利用DCT系数计算两幅图像之间的相似度
- 格式:pdf
- 大小:114.40 KB
- 文档页数:5

基于均值聚类的图像检索技术在数字图书馆中的应用摘要:在数字图书馆的各类数据查询中,图像检索占有十分重要的地位。
为了更好地实现图像检索任务,本文建立了一种新的基于内容的图像检索方法。
这种图像检索方法先对图像进行模块化,再根据各个图像块计算出其相应的DCT系数并形成特征向量,再通过k-均值聚类方法生成用于最终检索的12维特征向量,最后利用卡方距离进行相似度差异的检测完成图像检索。
为了模拟本文方法在数字图书馆中的使用效果,自建了图像检索系统和小型图像数据库。
实验结果表明,本文所提出的图像检索方法具有较高的检索准确性,可以用于数字图书馆中的图像检索。
关键词:数字图书馆图像检索DCT系数k-均值聚类随着计算机技术、网络技术、数字化技术的迅猛发展,传统的图书馆模式被彻底打破,一种全新的图书馆模式飞速发展起来,这就是数字图书馆[1]。
相比于传统图书馆模式,数字图书馆具有海量可扩展存储、远程二十四小时在线服务、信息速递即发即收等诸多优点[2],因此受到用户的广泛青睐。
在数字图书馆的各种信息资源中,图像是用户需求量非常大的资源。
因此,如何根据用户需要,准确、迅速地查询到相应的图像资源,成为数字图书馆技术发展过程中必须攻克的重要课题,这就促成了图像检索技术的出现[3]。
图像检索技术有两个重要分支,一是基于文本的图像检索,一是基于内容的图像检索(Content Based Image retrieval,简称CBIR)。
从近年来的发展态势看,CBIR技术已经称为数字图书馆中图像检索技术的主要发展方向[4]。
无论是简单还是复杂的CBIR技术,其实现过程都包括两项基本内容,即定义检索规则和提取每一幅图像的检索特征[5~6]。
检索特征一般是基于图像像素值的,它是图像内容的一种压缩描述。
在CBIR 技术中,直方图、颜色布局、区域信息这三类特征被广泛使用[7~8]。
本文将离散余弦变换(Discrete cosine transform,简称DCT)系数作为特征向量,构建一种基于k-均值聚类的图像检索技术,并通过自建的数字图像库来检验这种方法的有效性。

基于频域的SSIM立体图像评价方法杨蕾;牛林林;宋晓炜;刘清丽【摘要】针对空域SSIM(Structural Similarity)在立体图像评价中存在的人类视觉系统感知敏感性问题,提出了基于频域的SSIM立体图像质量评价算法.实验结果表明,相比其他图像质量评价方法,该算法更符合人类视觉系统的特性.【期刊名称】《中原工学院学报》【年(卷),期】2015(026)001【总页数】5页(P5-8,43)【关键词】图像质量评价;立体图像;结构相似度【作者】杨蕾;牛林林;宋晓炜;刘清丽【作者单位】中原工学院,郑州450007;中原工学院,郑州450007;中原工学院,郑州450007;中原工学院,郑州450007【正文语种】中文【中图分类】TN911.73平面图像质量评价有客观评价方法与主观评价方法两种。
主观评价方法是最准确的方法,但是存在着评价步骤复杂、实时性不好等问题,不能在图像处理系统中直接应用。
与主观评价方法不同,客观评价方法通过建立一定的数学模型,计算相应的参数或量化指标来判断平面图像的质量。
目前使用最多的二维图像质量客观评价方法是均方误差(MSE)和峰值信噪比(PSNR)两种方法。
这两种方法虽然计算简单,但有时和人眼的视觉感知不一致,造成客观评价结果不符合主观评价。
近年来出现了许多结合人类视觉系统的二维图像评价模型。
其中,HVS对于图像的低频分量敏感度比较高,对比敏感度函数(Contrast Sensitivity Function,CSF)可以用来模拟HVS的评价行为[1-6]。
与二维图像不同,立体图像是由左右两个视点的图像组成的。
在对立体图像质量进行客观评价时,若使用MSE和PSNR方法不能进行正确的评价。
近些年,Wang Z等认为:人眼可以高度自适应地提取出图像场景中的结构信息,于是提出了基于结构相似度(SSIM)的评价模型。
他们的实验结果表明,这个方法的性能比PSNR好[7-8]。
此后,其他学者提出了很多对SSIM的改进算法,例如:基于梯度结构和边缘结构的相似度[9]、基于频域的结构相似度[10-11]、多尺度的结构相似度[12]及将SSIM和其他的图像质量评价方法加权结合[1]等。
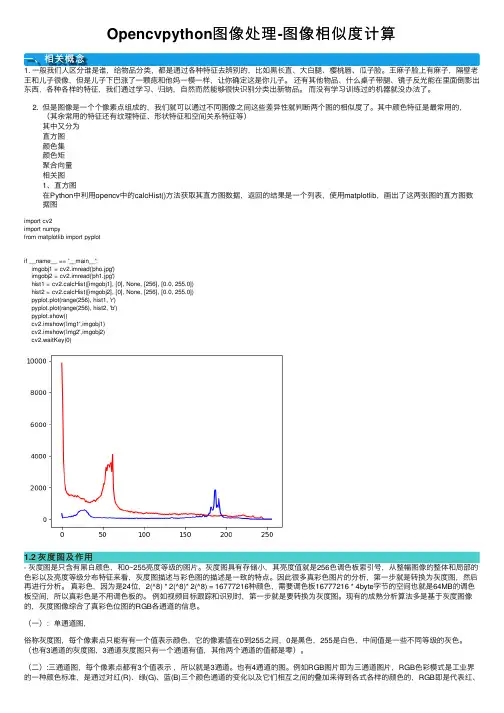
Opencvpython图像处理-图像相似度计算⼀、相关概念1. ⼀般我们⼈区分谁是谁,给物品分类,都是通过各种特征去辨别的,⽐如⿊长直、⼤⽩腿、樱桃唇、⽠⼦脸。
王⿇⼦脸上有⿇⼦,隔壁⽼王和⼉⼦很像,但是⼉⼦下巴涨了⼀颗痣和他妈⼀模⼀样,让你确定这是你⼉⼦。
还有其他物品、什么桌⼦带腿、镜⼦反光能在⾥⾯倒影出东西,各种各样的特征,我们通过学习、归纳,⾃然⽽然能够很快识别分类出新物品。
⽽没有学习训练过的机器就没办法了。
2. 但是图像是⼀个个像素点组成的,我们就可以通过不同图像之间这些差异性就判断两个图的相似度了。
其中颜⾊特征是最常⽤的,(其余常⽤的特征还有纹理特征、形状特征和空间关系特征等)其中⼜分为直⽅图颜⾊集颜⾊矩聚合向量相关图1、直⽅图在Python中利⽤opencv中的calcHist()⽅法获取其直⽅图数据,返回的结果是⼀个列表,使⽤matplotlib,画出了这两张图的直⽅图数据图import cv2import numpyfrom matplotlib import pyplotif __name__ == '__main__':imgobj1 = cv2.imread('pho.jpg')imgobj2 = cv2.imread('ph1.jpg')hist1 = cv2.calcHist([imgobj1], [0], None, [256], [0.0, 255.0])hist2 = cv2.calcHist([imgobj2], [0], None, [256], [0.0, 255.0])pyplot.plot(range(256), hist1, 'r')pyplot.plot(range(256), hist2, 'b')pyplot.show()cv2.imshow('img1',imgobj1)cv2.imshow('img2',imgobj2)cv2.waitKey(0)1.2 灰度图及作⽤- 灰度图是只含有⿊⽩颜⾊,和0~255亮度等级的图⽚。


标题:OpenCV DCT算法原理一、背景介绍DCT(Discrete Cosine Transform,离散余弦变换)是一种基于频率变换的算法,常用于图像压缩、图像处理和信号处理等领域。
在计算机视觉领域,OpenCV作为一个开源的计算机视觉库,提供了丰富的图像处理和分析功能,其中包括了DCT算法。
二、DCT算法原理DCT算法是通过对图像或信号进行频率变换,将原始的空间域数据转换成频域数据,从而实现图像压缩和去除冗余信息的目的。
DCT算法可以分为一维DCT和二维DCT。
在OpenCV中,通常使用二维DCT 来处理图像。
1. 一维DCT一维DCT是将一维的信号或图像数据转换为频域数据。
其数学表达式可以表示为:\[ X_k = \sum_{n=0}^{N-1} x_n \cdot\cos\left(\frac{\pi{N}}{2}\left(n+\frac{1}{2}\right)k\right), \ k = 0,1,...,N-1 \]其中,\( x_n \) 是原始的一维信号或图像数据,而 \( X_k \) 则是通过DCT转换得到的频率域数据。
2. 二维DCT二维DCT是将二维的图像数据转换为频域数据。
其数学表达式可以表示为:\[ F(u, v) = \frac{C(u)C(v)}{2N}\sum_{x=0}^{N-1}\sum_{y=0}^{N-1}f(x,y)\cos\left(\frac{(2x+1)u\pi}{2N}\right)\cos\left(\frac{(2y+1)v\pi}{ 2N}\right), \ u,v = 0,1,...,N-1 \]其中,\( f(x, y) \) 是原始的二维图像数据,\( F(u, v) \) 则是通过DCT 转换得到的频率域数据。
在OpenCV中,常使用的是8x8的块进行DCT变换。
三、OpenCV中的DCT实现在OpenCV中,DCT算法的实现主要基于DCT类。

相似图像的检测方法一、哈希算法哈希算法可对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。
结果越接近,就说明图像越相似。
常用的哈希算法有三种:1.均值哈希算法(ahash)均值哈希算法就是利用图片的低频信息。
将图片缩小至8*8,总共64个像素。
这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
将缩小后的图片,转为64级灰度。
计算所有64个像素的灰度平均值,将每个像素的灰度,与平均值进行比较。
大于或等于平均值,记为1;小于平均值,记为0。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。
均值哈希算法计算速度快,不受图片尺寸大小的影响,但是缺点就是对均值敏感,例如对图像进行伽马校正或直方图均衡就会影响均值,从而影响最终的hash值。
2.感知哈希算法(phash)感知哈希算法是一种比均值哈希算法更为健壮的算法,与均值哈希算法的区别在于感知哈希算法是通过DCT(离散余弦变换)来获取图片的低频信息。
先将图像缩小至32*32,并转化成灰度图像来简化DCT的计算量。
通过DCT变换,得到32*32的DCT系数矩阵,保留左上角的8*8的低频矩阵(这部分呈现了图片中的最低频率)。
再计算8*8矩阵的DCT的均值,然后将低频矩阵中大于等于DCT均值的设为”1”,小于DCT均值的设为“0”,组合在一起,就构成了一个64位的整数,组成了图像的指纹。
感知哈希算法能够避免伽马校正或颜色直方图被调整带来的影响。
对于变形程度在25%以内的图片也能精准识别。
3.差异值哈希算法(dhash)差异值哈希算法将图像收缩小至8*9,共72的像素点,然后把缩放后的图片转化为256阶的灰度图。
通过计算每行中相邻像素之间的差异,若左边的像素比右边的更亮,则记录为1,否则为0,共形成64个差异值,组成了图像的指纹。
相对于pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。

基于分类的DCT域快速分形编码方法[摘要] 该文提出了一种基于分类的dct域快速分形编码方法。
考虑到人眼视觉系统的特点,应用视觉亮度掩蔽特性来确定dct域中的均匀块,直接将其直流分量编码输出,无需分形编码。
为进一步缩短编码时间,对于非均匀块,利用两个低频dct系数分为三类:平滑类、对角线类和水平/垂直类,使匹配搜索在同类内进行。
实验表明,该方法解码图像质量无明显下降,编码时间和压缩比均有所提高。
[关键词] 分形编码 dct 分类1、引言分形压缩编码借助于编码效率高、解码速度快、与分辨率无关等潜力,成为当今国际上图像编码领域中令人瞩目的研究方向。
其中,减少搜索范围、加快编码速度一直是分形编码的研究热点之一。
为了在降低dct域分形编码的复杂度的同时保证恢复图像的视觉效果,本文提出应用视觉亮度掩蔽特性确定dct域内的均匀块;同时,为了进一步加快分形匹配搜索的时间,依据低频dct系数将非均匀的图像块分类,只在类内进行匹配查找,使得编码时间大大降低。
而且由于本文方法考虑到人眼的视觉特性,恢复图像的视觉效果也较好,图像质量有保证。
2、分形编码的基本思想分形编码方法一般首先在空间域内把图像分为不同大小的图像块:值域块r和定义域块d,其中r块较小且各块之间互不重叠,而d块较大(边长一般为r块的2倍),各块之间可以有重叠。
然后d块经过像素平均收缩为r块的大小,子块的全体构成定义域块池;对每一个r块,在定义域块池内找到其最佳匹配的d块,使得,其中s是比例因子,o是亮度调整因子,1是亮度均值为1的常值块。
此外,为了改进图像的质量,一般还要对定义域块d进行8种等距变换。
因为每一个r块的分形压缩码只需记录s、o、d块的位置等数据,所以可以达到较高的压缩比,非常适合有限带宽的应用场合。
但是由于在搜索匹配时,一个值域块要搜索全部的定义域块池来寻找最佳匹配块,大量的比较与计算浪费了时间,所以耗时过长限制了经典分形压缩编码(pifs)[1]的实用性发展。

fsimc计算公式
FSIMC(Feature similarity index for image quality assessment)是用于图像质量评估的一种指标,它主要用于衡量两
幅图像之间的相似度。
FSIMC的计算公式如下:
FSIMC(I1, I2) = l(I1, I2) s(I1, I2) c(I1, I2)。
其中,I1和I2分别代表两幅图像,l(I1, I2)代表亮度相似度,s(I1, I2)代表对比度相似度,c(I1, I2)代表结构相似度。
这三个
相似度分别综合反映了图像的亮度、对比度和结构信息的相似程度。
亮度相似度l(I1, I2)的计算通常使用均值和方差来衡量图像
的亮度信息。
对比度相似度s(I1, I2)通常使用局部对比度的加权
平均来衡量图像的对比度信息。
结构相似度c(I1, I2)则是通过图
像的梯度信息来计算的,通常使用局部结构相似度的加权平均来表示。
综合来看,FSIMC通过综合考虑图像的亮度、对比度和结构信息,能够比较全面地评估图像的相似度,对图像质量评估有一定的
参考价值。

phash方法phash方法是一种用于图像检索和相似度计算的算法。
它基于感知哈希算法,通过将图像转换为一个固定长度的哈希值来表示图像的特征。
phash方法可以应用于各种领域,如图像搜索、版权保护和图像识别等。
在phash方法中,图像首先通过离散余弦变换(DCT)将其转换为频域表示。
然后,根据变换后的图像,计算每个像素点的相对能量,并将其映射到一个固定长度的二进制串。
这个二进制串就是图像的感知哈希值,用于表示图像的特征。
phash方法的优点是能够对图像进行压缩,将复杂的图像信息转化为固定长度的哈希值,并且具有一定的抗干扰能力。
因此,在图像搜索领域中,可以通过计算图像之间的感知哈希值的差异来快速找到相似的图像。
此外,phash方法还可以用于版权保护,即通过比对图像的感知哈希值来判断是否存在侵权行为。
在实际应用中,phash方法可以与其他图像检索算法相结合,提高图像检索的准确性和效率。
例如,可以通过计算两个图像的感知哈希值之间的汉明距离来衡量它们的相似度,从而实现图像的相似度排序和分类。
除了图像检索和相似度计算,phash方法还可以应用于图像识别。
通过比对待识别图像的感知哈希值与已知图像的感知哈希值,可以快速判断待识别图像是否与已知图像相匹配。
这在人脸识别、指纹识别和物体识别等领域都有广泛的应用。
需要注意的是,phash方法虽然在图像检索和相似度计算中表现出良好的性能,但也存在一些限制。
首先,由于哈希值的固定长度,可能会出现冲突现象,即不同的图像可能具有相同的哈希值。
其次,phash方法对于一些变换后的图像,如旋转、缩放和裁剪等,可能无法准确匹配。
phash方法是一种基于感知哈希算法的图像检索和相似度计算方法。
它通过将图像转换为一个固定长度的哈希值来表示图像的特征,可以应用于图像搜索、版权保护和图像识别等领域。
尽管phash方法存在一些限制,但在实际应用中仍然具有广泛的应用前景。

图像编码是图像处理中的一个重要技术,它通过对图像进行压缩,实现图像的储存和传输。
而其中的块匹配算法则是图像编码中的一个重要环节。
本文将从块匹配算法的原理与应用两个方面,阐述图像编码中的这一关键技术。
一、块匹配算法的原理块匹配算法是一种基于灰度相似性的图像处理算法,通过将图像分割成小块,并在目标图像中寻找与源图像块最为相似的块,从而实现图像的压缩。
块的分割块匹配算法中的第一步是将图像进行分块。
分块的大小可以根据具体应用进行设置,常见的块大小有8x8、16x16等。
通过将图像分块可以减小计算量,提高算法效率。
块的相似性度量在分块后,我们需要计算源图像块和目标图像块的相似性度量。
目前,常用的相似性度量方法有均方误差(MSE)和结构相似性(SSIM)等。
其中,均方误差是一种常见的度量方法,它通过计算源图像块和目标图像块的像素差值的平方和,来衡量两者之间的差异。
块的搜索和匹配在计算出相似度后,接下来的任务是在目标图像中寻找与源图像块最为相似的块。
常见的块搜索方法有全搜索法、三步搜索法和快速全局搜索法等。
全搜索法是一种最简单的搜索方法,它需遍历目标图像中的所有块,并计算每个块与源图像块的相似度,从而找到最相似的块。
而三步搜索法则通过设置步长,在目标图像中进行搜索,从而降低搜索复杂度。
二、块匹配算法的应用块匹配算法在图像编码中有广泛的应用。
下面将介绍它在JPEG和编码中的具体应用。
JPEG编码中的块匹配算法应用在JPEG编码中,块匹配算法主要用于基于DCT变换的压缩过程中。
将图像分块后,每个块通过DCT变换得到频域系数,然后通过量化和熵编码进一步压缩。
在这一过程中,块匹配算法用于选择合适的量化表和最佳匹配块,从而提高压缩效率。
编码中的块匹配算法应用在编码中,块匹配算法主要用于运动估计和补偿过程中。
运动估计和补偿是视频编码的核心技术,它通过预测未来帧的内容,从而减少视频帧的冗余信息。
块匹配算法在运动估计中用于寻找最佳匹配块,从而实现运动补偿,进一步提高压缩率和视频质量。

图像相似度计算图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。
可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。
然后一直跟着。
已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。
还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。
比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。
下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。
(1)直方图匹配。
比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。
这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。
那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。
而且计算量比较小。
这种方法的缺点:1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。
那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。
2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。
3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。
使用计算机视觉技术实现图像距离度量和相似性计算的方法引言:随着计算机视觉技术的快速发展,图像处理和分析已成为很多领域的研究热点,包括自动驾驶、医学影像诊断、视频监控等。
在这些应用中,图像的距离度量和相似性计算是非常重要的任务。
本文将讨论使用计算机视觉技术实现图像距离度量和相似性计算的方法。
一、图像距离度量算法图像距离度量算法用于衡量两个图像之间的差异程度,常用于图像分类、图像检索等任务。
以下是一些常见的图像距离度量算法:1. 欧氏距离欧氏距离是最简单的度量算法之一,在计算两个图像之间的距离时,将每个像素点的差值进行平方并求和,然后开方得到距离值。
欧氏距离不考虑图像的结构特征,只关注像素值的差异,因此对于某些应用可能不够准确。
2. 基于直方图的距离度量直方图是描述图像颜色分布的统计量,通过比较两个图像的直方图相似性来计算距离。
常见的度量方法有卡方距离、巴氏距离等。
这些方法可以很好地衡量图像的颜色分布,适用于图像分类等任务。
3. 基于感知的距离度量基于感知的距离度量算法考虑了人类感知的特性,通过模拟人眼的视觉特性来计算图像的相似度。
常见的方法有结构相似性(SSIM)指数和感知哈希(Perceptual Hash)算法等。
这些方法能够更好地反映人类对图像相似性的主观感知。
二、相似性计算方法图像相似性计算用于比较两个图像之间的相似程度,常用于图像检索、图像比对等任务。
以下是一些常见的图像相似性计算方法:1. 特征提取与匹配特征提取是图像相似性计算的关键步骤之一。
通过提取图像中的特征描述子,如SIFT、HOG等,来表示图像。
然后使用匹配算法(如最近邻匹配)来计算图像之间的相似度。
2. 卷积神经网络(CNN)卷积神经网络是目前最流行的图像处理方法之一,它可以通过训练得到图像的特征表示。
通过使用预训练的CNN模型(如VGG、ResNet等),可以提取出图像的特征向量,然后计算图像之间的余弦相似度或欧氏距离等指标来衡量相似性。
ncc归一化互相关NCC归一化互相关是一种常用的图像处理技术,它可以用于图像匹配、目标跟踪、3D重建等领域。
本文主要介绍NCC归一化互相关的原理及其在图像处理中的应用。
一、NCC归一化互相关的原理NCC归一化互相关是一种用于计算两个图像之间相似度的方法。
在计算相似度之前,我们需要对两个图像进行预处理,包括图像归一化和边缘填充。
1. 图像归一化图像归一化是指将图像的像素值进行归一化处理,使其符合一定的分布规律。
这样做的目的是为了消除图像的亮度和对比度差异,从而提高图像的匹配精度。
常用的图像归一化方法包括:(1)均值归一化:将图像的像素值减去图像的均值,并除以图像的标准差。
(2)直方图均衡化:将图像的像素值映射到一个均匀分布的区间内,从而提高图像的对比度。
(3)对数变换:将图像的像素值取对数,从而将图像的动态范围压缩到一定的范围内。
2. 边缘填充边缘填充是指在图像边缘填充一定宽度的像素值,从而避免在计算互相关时出现边缘效应。
常用的边缘填充方法包括:(1)零填充:在图像边缘填充0值像素。
(2)复制填充:在图像边缘复制边缘像素值。
(3)反射填充:在图像边缘反射图像像素值。
经过图像归一化和边缘填充后,我们可以使用NCC归一化互相关计算两个图像之间的相似度。
NCC归一化互相关的计算公式如下:NCC(x,y)=∑[f(x′,y′)μf][g(x′x,y′y)μg]/σfσg 其中,f(x,y)为第一个图像在(x,y)处的像素值;g(x,y)为第二个图像在(x,y)处的像素值;μf和μg分别为f和g的均值;σf和σg分别为f和g的标准差;NCC(x,y)为第一个图像与第二个图像在(x,y)处的归一化互相关系数。
NCC归一化互相关系数的取值范围为[-1,1],当NCC(x,y)越接近1时,表示第一个图像与第二个图像在(x,y)处的相似度越高;当NCC(x,y)越接近-1时,表示第一个图像与第二个图像在(x,y)处的相似度越低;当NCC(x,y)接近0时,表示第一个图像与第二个图像在(x,y)处没有明显的相似度。
icon 相似度计算
计算两个图标(icon)之间的相似度可以采用多种方法,包括但不限于像素比较、特征提取和机器学习方法。
以下是一些常用的方法:
1. 像素比较:对于简单的图标,可以直接比较两个图标中相同位置的像素值来计算相似度。
这种方法简单但可能不太准确,因为像素值可能因为颜色和亮度差异而有所不同。
2. 特征提取:对于更复杂的图标,可以使用特征提取方法来提取图标中的关键特征,然后比较这些特征的相似度。
常用的特征提取方法包括主成分分析(PCA)、离散余弦变换(DCT)等。
3. 机器学习方法:使用机器学习算法来训练一个模型,该模型可以自动学习图标的特征,并根据这些特征来比较两个图标的相似度。
常见的机器学习方法包括支持向量机(SVM)、神经网络等。
无论使用哪种方法,都需要对图标进行预处理,例如归一化大小、去除背景、颜色校正等,以提高计算相似度的准确性。
同时,需要注意相似度的计算可能会受到图标设计风格、细节处理等因素的影响,因此需要综合考虑各种因素来评估两个图标的相似度。
Visual image retrieval on compressed domain with Q-distanceHong Heather YuPanasonic Information and Networking Technology Lab.heathery@AbstractThis paper proposes a new image retrieval scheme that works directly on compressed image(JPEG)databases.As we know,a large percentage of the image databases are stored in compressed image format,such as JPEG format.In addition,about half of the images on the Internet are also in JPEG format.Thus,image retrieval systems that require JPEG decompression greatly limit the speed of image searching.Subsequently,new methodologies for retrieving of images without JPEG decoding is needed for web image search and compressed image database retrieval.In this paper,we propose a new metric,Q-distance, that can be utilized to measure the distance between two compressed images.A system that uses Q-distance for fast image retrieval is also presented.Experiment results show that Q-distance is robust against variation and this new retrieval scheme,which directly works on compressed image domain,is fast to execute and suitable for web image searching and retrieval.1.Introduction1.1MotivationA study by Euro-marketing shows that there are over157million people worldwide who have access to the Internet,the gigantic multimedia information database.Needless to say,one of the most important functions of the Internet is'search'.The overwhelmingly available multimedia on such high traffic Internet demand fast searching and browsing capability of text,audio,as well as visual data.Since most of the images on the Internet are in compressed formats,it is therefore important to develop techniques that can allow visual image searching without image decompression,that is,directly search on compressed image domain.As we know,a compressed image,such as JPEG image,can compress an image whereas keeping the visual quality of it by discarding the small high frequency coefficients.This means by throwing away the least significant coefficients,the visual appearance of an image does not change significantly,i.e.,the overall structure of an image is kept in the significant coefficients.Is this characteristic useful in designing similarity-based image retrieval systems?Can this property be employed to design a compressed-domain image search engine?In this paper,we present such an image search engine and show that this characteristic of visual media is indeed helpful in designing a compressed-domain image retrieval ware.Why?With regards to image retrieval,many real world scenarios emphasize on the similarity of the overall structure of images.For instance,on web image searching,users may have a rough idea of the image they are looking for.Hopefully,a simple sketch of the overall structure of the image can help them to find the image in the database.This requires a good distance measurement between the query sketch and the images in the database.In this paper,wepropose anew metric,Q-metric,for domain.It is defined based on the analysis of the aforementioned visual characteristics of image and gives a measurement of how many SFCs (Significant Frequency Component)of two images are in common.As a result,it gives a good measurement on the overall similarity between images.By directly measuring the distance on compressed domain,it significantly enhances image query speed.Consequently,it gives higher usability for compressed image database retrieval,such as web image searching.1.2Related worksResearch works on visual content-based image retrieval[1,2,3,4,5,6,7,8,9,10]started several years ago.One of the application areas is web-image search engine.Yahoo image surfer by Excalibour [11],the MIQ by the University of Washington [12],VisualSEEk by Columbia University [13],and etc.for web image searching have made great progress in this area.In particular,the MIQ [11]system by Jacobs,Finkelstein,and Salesin designed a new metric for querying images that essentially compares how many significant wavelet coefficients the query has in common with potential targets.Their experiment results showed dramatic improvement in both speed and success rate,over using the conventional L1,L2,or color histogram norm.However,one drawback of this system is that it works on raw images instead of compressed images while most of the images on the World Wide Web are in either JPEG format or GIF format.This greatly degraded the efficiency of the system.In this paper,we propose a new metric that works on compressed image (JPEG format)directly,which,from the application point of view,can significantly improve the performance of web image searching and compressed image database retrieval.In the next section,the definition of Q-distance along with the description on using Q-distance for image retrieval is given.Thereafter,we outline the system architecture for compressed domain image retrieval with Q-distance .Experiment results will be presented in the last section followed by conclusion remarks.2.Q-metricLet I 1,I 2…I N represent the images in the database and Q represent the query image.Assume the image size is XxY .Denote I n 00(i,j)to be the DC coefficient of the (i,j)th block and I n lk (i,j)to be the coefficient of the (l,k)th channel of the (i,j)th block of image I n .Here,l ∈[,]18,k ∈[,]18,i I ∈[,]1,and j J ∈[,]1.Notice that I X ×=8and J Y ×=8.The DC coefficient of each block can form a new image,DC-image I DC n of an original image I n .To define the Q-metric ,wavelet transformation is performed on the DC-images of the query and the target images.Let's denote the wavelet coefficient of the DC-image as I DC n*00(i,j).Q-metric,which measures the distance between the query image and the target image,is thus defined asQ I Q i j I i j Q i j I i j m DC DC i j lk l kl k l k i j ,((,),(,))((,),(,))**,,,*,*,=+åååωδωδ00Where ωlk are weighting functions,and the single channel distance function δis defined as following:δ(,)Q I =1,when Q DC *(i,j)>T*,I DC *(i,j)>T*and Q lk (i,j)>T ,I lk (i,j)>T with threshold T*and T ;δ(,)Q I =0,otherwise.Here,we refer the distance between two images Q &I that is computed using Q-metric as Q-distance :Q Q I Q Q Q I(,),,=−A fast image retrieving system that directly works on compressed image is presented in the next section.In this system,Q-distance is employed to measure the visual similarity of two images and therefore is used to retrieve similar images of the query image in the system.During the retrieval phase,image I M is returned as the best matching image of the query image Q if,Q Q I Q Q I for m N M m (,)(,)[,]≤∀∈1,i.e.,if.|,||,|[,]Q I Q I for m N M m ≥∀∈13.The systemThe query system utilizes the above-defined metric for similarity-based image retrieval.As we mentioned in the first section,a compressed image,such as JPEG image,can compress an image and keep the visual quality of it by discarding the small high frequency coefficients.This is exactly the useful characteristic we employed to design a compressed-domain image search engine.By means of recognizing the important coefficients of an image,the above-defined Q -metric is able to capture the distance of the overall structure of two images.It in return gives a good measure of the similarity between two images.The metric uses both the wavelet coefficients of the DC-image and the AC coefficients of DCT transformation.Since the DC coefficient as well as the AC coefficients of an image can be gotten directly from the JPEG without decoding,the performance of the system that utilizes the above-defined Q -metric is greatly enhanced.3.1Q-distance for image similarity retrievalFigure 1.Image retrieval system layoutFigure 1outlines an image retrieval system.The database consists of JPEG compressed images only.In this system,a 2-D standard Haar wavelet decomposition is first performed on the DC-image (see section 3for definition of DC-image.)Next,the Q-distance between the query image Q and each of the potential target image in the database I 1,I 2…I N is At last,a of images is returned to the user based on a winner first strategy,i.e.,I M is returned if the Q-distance of I M to Q is among the K smallest Q-distance s of all N images.i.e.,Q Q I Q Q I M m (,)(,)≤which equivalents to |,||,|[,]Q I Q I m N m M m ≥∀∈∉for and 1MWhere M represents the returned image set.3.2Web image search engineIn web image searching,two important factors need to be considered:speed and interface.The interface problem is beyond the scope of this paper.However,the advantage of searching directly on compressed images will no doubt boost up the performance.4.Results and summary4.1Experiment resultOur first set of experiments is comparison student between the Q-distance and visual similarity.In Figure 2(c),|Q,I m |between a query image Q and 32other images in the database are plotted.Figure1(b)shows several sample images with I(I 5),II(I 9),IV(I 11),and V(I 15)have a large Q-distance (small |Q,I m |)and III(I 10)and V(I 21)have small Q-distance s to Q=I 31.Figure 3shows a sample retrieval result.The query image shown in (a)is a sketch that is painted by user.The 9images in (b)are the first nine images on the returning list.(c)and (d)give the sample Q-distance plots with (c)plots the Q-distance s between the sample query image Q1shown in (a)and the first 33images in the database,whereas (d)shows the result of ordered Q-distance s for retrieval.Experimental results show that the retrieval system that uses the Q-distance to measure the similarity between two images outperforms those using L1or L2distance.In addition,this system goes one step further.It performs searching and retrieval on the compressed images which is fast to execute and suitable for web image searching.4.2Future workCurrently we are working on testing this system on a large image database.In the mean time,the same methodology can be extended to similarity-based video clip retrieval.The video retrieval system that works directly on MPEG video is also under testing.Figure 2.A comparison study:plot of |Q,I m |References[1].H.J.Zhang,C.Low,S.Smoliar,"Automatic parsing of news video",in Proceedings,IEEE ICMCS'94,1994,P45-54[2].J.Dowe,"Content-based retrieval in multimedia imaging",in Proceedings,SPIE,Visual Communication andImage Processing,1993[3].M.Flickner,et al,"Query by image and video content:the QBIC system",IEEE Computer,1995(a)Query image Q(b)Image I 5(|Q,I m |=29),I 9(|Q,I m |=24),I 10(|Q,I m |=150),I 11(|Q,I m |=30),I 15(|Q,I m |=11),I 21(|Q,I m |=120)in comparison with I 31in(b)(c)Plot of |Q,I m |with (the first 33images in the database)and Q=I 31I II IIIIV V VI[4].J.Smith,S.-F.Chang,"VisualSEEk:a fully automated content-based image query system",in Proceedings,ACM Multimedia'96,1996,P87-96[5].T.S.Huang,S.Mehrotra,K.Ramchandram,"Multimedia analysis and retrieval system (MARS)project",inProceedings,Clinic on Library Application of Data Processing,1996[6].J.R.Bach,C.Fuller,A.Gupta,A.Hampapur,B.Horowitz,R.Humphrey,R.Jain,C.F.Shu,"The virageimage search engine:an open framework for image management",in Proceedings,SPIE,1996[7] Cascia,E.Ardizzone,"JACOB:Just a content-based query system for video databases",ICASSP'96,1996[8].T.P.Minka,R.W.Picard,"Interactive learning using a 'Society of Models'",Pattern Recognition,V30,N4,1997[9].H.Yu,W.Wolf,"A visual search system for video and image databases",in Proceedings,IEEE ICMCS'97,1997[10].J.Krey,et al,"Video Retrieval by still image analysis with ImageMiner",in Proceedings,SPIE'97,1997[11]./Figure 3.A query sample result*Note:In the above examples,the size of each image is 640x480.For illustration purpose,the images shown are several times smaller than their actual sizes and only the first 33images in the retrieving database are plotted.The matching point withminimumQ-distance(a)Query image Q1,a rough(b)Returned first 9images(c)Plot of Q-distances between the sample querysketch Q1shown in (a)and the first 33images inthe database(d)Plot of ordered Q-distance s of the sample query in (a)。