C语言一维数组
- 格式:ppt
- 大小:301.00 KB
- 文档页数:16


c语言一维数组矩阵相乘下面是一个在C语言中实现一维数组矩阵相乘的示例代码:```c#include <stdio.h>#define ROWS_A 2#define COLS_A 3#define ROWS_B 3#define COLS_B 2void multiplyMatrix(const int* A, const int* B, int* C, int rowsA, int colsA, int colsB) {for (int i = 0; i < rowsA; i++) {for (int j = 0; j < colsB; j++) {C[i * colsB + j] = 0; // 初始化结果矩阵Cfor (int k = 0; k < colsA; k++) {C[i * colsB + j] += A[i * colsA + k] * B[k * colsB + j]; }}}}int main() {int A[ROWS_A][COLS_A] = {{1, 2, 3}, {4, 5, 6}};int B[ROWS_B][COLS_B] = {{1, 2}, {3, 4}, {5, 6}};int C[ROWS_A][COLS_B];multiplyMatrix((int*)A, (int*)B, (int*)C, ROWS_A, COLS_A,COLS_B);printf("Result:\n");for (int i = 0; i < ROWS_A; i++) {for (int j = 0; j < COLS_B; j++) {printf("%d ", C[i][j]);}printf("\n");}return 0;}```该代码中,我们首先定义了两个要相乘的矩阵A和B,然后定义了结果矩阵C。


c语言3维数组转化为一维数组类型下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!从三维数组到一维数组:C 语言中的数据结构转化在C 语言中,数组是一种常见的数据结构,它可以存储多个相同类型的数据元素。


c语言一维大数组连续寻址和随机寻址一维大数组是指只有一个维度的数组,也就是只有一个索引来访问数组元素的数据结构。
在C语言中,一维大数组可以通过连续寻址和随机寻址两种方式来访问和操作数组元素。
连续寻址是指通过数组的起始地址和偏移量来计算出要访问的数组元素的地址。
在内存中,数组元素是连续存储的,每个元素占据相同的字节大小。
通过起始地址和偏移量的计算,我们可以直接计算出要访问的数组元素的地址,从而实现连续寻址。
这种方式的优点是访问速度快,因为计算地址的过程简单,不需要额外的访问操作。
然而,连续寻址的缺点是数组的大小必须在编译时确定,并且不能动态改变数组的大小。
随机寻址是指通过数组的起始地址和索引来计算出要访问的数组元素的地址。
在内存中,数组元素的地址是根据索引和起始地址进行计算的。
通过起始地址和索引的计算,我们可以定位到要访问的数组元素的地址,从而实现随机寻址。
这种方式的优点是数组的大小可以在运行时确定,并且可以动态改变数组的大小。
然而,随机寻址的缺点是访问速度相对较慢,因为需要进行额外的访问操作来计算地址。
在C语言中,我们可以使用下标运算符"[]"来访问和操作一维大数组。
通过指定数组的索引,我们可以直接访问数组中的元素。
例如,对于一个一维大数组a,我们可以使用a[i]来访问第i个元素。
当使用连续寻址方式时,计算数组元素的地址是简单的,只需要使用起始地址加上偏移量即可。
当使用随机寻址方式时,计算数组元素的地址需要使用起始地址加上索引乘以元素的大小来计算。
一维大数组的连续寻址和随机寻址方式在不同的场景中有不同的应用。
连续寻址方式适用于数组大小已知且不会改变的情况,例如静态数组或者全局数组。
由于连续寻址方式的访问速度快,适合对数组进行频繁的访问操作。
而随机寻址方式适用于数组大小不确定或者需要动态改变的情况,例如动态数组或者堆上的数组。
由于随机寻址方式的访问速度相对较慢,适合对数组进行较少的访问操作。



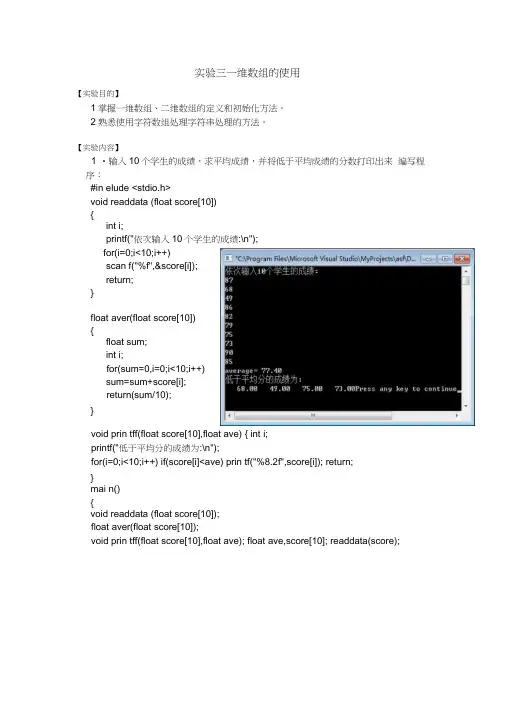
实验三一维数组的使用【实验目的】1掌握一维数组、二维数组的定义和初始化方法。
2熟悉使用字符数组处理字符串处理的方法。
【实验内容】1 •输入10个学生的成绩,求平均成绩,并将低于平均成绩的分数打印出来编写程序:#in elude <stdio.h>void readdata (float score[10]){int i;printf("依次输入10个学生的成绩:\n");for(i=0;i<10;i++)scan f("%f",&score[i]);return;}float aver(float score[10]){float sum;int i;for(sum=0,i=0;i<10;i++)sum=sum+score[i];return(sum/10);}void prin tff(float score[10],float ave) { int i;printf("低于平均分的成绩为:\n");for(i=0;i<10;i++) if(score[i]<ave) prin tf("%8.2f",score[i]); return;}mai n(){void readdata (float score[10]);float aver(float score[10]);void prin tff(float score[10],float ave); float ave,score[10]; readdata(score);ave=aver(score);prin tf("average=%6.2f\n",ave);prin tff(score,ave);}2、将一个数组中的值按逆序重新存放。
例如,原来顺序为8, 6, 5, 4, 1。
要求改为1,4, 5, 6, 8<编写程序:#include viostream.h>int main(){int i,j,a[5]={8,6,5,4,1},b[5];for(i=0,j=4;iv5,j>=0;i++,j--)b[j]=a[i];for(i=0;i<5;i++)a[i]=b[i];for(i=0;i<5;i++)coutv<a[i]vv"\t";}3、应用一维数组,对10个从键盘输入的数进行冒泡排序,使其按照从大到小的顺序输出。