深度学习的深度信念网络DBN
- 格式:ppt
- 大小:1.96 MB
- 文档页数:16

基于深度信念网络的特征抽取方法研究与应用深度学习在近年来取得了巨大的突破,成为人工智能领域的热门研究方向。
其中,深度信念网络(Deep Belief Networks,DBN)作为一种基于无监督学习的深度学习模型,被广泛应用于特征抽取任务中。
本文将探讨基于DBN的特征抽取方法的研究与应用。
一、深度信念网络的基本原理深度信念网络是由多层堆叠的玻尔兹曼机(Boltzmann Machine,BM)组成的,每一层都是一个BM。
它的训练过程可以分为两个阶段:预训练和微调。
预训练阶段通过逐层训练,将每一层的权重初始化为最优值,使得网络可以自动地学习到输入数据的高层抽象特征。
而微调阶段则是通过反向传播算法对整个网络进行训练,进一步提升网络的性能。
二、基于DBN的特征抽取方法基于DBN的特征抽取方法主要包括两个步骤:预训练和特征提取。
预训练阶段通过逐层训练,将原始输入数据转化为高层次的抽象特征表示。
而特征提取阶段则是将预训练得到的权重参数应用于新的数据集,提取其特征表示。
在预训练阶段,DBN通过对每一层进行贪心逐层训练,逐渐提高网络的表达能力。
每一层的训练过程都是一个无监督的学习过程,通过最大化对数似然函数来学习每一层的权重参数。
在训练过程中,网络通过学习到的权重参数,逐渐学习到输入数据的高层次抽象特征。
在特征提取阶段,DBN将预训练得到的权重参数应用于新的数据集,提取其特征表示。
通过将新的数据集输入到DBN中,可以得到每一层的输出,即特征表示。
这些特征表示可以用于后续的分类、聚类等任务。
三、基于DBN的特征抽取方法的应用基于DBN的特征抽取方法在图像识别、语音识别、自然语言处理等领域中得到了广泛的应用。
在图像识别领域,DBN可以通过学习到的高层次抽象特征,对图像进行特征表示。
这些特征表示可以用于图像分类、目标检测等任务。
通过深度学习的方法,可以提高图像识别的准确率和鲁棒性。
在语音识别领域,DBN可以通过学习到的语音特征表示,提高语音识别的准确率。

DBN(深度信念网络)MATLABDeepLearnToolbox源码学习深度信念网络(Deep Belief Networks,DBN)是一种无监督学习算法,用于将浅层的无监督学习算法(如受限玻尔兹曼机)组合成深层的结构。
DBN的核心思想是通过逐层训练,将特征从原始数据中抽取出来,并在每一层中学习到更加抽象和高级的特征表示。
为了学习DBN的实现细节,我选择了MATLAB中的DeepLearnToolbox源码进行学习。
DeepLearnToolbox是MATLAB的一个开源工具包,提供了各种深度学习模型的实现,包括DBN。
在学习DBN的MATLAB源码之前,首先了解一下DBN的结构和训练过程是非常重要的。
DBN由多层玻尔兹曼机(RBM)组成,每一层的RBM都被训练为一个无监督学习的生成模型。
在训练完成之后,DBN的每一层就是上一层的隐藏层,通过从上到下的顺序连接起来形成整个DBN。
学习源码时,首先需要熟悉DeepLearnToolbox提供的DBN类的方法和属性。
然后,可以根据具体的需求对源码进行修改和调试。
在学习源码的过程中,我发现DBN类中的一些核心方法特别值得关注,如train、propup、sampleH、reconstruct和propdown等。
这些方法分别对应DBN的训练过程中的不同步骤,如正向传播、反向传播、样本采样和重构等。
理解这些方法的实现细节,可以帮助我们更好地理解DBN的实现原理。
此外,我还注意到DeepLearnToolbox提供了一些辅助函数,如sigm、rbmup、rbmdown和sample等,用于计算激活函数的输出、计算RBM的正向传播和反向传播的输出、以及对样本进行采样等。
这些辅助函数在DBN 的实现中起到了重要的作用。
在学习DBN的源码过程中,我还可以将实现的方法与DBN的理论知识进行对比,加深对DBN算法的理解。
另外,还可以通过实验和调试源码,观察不同参数设置对DBN性能的影响,从而进一步探索DBN的特性。

深度学习--深度信念网络(Deep Belief Network)概述深度信念网络(Deep Belief Network, DBN) 由Geoffrey Hinton 在2006 年提出。
它是一种生成模型,通过训练其神经元间的权重,我们可以让整个神经网络按照最大概率来生成训练数据。
我们不仅可以使用DBN 识别特征、分类数据,还可以用它来生成数据。
下面的图片展示的是用DBN 识别手写数字:图 1 用深度信念网络识别手写数字。
图中右下角是待识别数字的黑白位图,它的上方有三层隐性神经元。
每一个黑色矩形代表一层神经元,白点代表处于开启状态的神经元,黑色代表处于关闭状态的神经元。
注意顶层神经元的左下方即使别结果,与画面左上角的对应表比对,得知这个DBN 正确地识别了该数字。
下面是展示了一个学习了大量英文维基百科文章的DBN 所生成的自然语言段落:In 1974 Northern Denver had been overshadowed by CNL, and several Irish intelligence agencies in the Mediterranean region. However, on the Victoria, Kings Hebrew stated that Charles decided to escape during analliance. The mansion house was completed in 1882, the second in its bridge are omitted, while closing is the proton reticulum composed below it aims, such that it is the blurring of appearing on any well-paid type of box printer.DBN 由多层神经元构成,这些神经元又分为显性神经元和隐性神经元(以下简称显元和隐元)。

dbn原理
DBN(Deep Belief Network,深度信念网络)是一种深度学习模型,由多个堆叠的受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)组成。
DBN的原理涉及到概率图模型、无监督学习和逐层贪婪训练等概念。
以下是DBN的基本原理:
1.概率图模型:DBN是一种概率图模型,用于建模变量之间的概率关系。
它的基本组成部分是RBM,是一种能量模型,用于描述变量之间的概率分布。
2.受限玻尔兹曼机(RBM):RBM是概率图模型中的一种,具有两层神经元,分别是可见层和隐藏层。
RBMs之间的连接是双向的,但层内神经元之间没有连接。
RBMs用于学习数据的分布,并提取数据中的特征。
3.逐层贪婪训练:DBN的训练过程采用逐层贪婪训练的策略。
首先,每一层的RBM在无监督方式下逐层地进行训练,学习输入数据的分布和特征。
然后,将前一层RBM的隐藏层作为后一层RBM的可见层,层层堆叠形成DBN。
4.深度表示学习:由于DBN的层层堆叠,它可以学习数据的层次化表示。
底层表示捕捉原始数据的基本特征,而高层表示捕捉更抽象和复杂的特征。
这使得DBN在处理复杂数据和进行特征学习方面具有优势。
5.有监督微调:在无监督训练之后,可以通过有监督微调的方式使用反向传播算法进一步调整网络,以适应特定的任务,如分类或回归。
总体而言,DBN的原理结合了概率图模型和深度学习的思想,通过逐层贪婪训练学习数据的层次化表示,使其在处理复杂数据和进行特征学习方面表现出色。

dbn方法-回复什么是DBN方法?DBN方法指的是深度信念网络(Deep Belief Networks)方法。
深度信念网络是一种基于神经网络的无监督学习算法,被广泛应用于机器学习和人工智能领域。
它由多层堆叠的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成,其中每一层都是由一组可见单元和一组隐藏单元组成。
在深度信念网络中,每一层的可见单元由外部输入提供,而隐藏单元则通过学习自动提取输入数据中的特征。
通过逐层训练,每一层的隐藏单元都可以认为是下一层的输入数据的高级抽象表示。
这种层级化的特征提取能力使得深度信念网络在处理复杂高维数据时具有优势。
DBN方法的训练过程主要分为两个阶段:预训练和微调。
首先是预训练阶段,也称为无监督预训练。
在该阶段中,每一层的RBM 按顺序进行训练。
通过最大化数据的似然函数,RBM学习到了输入数据的分布特征,并通过学习自动提取了输入数据的抽象表示。
每一层的隐藏单元的值也可作为下一层的输入数据,使得每一层的特征逐渐变得更加抽象。
这一阶段的目标是逐层构建一个具有良好表示能力的特征提取器。
接下来是微调阶段,也称为有监督微调。
在该阶段中,通过使用带标签的数据来训练整个网络。
通过最小化损失函数(如交叉熵损失函数),网络的权重参数进行调整,从而提高网络的准确性和泛化能力。
微调过程中,网络的所有层都参与训练,使得整个网络能够适应于特定的任务和数据集。
DBN方法的优势在于它能够自动学习和提取数据的抽象表示,无需手工设计特征。
这种特点使得DBN方法在特征表示和数据表示方面具有很强的表达能力。
此外,DBN方法还可以处理高维数据、具有更好的可解释性和更快的训练速度。
然而,DBN方法也存在一些挑战和限制。
首先,预训练阶段是无监督的,无法直接优化整个网络的目标函数,可能导致预训练与微调之间的性能下降。
其次,DBN方法对超参数的选择敏感,包括网络结构、学习率和正则化参数等。

深度信念网络(DBN)是一种深度学习模型,它由多层堆叠自动编码器组成。
在本文中,我们将对堆叠自动编码器和深度信念网络进行解析,探讨它们在机器学习领域的应用和原理。
自动编码器是一种无监督学习算法,它的目标是学习数据的表示,然后重构输入。
自动编码器由输入层、隐藏层和输出层组成。
隐藏层的节点数比输入层和输出层更少,这迫使自动编码器学习数据的压缩表示。
在训练过程中,自动编码器尝试最小化输入和重构输出之间的差异,从而学习到数据的有用特征。
堆叠自动编码器是由多个自动编码器组成的深度学习模型。
它通过逐层训练每个自动编码器,然后将它们堆叠在一起形成一个深层结构。
这种逐层训练的方法可以解决训练深度神经网络时遇到的梯度消失和梯度爆炸等问题。
深度信念网络是一种由多层堆叠自动编码器组成的概率生成模型。
它可以用来对数据进行建模和生成。
深度信念网络的训练过程是通过无监督的逐层贪婪训练方法来实现的。
在训练过程中,每一层的参数都被调整以最大化模型对训练数据的似然。
深度信念网络在许多领域都有广泛的应用,包括计算机视觉、自然语言处理和推荐系统等。
在计算机视觉领域,深度信念网络可以用来进行特征学习和图像生成。
在自然语言处理领域,它可以用来进行情感分析和语言建模。
在推荐系统领域,它可以用来进行用户画像和推荐算法。
堆叠自动编码器的深度信念网络具有许多优点,例如它可以对大规模数据进行高效的表示学习和生成。
它还可以学习到数据的多层次抽象表示,从而可以更好地捕捉数据的内在特性。
此外,深度信念网络还可以应对数据的高维度和复杂性,提高模型的泛化能力。
然而,堆叠自动编码器的深度信念网络也存在一些局限性。
例如,它需要大量的训练数据和计算资源来进行训练。
此外,它的训练过程可能会受到参数初始化和超参数选择等因素的影响,需要进行仔细的调参和实验设计。
在总结上述内容之后,我们可以看到堆叠自动编码器的深度信念网络在深度学习领域具有重要的地位和应用前景。
它的原理和方法有助于我们更好地理解深度学习模型的内在机理和训练过程。

深度信念网络(DBN)是一种用于无监督学习的神经网络模型,它由多层堆叠自动编码器组成。
在本文中,我们将探讨堆叠自动编码器的深度信念网络的原理、结构和应用。
首先,让我们介绍一下自动编码器。
自动编码器是一种用于学习数据的特征表示的神经网络模型。
它由一个由编码器和解码器组成的结构构成,其中编码器将输入数据映射到隐藏层表示,解码器将隐藏层表示映射回原始数据空间。
自动编码器通过最小化输入和重构之间的误差来学习数据的高级表示。
堆叠自动编码器则是将多个自动编码器层叠在一起,每一层的输出作为下一层的输入,从而构建了一个深层的特征学习模型。
深度信念网络是一种基于概率图模型的无监督学习方法,它由多层堆叠自动编码器组成。
在深度信念网络中,每一层自动编码器的隐藏层表示被用作上一层自动编码器的输入,从而构建了一个深层的概率生成模型。
深度信念网络通过学习数据的概率分布来进行特征学习和生成模型的训练。
堆叠自动编码器的深度信念网络具有许多优点。
首先,它可以通过无监督学习来学习数据的高级表示,从而可以在没有标签数据的情况下进行特征学习和模型训练。
其次,深度信念网络具有强大的表示能力和泛化能力,能够对复杂的数据分布进行建模和生成。
此外,深度信念网络还可以通过反向传播算法进行有监督学习,从而可以在标签数据有限的情况下进行监督学习任务。
在实际应用中,堆叠自动编码器的深度信念网络被广泛应用于图像识别、语音识别、自然语言处理等领域。
在图像识别任务中,深度信念网络可以学习图像的高级特征表示,从而可以实现对图像的分类、检测和生成。
在语音识别任务中,深度信念网络可以学习语音的特征表示,从而可以实现对语音的识别和合成。
在自然语言处理任务中,深度信念网络可以学习文本的语义表示,从而可以实现对文本的分类、情感分析和生成。
总之,堆叠自动编码器的深度信念网络是一种强大的无监督学习模型,它具有强大的特征学习能力和泛化能力,并且在图像识别、语音识别、自然语言处理等领域有着广泛的应用。
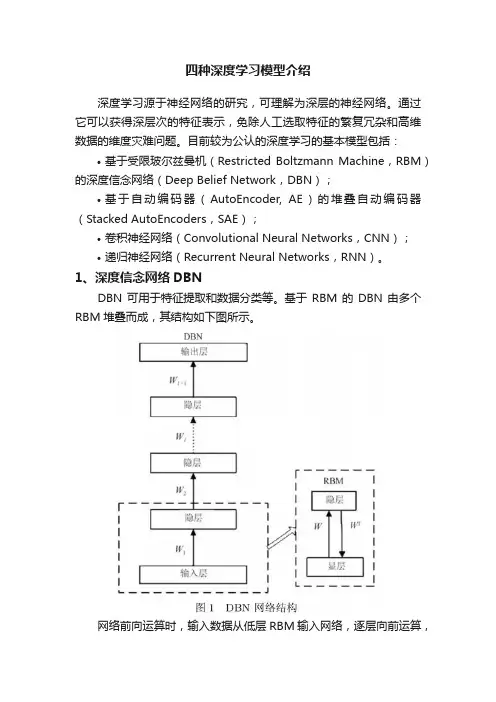
四种深度学习模型介绍深度学习源于神经网络的研究,可理解为深层的神经网络。
通过它可以获得深层次的特征表示,免除人工选取特征的繁复冗杂和高维数据的维度灾难问题。
目前较为公认的深度学习的基本模型包括:•基于受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)的深度信念网络(Deep Belief Network,DBN);•基于自动编码器(AutoEncoder, AE)的堆叠自动编码器(Stacked AutoEncoders,SAE);•卷积神经网络(Convolutional Neural Networks,CNN);•递归神经网络(Recurrent Neural Networks,RNN)。
1、深度信念网络DBNDBN可用于特征提取和数据分类等。
基于RBM的DBN由多个RBM堆叠而成,其结构如下图所示。
网络前向运算时,输入数据从低层RBM输入网络,逐层向前运算,得到网络输出。
网络训练过程,不同于传统的人工神经网络(Artificial Neural Network),分为两个阶段:•预训练(Pretraining)•全局微调(Fine tuning)预训练阶段,从低层开始,每个RBM单独训练,以最小化RBM 的网络能量为训练目标。
低层RBM训练完成后,其隐层输出作为高层RBM的输入,继续训练高层RBM。
以此类推,逐层训练,直至所有RBM训练完成。
预训练阶段,只使用了输入数据,没有使用数据标签,属于无监督学习(Unsupervised Learning)。
全局微调阶段,以训练好的RBM之间的权重和偏置作为深度信念网络的初始权重和偏置,以数据的标签作为监督信号计算网络误差,利用BP(Back Propagation)算法计算各层误差,使用梯度下降法完成各层权重和偏置的调节。
2、堆叠自动编码器SAE类似于DBN,SAE由多个AE堆叠而成,其结构如下图所示。
SAE前向计算类似于DBN,其训练过程也分为预训练和全局微调两个阶段。

深度信念网络(DBN)是一种基于深度学习的神经网络模型,它的核心思想是通过多层次的特征提取和抽象来学习数据的表示。
而堆叠自动编码器(SAE)则是DBN中常用的一种结构,它通过逐层的训练来逐步学习数据的抽象表示。
本文将对堆叠自动编码器的深度信念网络进行解析,从原理到应用进行全面探讨。
首先,我们来了解一下自动编码器(AE)的基本原理。
自动编码器是一种无监督学习的神经网络模型,它的目标是学习输入数据的有效表示。
自动编码器的结构包括编码器和解码器两部分,编码器将输入数据映射到隐藏层的表示,而解码器则将隐藏层的表示映射回原始数据空间。
通过最小化重构误差,自动编码器能够学习到数据的潜在结构,从而实现对数据的降维和特征提取。
而堆叠自动编码器则是通过将多个自动编码器堆叠在一起构成深度网络,从而实现对数据更加复杂的表示学习。
在堆叠自动编码器中,每个自动编码器的隐藏层都作为下一个自动编码器的输入层,通过逐层地训练,模型能够学习到数据的层次化特征表示。
这种逐层的训练方式可以有效地缓解深度学习中的梯度消失和梯度爆炸问题,同时也能够提高模型对数据的表征能力。
在实际应用中,堆叠自动编码器的深度信念网络被广泛应用于各种领域。
在图像识别领域,深度信念网络能够通过学习到的层次化特征表示来实现对图像的分类和识别。
在自然语言处理领域,深度信念网络能够学习到词向量的表示,从而提高文本分类和情感分析的性能。
此外,深度信念网络还被应用于推荐系统、信号处理、生物信息学等多个领域,取得了良好的效果。
然而,深度信念网络也面临一些挑战和限制。
首先,深度信念网络的训练过程相对复杂,需要大量的数据和计算资源。
其次,深度信念网络的模型解释性相对较弱,难以解释模型学习到的特征表示。
此外,深度信念网络在处理非结构化数据和小样本数据上的效果有限,需要更多的改进和优化。
针对深度信念网络的挑战和限制,研究者们也在不断探索和改进。
例如,通过引入正则化、Dropout、批归一化等方法来提高模型的稳定性和泛化能力;通过引入注意力机制、迁移学习等方法来提高模型的解释性和泛化能力;通过引入生成对抗网络、变分自编码器等方法来提高模型对非结构化数据和小样本数据的处理能力。

dbn的公式推导全文共四篇示例,供读者参考第一篇示例:DBN(Deep belief networks)深度置信网络是一种用于学习概率模型的神经网络模型,它由多层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成。
在深度学习领域,DBN是一种常用的模型,可以用于无监督学习和特征学习。
在本文中,我们将介绍DBN的公式推导过程,让读者了解DBN 的原理和实现方法。
我们将介绍RBM的基本原理,然后讨论如何将多个RBM组合成DBN,并推导DBN的学习算法。
1. 受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)受限玻尔兹曼机是一种基于能量的概率生成模型,它由一个可见层和一个隐含层组成,可用于学习数据的潜在特征。
RBM的能量函数定义如下:\[E(v, h) = -\sum_{i=1}^{n}\sum_{j=1}^{m}w_{ij}v_ih_j -\sum_{i=1}^{n}b_iv_i - \sum_{j=1}^{m}c_jh_j\]\(v\)为可见层的状态向量,\(h\)为隐含层的状态向量,\(w_{ij}\)为可见层和隐含层之间的连接权重,\(b_i\)和\(c_j\)为可见层和隐含层的偏置项。
RBM的联合概率分布可以表示为:\[P(v, h) = \frac{e^{-E(v, h)}}{Z}\]\(Z\)是分区函数,用于归一化概率分布。
RBM的学习算法通常使用对比散度(Contrastive Divergence,CD)算法进行参数估计和模型训练。
2. 深度置信网络(Deep Belief Networks,DBN)DBN的生成过程如下:- 训练第一个RBM,得到第一层的特征表示- 使用第一层特征表示训练第二个RBM,得到第二层的特征表示- 重复上述过程直到所有RBM训练完成- 将RBM的隐含层连接起来,构成DBN的特征表示\[P(v, h^{(1)}, h^{(2)}, ..., h^{(k)}) =P(v|h^{(1)})P(h^{(1)}|h^{(2)})...P(h^{(k-1)}|h^{(k)})\]\(v\)为可见层的状态向量,\(h^{(1)}, h^{(2)}, ..., h^{(k)}\)为各个隐含层的状态向量。

支持向量机与深度信念网络的比较与优劣分析支持向量机(Support Vector Machine,SVM)和深度信念网络(Deep Belief Network,DBN)是机器学习领域中两种常用的分类算法。
它们在不同的应用场景中具有各自的优势和劣势。
本文将对这两种算法进行比较与优劣分析。
SVM是一种监督学习算法,其主要思想是通过构建一个最优超平面来实现分类。
SVM在处理小样本问题时表现出色,可以很好地处理线性可分和线性不可分的情况。
它的核心是寻找一个最大间隔的超平面,使得不同类别的样本点能够被有效地分开。
SVM在处理高维数据时也具有较好的性能,可以通过核函数将数据映射到高维空间,从而实现非线性分类。
然而,SVM也存在一些不足之处。
首先,SVM对数据的规模敏感,当数据量较大时,训练时间会较长。
其次,SVM对参数的选择比较敏感,需要通过交叉验证等方法进行调优。
此外,SVM只能进行二分类,对于多分类问题需要进行一对多或一对一的策略。
与SVM相比,DBN是一种非监督学习算法,它属于深度学习的一种。
DBN由多个堆叠的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成,通过逐层训练来提取数据的高级特征。
DBN在处理大规模数据时具有较好的性能,可以自动学习数据的分布和特征表示。
它在处理图像、语音等复杂数据上表现出色,可以提取出更加抽象和高级的特征。
然而,DBN也存在一些限制。
首先,DBN的训练过程相对较慢,需要大量的计算资源和时间。
其次,DBN对于参数的选择不够直观,需要通过试错和经验来确定。
此外,DBN的可解释性较差,难以解释模型的内部工作机制。
综上所述,SVM和DBN在不同的应用场景中具有各自的优势和劣势。
SVM 适用于小样本和高维数据的分类问题,具有较好的鲁棒性和泛化能力。
而DBN适用于大规模数据和复杂数据的特征提取,可以学习到更加高级和抽象的特征表示。
在实际应用中,我们可以根据具体的问题和数据特点选择适合的算法。
DBN深度信念网络详解1. 自联想神经网络与深度网络自联想神经网络是很古老的神经网络模型,简单的说,它就是三层BP网络,只不过它的输出等于输入。
很多时候我们并不要求输出精确的等于输入,而是允许一定的误差存在。
所以,我们说,输出是对输入的一种重构。
其网络结构可以很简单的表示如下:如果我们在上述网络中不使用sigmoid函数,而使用线性函数,这就是PCA模型。
中间网络节点个数就是PCA模型中的主分量个数。
不用担心学习算法会收敛到局部最优,因为线性BP网络有唯一的极小值。
在深度学习的术语中,上述结构被称作自编码神经网络。
从历史的角度看,自编码神经网络是几十年前的事情,没有什么新奇的地方。
既然自联想神经网络能够实现对输入数据的重构,如果这个网络结构已经训练好了,那么其中间层,就可以看过是对原始输入数据的某种特征表示。
如果我们把它的第三层去掉,这样就是一个两层的网络。
如果,我们把这个学习到特征再用同样的方法创建一个自联想的三层BP网络,如上图所示。
换言之,第二次创建的三层自联想网络的输入是上一个网络的中间层的输出。
用同样的训练算法,对第二个自联想网络进行学习。
那么,第二个自联想网络的中间层是对其输入的某种特征表示。
如果我们按照这种方法,依次创建很多这样的由自联想网络组成的网络结构,这就是深度神经网络,如下图所示:注意,上图中组成深度网络的最后一层是级联了一个softmax分类器。
深度神经网络在每一层是对最原始输入数据在不同概念的粒度表示,也就是不同级别的特征描述。
这种层叠多个自联想网络的方法,最早被Hinton想到了。
从上面的描述中,可以看出,深度网络是分层训练的,包括最后一层的分类器也是单独训练的,最后一层分类器可以换成任何一种分类器,例如SVM,HMM等。
上面的每一层单独训练使用的都是BP算法。
相信这一思路,Hinton早就实验过了。
2. DBN神经网络模型使用BP算法单独训练每一层的时候,我们发现,必须丢掉网络的第三层,才能级联自联想神经网络。
深度信念网络(DBN)是一种深度学习模型,它由多层堆叠自动编码器组成。
随着深度学习在各个领域的广泛应用,DBN作为一种有效的特征提取和分类方法,受到了广泛关注。
本文将对堆叠自动编码器的深度信念网络进行解析,包括其原理、结构以及应用场景。
一、深度信念网络的原理深度信念网络是由多层堆叠自动编码器组成的,它的原理基于概率图模型和无监督预训练。
在深度信念网络中,每一层的自动编码器都被训练成能够重构输入数据的特征提取器,同时也可以通过反向传播算法进行微调,以提高整个网络的性能。
具体而言,深度信念网络的每一层都是一个受限玻尔兹曼机(RBM)算法。
RBM是一种基于能量的概率生成模型,它通过最大化数据的对数似然来学习数据的分布,从而得到一组特征。
在深度信念网络中,多个RBM被堆叠在一起,每个RBM的隐藏层作为下一个RBM的可视层,这样就形成了多层的自动编码器。
二、深度信念网络的结构深度信念网络的结构包括多个堆叠的自动编码器和一个顶层的逻辑回归分类器。
每个自动编码器由一个可视层和一个隐藏层组成,可视层和隐藏层之间的连接采用权重矩阵来表示。
通过对每一层的自动编码器进行预训练和微调,可以得到一个深度的特征提取器,并且可以用来进行分类任务。
在深度信念网络中,每一层的自动编码器都可以看作是一个特征提取器,它们可以从输入数据中学习到不同层次的抽象特征。
通过堆叠多个自动编码器,可以逐渐提取出更加抽象和高级的特征,从而提高整个网络的性能。
三、深度信念网络的应用场景深度信念网络在图像识别、语音识别、自然语言处理等领域都有着广泛的应用。
在图像识别领域,深度信念网络可以用来提取图像的特征,从而实现图像分类、目标检测等任务。
在语音识别领域,深度信念网络可以用来提取语音的特征,从而实现语音识别、语音合成等任务。
在自然语言处理领域,深度信念网络可以用来提取文本的特征,从而实现文本分类、情感分析等任务。
总之,深度信念网络作为一种有效的特征提取和分类方法,在各个领域都有着广泛的应用价值。
dbn模型训练方法
DBN(深度信念网络)是一种深度学习模型,通常使用无监督学
习的方法进行预训练。
下面我会从多个角度全面地解释DBN模型的
训练方法。
首先,DBN模型的训练方法通常分为两个阶段,无监督预训练
和有监督微调。
在无监督预训练阶段,DBN模型使用逐层贪婪训练的方法。
首先,每一层的RBM(受限玻尔兹曼机)被训练以重构其输入数据。
这个过程是无监督的,意味着模型只使用输入数据本身而不需要标签。
通过这种方式,每一层RBM都学习到了输入数据的特征表示。
然后,这些逐层训练的RBM被堆叠在一起形成DBN模型。
在有监督微调阶段,DBN模型的参数被微调以最小化一个有监
督学习的目标函数,比如交叉熵损失函数。
这个阶段通常使用反向
传播算法,结合标签数据来调整模型参数,以使得模型能够更好地
适应特定的任务,比如分类或回归。
除了训练方法,还有一些关于DBN模型训练的注意事项。
首先,
DBN模型的训练通常需要大量的数据来取得好的效果,因为深度学
习模型需要大量的数据来学习到泛化的特征表示。
其次,对于无监
督预训练阶段,一些常用的优化算法包括随机梯度下降(SGD)、动
量法和自适应学习率方法(如Adam)等。
在有监督微调阶段,通常
使用反向传播算法结合上述优化算法来更新模型参数。
总的来说,DBN模型的训练方法涉及到无监督预训练和有监督
微调两个阶段,需要大量的数据和适当的优化算法来取得好的效果。
希望这些信息能够帮助你更全面地了解DBN模型的训练方法。
dbn模型训练方法全文共四篇示例,供读者参考第一篇示例:DBN模型(Deep Belief Network)是一种基于深度学习的神经网络模型,它能够学习数据中的高级特征表达,在各种领域中都有广泛的应用。
在实际应用中,训练DBN模型是非常重要的一步,它决定了模型的性能和泛化能力。
本文将介绍DBN模型的训练方法,帮助读者更好地理解和应用这一强大的深度学习模型。
一、DBN模型简介DBN模型是由多个RBM(Restricted Boltzmann Machine)组成的深度学习模型,其中RBM是一种基于概率的无向图模型。
DBN模型由输入层、多个隐层和输出层组成,在训练过程中,通过逐层训练和微调的方式来学习数据的分布和特征表示。
DBN模型能够学习数据中的抽象特征,实现从浅层特征到高级特征的逐渐提取。
2. RBM模型的训练RBM模型是DBN模型中的基本单元,在训练RBM模型时,通常采用CD算法(Contrastive Divergence)或者CD-k算法(Contrastive Divergence with k step gibbs sampling)。
CD算法是一种基于蒙特卡洛采样的方法,通过Gibbs采样来近似计算模型的梯度。
在训练RBM模型时,需要调整模型的权重和偏置参数,使得模型能够更好地拟合数据。
3. DBN模型的微调在逐层训练完成后,需要对整个DBN模型进行微调(fine-tuning),以进一步提高模型的性能。
微调的方法可以采用传统的反向传播算法(backpropagation),通过最小化损失函数来调整模型的参数。
微调过程中,可以使用梯度下降算法来更新模型的参数,并通过交叉验证等方法来选择合适的模型参数。
4. 正则化方法在训练DBN模型时,为了防止模型过拟合和提高泛化能力,通常会采用正则化方法。
常用的正则化方法包括L1正则化、L2正则化和dropout等。
通过正则化方法可以有效避免模型在训练过程中出现过拟合问题,提高模型的泛化能力。