255.01.3.4Cluster Node 2OS: Windows Server 2003企业版Role: Member ServerServer Name: SQLClusterNode2IP - Public: 192.168.0.102mask - Public: 255.255.255.0DNS - Public: 192.168.0.1IP - Prive 192.168.1.102 (Heartbeat连接)mask - Prive: 255.255.255.01.3.5Cluster Node 3OS: Windows Server 2003企业版Role: Member ServerServer Name: SQLClusterNode3IP - Public: 192.168.0.103mask - Public: 255.255.255.0DNS - Public: 192.168.0.1IP - Prive 192.168.1.103 (Heartbeat连接)mask - Prive: 255.255.255.01.3.6SQL Server 实例Virtual Server Name - 1:SQL01Virtual Server IP - 1:192.168.0.211Instance Name - 1: SQL01Virtual Server Name - 2:SQL02Virtual Server IP - 2:192.168.0.212Instance Name - 2: SQL02在VMWare 中配置SQL Server 2005 N + 1 群集(二) 在Vmware配置虚拟机2.在Vmware配置虚拟机所以的OS均使用Windows Server 2003企业版,故可以创建一台虚拟机,完成基本的配置和安装,最后使用Sysprep工具抽取SID后关机并做一个快照,然后克隆出另外4台虚拟机(也可以不使用Sysprep工具,直接克隆,然后使用newsid这个小工具重新生成SID并修改计算机名)。