基于卷积神经网络的ImageNet分类器
- 格式:ppt
- 大小:3.99 MB
- 文档页数:27

outputsegmentation map128 128256 128▼ 256 256U L I5125121024512512 256 ■1024♦c o n v 3x 3, R eLU .copy and crop f max pool 2x2♦ up-conv 2x2♦ conv l x l基于U _net ++卷积神经网络的C T 图像肺实质分割方法姜旭恒常宗强丁英杰(威海市中心医院山东省威海市264400 )摘要:本文介绍了随着人工智能技术的不断发展,计算机辅助诊断在肺癌、肺结节和新型冠状病毒肺炎等肺部疾病诊断领域取得了 广泛的应用。
为了提高神经网络检测的准确性,需要通过大量肺部CT 图像进行训练。
因此,获取干扰信息更少、病灶更加明显的肺实质 断层图像可以显著提高神经网络的准确率。
使用U -net ++卷积神经网络对L U N A 16肺部CT 数据集进行训练,将训练好的模型用于肺实质分 割。
肺实质分割网络输出平均D ice 系数为0.9925,实现了较为精准的肺实质分割。
通过U -net —卷积神经网络实现了对肺实质快速、准确的分割,对肺部疾病的计算机辅助诊断的发展具有一定的推动作用。
关键词:计算机辅助诊断;卷积神经网络;肺实质分割1引言肺部疾病一直是威胁人类健康的主要疾病。
近年来,肺癌的发病率和死亡率迅速增长,己经成为对人类生命威胁最大的恶性肿瘤之一 [11。
作为肺部疾病最有效的无创检测技术,C T 以其分层薄、分辨率高、低噪声等特点,被广泛应用到肺部疾病筛查和诊断当中[2]〇近年来,随着人工智能的不断发展,计算机辅助诊断(computeraided diagnosis ,CAD )在医学影像领域得到了广泛的应用⑴,特 别是在肺癌、肺结节等肺部疾病诊断方面己取得了重要进展。
现阶 段,计算机辅助诊断系统主要利用深度学习算法训练灵敏度较高的 卷积神经网络来实现对病灶的快速自动检测。

基于卷积神经网络的图像处理技术研究图像处理技术是目前智能化发展的重要组成部分。
其主要通过对图像进行分析、识别、处理等一系列操作,来获取有用信息,帮助人们更好的进行决策。
而其中的卷积神经网络(CNN)则成为了图像处理技术中最为重要的一部分。
卷积神经网络是一种强大的图像处理技术,它通过学习和训练大量的数据来自动提取图像中的特征,并对图像进行分类、识别和分割等操作,因此在目标检测、人脸识别等领域发挥着重要的作用。
接下来,我们将从以下几个方面对基于卷积神经网络的图像处理技术进行研究。
一、卷积神经网络的基本结构卷积神经网络的基本结构由多个卷积层、池化层、全连接层等组成。
其中卷积层主要用来提取特征,池化层用来降维,全连接层用来做最终的分类。
在卷积神经网络中,对图像进行卷积操作是核心步骤。
卷积操作通过使用一组大小固定的卷积核,对原图的每个像素进行计算,得出新的图像特征,从而实现对图像特征的提取。
而池化层则通过缩小卷积特征图的尺寸,且保留主要特征信息,来减少网络的参数量,提高网络的鲁棒性和泛化能力。
全连接层则是卷积神经网络中的最后一层,它将卷积层和池化层提取好的特征进行分类,输出结果。
由于特征的提取已经在前面的层次中完成,因此全连接层的主要作用是输出对应的分类标签。
二、基于卷积神经网络的图像分类基于卷积神经网络的图像分类,可以分为传统的单尺度CNN 和新型的多尺度CNN两种。
单尺度CNN通过不同深度的卷积层和池化层来对图片进行特征提取,并通过全连接层将结果分类。
其最大的问题是无法处理不同尺度的输入图片,因此从单尺度CNN出发,提出了新型多尺度CNN。
多尺度CNN是指将图像分成几个不同的尺度,然后将不同尺度的图像输入到不同的卷积层,使得不同尺度的特征能够在一个网络中学习到更好的表示。
而这种方法能更好的改善单尺度CNN 无法处理不同尺度图片的问题。
三、基于卷积神经网络的图像处理技术基于卷积神经网络的图像处理技术包括目标检测、图像分割、人脸识别等。

imagenet 使用说明Imagenet 使用说明引言:Imagenet 是一个庞大且广泛使用的图像数据库,用于计算机视觉领域的研究和发展。
本文将详细介绍Imagenet 的使用方法和重要性。
一、Imagenet 的定义和背景Imagenet 是一个由斯坦福大学研究团队创建的图像数据库,旨在为计算机视觉领域的研究提供数据支持。
该数据库包含超过一百万张图片,涵盖了来自超过一千个类别的物体和场景。
每个类别都包含了数百至数千张图片,这使得Imagenet 成为了一个全面而丰富的图像数据集。
二、Imagenet 的用途Imagenet 的主要用途是用于图像分类和目标识别的研究。
通过Imagenet 数据集,研究人员可以开展各种计算机视觉任务的实验和算法优化。
其重要性主要体现在以下几个方面:1. 训练模型:Imagenet 数据集可以用于训练深度学习模型,如卷积神经网络(CNN)。
通过大规模的数据集,模型可以学习到更广泛的特征和模式,从而提高分类和识别的准确性。
2. 评估算法:Imagenet 提供了一个标准化的评估基准,可以用于比较不同算法和模型的性能。
研究人员可以使用Imagenet 数据集进行算法的测试和对比,评估其在图像分类和目标识别任务上的表现。
3. 推动研究进展:Imagenet 的广泛应用促进了计算机视觉领域的研究进展。
通过分享和利用Imagenet 数据集,研究人员可以共同推动图像分类、目标检测和图像理解等方向的研究。
三、Imagenet 数据集的获取和使用要使用Imagenet 数据集,需要遵循以下步骤:1. 注册和获取许可:访问Imagenet 数据集需要进行注册并获取相应的许可证。
用户可以在Imagenet 网站上注册账号,并按照要求进行许可证申请。
2. 下载数据集:一旦获得了许可证,用户可以通过Imagenet 网站提供的下载链接获取数据集。
根据需求,用户可以选择下载全部数据或特定类别的数据。

imagenet训练方法Imagenet训练方法是一种深度学习的训练方法,它是基于大规模图像数据集Imagenet的训练方法。
Imagenet是一个包含1400万张图像的数据集,其中每张图像都被标注了1000个类别。
这个数据集被广泛应用于计算机视觉领域的研究和应用中。
Imagenet训练方法的核心是深度卷积神经网络(CNN)。
CNN是一种特殊的神经网络,它可以自动学习图像中的特征,并将这些特征用于分类、识别和检测等任务。
CNN的训练过程是通过反向传播算法来实现的,这个算法可以自动调整神经网络中的权重和偏置,使得网络的输出与实际标签更加接近。
Imagenet训练方法的具体步骤如下:1. 数据预处理:将Imagenet数据集中的图像进行预处理,包括图像的缩放、裁剪、旋转、翻转等操作,以增加数据的多样性和鲁棒性。
2. 网络设计:设计一个深度卷积神经网络,包括卷积层、池化层、全连接层等组件。
网络的设计需要考虑到数据集的特点和任务的要求,以提高网络的性能和泛化能力。
3. 初始化网络参数:将网络中的权重和偏置进行随机初始化,以便网络可以从零开始学习图像中的特征。
4. 前向传播:将图像输入到网络中,通过卷积、池化等操作,逐层计算网络的输出。
5. 计算损失函数:将网络的输出与实际标签进行比较,计算出网络的损失函数。
损失函数可以采用交叉熵、均方误差等方法进行计算。
6. 反向传播:通过反向传播算法,将损失函数的梯度传递回网络中,调整网络中的权重和偏置,以使得网络的输出更加接近实际标签。
7. 重复训练:重复执行前向传播、计算损失函数、反向传播等步骤,直到网络的性能达到预期要求。
Imagenet训练方法的优点是可以利用大规模数据集进行训练,从而提高网络的泛化能力和性能。
同时,Imagenet数据集中包含了各种不同的图像类别,可以帮助网络学习到更加丰富和多样的特征。
因此,Imagenet训练方法已经成为了计算机视觉领域中最为流行和有效的训练方法之一。

基于深度卷积网络的糖尿病性视网膜病变分类杜霞【摘要】糖尿病性视网膜病变是一种高致盲率的糖尿病眼底并发症且发病率逐年上升,临床人工诊断中存在判别困难、极度依赖医生经验、诊断准确率低等问题,因此对眼底病变的自动诊断方法有重要现实意义.采用深度卷积网络的In?ception-V4结构,根据视网膜图像进行四个病变阶段的分类.首先对原始数据进行归一化操作降低数据噪声,再通过旋转、剪裁等数据增强方法扩充数据集.然后采用迁移学习方法,先加载ImageNet预训练模型,再对Inception-V4网络进行参数微调.最后,接入一个四分类的分类器,使用Softmax函数获得图像的分类结果.实验在包含2409张眼底彩照的数据集上获得了88%的四分类准确率.该方法克服样本量不足以及数据不均衡的问题,在小数据集上获得较好的分类准确率,在辅助临床诊断中具有较好的应用价值.【期刊名称】《现代计算机(专业版)》【年(卷),期】2019(000)011【总页数】6页(P14-19)【关键词】糖尿病性视网膜病变;卷积神经网络;深度学习【作者】杜霞【作者单位】四川大学计算机学院,成都 610065【正文语种】中文0 引言糖尿病性视网膜病变(Diabetic Retinopathy,DR)是一种严重的糖尿病眼底微血管并发症,DR在导致20-74岁成人失明的因素中排列首位[1]。
据WHO发布的2016年《全球糖尿病报告》数据,全球截止2014年成人中糖尿病患者已经达到4.22亿,患病率显著上升。
在已有15年以上糖尿病史的患者中,80%以上患有DR。
DR的病情发展是渐进变化的,及时检查和治疗是预防失明的有效手段。
在医学上,根据视网膜眼底图像的特征对DR病情阶段进行了准确的分类,也是医生临床诊断的重要标准。
在实际诊断中,主要存在的问题包括:分类准确性极度依赖医生的临床经验;眼底照相的质量受到操作技术、设备、光线等影响较大;图像中存在的细微特征依靠肉眼难以辨别等[2]。

基于VGG网络模型的图像分类研究随着计算机视觉技术的不断发展,图像分类是其中最基础和重要的研究方向之一。
计算机视觉技术通过对图像的像素级别分析和处理,可以从中提取出有意义的特征,以实现对图像的分类、识别等任务。
近年来,基于深度学习的图像分类技术已经取得了长足的发展,在各种领域都有着广泛的应用。
其中,VGG网络模型是一个非常经典的深度学习模型之一,它采用了一个非常深的卷积神经网络架构,并在ImageNet大规模视觉识别竞赛中表现出了非常出色的性能。
本文将以VGG网络模型为基础,进行图像分类的研究,旨在探讨深度学习在图像分类任务中的应用。
一、VGG网络模型简介VGG网络模型是由牛津大学的Simonyan和Zisserman所提出的,它是一个比较经典的卷积神经网络模型。
VGG网络模型的主要特点在于它采用了非常深的卷积神经网络结构,网络层数在16层到19层之间。
这种非常深的网络结构可以更好地实现特征的提取和分类,从而有效地进行图像识别和分类任务。
VGG网络模型的核心结构是卷积层和池化层的交替排列。
卷积层可以有效地提取出图像的特征,包括边缘、纹理、颜色等信息,而池化层则可以将特征图的尺寸缩小,进一步提高了特征的抽象程度。
在VGG网络模型中,还采用了全连接层和softmax层,以实现分类的任务。
二、VGG网络模型的优缺点VGG网络模型在深度学习领域中具有非常高的知名度和影响力,它的优缺点也比较明显。
优点:1、较为简单的网络结构。
相对于其他深度网络模型,VGG网络模型的结构比较简单明晰,易于理解和实现。
2、非常深的网络结构。
VGG网络模型可以将网络层数增加到甚至30层以上,以进一步提高特征的抽象程度和分类的精度。
3、在ImageNet比赛中表现非常出色。
VGG网络模型在ImageNet比赛中表现非常出色,分类准确率达到了92.7%,并且还斩获了多项比赛奖项。
缺点:1、比较大的模型规模。
VGG网络模型由于采用了非常深的网络结构,导致它的参数量非常庞大,难以进行快速训练和推理。

imagenet数据集用法Imaegenet数据集是目前被广泛使用的一种用来训练深度学习模型的数据集。
它由Princeton的Fei-Fei Li等人创建,拥有超过1.4百万的图像,覆盖了超过一千个对象类别。
它的作用是帮助训练图片分类,物体检测和物体定位等深度学习模型。
本文将介绍Imagenet数据集的用法。
首先,我们需要明确,对于深度学习来说,数据集几乎是至关重要的。
Imaegenet数据集提供了大量的图像和标注来帮助我们训练深度学习模型。
在使用Imagenet数据集时,我们一般的做法是将其分成训练集和测试集,通常是70%的数据用于训练,30%用于测试。
这样可以保证我们训练出来的模型在未知的数据上也能有很好的表现。
同时,为了避免过拟合,我们还需要进行数据增强,常见的数据增强方法包括:随机裁剪、随机缩放、翻转、旋转等。
对于Imagenet数据集,我们要进行下面几个步骤:1. 数据预处理。
Imagenet数据集中包含了不同大小和形状的图片,我们需要对其进行统一的尺寸处理和归一化处理,以便于模型的训练。
2. 模型构建。
目前,Imagenet数据集上表现最好的模型是卷积神经网络(CNN)模型。
我们可以使用开源框架如Keras、Pytorch和Tensorflow等来搭建我们的模型。
一般建议使用预训练模型来提高训练效率,包括VGGNet、ResNet、Inception等。
3. 模型训练。
在将Imagenet数据集用于CNN模型时,我们可以使用优化算法如SGD、Adam等来训练模型。
每一次训练我们需要分别计算训练集和测试集上的损失函数,以便于调整模型。
4. 模型测试。
在得到训练好的模型后,我们可以使用测试集来测试模型的准确率。
通常将测试结果以混淆矩阵的形式进行展示,以便于评价模型的性能。
总之,Imagenet数据集是训练深度学习模型最重要的数据集之一,它为我们提供了大量的数据和标注来训练模型。
在使用Imaegenet数据集时,我们需要进行数据预处理、模型构建、模型训练和模型测试等多个步骤,并结合数据增强等技术来优化模型性能。

文章题目:深入了解ConvNetV2分类模型的构建和性能分析一、 ConvNetV2分类模型概述1.1 模型背景ConvNetV2分类模型是一种基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习模型,广泛应用于图像识别、物体检测和分类等领域。
它的主要特点是能够有效提取图像的特征,并通过神经网络的层层处理最终实现分类识别的功能。
1.2 模型结构ConvNetV2分类模型一般由若干个卷积层、池化层、全连接层等构成。
其中,卷积层用于提取图像中的特征,池化层用于压缩特征图的尺寸,全连接层用于实现分类识别。
通过这些层的组合使用,可以构建出一个具有较高识别精度的分类模型。
二、 ConvNetV2分类模型的构建2.1 数据预处理在构建ConvNetV2分类模型之前,需要对原始数据进行预处理,包括数据的清洗、标准化、归一化等工作。
这些步骤的目的是为了使模型训练所使用的数据更加规范化,从而有利于模型的训练和优化。
2.2 模型参数设置在构建ConvNetV2分类模型时,需要设置模型的各种参数,包括卷积核大小、滑动步长、池化大小、激活函数、学习率等。
这些参数的设置对模型的性能和训练效果都有着重要的影响。
2.3 神经网络结构ConvNetV2分类模型的神经网络结构一般由输入层、卷积层、池化层、全连接层和输出层等组成。
在构建模型时,需要根据具体的应用场景和数据特点来设计合理的网络结构,以实现最佳的分类识别效果。
三、 ConvNetV2分类模型的训练与优化3.1 损失函数选择在训练ConvNetV2分类模型时,需要选择合适的损失函数,常用的损失函数包括交叉熵损失函数、均方误差损失函数等。
不同的损失函数适用于不同的应用场景,选择合适的损失函数可以有效提高模型的训练效果。
3.2 梯度下降优化在模型训练过程中,通常采用梯度下降优化算法来调整模型的参数,以使模型的损失函数最小化。
常用的梯度下降算法包括随机梯度下降(SGD)、动量法、Adam优化算法等,通过合理选择和调整优化算法,可以加快模型的收敛速度,提高训练效果。

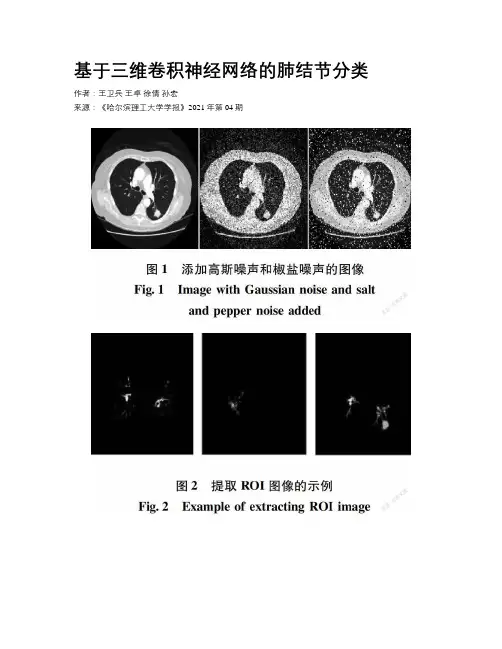
基于三维卷积神经网络的肺结节分类作者:王卫兵王卓徐倩孙宏来源:《哈尔滨理工大学学报》2021年第04期摘要:为提高不易分割诊断的毛玻璃结节的分类准确率,同时针对VGG16网络结构卷积层数深,参数多的問题,提出一种基于灰度增强、纹理和形状滤波增强的三维深度卷积神经网络用于肺结节分类。
对VGG16网络结构进行优化,提出的模型在肺结节公开数据集LIDC-IDRI上进行训练和测试。
结果表明,采用灰度增强、纹理和形状滤波增强相结合的方法图像分类精度最高,准确率为91.7%,其他评价指标包括敏感性和特异性也略有提高,优于现有方法。
关键词:肺结节;深度学习;卷积神经网络DOI:10.15938/j.jhust.2021.04.012中图分类号:TP391.41文献标志码:A文章编号:1007-2683(2021)04-0087-07Abstract:In order to improve the classification accuracy of ground glass nodules that are difficult to segment and diagnose and at the same time, the VGG16 network structure has deep convolutional layers and many parameters, A 3D deep convolutional neural network based on intensity, texture, and shape-enhanced images for pulmonary nodule recognition was proposed. The VGG16 network structure was optimized, and the proposed model was trained and tested on the public nodule dataset of lung nodules LIDC-IDRI. The results showed that the proposed method using the composition of intensity, texture and shape-enhanced has the highest image classification accuracy, with an accuracy of 91.7%. Other measures, including sensitivity and specificity, also improved slightly, It is superior to existing methods.Keywords:pulmonary nodule;deep learning;convolutional neural network0 引言国际癌症研究机构制定的癌症发病率和死亡率报告显示,肺癌是最常见的癌症,且是死亡率较高的癌症之一[1]。

基于神经网络的信号处理与识别近年来,在各个领域中,基于神经网络的技术正在得到广泛应用。
在信号处理和识别方面,神经网络也展现出了其出色的性能和优势。
神经网络的出现打破了传统信号处理方法的局限性,有效地提高了信号处理和识别的精度和效率。
本文将探讨基于神经网络的信号处理与识别技术的研究现状、优势和应用。
一、神经网络的概念和发展神经网络是一种类似于人脑结构的计算机模型,由神经元构成,具有学习、存储和自适应能力。
神经网络的模型是由人工神经元和人工突触构成的。
它们可以自适应地调整其权值和连接方式,从而实现输入与输出之间的关联和转换,这种特性使得神经网络在模式识别和信号处理领域的应用具有广泛的前景。
神经网络的知名度和应用领域可能要追溯到上世纪50年代和60年代。
早期的神经网络模型主要采用感知机(Percetron)和自适应线性元件神经网络(ADALINE)。
感知机是一种二元分类器,由两个层次组成:输入层和输出层。
它可以对输入进行线性分类。
后来的一些模型中,将感知机的权值调整规则改为反向传播(backpropagation)算法,使用梯度下降法来求误差最小化。
自适应线性元件神经网络(ADALINE)则是一种线性元件神经网络,它通过将输入和输出之间的权重进行自适应调整,来将不同的输入分类。
随着深度学习和大数据的发展,神经网络模型得到了进一步发展。
例如,在2012年,Alex Krizhevsky提出的深度卷积神经网络(Deep Convolutional Neural Network, DCNN)在ImageNet Large Scale Visual Recognition Challenge(ILSVRC)上取得惊人的成绩,将错误率从之前的30%下降到15%。
这些成果表明深度学习已经成为影响人类生产力和社会生活的重要技术之一。
二、基于神经网络的信号处理在信号处理领域,神经网络已经得到了广泛的应用。
基于神经网络的信号处理可以从以下几个方面进行介绍:(一)语音/音频处理语音/音频处理是神经网络在信号处理领域中的重要应用之一。
AI技术在图像识别领域的应用案例分析一、引言随着人工智能(AI)技术的快速发展,图像识别逐渐成为AI领域的热门应用之一。
图像识别是通过计算机对数字图像进行分析、理解和推断,从而实现对图像中物体、场景或特征的自动识别。
本文将分析几个在图像识别领域中应用AI技术的案例,以揭示这些技术的潜力和应用前景。
二、基于深度学习的人脸识别人脸识别是图像识别领域中应用广泛且重要的任务之一。
传统的人脸识别方法主要基于手工设计的特征提取算法,效果有限。
然而,随着深度学习算法的兴起,基于卷积神经网络(CNN)的人脸识别方法取得了显著进展。
Facebook AI Research团队利用深度学习开发了FaceNet模型,该模型可以将不同角度、光照条件下拍摄到的人脸进行高效准确地匹配。
这一技术被广泛应用于社交媒体平台和手机设备中,帮助用户自动标记朋友的照片,并提供相应的人脸识别功能。
此外,深度学习在人脸识别领域的另一个重要应用是检测欺诈行为。
许多金融机构利用AI技术对客户进行身份验证和欺诈检测,以防止身份盗窃和金融欺诈。
通过对用户上传的照片进行人脸识别,可以快速准确地判断是否涉及欺诈行为。
三、基于卷积神经网络的图像分类图像分类是图像识别中最常见且具有挑战性的任务之一。
传统方法主要基于手工设计特征和分类器进行图像分类,但面临着特征表示不充分和泛化能力差的问题。
然而,卷积神经网络(CNN)的出现改变了这一局面。
谷歌开发了一个名为Inception的深度学习模型,在ImageNetLarge Scale Visual Recognition Challenge竞赛中取得了优异成绩。
该模型采用了多层卷积结构,并通过自适应权重调整来提取图片中物体特征。
Inception模型在图像分类领域取得了显著进步,并被广泛应用于搜索引擎、社交媒体和医学影像领域。
另一个开创性的图像分类案例是基于卷积神经网络的猫狗识别。
斯坦福大学的研究团队利用深度学习算法训练了一个特殊的CNN模型,可以准确地识别猫和狗的图像。
基于卷积神经网络的识别技术研究一、引言卷积神经网络(Convolutional Neural Network, CNN)是一种应用广泛的深度学习算法,在图像识别、语音识别、自然语言处理等领域取得了非常显著的成果。
基于卷积神经网络的识别技术也是市场上热门的技术之一。
本文旨在对基于卷积神经网络的识别技术进行深入研究,探究其原理及应用,以期为相关领域进行技术优化提供借鉴。
二、基本原理卷积神经网络是一种前向反馈神经网络,主要用于处理具有网格状拓扑结构的数据,如图像。
该网络主要由三种层组成:卷积层、池化层和全连接层。
卷积层主要用于提取图像特征,它通过将多个卷积核应用于输入图像,生成多个卷积特征映射。
池化层则是为了减少数据维度,常用的池化方法有最大池化和平均池化。
全连接层则将卷积层和池化层输出的特征向量进行连接,实现分类任务。
卷积神经网络有以下两种常见结构:LeNet和AlexNet。
其中,LeNet是最早提出的卷积神经网络,它由两个卷积层、两个池化层和三个全连接层组成,主要应用于手写数字识别。
而AlexNet则是一种更深的卷积神经网络,它有五个卷积层、三个池化层和三个全连接层。
三、高级技术1.迁移学习迁移学习是指在一个领域训练好的模型可以应用于另一个领域。
在基于卷积神经网络的识别技术中,迁移学习可以通过利用预训练模型对小样本数据进行特征提取,从而提高模型的准确性和泛化能力。
常用的预训练模型有VGG、ResNet、Inception等。
2.物体检测物体检测是指在图像中检测出特定物体的位置和数量,常用的方法有R-CNN、Fast R-CNN、Faster R-CNN、YOLO等。
其中,Faster R-CNN是目前较为先进的物体检测方法,它通过引入区域提议网络(Region Proposal Network, RPN)和锚框(Anchor)机制,实现了物体检测的端到端训练。
3.图像分割图像分割是指将图像分割成多个区域,并将每个区域分配给相应的对象,实现对每个对象的精细分类。
imagenet训练方法ImageNet训练方法是深度学习领域中的重要技术之一,主要用于图像分类、物体检测和语义分割等任务。
本文将介绍ImageNet训练方法的基本原理和流程。
一、数据集ImageNet是一个庞大的图像数据库,其中包含1000个类别的超过1400万张标注图像。
每个类别包含1000张训练图像和1000张验证图像。
训练数据包含130万张图像,其中50万张已经过手工标注。
每个图像都有一个标签,标签是该图像所属的类别。
二、网络结构ImageNet训练网络的结构通常采用卷积神经网络(CNN),其中最常用的网络是AlexNet、VGG、GoogLeNet和ResNet。
其中,AlexNet是最先进的网络,VGG是最简单和最流行的网络,GoogLeNet是最复杂的网络,ResNet是最新的网络。
AlexNet网络结构主要由5个卷积层、3个全连接层和1个softmax分类器组成,其中两个卷积层后跟着一个池化层。
VGG网络结构由13个卷积层和3个全连接层组成,它使用3 x 3的滤波器大小,精度比AlexNet高。
GoogLeNet网络结构由22个层组成,包括14个Inception层,其中每个Inception层由多个不同滤波器组合而成。
ResNet网络结构是最近发表的,它采用残差单元(Residual Unit),具有较高的准确率和更深的网络深度。
三、训练过程ImageNet训练过程中,输入图像尺寸为224 x 224像素,采用随机裁剪和水平翻转等数据增强操作,可以增加数据的丰富性、减少过拟合现象并提高模型性能。
生成训练和验证数据的基本步骤如下:1. 预处理图像数据,包括剪切、缩放和归一化等操作。
2. 对于每个类别,随机选择1000张图像作为验证集。
3. 采用随机梯度下降(SGD)算法对网络进行训练,基于每个batch的损失计算反向传播误差,更新网络权重。
4. 评估模型的性能,基于验证集计算模型准确率和损失函数值。