联机手写数字识别实验报告
- 格式:doc
- 大小:1.10 MB
- 文档页数:13

数字识别实验报告数字识别实验报告引言:数字识别是计算机视觉领域的一个重要研究方向,它涉及到图像处理、模式识别等多个学科。
本实验旨在通过构建一个数字识别模型,探索不同算法在数字识别中的效果,并比较它们的准确性和稳定性。
一、实验设计1. 数据集选择本实验选用了MNIST数据集,该数据集包含了大量手写数字的图像样本,是数字识别领域中最经典的数据集之一。
2. 算法选择本实验采用了三种常见的数字识别算法:K近邻算法、支持向量机算法和深度学习算法(卷积神经网络)。
3. 实验步骤(1)数据预处理:对原始图像进行灰度化、二值化等处理,以便将图像转化为算法所需的输入格式。
(2)特征提取:提取图像中的特征,如边缘、纹理等,以便算法能够更好地区分不同的数字。
(3)模型训练:使用训练集对选定的算法进行训练,并调整算法的参数以提高模型的准确性。
(4)模型测试:使用测试集对训练好的模型进行测试,并记录准确率和识别速度等指标。
(5)结果分析:比较不同算法在数字识别中的表现,并分析其优缺点。
二、实验结果1. K近邻算法经过实验,我们发现K近邻算法在数字识别中表现出较高的准确性,但由于其计算复杂度较高,在大规模数据集上的运行速度较慢。
2. 支持向量机算法支持向量机算法在数字识别中也取得了不错的效果,尤其在处理非线性可分问题时表现出色。
然而,该算法对于大规模数据集的训练时间较长。
3. 深度学习算法(卷积神经网络)深度学习算法在数字识别中展现出了强大的潜力,通过构建多层卷积神经网络,我们得到了较高的准确率和较快的识别速度。
然而,该算法对于数据集的规模和质量要求较高,需要更多的计算资源和训练时间。
三、结果分析综合比较三种算法的实验结果,我们可以得出以下结论:1. K近邻算法在准确性方面表现出色,但在处理大规模数据时速度较慢。
2. 支持向量机算法在处理非线性问题时具有优势,但对于大规模数据集的训练时间较长。
3. 深度学习算法在准确率和识别速度方面都有较好的表现,但对数据集的规模和质量要求较高。

手写数字识别调研报告手写数字识别是一种将手写数字转换为可识别数字的技术,它在现实生活中有着广泛的应用。
本调研报告旨在对手写数字识别的相关技术进行调查研究,并对其应用领域和未来发展进行探讨。
首先,我们对手写数字识别的技术进行了研究。
目前常用的手写数字识别技术包括基于传统机器学习算法的方法和基于深度学习算法的方法。
传统机器学习算法通常使用特征提取和分类器的组合,如支持向量机(SVM)和k最近邻(k-NN)算法。
深度学习算法则通过构建多层神经网络,通过大量数据的训练来实现高准确率的分类。
当前,深度学习算法在手写数字识别方面取得了很大进展。
其次,我们调查了手写数字识别的应用领域。
手写数字识别可以应用于各种场景,如无人驾驶、金融支付、邮件分类等。
在无人驾驶方面,手写数字识别可以帮助车辆识别交通标志和路标,并做出相应的行动。
在金融支付方面,手写数字识别可以应用于支票的自动识别和存储,提高支付效率和精确度。
在邮件分类方面,手写数字识别可以帮助自动邮件分拣系统进行分类,提高邮件处理的效率。
最后,我们对手写数字识别的未来发展进行了讨论。
随着深度学习技术的不断进步,手写数字识别的准确率将不断提高。
此外,随着各种硬件设备的发展,如智能手机、平板电脑等,手写数字识别技术将更加广泛地应用于日常生活中。
另外,结合其他技术如图像处理和自然语言处理,手写数字识别的应用领域将进一步扩展。
综上所述,手写数字识别是一种在现实生活中有广泛应用的技术。
随着技术的不断进步,手写数字识别的准确率将不断提高,并在更多领域得到应用。
未来,我们可以期待手写数字识别技术在各个行业中发挥更大的作用。

基于LeNet的手写数字识别实验是计算机视觉领域中一个经典的实例,通过对MNIST数据集进行处理和分析,使用LeNet-5神经网络模型实现对手写数字(0-9)的识别。
以下是对该实验的总结:1. 数据集介绍MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。
这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素)。
数据集分为训练集、验证集和测试集,方便进行模型训练和性能评估。
2. LeNet-5模型LeNet-5是一种卷积神经网络模型,由Yann LeCun于1998年提出。
尽管其提出时间较早,但在手写数字识别任务上取得了显著的成功。
实验中,我们采用LeNet-5模型对MNIST数据集进行处理。
3. 模型结构LeNet-5模型包括两个卷积层和三个全连接层。
卷积层分别包含6个和16个卷积核,卷积核大小为5x5。
每个卷积层之后跟着一个最大池化层,池化核大小为2x2。
全连接层分别具有64、120和84个神经元。
最后,模型输出10个神经元,对应10个数字类别。
4. 实验流程实验中,首先对数据集进行预处理,将图像缩放到28x28像素。
然后,将数据集划分为训练集、验证集和测试集。
接着,构建LeNet-5模型并使用训练集进行训练。
在训练过程中,采用交叉熵损失函数和随机梯度下降(SGD)优化器。
最后,使用验证集评估模型性能,并选取最优模型在测试集上进行测试。
5. 实验结果经过训练,LeNet-5模型在MNIST数据集上取得了较好的识别效果。
在测试集上,模型对数字的识别准确率达到了98.89%。
实验结果表明,尽管LeNet-5模型相对简单,但在手写数字识别任务上具有较高的准确率。
6. 实验总结基于LeNet的手写数字识别实验展示了卷积神经网络在计算机视觉领域的应用。
通过搭建LeNet-5模型并对MNIST数据集进行处理,实验证明了卷积神经网络在识别手写数字方面的有效性。

基于HMM的联机手写汉字识别的开题报告一、研究背景及意义随着信息时代的发展,人们对手写汉字识别技术的需求越来越大。
联机手写汉字识别就是指将一笔一划的输入过程与识别过程同时进行,实时地将手写笔迹转化成汉字,这种识别方式比离线手写汉字识别更加实用。
联机手写汉字识别的应用场景非常广泛,涉及到自然语言处理、信息检索、语音合成、OCR等多个领域,尤其在移动设备上的输入交互中得到广泛应用。
因此,研究联机手写汉字识别有极高的实际应用和研究价值。
二、研究内容本研究的主要内容是基于HMM(隐马尔科夫模型)的联机手写汉字识别。
HMM是一种基于概率的统计模型,在语音识别、图像识别、自然语言处理等领域得到广泛应用。
HMM模型是一种基于时间序列的模型,将输入序列转化成一个隐藏序列和一个观测序列,其中,隐藏序列是模型中不可见的状态序列,观测序列是模型中可见的观测值序列。
在联机手写汉字识别中,输入的手写笔迹就是观测序列,而笔迹所代表的汉字就是隐藏序列,使用HMM来建模可以充分利用笔迹的时间序列特征。
具体实现上,本研究将研究和探讨:1. 建立HMM模型:通过对手写汉字进行分析和研究,确定HMM的状态数和观测序列,构建初始HMM模型。
2. 模型训练:通过学习手写汉字的样本,对HMM模型进行训练,得到训练好的HMM模型,使其能够准确地识别手写汉字。
3. 模型评估:考虑使用交叉验证等方法,对训练好的HMM模型进行评估,包括准确率、召回率、F1值等指标。
4. 应用实现:将训练好的HMM模型应用于实际的联机手写汉字识别场景中。
例如,可以将其集成到智能手机的输入法中,实现快速精准的手写汉字输入。
三、研究方法及技术路线本研究的技术路线如下:1. 数据预处理:对手写汉字数据进行预处理,包括数据采集、数据清洗、数据预处理等。
2. 特征提取:对手写汉字进行特征提取,挖掘其时间序列特征,提取出代表汉字的主要特征。
3. HMM模型建立:根据手写汉字特征,建立HMM模型。

《基于深度学习的联机蒙古文手写识别系统研究》篇一一、引言随着信息技术的快速发展,手写识别技术已经成为一项重要的研究领域。
作为多元文化的一部分,蒙古文手写识别技术的发展显得尤为重要。
联机手写识别技术能够实时地将手写输入转化为计算机可识别的文字信息,具有广泛的应用前景。
本文旨在研究基于深度学习的联机蒙古文手写识别系统,以提高蒙古文手写识别的准确性和效率。
二、蒙古文手写识别的现状与挑战蒙古文作为一种独特的文字系统,其手写识别具有一定的难度。
目前,蒙古文手写识别主要面临以下挑战:一是蒙古文字符的形态多样,结构复杂,导致识别难度大;二是手写输入的随意性大,同一字符的书写方式可能多种多样;三是受书写工具、纸张等因素的影响,手写输入的图像质量差异较大。
三、深度学习在蒙古文手写识别中的应用深度学习在图像识别领域取得了显著的成果,为蒙古文手写识别提供了新的思路。
基于深度学习的联机蒙古文手写识别系统,通过训练深度神经网络模型,能够自动提取手写图像中的特征,提高识别的准确性和鲁棒性。
此外,深度学习还能够处理复杂的时空数据,适应联机手写识别的实时性要求。
四、系统设计与实现本文设计了一种基于深度学习的联机蒙古文手写识别系统,包括数据预处理、特征提取、模型训练和识别等模块。
首先,对手写图像进行预处理,包括去噪、归一化等操作,以提高图像质量。
然后,利用深度神经网络模型提取手写图像中的特征。
在模型训练阶段,采用大量标注的蒙古文手写数据集进行训练,优化模型参数。
最后,通过实时获取手写轨迹数据,进行在线识别。
五、实验与分析为了验证基于深度学习的联机蒙古文手写识别系统的性能,我们进行了大量的实验。
实验结果表明,该系统能够有效地提取手写图像中的特征,提高识别的准确率和鲁棒性。
与传统的蒙古文手写识别方法相比,该系统具有更高的识别率和更低的误识率。
此外,该系统还能够适应不同的书写工具和纸张,具有较好的泛化能力。
六、结论与展望本文研究了基于深度学习的联机蒙古文手写识别系统,提高了蒙古文手写识别的准确性和效率。

手写数字识别系统的设计与实现摘要手写体数字识别是文字识别中的一个研究课题,是多年来的研究热点,也是模式识别领域中最成功的应用之一。
主要功能是通过在点击手写数字识别菜单下的绘制数字标签弹出的绘制数字窗口中完成数字的手写,在此窗口中可以进行数字的保存及清屏,然后通过文件菜单中的打开标签打开所绘制的数字,从而进行数字的预处理,其中包括灰度化及二值化处理,然后进行特征提取,最后实现数字的识别。
利用Matlab程序设计的相关知识,运用模块设计等相关技术,最终完成手写体识别综合设计。
实验结果表明,本系统具有较高的识别率。
关键词:绘制数字;预处理;特征提取;特征库;数字识别1前言自上世纪六十年代以来,计算机视觉与图像处理越来越受到人们的关注,并逐渐成为一门重要的学科领域。
而作为它们的研究对象的数字图像,也因为它含有研究目标的丰富信息而成为越来越重要的研究对象。
图像识别的目标是用计算机自动完成某些信息的处理,用来替代人工去处理图像分类及识别的任务。
手写数字识别是图像识别学科下的一个分支,是图像处理和模式识别领域研究的课题之一,由于其具有很强的实用性一直是多年来的研究热点。
由于手写体数字的随意性很大,例如,笔画的粗细,字体的大小,倾斜等等都直接影响到字符的正确识别,所以手写体数字识别是一个很有挑战性的课题。
在过去的数十年中,研究者们提出了许多的识别方法,取得了较大的成果。
手写体数字识别实用性很强,在大规模数据统计(如例行年检,人口普查),财务,税务,邮件分拣等等应用领域中都有广阔的应用前景。
本课题拟研究手写体数字识别的理论和方法,开发一个小型的手写体数字识别系统。
在研究手写体数字识别理论和方法的基础上,开发这样一个小型的手写体数字识别系统需要完成以下主要方面的研究与设计工作:手写数字绘制的问题、数字的预处理问题、特征提取问题、特征库的建立问题、数字识别问2课题的背景2.1手写数字识别的发展模式识别是六十年代初迅速发展起来的一门学科。

软件学院12-13-2学期《人工智能》课程项目报告题目:使用SMO方法进行手写体数字识别目录软件学院12-13-2学期《人工智能》课程项目报告 (1)1 问题描述 (2)2 二值化处理 (2)2.1 思想: (2)2.2 OSTU算法: (2)2.3 OTSU算法伪代码: (2)3 降维处理 (2)4.半监督算法 (4)4.1半监督算法流程: (4)4.2半监督算法的主要算法: (4)1)self-Training models: (4)2)Propagating-1-nearest-neighbor: (4)3)CLUSTER-THEN-LABELMETHODS (4)4)Co_Training: (4)5)基于图的算法(Graph based Learning): (5)4.4半监督学习分类算法的现实价值: (5)5 我使用SVM的SMO算法 (5)5.1 SMO算法基本思想: (5)5.2 应用SMO算法的流程: (5)6 性能分析 (6)6.1.监督学习 (6)6.2.半监督学习(Tri-training) (6)6.3 我们用J48,SMO, NaiveBayes以及BayesNet四种算法对降维后的算法进行训练并求出其准确性,得到如下数据 (7)7 思考总结 (7)1 问题描述手写体数字识别问题,简而言之就是识别出10个阿拉伯数字,由于数字的清晰程度或者是个人的写字习惯抑或是其他,往往手写体数字的形状,大小,深浅,位置会不大一样。
现在我们拥有3006个带标记的数据以及56994的未带标记的数据,而我们的目标就是正确识别出这些手写体数字。
因此我们可以把这些带标记的数据看作经验值,运用一定算法来学习,预测出这些未带标记的数据。
对问题的分析如下:1 考虑到每个值都是0-255之间的一个整型值,对于算法的分析操作会影响性能,我将每个值进行了二值化,变成0,1。
2 考虑到这些数据都是28×28=784维的,维数太大,在后续的学习过程中效率会很低,我对它进行了降维处理。
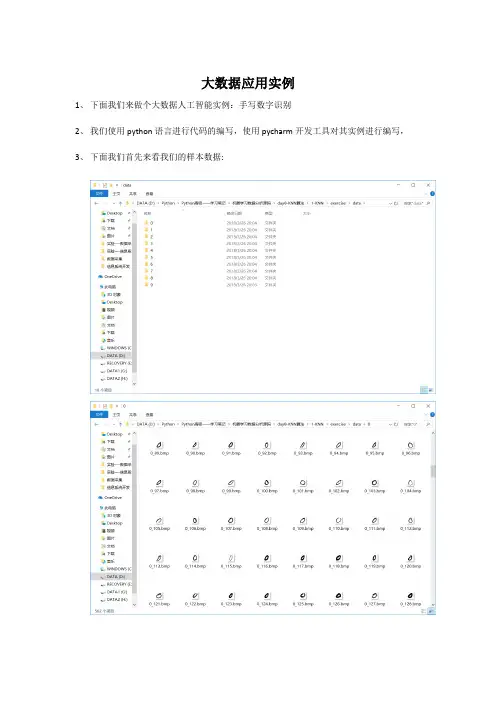
大数据应用实例1、下面我们来做个大数据人工智能实例:手写数字识别2、我们使用python语言进行代码的编写,使用pycharm开发工具对其实例进行编写,3、下面我们首先来看我们的样本数据:4、我们使用python语言来对其数据进行机器学习和识别代码如下:import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.neighbors import KNeighborsClassifier# 1、数据读取data = plt.imread('./data/0/0_1.bmp')# plt.imshow(data)# plt.show()# x_tain=[]# for i in range(1,501):# x_tain.append(plt.imread('./data/0/0_%d.bmp'%(i)))x_tain =[]x_test =[]y_tain=[]y_test=[]for i in range(0,10):for j in range(1,501):if j < 451: #将数据保存到训练数据中x_tain.append(plt.imread('./data/%d/%d_%d.bmp'%(i,i,j)).reshape(-1) ) #reshape 可以降维也就是矩阵变化y_tain.append(i) #append 是读进来的数据进行存储的意思else: #保存到预测数据中x_test.append(plt.imread('./data/%d/%d_%d.bmp'%(i,i,j)).reshape(-1)) y_test.append(i)# 2、数据转换成x_tain,y_tain= np.array(x_tain),np.array(y_tain)# print(x_tain.shape,len(y_tain),len(x_test))# 3、机器学习knn = KNeighborsClassifier() #构造分类器knn.fit(x_tain,y_tain)y_ = knn.predict(x_test) #进行预测的结果# print(len(y_[::10]),'\n',y_test[::10])gl=knn.score(x_test,y_test)print('准确率为:',gl)# 3、图片绘制plt.figure(figsize=(13,15))img = x_test[::10]img1 = y_test[::10]yimg = y_[::10]for i in range(50):plt.subplot(5,10,i+1)plt.imshow(img[i].reshape(28,28))plt.title('预测数据:%d'%(yimg[i])+'\n真实数据:%d'%(img1[i]))plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号plt.show()'''import matplotlib.ticker as tickerfig=plt.figure()ax = fig.add_subplot(111)ax.yaxis.set_major_locator(ticker.NullLocator())'''5、结果展示。


手写数字识别调研报告格式手写数字识别调研报告一、引言手写数字识别是计算机视觉领域的一个重要研究课题,其应用在验证码识别、银行支票自动处理、邮件识别等方面具有广泛的应用价值。
本次调研旨在了解手写数字识别的现状、技术方案以及前沿发展趋势,为相关领域的研究和应用提供参考。
二、调研过程1. 确定调研目标:本次调研的主要目标是了解手写数字识别的技术原理、现有的算法模型以及应用案例。
2. 收集文献资料:通过查阅相关学术论文、研究报告、技术博客等渠道,收集手写数字识别的相关资料。
3. 数据分析:对收集到的文献资料进行整理和分析,了解手写数字识别研究的现状和发展趋势。
4. 报告撰写:根据分析结果撰写调研报告。
三、手写数字识别的技术原理手写数字识别的技术原理主要包括图像预处理、特征提取和分类器训练三个步骤。
其中,图像预处理主要用于降低图像噪声、增强图像对比度等;特征提取是提取图像中的关键特征,如边缘、轮廓、纹理等;分类器训练是利用已标注的手写数字图像进行训练,建立分类模型。
四、手写数字识别的算法模型目前,手写数字识别常用的算法模型包括传统机器学习算法和深度学习算法两种。
传统机器学习算法包括支持向量机(SVM)、K近邻(KNN)、决策树等。
深度学习算法则主要包括卷积神经网络(CNN)、循环神经网络(RNN)等。
按照数据集的标注方式不同,算法模型还可分为有监督学习和无监督学习两种。
五、手写数字识别的应用案例手写数字识别广泛应用于验证码识别、银行支票自动处理、邮件识别等场景。
例如,验证码识别中,手写数字识别可用于自动化注册、登录等场景,提高用户体验。
银行支票自动处理中,手写数字识别可用于支票金额的自动提取和识别,减少人工处理的工作量。
邮件识别中,手写数字识别可用于自动提取信件上的邮政编码,提高邮件配送的准确性。
六、手写数字识别的前沿发展趋势1. 数据集的规模和质量将继续提升,有助于提高手写数字识别的准确率和鲁棒性。
2. 深度学习算法在手写数字识别中的应用将更加广泛,模型结构和训练方法将持续优化,提高识别性能。

模式识别课程论文----手写数字识别系统的设计与实现综述学院:计算机学院班号:*********姓名:******学号:指导老师:2010.07一、样本的获取预处理手写数字识别因书写者的随意性和环境差异限制了其向实际应用领域的推广,因此有必要对其进行预处理研究。
手写数字识别的预处理一般包括数字字符图像的平滑去噪、二值化、归一化和细化等过程。
1. 平滑去噪平滑去噪的目的在于除去孤立的噪声点,删除其中的小凸起,平滑笔划边缘,以利于后续算法的进行。
一般选择二维中值滤波进行平滑去噪,二维中值滤波输出为:( , ){( , ) , ( , )} gxymedfxkylklW=−−其中f(x,y),g(x,y)分别为原始图像和处理后图像,W为二维模板,通常为2*2或3*3区域。
模板的选择很关键,太小则不能去除噪声,太大则不但去除了噪声,也删除字符图像中的有用信息。
字符图像经平滑处理后, 还有一些孤立噪声或只是减小了噪声的面积,而没有消除。
对于这些噪声, 可以在区域连通处理中消除。
2. 二值化二值化处理是将图像转化为由0 和 1 表示的二值像素矩阵形式。
二值化的关键在于阈值T 的选择,通常采用由灰度级直方图确定整体阈值T。
字符图像的直方图一般有两个峰值,一个峰值对应数字的笔划部分,另一个峰值对应数字的背景部分。
阈值应该取在两个峰值的波谷处,波谷越深陡,二值化效果越好。
本文采用基于类间方差最大化的ostu方法求取阈值,进行二值化。
3. 尺寸归一化为便于识别,我们要将手写数字进行归一化得到尺寸一致的图像。
尺寸归一化包括字符分割和规范化。
a)字符分割字符分割首先对图像自上而下逐行扫描找到第一个黑像素点,记录下来;再由下向上逐行扫描找到第一个黑像素点,记录下来,得到图像的高度范围。
然后在这个高度范围之内自左向右逐列扫描,记录第一个黑像素点;再由右向左逐列扫描找到第一个黑像素点,记录下来,得到图像的宽度范围。
手写数字识别实验报告最近,手写数字识别技术受到越来越多的关注,各种手写数字识别系统也被广泛应用于实际应用中。
为了验证手写数字识别技术的有效性,本实验选择了国际上最流行的MNIST数据集,实现了一个深度学习模型,用来实现对手写数字的自动识别。
本实验步骤如下:一、数据集的准备本实验使用MNIST数据集。
MNIST数据集是一个包含60,000个训练图像和10,000个测试图像的数据集,所有图像都是灰度图像,每个图像都是28×28像素大小,每张图片都标记有0-9的数字,图像所属的类别。
二、模型构建本实验使用Convolutional Neural Network(CNN)构建模型,CNN是一种卷积神经网络,具有卷积层、池化层和全连接层等,可以有效提取图像中的特征。
本实验CNN模型构建方法:(1)卷积层:积核大小为3×3,输入通道为1,输出通道为64,采用ReLU激活函数;(2)池化层:用最大池化操作,池化窗口大小为2×2;(3)全连接层:入节点数为1024,输出节点为10,采用Softmax 激活函数。
三、模型训练本实验使用python的Keras库,并采用Adam作为优化器,学习率为0.001。
本实验使用训练集中的50,000图像训练模型,使用另外10,000图像作为测试集,训练次数为20次,每次训练500张图片。
四、结果分析本实验模型最终在测试集上的准确率达到99.32%,属于公认的良好水准。
从精度曲线图可以看出,模型的精度在训练的过程中持续上升,训练时间也在不断减少,说明模型越来越稳定,具有良好的泛化能力。
综上所述,本实验通过使用CNN模型,基于MNIST数据集,实现对手写数字的自动识别,达到了良好的效果。
本实验设计技术有助于提高手写数字识别技术的应用水平,为相关领域的研究提供了参考依据。
基于神经网络的联机手写识别系统研究与实现的开题报告一、选题背景及意义随着科技的不断提升,手写识别系统已经逐渐成为一个重要的应用领域。
传统的手写识别系统大多需要离线处理,对于实时性要求较高的场景,离线处理就不能满足需求了。
为了解决这个问题,近年来越来越多的研究在进行基于神经网络的联机手写识别系统。
基于神经网络的联机手写识别系统具有许多优点,如极高的准确度、自适应能力等。
并且其可以在实时处理的同时进行学习,使得系统的识别能力不断提升。
因此,本研究旨在研究和实现基于神经网络的联机手写识别系统,为未来的实时手写识别提供技术支持。
二、研究内容和方法1. 设计神经网络模型:本研究将以卷积神经网络(Convolutional Neural Network,CNN)作为基本模型,通过网络结构的设计和参数的调整,提高手写识别的准确度和速度。
2. 数据集的构建和处理:采用现有的手写体数字数据集进行训练和测试,同时,数据的预处理对于识别的准确度也非常重要,本研究将对数据进行标准化、归一化等处理。
3. 联机手写识别系统的实现:基于CNN模型,搭建联机手写识别系统,实现实时处理手写输入并将结果输出到屏幕或其他设备中。
4. 系统性能评估:本研究将通过识别准确度、运行速度和资源使用率等参数,对系统进行评估和分析。
三、预期成果1. 设计和实现一个基于神经网络的联机手写识别系统,实现对手写数字的实时识别并输出结果。
2. 对系统进行性能评估和分析,提出进一步优化的方式。
3. 给出研究中的经验和技术支持,为未来基于神经网络的实时手写识别提供参考。
四、研究难点和解决方案1. 神经网络模型的设计和训练:针对手写数字的特点,设计一个高效准确的神经网络模型是本研究的重点。
解决方案:通过尝试不同的网络结构和参数优化,找到最优的模型方案,提高识别准确度和速度。
2. 联机手写识别系统的实现和优化:实现实时处理手写输入的联机手写识别系统需要考虑系统的稳定性和资源利用率。
《基于深度学习的联机蒙古文手写识别系统研究》篇一一、引言随着信息技术的快速发展,手写识别技术已经成为一项重要的研究领域。
作为多元文化中的一部分,蒙古文手写识别系统的开发显得尤为重要。
联机手写识别技术,作为一种自然的输入方式,对于蒙古文这样的复杂文字体系具有很高的应用价值。
本文将介绍一种基于深度学习的联机蒙古文手写识别系统,通过分析其原理、方法及实验结果,展示其在实际应用中的优势。
二、蒙古文手写识别的背景与意义蒙古文作为一种具有独特书写风格的文字体系,其手写识别技术的研究具有重要的实际意义。
传统的蒙古文手写识别系统多采用传统的机器学习算法,随着深度学习技术的发展,这种传统的识别方式已逐渐被超越。
深度学习能够自动学习特征,有效地处理复杂的文字图像,提高蒙古文手写识别的准确率。
因此,基于深度学习的联机蒙古文手写识别系统的研究具有重要的理论意义和实际应用价值。
三、系统原理与方法本文提出的联机蒙古文手写识别系统主要基于深度学习技术,包括卷积神经网络(CNN)和循环神经网络(RNN)等。
系统通过捕捉用户的手写轨迹信息,结合深度学习算法进行文字识别。
具体步骤如下:1. 数据预处理:将用户的手写轨迹数据转化为图像数据,以便于深度学习算法进行处理。
2. 特征提取:利用CNN从图像中提取出有用的特征信息。
3. 序列建模:利用RNN对提取出的特征进行序列建模,以便于处理时序信息。
4. 文字识别:将建模后的序列信息输入到分类器中进行文字识别。
四、实验与结果分析为验证本文提出的联机蒙古文手写识别系统的有效性,我们进行了大量的实验。
实验数据集包括多种不同风格的蒙古文手写数据。
实验结果表明,本文提出的系统在准确率和效率上均表现出良好的性能。
具体来说,我们通过比较不同算法在相同数据集上的表现,发现基于深度学习的联机蒙古文手写识别系统在准确率上明显优于传统算法。
此外,我们还对系统的实时性能进行了评估,结果表明该系统具有良好的实时性,能够满足用户的需求。
基于移动平台的联机手写汉字识别的开题报告一、研究背景手写汉字识别技术是信息化时代非常重要的技术之一,随着移动互联网的快速发展,人们的需求越来越多地向着方便、快捷、易用等方向进行,移动平台逐渐成为人们进行日常生活和工作的主要方式,尤其是在我们日常的信息交流、学习、工作中,我们更多地使用手机和平板电脑等移动设备。
因此,基于移动平台的联机手写汉字识别技术的研究具有重要的实际应用价值。
二、研究目的和意义目前,市场上存在了一些手写汉字识别软件,但是其虽然多数都具有高精度和识别速度的优势,但是存在离线的局限性,同时因为需要与云端建立连接,传输数据的速度和质量也会受到很大的影响。
而基于移动平台的联机手写汉字识别技术可以解决这些问题,因此,本文旨在研究并开发一种基于移动平台的联机手写汉字识别技术。
该技术可以在用户使用移动设备时,通过手写输入设备进行输入,然后通过移动网络,将用户输入的手写汉字信息传送到远程的汉字识别服务器上,对输入的手写汉字信息进行识别处理,并将处理结果以文本或图片的形式发送回用户设备,使用户随时随地方便快捷地进行手写汉字输入和识别,具有很大的实用价值。
三、研究内容本文将从以下几个方面进行研究:1. 调研移动平台下的汉字手写识别技术,分析评估其特点和优劣势,总结现有技术的不足之处。
2. 设计和开发一个具有高精度和高实时性的基于移动平台的联机手写汉字识别系统,包括前端手写输入、中间数据传输、后台汉字识别等模块。
3. 通过大规模的实验和测试,对系统进行评估和分析,验证其稳定性、精确度和速度等方面的性能。
四、研究方法本研究将采用以下方法:1. 文献调研方法:对现有的基于移动平台的联机手写汉字识别系统相关文献进行综合、分析和总结,查找和了解该领域的最新进展。
2. 系统设计和开发方法:设计和开发一个实用、有效、高效的基于移动平台的联机手写汉字识别系统,考虑到移动设备的特点和实际应用场景,系统设计应该具有低功耗,体积小,容易使用等特点。
实验17 数字识别一、实验目的1.掌握OpenCV 识别手写数字的方法。
2.掌握AiCam 框架的部署和使用。
二、实验环境硬件环境:PC 机Pentium 处理器双核2GHz 以上,内存4GB 以上 操作系统:Windows7 64位及以上操作系统 开发软件:MobaXterm 实验器材:人工智能边缘应用平台实验配件:无三、实验内容1.算法原理1.1 基本描述 手写数字识别是深度学习入门的一个非常基础的实验,本实验利用OpenCV 方法调用手写数字识别模型,实现详细模型的推理过程,其中涉及数学形态学运算、图像灰度处理等基础算法,更为重要的是本实验中讲解如何构建训练集和有关深度学习的KNN 算法。
1.2 算法逻辑手写数字识别是依据深度学习训练KNN 模型实现的,识别之前是要进行KNN 模型训练,但是再本例的演示实验中已经训练好了模型,上图描述的是使用训练好的KNN 模型实现手写字算法分类的主要流程。
其中最核心的是灰度化、二值化、闭操作、获取轮廓特征点和进行提取特征。
详细的算法流程如下:二值化cv.threshold 原始图像 image 灰度化cv.cvtColor 闭操作cv.morphologyEx 获取轮廓特征点self.getContours 循环轮廓特征点 提取特征self.get_feature KNN 算法分类 画分类标签 画识别框2.功能设计2.1 功能描述AiCam 人工智能轻量化应用框架是一款面向于人工智能边缘应用的开发框架,采用统一模型调用、统一硬件接口、统一算法封装和统一应用模板的设计模式,实现了嵌入式边缘计算环境下进行快速的应用开发和项目实施。
AiCam 为模型算法的调用提供RESTful 调用接口,实时返回分析的视频结果和数据,同时通过物联网云平台的应用接口,实现与硬件的连接和互动,最终形成各色智联网产业应用。
AiCam 框架如下图所示:2.2 接口描述本实验的应用基于AiCam 框架开发,开发流程如下: 1)在AiCam 工程的配置文件添加摄像头(config\app.json )。
数字图像处理与识别实验报告实验题目:手写数字识别实验目的:使用神经网络图像识别方法对鼠标滑动输入的手写数字进行训练和识别,使计算机能够识别0~9十个数字。
了解机器学习和神经网络原理并且将其应用在图像处理识别中。
实验方法:基于反向传播(BP)神经网络方法BP拓扑网络结构:BP网络包含输入层、隐含层和输出层,每层包含了许多并行运算的神经元,层与层之间的神经元采用全互连方式,当样本输入网络后,各神经元的激励值由输入层经各隐含层向输出层传播。
然后计算目标输出与实际输出的误差,并按照误差减小的方向,从输出层逐层修正各连接权值,最后回到输入层,如此反复直到达到期望的输出。
这种信息的正向传递和误差的反向传播过程,就是BP网络每一层权值不断调整过程,也就相当于网络的学习过程。
它的实质是计算误差信号的最小值,采用的是梯度下降算法,按误差函数的负梯度方向修改权值。
本实验中可以将训练与测试同步结合起来,测试的过程中也在不断的学习。
本次实验采用的是神经网络中的监督式学习,也就是说外部环境有一个监督元。
它能为一组输入提供期望得到的输出,系统可以根据实际输出与目标输出的差值反馈给权重来调节权重的值,这一差值也就是误差信号。
在试验中,系统每次做出一个预测,会提问你预测的是否正确,若正确则不用对参数进行重新训练,若错误,则需要输入正确的值,系统对参数进行训练,这就是一个监督学习的方式。
基于BP神经网络的数字识别算法步骤为:a.初始化神经单元参数。
包括输入层、隐藏层和输出层节点数量,本次实验的输入层是400(20×20的灰度值),隐藏层是26,输出层是10,设置最大迭代次数为50.b.加载训练数据集。
将已经训练过的数字图像数据导入进来。
我输入的是一个20×20像素的手写数字图像,将其转化为灰度图,取400个像素值作为输入层的值。
实验中需要大量的训练数据,对神经网络中的参数进行训练。
本实验,下图为输入的黑白手写数字图像。
联机手写数字识别设计一、设计论述模式识别是六十年代初迅速发展起来的一门学科。
由于它研究的是如何用机器来实现人(及某些动物)对事物的学习、识别和判断能力,因而受到了很多科技领域研究人员的注意,成为人工智能研究的一个重要方面。
字符识别是模式识别的一个传统研究领域。
从50年代开始,许多的研究者就在这一研究领域开展了广泛的探索,并为模式识别的发展产生了积极的影响。
字符识别一般可以分为两类:1.联机字符识别;2.光学字符识别(Optical Chara- cter Recognition,OCR)或称离线字符识别。
在联机字符识别中,计算机能够通过与计算机相连的输入设备获得输入字符笔划的顺序、笔划的方向以及字符的形状,所以相对离线字符识别来说它更容易识别一些。
参照联机字符识别的原理,我们对手写数字的特征进行了深入的研究,同时作为一个初学者,我们本次考虑设计联机手写数字0——9识别,以达到加深对《模式识别》课程理论的了解和掌握的目的。
二、设计内容本次设计,我们使用Visual C++ 6.0软件,在《模式识别》课程理论基础上,运用VC++语言设计联机手写数字识别系统。
三、设计原理1、基于笔划及笔划特征分类的联机识别联机手写汉字识别的方法可以分为两类:基于整字识别方法和基于笔划识别的方法。
大多数联机识别都是采取笔划识别的方法,这是因为在联机识别过程中,汉字笔划是以点坐标形式一笔一划地输入到计算机的,同样,数字在联机输入过程中也是按照一笔一划输入的。
笔划的分类有很多,基于便于识别的原理,我们在这里仅介绍一种笔划的分类。
我们把汉字看成是由把构成所有汉字的笔划分为两大类:即单向笔划和变向笔划。
单向笔划表示笔划的走向保持在某一方向上,即人们通常所说的基本笔划,包括有横(笔划代码1)、竖(笔划代码2)、撇(笔划代码3)、捺(笔划代码4)。
变向笔划的一种分类,规定变向笔划由三种笔划组成:(1)顺笔划(笔划代码5):笔划的变向是按照顺时针规律变化的;(2)逆笔划(笔划代码6):笔划的变向是按照逆时针规律变化的;(3)混合笔划(笔划代码7):笔划的变向既有顺时针又有逆时针规律变化。
同样,这样的汉字分类也适用于对数字0——9的笔划特征分类,这样的分类有助于我们对数字0——9的特征提取,在本次设计中,我们就参照汉字的这一分类。
2、联机数字识别的原理框图四、设计过程 1、前处理1)手写数字输入在设计数字输入时,我们设计了一个画板做手写屏,运行程序时,我们在该画板上用鼠标输入0——9的数字。
2)笔划识别前的噪声处理由于在原始笔划点坐标数据中,有大量的冗余和噪声,必须对这些输入数据进行预处理以消除这些冗余和噪声。
处理的方法有很多,这里根据汉字的特点,把笔划走笔方向进行8方向编码,如下图所示,将坐标平面的360度分为8个区,按顺序编号为1、2、3、4、5、6、7、8。
原始数据的滤波处理分为两步:第一步是对原始点坐标的滤波;第二步是对由这些点坐标所计算出的方向码的滤波。
原始坐标数据的滤波(1)平滑滤波处理由于同一笔划中的相相邻点具有一定相关关系,不可能出现距离较大的相邻点,这里可以采用一种有限的平滑处理方法。
X XXt ptpt)1(αα-+= L L max min <∆<手写数字输入前处理模式表达(特征抽取)判别后处理识别结果输出Y Y Yt pt pt)1(αα-+=L Lmax min<∆<))()1(()1(22Y Y X X t p t t p t -+-=∆--噪声点为:L max >∆;冗余点为:L m in <∆。
其中,(Y X t t ,)是笔划在t 时刻的坐标,下标p 表示经过平滑后的数据,α是平滑系数,10≤≤α,α越大,平滑后两点相关性越大,反正α为0,不进行平滑处理。
Lmin和L max 是判别冗余点和噪声点的距离阈值。
(2)笔划方向码的确定根据输入点坐标,由下式产生笔划方向码: )/()()()(X X Y Y m t p pt m t p pt k ----=其中,k 是两点间的变化斜率,根据斜率来确定出相应的方向码;m 是在计算t 时刻的方向码时,所取的前第m 点坐标。
在实际中m 的选取,带有很大的技巧和直感,通常选取m=,即只在两相邻点上计算方向码,显然这不能克服抖动所带来的噪声,m 取得太大,容易造成方向的错判。
这里的m 值需要根据实际所用手写板的采样频率等确定。
方向码的滤波处理由于在实际书写过程中,输入的笔划并不标准,在方向码序列中,还含有大量的噪声和人为的错笔,这就需要对方向码进行滤波。
(1)笔划起始处和终止处的噪声人们的书写习惯容易在落笔和抬笔是引入噪声,一般消除同一笔划的前两个方向码和后两个方向码,能克服这种噪声。
(2)笔划平直处的噪声笔尖的抖动容易造成在一串相同的方向码中混有一个或两个不同的方向码,删除这个方向码,即可克服这种噪声。
(3)笔划变向处的噪声在笔划变相=向处容易引入噪声,出现一个或两个方向码与前后方向码不相同,删除它们来克服这种噪声。
(4)带笔噪声这基本上是人为的噪声,通过下面将介绍的笔划合并方法来消除这种噪声。
参照以上对笔划的噪声处理,在该程序中,数字是通过模拟手写板输入的,为了后面特征提取的方便,以及减少数据量,先做了一下下面的去除直角处理。
如上图所示,斜着的直线是笔迹经过的点,本来图中的三个黑点都应该在这条笔迹经过的路径上,但考虑到为了不使方向变来变去,对于该图这种处在拐角上的点我们都给剔除掉,剔除的条件的数学描述是:|x[I+2]-x[I]|=1且 |y[I+2]-y[I]|=1如果满足以上条件,则剔除点(x[I+1],y[I+1])。
//在输入过程中动态的去除直角点的代码实现如下:if((i!=oldpoint.x)||(j!=oldpoint.y)){int k,n;if(mytime<2){k=0;n=0; }else{k=(i-mypoint[mytime-2].x)*(i-mypoint[mytime-2].x);n=(j-mypoint[mytime-2].y)*(j-mypoint[mytime-2].y); }if((k==1)&&(n==1)){mypoint[mytime-1].x=i;mypoint[mytime-1].y=j;oldpoint=mypoint[mytime-1]; }//disable=1;else{mypoint[mytime].x=i;mypoint[mytime].y=j;oldpoint=mypoint[mytime];mytime++; }3)笔划方向码合并处理及笔划识别通过上述方法,根据原始坐标数据,获得了所需的笔划方向码,在确定7种笔划代码之前,还得再对笔划方向码进行合并处理。
由于不同的书写习惯,往往书写笔划时有些变异。
因此,对这些笔划方向码应作出合并处理。
处理原则是:首先对同一笔划中的方向码进行合并处理,得到两组数。
第一组数,代表输入笔划的方向码序列Mi(i=1,2,...,n),1≤Mi≤8,相邻方向Mi与Mi-1经合并后,不可能是同方向的码值,第二组数代表方向码序列Mi所对应的某方向上的方向码数Ni(i=1,2,...,n)。
然后再对方向码序列Mi进行合并处理,当|Mi+1-Mi|=1或|Mi+1-Mi|=7成立时,表示Mi与Mi-1是相邻的两个方向。
由于采用了上面所定义的七种笔划,可以对相邻两个方向合并为一方向,当两个方向的方向数之比Ni+1/Ni≤K时,Mi与Mi-1合并为Mi ;当Ni+1/Ni >K时,Mi与Mi-1合并为Mi-1 ;n'=n-1,其中方向数为:Nf'=(Nf+Ni+1)/2。
得到两组新数Mi',Ni',(i=1,2,...,n)。
式中K是合并阈值,可根据实际书写情况进行调整,一般K=1。
根据上述原则,可再对方向码序列Mi进行合并处理。
有了正确的笔划方向码序列Mi ,我们就能对笔划进行正确的分类,实线笔划识别,其识别过程如下:第一,判断方向码序列Mi的方向码数n是否为一,即是否是单方向的基本笔划,由右表可查出对应的笔画码。
第二,如果n>1,即是变方向的复合笔划,根据下式可以确定出顺笔画、逆笔划、混合比划。
如果-4≤Mi - Mi+1≤-1或4≤Mi - Mi+1≤7对于所有i=1,2,...,n成立,那么输入笔划顺笔划。
如果1≤Mi - Mi+1≤4或-7≤Mi - Mi+1≤-4对于所有i=1,2,...,n成立,那么输入笔划逆笔划。
其他情况,输入笔划是混合比划。
参照以上笔划方向码合并处理及笔划识别原理,在本次程序设计中,为了量化特征,我们规定了如下四个方向:向右、向下、向左、向上,各方向包含的范围如下图所示:之所以每个方向都包含3个范围,是为了避免一些小的方向扰动或抖动改变方向。
从上面四个图中,我们可以看到,在斜线上的4个方向,每个都包含在两个方向上,对于方向的确定,我们有如下的规则:(1)对于每一个起点,选择方向的优先顺序是:向右、向下、向左、向上。
这里我们这样规定的原因是:考虑手写数字的特点和人的书写习惯。
(2)如果已经处在一个方向上,那么对于接着的一个方向,应尽量保持和原来的方向一致,这样方向在一个小的范围内波动,可以尽最大可能保持方向的一致性,除非已经超出了这个方向的范围。
除做以上的规定外,我们还考虑了相邻点间的方向,分析出了如下表格的方第I个点的方向第I+1个点的方向符号表示根据表格中信息,设计了如下实现程序代码:if(mypoint[j+1].x>mypoint[j].x)mytezheng->VHDerection[i]=1;else if(mypoint[j+1].y>mypoint[j].y)mytezheng->VHDerection[i]=2;else if(mypoint[j+1].x<mypoint[j].x)mytezheng->VHDerection[i]=3;elsemytezheng->VHDerection[i]=4;mytezheng->lenth=1;//尽量保持目前的方向else{if(j==0){if(mypoint[1].x>mypoint[0].x)mytezheng->VHDerection[0]=1;else if(mypoint[1].y>mypoint[0].y)mytezheng->VHDerection[0]=2;else if(mypoint[1].x<mypoint[0].x)mytezheng->VHDerection[0]=3;elsemytezheng->VHDerection[0]=4;mytezheng->lenth=1;}//end ifelse{switch(mytezheng->VHDerection[i]){case 1:if(mypoint[j+1].x<=mypoint[j].x){i++;mytezheng->lenth=1;if(mypoint[j+1].y>mypoint[j].y)mytezheng->VHDerection[i]=2;else if(mypoint[j+1].y<mypoint[j].y)mytezheng->VHDerection[i]=4;elsemytezheng->VHDerection[i]=3;}elsemytezheng->lenth++;break;case 2:if(mypoint[j+1].y<=mypoint[j].y){i++;mytezheng->lenth=1;if(mypoint[j+1].x<mypoint[j].x)mytezheng->VHDerection[i]=3;else if(mypoint[j+1].x>mypoint[j].x)mytezheng->VHDerection[i]=1;elsemytezheng->VHDerection[i]=4;}elsemytezheng->lenth++;break;case 3:if(mypoint[j+1].x>=mypoint[j].x){i++;mytezheng->lenth=1;if(mypoint[j+1].y<mypoint[j].y)mytezheng->VHDerection[i]=4;else if(mypoint[j+1].y>mypoint[j].y)mytezheng->VHDerection[i]=2;elsemytezheng->VHDerection[i]=1;}elsemytezheng->lenth++;break;case 4:if(mypoint[j+1].y>=mypoint[j].y){i++;mytezheng->lenth=1;if(mypoint[j+1].x>mypoint[j].x)mytezheng->VHDerection[i]=1;else if(mypoint[j+1].x<mypoint[j].x)mytezheng->VHDerection[i]=3;elsemytezheng->VHDerection[i]=2;}elsemytezheng->lenth++;break;default:break;}//end switch}//end else}//end else}//end for4)特征抽取方向的特征抽取如3中笔划的方向处理,在得到方向序列后,我们还要计算几个特征,即节点的分支数、尾点距交点的距离、首点距交点的距离、首点和尾点的距离。