数据结构:栈子系统
- 格式:doc
- 大小:41.50 KB
- 文档页数:8



栈的应用场景栈是一种常见的数据结构,它的特点是后进先出(Last In First Out,LIFO)。
栈的应用场景非常广泛,从计算机科学到日常生活都可以见到其身影。
本文将介绍栈在不同领域的应用场景。
1.计算机算法在计算机算法中,栈经常被用于实现递归函数、表达式求值、括号匹配等操作。
递归函数的调用过程实际上是一个栈的过程,每当一个函数调用另一个函数时,系统会将当前函数的状态信息压入栈中,待调用的函数执行完毕后再从栈中弹出上一个函数的状态信息继续执行。
表达式求值中,栈可以用于存储操作数和运算符,通过弹出栈中的元素进行计算,最终得到表达式的结果。
括号匹配中,栈可以用于判断左右括号是否匹配。
2.编译器和操作系统编译器和操作系统也是栈的常用应用场景。
在编译器中,栈用于存储函数调用的参数、局部变量和返回地址等信息。
每当函数调用时,编译器会将相关信息压入栈中,函数执行结束后再从栈中弹出相关信息。
操作系统中的函数调用、中断处理等过程也经常使用栈来保存现场信息,保证程序的正确执行。
3.网络协议在网络协议中,栈被广泛应用于网络数据的传输和处理。
TCP/IP协议栈是一个典型的例子,它将网络层、传输层、应用层等不同的协议通过栈的形式依次封装,完成数据的传输和处理。
数据包从应用层一直传输到网络层,以栈的形式不断压入和弹出,确保数据的准确传递和处理。
4.浏览器的前进后退功能在浏览器中,前进和后退功能是栈应用的典型场景。
当我们浏览网页时,每当点击一个链接或者输入一个网址,浏览器会将当前的URL 压入栈中。
当我们点击“后退”按钮时,浏览器会从栈中弹出上一个URL,完成页面的后退操作。
同样地,当我们点击“前进”按钮时,浏览器会从栈中弹出下一个URL,完成页面的前进操作。
5.撤销和恢复操作在各种应用程序中,栈可用于实现撤销和恢复操作。
例如,在文字编辑器中,当我们对文字进行修改后,可以将修改前的状态信息压入栈中,以备将来的撤销操作。

数据结构经典案例在计算机科学领域,数据结构是组织和存储数据的方式,以便能够高效地访问、操作和管理数据。
数据结构的选择对于算法的性能和程序的效率有着至关重要的影响。
下面将为您介绍几个数据结构的经典案例。
一、栈(Stack)栈是一种遵循“后进先出”(Last In First Out,LIFO)原则的数据结构。
想象一下一叠盘子,最后放上去的盘子总是最先被拿走,栈就是这样的工作原理。
一个常见的栈的应用是表达式求值。
比如我们要计算数学表达式“3 + 4 2”。
首先,将数字和运算符依次压入栈中。
当遇到运算符时,从栈中弹出相应数量的操作数进行计算,然后将结果压回栈中。
通过这种方式,能够按照正确的运算顺序得出最终的结果。
在编程语言中,函数调用也用到了栈。
当一个函数被调用时,其相关的信息(如参数、返回地址等)被压入栈中。
当函数执行完毕后,这些信息被弹出,程序回到之前的执行点继续执行。
二、队列(Queue)队列遵循“先进先出”(First In First Out,FIFO)原则。
就像排队买东西,先排队的人先得到服务。
在操作系统中,打印任务通常使用队列来管理。
多个打印任务按照提交的先后顺序排列在队列中,打印机依次处理队列中的任务。
另外,在消息传递系统中,队列也被广泛应用。
发送方将消息放入队列,接收方从队列中取出消息进行处理。
三、链表(Linked List)链表是一种动态的数据结构,其中的元素通过指针连接在一起。
在需要频繁进行插入和删除操作的场景中,链表表现出色。
比如,在一个学生管理系统中,如果需要不断地添加或删除学生信息,使用链表可以方便地在任意位置进行操作,而不需要像数组那样移动大量的元素。
四、树(Tree)树是一种分层的数据结构,具有根节点、子节点和叶节点。
二叉搜索树(Binary Search Tree)是一种常见的树结构。
在二叉搜索树中,左子树的所有节点值都小于根节点的值,右子树的所有节点值都大于根节点的值。




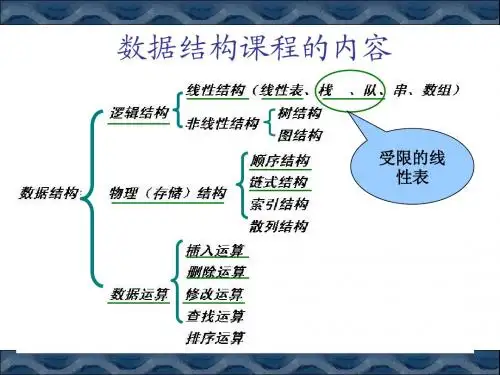
数据结构(⼀)——线性表、栈和队列数据结构是编程的起点,理解数据结构可以从三⽅⾯⼊⼿:1. 逻辑结构。
逻辑结构是指数据元素之间的逻辑关系,可分为线性结构和⾮线性结构,线性表是典型的线性结构,⾮线性结构包括集合、树和图。
2. 存储结构。
存储结构是指数据在计算机中的物理表⽰,可分为顺序存储、链式存储、索引存储和散列存储。
数组是典型的顺序存储结构;链表采⽤链式存储;索引存储的优点是检索速度快,但需要增加附加的索引表,会占⽤较多的存储空间;散列存储使得检索、增加和删除结点的操作都很快,缺点是解决散列冲突会增加时间和空间开销。
3. 数据运算。
施加在数据上的运算包括运算的定义和实现。
运算的定义是针对逻辑结构的,指出运算的功能;运算的实现是针对存储结构的,指出运算的具体操作步骤。
因此,本章将以逻辑结构(线性表、树、散列、优先队列和图)为纵轴,以存储结构和运算为横轴,分析常见数据结构的定义和实现。
在Java中谈到数据结构时,⾸先想到的便是下⾯这张Java集合框架图:从图中可以看出,Java集合类⼤致可分为List、Set、Queue和Map四种体系,其中:List代表有序、重复的集合;Set代表⽆序、不可重复的集合;Queue代表⼀种队列集合实现;Map代表具有映射关系的集合。
在实现上,List、Set和Queue均继承⾃Collection,因此,Java集合框架主要由Collection和Map两个根接⼝及其⼦接⼝、实现类组成。
本⽂将重点探讨线性表的定义和实现,⾸先梳理Collection接⼝及其⼦接⼝的关系,其次从存储结构(顺序表和链表)维度分析线性表的实现,最后通过线性表结构导出栈、队列的模型与实现原理。
主要内容如下:1. Iterator、Collection及List接⼝2. ArrayList / LinkedList实现原理3. Stack / Queue模型与实现⼀、Iterator、Collection及List接⼝Collection接⼝是List、Set和Queue的根接⼝,抽象了集合类所能提供的公共⽅法,包含size()、isEmpty()、add(E e)、remove(Object o)、contains(Object o)等,iterator()返回集合类迭代器。


栈及其应用第一节栈的基本知识一、栈的基本概念栈(stack,又称为堆栈)是一种特殊的线性表。
作为一个简单的例子,可以把食堂里冼净的一摞碗看作一个栈。
在通常情况下,最先冼净的碗总是放在最底下,后冼净的碗总是摞在最顶上。
而在使用时,却是从顶上拿取,也就是说,后冼的先取用,后摞上的先取用。
如果我们把冼净的碗“摞上”称为进栈(压栈),把“取用碗”称为出栈(弹出),那么上例的特点是:后进栈的先出栈。
然而,摞起来的碗实际上仍然是一个线性表,只不过“进栈”和“出栈”都在最顶上进行,或者说,元素的插入和删除操作都是在线性表的一端进行而已。
一般而言,栈是一个线性表,其所有的插入和删除操作均是限定在线性表的一端进行,允许插入和删除的一端称栈顶(Top),不允许插入和删除的一端称栈底(Bottom)。
若给定一个栈S=(a1, a2,a3,……,a n),则称a1为栈底元素,a n为栈顶元素,元素a i位于元素a i-1之上。
栈中元素按a1, a2,a3,……,a n的次序进栈,如果从这个栈中取出所有的元素,则出栈次序为a n, a n-1,……,a1。
也就是说,栈中元素的进出是按“后进先出”的原则进行,这是栈的重要特征。
因此栈又称为后进先出表(LIFO表—Last In First Out)。
我们常用下图来形象地表示栈:二、栈的存储结构(1)顺序栈栈是一种线性表,在计算机中用一维数组作为栈的存储结构最为简单,操作也最为方便,也是最为常用的。
例如,设一维数组STACK[1..n] 表示一个栈,其中n为栈的容量,即可存放元素的最大个数。
栈的第一个元素,或称栈底元素,是存放在STACK[1]处,第二个元素存放在STACK[2]处,第i个元素存放在STACK[i]处。
另外,由于栈顶元素经常变动,需要设置一个指针变量top,用来指示栈顶当前位置,栈中没有元素即栈空时,令top=0;当top=n时,表示栈满。
如果一个栈已经为空,但用户还继续做出栈(读栈)操作,则会出现栈的“下溢”;如果一个栈已经满了,用户还继续做进栈操作,则会出现栈的“上溢”。
栈在生活中的实际例子
栈:铁路调度中用到栈。
队列:民航机票订购。
栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。
它按照先进后出的原则存储数据,先进入的数据被压入栈底。
最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
扩展资料:
由于入队和出队操作中,头尾指针只增加不减小,致使被删元素的空间永远无法重新利用。
当队列中实际的元素个数远远小于向量空间的规模时,也可能由于尾指针已超越向量空间的上界而不能做入队操作。
在循环队列中,当队列为空时,有front=rear,而当所有队列空间全占满时,也有front=rear。
为了区别这两种情况,规定循环队列最多只能有MaxSize-1个队列元素,当循环队列中只剩下一个空存储单元时,队列就已经满了。
第一节栈
一、栈的定义及其运算
1、栈的定义
栈(Stack):是限定在表的一端进行插入和删除运算的线性表,通常将插入、删除的一端称为栈项(top),另一端称为栈底(bottom)。
不含元素的空表称为空栈。
栈的修改是按后进先出的原则进行的,因此,栈又称为后进先出(Last In First Out)的线性表,简称为LIFO表。
真题选解
(例题·填空题)1、如图所示,设输入元素的顺序是(A,B,C,D),通过栈的变换,在输出端可得到各种排列。
若输出序列的第一个元素为D,则输出序列为。
隐藏答案
【答案】DCBA
【解析】根据堆栈"先进后出"的原则,若输出序列的第一个元素为D,则ABCD入栈,输出序列为DCBA
2、栈的基本运算
(1)置空栈InitStack(&S):构造一个空栈S。
stack方法(一)Stack 数据结构介绍什么是 Stack?Stack(栈)是一种常见的数据结构,它按照后进先出(LIFO)的原则管理数据。
在 Stack 中,元素只能在栈的顶部进行插入和删除操作,这也是其与队列的最大区别之一。
Stack 的操作Stack 主要包含以下几种操作:•push(item): 将元素item插入栈的顶部。
•pop(): 删除并返回栈顶部的元素。
•peek(): 返回栈顶部的元素,但不对栈进行修改。
•isEmpty(): 检查栈是否为空。
•size(): 返回栈中元素的个数。
Stack 的实现方法Stack 可以用多种方式来实现,下面是常见的两种方法:1.使用数组实现 Stack:class Stack:def __init__(self):self.stack = []def push(self, item):self.stack.append(item)def pop(self):if not self.isEmpty():return self.stack.pop()def peek(self):if not self.isEmpty():return self.stack[-1]def isEmpty(self):return len(self.stack) == 0def size(self):return len(self.stack)2.使用链表实现 Stack:class Node:def __init__(self, data):self.data = dataself.next = Noneclass Stack:def __init__(self):self.head = Nonedef push(self, item):new_node = Node(item)new_node.next = self.headself.head = new_nodedef pop(self):if not self.isEmpty():temp = self.headself.head = self.head.next return temp.datadef peek(self):if not self.isEmpty():return self.head.datadef isEmpty(self):return self.head is Nonedef size(self):count = 0current = self.headwhile current:count += 1current = current.nextreturn countStack 的应用场景Stack 在计算机科学中有许多应用场景,下面是其中的几个例子:•表达式求值:Stack 可以用来实现对中缀表达式求值的算法,如将中缀表达式转换为后缀表达式,再利用后缀表达式求值的方法来计算表达式的结果。
sk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。
它在<include/linux/skbuff.h>中定义,并包含很多成员变量供网络代码中的各子系统使用。
这个结构在linux内核的发展过程中改动过很多次,或者是增加新的选项,或者是重新组织已存在的成员变量以使得成员变量的布局更加清晰。
它的成员变量可以大致分为以下几类:Layout 布局General 通用Feature-specific功能相关Management functions管理函数这个结构被不同的网络层(MAC或者其他二层链路协议,三层的IP,四层的TCP或UDP 等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。
L4向L3传递前会添加一个L4的头部,同样,L3向L2传递前,会添加一个L3的头部。
添加头部比在不同层之间拷贝数据的效率更高。
由于在缓冲区的头部添加数据意味着要修改指向缓冲区的指针,这是个复杂的操作,所以内核提供了一个函数skb_reserve(在后面的章节中描述)来完成这个功能。
协议栈中的每一层在往下一层传递缓冲区前,第一件事就是调用skb_reserve在缓冲区的头部给协议头预留一定的空间。
skb_reserve同样被设备驱动使用来对齐接收到包的包头。
如果缓冲区向上层协议传递,旧的协议层的头部信息就没什么用了。
例如,L2的头部只有在网络驱动处理L2的协议时有用,L3是不会关心它的信息的。
但是,内核并没有把L2的头部从缓冲区中删除,而是把有效荷载的指针指向L3的头部,这样做,可以节省CPU时间。
1. 网络参数和内核数据结构就像你在浏览TCP/IP规范或者配置内核时所看到的一样,网络代码提供了很多有用的功能,但是这些功能并不是必须的,比如说,防火墙,多播,还有其他一些功能。
大部分的功能都需要在内核数据结构中添加自己的成员变量。
因此,sk_buff里面包含了很多像#ifdef这样的预编译指令。
/* *题目:设计一个字符型的链栈。 * 编写进栈、出栈、显示栈中全部元素的程序。 *题目:编写一个把十进制整数转换为二进制数的应用程序 *题目:编写一个把中缀表达式转换为后缀表达式(逆波兰式)的应用程序 *题目:设计一个选择式菜单,以菜单方式选择上述操作。 * 栈 子 系 统 * ******************************* * * 1------进 栈 * * * 2------出 栈 * * * 3------显 示 * * * 4------数值转换 * * * 5------逆波兰式 * * * 0------返 回 * * ******************************* * 请选择菜单号(0--5): */
#include #include
#define STACKMAX 50 typedef struct sta //栈的存储结构 { int data; struct sta *next; }stackNode; typedef struct //指向栈顶的指针 { stackNode *top; }linkStack;
void conversion(int n); void push(linkStack *p, int x); int pop(linkStack *p); void showStack(linkStack *p); void sufflx();
/************************************************* Function: main() Description: 主调函数 Calls: push() pop() showStack() conversion() Input: NULL Return: void Others: NULL *************************************************/ void main() { int x, choice, i = 1;
linkStack p; p.top = NULL; //置空栈
while (i) { printf("\n 栈 子 系 统\n"); printf("*******************************\n"); printf("* 1------进 栈 *\n"); printf("* 2------出 栈 *\n"); printf("* 3------显 示 *\n"); printf("* 4------数值转换 *\n"); printf("* 5------逆波兰式 *\n"); printf("* 0------返 回 *\n"); printf("*******************************\n"); printf("请选择菜单号(0--5):"); fflush(stdin); //清空输入的缓存区 choice = getchar();
switch(choice) { case '1': while (1) { printf("请输入一个整数(‘0’表示结束)并按回车:"); scanf("%d", &x);
if (x != 0) { push(&p, x); //入栈 } else { break; } } break; case '2': x = pop(&p); //出栈 if (x > 0) { printf("出栈元素为:%d\n", x); } else { printf("栈为空,没有元素可以出栈!\n"); } break; case '3': showStack(&p); //显示栈元素 break; case '4': printf("请输入十进制数:"); scanf("%d", &x);
conversion(x); //数值转换 break; case '5': sufflx(); break; case '0': i = 0; break; default: i = 1; break; } } }
/************************************************* Function: conversion() Description: 十进制数转换二进制数 Calls: push() pop() Input: n :输入的要转换的数 Return: void Others: NULL *************************************************/ void conversion(int n) { linkStack s; int x, i = 1;
s.top = NULL; //置空栈 do { x = n%2; //求余数 n = n/2; //求新商 push(&s, x); //入栈 }while (n);
printf("转化的二进制为:"); while (i) { x = pop(&s); //出栈 if (x != -1) //判断是否全部出栈 { printf("%d", x); } else { i = 0; } } printf("\n"); }
void sufflx() { char str[STACKMAX]; //存储中缀表达式 char exp[STACKMAX]; //存储后缀表达式 char stark[STACKMAX]; //顺序栈来存放运算符 int top = 0; //顺序栈置空 int sum, t, i = 0; char ch;
printf("请输入一个算术表达式(运算符只能包含+,-,*,/),以#结束:\n"); fflush(stdin);
do { i++; scanf("%c", &str[i]); } while (str[i] != '#' && i != STACKMAX); //存储用户输入的中缀表达式
sum = i; //保存表达式的长度 i = t = 1; ch = str[i]; i++; while (ch != '#') { switch (ch) { case '(': //读取到‘(’时,入栈 top++; stark[top] = ch; break; case ')': //读取到‘)’时 while (stark[top] != '(') { exp[t++] = stark[top--]; //出栈并赋值给输出数组 exp[t++] = ','; //添加分割符号 } top--; //栈顶元素为‘(’时,出栈 break; case '+': //读取到‘+’时 while (top != 0 && stark[top] != '(') //判断符号优先级 { exp[t++] = stark[top--]; exp[t++] = ','; } stark[++top] = ch; //栈为空时入栈 break; case '-': //读取到‘-’时 while (top != 0 && stark[top] != '(') { exp[t++] = stark[top--]; exp[t++] = ','; } stark[++top] = ch; //栈为空时入栈 break; case '*': //读取到‘*’时 while (stark[top] == '*' || stark[top] == '/') //*、/运算级最高 { exp[t++] = stark[top--]; exp[t++] = ','; } stark[++top] = ch; //运算符优先级高的入栈 break; case '/': //读取到‘/’时 while (stark[top] == '*' || stark[top] == '/') { exp[t++] = stark[top--]; exp[t++] = ','; } stark[++top] = ch; //运算符优先级高的入栈 break; case ' ': //读取到空格时忽略 break; default: //不是运算符号时 while (ch >= '0' && ch <= 'z') //限制输入的变量 { exp[t++] = ch; ch = str[i++]; } i--; //上面多加的要去掉 exp[t++] = ','; break; } ch = str[i++]; }
while (top != 0) //顺序栈中仍有数值时 { exp[t++] = stark[top--]; if (top != 0) { exp[t++] = ','; } }
printf("中缀表达式为:"); //输出 for (i = 1; i < sum; i++) { printf("%c", str[i]); } printf("\n后缀表达式为:"); for (i = 1; i < t; i++)