spss第二版习题及答案
- 格式:docx
- 大小:3.78 KB
- 文档页数:2

spss考试题型及答案一、单项选择题1. 在SPSS中,数据文件的扩展名是什么?A. .txtB. .csvC. .savD. .xls答案:C2. 下列哪个选项不是SPSS中的数据类型?A. 数值型B. 字符串型C. 日期型D. 图片型答案:D3. 在SPSS中,如何将数据文件中的数据进行排序?A. 使用“数据”菜单中的“排序案例”命令B. 使用“分析”菜单中的“排序案例”命令C. 使用“转换”菜单中的“排序案例”命令D. 使用“文件”菜单中的“排序案例”命令答案:A二、多项选择题1. 在SPSS中,以下哪些是描述性统计分析的常用指标?A. 平均值B. 中位数C. 众数D. 方差答案:ABCD2. 在SPSS中,进行相关性分析时,可以使用哪些方法?A. 皮尔逊相关系数B. 斯皮尔曼等级相关系数C. 肯德尔等级相关系数D. 偏相关分析答案:ABCD三、简答题1. 请简述SPSS中数据导入的步骤。
答:在SPSS中导入数据的步骤通常包括:打开SPSS软件,点击“文件”菜单选择“打开”选项,然后选择“数据”并找到需要导入的数据文件,点击“打开”即可完成数据导入。
2. 描述在SPSS中进行数据清洗的一般流程。
答:在SPSS中进行数据清洗的一般流程包括:识别数据中的异常值、缺失值和重复值,然后根据需要进行删除、替换或填充操作,以确保数据的准确性和完整性。
四、计算题1. 假设在SPSS中有一个数据集,包含10个数值型变量,计算这些变量的平均值。
答:在SPSS中,可以通过“分析”菜单选择“描述性统计”选项,然后选择“描述”并点击“确定”,在弹出的对话框中选择需要计算平均值的变量,点击“确定”后,SPSS将输出包含这些变量平均值的统计表。
2. 给定一组数据,计算其标准差。
答:在SPSS中,可以通过“分析”菜单选择“描述性统计”选项,然后选择“描述”并点击“确定”,在弹出的对话框中选择需要计算标准差的变量,并勾选“标准差”选项,点击“确定”后,SPSS将输出包含该变量标准差的统计表。

spss期末考试题目及答案一、单项选择题(每题2分,共20分)1. SPSS软件的全称是什么?A. Statistical Package for the Social SciencesB. Statistical Package for the Social StudiesC. Statistical Package for the Scientific StudiesD. Statistical Package for the Social Surveys答案:A2. 在SPSS中,用于描述数据集中趋势的统计量是:A. 方差B. 标准差C. 平均值D. 中位数答案:C3. 在SPSS中,以下哪个选项不是数据类型?A. 数值型B. 字符串型C. 逻辑型D. 图像型答案:D4. SPSS中的数据视图和变量视图分别对应于:A. 数据编辑器和数据浏览器B. 数据编辑器和变量编辑器C. 数据浏览器和变量编辑器D. 数据浏览器和数据编辑器答案:B5. 在SPSS中进行相关性分析时,通常使用哪种统计方法?A. 回归分析B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D6. 在SPSS中,要将数据导入到数据集中,可以使用以下哪个功能?A. 文件导入B. 数据合并C. 数据转换D. 数据导出答案:A7. 在SPSS中,进行数据清洗时,以下哪个选项不是常用的数据清洗方法?A. 删除重复记录B. 填充缺失值C. 转换数据格式D. 增加数据量答案:D8. 在SPSS中,以下哪个选项不是数据转换的方法?A. 计算变量B. 重新编码C. 分组数据D. 数据导出答案:D9. 在SPSS中,进行因子分析时,以下哪个选项不是因子提取方法?A. 主成分分析B. 因子分析C. 聚类分析D. 探索性因子分析答案:C10. 在SPSS中,以下哪个选项不是数据导出的格式?A. SPSS数据文件B. Excel文件C. CSV文件D. PDF文件答案:D二、多项选择题(每题3分,共15分)1. 在SPSS中,以下哪些选项是描述数据离散程度的统计量?A. 方差B. 标准差C. 均值D. 极差答案:ABD2. 在SPSS中,进行数据编码时,以下哪些选项是正确的编码方式?A. 连续编码B. 顺序编码C. 无序编码D. 缺失编码答案:ABC3. 在SPSS中,以下哪些选项是数据转换的方法?A. 计算变量B. 重新编码C. 分组数据D. 数据导出答案:ABC4. 在SPSS中,以下哪些选项是数据清洗的方法?A. 删除重复记录B. 填充缺失值C. 转换数据格式D. 增加数据量答案:ABC5. 在SPSS中,进行因子分析时,以下哪些选项是因子提取方法?A. 主成分分析B. 因子分析C. 聚类分析D. 探索性因子分析答案:ABD三、简答题(每题5分,共20分)1. 简述SPSS中数据编辑器和变量编辑器的功能。

spss考试题及答案1. 单选题:在SPSS中,以下哪个选项不是数据清洗的步骤?A. 缺失值处理B. 异常值检测C. 数据转换D. 数据备份答案:D2. 多选题:在SPSS中进行描述性统计分析时,可以输出哪些统计量?A. 均值B. 中位数C. 众数D. 标准差E. 方差答案:A, B, C, D, E3. 判断题:在SPSS中,使用“描述统计”功能可以计算出数据的峰度。
对错答案:错4. 填空题:在SPSS中,进行相关性分析时,可以使用_________菜单下的“相关性”选项。
答案:分析5. 简答题:请简述SPSS中因子分析的步骤。
答案:因子分析的步骤包括:a. 确定分析变量b. 进行KMO和Bartlett的球形度检验c. 选择提取方法(如主成分分析或因子分析)d. 确定因子数量e. 进行因子旋转(如需要)f. 解释因子6. 案例分析题:某研究者收集了一组数据,想要使用SPSS进行方差分析。
请描述方差分析的一般步骤。
答案:方差分析的一般步骤如下:a. 确定研究假设b. 选择合适的方差分析类型(如单因素方差分析或多因素方差分析)c. 输入数据并设置因子和因变量d. 进行方差分析e. 检查方差齐性f. 进行后续多重比较(如果需要)g. 解释结果7. 操作题:使用SPSS进行回归分析,并解释回归系数的意义。
答案:进行回归分析的步骤包括:a. 选择分析菜单下的回归选项b. 选择线性回归c. 设置因变量和自变量d. 运行回归分析e. 查看输出结果f. 解释回归系数,即自变量每变化一个单位,因变量预期的变化量以上即为SPSS考试题及答案的排版及格式。
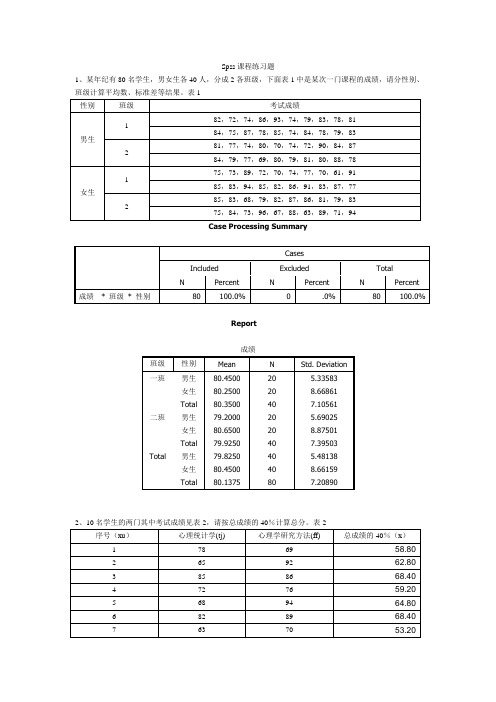
Spss课程练习题1、某年纪有80名学生,男女生各40人,分成2各班级,下面表1中是某次一门课程的成绩,请分性别、班级计算平均数、标准差等结果。
表1Case Processing SummaryReport成绩2、10名学生的两门其中考试成绩见表2,请按总成绩的40%计算总分。
表23、将表1中的数据合并,即不再分组,试整理成频数分布表,绘制出频数分布图,计算出常用的统计量。
Statistics成绩N Valid 80Missing 0Mean 80.1375Std. Error of Mean .80598Median 80.5000Mode 74.00(a)Std. Deviation 7.20890Minimum 61.00Maximum 96.00Sum 6411.00Percentiles 25 74.250050 80.500075 85.0000a Multiple modes exist. The smallest value is shown成绩F r e q u e n c y4、正常人的脉搏平均 数为72次/分。
现测得15名患者的脉搏:71,55,76,68,72,69,56,70,79,67,58,77,63,66,78 试问这15名患者的脉搏与正常人的脉搏是否有差异?One-Sample Test由结果可知,因为0.088>0.05,所以在p=0.05的显著性水平上差异不显著5、收集了20名学生的自信心值,见表3,试问该指标是否与性别有关?表3Independent Samples Test由数据可知,F检验的p=0.608>0.05,所以两组样本的方差差异不显著,所以t检验应该是Equal variances assumed一项进行判断。
双侧t检验的p=0.392>0.05,表示两个样本没有显著性差异4,试问两种训练方法的效果是否相同?表4注:x1、x2表示两组学生的跳高成绩,单位厘米(cm)配对样本T检验:Analyze -Compare Means -Paried-sample T TestPaired Samples CorrelationsPaired Samples Test由配对样本相关性检验可知,两样本相关性的p=0.00<0.05,因此两者存在相关性,由配对样本T检验的数据分析可得,两组数据的p=0.006<0.05所以两者之间在0.05的差异水平上差异显著7、为了探讨不同教法对英语教学效果的影响,将一个班级随机分成3组,接受3种不同的教法,英语成绩见表5,试问不同的教法之间是否存在着差异。

SPSS练习题1、现有两个SPSS数据文件,分别为“学生成绩一”和“学生成绩二”,请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
先排序data---sort cases 再合并data---merge files2、有一份关于居民储蓄调查的数据存储在EXCEL中,请将该数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。
转换Data---transpose,输题目3、利用第2题的数据,将数据分成两份文件,其中第一份文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000-2000之间的调查数据,第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
选取数据data---select cases4、利用第2题数据,将其按常住地(升序)、收入水平(升序)存款金额(降序)进行多重排序。
排序data---sort cases一个一个选,加5、根据第1题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算transform---count按个输,把所有课程选取,define设区间,再排序6、根据第1题的完整数据,计算每个学生课程的平均分和标准差,同时计算男生和女生各科成绩的平均分。
描述性统计,先转换Data---transpose学号放下面,全部课程(poli到his)放上面,ok,analyze---descriptive statistics---descriptives,全选,options。
先拆分data---split file按性别拆分,analyze---descriptive statistics---descriptives全选所有课程options---mean7、利用第2题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
数据分组Transform---recode---下面一个,输名字,change,old,range,new value---add挨个输,从小加到大,等距—8、在第2题的数据中,如果认为调查“今年的收入比去年增加”且“预计未来一两年收入仍会会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。

spss考试试题及答案一、选择题(每题2分,共20分)1. SPSS中,用于描述数据集中的观测值的中心趋势的统计量是:A. 方差B. 均值C. 标准差D. 众数答案:B2. 在SPSS中,以下哪个选项不是数据转换的方法?A. 计算变量B. 重新编码C. 描述统计D. 计算描述答案:C3. 在SPSS中,进行相关性分析的命令是:A. CORRELATEB. REGRESSIONC. T-TESTD. ANOVA答案:A4. SPSS中,用于创建新的变量或修改现有变量的命令是:A. COMPUTEB. DESCRIPTIVESC. AGGREGATED. RECODE答案:A5. 在SPSS中,用于比较两个独立样本均值差异的统计检验是:A. 卡方检验B. T检验C. 方差分析D. 相关性检验答案:B6. SPSS中,用于检查数据中是否存在缺失值的命令是:A. DESCRIPTIVESB. FREQUENCIESC. MISSING VALUESD. DETECT答案:A7. 在SPSS中,用于创建数据集的副本的命令是:A. SPLIT FILEB. SAVE ASC. TRANSPOSED. DATASET ACTIVATE答案:B8. SPSS中,用于生成数据集的频率分布表的命令是:A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. DESCRIPTIVES EXPLORE答案:B9. 在SPSS中,用于执行多重回归分析的命令是:A. REGRESSIONB. MANOVAC. FACTORD. CLUSTER答案:A10. SPSS中,用于绘制箱线图的命令是:A. CHARTSB. PLOTC. GRAPHD. EXAMINE答案:A二、简答题(每题5分,共20分)1. 请简述SPSS中数据清洗的步骤。
答案:数据清洗通常包括以下步骤:检查缺失值、异常值、错误数据,进行数据转换,以及数据标准化等。
s p s s实践题分析及答案(二)本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March期末实践考查一、一家消费者调查有限公司,它为许多企业提供消费者态度和消费者行为的调查。
在一项研究中,客户要求调查消费者的消费特征,此特征可以用来预测用户使用信用卡的支付金额。
研究人员收集了50位消费者的年收入、家庭人口和每年使用信用卡支付的金额数据。
试按照客户要求进行分析,给出分析报告(数据见附表)。
Descriptive StatisticsMean Std. Deviation N消费金额(元)50年收入(元)50家庭人口(人)50Correlations消费金额(元)年收入(元)家庭人口(人)Pearson Correlation消费金额(元).631.753年收入(元).631.173家庭人口(人).753.173Sig. (1-tailed)消费金额(元)..000.000年收入(元).000..115家庭人口(人).000.115.N消费金额(元)505050年收入(元)505050家庭人口(人)505050Model Summary bModel R R Square Adjusted R Square Std. Error of the Estimate1.909a.826.818ANOVA bModel Sum of SquaresdfMean SquareFSig. 1Regression .6722 .836.000aResidual 47Total.82049Coefficients aModel Unstandardized CoefficientsStandardizedCoefficients tSig. BStd. ErrorBeta1(Constant).000 年收入(元) .033.004.516 .000 家庭人口(人).664.000结果分析:由题目可知客户要求,是根据消费者年收入、家庭人口来预测其每年使用信用卡支付的金额数据,属于多元线性回归问题,其中年收入和家庭人口看作两个自变量,每年信用卡支付金额看作因变量。
128表5-11中,“成对样本统计量”表中对每个分析变量输出两个配对样本的均值、样本量、标准差及均值的标准误。
表5-11中的“成对样本相关系数”表中输出两个配对样本的样本量、相关系数和相关系数的p值。
“对2”(即采用该饮食计划前的体重和采用该饮食计划后的体重)的相关系数为0.996,从显著性值小于0.05可知,该相关系数明显大于0,并且采用该饮食计划前体重和最后体重之间具有强线性相关,而采用该饮食计划前的甘油三酸酯含量和最后的甘油三酸酯含量的相关系数为-0.286,其显著性值为0.283,该相关系数不显著。
表5-11中的“成对样本检验”表中输出配对样本的差值的均值、差值的标准差、差值均值的标准误、差分的95%置信区间、t统计量和相应的Sig.(双侧)值(即显著性值,或p值)。
这里,t统计量的值为差值的均值除以均值的标准误。
“对1”的均值14.063,即采用饮食计划前体重减去采用该饮食计划之后的体重的差值的均值,表明采用该计划后的个体的甘油三酸酯含量减轻了14.063。
而体重减轻了8.063,但由于甘油三酸酯的差值的标准差及差值均值的标准误远远高于体重的标准差和标准误,因而“对2”的t值远远大于“对1”的t值。
从最后的显著性值来看,体重的减轻在统计学上是显著的,即采用该饮食计划的受试者的体重确实减轻了,而受试者的甘油三酸酯在统计学上并没有显著变化。
因此,对该饮食计划最终的评估结果为该减肥药可以减轻体重,但尚不能确定可以减轻甘油三酸酯(脂肪)。
应用配对T检验前,需要先检查两个样本是否服从正态分布。
等价地,可以检验两个配对样本的差值变量是否服从正态分布。
可以应用直方图、Q-Q图或者K-S检验等方法来检验差值变量的正态性。
要特别注意所分析变量中是否含有离群值,用户可以用箱图来检查离群值的情况。
有时候,可以先计算配对样本的差值变量,然后进行单样本的T检验。
5.6 小结本章首先解释了假设检验的思想与原理(这是理解建设检验问题的核心),然后,主要介绍了均值过程,给出了变量的描述性统计量,同时可以给出相应总体的均值是否相等的判断。
spss复习题答案一、选择题1. 在SPSS中,数据文件的扩展名是什么?A. .txtB. .csvC. .savD. .xls答案:C2. 如何在SPSS中创建一个新的数据文件?A. 通过“文件”菜单选择“新建”B. 通过“文件”菜单选择“打开”C. 通过“数据”菜单选择“新建数据集”D. 通过“编辑”菜单选择“新建数据集”答案:A3. 在SPSS中,如何对数据进行排序?A. 通过“数据”菜单选择“排序案例”B. 通过“转换”菜单选择“排序案例”C. 通过“分析”菜单选择“排序案例”D. 通过“窗口”菜单选择“排序案例”答案:A4. 若想在SPSS中计算变量的平均值,应使用哪个命令?A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. MEANS答案:D5. 在SPSS中,如何对数据进行分组?A. 通过“数据”菜单选择“分组变量”B. 通过“转换”菜单选择“分组变量”C. 通过“分析”菜单选择“分组变量”D. 通过“窗口”菜单选择“分组变量”答案:B二、填空题1. 在SPSS中,数据文件的基本单位是________,它包含了一系列的变量和观测值。
答案:变量2. 使用SPSS进行数据分析时,数据的输入和编辑是通过________视图完成的。
答案:数据编辑3. 在SPSS中,可以通过________功能来对数据进行清洗,以确保数据的准确性和完整性。
答案:数据清洗4. 在进行假设检验时,SPSS提供了多种统计方法,其中用于比较两个独立样本均值差异的统计方法是________检验。
答案:独立样本T检验5. 在SPSS中,可以通过________功能来创建新的变量,以便于进行更复杂的数据分析。
答案:变量计算三、简答题1. 描述在SPSS中如何进行数据的导入和导出。
答案:在SPSS中,可以通过“文件”菜单选择“导入”来导入数据,支持多种格式如文本文件、Excel文件等。
数据导出则可以通过“文件”菜单选择“导出”来实现,可以选择导出为文本文件、Excel文件等多种格式。
spss统计分析期末考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图和变量视图分别指的是:A. 数据的输入和输出B. 数据的录入和变量的设置C. 数据的录入和数据的查看D. 数据的查看和变量的设置答案:D2. SPSS中,用于描述数据集中趋势的统计量是:A. 方差B. 标准差C. 平均数D. 众数答案:C3. 在进行相关分析时,SPSS中用于计算两个变量之间相关系数的命令是:A. DESCRIPTIVESB. CORRELATEC. T-TESTD. ANOVA答案:B4. 以下哪个选项不是SPSS中的数据类型?A. 数字B. 文本C. 图片D. 日期答案:C5. 在SPSS中,执行回归分析的菜单路径是:A. 分析 > 回归 > 线性B. 分析 > 描述统计 > 描述C. 分析 > 相关性 > 双变量D. 分析 > 描述统计 > 频率答案:A6. SPSS中,用于绘制箱线图的命令是:A. GRAPH > 箱线图B. GRAPH > 图形构建器C. GRAPH > 图形 > 箱线图D. GRAPH > 图形 > 直方图答案:C7. 在SPSS中,用于创建新的变量的命令是:A. COMPUTEB. DESCRIPTIVESC. RECODED. AGGREGATE答案:A8. SPSS中,用于执行因子分析的命令是:A. FACTORB. CLUSTERC. REGRESSIOND. DESCRIPTIVES答案:A9. 在SPSS中,用于计算卡方检验的命令是:A. CROSSTABSB. T-TESTC. ANOVAD. CORRELATE答案:A10. SPSS中,用于执行聚类分析的命令是:A. CLUSTERB. FACTORC. REGRESSIOND. DESCRIPTIVES答案:A二、简答题(每题5分,共30分)1. 请简述SPSS中数据清洗的步骤。
spss第二版习题及答案
SPSS第二版习题及答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛
应用于社会科学领域的数据分析和研究中。
对于学习SPSS的人来说,掌握习题并查看答案是提高技能的重要途径之一。
本文将为大家介绍一些SPSS第二版习题及其答案,希望能够帮助读者更好地理解和应用SPSS。
一、描述统计学习题
1. 对于以下数据集,请计算平均数、中位数、众数、标准差和极差。
数据集:12,15,18,20,22,25,25,27,30,30
答案:平均数:23.4,中位数:24,众数:25和30,标准差:6.89,极差:18 2. 对于以下数据集,请计算四分位数和箱线图。
数据集:10,12,15,18,20,22,25,25,27,30,30,32,35,40,45
答案:第一四分位数(Q1):18.5,第二四分位数(Q2):25,第三四分位数
(Q3):32.5,箱线图:参考附图1。
二、假设检验学习题
1. 一个研究人员想要确定一种新的药物是否对治疗抑郁症有效。
他随机选择了100名患有抑郁症的患者,并将他们分为两组:实验组和对照组。
实验组接受
新药物治疗,对照组接受安慰剂。
请使用SPSS进行假设检验,判断新药物是否显著改善了患者的抑郁症状。
答案:使用t检验进行假设检验。
设定零假设(H0):新药物对抑郁症状无显著改善;备择假设(H1):新药物对抑郁症状有显著改善。
根据样本数据计算得
到t值和p值,如果p值小于设定的显著性水平(通常为0.05),则拒绝零假设,
认为新药物对抑郁症状有显著改善。
三、相关性分析学习题
1. 一个市场研究人员想要确定广告投入和销售额之间的相关性。
他收集了10个不同广告投入和销售额的数据。
请使用SPSS进行相关性分析,并解释结果。
答案:使用Pearson相关系数进行相关性分析。
根据样本数据计算得到相关系数r,r的取值范围为-1到1,如果r接近1,则表示广告投入和销售额之间存在正相关关系;如果r接近-1,则表示存在负相关关系;如果r接近0,则表示不存在线性相关关系。
此外,还可以计算p值来判断相关性是否显著,如果p 值小于设定的显著性水平(通常为0.05),则认为相关性显著。
四、回归分析学习题
1. 一个经济学家想要探究GDP和失业率之间的关系。
他收集了10个不同国家的GDP和失业率数据。
请使用SPSS进行回归分析,并解释结果。
答案:使用线性回归分析。
将GDP作为自变量,失业率作为因变量,根据样本数据拟合回归方程,得到回归系数和截距项。
回归系数表示自变量对因变量的影响程度,截距项表示当自变量为0时,因变量的预测值。
此外,还可以计算回归方程的显著性和拟合优度,判断回归方程是否显著,以及自变量对因变量的解释程度。
综上所述,SPSS第二版习题及答案涵盖了描述统计、假设检验、相关性分析和回归分析等内容。
通过解答这些习题,读者可以加深对SPSS的理解和应用,提升数据分析的能力。
当然,这只是其中的一部分习题和答案,希望读者能够继续深入学习和实践,掌握更多SPSS的技巧和方法。