Talend 学习笔记
- 格式:pptx
- 大小:6.92 MB
- 文档页数:7


学习ExtJs笔记Grid表格1、添加数据的时候,将数据的属性设置为dirty。
因为在使用Ajax提交数据的时候,非dirty的数据不会自动保存到store的modifield属性中。
2、保存数据:(1)store.modifield.slice(start,end);作用:返回一个新数组,取得从start到end的所有元素,但不包括end元素。
如果参数只有一个0,则表示取得全部的数据;(2)each(m,function())(m为一个数组),该方法主要作用是遍历数组m中的每一条记录,并且每条记录都按照function()方法进行处理。
不可在function方法里面加上循环,否则,将出现多重结果。
(3)listeners监听器:listeners: {"afterEdit": {fn: afterEdit,scope: this} }作用:监听afterEdit。
当单元格编辑完成或者退出编辑状态,自动调用fn方法,作用的范围是当前页面。
(4)当添加数据成功后,新添加的数据有三角行的标识,要除掉标识,可用Record 的commit方法。
3、读取数据(1)从Txt文件中读取数据将读取的数据编码eval(response.responseText),否则将不能正确读取数据。
(2)设置记录的字段的值var initValue = {name:'',gender:'',age:''};var p = new Record(initValue);p.set('name',data_get[i].name);p.set('gender',data_get[i].gender);p.set('age',data_get[i].age);Tree 树1、Tree的加载使用方法render。
Tree.render()方法将tree加载到tree的‘el’中。

sequence学习笔记sequence概述模式对象的一种,能够以串行方式生成一系列顺序整数。
其最大的有点是可以在多用户并发环境中为各个用户生成不会重复的顺序整数,基本上可以认为序列天生就是为主键而存在的。
使用create sequence 语句创建序列之后,oracle将序列的定义描述存储在数据字典中,序列并不占用实际的存储空间。
sequence的创建创建序列需要提供如下信息:序列的名称序列生成整数的顺序是升序还是降序序列生成两个整数之间的间隔oracle是否在内存中缓存序列生成的整数语法:CREATE SEQUENCE seq_table_name可选参数如下:INCREMENT BY 1 —每次加几个START WITH 1 —从1开始计数NOMAXvalue —不设置最大值NOCYCLE —一直累加,不循环NOCACHE–不设置缓存CACHE 10; –设置缓存cache个序列,如果系统down掉了或者其它情况将会导致序列不连续sequence的变更可以alter除start至以外的所有sequence参数.如果想要改变start值,必须drop sequence 然后再重新创建。
ALTER SEQUENCE 的例子ALTER SEQUENCE emp_sequenceINCREMENT BY 10MAXvalue 10000CYCLE —到10000后从头开始NOCACHE ;sequence的使用使用CURRVAL得到序列的当前值;使用NEXTVAL得到序列的下一个值,当前序列值也会随之改变。
可以使用sequence的地方:- 不包含子查询、snapshot、VIEW的 SELECT 语句- INSERT语句的子查询中- INSERT语句的valueS中- UPDATE 的 SET中示例:insert into table_name(id, name)values(seq_table_name.Nextval,‘runto30′);其他说明序列只适合那些使用整数作为主键字段值的表。
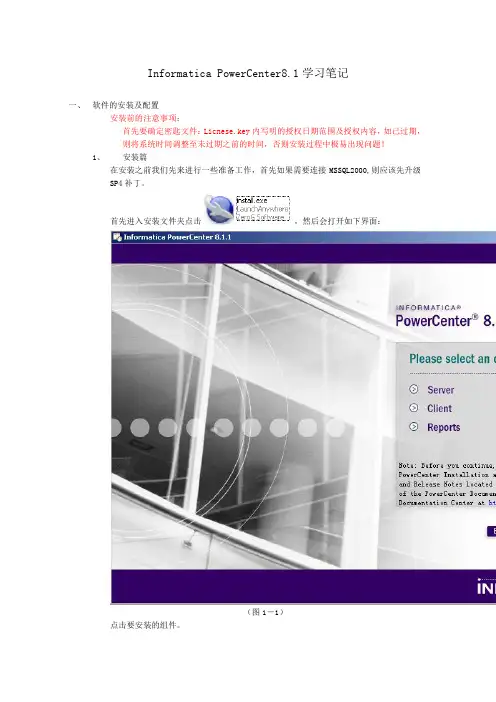
Informatica PowerCenter8.1学习笔记一、软件的安装及配置安装前的注意事项:首先要确定密匙文件:Licnese.key内写明的授权日期范围及授权内容,如已过期,则将系统时间调整至未过期之前的时间,否则安装过程中极易出现问题!1、安装篇在安装之前我们先来进行一些准备工作,首先如果需要连接MSSQL2000,则应该先升级SP4补丁。
首先进入安装文件夹点击,然后会打开如下界面:(图1-1)点击要安装的组件。
(1)安装服务端组件首先点击,等待安装准备工作完成后自动跳转至如下界面:(图1-2)点击,至下一步:(图1-3)在这里需选择密匙文件,点击后在出现的选择界面内:(图1-4)选中密匙文件点击即可。
然后会回到图1-3 的界面,点击进行下一步。
可能出现错误:(图1-5)这个错误是由于密匙文件过期造成的,只需将系统时间调整至过期日期之前即可。
密匙文件验证完毕后会出现如下界面:(图1-6)点击即可进入下一步。
(图1-7)如果想要完全安装,则直接点击即可,如需定制安装,刚选中即可,这里我们只需安装PowerCenterServices,对于完全安装就不再详述。
点击进行跳转:(图1-8)在这里我们只选Services组件,然后点击进入下一步:(图1-9)在这里我们可以选择安装还是升级,我们选择第一项,点击进入下一步:(图1-10)选择安装目录,然后点击(图1-11)在图1-11 中所示的界面内检查安装信息是否正确,如正确点击安装完成后进入如下域设定界面:(图1-12)第一项为建立新的域,第二项为导入现有域,可根据实际情况进行选择,这里我们只介绍新建域的操作。
选中第一项后点击,会出现配置服务器数据库信息界面:(图1-13)几个需要填写的内容分别为:Database type(数据库类型)Database URL(数据库连接URL字符串)Database userID(数据库登陆用户名)Database user password(数据库登陆密码)Database service name(数据库名)在填写完毕后点击进行链接测试,如通过则会出现:(图1-14)然后点击,进入服务器信息配置界面:(图1-15)几个需要填写的内容分别为:Domain name(域名称)Domain host name(映射地址名称)Node name(节点名称)Domain port no(域对应端口号) Domain user name(管理员帐号) Domain password(管理员密码)Confirm password(确认密码)Create Repository Service点击会出现(图1-16)可以配置Minimum port no(最小端口号)及Maximum port no(最大端口号),配置完毕后点击开始进行域的创建。

hibernate4学习笔记Hibernate4学习笔记本⼈全部以⾃学为主,在⽹上收集各种学习资料,总结归纳学习经验,现将学习路径给予⼤家分享。
此次学习的hibernate的版本是:hibernate-release-4.2.4.Final(截⽌2015年7⽉31⽇最新版),JAVA的版本是:java8.0,使⽤的开发⼯具是:Eclipse Mars Release (4.5.0)。
第⼀天:Hibernate4基础知识和HelloWorld简单编程Hibernate是⼀种半成品ORM框架,对数据库持久化操作,程序员对数据库的操作转换成对对象的操作。
ORM 采⽤元数据来描述对象-关系映射细节, 元数据通常采⽤XML 格式, 并且存放在专门的对象-关系映射⽂件中。
HelloWorld简单编程1、准备Hibernate环境(1)导⼊Hibernate的Jar包,如下:(2)导⼊Mysql驱动包,我⽤的数据库是:Mysql 5.0,数据库驱动包如下:以上所有Jar加完毕之后,需要加⼊到Eclipse⾃⾝系统⾥⾯,具体如下:以上操作完毕之后,Hibernate的环境就算搭建完毕,下⾯就可以进⼀步操作。
2、配置hibernate.cfg.xml⽂件,主要是对数据库的连接,具体如下:"-//Hibernate/Hibernate Configuration DTD 3.0//EN""/doc/63fa364d5022aaea998f0fde.html /hibernate-configuration-3.0.dtd ">rootmysqlname="connection.driver_class">com.mysql.jdbc.Driver jdbc:mysql:///Test(或者:jdbc:mysql://localhost:3306/Test)name="dialect">org.hibernate.dialect.MySQLInnoDBDialecttruetrueupdate3、编写⼀个实例类News.java,具体代码如下:package com.hibernate.helloworld;import java.sql.Date;public class News {private Integer id;private String title;private Date date;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String getAuthor() {return author;}public void setAuthor(String author) {this.author = author;}public Date getDate() {return date;}public void setDate(Date date) {this.date = date;}public News(String title, String author, Date date) { super();this.title = title;this.author = author;this.date = date;}public News(){}@Overridereturn"News [id="+ id+ ", title="+ title+ ", author="+ author + ", date=" + date + "]";}}4、创建News.hbm.xml配置映射⽂件,具体代码如下:"/doc/63fa364d5022aaea998f0fde.html /hibernate-mapping-3.0.dtd">5、将映射⽂件News.hbm.xml指定到hibernate.cfg.xml配置⽂件⾥⾯,即在hibernate.cfg.xml⽂件⾥加⼊⼀⾏映射代码,具体如下:6、创建hibernate API操作测试类(Juit测试),验证hibernate的优势效果,具体代码如下:package com.hibernate.helloworld;import java.sql.Date;import org.hibernate.Session;import org.hibernate.SessionFactory;import org.hibernate.Transaction;import org.hibernate.cfg.Configuration;import org.hibernate.service.ServiceRegistry;import org.hibernate.service.ServiceRegistryBuilder;import org.junit.Test;public class HibernateTest {@Testpublic void test() {//1. 创建⼀个 SessionFactory 对象SessionFactory sessionFactory=null;//1). 创建 Configuration 对象: 对应 hibernate 的基本配置信息和对象关系映射信息Configuration configuration=new Configuration().configure();//4.0 之前这样创建//sessionFactory=configuration.buildSessionFactory();//2). 4.0以后创建⼀个 ServiceRegistry 对象: hibernate 4.x 新添加的对象//hibernate 的任何配置和服务都需要在该对象中注册后才能有效.ServiceRegistry serviceRegistry=newServiceRegistryBuilder().applySettings(configuration.getProperties() ).buildServiceRegistry();sessionFactory=configuration.buildSessionFactory(serviceRegistry) ;//2. 创建⼀个 Session 对象Session session=sessionFactory.openSession();//3. 开启事务Transaction transaction=session.beginTransaction();//4. 执⾏保存操作News news = new News("Java12345", "ATGUIGU", new Date(new java.util.Date().getTime()));session.save(news);//5. 提交事务/doc/63fa364d5022aaea998f0fde.html mit();//6. 关闭 Sessionsession.close();//7. 关闭 SessionFactory 对象sessionFactory.close();}}7、测试结果如下:(1)数据库⾥⾯的结果如下:(2)Eclipse下的语句⽣成如下:以上就是简单Hibernate的测试,总结:1、不需要在数据库⾥⾯创建任何数据,由hibernate ⾃动⽣成;2、代码简单易理解,不复杂,测试数据只需要先创建以下⼏个步骤:SessionFactory-→Session-→Transaction-→session操作数据库-→提交-→关闭;3、不需要写SQL 语句,从头到尾没有写⼀条SQL语句,反⽽Hibernate帮我们⽣成SQL语句。

stata学习笔记(stata学习笔记)data managementCreate a new dataEdit / / variables in the data table and the creation of open dataInput x1 x2......Set OBS 10Gen x1=_nGen, x2=seq ()Egen, x3=seq (), B (5) t (5)Egen x4=fill (3434)Rename X1 pop / / variable VAR1 renamed popRename x2 placeMax C= (1,0.8\0.8,1)Drawnorm, x1, X2, means (1,10), SDS (0.3,2), corr (C), n (500)Gen x1=invnormal (uniform ())Gen roll=1+trunc (uniform () *6) randomly generates 1-6 randomnumbersGen x=exp (uniform ())Gen x=-3ln (uniform ())Gen x= (invnorm (uniform ())) ^2 chi square distributionGen, x=invttail (DF, uniform ()) t distributionGen, x=invFtail (DF1, df2, uniform ()) F distributionSample 10, countLabel variable pop population in 1000s, 1995 "/ / add tags for the variable popLabel define, sex_label 1, "male", 2 "female""Label values sex sex_label / / add value labels for the variable sexSave AAA / / keep the aaa.dta fileSave, replaceMerge dataUse a.datAppend using B.datUse a.datSort placeSave, replaceUse B.datSort placeMerge place using a.datReshape, long, grow, I (ID), J (year)Reshppe, wide, grow, I (ID), J (year)ClearCD f:\ statistics \stataUse AAASort pop / / as the pop variable orderingOrder place pop place pop / / variables were placed in the first, second positionDescrible / / description variable informationList / / show variable and variable valuesList, Sep (3) is shown separately in each of the 3 linesList, sepby (VaR) is shown as bounded by the VaR variableSummarize X / / display basic information variables, can add "d" to display detailed informationBy, VAR1, var2, sort:su, X (by can be used for Su, CI, centile, etc.)Tabstat, x, stats (mean, median, SD,, VaR, skewness, kurtosis, IQR, CV, semean, P2, etc)Collapse (sum), VAR1, var2 (SD), var3 (mean), newvar1=var4 (median), newvar2=var5A subset of variables (used by if and in)List, pop, place, sex, in, 1/50Sort popList pop place in -4/1 / / four observation shows that the value of pop maximumSummarize if pop<1000Summarize if place = = "China""Summarize, pop, place, sex, if, pop>100 & pop<1000Summarize place sex if pop<100 pop>1000 |Summarize place if pop<. / / the missing value is bigger than any numericalDrop, pop, if, place==, "China""KeepCreate and replace variables1, use, canada1, clearGenerate gap=flife-mlife"Label variable gap" "flife-mlife gap life""Format gap%4.1f / / fixed width of 4 decimal 1Other%4.1g (width 4, decimal part at least 1, can be displayed by decimal or scientific notation),%4.1eFormat only changes the display and does not affect the calculationUse, canada1, clearGenerate type=1Replace, type=2, if, place==, "Canada""Replace, type=3, if, place==, "Yukou""operator+ * / ^ mod (x, y)Use function(ABS)ACOS () //di ACOS (0.5) *180/_piSin, cos, asin, atan, atan2 () y/x's tangent functionSqrt, log (), ==ln (), log10, expThe smallest integer of ceil (x) >xThe maximum integer of floor (x) <xRound (x) four into fiveComb () lnfactorial ()distribution functionProbability of Ttail (DF, t) t>t0.05 (Dan Ce)Invttail (DF, P) calculates the T value based on the probability, and P is the right probabilityF (DF1, df2, f) left probability invF (N1, N2, P)Ftail (DF1, df2, f) the right probability invFtail (N1, N2, P)Chi2 (DF, x) left probabilityChi2tail (DF, x) right probabilityBinomial (n, x, P), n trials, x times and smaller probability1-binomial (n, X-1, P)Normal (z) standard normal distribution, left, cumulative probabilityDate function(1) assume that the numeric variable a is 20100312Gen str str_a=string (a,%10.0f) / / a conversion to character variableGene _ to date = DATE ("STR _, Ymd") / / 转换str _ a为日期变量, 返回值为当前日期 - 1960年1月1日的数值FORMAT DATE _% TD / / 转换date _ a的格式为日期12may2010假设有数值变量a格式为20100312101205STR str Gene _ = String ("% 16.0f")To _ = Clock Gene Double Date (STR _, "ymdhms")_% TC to date format假设有三个数值变量m、d、y分别表示月、日、年Gene _ date to mdy = (m, d)EgenEgen = seq (x t), B (3) (2) 111222111222Egen fill (x = 100,98) 100 98 94 96X = (0,2,7,0,2,7 egne fill)Rowmean egen x = (x1, X2, x3) 产生新变量, 其值为x1x2x3各行的均值Rowsum egen x = (x1, X2, x3) 产生新变量, 其值为x1x2x3各行的和Egen = STD X (a)Num 1: 15 for STD / egen xx = (AX)Xrank egen = RANK (X)10、其他函数Recode Group encodeX1 = recode gene (AGE, 24,28,32, ~) / / < < = 24 = 28Egen Group (x2 = x1)Strvar Gene ENCODE, 将字符变量转为数值变量 (numvar)Decode numvar, Gene (strvar)创建新的分类变量和定序变量假设有分类变量 (byte) type (1 - 3)Tab typeTab type, Gene (type) / / 产生type1 - 3三个哑变量2、将数值变量X1 = recode gene (AGE, 24,28,32, ~) / / 以 < < = 24 = 28~分组Egen Group (x2 = x1)变量下标Di x [4]Gene _ = X - X [N - 1] / / x与其前一个数值的差B gene _ = X - X [n + 1]从外部ascii文件导入数据以空格分隔, 字符串需带引号Str30 INFILE Place ulife tlife using aaa.raw / / 产生三个变量, place为30长度的字符变量COMPRESS / / 压缩place变量为最长的字符以tab或 "," 分隔Insheet Place ulife tlife using aaa.raw, comma (or tab).固定栏宽Infix Wood Year 1 - 4 5 - 8 9 - 10 aaa.raw using Water绘图Hist X, Bin (10) xlabel (0 (2) 10) ylabel (100 1000 xtick (100) (1) (2) 11) Norm fractionHist Start (50 x width (5) (FREQ by Group, total)Graph TwoWay Scatter and | | X Line and | | lfit X and X, mlabel (ID) msymbol (o / X)Graph TwoWay Scatter and x | | lfitci, STDFGraph Matrix X and ZGraph TwoWay line and year XGraph TwoWay line and yaxis (1 year) | yaxis | x Year (2)Graph TwoWay area and year XGraph box x and Z over (Group) yline (6.35).Graph pie x and Z, by (Group) foot (3, explode)Graph BAR (Mean) of X and Z, over (Group)Grapg DOT (median) x1 x2, over (Group) Marker (1, msymbol (OH) (2) Marker, msymbol (X))X Qnorm, GridPnorm X, Grid交叉表Tab B, SUM (X) meanTab B, All tabi B \ C D, All tab b] [FW = count, AllA B C 分布绘制abc的一维表 tab1A B C 建立所有可能的二维表 Tab2Sort by: a B C, Tab, All 以c的不同取值分别绘制a b的二维表Table Row col (col1, by 绘制多维表 row1)Sktest x swilk sfrancia正态性检验及数据变换Sktest x swilk sfrancia立方严重负偏态平方轻度负偏态平方根轻度正偏态对数正偏态平方根负倒数严重正偏态倒数非常严重正偏态平方倒数同上立方倒数同上X / / 产生以上8种变换后的正态性检验 LadderGladder X / / 针对ladder结果绘制直方图Bcskews newx = X / / 产生新变量newx, 是对x的变换方差齐性检验Sdtest X1 = x2Sdtest X1, by (Group)Robvar X, by levene检验, 返回值 (Group)W0: 均数 W50: 中位数 W10: 后的均数 trim10%方差分析单个样本TTEST (x = 10 signtest x = 10 二项分布ttest x1 = x2 signrank x1 = x2 wilcoxon符号检验ttest x city (group) ranksum x city (group) wilcoxon检验ttest x1 = x2, unpaired unequalbitest x = = pbitesti n c p单因素方差分析oneway x group, tabluate scheffe bonferroni sidak kwallis x city (group)多因素方差分析anova x a # # btest 1 (a = (test 2 (b = 3. bbonferonni: r (p) * c c: 比较次数, 组数x (组数 - 1) / 2scheffe: 1 - f (组数 - 1, 误差自由度, r (f) / (组数 - 1))regresspredict newvar 预测值predict newvar, stdp 预测值标准误anova x a b | aanova x a / id | a b a # banova x a b c.age相关分析 (town was:)cor x ypwcorr x y, bonferrior / sidakspearman x y, bonferrior / sidakpcorr y x1 - x3 去除其他x的影响后y与x的偏相关系数回归分析基本方法reg y x1 x2 x3, beta uncons预测值predict newvar, cooksd hat covratio dfits residuals rstudent rstandard stdp stdfhat > 2p / n 发现高杠杆值dfits > 2sqrt (p / n) 案例的自变量组合对回归直线的影响力cooksd > 4 / n 同上welsch > 3sqrt (p) 同上covratio: | r - 1 | > = 3p / nrvfplot, yline (0)假设检验reg x * ytest x1 x2 x1 和x2回归系数同时为0test x1 = x2虚拟变量loss region gene (reg) / / 产生reg1 - 4四个哑变量reg cmat reg2 / / reg2与其他3个地区的比较reg cmat reg1 reg2 reg3 reg4 = = xi: reg cmat i.region 此方法便于做交互分析char region [omit] 4 (与xi共同使用)xi: reg camt i.region逐步回归sw reg y x1 - x4, per (. 06) pe (0.05)sw reg y x1 x2 (x3, x4) lockterm1 per (. 06)面板数据iis regionten yearxtreg y x1 x2, rextmixed y 固定变量 | | school: 随机变量回归诊断estate ic 返回aic bic ll (null) ll (model) 值 (log likelihood 对数似然值)quietly reg y x1 - 85estimates of large fullquietly reg y x1 - x4lrtest fullovtest p < 0.05提示有二次、三次或四次方项目需要添加hettest p < 0.05提示方差不齐, 误差散点图不是随机分布的dwstat 一价自相关的durbin - watson检验kic 自变量共线性检查kic > 10 平均vif > 1 有问题宽容度 (vif的倒数) 表示该变量独立程度, 越大则越独立rvfplot 预测值与残差值的散点图rvpplot x 某一个自变量x与残差的散点图avplot x 去除其他变量影响后的x与y的线性关系, x轴上偏离的数值多为高杠杆值avplotsacprplot x, lowess 虚线在中间部分与直线不重和表示可能x与y 存在其他非线性关系,另外可以报告与x具有线性关系的其他自变量lvr2plot 注意拟合不好且具有较高杠杆作用的值可能是高杠杆值hat 较大值提示高杠杆值dfits cooksd covratio 提示对y影响较大的值logistic回归logit y x * logit y x *, orblogit n x * ylrocroctab y x, graphroccomp y x1 x2 比较y与x1的roc曲线和y与x2的是否相同rocgold y x x1 x2 比较y与x (金标准) 的roc曲线和y与x1的是否相同lsens, genprob (prob) gensens (sen) genspec (spec)lstatlfit, group (10) est gof, group (10)predict the phat, hat deviance ddeviance dbet dx2 dbetaclogit y x *, group (matchvar)ologit x * ymlogit y x *, b (1) mlogit y x *, rrrconstraint define 1 [3] x = 2 [2] xconstranit define 2 [4] x = 3 [2] xmlogit y x, c (1, 2) b (1)多元方差分析hotelling x *hotelling x *, city (group)manova x1 x2 x3 = g b g * b广义线性模型gaec y x1 x2家庭(高斯)链接(身份)* /正态分布线性回归GLM y x1 x2,家庭(二项式)链接(Logit)* /物流回归GLM y x1 x2,家庭(Poisson)链接(日志)lnoffset(暴露人年变量)泊松y x1 x2,曝光(暴露人年变量)poisgof [皮尔森]GLM y x1 x2,家庭(nbinomial)链接(日志)nbreg y x1 x2gnbreg y x1 x2,lnalpha(VAR)预测主成份分析PCA X点状图因子分析X因子*,PCF矿(0.5)主成份法X因子*,ML矿(0.5)最大似然法X因子*,IPF /迭代主因子法旋转方差极大旋转旋转,旋转斜交法生存分析认识时间,失败(结果)stsum,由(治疗)后缀树,由rmean(处理)STS列表,由(治疗)以损失为例的STS图STS图,通过gwood(治疗)STS测试组streg治疗组,诺尔公司(指数/ Weibull)预测new_var = = 1如果治疗,监测stcox治疗组,诺尔考克斯结果治疗组,死亡(结果)诺尔申银万国考克斯结果治疗组,死亡(结果)诺尔流行病队列研究IR案例的曝光时间(人年数)硝酸铵CS案例曝光[或数]CSI(A组)可使用结核病和精确(默认)计算RR可信区间,不能使用伍尔夫病例对照研究cc案例由(组)公开甲丙氨酯MCC的病例对照选择A B C D可使用精确(默认)、伍尔夫、麦田计算RR可信区间tabodds模型不如用物流、考克斯比例风险模型。

SaToken学习笔记-02SaToken学习笔记-02如果排版有问题,请点击:常⽤的登录有关的⽅法- StpUtil.logout()作⽤为:当前会话注销登录调⽤此⽅法,其实做了哪些操作呢,我们来⼀起看⼀下源码/*** 当前会话注销登录*/public static void logout() {stpLogic.logout();}⼀开始调⽤了stpLogic.logout()⽅法什么是stpLogic?stpLogic是在StpUtil类中定义的⼀个底层的StpLogic对象public static StpLogic stpLogic = new StpLogic("login");并且把stpLogic的loginkey设置为login,在创建对象时会在 SaTokenManager 中记录下此 StpLogic,以便根据 LoginKey 进⾏查找此对象继续进⼊/*** 当前会话注销登录*/public void logout() {// 如果连token都没有,那么⽆需执⾏任何操作String tokenValue = getTokenValue();if(tokenValue == null) {return;}// 如果打开了cookie模式,第⼀步,先把cookie清除掉if(getConfig().getIsReadCookie() == true){SaHolder.getResponse().deleteCookie(getTokenName());}logoutByTokenValue(tokenValue);}可以看到,⾸先取到tokenvalue的值,判断token是否为空,如果为空就直接结束,表⽰此⽤户已经为⾮登录状态。
接着通过调⽤getIsReadCookie()⽅法返回isReadCookie的常量值,默认为true。
判断如果返回的值为true则表⽰打开了Cookie模式,使⽤deleteCookie()⽅法通过传⼊的token清楚对应的Cookie。

∙韩顺平 servlet与jsp 笔记与心得∙∙∙∙Java EE概述:Java EE是一个开放的平台,它包括的技术很多,主要包括十三种核心技术(java EE就是十三种技术的总称)。
建立一个整全的概念。
J2ee的十三种技术(规范)1.java数据库连接(JDBC)。
——JDBC定义了4种不同的驱动:1.JDBC-ODBC桥,2.JDBC-native驱动桥3,JDBC-network桥4.纯java驱动。
2.Java命名和目录接口(JNDI)(它是为了对高级网络应用开发中的使用的目录基础结构的访问。
)。
3.企业Java Beans(Enterprise Java Beans,EJB)(它提供了一个架构来开发和配置到客户端的分布式商业逻辑,因此可以明显减少开发扩展性、高度复杂企业应用的难度。
)。
4.JavaServer Pages(JSPs)。
5.Java servlets(servlets提供的功能大部分与JSP相同,JSP中大部分是HTML代码,其中只有少量的Java代码,而servlets则相反,它完全使用Java编写,并且产生HTML代码。
)。
6.Java IDL/CORBA(用得不多)。
7.Java 事务体系(JTA)/Java事务服务(JTS)(用得不多)。
8.JavaMail和JavaBenas激活架构(JavaBeans ActivationFramework,JAF)。
(JavaMail是一个用来访问邮件服务的API)。
9.Java信使服务(Java Messaging Service,JMS)(JMS是一个用来和面向信息的中层通信的API)。
10.扩展标记语言(Extensible Markup Language,XML)。
11.12. 13当前流行的及格框架struts+hibernate+spring(ssh).Java ee的开发环境(eclipse)Eclipse是一个开源的、可扩展的集成开发环境,已经成为目前最流行的j2ee 开发工具。
kettle学习笔记(五)——kettle输出步骤⼀、概述 数据库表: • 表输出 • 更新,删除,插⼊/更新 • 批量加载(mysql,oracle) • 数据同步 ⽂件: • SQL ⽂件输出 • ⽂本⽂件输出 • XML 输出 • Excel Output/Excel Writer 其他(报表、应⽤)⼆、数据库输出 1.表输出 使⽤SQL的⽅式向数据库插⼊数据(INSERT) ⽀持批量提交 ⽀持分区(Date分区) ⽀持字段映射 ⽀持返回⾃增列 这⾥提⽰⼀下出现表输出的中⽂乱码问题的解决⽅案: 设置连接编码:characterEncoding utf8 设置连接编码⼀般就可以正常输出不乱吗的字符了。
如果还有问题,可以继续设置客户端编码 设置客户端:set names utf8; ⼀个测试的表输出如下: 如果选择分区,需要选择Date字段进⾏分区,并且需要⼿动创建表(例如按⽉分区,有201804 201805两个⽉,则需要创建tb_201804 tb_201805两个表) 如果是要错误输出,可以单击⼀下连接线改变输出⽅式(⼀把锁:开始了执⾏下⾯的,勾和叉:正确或者错误输出) 2.返回⾃增主键 表输出的配置如下: 选择了【裁剪表】,在数据加载之前会对此表做truncate操作。
预览即可查看返回的主键: 3.数据库字段映射 前⾯步骤可以后后⾯表输出进⾏字段映射匹配: 表输出配置如下: 字段映射: 使⽤猜⼀猜可以进⾏名称匹配,如果需要⼿动匹配,可以左右分别选择,点击Add即可! 并且映射完成之后也可以删除丢弃某些字段 4.其它操作——删除、更新、插⼊更新 删除: 根据关键字匹配,删除数据库中已有的数据。
更新: 根据关键字匹配,更新数据库中已有的数据。
插⼊更新: 有则更新,⽆则插⼊。
操作都是类似,上⾯进⾏匹配,下⾯进⾏处理: 5.数据同步 基于⽐较的同步⽅式。
根据⼀个flag字段执⾏相应的插⼊/更新/删除操作。

学习笔记-Tableau一、简介Tableau 帮助人们看到并理解数据。
2020 年,世界产生的数据量将是 2011 年的 50 倍,信息源的数量将是 75 倍 (IDC,2011 年)。
这些数据是如此的庞大,为人类的进步提供了前所未有的机会。
但是,若要把机会变成现实,人们就得需要这些指尖中的数据力量。
Tableau 就是将它变为现实的一种构建软件。
Tableau 帮助人们使用数据来解决问题,使数据分析快速,方便,美观并且实用。
它是一款适合于任何人的软件。
二、Tableau 的理念创建一家从根本上改变人们如何看待和理解数据的公司需要一种不同的哲学理念。
所以TABLEAU 创始人将这具有颠覆性的观点浸透进他们的公司。
1. 解放数据数据分析是关于问的问题,而不是学习软件。
做出鼓舞人心,易于使用的产品,帮助人们通过数据获得成功。
因此,数据可以充分发挥其潜力,并积极影响世界。
通过自由使用数据来为那些关心数据之间关系的人讲述数据背后的故事。
发现并共享这些故事很容易。
但实际上并非如此。
为什么?大多数软件,旨在帮助人们访问和理解数据却很难使用。
由于过大,数据被困于脚本,向导和代码中。
如今,一切都已改变。
人们可以选择另一种方式, 解放每个人的数据。
2. 提高工作效率当一家公司能够为人们提供自助式分析工具,人们可能会以一种无法预计的方式向前发展。
充分表达自己的聪明才智和创造力。
不幸的是,大多数商业分析产品都是集中控制数据,而不是大众化。
大多数公司的人只能回答基本问题,深层次的问题都只能依赖于专家。
他们通过不灵活的表单系统来工作。
或者,通过企业的智能业务平台花更多的时间来开发。
这种做法没有任何效率。
有效的方式就是帮助人们思考,行动和传递信息。
3. 为人而设计Tableau 的设计理念专注于人。
这些人包括:在大型或小型企业工作的人,在政府中任职的人,非营利组织中的人,博客,学生,任何人,每个人。
Tableau 坚持以用户至上的原则来构筑产品。

1.1过滤流与包装类:在上节中对于过滤流和包装类的概念给出了明确的定义,过滤流和包装类是定义在节点流的基础之上的。
程序中可以通过一个间接的流类去调用节点流类,以达到更加灵活方便的读取给种类型的数据,这个间接的流类就叫做过滤流类,也叫包装类。
如果我们仅仅使用节点流类虽然也可以达到输入输出的目的,但是我们必须先将其他类型的数据的数据转换成字节数组后写入文件或是将从文件中读取的字节数组转换成其他类型,这样带来了一些困难和麻烦。
因此就引入了包装类作为一个中间类,这个中间类提供了读写各种类型的数据的各种方法,在这个中间类的方法内部可以将其他数据类型装换为字节数组,然后调用底层的节点类将这个字节数组写入目标设备。
过滤流类的引入方便了数据的读写。
BufferedInputStream与BufferedOutputStream类,缓冲流为IO流增加了内存缓冲区,增加缓冲区有两个基本目的:1、允许Java程序一次不止操作一个字节,提高了程序的性能2、由于有了缓冲区,使得在流上执行skip,mark和reset方法都成为可能BufferedInputStream与BufferedOutputStream是Java提供的两个缓冲区包装类,不管底层系统是否使用了缓冲区,这两个类在自己的实例对象中创建缓冲区。
DataInputStream与DataOutputStream类DataInputStream允许应用程序以与机器无关方式从基础输入流中读取基本Java 数据类型。
应用程序可以使用DataOutputStream写入稍后由数据输入流读取的数据。
PrintStream类PrintStream类提供了一系列的print和println方法,可以将基本数据类型的数据格式化成字符串输出。
ObjectInputStream与ObjectOutputStream这两个包装类,用于从底层输入流中读取对象类型的数据和将对象类型的数据写入到底层输出流。
软件开发实习技术学习笔记导语:软件开发是当前互联网时代最重要的技能之一,有着广泛的应用领域。
作为软件开发实习生,对于学习和掌握相关的技术知识具有重要意义。
在这篇文章中,我将分享我在软件开发实习过程中所学习到的一些技术知识和经验,希望能对初学者提供一些帮助。
一、数据库1. 数据库概述:数据库是软件开发中重要的数据存储和管理工具,常见的数据库种类有关系数据库、非关系数据库等。
2. SQL语言:SQL是结构化查询语言,用于对数据库进行增删改查操作。
了解SQL语法和常用命令对于数据的有效管理至关重要。
3. 数据库设计:合理的数据库设计是软件开发的基础,包括实体-关系模型(ER模型)、范式等核心概念。
通过设计规范的数据库结构,可以提高数据的存储效率和查询性能。
二、前端开发1. HTML/CSS/JavaScript:这是前端开发的基础知识。
HTML负责网页的结构,CSS负责网页的样式,JavaScript则实现网页的交互功能。
2. 前端框架:常用的前端框架有Bootstrap、Vue.js、React等。
掌握这些框架可以帮助开发人员更高效地进行网页开发。
3. 移动端开发:随着智能手机的普及,移动端开发变得越来越重要。
学习使用响应式设计等技术,可以实现网页在不同屏幕上的适应性。
三、后端开发1. 编程语言:后端开发常用的编程语言有Java、Python、C#等。
选择一门熟悉的语言,并学习其相关框架和库,对于后端开发至关重要。
2. Web框架:常用的后端Web框架有Spring Boot、Django、等。
这些框架提供了丰富的功能和工具,能够帮助开发人员快速构建稳定的后端系统。
3. 接口设计与实现:后端开发主要负责数据的处理和逻辑的实现,学习接口设计规范和实现技巧,能够更好地协同前端完成项目开发。
四、版本控制与团队协作1. Git:Git是目前最流行的版本控制工具,可以有效地管理代码版本,便于多人协同开发。
2. GitHub/GitLab:这些平台提供了基于Git的代码托管服务,方便团队成员协作、交流和代码审查。
爱淘课学习笔记1、html头部标记(1) 网页标题标记〈title〉</title〉;(2)meta标记meta叫做元信息标记,这个元素提供的信息不显示在页面中,一般用来定义页面的关键字、页面说明、刷新等。
meta标记不需要结束标记,一个尖括号内就是一个meta内容,在一个html页面中可以有多个meta。
meta元素的属性有两个:分别是name和http—equiv.name-—设置网页的关键字和描述信息等;设置关键字:如:<meta name=”keywords” content=”百度贴吧" >设置描述信息,如:<meta name=”description”content="这是描述信息” /〉其他的,还可以设置网页作者,如:〈meta name=”author” content=”周杰伦" / 〉http-equiv——定义网页语言的属性,当访客浏览你的网页时,浏览器会自动识别并设置网页中的语言;设置语言:<metahttp—equiv=”content-type”content=”text/html”charset=”GB2312” />(前半部分需要记忆,只需要更改charset的属性值就可以了,可以更改为中文、日文、英文等)。
设置网页在指定时间自动跳转:〈meta http—equiv=”refresh”content="5;url=http://www。
” / 〉即网页打开5秒钟之后,自动跳转到百度页面上。
2、body标签(1)body标签的属性①设置网页背景色或网页背景图body标签中用bgcolor来定义网页的背景颜色,属性值为16进制的颜色值。
直接写在body标签的尖括号里即可。
如:<body bgcolor="#FF00FF”>body标签中用background属性来定义网页的背景图,如:<body background=”1.jpg”〉(建议图片地址使用相对路径)②设置文字的颜色—-通过body标签的text属性如:<body text="#FFFF00”>我们可爱的学校〈/body〉预览网页,可发现字体的变化。
iText学习笔记之PdfPTableiText学习笔记之PdfPTable Email:cmliu2004@ QQ:27236220PdfPTablePdfPTable当你想使用iText制作账单、发票、清单、报表等电子表单时,你很可能需要将数据放置在表格当中,这就是下面要介绍的PdfPTable对象和PdfPCell对象。
这两个类使用起来都非常方便:构建一张指定列数的表,然后添加单元格:PdfPTable table = new PdfPTable(3);PdfPCell cell = new PdfPCell(new Paragraph("header with colspan 3"));cell.setColspan(3);table.addCell(cell);table.addCell("1.1");table.addCell("2.1");table.addCell("3.1");table.addCell("1.2");table.addCell("2.2");table.addCell("3.2");document.add(table);PdfPTable是一个强大而灵活的对象,但PdfPTable只用于生成PDF,如果你需要生成HTML或RTF文档,那么只能使用Table对象了(Table对象现在已不被支持)。
通过Document.add()方法添加PdfPTable对象,其默认宽度是页面可编辑空间的80%并居中对齐,要想改变这些默认值,可使用setWidthPercentage和setHorizontalAlignment方法。
iText学习笔记之PdfPTable Email:cmliu2004@ QQ:27236220// step1Document document = new Document(PageSize.A4);try {// step2PdfWriter.getInstance(document,new FileOutputStream("TableWidthAlignment.pdf"));// step3document.open();// step4PdfPTable table = new PdfPTable(3);PdfPCell cell = new PdfPCell(new Paragraph("header with colspan 3"));cell.setColspan(3);table.addCell(cell);table.addCell("1.1");table.addCell("2.1");table.addCell("3.1");table.addCell("1.2");table.addCell("2.2");table.addCell("3.2");cell = new PdfPCell(new Paragraph("cell test1"));cell.setBorderColor(new Color(255, 0, 0));table.addCell(cell);cell = new PdfPCell(new Paragraph("cell test2"));cell.setColspan(2);cell.setBackgroundColor(new Color(0xC0, 0xC0, 0xC0));table.addCell(cell);document.add(table);table.setWidthPercentage(100);document.add(table);table.setWidthPercentage(50);table.setHorizontalAlignment(Element.ALIGN_RIGHT); document.add(table);table.setHorizontalAlignment(Element.ALIGN_LEFT);document.add(table);} catch (Exception de) {de.printStackTrace();}// step5document.close();上面的例子运行效果如下:iText学习笔记之PdfPTable Email:cmliu2004@ QQ:27236220我们在表格中定义了很多列,iText自动计算各列的绝对宽度,每个单元格的默认宽度是:表格的绝对宽度/列数,同一表格中的所有列的宽度相同。
ThinkPHP php框架 真实项目开发步骤: 1. 多人同时开发项目,协作开发项目、分工合理、效率有提高(代码风格不一样、分工不好) 2. 测试阶段 3. 上线运行 4. 对项目进行维护、修改、升级(单个人维护项目,十分困难,代码风格不一样) 5. 项目稳定的运行阶段 6. 项目停止运行(旧项目的人员已经全部离职,新人开发新项目)
问题: 1. 多人开发项目,分工不合理,(html php mysql) 2. 代码风格不一样,后期维护十分困难 3. 项目生命周期十分短,项目生命没有延续性,造成资源浪费、人员浪费 4. 项目不能很好适应客户需求,牵一发而动全身。
其他相关框架 1. zendframework zend php语言公司发布的官方框架,重量级(功能多) 2. yii 美国华人开发的框架,xue qiang, qiang, 重量级框架,纯OOP框架 3. CI CodeIgniter 轻量级框架,开发速度快,部署灵活 4. cakephp 外国框架,重量级,速度慢 5. symfony 外国重量级框架 6. ThinkPHP 轻量级框架,国人框架,入门容易
什么框架: 一堆代码的集合,里边有变量、函数、类、常量,里边也有许多设计模式MVC、AR数据库、单例等等。 框架可以节省我们50-60%的工作量,我们全部精力都集中在业务层次。
为什么使用框架 框架可以帮组我们快速、稳定、高效搭建程序系统 该系统由于框架的使用使得本身的维护性、灵活性、适应客户需求方面得到最大化的增强。 使用框架的过程中可以使得我们的注意力全部集中业务层面,而无需关心程序的底层架构。 【使用框架】 thinkphp.cn
thinkphp 3.2版本 【框架项目部署】 shop商城项目 book图书管理系统 car汽车销售系统 三个项目可以使用一个公共的tp框架。
步骤: 1. 创建一个入口文件index.php