log4j日志框架的设计和实现
- 格式:docx
- 大小:30.68 KB
- 文档页数:6

log4j 漏洞原理
log4j是一个流行的日志框架,它提供了丰富的日志输出方式和配置选项。
然而,最近爆出了一个严重的漏洞,被命名为
log4shell,它允许攻击者远程执行任意代码,甚至获取系统权限。
该漏洞的原理是利用 log4j 的 JNDI 功能,通过构造特殊的日志消息,在服务器上触发 JNDI 查询并加载远程服务器上的恶意代码。
攻击者可通过控制恶意服务器上的代码,获取系统权限或执行任意命令,造成极大的危害。
受影响的版本包括 log4j 2.0-beta9 至 2.14.1,建议尽快升级至最新版本。
同时,可以通过禁用 JNDI 功能或限制 JNDI 查询的范围等方式,降低风险。
该漏洞已被广泛利用,各大厂商也纷纷发布了安全补丁。
作为开发者和系统管理员,我们需要及时关注并采取相应措施,确保系统安全。
- 1 -。
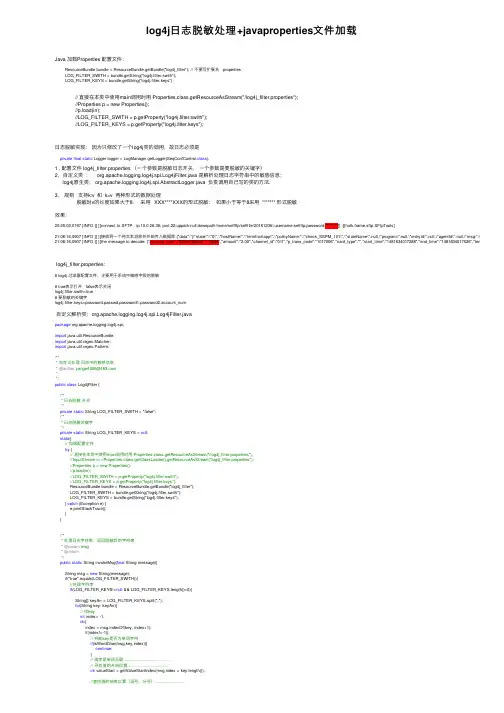
log4j⽇志脱敏处理+javaproperties⽂件加载Java 加载Properties 配置⽂件:ResourceBundle bundle = ResourceBundle.getBundle("log4j_filter"); // 不要写扩展名 .propertiesLOG_FILTER_SWITH = bundle.getString("log4j.filter.swith");LOG_FILTER_KEYS = bundle.getString("log4j.filter.keys"); // 直接在本类中使⽤main调⽤时⽤ Properties.class.getResourceAsStream("/log4j_filter.properties"); //Properties p = new Properties(); //p.load(in); //LOG_FILTER_SWITH = p.getProperty("log4j.filter.swith"); //LOG_FILTER_KEYS = p.getProperty("log4j.filter.keys");⽇志脱敏实现:因为只修改了⼀个log4j类的调⽤,故⽇志必须是private final static Logger logger = LogManager.getLogger(SeqConfControl.class);1 , 配置⽂件 log4j_filter.properties (⼀个参数是脱敏⽇志开关,⼀个参数是要脱敏的关键字)2,⾃定义类: org.apache.logging.log4j.spi.Log4jFilter.java 是解析处理⽇志字符串中的敏感信息;log4j原⽣类: org.apache.logging.log4j.spi.AbstractLogger.java 负责调⽤⾃⼰写的类的⽅法.3,规则⽀持k:v 和 k=v 两种形式的数据处理脱敏时v的长度如果⼤于8,采⽤ XXX****XXX的形式脱敏;如果⼩于等于8采⽤ ******* 形式脱敏效果:20:25:02,0197 [INFO ][ ][connect to SFTP . ip:10.0.26.36; port:22;uppath:null;downpath:home/selfftp/selffile/20161209/;username:selfftp;password:********][ :][hulk.frame.sftp.SFtpTools]21:06:16,0907 [INFO ][ ][接收到⼀个纯⽂本消息并开始传⼊数据库:{"data":"{\"state\":\"0\",\"hostName\":\"termfrontapp\",\"policyName\":\"check_SSPM_101\",\"stateName\":null,\"program\":null,\"entryId\":null,\"agentId\":null,\"msg\":\"{\\\21:06:16,0907 [INFO ][ ][the message to decode: {"account_num":"62294785200****0034","amount":"2.00","channel_id":"01I","p_trans_code":"1017006","card_type":"","start_time":"1481634017288","end_time":"1481634017526","term_id":"01159log4j_filter.properties:# log4j 过滤器配置⽂件,主要⽤于系统中敏感字段的脱敏# true表⽰打开 false表⽰关闭log4j.filter.swith=true# 要脱敏的关键字log4j.filter.keys=password,passwd,password1,password2,account_num⾃定义解析类:org.apache.logging.log4j.spi.Log4jFilter.javapackage org.apache.logging.log4j.spi;import java.util.ResourceBundle;import java.util.regex.Matcher;import java.util.regex.Pattern;/*** ⾃定义处理⽇志中的敏感信息* @author yangw1006@**/public class Log4jFilter {/*** ⽇志脱敏开关*/private static String LOG_FILTER_SWITH = "false";/*** ⽇志脱敏关键字*/private static String LOG_FILTER_KEYS = null;static{// 加载配置⽂件try {// 直接在本类中使⽤main调⽤时⽤ Properties.class.getResourceAsStream("/log4j_filter.properties");//InputStream in =Properties.class.getClassLoader().getResourceAsStream("log4j_filter.properties");//Properties p = new Properties();//p.load(in);//LOG_FILTER_SWITH = p.getProperty("log4j.filter.swith");//LOG_FILTER_KEYS = p.getProperty("log4j.filter.keys");ResourceBundle bundle = ResourceBundle.getBundle("log4j_filter");LOG_FILTER_SWITH = bundle.getString("log4j.filter.swith");LOG_FILTER_KEYS = bundle.getString("log4j.filter.keys");} catch (Exception e) {e.printStackTrace();}}/*** 处理⽇志字符串,返回脱敏后的字符串* @param msg* @return*/public static String invokeMsg(final String message){String msg = new String(message);if("true".equals(LOG_FILTER_SWITH)){//处理字符串if(LOG_FILTER_KEYS!=null && LOG_FILTER_KEYS.length()>0){String[] keyArr = LOG_FILTER_KEYS.split(",");for(String key: keyArr){// 找keyint index= -1;do{index = msg.indexOf(key, index+1);if(index!=-1){// 判断key是否为单词字符if(isWordChar(msg,key,index)){continue;}// 确定是单词⽆疑....................................// 寻找值的开始位置.................................int valueStart = getValueStartIndex(msg,index + key.length());//查找值的结束位置(逗号,分号)........................int valueEnd = getValuEndEIndex(msg,valueStart);// 对获取的值进⾏脱敏String subStr = msg.substring(valueStart, valueEnd);subStr = tuomin(subStr);///////////////////////////msg = msg.substring(0,valueStart) + subStr + msg.substring(valueEnd); }}while(index!=-1);}}}return msg;}private static Pattern pattern = pile("[0-9a-zA-Z]");/*** 判断从字符串msg获取的key值是否为单词, index为key在msg中的索引值* @return*/private static boolean isWordChar(String msg,String key, int index){// 必须确定key是⼀个单词............................if(index!=0){ //判断key前⾯⼀个字符char preCh = msg.charAt(index-1);Matcher match = pattern.matcher(preCh+"");if(match.matches()){return true;}}//判断key后⾯⼀个字符char nextCh = msg.charAt(index+key.length());Matcher match = pattern.matcher(nextCh+"");if(match.matches()){return true;}return false;}/*** 获取value值的开始位置* @param msg 要查找的字符串* @param valueStart 查找的开始位置* @return*/private static int getValueStartIndex(String msg, int valueStart ){// 寻找值的开始位置.................................do{char ch = msg.charAt(valueStart);if(ch == ':' || ch == '='){ // key 与 value的分隔符valueStart ++;ch = msg.charAt(valueStart);if(ch == '"'){valueStart ++;}break; //找到值的开始位置}else{valueStart ++;}}while(true);return valueStart;}/*** 获取value值的结束位置* @return*/private static int getValuEndEIndex(String msg,int valueEnd){do{if(valueEnd == msg.length()){break;}char ch = msg.charAt(valueEnd);if(ch == '"'){ // 引号时,判断下⼀个值是结束,分号还是逗号决定是否为值的结束if(valueEnd+1 == msg.length()){break;}char nextCh = msg.charAt(valueEnd+1);if(nextCh ==';' || nextCh == ','){// 去掉前⾯的 \ 处理这种形式的数据 "account_num\\\":\\\"6230958600001008\\\"while(valueEnd>0 ){char preCh = msg.charAt(valueEnd-1);if(preCh != '\\'){break;}valueEnd--;}break;}else{valueEnd ++;}}else if (ch ==';' || ch == ','){break;}else{valueEnd ++;}}while(true);return valueEnd;}private static String tuomin(String submsg){StringBuffer sbResult = new StringBuffer();if(submsg!=null && submsg.length()>0){int len = submsg.length();if(len > 8){ //8位以上的隐掉中间4位for(int i = len-1;i>=0;i--){if(len-i<5 || len-i>8){sbResult.insert(0, submsg.charAt(i));}else{sbResult.insert(0, '*');}}}else{ //8位以下的全部使⽤ *for(int i =0;i<len;i++){sbResult.append('*');}}}return sbResult.toString();}public static void main (String[] args) {//{\\\"account_num\\\":\\\"6230958600001008\\\",\\\"amount\\\":\\\"\\\"String msg = "\\\"account_num\\\":\\\"6230958600001008\\\",\\\"amount\\\":\\\"\\\"";System.out.println(invokeMsg(msg));}}log4j原⽣类 org.apache.logging.log4j.spi.AbstractLogger.java 修改的地⽅# 代码 725⾏左右的⽅法protected void logMessage(final String fqcn, final Level level, final Marker marker, final String message, final Throwable t) { // by yangwString invokeMsg = Log4jFilter.invokeMsg(message);logMessage(fqcn, level, marker, messageFactory.newMessage(invokeMsg), t);}。

RCP随着信息技术的不断发展,越来越多的企业和组织依赖于软件系统进行业务运营和管理。
而软件系统的稳定性和可靠性一直是企业和组织的重要关注点。
在这个过程中,日志是非常重要的一环。
软件系统会产生大量的日志,这些日志包含了系统的运行状态、异常信息、性能指标等重要信息。
通过对这些日志的收集和分析,可以及时发现系统故障、优化性能,提高系统的可靠性和稳定性。
本文将介绍RCP 程序的日志收集与分析实践。
一、RCP 程序简介RCP ( Rich Client Platform)是一个基于Eclipse 的框架,用于开发客户端应用程序。
RCP 程序可以在多个操作系统平台上运行,包括Windows、Linux 和Mac OS 等。
RCP 程序的架构分为三层:应用层、中间件层和系统层。
应用层包括用户界面、业务逻辑和数据持久化。
中间件层包括服务注册、服务提供和服务调用等。
系统层包括操作系统和底层接口。
二、RCP 程序的日志收集RCP 程序的日志信息最终会被输出到一个日志文件中。
在调试和问题排查时,需要查看日志文件中的信息。
因此,正确地配置日志输出非常重要。
下面介绍RCP 程序日志收集的实践:1. 使用log4j 作为日志框架:log4j 是一个开源的Java 日志框架,被广泛应用于Java 应用程序的日志记录。
在RCP 程序中,可以通过在插件中集成log4j,并通过配置文件设置日志输出级别和输出目的地。
下面是一个示例的log4j 配置文件:```log4j.rootLogger=INFO,FILElog4j.appender.FILE=org.apache.log4j.RollingFileAppenderlog4j.appender.FILE.File=${workspace_loc}/logs/eclipse.loglog4j.appender.FILE.MaxFileSize=10MBlog4j.appender.FILE.MaxBackupIndex=5yout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %p [%c] - %m%n```其中,rootLogger 设置日志输出级别为INFO,表示只输出INFO 级别及以上的日志信息;appender.FILE 设置输出目的为一个滚动式日志文件,文件大小不超过10MB,保留5 个备份文件;layout.ConversionPattern 设置日志输出格式。

JAVAlog4j同一个类日志输出到不同的log文件中配置不能通过简单的配置log4j配置文件来实现,而需要在代码中调用Log4j的类来实现。
下面给出实现类:/** * @author QG * * 2010-7-22 上午10:27:50 LoggerRun.java */public class LoggerRun { //设定两个Logpublic static Logger infoLogger = Logger.getLogger("info.logger");public static Logger errorLogger = Logger.getLogger("error.logger");public static final String PROFILE = "log4j.properties";//设定异常log输出的路径private static final String PATH = Constants.PATH;static{try{URL configFileResource = (new File(LoggerRun.class.getResource("/").getPath()+PROFILE)).toUR L();PropertyConfigurator.configure(configFileResource);}catch(Exception e){e.printStackTrace();}}public LoggerRun(){try {Date date = new Date();SimpleDateFormat sf = new SimpleDateFormat("yyyyMMddHHmmss");String fileName = PATH + "exception_" +sf.format(date).toString() + ".log";FileAppender exceptionAppender = new FileAppender(new SimpleLayout(), fileName);errorLogger.addAppender(exceptionAppender);} catch (Exception e) {e.printStackTrace();}}}同时给出配置文件配置信息:.logger=INFO, info,stdoutlog4j.category.error.logger=ERROR,errorlog4j.appender.stdout=org.apache.log4j.ConsoleAppender yout=org.apache.log4j.PatternLayo utyout.ConversionPattern=%d{yyyy/ MM/dd HH:mm:ss.SSS} %-5p %m%=org.apache.log4j.RollingFileAppe nder.File=bin/log/info.log.MaxFileSize=100kb.MaxBackupIndex=4yout=org.apache.log4j.PatternLayout yout.ConversionPattern=%d{yyyy/MM /dd HH:mm:ss.SSS} %-5p %m%nlog4j.appender.error=org.apache.log4j.RollingFileApp enderlog4j.appender.error.File=bin/log/error.loglog4j.appender.error.MaxFileSize=100kblog4j.appender.error.MaxBackupIndex=4yout=org.apache.log4j.PatternLayout yout.ConversionPattern=%d{yyyy/M M/dd HH:mm:ss.SSS} %-5p %m%n在给出测试类:public class TestLog {public static final Logger logger=Logger.getLogger(T estLog.class);/** * @param args */public static void main(String[] args) {// TODO Auto-generated method stubfor(int i=0;i<10;i++){if(i<5){("TEST The Logger DUBUG");}else{LoggerRun.errorLogger.error("TEST THe LOGGER ERROR");}}}}同一个类中的日志按类型输出到了不同的日志文件中。
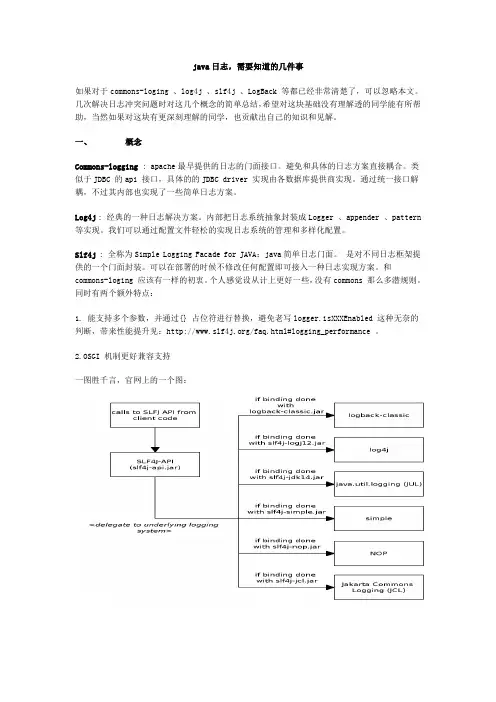
java日志,需要知道的几件事如果对于commons-loging 、log4j 、slf4j 、LogBack 等都已经非常清楚了,可以忽略本文。
几次解决日志冲突问题时对这几个概念的简单总结,希望对这块基础没有理解透的同学能有所帮助,当然如果对这块有更深刻理解的同学,也贡献出自己的知识和见解。
一、概念Commons-logging : apache最早提供的日志的门面接口。
避免和具体的日志方案直接耦合。
类似于JDBC 的api 接口,具体的的JDBC driver 实现由各数据库提供商实现。
通过统一接口解耦,不过其内部也实现了一些简单日志方案。
Log4j : 经典的一种日志解决方案。
内部把日志系统抽象封装成Logger 、appender 、pattern 等实现。
我们可以通过配置文件轻松的实现日志系统的管理和多样化配置。
Slf4j : 全称为Simple Logging Facade for JAVA:java简单日志门面。
是对不同日志框架提供的一个门面封装。
可以在部署的时候不修改任何配置即可接入一种日志实现方案。
和commons-loging 应该有一样的初衷。
个人感觉设从计上更好一些,没有commons 那么多潜规则。
同时有两个额外特点:1. 能支持多个参数,并通过{} 占位符进行替换,避免老写logger.isXXXEnabled 这种无奈的判断,带来性能提升见:/faq.html#logging_performance 。
2.OSGI 机制更好兼容支持一图胜千言,官网上的一个图:从上图可以发现,选择还是很多的。
Logback : LOGBack 作为一个通用可靠、快速灵活的日志框架,将作为Log4j 的替代和SLF4J 组成新的日志系统的完整实现。
官网上称具有极佳的性能,在关键路径上执行速度是log4j 的10 倍,且内存消耗更少。
具体优势见:http://logback.qos.ch/reasonsToSwitch.html二、常见日志方案和注意事项mons-logging+log4j : 经典的一个日志实现方案。

log4j2配置⽂件log4j2.xml解析⼀、背景最近由于项⽬的需要,我们把log4j 1.x的版本全部迁移成log4j 2.x 的版本,那随之⽽来的slf4j整合log4j的配置(使⽤Slf4j集成Log4j2构建项⽬⽇志系统的完美解决⽅案)以及log4j2配置⽂件的详解,就需要我们来好好聊⼀聊了。
本⽂就专门来讲解下log4j2.xml配置⽂件的各项标签的意义。
⼆、配置全解1.关于配置⽂件的名称以及在项⽬中的存放位置log4j 2.x版本不再⽀持像1.x中的.properties后缀的⽂件配置⽅式,2.x版本配置⽂件后缀名只能为”.xml”,”.json”或者”.jsn”.系统选择配置⽂件的优先级(从先到后)如下:(1).classpath下的名为log4j2-test.json 或者log4j2-test.jsn的⽂件.(2).classpath下的名为log4j2-test.xml的⽂件.(3).classpath下名为log4j2.json 或者log4j2.jsn的⽂件.(4).classpath下名为log4j2.xml的⽂件.我们⼀般默认使⽤log4j2.xml进⾏命名。
如果本地要测试,可以把log4j2-test.xml放到classpath,⽽正式环境使⽤log4j2.xml,则在打包部署的时候不要打包log4j2-test.xml即可。
2.缺省默认配置⽂件<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"><Appenders><Console name="Console" target="SYSTEM_OUT"><PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/></Console></Appenders><Loggers><Root level="error"><AppenderRef ref="Console"/></Root></Loggers></Configuration>3.配置⽂件节点解析(1).根节点Configuration有两个属性:status和monitorinterval,有两个⼦节点:Appenders和Loggers(表明可以定义多个Appender和Logger). status⽤来指定log4j本⾝的打印⽇志的级别.monitorinterval⽤于指定log4j⾃动重新配置的监测间隔时间,单位是s,最⼩是5s.(2).Appenders节点,常见的有三种⼦节点:Console、RollingFile、File.Console节点⽤来定义输出到控制台的Appender.name:指定Appender的名字.target:SYSTEM_OUT 或 SYSTEM_ERR,⼀般只设置默认:SYSTEM_OUT.PatternLayout:输出格式,不设置默认为:%m%n.File节点⽤来定义输出到指定位置的⽂件的Appender.name:指定Appender的名字.fileName:指定输出⽇志的⽬的⽂件带全路径的⽂件名.PatternLayout:输出格式,不设置默认为:%m%n.RollingFile节点⽤来定义超过指定⼤⼩⾃动删除旧的创建新的的Appender.name:指定Appender的名字.fileName:指定输出⽇志的⽬的⽂件带全路径的⽂件名.PatternLayout:输出格式,不设置默认为:%m%n.filePattern:指定新建⽇志⽂件的名称格式.Policies:指定滚动⽇志的策略,就是什么时候进⾏新建⽇志⽂件输出⽇志.TimeBasedTriggeringPolicy:Policies⼦节点,基于时间的滚动策略,interval属性⽤来指定多久滚动⼀次,默认是1 hour。

log4j2 filepermission的使用Log4j2是一个强大的Java日志框架,可以帮助开发人员在应用程序中实现灵活和高效的日志记录。
其中一个重要的功能是文件权限管理,它可以帮助开发人员控制日志文件的访问权限,并保护敏感数据不被非授权人员获取。
文件权限管理在Log4j2中通过使用FilePermissions属性来实现。
FilePermissions属性是一个用于指定文件权限的字符串,它可以设置读、写和执行权限。
下面是一些常用的FilePermissions属性的示例:1. "rw-rw-rw-":所有用户都有读和写的权限,没有执行的权限。
2. "rwxr-x---":所有用户都有读、写和执行的权限,但其他用户没有读、写和执行的权限。
3. "rw-------":只有文件所有者有读和写的权限,其他用户没有任何的权限。
在Log4j2中,可以通过在配置文件中添加<Properties>元素来定义FilePermissions属性的值。
例如:```<Properties><Property name="filePermissions">rw-rw-rw-</Property></Properties>```此外,还可以通过使用系统属性来动态设置FilePermissions属性的值。
例如,可以在程序启动时设置System Property来指定FilePermissions属性的值。
下面是一个设置FilePermissions属性的示例:```javaSystem.setProperty("log4j2.filePermissions", "rw-rw-rw-");```设置FilePermissions属性后,Log4j2会将此属性应用到所有生成的日志文件上。

idea插件开发日志打印开发日志打印是一种常见的技术实践,它可以帮助开发人员在开发过程中记录关键信息、调试代码以及追踪问题。
在开发 IDEA 插件时,我们可以使用不同的方法来实现日志打印。
下面我将从多个角度来回答这个问题。
首先,我们可以使用 Java 自带的日志框架,如java.util.logging 或 log4j。
这些框架提供了一套丰富的 API,可以用于在插件代码中打印日志。
我们可以通过配置日志级别来控制日志的输出,从而在不同的场景下灵活地记录信息。
使用这些框架,我们可以在插件代码中添加日志语句,并在运行时将日志输出到控制台或者指定的日志文件中。
其次,JetBrains 提供了自己的日志框架,即 JetBrains Logger。
这个框架是专门为开发 IDEA 插件而设计的,它提供了一些特定的 API,可以方便地在插件代码中打印日志。
使用JetBrains Logger,我们可以通过调用`Logger.getInstance(Class)` 方法获取一个 Logger 实例,然后使用该实例的方法来记录日志。
这个框架还支持在插件配置文件中配置日志级别和输出目标。
此外,我们还可以使用 System.out.println 或System.err.println 方法在插件代码中打印日志。
这种方法简单直接,适用于快速调试和验证想法。
但需要注意的是,这种方式输出的日志会直接打印在控制台上,可能会与其他插件或应用程序的输出混合在一起,不够规范和可控。
另外,为了更好地管理和查看日志,我们可以考虑使用专门的日志库或工具。
例如,我们可以使用 Logback 或 Log4j2 这样的日志库,它们提供了更丰富的功能和配置选项。
此外,IDEA 自带了一个 Log Viewer 插件,可以方便地查看和搜索日志文件。
总结来说,在开发 IDEA 插件时,我们可以选择使用 Java 自带的日志框架、JetBrains Logger、System.out.println 或者第三方日志库来实现日志打印。

在struts2框架下,使用AOP(面向切面编程)实现日志管理是一个常见的需求。
在实际开发中,我们经常需要对一些方法进行日志记录,以便在出现问题时进行排查和分析。
本文将从以下几个方面介绍在struts2框架下使用AOP实现日志管理部分方法的方法。
一、AOP概述AOP是一种编程范式,它通过预编译方式和运行期动态代理实现系统功能的增强。
在struts2框架中,我们可以使用AOP来实现日志管理、事务管理、安全检查等功能。
通过AOP,我们可以将这些功能与业务逻辑解耦,提高系统的可维护性和复用性。
二、使用Log4j记录日志在struts2框架下,我们通常使用Log4j来记录日志。
Log4j是一个功能强大的日志框架,它可以对日志信息进行灵活的配置和管理。
我们可以通过在方法中插入Log4j的日志记录代码,来实现对方法的日志管理。
三、编写Aspect类在struts2框架中,我们可以通过编写Aspect类来实现AOP。
Aspect类是一个Java类,其中包含了我们希望在方法执行前、执行后或出现异常时执行的代码。
在Aspect类中,我们可以通过注解或XML配置的方式来定义切点和通知。
切点用于指定哪些方法需要被增强,通知用于定义增强逻辑。
四、定义切点和通知通过在Aspect类中定义切点和通知,我们可以精确地控制增强的范围和逻辑。
切点可以使用通配符、正则表达式等方式来指定目标方法,通知可以分为前置通知、后置通知、环绕通知和异常通知。
通过合理地定义切点和通知,我们可以实现对特定方法的日志管理。
五、配置Spring AOP在struts2框架中,我们可以通过配置Spring AOP来实现AOP。
Spring AOP是基于代理的AOP框架,它可以与struts2框架无缝集成。
我们可以通过在Spring配置文件中定义Aspect类和切点,来实现对方法的日志管理。
六、示例代码以下是一个在struts2框架下使用AOP实现日志管理的示例代码:```java//Aspect类public class LogAspect {@Before("execution(*.example.service.*.*(..))")public void beforeLog(JoinPoint joinPoint){String methodName = joinPoint.getSignature().getName(); String className =joinPoint.getTarget().getClass().getName();System.out.println(className + "的" + methodName + "方法开始执行");}@After("execution(*.example.service.*.*(..))")public void afterLog(JoinPoint joinPoint){String methodName = joinPoint.getSignature().getName(); String className =joinPoint.getTarget().getClass().getName();System.out.println(className + "的" + methodName + "方法执行结束");}}``````xml<!--Spring配置文件--><bean id="logAspect" class=.example.aspect.LogAspect"/><bean id="logInterceptor"class="org.springframework.aop.framework.autoproxy.BeanNa meAutoProxyCreator"><property name="proxyTargetClass" value="true"/><property name="beanNames"><list><value>*Service</value></list></property><property name="interceptorNames"><list><value>logAspect</value></list></property></bean>```七、总结在struts2框架下使用AOP实现日志管理是一个非常有用的功能。

log设计方案日志是软件系统中记录运行时状态和事件的重要工具。
通过日志,我们可以了解系统的运行情况,快速定位问题,进行故障排查和分析,从而提高软件系统的可维护性和可靠性。
在设计日志系统时,需要考虑以下几个方面。
首先是日志的存储方式。
日志可以存储在本地文件系统中,也可以存储在远程服务器或云存储中。
对于大规模分布式系统,通常采用集中存储的方式,将所有服务的日志统一存储在一个中心化的位置,方便管理和查询。
常见的集中化存储方案有Hadoop、Elasticsearch、Kafka等。
其次是日志的格式化方式。
日志格式化是为了方便日志的收集、存储和查询。
通常采用的格式有文本格式、JSON格式和XML格式。
文本格式简单直观,易于阅读,但不便于自动化处理和分析。
JSON格式和XML格式具有更好的结构性,可以方便地提取和处理特定字段的信息,但相对于文本格式来说,对存储空间的占用更大。
再次是日志的级别和分类。
日志可以按照严重性分为不同的级别,比如DEBUG、INFO、WARN、ERROR等。
根据实际需要,可以定义更细粒度的级别。
日志还可以按照不同的功能模块或模块间的关系进行分类,以方便快速定位问题。
一个常见的做法是使用不同的日志文件或日志目录来存储不同级别或不同分类的日志。
此外,还需要考虑日志的输出方式和目标。
日志可以输出到标准输出、文件、数据库、消息队列等不同的目标。
对于实时性要求较高的日志,比如错误日志,可以将其输出到标准输出或消息队列中,以便及时通知运维人员。
对于历史性和可追溯性较重要的日志,比如访问日志,可以将其输出到文件或数据库中,以便进行长期存储和查询。
最后,还需要考虑日志的性能和可扩展性。
日志是系统运行的重要组成部分,它的记录和输出会产生一定的开销。
为了保证系统的正常运行,需要控制日志的开销,并合理地进行策略,比如选择合适的日志级别、限制日志文件大小和数量、异步输出等。
同时,需要考虑日志系统的可扩展性,以适应系统规模的增长和日志数据的增加。

Log4j手册文档版本:1.1编者:陈华联系方式:clinker@发布日期:2006年4月5日1. 简介 (1)1. 简介 (3)1.1 概述 (3)1.2 主要组件 (3)2. Logger (4)2.1 层次结构 (4)2.2 输出级别 (5)3. Appenders (7)3.1 概念说明 (7)3.2 Appender的配置 (7)3.3 Appender的添加性 (8)4. Layouts (8)4.1 概念说明 (8)4.2 Layout的配置 (9)5. 配置 (10)6. 默认的初始化过程 (13)7. 配置范例 (14)7.1 Tomcat (14)8. Nested Diagnostic Contexts (14)9. 优化 (15)9.1 日志为禁用时,日志的优化 (15)9.2 当日志状态为启用时,日志的优化 (16)9.3 日志信息的输出时,日志的优化 (16)10. 总结 (16)11. 附录 (17)11.1 参考文档 (17)11.2 比较全面的配置文件 (17)11.3 日志乱码的解决 (19)1. 简介1.1 概述程序开发环境中的日志记录是由嵌入在程序中以输出一些对开发人员有用信息的语句所组成。
例如,跟踪语句(trace),结构转储和常见的System.out.println或printf调试语句。
log4j提供分级方法在程序中嵌入日志记录语句。
日志信息具有多种输出格式和多个输出级别。
使用一个专门的日志记录包,可以减轻对成千上万的System.out.println语句的维护成本,因为日志记录可以通过配置脚本在运行时得以控制。
log4j维护嵌入在程序代码中的日志记录语句。
通过规范日志记录的处理过程,一些人认为应该鼓励更多的使用日志记录并且获得更高程度的效率。
1.2 主要组件Log4j有三个主要组件: loggers、appenders和layouts。
这三个组件协同工作,使开发人员能够根据消息类型和级别来记录消息,并且在程序运行期控制消息的输出格式位置。
Document number 文档编号Confidentiality level 密级内部公开Document version 文档版本Total 25 pages 共25 页V1.0流程详细设计Prepared by拟制王先红Date日期2012-3-18Reviewed by 评审人Date 日期Approved by批准Date 日期1流程框架1.1架构模式流程采用一套独立的框架,与业务平台没有任何依赖。
其架构模式为:1)采用log4j为日志框架。
2)单元测试使用junit4.0框架。
3)定义config.xml文件,所有的数据访问对象与业务逻辑对象的注册,外部接口的获取,均配置在这里。
4)底层实体po包,封装所有数据库的表结构;5)底层数据访问对象dao包,由一个接口类与一个通用的UDao类组成,即所有的数据操作均由UDao去实现;6)异常类均封装在exception包中;7)业务逻辑封装在biz包中,这里是流程所有的对外调用接口,即业务平台与流程的接口都定义在这里。
8)数据库的连接获取定义在db包,这里只管从业务平台获取连接,不包括连接的释放,事务的提交与回滚。
9)一个连接工厂包,主要用来获取config.xml中的对象。
1.2主键生成器在一个数据库设计里,假如使用了逻辑主键,那么你一般都需要一个ID生成器去生成逻辑主键。
在许多数据库里面,都提供了ID生成的机制,如Oracle中的sequence,MSSQL中的identity,可惜这些方法各种数据库都不同的,所以需要找寻一种通用的方式。
如果用字符串的形式,在集群的时候就不行了,通常还需要加上IP的前缀,即IP + 时间+ 计数器,这个就是JA V A原版本的实现了。
但是,这样这个ID就会太长了。
并且,字符串主键本身就存在效率问题,所以还是要考虑用数字主键,用一张表来保存,但取主键的时侯,必须用同步synchronized的方法来做,否则肯定会重复。
timebasedrollingpolicy参数在Java日志框架中,Log4j是一个非常流行的日志框架。
它允许程序员将不同级别的日志记录到不同的文件中,并轻松地对其进行配置。
其中,timebasedrollingpolicy参数则是Log4j中一个非常重要的参数,用于设置日志文件的滚动策略。
Step 1:了解Log4j的基本概念在使用“timebasedrollingpolicy参数”之前,需要先了解Log4j中的几个基本概念。
其中,Logger是Log4j中最重要的类之一,用于记录不同级别的日志。
除了Logger之外,还有Appender(用于将日志输出到不同的目标,例如控制台、文件等)、Layout(用于确定日志的格式)等。
Step 2:了解日志滚动的概念在Log4j中,日志文件的滚动是指当日志达到一定大小或时间后,自动创建一个新的日志文件,以避免日志文件过大或日志被覆盖的情况。
这就是所谓的“Rolling”。
Step 3:了解timebasedrollingpolicy参数在Log4j中,可以通过设置RollingFileAppender的相应参数来实现日志滚动。
其中,timebasedrollingpolicy参数用于根据时间滚动日志文件。
它支持以下几个子属性:- FileNamePattern:用于指定日志文件的命名格式。
例如,如果设置为“myapp.%d{yyyy-MM-dd}.log”,则会创建一个以日期命名的日志文件。
- ActiveFileName:用于指定当前活动的日志文件的文件名。
- rollover:在切换到一个新的日志文件之前,要记录多少个日志事件。
- TimeZone:时区设置,可以指定特定的时区来滚动日志文件。
Step 4:应用timebasedrollingpolicy参数使用“timebasedrollingpolicy参数”来实现日志滚动非常简单。
首先,需要在Log4j配置文件中定义RollingFileAppender,并设置对应的参数。
⽇志组件slf4j介绍及配置详解1 基本介绍每⼀个Java程序员都知道⽇志对于任何⼀个Java应⽤程序尤其是服务端程序是⾄关重要的,⽽很多程序员也已经熟悉各种不同的⽇志库,如java.util.logging、Apache log4j、logback。
但如果你还不知道SLF4J(Simple logging facade for Java)的话,那么是时候在你的项⽬中学习使⽤SLF4J了。
SLF4J不同于其他⽇志类库,与其它⽇志类库有很⼤的不同。
SLF4J(Simple logging Facade for Java)不是⼀个真正的⽇志实现,⽽是⼀个抽象层( abstraction layer),它允许你在后台使⽤任意⼀个⽇志类库。
如果是在编写供内外部都可以使⽤的API或者通⽤类库,那么你真不会希望使⽤你类库的客户端必须使⽤你选择的⽇志类库。
如果⼀个项⽬已经使⽤了log4j,⽽你加载了⼀个类库,⽐⽅说 Apache Active MQ——它依赖于于另外⼀个⽇志类库logback,那么你就需要把它也加载进去。
但如果Apache Active MQ使⽤了SLF4J,你可以继续使⽤你的⽇志类库⽽⽆需忍受加载和维护⼀个新的⽇志框架的痛苦。
总的来说,SLF4J使你的代码独⽴于任意⼀个特定的⽇志API,这是对于API开发者的很好的思想。
虽然抽象⽇志类库的思想已经不是新鲜的事物,⽽且Apache commons logging也已经在使⽤这种思想了,但SLF4J正迅速成为Java世界的⽇志标准。
让我们再看⼏个使⽤SLF4J⽽不是log4j、logback或者java.util.logging的理由。
2 SLF4J对⽐Log4J,logback和java.util.Logging的优势正如我之前说的,在你的代码中使⽤SLF4J写⽇志语句的主要出发点是使得你的程序独⽴于任何特定的⽇志类库,依赖于特定类库可能需要使⽤不同于你已有的配置,并且导致更多维护的⿇烦。
实例#定义log输出级别log4j.rootLogger=debug,CONSOLE#log4j.rootLogger=INFO,DEFAULT#定义日志输出目的地:控制台log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender#日志输出格式,下面一行是指定具体的格式yout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%d{yyyy-MM-ddHH:mm:ss,SSS}[%c]-[%p]%m%n#按一定的频度滚动日志记录文件log4j.appender.DEFAULT=org.apache.log4j.DailyRollingFileAppender#DatePattern,精确到dd为每天log4j.appender.DEFAULT.DatePattern='.'yyyy-MM-dd#append的值为true为增加,false则为覆盖log4j.appender.DEFAULT.Append=true#file 指定日志输出目录log4j.appender.DEFAULT.File=D:/logs/default.log#日志输出格式yout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%d{yyyy-MM-ddHH:mm:ss,SSS}[%c]-[%p]%m%n% 含义:%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日22:10:28,921 %r: 输出自应用启动到输出该log信息耗费的毫秒数%c: 输出日志信息所属的类目,通常就是所在类的全名%t: 输出产生该日志事件的线程名%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。
log4j集成syslog配置说明1.更改接收日志主机syslog配置在syslogd_uu添加\CX\in选项中编辑/etc/sysconfig/syslog,如下所示:#optionstosyslogd#-M0禁用“标记”消息。
#-renablesloggingfromremotemachines#-xDisablesDnsLookupsonMessagesReceivedWith-r#有关详细信息Syslogd_u选项,请参阅Syslogd(8)=\2.修改syslog的配置文件/etc/syslog.conf,在最后加上如下内容(注意中间的空白必必须是制表键,而不是空格,无限数,记住!)本地6.*/Var/log/log文件名log系统默认提供facility变量包括:local0-local7,可自行选择。
如果不想将日志写入/var/log/messages,则必须*.info;mail.none;news.none;authpriv.none;cron.none/var/log/messages中把local6排除,变为:*.信息;邮政没有一个消息没有一个authpriv。
没有一个克朗。
没有一个地方的无/var/log/messages3.重新启动syslog服务servicesyslogrestartservicesyslogstatus:查看syslog是否开启成功4.检查540端口是否打开netstat-tunl|grep5145.检查防火墙是否关闭serviceiptablesstatus6.为了测试配置是否正确,可以使用以下语句进行测试#/usr/bin/“hellohhhh”,查看日志中是否正确写入。
7.log4j。
属性配置在log4j.rootlogger中增加一个appender,如:sysloglog4j.appender.syslog=.syslogappenderlog4j.appender. syslog.sysloghost=172.16.250.198log4j.appender.syslog.facility=local6log4j.app ender.syslog.header=truelog4j.appender.syslog.threshold=infolog4j。
一、概述log4j2是一个广泛使用的Java日志框架,它具有丰富的功能和灵活的配置选项。
在使用log4j2时,文件输出是一种常见的日志记录方式,而filepattern命名规则则是控制日志文件命名和轮转的重要配置参数之一。
本文将对log4j2的filepattern命名规则进行详细介绍,以帮助开发者更好地理解和使用该功能。
二、filepattern命名规则的作用filepattern命名规则是用来指定日志文件的命名格式和轮转策略的。
通过合理设置filepattern,开发者可以实现按时间、文件大小等条件对日志文件进行轮转和命名,从而满足不同的日志记录需求。
三、filepattern命名规则的语法在log4j2中,filepattern命名规则的语法如下所示:${prefix}-d{yyyyMMdd-HHmm}-i.log.gz其中:1. ${prefix}:表示文件名的前缀部分,可以根据实际需求进行设置。
2. d{yyyyMMdd-HHmm}:表示日期格式的占位符,用于指定日期的格式和精度。
3. i:表示轮转索引,用于区分同一时刻生成的不同日志文件。
4. .log.gz:表示日志文件的后缀名,可以根据实际需求进行设置。
四、filepattern命名规则的示例下面是几个常见的filepattern命名规则示例:1. ${prefix}-d{yyyyMMdd}.log:表示以日期为单位轮转的日志文件,例如:app-xxx.log、app-xxx.log等。
2. ${prefix}-d{yyyyMMdd-HH}.log:表示以小时为单位轮转的日志文件,例如:app-xxx-01.log、app-xxx-02.log等。
3. ${prefix}-d{yyyyMMdd-HHmm}-i.log.gz:表示以分钟为单位轮转的压缩日志文件,例如:app-xxx-0101-1.log.gz、app-xxx-0101-2.log.gz等。
1 简介 日志系统是一种不可或缺的跟踪调试工具,特别是在任何无人职守的后台程序以及那些没有跟踪调试环境的系统中有着广泛的应用。 长期以来, 日志系统作为一种应用程序服务,对于跟踪调试、程序状态记录、崩溃数据恢复都有非常现实的意义。这种服务通常以两种方式存在: 1. 日志系统作为服务进程存在。 Windows 中的的事件日志服务就属于这种类型,该类型的日志系统通常通过消息队列机制将所需要记录的日志由日志发送端发送给日志服务。日志发送端和日志保存端通常不在同一进程当中,日志的发送是异步过程。这种日志服务通常用于管理员监控各种系统服务的状态。 2. 日志系统作为系统调用存在。 Java 世界中的日志系统和 Unix 环境下诸多守护进程所使用的日志系统都属于这种类型。日志系统的代码作为系统调用被编译进日志发送端,日志系统的运行和业务代码的运行在同一进程空间。日志的发送多数属于同步过程。这种日志服务由于能够同步反映处系统运行状态,通常用于调试跟踪和崩溃恢复。 本文建立的日志系统基本属于第二种类型,但又有所不同。该日志系统将利用 Java 线程技术实现一个既能够反映统一线程空间中程序运行状态的同步日志发送过程,又能够提供快速的日志记录服务,还能够提供灵活的日志格式配置和过滤机制。 1.1 系统调试的误区 在控制台环境上调试 Java 程序时,此时往控制台或者文本文件输出一段文字是查看程序运行状态最简单的做法,但这种方式并不能解决全部的问题。有时候,对于一个我们无法实时查看系统输出的系统或者一个确实需要保留我们输出信息的系统,良好的日志系统显得相当必要。 因此,不能随意的输出各种不规范的调试信息,这些随意输出的信息是不可控的,难以清除,可能为后台监控、错误排除和错误恢复带来相当大的阻力。 1.2 日志系统框架的基本功能 一个完备的日志系统框架通常应当包括如下基本特性:
1. 所输出的日志拥有自己的分类。这样在调试时便于针对不同系统的不同模块进行查询,从而快速定位到发生日志事件的代码。 2. 日志按照某种标准分成不同级别。分级以后的日志,可以用于同一分类下的日志筛选。 3. 支持多线程。日志系统通常会在多线程环境中使用,特别是在 Java 系统当中,因此作为一种系统资源,日志系统应当保证是线程安全的。 4. 支持不同的记录媒介。不同的工程项目往往对日志系统的记录媒介要求不同,因此日志系统必须提供必要的开发接口,以保证能够比较容易的更换记录介质。 5. 高性能。日志系统通常要提供高速的日志记录功能以应对大系统下大请求流量下系统的正常运转。 6. 稳定性。日志系统必须是保持高度的稳定性,不能因为日志系统内部错误导致主要业务代码的崩溃。
1.3 常用日志系统简介 在 Java 世界中,以下三种日志框架比较优秀: 1) Log4J 最早的 Java 日志框架之一,由 Apache 基金会发起,提供灵活而强大的日志记录机制。但是其复杂的配置过程和内部概念往往令使用者望而却步。
2) JDK1.4 Logging Framework 继 Log4J 之后, JDK 标准委员会将 Log4J 的基本思想吸收到 JDK 当中,在 JDK1.4 中发布了第一个日志框架接口,并提供了一个简单实现。
3) Commons Logging Framwork 该框架同样是 Apache 基金会项目,其出现主要是为了使得 Java 项目能够在 Log4J 和 JDK1.4 l Logging Framework 的使用上随意进行切换,因此该框架提供了统一的调用接口和配置方法。
2 系统设计 由 于 Log4J 得到广泛应用,从使用者的角度考虑,本文所设计的框架,采用了部分 Log4J 的接口和概念,但内部实现则完全不同。使用 Java 实现日志框架,关键的技术在于前面提及的日志框架特性的内部实现,特别是:日志的分类和级别、日志分发框架的设计、日志记录器的设计以及在设计中的高性能 和高稳定性的考虑。
2.1 系统架构 日 志系统框架可以分为日志记录模块和日志输出模块两大部分。日志记录模块负责创建和管理日志记录器 (Logger) ,每一个 Logger 对象负责按照不同的级别 (LoggerLevel) 接收各种记录了日志信息的日志对象 (LogItem) , Logger 对象首先获取所有需要记录的日志,并且同步地将日志分派给日志输出模块。日志输出模块则负责日志 输出器 (Appender) 的创建和管理,以及日志的输出。系统中允许有多个不同的日志 输出器 ,日志 输出器 负责将日志记录到存储介质当中。系统结构如下图 1 所示:
图 1 ,日志系统结构图 下图 2 使用 UML 类图给出了日志系统的架构:
图 2 ,日志系统框架架构图 在图 2 给出的架构中, 日志记录器 Logger 是整个日志系统框架的用户使用接口,程序员可以通过该接口记录日志,为了实现对日志进行分类,系统设计允许存在多个 Logger 对象,每一个 Logger 负责一类日志的记录, Logger 类同时实现了对其对象本身的管理。 LoggerLevel 类定义了整个日志系统的级别,在客户端创建和发送日志时,这些级别会被使用到。 Logger 对象在接收到客户端创建和发送的日志消息时,同时将该日志消息包装成日志系统内部所使用的日志对象 LogItem ,日志对象除了发送端所发送的消息以外,还会包装诸如发送端类名、发送事件、发送方法名、发送行号等等。这些额外的消息对于系统的跟踪和调试都非常有价 值。包装好的 LogItem 最终被发送给 输出器 ,由这些 输出 器负责将日志信息写入最终媒介, 输出器 的类型和个数均不固定,所有的 输出器 通过 AppenderManager 进行管理,通常通过配置文件即可方便扩展出多个 输出器 。
2.2 日志记录部分的设计 如前文所述,日志记录部分负责接收日志系统客户端发送来的日志消息、日志对象的管理等工作。下面详细描述了日志记录部分的设计要点:
1. 日志记录器的管理 系统通过保持多个 Logger 对象的方式来进行日志记录的分类。每一个 Logger 对象代表一类日志分类。因此, Logger 对象的名称属性是其唯一标识,通过名称属性获取一个 Logger 对象: Logger logger = Logger.getLogger(“LoggerName”); 一般的,使用类名来作为日志记录器的名称,这样做的好处在于能够尽量减少日志记录器命名之间的冲突(因为 Java 类使用包名),同时能够将日志记录分类得尽可能的精细。因此,假定有一 UserManager 类需要使用日志服务,则更一般的使用方式为:
Logger logger = Logger.getLogger(UserManager.class); 2. 日志分级的实现 按照日志目的不同,将日志的级别由低到高分成五个级别: DEBUG - 表示输出的日志为一个调试信息 INFO - 表示输出的日志是一个系统提示 WARN - 表示输出的日志是一个警告信息 ERROR - 表示输出的日志是一个系统错误 FATAL - 表示输出的日志是一个导致系统崩溃严重错误 这些日志级别定义在 LoggerLevel 接口中,被日志记录器 Logger 在内部使用。而对于日志系统客户端则可使用 Logger 类接口对直接调用并输出这些级别的日志, Logger 的这些接口描述如下:
public void debug(String msg); // 输出调试信息 public void info(String msg); // 输出系统提示 public void warn(String msg); // 输出警告信息 public void fatal(String msg); // 输出系统错误 public void error(String msg); // 输出严重错误 通过对 Logger 对象上这些接口的调用,直接为日志信息赋予了级别属性,这样为后继的按照不同级别进行输出的工作奠定了基础。
3. 日志对象信息的获取 日志对象上包含了一条日志所具备的所有信息。通常这些信息包括:输 出日志的时间、 Java 类、类成员方法、所在行号、日志体、日志级别等等。在 JDK1.4 中可以通过在方法中抛出并且捕获住一个异常,则在捕捉到的异常对象中已经由 JVM 自动填充好了系统调用的堆栈,在 JDK1.4 中则可以使用 java.lang.StackTraceElement 获取到每一个堆栈项的基本信息,通过对日志客户端输出日志方法调用层数的推算,则可以比较容易的获取到 StackTraceElement 对象,从而获取到输出日志时的 Java 类、类成员方法、所在行号等信息。在 JDK1.3 或者更早的版本中,相应的工作则必须通过将异常的堆栈信息输出到字符串中,并分析该字符串格式得到。 2.3 日志 输出部分 的设计 日志输出部分的设计具有一定的难度,在本文设计的日志系统中,日志的输出、多线程的支持、日志系统的扩展性、日志系统的效率等问题都交由日志输出部分进行管理。
1. 日志输出器的继承结构 在日志的输出部分采用了二层结构,即定义了一个抽象的日志输出器( AbstractLoggerAppender ) , 然后从该抽象类继承出实际的日志输出器。 AbstractLoggerAppender 定义了一系列的对日志进行过滤的方法,而具体输出到存储媒介的方法则是一个抽象方法,由子类实现。在系统中默认实现了控制台输出器和文件输出器两种,其中 控制台输出器的实现颇为简单。
2. 文件输出器的内部实现 在日志记录部分的实现中,并没有考虑多线程、高效率等问题,因此文 件输出器必须考虑这些问题的处理。在文件输出器内部使用 java.lang.Vector 定 义了一个线程安全的高速缓冲,所有通过日志记录部分分派到文件输出器的日志被直接放置到该高速缓冲当中。同时在文件输出器内部定义一个工作线程,负责定期 将高速缓冲中的内容保存到文件,在保存的过程中同时可以进行日志文件的备份等工作。由于采用了高速缓冲的结构,很显然日志客户端的调用已经不再是一个同步 调用,从而不再会需要等到文件操作后才返回,提高的系统调用的速度。该原理 如图 3 所示:
图 3 ,文件输出器内部结构 2.4 设计难点 通过上述设计,一个具有良好扩展能力的高性能日志系统框架就已经具有了一定的雏形。在设计过程中几个难点问题需要进一步反思。
一、是否整个系统应当采用完全异步的结构,通过类似于消息机制的方式来进行由日志客户端发送日志给日志系统。这种方式可以作为日志系统框架另一种运行方式,在后继设计中加以考虑。