中文信息处理与机器学习研究团队
- 格式:doc
- 大小:28.00 KB
- 文档页数:1

信息与计算科学学科前沿总结一、引言信息与计算科学是一门涉及信息处理、计算理论、算法设计与分析等多个领域的综合性学科。
随着科技的飞速发展,该学科的研究范围和深度也在不断扩大和深化,涌现出了许多新的研究领域和方向。
本文将对信息与计算科学学科的前沿进行总结。
二、信息与计算科学学科前沿1.人工智能与机器学习人工智能与机器学习是当前信息与计算科学领域最热门的研究方向之一。
该方向主要研究如何让计算机具备类似于人类的智能,以及如何利用机器学习算法进行数据分析和预测。
具体研究内容包括深度学习、自然语言处理、计算机视觉等。
2.大数据分析与处理随着大数据时代的到来,大数据分析与处理已经成为信息与计算科学领域的重要研究方向。
该方向主要研究如何高效地处理和分析大规模数据,挖掘其中的有用信息。
具体研究内容包括数据挖掘、云计算、分布式计算等。
3.量子计算与量子信息量子计算与量子信息是当前信息与计算科学领域最具挑战性的研究方向之一。
该方向主要研究如何利用量子力学原理进行信息处理和计算,实现更高效、更安全的计算和通信。
具体研究内容包括量子算法、量子纠错码、量子通信等。
4.信息安全与隐私保护信息安全与隐私保护是当前信息与计算科学领域最受关注的研究方向之一。
该方向主要研究如何保障信息安全和保护个人隐私,防止信息泄露和被攻击。
具体研究内容包括密码学、网络安全、隐私增强技术等。
5.生物信息学与计算生物学生物信息学与计算生物学是当前信息与计算科学领域最具发展潜力的研究方向之一。
该方向主要研究如何利用计算机科学和数学的方法和技术,对生物数据进行分析和建模,揭示生命活动的本质和规律。
具体研究内容包括基因组学、蛋白质组学、生物系统建模等。
三、总结与展望信息与计算科学学科的发展日新月异,其前沿研究领域涉及多个交叉学科,具有极高的挑战性和探索性。
未来,随着科技的不断发展,信息与计算科学学科将会涌现出更多新的研究方向和领域,为人类社会的进步和发展做出更大的贡献。

智能信息处理技术的发展和应用研究1 发展历程智能信息处理技术指的是运用人工智能、机器学习、自然语言处理等技术实现信息处理的过程。
其发展历程可以追溯至二十世纪五十年代,当时计算机科学家开始尝试模拟人脑的思维方式和决策方式。
随着计算机硬件和算法的发展,智能信息处理技术逐渐成为研究热点,涉及的领域也变得越来越广泛。
2 应用领域智能信息处理技术已经延伸到许多领域,包括但不限于以下几个:2.1 自然语言处理自然语言处理是指通过算法和语言学知识处理人类语言的能力。
这项技术广泛应用于搜索引擎、在线翻译、人机对话系统等领域。
2.2 图像识别图像识别是指通过计算机视觉和机器学习算法对图像进行分析和解释的过程。
这项技术已经应用于医疗诊断、智能家居、自动驾驶等领域。
2.3 大数据分析随着互联网和传感器技术的普及,数据规模不断增大。
大数据分析通过采用人工智能、机器学习等技术,能够从海量数据中提取有意义的信息。
2.4 人工智能人工智能是指计算机系统能够模拟人类的智能和决策能力。
这项技术已经应用于金融、医疗、教育等领域,成为了未来各个行业发展的趋势。
3 研究进展智能信息处理技术的研究一直都在进行当中。
现在,一些新的技术应运而生,如深度学习、强化学习、多智能体系统等,都为智能信息处理技术的应用提供了更大的可能性。
3.1 深度学习深度学习是指一种人工神经网络模型。
它通过多层非线性变换来对输入数据进行高层特征的抽象和表达,并通过反向传播算法对网络参数进行优化。
深度学习已广泛应用于图像识别、自然语言处理等领域,取得了很多成功。
3.2 强化学习强化学习是指建立在智能体与环境交互基础上的机器学习方法。
通过学习从环境中获得的奖励信号,智能体能够自主地探索最优策略。
强化学习已经应用于游戏AI、自动驾驶等领域。
3.3 多智能体系统多智能体系统是指由多个智能体组成的系统。
不同于单一智能体,多智能体系统可以通过协作和竞争来达到更优的结果。
多智能体系统应用于交通管理、资源调度等领域,是一种十分有效的解决方案。

《基于汉语语料库的中文词句快速检索算法研究》篇一一、引言随着信息技术的飞速发展,中文语料库在各行各业的应用日益广泛。
无论是自然语言处理、搜索引擎优化还是信息挖掘,快速准确的中文词句检索都成为关键任务。
为了应对海量中文文本的检索需求,基于汉语语料库的中文词句快速检索算法研究显得尤为重要。
本文旨在探讨基于汉语语料库的中文词句快速检索算法的原理、方法及其实验结果。
二、研究背景与意义随着互联网的普及,网络信息呈爆炸式增长。
如何在海量信息中快速找到用户关注的词句成为一项挑战。
汉语作为世界上最难掌握和运用的语言之一,其复杂性和丰富性使得词句检索更加困难。
因此,研究基于汉语语料库的中文词句快速检索算法具有重大意义。
三、算法原理及方法1. 分词技术:首先,对中文文本进行分词处理,将连续的文本序列切分成单个的词语或词组。
分词技术是中文词句检索的基础。
2. 索引构建:将分词后的结果建立索引,便于后续的检索操作。
常用的索引结构包括倒排索引、前缀树等。
3. 算法优化:针对中文语言的特性,如多义词、同义词等,采用多种算法优化手段,如基于统计的算法、基于深度学习的算法等,提高检索准确率。
4. 检索流程:用户输入查询语句后,系统通过匹配算法在索引中查找与查询相关的词句,返回给用户。
四、算法实现与实验结果1. 算法实现:采用多种技术手段实现基于汉语语料库的中文词句快速检索算法,包括分词技术、索引构建、算法优化等。
2. 实验数据:采用大规模的汉语语料库进行实验,包括新闻报道、学术论文、网络文章等。
3. 实验结果:通过对比不同算法在实验数据上的表现,发现基于深度学习的算法在准确率和效率方面具有明显优势。
此外,针对多义词和同义词等问题,通过算法优化提高了检索效果。
五、实验分析1. 准确性分析:实验结果表明,基于深度学习的检索算法在准确性方面具有显著优势,能够更准确地理解用户意图并返回相关词句。
2. 效率分析:在处理大规模语料库时,该算法能够在较短时间内完成检索任务,满足用户的实时需求。

hanlp的作用-概述说明以及解释1.引言1.1 概述HanLP(即“Han Language Processing”)是一个开源的自然语言处理(NLP)工具包,最初由人民日报社自然语言处理实验室开发,并已经在众多大型项目和企业中被广泛应用。
自然语言处理是人工智能领域中一个重要的研究方向,涉及到对人类语言的理解和处理。
HanLP作为一款功能强大的NLP工具包,集成了一系列中文文本的处理和分析功能,能够帮助开发者快速、准确地处理中文文本数据。
HanLP具备多项核心功能,包括分词、词性标注、命名实体识别、依存句法分析、关键词提取等。
这些功能能够协助用户完成诸如文本分析、信息提取、机器翻译、情感分析、智能问答等各种任务。
HanLP具有以下几个显著特点:1. 智能高效:HanLP采用了深度学习和统计机器学习等先进的技术,能够实现高效、准确的文本处理。
它精心训练的模型和优化算法确保了在不同场景下的稳定性和效果。
2. 针对中文:HanLP是专门为中文设计的工具包,充分考虑了中文的特殊性。
它支持繁简体转换、拼音转换等特殊处理,并基于大规模中文语料库进行训练,以获得更好的中文处理效果。
3. 可定制性:HanLP提供了丰富的功能和参数设置,允许用户根据自己的需求进行个性化定制。
用户可以选择不同的模型、配置和插件,以满足特定场景下的需求。
4. 强大的生态系统:HanLP的社区活跃,拥有众多用户和开发者参与其中。
在HanLP的基础上,还衍生出了丰富的周边工具和应用,形成了一个庞大的生态系统。
总之,HanLP作为一款功能全面、性能出色的中文NLP工具包,为中文文本处理和分析提供了便捷、高效的解决方案。
无论是学术研究还是商业应用,HanLP都是一个不可或缺的利器。
它的出现大大降低了中文自然语言处理的门槛,为中文信息处理领域的发展做出了重要贡献。
1.2 文章结构文章结构部分的内容如下:2. 正文在这一部分,我们将详细介绍HanLP的作用和功能。

NLPIR⼤数据通过知识图谱技术进⾏深度挖掘 近些年,由于以社交⽹站、基于位置的服务LBS 等为代表的新型信息产⽣⽅式的涌现,以及云计算、移动和物联⽹技术的迅猛发展,⽆处不在的移动、⽆线传感器等设备⽆时不刻都在产⽣数据,数以亿计⽤户的互联⽹服务时时刻刻都在产⽣着数据交互,⼤数据时代已经到来。
在当下,⼤数据炙⼿可热,不管是企业还是个⼈都在谈论或者从事⼤数据相关的话题与业务,我们创造⼤数据同时也被⼤数据时代包围。
在⼤量的数据中找到有意义的模式和规则。
在⼤量数据⾯前,数据的获得不再是⼀个障碍,⽽是⼀个优势。
知识图谱是以科学知识为对象,显⽰科学知识的发展进程与结构关系的⼀种图形。
科学知识图谱研究,是以科学学为研究范式,以引⽂分析⽅法和信息可视化技术为基础,涉及数学、信息科学、认知科学和计算机科学诸学科交叉的领域,是科学计量学和信息计量学的新发展。
科学知识图谱具有“图”和“谱”的双重性质与特征:既是可视化的知识图形,⼜是序列化的知识谱系,显⽰了知识元或知识群之间⽹络、结构、互动、交叉、演化或衍⽣等诸多复杂的关系。
借助科学知识图谱,⼈们可以查看庞⼤的⼈类知识体系中各个领域的结构,理顺当代知识⼤爆炸形成的复杂知识⽹络,预测科学技术知识前沿发展的新态势。
北京理⼯⼤学⼤数据搜索与挖掘实验室张华平主任研发的KGB知识图谱引擎,KGB知识图谱引擎(Knowledge Graph Builder)是基于⾃然语⾔理解、汉语词法分析,采⽤KGB语法从结构化数据与⾮结构化⽂档中抽取各类知识,⼤数据语义智能分析与知识推理,深度挖掘知识关联,实时⾼效构建知识图谱。
KGB知识图谱引擎核⼼技术与特⾊ 1 、KGB知识抽取 KGB(Knowledge Graph Builder)知识图谱引擎是我们⾃主研发的知识图谱构建与推理引擎,基于汉语词法分析的基础上,采⽤KGB语法实现了实时⾼效的知识⽣成,可以从⾮结构化⽂本中抽取各类知识,并实现了从表格中抽取指定的内容等。

新一代信息技术研究报告1. 引言1.1 新一代信息技术的背景与意义在21世纪的今天,信息技术的发展已经成为推动全球经济增长和社会进步的重要动力。
随着互联网、移动通信、大数据等技术的迅速崛起和广泛应用,人类社会正面临着一场以信息技术为核心的新一轮科技革命。
我国政府对新一代信息技术的发展给予了高度重视,将其作为国家战略性新兴产业来布局和推动,以期在全球科技竞争中占据有利地位。
新一代信息技术主要包括人工智能、大数据、云计算等,这些技术对于提高生产力、优化资源配置、促进产业升级等方面具有重要意义。
它们不仅为传统行业带来深刻的变革,还孕育出一系列新兴产业,为我国经济发展注入新活力。
1.2 研究目的与内容概述本报告旨在分析新一代信息技术的发展现状、核心领域、应用场景以及未来发展趋势与挑战,为我国新一代信息技术产业的发展提供有益的参考。
报告主要内容包括:1.新一代信息技术发展概况:分析国内外发展现状、政策规划及产业链情况;2.新一代信息技术的核心领域:深入探讨人工智能、大数据、云计算等关键技术的发展情况;3.新一代信息技术的应用场景:研究智能制造、智慧城市、金融科技等领域的实际应用;4.新一代信息技术的发展趋势与挑战:分析产业发展趋势、面临的挑战及应对策略;5.新一代信息技术在我国的创新实践:总结我国创新成果、典型企业案例分析及未来发展前景展望。
1.3 研究方法与数据来源本报告采用文献调研、数据分析、案例研究等方法,收集和整理了大量国内外相关政策文件、研究报告、企业案例等资料。
数据来源主要包括政府部门、行业协会、科研机构、企业公开资料等,力求确保报告内容的客观性、真实性和准确性。
2 新一代信息技术发展概况2.1 国内外发展现状新一代信息技术在全球范围内得到了快速发展。
国外,尤其是美国、欧洲、日本等发达国家,在人工智能、大数据、云计算等领域具有明显的技术领先优势。
美国作为全球科技创新的领导者,拥有谷歌、微软、亚马逊等科技巨头,不断推动着新一代信息技术的革新与应用。

1. 导师姓名:范明科研方向:数据库197k年郑州大学毕业,后在美国、加拿大进修及合作研究,教授,硕士生导师。
省重点学科计算机软件与理论的学术带头人,兼任中国计算机学会数据库专业委员会委员、中国计算机学会CAD与计算机图形学专业委员会委员、河南省计算机学会软件专业委员会主任,长期从事计算机软件教学和研究。
曾参与南京大学徐洁磬教授合作主持国家自然科学基金项目1项,主持河南省自然科学基金和科技攻关项目多项。
近年在《科学通报》、《计算机学报》、《软件学报》等国内外学术刊物发表论文近30篇,参加了《数据库综合大辞典》等多部著作的编写,1992年被评为河南省首批优秀中青年骨干教师,1999年获得全国归侨、侨眷先进个人称号。
2.导师姓名:王世卿科研方向:软件开发环境与开发技术199k年获中科院金属研究所工学博士学位,教授,硕士生导师,被北京理工大学聘为博士生指导教师。
现任信息工程学院副院长,兼任郑州市计算机学会理事长、郑州市科协常务委员、郑州市政府领导联系专家等职。
近年来发表学术论文20余篇,出版著作2部,承担省自然科学基金项目3项,科技开发项目5项。
曾获省计算机技术推广应用先进个人,郑州市科技先进个人和郑州市科技拔尖人才等称号。
3. 导师姓名:周清雷科研方向:自动机理论及模型验证、信息安全、操作系统1983年郑州大学数学系计算机专业本科毕业,1987年黄河大学计算机软件专业研究生毕业,教授,硕士生导师,现任信息工程学院副院长,兼任中国计算机学会理事、河南省计算机学会理事长、河南省计算机安全协会副理事长、全国高校计算机教育研究会理事。
主讲的课程有《操作系统》、《UNIX系统》、《计算理论》、《形式语言与自动机》等。
主要研究方向:形式语言与自动机理论、模型验证、信息安全、操作系统。
近年来主要完成了三项国家自然科学基金项目及多项省自然科学基金项目和一项省科技攻关项目研究。
承担了政府办公自动化系统项目、企业MIS系统及电子商务系统等10余项横向项目的开发。

邓国超个人简历邓国超是一位来自中国的科学家,他的成就不仅受到了国内的赞誉,而且在国外也备受尊重。
邓国超在多个领域做出了杰出的贡献,特别是在人工智能和计算机科学领域。
下面是邓国超的个人简历以及他在科学领域的一些成果和贡献。
个人简介邓国超于1990年获得了武汉大学电气工程学士学位,并于1993年获得武汉大学电气工程硕士学位。
之后,他进入了清华大学计算机科学和技术系攻读博士学位,并于1996年毕业。
1996年至1998年,他作为博士后在加州大学伯克利分校从事研究工作。
1998年,邓国超回到中国,在清华大学计算机科学与技术系担任讲师,并于2001年晋升为教授。
他还是清华信息技术研究院(THUIR)的副院长,担任清华大学机器智能与人工智能实验室主任。
他还是北京市智能机器人协会副理事长。
成果和贡献邓国超在数据挖掘、自然语言处理、机器学习和人工智能等领域发表了许多论文,并且在这些领域有很高的声誉。
邓国超在人工智能领域贡献巨大。
他是中文信息处理领域的权威专家之一,是汉语自然语言处理的主要开拓者之一。
2014年,邓国超在世界计算机大会上发表了题为《深度学习:机器智能的未来》的主题演讲,指出深度学习将成为机器智能的下一个重要发展方向。
这个演讲为他赢得了国内外很高的赞誉。
此外,他创立的THUIR(清华信息技术研究院)也在人工智能领域做出了很多成果。
邓国超还是中央电视台《挑战杯》节目组智能机器人比赛的评委,这个节目是一个非常受欢迎的智能机器人比赛,在国内外都有很大的影响力。
总结邓国超是一位享有很高国际声誉的科学家,他在人工智能等领域做出了很多的成果和贡献。
他的许多研究成果和发明对人工智能产业的发展带来了重要的推动作用。
此外,他也是众多科技类比赛的评委,并且常年在教学和科学研究方面做出了杰出的贡献。

中国计算机学会《学科前沿讲习班》第四十六期面向大数据的自然语言处理与机器学习2013年11月15日-17日重庆简介自然语言处理(Natural Language Processing, NLP)与机器学习(Machine Learning,ML)一直是计算机科学,尤其是人工智能研究方向的两个核心问题。
近几年来,互联网、社交媒体与移动平台的迅猛发展为传统自然语言处理与机器学习技术带来前所未有的挑战和机遇,使其成为学术界和工业界的研究热点。
一方面,传统的自然语言处理与机器学习在基础研究方面取得了长足进展,为工业应用提供了有效的技术支持;另一方面,不断涌现的真实问题和大规模数据又呼唤更加有效的自然语言处理与机器学习技术。
本期CCF学科前沿讲习班《面向大数据的自然语言处理与机器学习》将邀请学术界和工业界的著名专家、学者对自然语言处理基础理论、方法和应用,面向自然语言的机器学习技术,以及当前面向大数据时代的热点问题进行深入浅出的讲解。
目的是为青年学者和学生提供一个三天的学习、交流机会,快速了解本领域的基本概念、研究内容、方法和发展趋势。
本讲习班同时作为第二届CCF自然语言处理与中文计算会议(NLP&CC 2013)的Tutorials,将围绕大会主题——“数据智能、知识智能与社会智能”,重点讲解自然语言处理基础、社会媒体和语言计算、NLP工业应用和典型案例、面向NLP的机器学习、Deep Learning以及深层神经网络计算等内容。
学术主任张民,苏州大学教授李沐,微软亚洲研究院研究员协办单位重庆大学苏州大学微软亚洲研究院日程安排================2013年11月15日:自然语言处理和机器翻译8:30-9:00 开班仪式、合影第一讲自然语言处理:基础技术与互联网创新万小军北京大学副教授第一课 09:00-10:20 自然语言处理基础第二课 10:40-11:40 语义计算和篇章分析第三课 11:40-12:00 互动问答第二讲大数据时代的机器翻译刘洋清华大学副教授第一课 13:30-15:30 机器翻译概况、基于词和短语的方法第二课 16:00-17:30 基于句法的方法和未来发展趋势第三课 17:30-17:50 互动问答==============2013年11月16日:社会计算与自然语言处理应用第三讲社会网络计算及社会影响力分析唐杰清华大学副教授第一课 09:00-10:20 社会网络计算基础第二课 10:40-11:40 社会网络计算之社会影响力分析第三课 11:40-12:00 互动问答第四讲自然语言处理工业应用/开发实践第一课 13:20-15:20 大数据时代的智能问答和搜索张阔搜狗研究员第二课 15:40-16:40 大数据时代的搜索广告查询分析胡云华阿里研究员第三课 16:40-17:40 大数据下的广告排序技术及实践蒋龙阿里研究员第四课 17:40-18:00 互动问答==============2013年11月17日:机器学习第五讲 Statistical Machine Learning for NLP (统计机器学习与自然语言处理)朱小槿 University of Wisconsin-Madison 副教授第一课 09:00-10:00 Basics of Statistical Learning (统计机器学习基础)第二课 10:20-11:10 Graphical Models (图模型)第三课 11:10-12:00 Bayesian Non-Parametric Models (贝叶斯非参数方法)第四课 12:00-12:20 互动问答第六讲 Deep Learning - What, Why, and How 俞栋 MSR 研究员第一课 13:40-14:40 Deep Learning: Premise, Philosophy, and ItsRelation to Other Techniques 第二课 14:40-15:40 Basic Deep Learning Models第三课 16:00-17:15 Deep Neural Network and Its Applicationin Speech Recognition 第四课 17:15-17:35 互动问答17:35-18:00 结业式讲者介绍========================万小军北京大学副教授报告题目:自然语言处理:基础技术与互联网创新摘要:随着互联网上文本数据的爆炸性增长,如何对这些数据进行智能分析、语义挖掘与深度利用是学术界和工业界所共同面临的重大挑战。

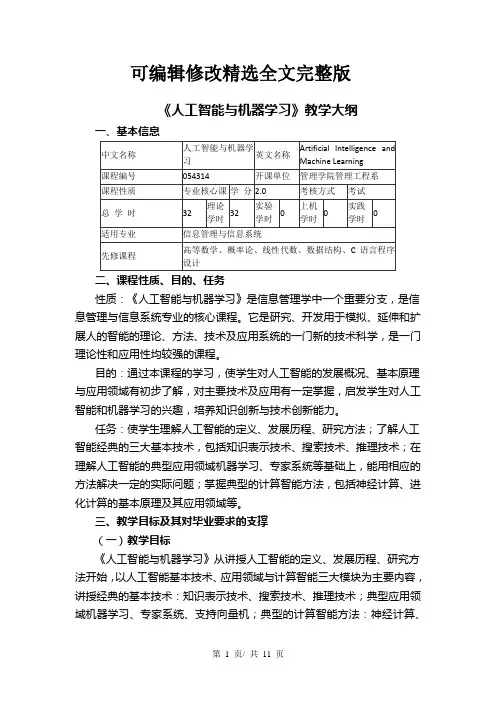
可编辑修改精选全文完整版(一)教学内容结构关系图(二)具体教学内容(2)教学要求了解人工智能的研究方法、发展简史。
理解人工智能的基本概念、基本技术。
掌握人工智能研究的基本内容和应用领域。
(3)重点人工智能概念(4)难点人工智能的研究方法(5)对毕业要求的支撑本知识点的讲授和学习,可以支撑“毕业要求5 能够针对本学科领域复杂问题,开发、选择与使用恰当的技术、方法、现代工程工具和信息技术工具,包括对本学科领域问题的预测与模拟,并能够理解其局限性。
”中的“指标点5.2掌握管理学理论与研究的前沿知识,培养具有持续适应社会和能力和及时了解新准则、新法规的能力。
”2.知识工程(1)教学内容知识工程概述、谓词逻辑表示法、产生式表示法、层次结构表示法、网络结构表示法、知识获取与管理、基于知识的系统(2)教学要求了解基于知识的系统、知识获取与管理。
理解知识工程的概念。
掌握逻辑谓词表示法及其应用,会用框架去描述一些具体问题,能用脚本来描述特定范围内的一些事件的发生顺序。
(3)重点经典谓词逻辑表示法、产生式表示法、层次结构表示法、网络结构表示法。
(4)难点层次结构表示法、网络结构表示法(5)对毕业要求的支撑本知识点的讲授和学习,可以支撑“毕业要求5 能够针对本学科领域复杂问题,开发、选择与使用恰当的技术、方法、现代工程工具和信息技术工具,包括对本学科领域问题的预测与模拟,并能够理解其局限性。
”中的“指标点5.2掌握管理学理论与研究的前沿知识,培养具有持续适应社会和能力和及时了解新准则、新法规的能力。
”3.确定性推理(1)教学内容推理的基本概念及归结、演绎等确定性推理方法。
推理的基本概念,了解正向推理、逆向推理、混合推理及其推理的冲突消解策略、推理的逻辑基础、自然演绎推理、归结演绎推理、基于规则的演绎推理、规则演绎推理的剪枝策略。
(2)教学要求理解推理的概念,了解正向推理、逆向推理、混合推理及其推理的冲突消解策略,了解自然演绎推理的概念以及三段论推理规则。
第 4 章走进智能时代4.1 认识人工智能教学设计教学背景信息科技是现代科学技术领域的重要部分,主要研究以数字形式表达的信息及其应用中的科学原理、思维方法、处理过程和工程实现。
当代高速发展的信息科技对全球经济、社会和文化发展起着越来越重要的作用。
义务教育信息科技课程具有基础性、实践性和综合性,为高中阶段信息技术课程的学习奠定基础。
信息科技课程旨在培养科学精神和科技伦理,提升自主可控意识,培育社会主义核心价值观,树立总体国家安全观,提升数字素养与技能。
教材分析本节课的教学内容选自人教/地图出版社第 4 章走进智能时代 4.1 认识人工智能,信息技术的发展与普及为我们创造了一个全新的数字化生活环境。
它们在给我们带来生活便利的同时,也在逐渐地改变着我们的生活方式。
在 2018 年的上海科技博览会上,有一位声音甜美、行动自如的机器人“小i”,受到了人们的关注。
“你会唱歌吗?”“可不可以给我讲个笑话?”“明天的天气怎么样?”人们争抢着和这个可爱的机器人对话。
小 i 不仅逐一回答了它所“听”到的每一个问题,还不时地用一个个笑话、萌劲十足的表情,以及语气逗乐了现场的观众。
其实,它是我国一家智能科技公司开发的一款具有自我学习能力的实体机器人。
该科技公司在自然语言处理、语义分析和理解、知识工程和智能大数据等方面走在了世界前列,它研发的相关智能技术已经在我国的金融、医疗、交通等领域得到广泛应用。
同学们,想想还有哪些人工智能技术就在我们的生活中?它有哪些奇妙之处?又如何影响着我们的生活?现在,就让我们一起走进这神奇的人工智能artificial intelligence,简称 AI)世界吧!本章我们将以“智能交互益拓展”为主题开展项目活动,体验人工智能对日常生活的影响,了解人工智能的关键技术,认识人工智能在信息社会中的重要作用。
学情分析此节课针对的对象是高一年级的学生,学生对信息技术的关键技术以及信息技术对生活与学习的影响有一定的了解,但对所学内容只是体验性和经验性的认识。
词性标注规则的获取和优化1陈文亮2朱靖波3吕学强4姚天顺5中文信息处理实验室东北大学计算机软件与理论研究所辽宁沈阳 110004Website:E_mail:*****************摘要:本文提出一种词性标注规则自动学习算法。
通过对规则进行评价、优化,有效提高标注正确率和标注效率。
系统对PFR标注语料库(98年1月)进行标注,相对于NA假设的词性兼类消歧模型标注结果,封闭测试正确率提高了5.53%,开放测试提高了4.57%。
关键词词性标注;规则自动学习;中文信息处理;Acquisition and Optimization of Rules for Part of SpeechChen WenLiang Zhu JingBo Lv Xueqiang Yao TianShunInstitute of Computer Software & Theory, Northeastern University, Shenyang 110004 Abstract: A learning algorithm is presented to acquire and optimize rules which are applied on part of speech tagging. It can increase the tagging precision and efficiency. Applying the algorithm, an experiment is conducted with PTR corpus. Comparing with tagged result of grammatical tagging based on NA assumption, the tagging precision increases 5.53% in close text and 4.57% in open text. Keyword: Part of speech tagging, Automatic learning of rules, Chinese information processing1.前言汉语词性标注一直是中文信息处理领域的一个重要研究课题。
基于自然语言处理的中文网络舆情监测与分析研究近年来,随着信息科技的高速发展,互联网成为人们获取信息的重要渠道之一。
而中文网络舆情作为互联网上一种特殊的信息形式,对社会舆论的引导和社会风气的塑造扮演着重要的角色。
因此,基于自然语言处理的中文网络舆情监测与分析研究显得尤为重要。
中文网络舆情监测与分析是指通过收集和分析互联网上与特定事件、话题或者个体有关的信息,以了解公众对于这些信息的态度和情感倾向。
而自然语言处理(NLP)则是研究计算机与人类自然语言交互的一门学科。
将这两个领域结合起来,可以提高对中文网络舆情的有效监测和分析能力。
首先,中文网络舆情的监测需要使用NLP技术进行舆情信息的收集和筛选。
NLP技术可以对大规模网络文本数据进行语义分析,提取其中的主题和情感倾向。
通过建立自然语言处理模型,可以对不同主题的舆情信息进行自动分类和归档,提高监测效率。
例如,利用NLP技术可以将舆情信息根据正面、负面、中性的情感倾向进行划分,从而帮助相关机构捕捉社会舆论动向,进行舆情危机的预警和处理。
其次,中文网络舆情的分析需要利用NLP技术进行情感分析和观点挖掘。
情感分析是指通过对文本情感的识别和分类,了解舆情信息中公众对特定事件、话题或者个体的态度和情绪。
而观点挖掘则是指从大规模网络文本中提取出人们的观点和意见,进一步分析不同群体对于特定事件的看法和立场。
这些信息的分析可以帮助相关机构更好地了解公众意见和需求,从而做出有针对性的决策和回应。
此外,基于自然语言处理的中文网络舆情监测与分析还可以结合机器学习和数据挖掘的方法,进一步提高舆情信息的预测和分析能力。
通过对大规模网络文本数据的训练和学习,可以建立舆情信息的预测模型,实现对未来可能出现的舆情倾向的预测和评估。
同时,还可以利用数据挖掘的技术,在舆情信息中发现隐藏的关联性和趋势,为相关机构提供更全面准确的决策依据。
然而,基于自然语言处理的中文网络舆情监测与分析也面临着一些挑战和问题。
中文信息处理与机器学习研究团队
4月份活动安排
(团队负责人 李济洪教授、博导)
一、活动主题:论文阅读及科研项目讨论
二、内容介绍:
1. 王瑞波主讲
Arora S, Li Y, Liang Y, Ma T, Risteski A. Random Walks on Context
Spaces: Towards an Explanation of the Mysteries of Semantic Word
Embeddings. arXiv preprint arXiv:150203520. 2015.
2. 杨静主讲
Moreno-Torres JG, Raeder T, Alaiz-Rodríguez R, Chawla NV, Herrera F.
A unifying view on dataset shift in classification. Pattern Recognition.
2012;45(1):521-30.
3. 石隽峰主讲
López V, Fernández A, Herrera F. On the importance of the validation
technique for classification with imbalanced datasets: Addressing
covariate shift when data is skewed. Information Sciences. 2014;257:1-13.
4. 刘展鹏主讲
Zhang X, LeCun Y. Text Understanding from Scratch. arXiv preprint
arXiv:150201710. 2015.
时间:每周一下午4点到6点 周三和周五上午10点到12点
地点:理科楼四层语义网研究室