R语言案例_隐马尔科夫链模型
- 格式:pdf
- 大小:412.62 KB
- 文档页数:50

R语言隐马尔科夫模型HMM识别股市变化分析报告
了解不同的市场状况如何影响您的策略表现可能会对您的回报产生巨大的影响。
某些策略在波动剧烈的市场中表现良好,而其他策略则需要强劲而平稳的趋势,否则将面临长时间的下跌风险。
搞清楚什么时候开始或停止交易策略,调整风险和资金管理技巧,甚至设置进入和退出条件的参数都取决于市场制度或当前的情况。
能够识别不同的市场制度并相应地改变您的策略可能意味着市场成功和失败之间的差异。
在本文中,我们将探讨如何通过使用一种强大的机器学习算法来识别不同的市场机制,称为隐马尔可夫模型。
马尔科夫模型是一个概率过程,看当前的状态来预测下一个状态。
一个简单的例子就是看天气。
假设我们有三个天气条件(也称为国家”或政权):多雨,多云,阳光明媚。
如果今天下雨,马尔可夫模型寻找每个不同的天气情况发生的概率。
例如,明天可能继续下雨的概率较高,多云的可能性略低,晴天可能性较小。
交易申请非常清晰。
我们可以将市场定义为看涨,看跌或横盘整理,或者波动的高低,或者我们所知道的一些因素的综合影响我们的策略的表现,而不是天气条件。
构建真实数据模型
我们正在寻找基于这些因素的不同的市场制度,然后我们可以用它来优化我们的交易策略。
为此,我们将使用depmixS4 R库以及可追溯到年的EUR / USD首先,我们安装这些库并在R中构建我们的数据集
装载数据集(可以在这里下载),然后把它变成一个时间序列对象。
现在是时候建立隐马尔可夫模型了!
summary(HMMfit)
:。

马尔可夫链蒙特卡洛方法及其r实现马尔可夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)方法是一种统计推断方法,主要用于解决难以直接计算的问题。
它的基本思想是通过构造一个马尔可夫链,使其平稳分布为所要求解的分布,然后通过迭代这个马尔可夫链来得到所要求解的分布的样本。
在R语言中,我们可以使用`rstan`包来实现MCMC方法。
下面是一个简单的例子,说明如何使用MCMC方法来估计一个简单模型的参数。
首先,你需要安装和加载`rstan`包:```r("rstan")library(rstan)```然后,定义一个Stan模型。
这里我们使用一个简单的线性回归模型作为例子:model_code <- "data {int<lower=0> N; // number of data pointsvector[N] y; // response variablevector[N] x; // predictor variable};parameters {real mu; // mean of yreal beta; // slope of the regression line};model {y ~ normal(mu, 1); // normal distribution for ymu ~ normal(0, 1); // normal distribution for mu beta ~ normal(0, 1); // normal distribution for beta };"```接着,使用`stan`函数来拟合模型:Generate some fake dataN <- 100 number of data pointsx <- rnorm(N) predictor variabley <- 3x + rnorm(N) response variable with added noiseFit the model using MCMC methodfit <- stan(model_code, data = list(N = N, y = y, x = x))```最后,你可以使用`print`函数来查看模型拟合的结果:```rprint(fit)```这只是一个非常简单的例子。


Matlab统计学工具箱之(隐)马尔可夫模型:MarkovModels-Matlab此文讲述的内容在Matlab 7.0、7.5(R2007b)中均有——马尔可夫工具箱,主要内容如下。
简介:马尔可夫处理是随机处理的一个典型例子——此种处理根据特定的概率产生随机输出或状态序列。
马尔可夫处理的特别之处在于它的无记忆性——他的下一个状态仅依赖他的当前状态,不考虑导致他们的历史。
马尔可夫处理的模型在实际应用中使用非常广泛,从每日股票价格到染色体中的基因位置都有应用。
马尔可夫链马尔可夫模型用状态图可视化描述如下。
MarkovModel.jpg在图中,矩形代表你要描述的模型在处理中可能出现的状态,箭头描述了状态之间的转换。
每个箭头上的标签表明了该转换出现的概率。
在处理的每一步,模型都可能根据当前状态产生一种output或emission,然后做一个到另一状态的转换。
马尔可夫模型的一个重要特点是:他的下个状态仅仅依赖当前状态,而与导致其成为当前状态的历史变换无关。
马尔可夫链是马尔可夫模型的一组离散状态集合的数学描述形式。
马尔可夫链特征归纳如下:1. 一个状态的集合{1, 2, ..., M}2. 一个M * M的转移矩阵T,(i, j)位置的数据是从状态i转到状态j的概率。
T的每一行值的和必然是1,因为这是从一个给定状态转移到其他所有可能状态的概率之和。
3. 一个可能的输出(output)或发布(emissions)的集合{S1, S2, ..., SN}。
默认情况下,发布的集合是{1, 2, ..., N},这里N是可能的发布的个数,当然,你也可以选择一个不同的数字或符号的集合。
4. 一个M * N的发布矩阵E,(i, k)入口给出了从状态i得到发布的标志Sk的概率。
马尔可夫链在第0步,从一个初始状态i0开始。
接着,此链按照T(1, i1)概率转移到状态i1,且按概率E(i1, k1)概率发布一个输出S(k1)。


隐马尔可夫模型维基百科,自由的百科全书跳转到:导航, 搜索隐马尔可夫模型状态变迁图(例子)x—隐含状态y—可观察的输出a—转换概率(transition probabilities)b—输出概率(output probabilities)隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
其难点是从可观察的参数中确定该过程的隐含参数。
然后利用这些参数来作进一步的分析,例如模式识别。
在正常的马尔可夫模型中,状态对于观察者来说是直接可见的。
这样状态的转换概率便是全部的参数。
而在隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量则是可见的。
每一个状态在可能输出的符号上都有一概率分布。
因此输出符号的序列能够透露出状态序列的一些信息。
目录[隐藏]∙ 1 马尔可夫模型的演化∙ 2 使用隐马尔可夫模型o 2.1 具体实例o 2.2 隐马尔可夫模型的应用∙ 3 历史∙ 4 参见∙ 5 注解∙ 6 参考书目∙7 外部连接[编辑]马尔可夫模型的演化上边的图示强调了HMM的状态变迁。
有时,明确的表示出模型的演化也是有用的,我们用x(t1)与x(t2)来表达不同时刻t1和t2的状态。
在这个图中,每一个时间块(x(t), y(t))都可以向前或向后延伸。
通常,时间的起点被设置为t=0 或t=1.另外,最近的一些方法使用Junction tree算法来解决这三个问题。
[编辑]具体实例假设你有一个住得很远的朋友,他每天跟你打电话告诉你他那天作了什么.你的朋友仅仅对三种活动感兴趣:公园散步,购物以及清理房间.他选择做什么事情只凭天气.你对于他所住的地方的天气情况并不了解,但是你知道总的趋势.在他告诉你每天所做的事情基础上,你想要猜测他所在地的天气情况.你认为天气的运行就像一个马尔可夫链.其有两个状态 "雨"和"晴",但是你无法直接观察它们,也就是说,它们对于你是隐藏的.每天,你的朋友有一定的概率进行下列活动:"散步", "购物", 或 "清理".因为你朋友告诉你他的活动,所以这些活动就是你的观察数据.这整个系统就是一个隐马尔可夫模型HMM.你知道这个地区的总的天气趋势,并且平时知道你朋友会做的事情.也就是说这个隐马尔可夫模型的参数是已知的.你可以用程序语言(Python)写下来:states = ('Rainy', 'Sunny')observations = ('walk', 'shop', 'clean')start_probability = {'Rainy': 0.6, 'Sunny': 0.4}transition_probability = {'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},}emission_probability = {'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},}在这些代码中,start_probability代表了你对于你朋友第一次给你打电话时的天气情况的不确定性(你知道的只是那个地方平均起来下雨多些).在这里,这个特定的概率分布并非平衡的,平衡概率应该接近(在给定变迁概率的情况下){'Rainy': 0.571, 'Sunny': 0.429}< transition_probability表示基于马尔可夫链模型的天气变迁,在这个例子中,如果今天下雨,那么明天天晴的概率只有30%.代码emission_probability表示了你朋友每天作某件事的概率.如果下雨,有 50% 的概率他在清理房间;如果天晴,则有60%的概率他在外头散步.这个例子在Viterbi算法页上有更多的解释。

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogR语言使用马尔可夫链Markov Chain, MC来模拟抵押违约数据分析报告来源:大数据部落| 有问题百度一下“”就可以了原文/?p=3603这篇文章的目的是将我学习的材料与我的日常工作和R相结合。
如果我们有一些根据固定概率随时间在状态之间切换的对象,我们可以使用马尔可夫链 * 来模拟该对象的长期行为。
一个很好的例子是抵押贷款。
在任何给定的时间点,贷款都有违约概率,保持最新付款或全额偿还。
总的来说,我们将这些称为“转移概率”。
假设这些概率在贷款期限内是固定的**。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog举个例子,我们将看一下传统的固定利率30年期抵押贷款。
让我们假设每个当前贷款的时间T有75%的可能性保持最新,10%的违约机会,15%的机会在T + 1时间内获得回报。
这些转换概率在上图中列出。
显然,一旦贷款违约或获得偿还,它将保持默认或支付。
我们称这些国家为“吸收国家”。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog由于我们知道转移概率,我们所需要的只是贷款的初始分配,我们可以预测在30年期间任何给定点的每个州的贷款百分比。
假设我们从T = 0开始,有100个当前贷款,0个违约和已付清贷款。
在时间T + 1,我们知道(根据我们的转换概率),这100个中的75个将保持最新的付款。
但是,15笔贷款将被清偿,10笔贷款将被违约。
由于我们假设转移概率在贷款期限内是不变的,我们可以用它们来查找当前贷款的时间t = 2。
在目前T + 1的75笔贷款中,56.25笔贷款将保持在T + 2(75 * .75 = 56.25)。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog如果我们重复这个过程28次(在代码中完成)并绘制点,我们得到上面绘制的时间序列。

隐马尔科夫模型在心理学研究中的应用案例引言隐马尔科夫模型是一种常用的概率统计模型,它在语音识别、自然语言处理、生物信息学等领域得到了广泛的应用。
然而,隐马尔科夫模型在心理学研究中的应用也日益受到重视。
本文将介绍隐马尔科夫模型在心理学研究中的应用案例,并探讨其在心理学研究中的潜在价值。
隐马尔科夫模型简介隐马尔科夫模型是一种描述动态系统的概率模型,它包含两个随机过程:一个隐含的马尔科夫链和一个观测序列。
马尔科夫链用来描述系统的状态演化,而观测序列则是通过状态序列生成的可观测数据。
隐马尔科夫模型能够通过观测序列推断系统的状态序列,从而对系统的动态特性进行建模和预测。
隐马尔科夫模型在心理学研究中的应用案例1. 情绪识别情绪是心理学研究的重要课题之一,而隐马尔科夫模型可以用来识别和分析情绪的动态变化。
研究人员可以将情绪状态看作系统的隐含状态,而面部表情、语言特征等可观测数据则构成了观测序列。
通过对观测序列的分析,可以推断出个体的情绪状态序列,从而深入理解情绪的变化规律。
2. 认知行为建模隐马尔科夫模型还可以用来建模个体的认知行为过程。
研究人员可以将认知状态看作系统的隐含状态,而行为数据则构成了观测序列。
通过对观测序列的分析,可以推断出个体的认知状态序列,从而揭示认知行为的内在机制。
3. 精神疾病诊断隐马尔科夫模型还可以用来帮助精神疾病的诊断和分类。
研究人员可以将精神疾病的症状看作系统的隐含状态,而患者的言行举止构成了观测序列。
通过对观测序列的分析,可以推断出患者的病情状态序列,从而为临床医生提供精准的诊断依据。
隐马尔科夫模型在心理学研究中的潜在价值隐马尔科夫模型在心理学研究中的应用为心理学领域提供了新的研究方法和工具。
通过对观测序列的分析,隐马尔科夫模型能够揭示系统的隐含动态变化,从而为心理学研究提供了更加深入和全面的理解。
隐马尔科夫模型还可以帮助心理学研究人员揭示认知、情绪、精神疾病等方面的内在机制,为临床医生提供精准的诊断和治疗依据,对推动心理学领域的发展具有重要意义。


隐马尔可夫模型实例什么是隐马尔可夫模型?隐马尔可夫模型(Hidden Markov Model,HMM)是一种用于建模序列数据的概率图模型。
它在很多领域有着广泛的应用,例如语音识别、自然语言处理、生物信息学等。
隐马尔可夫模型能够描述一个系统在不同状态之间的转移以及每个状态下观测到不同的符号的概率。
隐马尔可夫模型由两个主要部分组成:状态序列和观测序列。
其中,状态序列是隐藏的,而观测序列是可见的。
状态序列和观测序列之间存在一个转移矩阵,描述了从一个状态转移到另一个状态的概率。
同时,每个状态对应着一个观测符号的概率分布。
隐马尔可夫模型的基本原理隐马尔可夫模型基于马尔可夫过程,认为当前状态只与前一个状态有关,与更早的状态无关。
模型假设当系统处于某个状态时,观测到的符号仅与该状态有关,与其他状态无关。
隐马尔可夫模型的核心思想是使用观测符号序列来推断状态序列。
通过观测到的符号序列,我们可以估计最可能的状态序列,以及观测到的符号是由哪个状态生成的概率。
模型中的参数包括初始状态分布、状态转移矩阵和观测符号概率分布。
通过这些参数,可以使用前向算法、后向算法和维特比算法等方法来进行模型的训练和推断。
隐马尔可夫模型的实例应用语音识别隐马尔可夫模型在语音识别中有着重要应用。
语音信号可以被看作是一个连续的观测序列,隐藏的状态序列表示语音的词语或音素序列。
通过训练隐马尔可夫模型,可以建立声学模型和语言模型,实现对语音信号的识别。
自然语言处理在自然语言处理领域,隐马尔可夫模型可以用于词性标注、命名实体识别等任务。
通过将不同词性或实体类别作为状态,将观测到的词语序列作为观测序列,可以建立一个标注模型,用于对文本进行标注。
生物信息学隐马尔可夫模型在生物信息学中也有广泛应用。
例如,在基因识别中,DNA序列可以看作是一个观测序列,而相应的蛋白质编码区域可以看作是一个隐藏的状态序列。
通过训练模型,可以对DNA序列进行分析和识别。
隐马尔可夫模型的训练与推断隐马尔可夫模型的训练可以通过监督学习和非监督学习两种方法进行。
R语言中实现马尔可夫链蒙特卡罗MCMC模型原文链接:/?p=2687什么是MCMC,什么时候使用它?MCMC只是一个从分布抽样的算法。
这只是众多算法之一。
这个术语代表“马尔可夫链蒙特卡洛”,因为它是一种使用“马尔可夫链”(我们将在后面讨论)的“蒙特卡罗”(即随机)方法。
MCMC只是蒙特卡洛方法的一种,尽管可以将许多其他常用方法看作是MCMC的简单特例。
正如上面的段落所示,这个话题有一个引导问题,我们会慢慢解决。
我为什么要从分配中抽样?你可能没有意识到你想(实际上,你可能并不想)。
但是,从分布中抽取样本是解决一些问题的最简单的方法。
可能MCMC最常用的方法是从贝叶斯推理中的某个模型的后验概率分布中抽取样本。
通过这些样本,你可以问一些问题:“参数的平均值和可信度是多少?”。
如果这些样本是来自分布的独立样本,则估计均值将会收敛在真实均值上。
假设我们的目标分布是一个具有均值m和标准差的正态分布s。
显然,这种分布的意思是m,但我们试图通过从分布中抽取样本来展示。
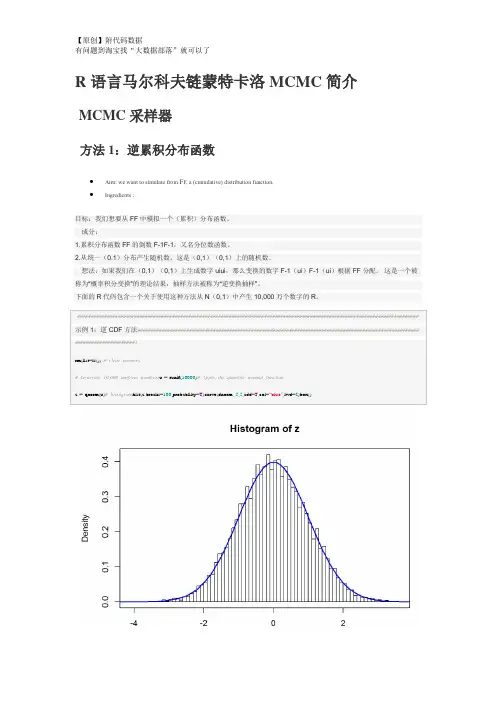
作为一个例子,考虑用均值m和标准偏差s来估计正态分布的均值(在这里,我将使用对应于标准正态分布的参数):我们可以很容易地使用这个rnorm 函数从这个分布中抽样•seasamples<-rn 000,m,s)样本的平均值非常接近真实平均值(零):•••••mean(sa es)## [1] -0. 537事实上,在这种情况下,$ n $样本估计的预期方差是$ 1 / n $,所以我们预计大部分值在$••••••\ pm 2 \,/ \ sqrt {n} = 0.02 $ 10000分的真实意思。
summary(re 0,mean(rnorm(10000,m,s))))## Min. 1st Qu. Median Mean 3rd Qu. Max. ## -0.03250 -0.00580 0.00046 0.00042 0.00673 0.03550这个函数计算累积平均值(即元素$ k $,元素$ 1,2,\ ldots,k $除以$ k $)之和。
以下是一个简单的马尔可夫模型的R语言代码示例,用于计算给定状态转移矩阵的稳态概率分布:
```r
# 定义状态转移矩阵
transition_matrix <- matrix(c(0.9, 0.1, 0.5, 0.5), nrow = 2)
# 计算稳态概率分布
steady_state <-eigen(transition_matrix)$vectors[, 1] / sum(eigen(transition_matrix)$vectors[, 1])
# 输出稳态概率分布
print(steady_state)
```
在这个例子中,我们定义了一个2x2的状态转移矩阵,其中第一行表示状态1的转移概率,第二行表示状态2的转移概率。
然后,我们使用R语言的eigen函数计算状态转移矩阵的特征值和特征向量,并取第一个特征向量作为稳态概率分布。
最后,我们将稳态概率分布输出到控制台。
请注意,这只是一个简单的示例,实际的马尔可夫模型可能更加复杂。
根据具体问题,您可能需要调整状态转移矩阵的大小和形状,以及计算稳态概率分布的方法。
R语言隐马尔科夫模型(HMM)模型股指预测代码了解不同的股市状况,改变交易策略,对股市收益有很大的影响。
有些策略在波澜不惊的股市中表现良好,而有些策略可能适合强劲增长或长期下跌的情况。
弄清楚何时开始或合适止损,调整风险和资金管理技巧,都取决于股市的当前状况。
在本文中,我们将通过使用一类强大的机器学习算法“隐马尔可夫模型”(HMM)来探索如何识别不同的股市状况。
▍隐马尔可夫模型马尔科夫模型是一个概率过程,查看当前状态来预测下一个状态。
一个简单的例子就是看天气。
假设我们有三种天气情况:下雨、多云、阳光明媚。
如果今天下雨,马尔科夫模型就会寻找每种不同天气的概率。
例如,明天可能会持续下雨的可能性较高,变得多云的可能性略低,而会变得晴朗的几率很小。
▍构建模型基于以上背景,然后我们可以用来找到不同的股市状况优化我们的交易策略。
我们使用2004年至今的上证指数(000001.ss)来构建模型。
首先,我们得到上证指数的收盘价数据,计算得到收益率数据,并建立HMM模型比较模型的预测结果。
library(depmixS4)library(TTR)library(ggplot2)library(reshape2)library(plotly)# create the returns stream from thisshdata<-getSymbols( "000001.ss", from="2004-01-01",auto.assign=F )gspcRets = diff( log( Cl( shdata ) ) )returns = as.numeric(gspcRets)write.csv(as.data.frame(gspcRets),"gspcRets.csv")shdata=na.omit(shdata)df <- data.frame(Date=index(shdata),coredata(shdata))p <- df %>%plot_ly(x = ~Date, type="candlestick",open = ~X000001.SS.Open, close = ~X000001.SS.Close,high = ~X000001.SS.High, low = ~X000001.SS.Low, name = "000001.SS",increasing = i, decreasing = d) %>%add_lines(y = ~up , name = "B Bands",line = list(color = '#ccc', width = 0.5),legendgroup = "Bollinger Bands",hoverinfo = "none") %>%add_lines(y = ~dn, name = "B Bands",line = list(color = '#ccc', width = 0.5),legendgroup = "Bollinger Bands",showlegend = FALSE, hoverinfo = "none") %>%add_lines(y = ~mavg, name = "Mv Avg",line = list(color = '#E377C2', width = 0.5),hoverinfo = "none") %>%layout(yaxis = list(title = "Price"))绘制上证指数的收盘价和收益率数据,我们看到2004年和2017年期间股市的波动情况。