数学建模实验四:Matlab神经网络以及应用于汽油辛烷值预测
- 格式:docx
- 大小:566.39 KB
- 文档页数:36

1 汽油调合汽油生产可分为汽油组分生产和汽油调合两个阶段。
汽油调合是一个复杂同时又蕴藏着巨大利润空间的工业过程[1]。
汽油调合是用几种组分油按一定的比例混合,使混合后的成品油符合牌号的质量指标要求。
组分油包括催化裂化汽油、重整汽油、加氢裂化汽油、甲基叔丁基醚(MTBE)、烷基化油等。
不同的组分油有不同的性质,生产成本也不同,不同牌号的成品油有不同的指标要求,销售价格也不同。
汽油调合是一个典型的优化问题,优化的目标是收益最大,辛烷值(RON)是关键的质量指标,其准确性对汽油调合优化具有重要意义[2]。
有的企业为保证成品汽油出厂合格,成品油RON明显比内控指标偏高,即RON存在质量过剩问题,每富裕1个单位RON损失效益约130元/吨[3]。
建立调合RON预测模型是汽油调合关键环节,由组分油RON预测成品油RON,模型越精确预测的结果越准确,使成品油RON既保证质量指标又无质量过剩。
2 RON模型文献汽油调合RON是一种典型的非线性函数,参与调合的各组分油之间存在着复杂的调合效应,成品油的RON不等于组分油质量分数乘以对应RON的线性加和,这使得对成品油调合的RON预测变得十分困难。
关于调合RON模型,国内外已有许多学者通过大量的研究提出了各种各样的模型形式。
A.H.Zahed[5]等根据已有的试验数据,利用回归分析方法提出一个预测汽油调合RON的数学模型,此模型预测的RON与实测值的平均偏差为0.54%,复相关系数为0.973。
王中平[4]用锦州石化公司组分油数据,对A.H.Zahed模型进行回归分析,建立汽油调合RON 模型。
结果表明预测精度较高,RON平均偏差为0.324%,能很好的预测汽油调合的RON。
Twu和Coon[6]提出的RON模型,在157种组分油的161次汽油调合测试中,该模型预测研究法RON 的平均偏差为1.00%,马达法辛烷值(MON)为1.19%。
3 RON模型的建立和求解3.1 建立模型汽油调合RON是组分油RON和组分油质量分数的非线性函数,可以表示为:R TH=f(R ZF,x ZF)。

实验三Matlab神经网络以及应用于汽油辛烷值预测一、实验目的1. 掌握MATLAB创建BP神经网络并应用于拟合非线性函数2. 掌握MATLAB创建REF神经网络并应用于拟合非线性函数3. 掌握MATLAB创建BP神经网络和REF神经网络解决实际问题4. 了解MATLAB神经网络并行运算二、实验原理2.1 BP神经网络2.1.1 BP神经网络概述BP神经网络Rumelhard和McClelland于1986年提出。
从结构上将,它是一种典型的多层前向型神经网络,具有一个输入层、一个或多个隐含层和一个输出层。
层与层之间采用权连接的方式,同一层的神经元之间不存在相互连接。
理论上已经证明,具有一个隐含层的三层网络可以逼近任意非线性函数。
隐含层中的神经元多采用S型传递函数,输出层的神经元多采用线性传递函数。
图1所示为一个典型的BP神经网络。
该网络具有一个隐含层,输入层神经元数据为R,隐含层神经元数目为S1,输出层神经元数据为S2,隐含层采用S型传递函数tansig,输出层传递函数为purelin。
图1含一个隐含层的BP网络结构2.1.2 BP神经网络学习规则BP网络是一种多层前馈神经网络,其神经元的传递函数为S型函数,因此输出量为0到1之间的连续量,它可以实现从输入到输出的任意的非线性映射。
由于其权值的调整是利用实际输出与期望输出之差,对网络的各层连接权由后向前逐层进行校正的计算方法,故而称为反向传播(Back-Propogation)学习算法,简称为BP算法。
BP算法主要是利用输入、输出样本集进行相应训练,使网络达到给定的输入输出映射函数关系。
算法常分为两个阶段:第一阶段(正向计算过程)由样本选取信息从输入层经隐含层逐层计算各单元的输出值;第二阶段(误差反向传播过程)由输出层计算误差并逐层向前算出隐含层各单元的误差,并以此修正前一层权值。
BP网络的学习过程主要由以下四部分组成:1)输入样本顺传播输入样本传播也就是样本由输入层经中间层向输出层传播计算。

汽油辛烷值神经网络预测模型的设计
秦秀娟;陈宗海
【期刊名称】《控制与决策》
【年(卷),期】1999(14)2
【摘要】针对催化重整工艺仿真数学模型中遇到的汽油辛烷值预测方面的困难,
提出一种将定量计算与神经网络计算相结合的催化重整工艺汽油辛烷值的预测模型。
此预测模型综合考虑了反应器温度。
【总页数】5页(P151-155)
【关键词】汽油;辛烷值;神经网络;预测模型;设计
【作者】秦秀娟;陈宗海
【作者单位】中国科学技术大学自动化系
【正文语种】中文
【中图分类】TE626.21
【相关文献】
1.汽油精制过程中的辛烷值损失预测模型 [J], 杜明洋;张甜甜;薄其高;许文文
2.基于BP神经网络对汽油辛烷值损失预测模型的构建 [J], 王宁宁
3.基于BP神经网络对汽油辛烷值损失预测模型的构建 [J], 王宁宁
4.基于改进PCA-RFR算法的汽油辛烷值损失预测模型的构建与分析 [J], 蒋伟;佟
国香
5.基于汽油催化裂化过程实时数据的辛烷值损失预测模型 [J], 韩庆珏;邹敏;霍皓灵
因版权原因,仅展示原文概要,查看原文内容请购买。
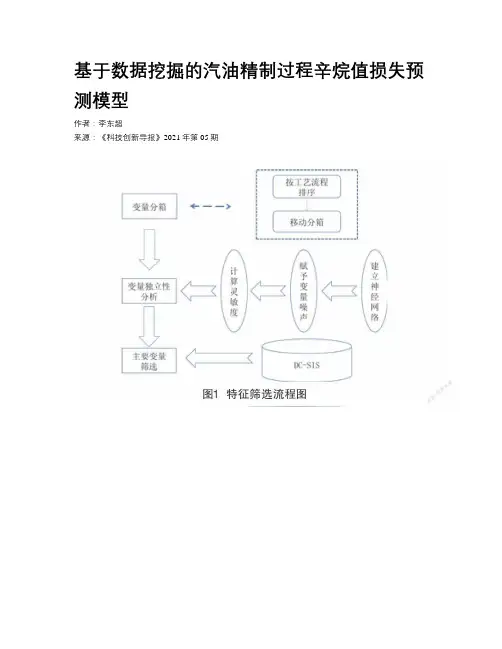
基于数据挖掘的汽油精制过程辛烷值损失预测模型作者:***来源:《科技创新导报》2021年第05期摘要:汽油精制过程中造成的辛烷值损失会降低汽油的燃烧效率,如何降低汽油精制过程中辛烷值的损失量是目前相关企业面临的一个重要课题。
本文利用我国某石化企业在催化裂化汽油精制过程中积累的数据,建立基于神经网络、测量误差模型以及DC-SIS数据降维方法的两阶段特征筛选模型,选择出对辛烷值影响比较大的因素。
设计了一种基于XGBoost和神经网络的辛烷值预测模型,可以实现对不同原材料和不同操作下精制后辛烷值的预测,经验证,模型的均方误差为0.06876,所设计模型在处理辛烷值预测问题时可以达到比较好的预测效果。
关键词:辛烷值高维降维测量误差模型神经网络 XGBoost中图分类号:TP274 文獻标识码:A 文章编号:1674-098X(2021)02(b)-0092-05Prediction Model of Octane Number Loss in Gasoline Refining Process Based on Data Mining LI Dongchao(School of Mathematics and Statistics, Nanjing University of Information Science & Technology, Nanjing, Jiangsu Province, 210044 China)Abstract: The loss of octane number in the process of gasoline refining will reduce the combustion efficiency of gasoline. How to reduce the loss of octane number in the process of gasoline refining is an important issue facing related enterprises. This paper uses the data accumulated by a petrochemical enterprise during the refining process of catalytic cracking gasoline to establish a two-stage feature screening model based on neural network, measurement error model and DC-SIS data dimensionality reduction method, and select the one that has a greater impact on the octane number factor. An octane number prediction model based on XGBoost and neural network is designed,which can predict the octane number after refining under different raw materials and different operations. After verification, the mean square error of the model is 0.06876. A better prediction effect can be achieved in the alkane number prediction problem.Key Words: Octane number; High dimensionality reduction; Neural networks; XGBoost汽油是小型车辆的主要燃料,汽油燃烧产生的尾气排放对大气环境有重要影响。

实验四:Matlab 神经网络以及应用于汽油辛烷值预测专业年级: 2014级信息与计算科学1班姓名: 黄志锐 学号:201430120110一、实验目的1. 掌握MATLAB 创建BP 神经网络并应用于拟合非线性函数2. 掌握MATLAB 创建REF 神经网络并应用于拟合非线性函数3. 掌握MATLAB 创建BP 神经网络和REF 神经网络解决实际问题4. 了解MATLAB 神经网络并行运算二、实验内容1. 建立BP 神经网络拟合非线性函数2212y x x =+第一步 数据选择和归一化根据非线性函数方程随机得到该函数的2000组数据,将数据存贮在data.mat 文件中(下载后拷贝到Matlab 当前目录),其中input 是函数输入数据,output 是函数输出数据。
从输入输出数据中随机选取1900中数据作为网络训练数据,100组作为网络测试数据,并对数据进行归一化处理。
第二步 建立和训练BP 神经网络构建BP 神经网络,用训练数据训练,使网络对非线性函数输出具有预测能力。
第三步 BP 神经网络预测用训练好的BP 神经网络预测非线性函数输出。
第四步 结果分析通过BP 神经网络预测输出和期望输出分析BP 神经网络的拟合能力。
详细MATLAB代码如下:27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54disp(['神经网络的训练时间为', num2str(t1), '秒']);%% BP网络预测% 预测数据归一化inputn_test = mapminmax('apply', input_test, inputps); % 网络预测输出an = sim(net, inputn_test);% 网络输出反归一化BPoutput = mapminmax('reverse', an, outputps);%% 结果分析figure(1);plot(BPoutput, ':og');hold on;plot(output_test, '-*');legend('预测输出', '期望输出');title('BP网络预测输出', 'fontsize', 12);ylabel('函数输出', 'fontsize', 12);xlabel('样本', 'fontsize', 12);% 预测误差error = BPoutput-output_test;figure(2);plot(error, '-*');title('BP神经网络预测误差', 'fontsize', 12);ylabel('误差', 'fontsize', 12);xlabel('样本', 'fontsize', 12);figure(3);plot((output_test-BPoutput)./BPoutput, '-*');title('BP神经网络预测误差百分比');errorsum = sum(abs(error));MATLAB代码运行结果截图如下所示:MATLAB代码运行结果如下所示:图1 BP神经网络预测输出图示图2 BP神经网络预测误差图示图3 BP 神经网络预测误差百分比图示2. 建立RBF 神经网络拟合非线性函数22112220+10cos(2)10cos(2)y x x x x ππ=-+-第一步 建立exact RBF 神经网络拟合, 观察拟合效果详细MATLAB 代码如下:MATLAB代码运行结果如下所示:图4 RBF神经网络拟合效果图第二步建立approximate RBF神经网络拟合详细MATLAB代码如下:13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41F = 20+x1.^2-10*cos(2*pi*x1)+x2.^2-10*cos(2*pi*x2); %% 建立RBF神经网络% 采用approximate RBF神经网络。


应用BP神经网络的二次反应清洁汽油辛烷值预测
周小伟;袁俊;杨伯伦
【期刊名称】《西安交通大学学报》
【年(卷),期】2010(044)012
【摘要】借鉴复杂反应动力学研究中的集总方法,将汽油辛烷值看成汽油链烷烃集总、环烷烃集总、芳烃集总、烯烃集总的函数.采用多元线性回归和BP神经网络算法,分别建立了二次反应清洁汽油的研究法辛烷值预测模型,并进行了实例计算验证和对比分析.结果表明,BP神经网络模型的整体性能优于多元线性回归模型,其强大的非线性映射能力能够更好地反映汽油研究法辛烷值与各集总组分之间的复杂关系,且具有更好的预测性能,模型预测值与实验测得的汽油辛烷值的平均相对误差为0.39%,与文献报道的汽油辛烷值的平均相对误差为0.92%.
【总页数】5页(P82-86)
【作者】周小伟;袁俊;杨伯伦
【作者单位】西安交通大学能源与动力工程学院,710049,西安;西安近代化学研究所,710065,西安;西安交通大学能源与动力工程学院,710049,西安
【正文语种】中文
【中图分类】TQ622;TP301.6
【相关文献】
1.基于BP神经网络的堆石坝参数二次反演与变形预测 [J], 程壮;陈星;董艳华;党莉
2.基于LM/SVM方法的二次反应清洁汽油辛烷值预测 [J], 袁俊;周小伟;杨伯伦
3.基于BP神经网络对汽油辛烷值损失预测模型的构建 [J], 王宁宁
4.基于BP神经网络对汽油辛烷值损失预测模型的构建 [J], 王宁宁
5.基于PLS-MI组合的天牛须搜索BP神经网络模型对汽油辛烷值的预测性能 [J], 石翠翠;刘媛华
因版权原因,仅展示原文概要,查看原文内容请购买。

汽油调合优化神经网络模型的研究
近几年来,随着我国经济的发展,汽油的需求量不断增加,汽油的质量要求也随之提高。
汽油的质量主要由其组分(例如烷烃、芳香烃、Alkene等)的比例来决定。
为了确保汽油的质量,汽油的调合必须恰到好处,这需要汽油的调合参数可以得到精确的掌握。
神经网络是一种智能的机器学习算法,它可以通过训练获取大量数据,从而使模型有较强的拟合能力和泛化能力。
因此,把神经网络用于汽油调合优化是科学、可行的。
本文分析了汽油调合优化神经网络模型的原理,把神经网络模型应用到汽油调合优化研究中,并且利用数值仿真与实验结果来验证模型的准确性。
首先,本文介绍了神经网络模型的结构,包括网络的输入层、隐层和输出层。
神经网络模型的输入层是汽油的调合参数,隐层是神经元,输出层是汽油的质量指标。
其次,本文利用BP神经网络模型进行汽油调合优化,首先根据汽油的调合参数,建立组分比例与汽油质量指标之间的关系模型,然后在数据库中获取大量数据,训练神经网络模型,模型最终能够正确地预测出给定组分比例下汽油的质量指标。
最后,本文通过数值仿真与实验结果来验证模型的准确性。
数值仿真的结果显示,汽油质量指标与给定组分比例的变化趋势一致,证明神经网络模型可以很好地模拟汽油调合过程;实验结果表明,模型计算结果与实际测试结果基本一致,验证了模型的准确性。
综上所述,运用神经网络模型可以帮助汽油调合优化研究者更有效、更准确地预测汽油的质量指标,从而提高汽油的调合效率和质量。

汽油精制过程中辛烷值损失预测模型一、前言汽油是一种重要的燃料,广泛应用于交通运输、工业生产和家庭生活等领域。
汽油的质量直接影响着发动机的性能和寿命,因此精制过程中的辛烷值损失问题一直是制约汽油质量提升的难点之一。
本文将介绍汽油精制过程中辛烷值损失预测模型的建立方法及其应用。
二、汽油精制过程概述汽油精制是指将原油中含有杂质、硫化物等有害成分去除,使其成为高纯度的汽油产品的过程。
通常包括以下几个步骤:1. 蒸馏:将原油加热至不同温度,使其分解成不同馏分,其中轻质组分为汽油组分。
2. 加氢脱硫:通过加氢反应去除硫化物等有害成分。
3. 裂化:将高碳数组分裂解成低碳数组分,以提高产量和辛烷值。
4. 合成:将不同来源的馏分混合,调整其组成和性质以达到所需品质。
在这些步骤中,裂化是最关键的一步,也是辛烷值损失的主要来源。
三、辛烷值损失机理汽油的辛烷值是衡量其抗爆性能的重要指标。
在精制过程中,由于裂化反应导致高碳数组分分解成低碳数组分,使得汽油中芳烃和饱和烃比例发生变化,从而影响其辛烷值。
具体来说,裂化反应会将芳烃转化为饱和烃和烯烃,其中饱和烃对提高辛烷值有贡献,而烯烃则对提高辛烷值有负面影响。
因此,在裂化过程中要尽可能减少芳构物的裂解,并控制合成过程中各组分的比例以达到预期的辛烷值。
四、建立预测模型为了准确预测汽油精制过程中的辛烷值损失情况,需要建立相应的预测模型。
常用的方法包括统计学方法、神经网络方法和机器学习方法等。
1. 统计学方法统计学方法主要基于历史数据进行分析和预测,常见的方法包括回归分析、主成分分析和聚类分析等。
这些方法可以通过对历史数据的拟合来建立预测模型,但需要满足数据量充足、质量可靠的条件。
2. 神经网络方法神经网络方法是一种基于模拟人脑神经元工作方式的预测方法,其优点在于可以处理非线性问题和高维数据。
常见的神经网络模型包括BP 神经网络、RBF神经网络和Hopfield神经网络等。
3. 机器学习方法机器学习方法是一种基于大量数据自主学习的预测方法,其优点在于可以自动提取特征并建立预测模型。

2021年5期创新前沿科技创新与应用Technology Innovation and Application基于BP 神经网络降低汽油精制过程中的辛烷值损失陈曦,刘都鑫,孙啸宇(北方工业大学信息学院,北京100144)1概述目前,计算机模拟燃料配混是一个重要的研究方向,因为它大大减少了通过实验定义辛烷值的成本。
过去的大量研究试图用数学方法将辛烷值描述为汽油成分。
所有这些方法都有优点和缺点。
最大的兴趣是基于数学模型的开发复合过程的物理化学性质,因为模型考虑了特性的非可加性汽油。
许多模型基于回归分析,其形式为汽油不同性质的辛烷值函数,用于例如,蒸气压,密度和分数组成。
这些方法有两个缺点。
首先,模型有很多系数,需要重新计算原料含量变化。
其次,这些模型没有考虑到原材料的变化文献综述表明,在过去的十年中,许多研究致力于优化复合工艺。
然而,大多数计算混合辛烷值的方法都是建立在依赖任何物理和化学性质的基础上,而没有考虑混合过程的性质。
本文通过数学建模的方法,建立了一种辛烷值失损预测模型。
首先通过PCA 降维的方法从在汽油生产过程中对辛烷值有影响的300多个操作变量中筛选出20个主要的操作变量,作为下一步建立预测模型的主要依据。
随后利用BP 神经网络建立预测辛烷值损失的模型,最后利用最小二乘法来拟合汽油辛烷值和硫含量的分析,分析的结果可以画出汽油的辛烷值和硫含量的变化视图。
本文主要研究了辛烷值损失预测模型的建模与价值评估,需要解决优化操作中各个参数模型的优化、主要操作变量优化调整过程中对汽油中辛烷值硫含量的变化预测等问题。
从而改善该模型的整体价值。
2数据预处理由于工厂得到的原始数据存在一定数据缺失和数据失真的情况,所以需要对数据中的坏值或者短缺值进行排除,对失真的数据进行修正。
在选择方法数据处理方法上确定了多因素加权[1]的方法,并调整了表格中的参数,尽量保留有效参数,增加最终结果的泛化能力和鲁棒性。
数据处理方法步骤的确定:(1)对于残缺数据较多的点,进行整列的数据剔除。

2020年中国研究生数学建模竞赛B题降低汽油精制过程中的辛烷值损失模型一、背景汽油是小型车辆的主要燃料,汽油燃烧产生的尾气排放对大气环境有重要影响。
为此,世界各国都制定了日益严格的汽油质量标准(见下表)。
汽油清洁化重点是降低汽油中的硫、烯烃含量,同时尽量保持其辛烷值。
欧盟和我国车用汽油主要规格车用汽油标准辛烷值≯≯≯≯国Ⅲ(2010年)90-9715014030国Ⅳ(2014年)90-975014028国Ⅴ(2017年)89-951014024国Ⅵ-A(2019年)89-95100.83518国Ⅵ-B(2023年)89-95100.83515欧Ⅴ(2009年)951013518欧VI(2013年)951013518世界燃油规范(Ⅴ类汽油)951013510注: μg/g是一个浓度单位,也有用mg/kg或ppm表示的(以下同)我国原油对外依存度超过70%,且大部分是中东地区的含硫和高硫原油。
原油中的重油通常占比40-60%,这部分重油(以硫为代表的杂质含量也高)难以直接利用。
为了有效利用重油资源,我国大力发展了以催化裂化为核心的重油轻质化工艺技术,将重油转化为汽油、柴油和低碳烯烃,超过70%的汽油是由催化裂化生产得到,因此成品汽油中95%以上的硫和烯烃来自催化裂化汽油。
故必须对催化裂化汽油进行精制处理,以满足对汽油质量要求。
辛烷值(以RON表示)是反映汽油燃烧性能的最重要指标,并作为汽油的商品牌号(例如89#、92#、95#)。
现有技术在对催化裂化汽油进行脱硫和降烯烃过程中,普遍降低了汽油辛烷值。
辛烷值每降低1个单位,相当于损失约150元/吨。
以一个100万吨/年催化裂化汽油精制装置为例,若能降低RON损失0.3个单位,其经济效益将达到四千五百万元。
化工过程的建模一般是通过数据关联或机理建模的方法来实现的,取得了一定的成果。
但是由于炼油工艺过程的复杂性以及设备的多样性,它们的操作变量(控制变量)之间具有高度非线性和相互强耦联的关系,而且传统的数据关联模型中变量相对较少、机理建模对原料的分析要求较高,对过程优化的响应不及时,所以效果并不理想。
汽油精制过程中辛烷值损失预测模型
汽油是一种常用的燃料,其质量指标之一是辛烷值。
辛烷值是指
汽油在发动机中爆炸燃烧的能力,一般来说,辛烷值越高,汽油的燃
烧效率越好,发动机的动力性能也越强。
因此,汽油精制过程中辛烷
值的损失成为了一个关键问题,预测模型的建立能够有效地解决这一
问题。
首先,汽油精制过程中的辛烷值损失主要包括两个方面:裂化和
加氢。
裂化是指将较重的石油馏分通过高温和催化剂的作用分解成较
轻的汽油,但随之而来的是辛烷值的下降;加氢则是指在精制过程中
加入氢气,通过化学反应去除杂质,但这也会带来一定的辛烷值损失。
基于这些现实问题,建立汽油精制过程中辛烷值损失预测模型的
目的是为了寻找一种相对准确的方法来估算加氢和裂化过程中的辛烷
值变化。
这种模型能够帮助石油行业的工程师处理生产过程中的问题
和优化工艺流程。
目前,常见的汽油辛烷值预测模型主要包括基于物理化学性质、
统计学方法和人工神经网络等。
其中,基于物理化学性质的模型利用
油品分子结构和组成,通过计算机模拟的方式来估算辛烷值损失,具有较高的准确性和适用性。
但是,这种方法需要大量的实验和计算,计算量巨大,成本也很高。
相比之下,统计学方法和人工神经网络的建立较为简单,但精度并不如基于物理化学性质的模型高。
因此,在实际生产中,不同的模型可以根据生产工艺和产品质量要求来进行选择和比较。
总的来说,汽油精制过程中辛烷值损失预测模型的建立是一项必要的任务。
合理的选择和使用模型能够帮助工程师更好地处理生产过程中的问题和优化工艺流程,从而提高石油行业的生产效率和经济效益。
**大学第九届数学建模竞赛承诺书我们仔细阅读了数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A, B, C中选择一项填写): C承诺人1(手写签名):承诺人2(手写签名):承诺人3(手写签名):C 题 市场预测摘要: 近年来,国内成品油油价不断上升。
油,已成为社会生产和人们生活的必需用品,与我们的生活息息相关。
与之对应,油价的升高使人们产生了新的汽车市场导向,油价,在一定程度上反映汽车市场的变化,也间接地对环境造成了影响。
为此本文合理地分析了影响油价主要因素、预测油市,车市的变化,这在现实生活中具有重要意义。
对于问题一、油价的影响因素是错综复杂,互为关联的。
首先通过网上查阅相关文献资料,分析得出影响国内油价的因素主要有国际原油价格、原油供需关系、税金。
以汽油价格代表成品油油价,建立灰色关联度模型,分别计算各因素的综合关联度1ρ、2ρ、3ρ,比较各因素的综合关联度的大小,分析得出影响国内成品油的最主要因素为国际原油价格,其次为原油供需量和税金。
由于油价在短时间内摆幅较大,而在较长一段时间呈现一定规律性,故分别建立灰色系统GM(1,1)模型对柴油汽油油价进行预测,对其精度检验发现,柴油和汽油的相对误差q 均为二级,方差比C 和小误差概率P 均为一级,故在中长期利用此模型进行预测,结果准确。
对于问题二,由文中提到的公务车型号的选定,可以在一定程度上反映人们越来越重视汽车的油耗,相比之下,国产车比进口车、合资车更确切地符合国情,且价格比较便宜。
MATLAB神经网络及其应用第一篇:MATLAB神经网络基础及其实现MATLAB是一个非常强大的科学计算软件,它具有很多功能,其中包括神经网络的实现。
神经网络是一种基于简单神经元相互连接的模型,用于进行数据分类、预测、模式识别等任务。
在本篇文章中,我们将介绍MATLAB神经网络的基础和其实现。
1. 神经网络的基础神经网络是由多个神经元组成的,每个神经元都有一个输入和一个输出,在神经网络中,每个神经元的输出可以作为其他神经元的输入。
神经元之间的连接可以有不同的权重,这些权重决定了神经元之间信息传递的强度。
神经网络可以分为很多种,例如感知机、递归神经网络、卷积神经网络等。
2. MATLAB神经网络工具箱的实现MATLAB神经网络工具箱是一个扩展的MATLAB工具箱,它提供了基于神经网络的解决方案,可以用于分类、回归等多种任务。
在MATLAB神经网络工具箱中,有很多函数可以用来构建神经网络,其中最常用到的是“feedforwardnet”。
“feedforwardnet”函数用于构建前馈神经网络,该函数的语法如下:net = feedforwardnet(hiddenSizes)其中,“hiddenSizes”是一个数组,用于指定神经网络中隐藏层的大小。
例如,如果要构建一个具有10个隐藏层节点的神经网络,可以使用以下语句:net = feedforwardnet([10]);构建神经网络之后,需要训练它以适应特定的任务。
MATLAB神经网络工具箱提供了很多训练算法,例如误差逆传播算法、遗传算法等。
其中最常用到的训练算法是“trainlm”。
“trainlm”函数用于使用Levenberg-Marquardt算法训练神经网络,该函数的语法如下:net = trainlm(net,inputs,targets)其中,“inputs”是一个输入数据矩阵,“targets”是一个目标数据矩阵,用于训练神经网络。
实验四:Matlab 神经网络以及应用于汽油辛烷值预测专业年级: 2014级信息与计算科学1班姓名: 黄志锐 学号:201430120110一、实验目的1. 掌握MATLAB 创建BP 神经网络并应用于拟合非线性函数2. 掌握MATLAB 创建REF 神经网络并应用于拟合非线性函数3. 掌握MATLAB 创建BP 神经网络和REF 神经网络解决实际问题4. 了解MATLAB 神经网络并行运算二、实验内容1. 建立BP 神经网络拟合非线性函数2212y x x =+第一步 数据选择和归一化根据非线性函数方程随机得到该函数的2000组数据,将数据存贮在data.mat 文件中(下载后拷贝到Matlab 当前目录),其中input 是函数输入数据,output 是函数输出数据。
从输入输出数据中随机选取1900中数据作为网络训练数据,100组作为网络测试数据,并对数据进行归一化处理。
第二步 建立和训练BP 神经网络构建BP 神经网络,用训练数据训练,使网络对非线性函数输出具有预测能力。
第三步 BP 神经网络预测用训练好的BP 神经网络预测非线性函数输出。
第四步 结果分析通过BP 神经网络预测输出和期望输出分析BP 神经网络的拟合能力。
详细MATLAB代码如下:27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54disp(['神经网络的训练时间为', num2str(t1), '秒']);%% BP网络预测% 预测数据归一化inputn_test = mapminmax('apply', input_test, inputps); % 网络预测输出an = sim(net, inputn_test);% 网络输出反归一化BPoutput = mapminmax('reverse', an, outputps);%% 结果分析figure(1);plot(BPoutput, ':og');hold on;plot(output_test, '-*');legend('预测输出', '期望输出');title('BP网络预测输出', 'fontsize', 12);ylabel('函数输出', 'fontsize', 12);xlabel('样本', 'fontsize', 12);% 预测误差error = BPoutput-output_test;figure(2);plot(error, '-*');title('BP神经网络预测误差', 'fontsize', 12);ylabel('误差', 'fontsize', 12);xlabel('样本', 'fontsize', 12);figure(3);plot((output_test-BPoutput)./BPoutput, '-*');title('BP神经网络预测误差百分比');errorsum = sum(abs(error));MATLAB代码运行结果截图如下所示:MATLAB代码运行结果如下所示:图1 BP神经网络预测输出图示图2 BP神经网络预测误差图示图3 BP 神经网络预测误差百分比图示2. 建立RBF 神经网络拟合非线性函数22112220+10cos(2)10cos(2)y x x x x ππ=-+-第一步 建立exact RBF 神经网络拟合, 观察拟合效果详细MATLAB 代码如下:MATLAB代码运行结果如下所示:图4 RBF神经网络拟合效果图第二步建立approximate RBF神经网络拟合详细MATLAB代码如下:13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41F = 20+x1.^2-10*cos(2*pi*x1)+x2.^2-10*cos(2*pi*x2); %% 建立RBF神经网络% 采用approximate RBF神经网络。
spread为默认值net = newrb(x, F);%% 建立测试样本% generate the testing datainterval = 0.1;[i, j] = meshgrid(-1.5:interval:1.5);row = size(i);tx1 = i(:);tx1 = tx1';tx2 = j(:);tx2 = tx2';tx = [tx1; tx2];%% 使用建立的RBF网络进行模拟,得出网络输出ty = sim(net, tx);%% 使用图像,画出3维图% 真正的函数图像interval = 0.1;[x1, x2] = meshgrid(-1.5:interval:1.5);F = 20+x1.^2-10*cos(2*pi*x1)+x2.^2-10*cos(2*pi*x2); subplot(1, 3, 1);mesh(x1, x2, F);zlim([0, 60]);title('真正的函数图像')% 网络得出的函数图像v = reshape(ty, row);subplot(1, 3, 2);mesh(i, j, v);MATLAB代码运行结果截图如下所示:MATLAB代码运行结果如下所示:图5 RBF神经网络拟合结果图示讨论题:对于非线性函数220.252220.11212(){sin [50()]1}y x x x x =+⋅++(1)分别建立BP 神经网络和RBF 神经网络拟合并比较两者的性能差异。
(2)就BP 神经网络验证单线程运算和并行运算的运行时间差异。
(1)详细MATLAB 代码如下:MATLAB代码运行结果截图如下所示:MATLAB代码运行结果如下所示:图6 BP神经网络拟合效果图详细MATLAB代码如下:MATLAB代码运行结果如下所示:图7 RBF神经网络拟合效果图详细MATLAB代码如下:5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33% 产生2*sample的随机矩阵,随机数在区间[a, b]中a = -2;b = 2;x = a + (b-a).*rand(2, sample);% 计算网络输出y值y = f(x(1, :), x(2, :));%% 训练数据归一化input_train = x;output_train = y;[input_n, input_ps] = mapminmax(input_train);[output_n, output_ps] = mapminmax(output_train);%% 构建和训练BP神经网络% BP神经网络构建hiddenSizes = 500;trainFcn = 'trainlm';% net = newff(input_n, output_n, hiddenSizes);net = fitnet(hiddenSizes,trainFcn);net.trainParam.epochs = 300;net.trainParam.goal = 0.00004;net.trainParam.lr = 0.1;net = train(net, input_n, output_n);%% BP网络预测input_test = a + (b-a).*rand(2, sample*0.05);output_test = f(input_test(1, :), input_test(2, :)); inputn_test = mapminmax('apply', input_test, input_ps); prediction = sim(net, inputn_test);BP_output = mapminmax('reverse', prediction, output_ps); %% 结果分析figure(1);34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62plot(BP_output, ':og');hold on;plot(output_test, '-*');legend('预测输出', '期望输出');title('BP网络预测输出', 'fontsize', 12);ylabel('函数输出', 'fontsize', 12);xlabel('样本', 'fontsize', 12);% 预测误差error = BP_output-output_test;figure(2);plot(error, '-*');title('BP神经网络预测误差', 'fontsize', 12);ylabel('误差', 'fontsize', 12);xlabel('样本', 'fontsize', 12);figure(3);plot((output_test-BP_output)./BP_output, '-*'); title('BP神经网络预测误差百分比');errorsum = sum(abs(error));%% 使用图像,画出3维图% 真正的函数图像interval = 0.1;[x1, x2] = meshgrid(a:interval:b);y = f(x1, x2);subplot(1, 3, 1);mesh(x1, x2, y);zlim([-2, 5]);title('真正的函数图像')% 网络得出的函数图像tx1 = x1(:);MATLAB代码运行结果如下所示:图8 BP神经网络预测输出图示图9 BP神经网络预测误差图示图10 BP神经网络拟合效果图详细MATLAB代码如下:13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41spread = 0.08;net = newrb(x, F, spread );%% 建立测试样本interval = 0.1;[i, j] = meshgrid(a:interval:b); row = size(i);tx1 = i(:);tx1 = tx1';tx2 = j(:);tx2 = tx2';tx = [tx1; tx2];%% 使用建立的RBF网络进行模拟,得出网络输出ty = sim(net, tx);%% 使用图像,画出3维图% 真正的函数图像interval = 0.1;[x1, x2] = meshgrid(a:interval:b);F = f(x1, x2);subplot(1, 3, 1);mesh(x1, x2, F);zlim([-2, 5]);title('真正的函数图像')% 网络得出的函数图像v = reshape(ty, row);subplot(1, 3, 2);mesh(i, j, v);zlim([-2, 5]);title('RBF神经网络结果')% 误差图像MATLAB 代码运行结果如下所示:图11 RBF 神经网络拟合效果图通过分析上述结果可知,对于非线性函数220.252220.11212(){sin [50()]1}y x x x x =+⋅++RBF 神经网络(spread 值为0.08)的拟合效果比BP 神经网络(隐含层神经元的个数为500个)的拟合效果更好,且RBF 神经网络性能更佳(耗时更少)。