SPSS发硒和血硒的含量的相关性分析
- 格式:doc
- 大小:307.00 KB
- 文档页数:9

第七章相关分析任何事物的存在都不是孤立的,而是相互联系、相互制约的。
在医学领域中,身高与体重、体温与脉搏、年龄与血压等都存在一定的联系。
说明客观事物相互间关系的密切程度并用适当的统计指标表示出来,这个过程就是相关分析。
值得注意,事物之间有相关,不一定是因果关系,也可能仅是伴随关系。
但如果事物之间有因果关系,则两者必然相关。
SPSS的相关分析是借助于Statistics菜单的Correlate选项完成的。
第一节Bivariate过程7.1.1 主要功能调用此过程可对变量进行相关关系的分析,计算有关的统计指标,以判断变量之间相互关系的密切程度。
调用该过程命令时允许同时输入两变量或两个以上变量,但系统输出的是变量间两两相关的相关系数。
7.1.2 实例操作[例7-1]某地区10名健康儿童头发和全血中的硒含量(1000ppm)如下,试作发硒与血硒的相关分析。
7.1.2.1 数据准备激活数据管理窗口,定义变量名:发硒为X,血硒为Y,按顺序输入相应数值,建立数据库(图7.1)。
图7.1 原始数据的输入7.1.2.2 统计分析激活Statistics菜单选Correlate中的Bivariate...命令项,弹出Bivariate Correlation对话框(图7.2)。
在对话框左侧的变量列表中选x、y,点击 钮使之进入Variables框;再在Correlation Coefficients框中选择相关系数的类型,共有三种:Pearson为通常所指的相关系数(r),K endell’s tau-b为非参数资料的相关系数,Spearman为非正态分布资料的Pearson 相关系数替代值,本例选用Pearson项;在Test of Significance框中可选相关系数的单侧(One-tailed)或双侧(Two-tailed)检验,本例选双侧检验。
图7.2 相关分析对话框点击Options...钮弹出Bivariate Correlation:Options对话框(图7.3),可选有关统计项目。

第七章相关分析任何事物的存在都不是孤立的,而是相互联系、相互制约的。
在医学领域中,身高与体重、体温与脉搏、年龄与血压等都存在一定的联系。
说明客观事物相互间关系的密切程度并用适当的统计指标表示出来,这个过程就是相关分析。
值得注意,事物之间有相关,不一定是因果关系,也可能仅是伴随关系。
但如果事物之间有因果关系,则两者必然相关。
由变量相依关系的特点,变量之间的依存关系可分为两大类型:(1)确定性关系——函数关系,例如圆面积S=πr2, y=e x+x2等。
(2)确定性关系——相关关系,例如人的血压y与年龄x之间的关系等。
以往我们讨论过的许多数学学科,如分析几何、代数等都是研究变量之间确定性关系的,但非确定性关系在自然界和我们熟知的教育领域中大量存在,例如学习成绩与智力因素或与非智力因素之间,数学成绩与物理成绩之间,性别与学习成绩之间等,都存在某种相互联系,相互制约的依存关系,这种关系不是那种严格的函数关系,而是一种非确定性的关系。
相关关系和函数关系也有联系:由于观察和测量中会产生误差,函数关系往往通过相关关系表现出来,变量间相关关系非常密切时,通常又呈现出某种函数关系趋势。
相关的种类按不同的分类标准,相关关系有多种分类1、简单相关和复相关简单相关——两个变量之间的相关关系按涉及变量的多少分复相关——一个变量与两个及以上个变量之间的相关关系2、线性相关和非线性相关线性相关(直线相关)按变量关系的表现形态,相关关系可分为非线性相关(曲线相关)3、正相关和负相关按变量数值变化方向的总趋势,相关关系可分为正相关、负相关正相关——两个变量变化方向的趋势相同(见教材P2,图1-2左)负相关——两个变量变化方向的趋势相反(见教材P2,图1-2右)4、完全相关、高度相关、低度相关和不相关按两变量联系的紧密程度分,相关关系可分为完全相关、高度相关、低度相关和不相关(零相关)相关分析的主要内容研究两个或两个以上变量之间是否存在相关关系,如果存在相关关系,其相关的性质和程度如何,这个过程在统计学上称为相关分析,相关分析的主要内容包括:1、确定变量之间有无相关关系存在,以及相关关系呈现的形态。


管理统计实验报告实验一一.实验目的掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p 值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
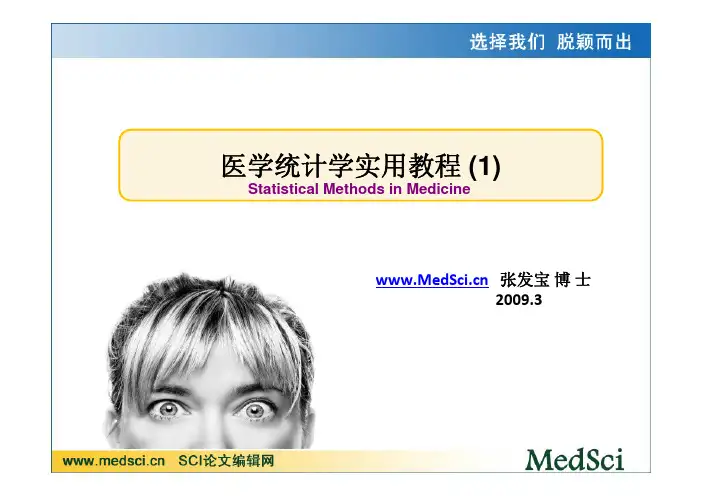
三、实验内容掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:A.点击Analyze correlate partial,系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。

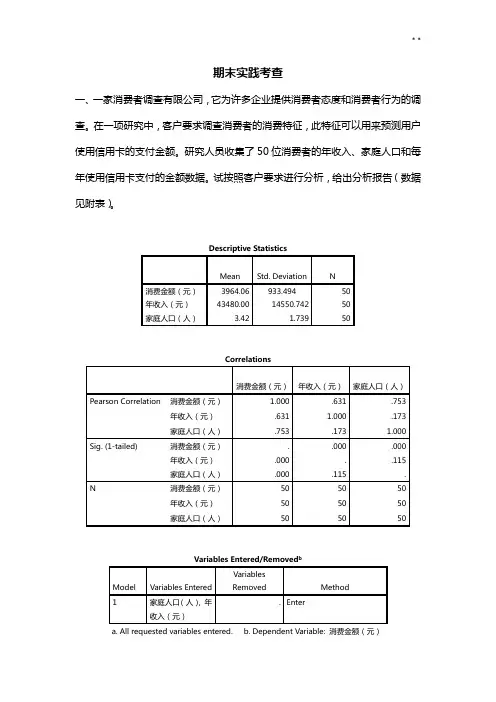
期末实践考查一、一家消费者调查有限公司,它为许多企业提供消费者态度和消费者行为的调查。
在一项研究中,客户要求调查消费者的消费特征,此特征可以用来预测用户使用信用卡的支付金额。
研究人员收集了50位消费者的年收入、家庭人口和每年使用信用卡支付的金额数据。
试按照客户要求进行分析,给出分析报告(数据见附表)。
Descriptive StatisticsMean Std. Deviation N消费金额(元)3964.06 933.494 50年收入(元)43480.00 14550.742 50家庭人口(人) 3.42 1.739 50Correlations消费金额(元)年收入(元)家庭人口(人)Pearson Correlation 消费金额(元) 1.000 .631 .753年收入(元).631 1.000 .173家庭人口(人).753 .173 1.000 Sig. (1-tailed) 消费金额(元). .000 .000年收入(元).000 . .115家庭人口(人).000 .115 .N 消费金额(元)50 50 50年收入(元)50 50 50家庭人口(人)50 50 50Model Summary bModel R R Square Adjusted RSquareStd. Error of theEstimate1 .909a.826 .818 398.091ANOVA bModel Sum of Squares df Mean Square F Sig.1 Regression 35250755.672 2 17625377.836 111.218 .000aResidual 7448393.148 47 158476.450Total 42699148.820 49Coefficients aModel Unstandardized CoefficientsStandardizedCoefficientst Sig.B Std. Error Beta1 (Constant) 1304.905 197.655 6.602 .000年收入(元).033 .004 .516 8.350 .000 家庭人口(人)356.296 33.201 .664 10.732 .000结果分析:由题目可知客户要求,是根据消费者年收入、家庭人口来预测其每年使用信用卡支付的金额数据,属于多元线性回归问题,其中年收入和家庭人口 看作两个自变量,每年信用卡支付金额看作因变量。
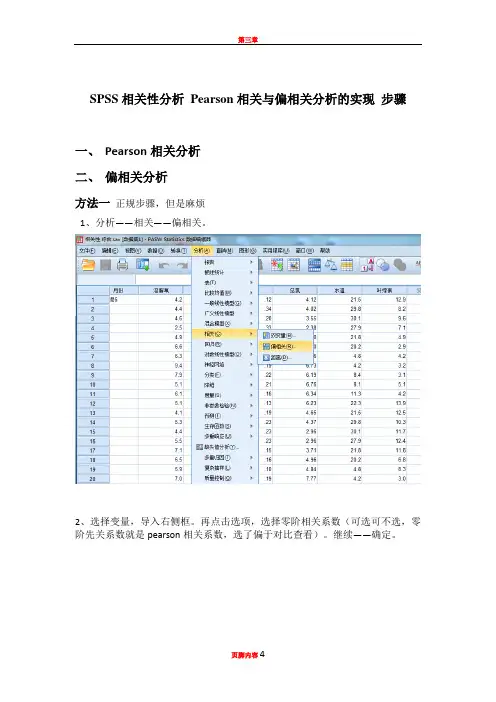
SPSS相关性分析Pearson相关与偏相关分析的实现步骤
一、Pearson相关分析
二、偏相关分析
方法一正规步骤,但是麻烦
1、分析——相关——偏相关。
2、选择变量,导入右侧框。
再点击选项,选择零阶相关系数(可选可不选,零阶先关系数就是pearson相关系数,选了偏于对比查看)。
继续——确定。
3、结果分析:总磷Pearson相关不显著,但偏相关显著。
Pearson相关系数,显著性P值为0.416>0.05,相关性不显著。
偏相关,显著性P值为0.001<o.o1,极显著相关。
(显著性看sig. P值,
P<0.05,“*”显著;
P<0.01,“**”极显著)
方法二:简便方法,快捷迅速,不用挨个分析偏相关,可以一下子出来。
1、分析——回归——线性。
2、“溶解氧、氨氮、总磷、总氮、水温”与“叶绿素”的偏相关分析。
如图,先选择变量,再选择“统计量”。
“统计量”一定要选择“部分相关和偏相关性”。
其他的可以不选。
继续—确定。
3、结果分析,分别看Sig. 显著性,和偏相关系数。
以总磷为例,与之前单独做“偏相关”分析结果是一样的。
其他变量与叶绿素的偏相关关系也可以在上表看出来。

SPSS统计软件实验指导书大庆师范学院生命科学学院徐太海2013年11月实验一描述性统计分析一、实验目的学习利用SPSS描述性统计分析。
二、实验内容及步骤实验内容:某医师测得血红蛋白值(g%)如表3.1,试利用Means过程作基本的描述性统计分析。
1.建立数据文件。
定义4个变量:ID、Gender、Age和HB,分别表示编号、性别、年龄和血红蛋白值。
2. 选择菜单“Analyze→Compare Means→Means”,弹出“Means”对话框。
在对话框左侧的变量列表中,选择变量“血红蛋白值”进入“Dependent List”列表框,选择变量“性别”进入“Independent List”,单击“Next”按钮,选择变量“年龄”进入“Independent List”。
3.单击“Options”按钮,在弹出的“选择描述统计量”对话框中设置输出的描述统计量。
4.单击“OK”按钮,得到输出结果。
实验二均值检验一、实验目的学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤(一)单样本T检验(One-Sample T Test过程)实验内容:某地区10年测得16-18岁人口的平均血红蛋白值为10.25。
现在抽查测量了该地区40个16-18岁人口的血红蛋白如表1,试分析该地区现在16-18岁人口的血红蛋白与10年前相比,是否有显著的差异?实验步骤:1.打开数据文件。
2. 选择菜单“Analyze→Compare Means→One-Sample T Test”。
弹出“One-Sample T Test”对话框。
3.在对话框左侧的变量列表中选择变量“血红蛋白”进入“Test Variable(s)”框;在“Test Value”编辑框中输入过去的平均血红蛋白值10.25.4.单击“OK”按钮,得到输出结果。
(二)双样本T检验(Independent-Samples T Test过程)实验内容:分别测得14例老年性慢性支气管炎病人及11例健康人的尿中17酮类固醇1.建立数据文件。

苏州科技大学环境学院计量地理学实验报告——SPSS软件专业班级地信学号姓名实习地点C1指导教师史守正2016 年12 月实验1:认识SPSS软件及频数分布图表的绘制实验报告1、该题目的平均数是 7.3654,标准差是 0.39596,中位数是 7.35 。
2、频数分布直方图实验2:回归分析实验报告1、某地区10名健康儿童头发和全血中的硒含量(1000ppm)如下,试作发硒与血硒的相关分析。
相关系数r是 0.872 ,检验P值是0.01 ,在0.05的水平下,r显著不显著:显著。
2、某医师测得10名3岁儿童的身高(cm)、体重(kg)和体表面积(cm2)资料如下。
试用多元回归方法确定以身高、体重为自变量,体表面积为应变量的回归方程。
回归方程是y=-2.856+0.69x1+0.184x2 ,方程是否显著:显著。
方差分析表、回归方程系数表:实验3 主成分分析四、实验报告下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行主成分分析。
X1 X2 X3 X4 X5 X6 X73.76 8.596.227.57 9.03 5.51 3.278.749.64 9.73 8.59 7.124.695.51 1.66 5.90 9.84 8.39 4.94 7.23 9.46 9.55 4.94 8.21 3.664.996.147.287.083.980.627.009.491.332.985.493.011.341.615.769.274.924.382.307.315.354.523.080.541.344.527.072.591.300.443.311.031.001.173.682.171.271.571.551.512.541.031.771.044.254.502.425.2810.029.8412.6611.766.923.3611.6813.579.879.179.725.985.812.808.8413.6010.056.687.7912.0011.748.079.109.777.502.171.794.545.337.633.5313.139.877.852.642.764.571.785.409.023.966.494.3911.582.771.793.7513.7410.162.732.106.227.308.844.7618.5211.069.913.433.555.382.097.5012.675.249.065.3716.183.512.104.664.782.131.090.821.282.408.391.122.353.702.621.192.013.433.721.971.751.432.812.272.421.051.291.729.41 6.44 5.11 12.50 2.45 3.10 0.911、KMO= 0.321Bartlett’s 球形假设适合做主成分分析。

如何用spss做相关性分析
•
•|DBQG4NOBE8KM2CR6GZWM83US94ILCFVVBJR9HEPF8WU7ONR4JD5KZ98GXIE5OPT7YGN BN6RT2X2NUI2MCI2E5JPUEYSB
•浏览:20013
•|
•更新:2014-06-14 10:19
简介
相关性是指两个变量之间的变化趋势的一致性,如果两个变量变化趋势一致,那么就可以认为这两个变量之间存在着一定的关系(但必须是有实际经济意义的两个变量才能说有一定的关系)。
相关性分析也是常用的统计方法,用SPSS统计软件操作起来也很简单,具体方法步骤如下。
1.选取在理论上有一定关系的两个变量,如用X,Y表示,数据输入到SPSS中。
2.从总体上来看,X和Y的趋势有一定的一致性。
3.为了解决相似性强弱用SPSS进行分析,从分析-相关-双变量。
4.打开双变量相关对话框,将X和Y选中导入到变量窗口。
5.然后相关系数选择Pearson相关系数,也可以选择其他两个,这个只是统计方法稍
有差异,一般不影响结论。
6.点击确定在结果输出窗口显示相关性分析结果,可以看到X和Y的相关性系数为
0.766,对应的显著性为0.076,如果设置的显著性水平位0.05,则未通过显著性检
验,即认为虽然两个变量总体趋势有一致性,但并不显著。
•相关分析研究的是两个变量的相关性,但你研究的两个变量必须是有关联的,如果你把历年人口总量和你历年的身高做相关性分析,分析结果会呈现显著地相关,但它没有实际的意义,因为人口总量和你的身高都是逐步增加的,从数据上来说是有一致性,但他们没有现实意义。
实验报告——第7章相关分析姓名杨秀娟班级人力10001 学号 10120700121 以下实验题参考教材,按照提示的步骤将内容补充完整,要求有文字说明和重要步骤截图。
【练习1】某地区10名健康儿童头发和全血中的硒含量(1000ppm)如表8-13,试作发硒与血硒的相关分析。
表8-13 儿童头发和全血中的硒含量编号发硒血硒1 74 132 73 93 66 74 96 145 66 106 88 137 69 118 58 59 91 1610 73 10【解】(1)数据准备将表8-13建立成SPSS文件,数据文件中一共有10个数据,3个变量(2)相关分析在SPSS主菜单中单击【分析】——【相关】——【双变量相关】,打开【双变量相关】主对话框:(3)结果解释:由上表可见“发硒”、“血硒”自身的相关系数均为1,而“发硒”和“血硒”的相关系数为0.872,P=0.001,P<0.01因此发硒与血硒存在显著相关性。
【练习2】已知有某河流的一年月平均流量观测数据和该河流所在地区当年的月平均雨量和月平均温度观测数据,如表8-14所示。
试分析温度与河水流量之间的相关关系。
表8-14 观测数据表月份月平均流量月平均雨量月平均气温1 0.50 0.10 -8.802 0.30 0.10 -11.003 0.40 0.40 -2.404 1.40 0.40 6.905 3.30 2.70 10.606 4.70 2.40 13.907 5.90 2.50 15.408 4.70 3.00 13.509 0.90 1.30 10.0010 0.60 1.80 2.7011 0.50 0.60 -4.8012 0.30 0.20 -6.00河流流量除了受温度影响之外,降雨量也是一个重要的影响因素。
那么要研究流量与温度的关系,有必要剔除降雨量的影响。
这就是一个把降雨量作为控制变量的偏相关分析问题。
【解】双变量相关分析(1)数据和变量说明将表8-14转换成SPSS数据文件,其中定义变量为“月份”、“月平均雨量”、“月平均流量”、“月平均气温”4个变量,共12个数据。
《血硒水平与原发性膜性肾病患者血栓形成的相关性研究》篇一摘要:本文旨在探讨血硒水平与原发性膜性肾病患者血栓形成之间的相关性。
通过对原发性膜性肾病患者进行血硒水平检测及临床资料分析,发现血硒水平与血栓形成风险之间存在一定关联。
本研究不仅为原发性膜性肾病患者的血栓预防提供了新的思路,也为临床治疗和营养干预提供了理论依据。
一、引言原发性膜性肾病是一种常见的肾脏疾病,其发病机制复杂,患者常伴有高凝状态,易发生血栓形成。
近年来,研究表明微量元素硒与人体健康密切相关,适量补充硒元素可以增强人体免疫力,降低多种疾病的风险。
因此,探究血硒水平与原发性膜性肾病患者血栓形成的关系具有重要的临床意义。
二、材料与方法1. 研究对象本研究选取了XX医院收治的原发性膜性肾病患者作为研究对象,共纳入XX例。
所有患者均经过临床诊断和实验室检查确诊为原发性膜性肾病。
2. 研究方法(1)血液样本采集:对入选患者进行血液样本采集,检测血硒水平。
(2)数据收集:收集患者的年龄、性别、病史、肾功能等相关资料。
(3)血栓形成情况统计:记录患者住院期间及随访期间的血栓形成情况。
3. 统计学分析采用SPSS软件进行数据分析,比较不同血硒水平患者的血栓形成率,分析血硒水平与血栓形成的相关性。
三、结果1. 血硒水平分布本研究中,原发性膜性肾病患者的血硒水平在正常范围内波动。
其中,血硒水平较低的患者占XX%,血硒水平较高的患者占XX%。
2. 血栓形成情况在随访期间,共XX例患者出现血栓形成。
其中,血硒水平较低的患者血栓形成率为XX%,血硒水平较高的患者血栓形成率为XX%。
经统计学分析,血硒水平与血栓形成风险之间存在显著相关性(P<0.05)。
3. 相关性分析通过相关性分析发现,血硒水平与原发性膜性肾病患者的血栓形成风险呈负相关。
即血硒水平越高,患者血栓形成风险越低。
四、讨论本研究表明,血硒水平与原发性膜性肾病患者的血栓形成风险之间存在显著相关性。
上机测试题库上机考试要求按以下步骤完成:1、资料分析分析资料的类型特点,并根据题意说明要计算的统计指标(或统计图表)和你将选择SPSS软件中的哪一种统计分析过程来完成。
2、建立数据库,录入数据,以被分析的变量为名保存数据库。
3、SPSS分析操作,并将分析结果保存。
4、对输出的统计结果进行评价。
5、将数据库、分析结果及本题签保存到以你的班级和姓名为文件名文件夹中。
1 某药物在某溶剂中溶解后的标准浓度为20.00mg/l,现采用某种方法测量该药物溶解液11次,测量后得到的结果为:20.99、20.41、20.10、20.00、20.91、22.41、20.00、23.00、22.00、19.89、21.11。
问:用该方法测量所得结果是否与标准浓度值有所不同?2 采用完全随机设计方法,将19只体重、出生日期等相仿的小白鼠随机分为两组,其中一组喂养高蛋白饲料,另一组喂养低蛋白饲料,然后观察喂养8周后各小白鼠所增体重(mg),问两组膳食对小白鼠增加体重有无不同?高蛋白组134 146 104 119 124 161 107 83 113 129低蛋白组70 118 101 85 107 132 94 97 1233 有195例肾炎患者,分别采用中药和西药的方法治疗,疗效见下表,问两组的疗效有无差异?治疗组治疗转归合计治愈未治愈西药61 83 144 中药32 19 51 合计93 102 1954冠心病复发与体育锻炼关系研究,结果见下表,问冠心病复发与体育锻炼有关系吗?冠心病复发与体育锻炼关系研究体育锻炼冠心病复发状况合计是否参加 2 62 64未参加8 42 50合计10 104 1145 随机抽取某市三个地区,调查60岁以上老年高血压患病情况,结果见下表,问三个地区的老年人高血压患病率有无差别?某市三个地区60岁以上老年高血压患病情况行政区高血压合计有无甲316 940 1256乙252 830 1082丙340 1264 1604合计908 3034 39426 2002年某市某区妇幼保健院对该区4-6岁儿童视力进行筛查,结果见下表,问不同年龄的儿童视力健康状况构成比是否有差异?年龄高血压合计异常可疑正常4 37 58 205 3005 104 236 971 13116 42 297 990 1329合计183 591 2166 29407研究者欲了解某种皮肤病的皮损程度对疗效的关系,对196名皮肤病患者进行了观察,结果见下表,问皮肤受损程度与疗效是否有关?皮损程度疗效合计显效中效微效无效恶化轻度11 27 42 53 11 144 重度7 15 16 13 1 52 合计18 42 58 66 12 1968考察硝苯地平治疗老年性支气管炎的疗效,治疗组60人,用硝苯地平治疗,对照组58人,常规治疗,两组患者的性别、年龄、病程无显著性差异,治疗结果见下表,问两组的疗效有无显著性差异?组别无效有效显效合计治疗组 6 19 35 60 对照组14 20 24 58 合计20 39 59 1189 对54例牙病患者的64颗患牙的根端形态不同分为3种,X线片显示喇叭口状为A型,管壁平行状为B型,管壁由聚状为C型,比较不同根端形态患牙的疗效有否差别。
怎么用SPSS进行相关分析相关分析是一种用来确定两个或多个变量之间关系的统计方法,其中一个比较常见的使用软件是SPSS。
在SPSS中进行相关分析包括计算相关系数以及进行显著性检验。
以下是一步一步的指导,如何使用SPSS进行相关分析。
第一步:导入数据首先,打开SPSS软件,然后导入要进行相关分析的数据集。
点击“文件”菜单,选择“打开”子菜单,然后选择数据集的位置并导入数据。
第二步:选择变量在SPSS中,要选择进行相关分析的变量,首先需要将这些变量放入一个变量列表中。
点击顶部菜单的“数据”选项,然后选择“选择变量”。
在弹出的对话框中,选择要进行相关分析的变量,并将它们添加到变量列表中。
可以通过按住Ctrl键同时点击变量名称,以选择多个变量。
在SPSS中进行相关分析的最常用方法是使用“相关”功能。
点击顶部菜单的“分析”选项,然后选择“相关”子菜单。
在弹出的对话框中,将要进行相关分析的变量从“可用变量”框拖放到“相关变量”的框中。
然后,可以选择计算Pearson相关系数或Spearman相关系数,也可以选择计算双尾还是单尾显著性。
点击“确定”按钮后,SPSS将计算相关系数,并在输出窗口中显示结果。
第四步:解释结果分析结果将显示在输出窗口中。
可以找到Pearson相关系数(或Spearman相关系数)和相应的显著性水平。
Pearson相关系数的取值范围在-1到1之间,接近1表示正相关,接近-1表示负相关,接近0表示无相关。
通过分析结果,可以得出结论并解释变量之间的关系。
可以引用结果中的显著性水平,以确定变量之间的关系是否具有统计学意义。
第五步:可视化结果(可选)如果需要,可以使用SPSS的绘图功能可视化相关分析的结果。
点击顶部菜单的“图表”选项,然后选择适当的图表类型,例如散点图或线图。
通过分析图表,可以更直观地观察变量之间的关系。
总结:使用SPSS进行相关分析通常包括导入数据、选择变量、进行相关分析、解释结果以及可视化结果。
SPSS学习第一章数据文件的建立数据编码Type:Numeric:数值型 string:字符串型Missing:Measure:scale定量变量 nominal定性变量根据已有的变量建立新变量1、对于数据进行重新编码Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue2、通过SPSS函数建立新变量Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if中设置要改变—continue—OK(可以对变量进行各种计算)第二章清除数据与基本统计分析1、对不合理的数据检查并清理检查:analysis-description statistic-frequencies—选入要检查的数据—OK结果:频数统计表—看是否有错误—missing system清理:1.对系统缺失值的清理Data—select case—if condition is satisfied—if—function group(missing)--下面选(missing)--continue—output(delete unselected cases)--OK—对num为哪一位的进行修改2.对sex=3的清理(直接就清除了)Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改2. 对相关变量间逻辑性检查和清理Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num 为哪一位的进行修改3.统计描述正态分布统计描述1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/2、统计描述:Analysis—descriptives--time选入—options—ok3、按照男女统计描述:data—split file –compare group –sex调入—okAnalysis-descriptive statistic –descriptive—time 调入—options选择—OK非正态分布资料统计描述1、正态性检验nonparametric2、Analysis—descriptive statistics—frequencies 选入-- statistics选择—OK第三章T检验1、单样本t检验正态性检验—analyze—compare means—one-sample t test—test value选择要对比的数值—OK2、配对样本t检验建立数据文档—两列(前和后)--正态性检验—analysis- compare means—paired sample t test –调入—ok3、两独立样本t检验(正态性检验的时候采用分开组,其他都要合并在一起)建立数据库—第一列(group)第二列(数值)-- data—split file –compare group—调入group—ok-正态性检验—OK-- data—split file—选择analysis all—analyze—compare means—independent sample t test—选入,分组—OK结果分方差齐与否第四章方差分析(前提正态)1、单因素方差分析(就是平常的三个组比较)建立数据库—第一列(group)第二列(数值)- data—split file –compare group—调入group—ok-正态性检验—OK-- data—split file—选择analysis all--analyze—compare means—one-way-anova—数据调入dependent list—分组调入factor------options—descriptive基本统计描述—homogeneity of variance做方差齐性分析—OK2、方差分析两两比较analyze—compare means—one-way-anova---数据调入dependent list—分组调入factor—点post hoc—选择SNK LSD3、随机区组设计方差分析建立数据库—第一列(group)第二列(block)第三列(数值)--按照group split开,进行正态性检验—OK—general liner model—univairate—数值调入dependent variable—group和block调入fixed factor—model—custom—build terms(main effects)再把group和block调入model下的矩形框---continue—OK如果区组间无差别,组间进行两两比较。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。