数据仓库培训案例
- 格式:pptx
- 大小:412.65 KB
- 文档页数:42

数据仓库ETL案例学习(⼀)来⾃课程案例学习某跨国⾷品超市的信息管理系统,每天都会记录成千上万条各地连锁超市的销售数据。
基于⼤数据的背景,该公司的管理层决定建⽴FoodMart数据仓库,期望能从庞⼤的数据中挖掘出有商业价值的信息,来进⼀步帮助管理层进⾏决策。
设计⼀个销售数据仓库。
要求:1、⾄少4个维度,每个维度⾄少3个属性,尽量包含维层。
2、⾄少1个事实表。
3、数据源能获取(设计的维度和度量字段应该在数据源中直接或间接得到)。
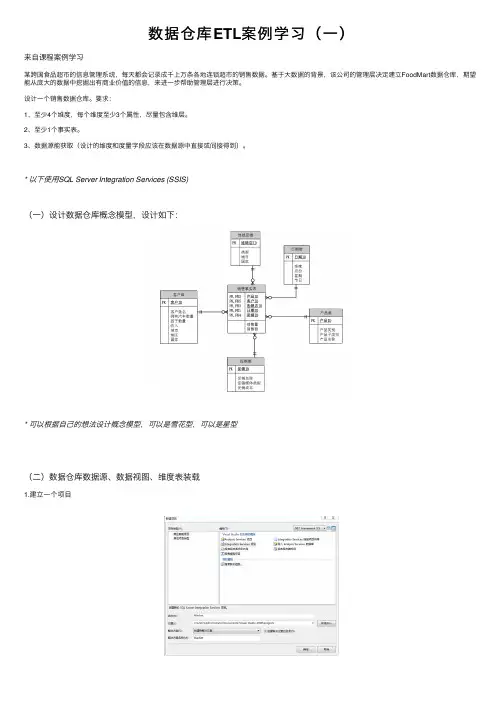
* 以下使⽤SQL Server Integration Services (SSIS)(⼀)设计数据仓库概念模型,设计如下:* 可以根据⾃⼰的想法设计概念模型,可以是雪花型,可以是星型(⼆)数据仓库数据源、数据视图、维度表装载1.建⽴⼀个项⽬2.将数据集导⼊sql server(本⽂将access数据库先转到sql server,再在SSIS⾥使⽤,也可以直接在SSIS⾥使⽤Access驱动)3.建⽴与sql server的连接4.依次装载数据产品维、顾客维、⽇期维、连锁店维、促销维。
产品维中涉及两个表product、product_class,根据⽣成查询获得了想要的数据⽬标编辑器选择新建表来存⼊数据仓库。
同理装载商品维同理装载促销维装载客户维同理装载时间维这⾥需要将时间字符串进⾏分割,使⽤派⽣列和⽇期函数,分别建⽴年、⽉、⽇(ps:这⾥不需要⼿动建⽴时间维,数据仓库提供了建⽴时间维的模板,这⾥后⾯会提到)5.装载事实表这⾥需要对汇率进⾏转换,将saledetail表和currency分别处理(查找、派⽣、排序等)后通过合并转换的内连接,使得汇率与交易的地区相对应,再加派⽣列,计算所得的利润。
具体的细节如下:1) 需要将currency的地区和⽇期与saledetail地区与⽇期做处理,才能够相对应2)两边的数据进⾏内连接3)通过派⽣列计算利润4)装载数据成功,共计251395⾏6.结果如下:在SQL数据库⾥可以查看装载好的数据仓库7.在Sql数据库中设置每周六晚24时⾃动执⾏装载新业务数据要把所有者改为[sa],才可以运⾏成功欢迎⼩伙伴的批评指正~。



数据仓库与数据挖掘案例分析在当今数字化的时代,数据已成为企业和组织最宝贵的资产之一。
如何有效地管理和利用这些海量数据,以获取有价值的信息和洞察,成为了摆在众多企业面前的重要课题。
数据仓库和数据挖掘技术的出现,为解决这一问题提供了有力的手段。
接下来,让我们通过一些具体的案例来深入了解这两项技术的应用和价值。
一、零售行业的数据仓库与数据挖掘以一家大型连锁超市为例,该超市每天都会产生大量的销售数据,包括商品的种类、价格、销售数量、销售时间、销售地点等。
通过建立数据仓库,将这些分散在不同系统和数据库中的数据整合起来,形成一个统一的、集成的数据源。
数据挖掘技术则可以帮助超市发现隐藏在这些数据中的模式和趋势。
例如,通过关联规则挖掘,可以发现哪些商品经常被一起购买,从而优化商品的摆放和促销策略。
如果顾客经常同时购买面包和牛奶,那么将这两种商品摆放在相邻的位置,或者推出面包和牛奶的组合促销活动,可能会提高销售额。
通过聚类分析,可以将顾客分为不同的群体,根据每个群体的消费习惯和偏好,进行个性化的营销。
比如,将经常购买高端进口食品的顾客归为一类,针对他们推送相关的新品推荐和优惠信息;而对于注重性价比的顾客群体,则推送一些打折促销的商品信息。
二、金融行业的数据仓库与数据挖掘在金融领域,银行和证券公司也广泛应用数据仓库和数据挖掘技术。
一家银行拥有大量的客户数据,包括客户的基本信息、账户交易记录、信用记录等。
利用数据仓库,银行可以对这些数据进行整合和管理,实现对客户的全面了解。
数据挖掘可以帮助银行进行客户细分,识别出高价值客户和潜在的流失客户。
对于高价值客户,提供个性化的服务和专属的金融产品,提高客户的满意度和忠诚度;对于潜在的流失客户,及时采取措施进行挽留,比如提供优惠政策或者改善服务质量。
在风险管理方面,数据挖掘可以通过建立信用评估模型,预测客户的违约风险。
通过分析客户的历史交易数据、收入情况、负债情况等因素,评估客户的信用等级,为贷款审批提供决策依据,降低不良贷款率。

hive项目实训案例Hive是一个基于Hadoop的数据仓库工具,用于处理和分析大数据。
以下是几个Hive项目实训案例,可以帮助你深入了解Hive的应用和实践:1. 数据仓库建模在这个案例中,你将使用Hive构建一个数据仓库模型,其中包括事实表、维度表和桥接表。
你可以使用一个现有的数据集,如电商交易数据,将其导入到Hive中,并使用Hive的DDL语句创建表和分区。
然后,你可以使用Hive的SQL查询语句进行数据分析,例如计算销售额、订单数量等指标。
2. 数据清洗和转换在这个案例中,你将使用Hive进行数据清洗和转换。
你可以使用Hive的内置函数和UDF(用户自定义函数)对数据进行处理,例如去除重复记录、填充缺失值、转换数据类型等。
然后,你可以将处理后的数据导出到另一个数据存储系统,例如关系型数据库或数据湖。
3. 数据分析和可视化在这个案例中,你将使用Hive进行数据分析和可视化。
你可以使用Hive的SQL查询语句对数据进行聚合、过滤和连接操作,例如计算销售额的分布、找出购买最多的商品等。
然后,你可以将分析结果导出到Excel或其他可视化工具中进行展示。
4. 数据挖掘和机器学习在这个案例中,你将使用Hive进行数据挖掘和机器学习。
你可以使用Hive 的MLlib库进行分类、聚类、回归等机器学习算法的实现。
然后,你可以将训练好的模型导出到另一个系统进行部署和应用。
以上是几个Hive项目实训案例,可以帮助你深入了解Hive的应用和实践。
通过这些案例的学习和实践,你可以更好地掌握Hive的使用方法和技巧,提高你的大数据处理和分析能力。


数据仓库案例随着信息时代的快速发展,数据充斥着人们的生活和工作。
人们越来越关注如何高效地管理和利用这些数据,以提高工作效率和决策能力。
这就催生了数据仓库的出现。
数据仓库是一种以主题为导向,集成、稳定、易于访问的数据集合,用于支持管理决策和业务智能的系统。
某电子商务公司作为一个新型的企业,涉及各种业务,如商品销售、库存管理、顾客管理等。
为了更好地管理和分析这些数据,他们决定建立一个数据仓库。
首先,他们进行了需求分析,确定了数据仓库的目标和内容。
由于销售是企业最关注的方面,他们决定将销售数据作为数据仓库的核心内容。
然后,他们收集了公司历年来的销售数据,包括销售额、销售量、销售渠道等。
为了增加数据的全面性和准确性,他们还收集了其他相关数据,如库存数据、顾客行为数据等。
接下来,他们对收集到的数据进行了清洗和整合。
由于数据来源不同,格式也各不相同,他们需要对数据进行转换和归一化,以确保数据的一致性和兼容性。
同时,他们还进行了数据清洗,将有错误或冗余的数据进行了删除或修复。
然后,他们设计了数据仓库的架构和模型。
他们使用了星型模型来组织数据,将销售事实表与维度表相连接,以实现对销售数据的多维度分析。
另外,他们还设计了一些指标和报表,用于监控销售情况和预测销售趋势。
最后,他们将数据仓库部署到了公司的服务器上,并对用户进行了培训和指导,以确保他们能够充分利用数据仓库的功能。
同时,他们也建立了一支数据仓库运维团队,负责维护和更新数据仓库,以适应企业的发展和变化。
通过建立数据仓库,该电子商务公司取得了许多好处。
首先,他们可以更好地管理和分析销售数据,及时了解销售情况和趋势,以便做出更有效的决策。
其次,他们可以通过数据仓库进行顾客行为分析,了解顾客的偏好和需求,以便精准地进行商业推广。
最后,他们还可以根据销售数据进行库存管理,避免库存过剩或缺货的情况。
综上所述,数据仓库在企业中的应用具有重要意义。
无论是传统企业还是新兴企业,都可以通过建立数据仓库来提高管理效率和决策能力,实现可持续发展。

数据仓库技术应用案例分享数据仓库是一种集成、关联,且描述数据随时间变化的数据存储架构。
它为企业提供了一种可信赖的数据存储方式,使得企业可以依据历史趋势和数据以及数据的变化趋势进行预测和分析。
数据仓库是商业智能(BI)和数据挖掘(DM)的基础,是实现数据应用的必要条件。
数据仓库技术应用广泛,不仅应用于传统的业务数据分析领域,也应用于各种其他领域,例如医疗卫生、城市安全等领域。
下面我将分享几个数据仓库技术应用案例。
案例1:汽车保险数据挖掘为了实现对汽车保险数据的有效分析,保险公司建立了一个基于数据仓库技术的数据挖掘系统。
该系统通过将保单、理赔、交通违规等数据整合到一个数据仓库中,并且运用数据挖掘和机器学习技术对保险进行风险评估、保费计算和理赔处理。
该系统的数据仓库结合了大数据量,通过应用模型和算法进行快速分析,帮助公司深入了解客户风险,并制定更好的保险产品和正确的赔偿标准。
案例2:医疗信息化医疗信息化是一项非常复杂的任务,需要应用数据仓库技术来分析和处理大量的医疗数据。
医院可以将病人就诊记录、医生门诊看诊记录、各种医疗设备产生的数据以及药剂数据等整合到一个数据仓库中,通过数据挖掘和机器学习技术对病人进行精细化管理和治疗。
例如,将来自多个ICU设备的数据整合到一个数据仓库中,可以为医生提供一个完整的病人健康记录,从而对患者病情发展和治疗效果进行更精细化的分析和诊断。
案例3:城市安全监控随着城市建设和智能化不断推进,数据仓库技术也被广泛应用于城市安全监控。
例如,通过将城市公安部门、交通部门、气象部门和环保部门等各个部门的数据整合到一个数据仓库中,可以实现对城市安全状态的实时监控。
数据仓库技术还可以帮助用警车、监视器、警报等各种设备产生的数据,实现整体实时监控和预警功能,以提高公共安全和防范城市恐怖袭击等事件。
总结数据仓库技术作为商业智能和数据挖掘的基础,广泛应用于各种领域。
无论是汽车保险、医疗信息化还是城市安全监控,数据仓库技术都可以帮助企业更好地进行数据分析和决策。


数据仓库技术在库存管理中的应用案例分析介绍现今社会,随着信息时代的到来,数据成为了一个组织运营中不可或缺的重要资源。
对于企业而言,库存管理是其日常运营的重要环节之一。
而数据仓库技术的应用能够提供决策支持和业务优化的便利,有效提高库存管理的效率和准确性。
案例分析1. 数据收集与整合公司A是一家大型零售企业,拥有众多实体店面。
然而,由于信息化程度不高,各个店面的库存数据分散保存,导致库存管理效率低下。
为了解决这个问题,公司A引入了数据仓库技术。
他们在各个店面的销售点设置了自动化POS系统,并通过数据仓库将各个店面的销售和库存数据进行实时收集和整合,形成统一的库存管理系统。
这样一来,公司A能够更加准确地了解每个店面的库存情况,做出更加合理的补货决策。
2. 数据分析与预测公司B是一家电子产品制造商,为了避免因库存过多或过少而导致的损失,他们利用数据仓库技术进行库存管理优化。
首先,公司B将各个环节的供应链数据集中存储到数据仓库中,包括供应商的交货周期、销售渠道的需求走势等等。
然后,通过数据仓库中的数据分析工具,公司B能够对过去的销售数据进行回顾,并基于历史数据进行库存需求的预测。
这样一来,公司B能够避免因库存过多或过少而导致的损失,实现库存管理的精细化和合理化。
3. 实时监控与风险预警公司C是一家规模较小的餐饮企业,由于人为因素和外部情况的影响,其库存管理存在一定的风险。
为了及时发现潜在的问题并做出相应的调整,公司C引入了数据仓库技术。
他们通过将原始的进货、出货、销售等数据实时地传输到数据仓库,实现了对库存情况的实时监控。
当库存超出或低于设定的预警线时,系统会自动发出警报,提醒相关人员进行相应的调整。
这样一来,公司C能够及时应对可能出现的风险,保证库存管理的稳定性和准确性。
结论数据仓库技术的应用对于库存管理的提升起到了积极的作用。
通过数据的收集与整合、数据的分析与预测、数据的实时监控与风险预警等手段,企业能够更加准确地了解库存情况,做出更加合理的调度和决策,从而提高库存管理的效率和准确性。
数据仓库之案例(基础篇)⼀、销售案例步骤(⼀)ODS层建⽴源数据库并⽣成初始的数据在Hive中创建源数据过渡区和数据仓库的表⽇期维度的数据装载数据的ETL => 进⼊dwd层,本案例简单,不需要清洗(⼆)DW层dwd层:ETL清洗,本案例不需要dws层:建模型+轻聚合,本案例只需要建模型,太简单,不需要聚合。
轻聚合后建模 => 星型模型【注意,是轻聚合后,成为星型模型】(三)DM层dm层:-> 宽表存放在hive -> 太慢!适合复杂计算,⽤来机器学习/数据挖掘存放在mysql/oracle等分析型数据库 -> 快!⽤来数据分析接⼝暴露:springboot 暴露接⼝数据仓库分层ODS(operational Date store) 源数据层DW(Data WareHouse) 数据仓库层DM(Data Market) 数据集市层⼆、数据仓库之构建步骤(⼀)ODS层(1)建⽴源数据库mysql并⽣成初始的数据/*****************************************************create database sales_source******************************************************/drop database if exists sales_source;create database sales_source default charset utf8 collate utf8_general_ci;use sales_source;/*****************************************************create table******************************************************/-- Table:Customerdrop table if exists Customer;create table customer(customer_number int primary key not null auto_increment,customer_name varchar(32) not null,customer_street_address varchar(256) not null,customer_zip_code int not null,customer_city varchar(32) not null,customer_state varchar(32) not null);-- Table:Productdrop table if exists product;create table product(product_code int primary key not null auto_increment,product_name varchar(128) not null,product_category varchar(32) not null);-- Table:Sales_orderdrop table if exists sales_order;create table sales_order(order_number int primary key not null auto_increment,customer_number int not null,product_code int not null,order_date date not null,entry_date date not null,order_amount int not null);-- add constraintalter table sales_order add constraint fk_cust_orderforeign key (customer_number) references customer(customer_number);alter table sales_order add constraint fk_product_orderforeign key (product_code) references product(product_code);/*************************************************insert data***********************************************/-- insert customerinsert into customer(customer_name,customer_street_address,customer_zip_code,customer_city,customer_state)values('Big Customers','7500 Louise Dr.',17050,'Mechanicsbrg','PA'),('Small Stroes','2500 Woodland St.',17055,'Pittsubtgh','PA'),('Medium Retailers','1111 Ritter Rd.',17055,'Pittsubtgh','PA'),('Good Companies','9500 Scott St.',17050,'Mechanicsbrg','PA'),('Wonderful Shops','3333 Rossmoyne Rd.',17050,'Mechanicsbrg','PA'),('Loyal Clients','7070 Ritter Rd.',17055,'Mechanicsbrg','PA');-- insert productinsert into product (product_name,product_category) values('Hard Disk','Storage'),('Floppy Driver','Storage'),('Icd panel','monitor');-- insert sales_orders-- customer_numer int,product_code int,order_date,entry_date,order_amountdrop procedure if exists proc_generate_saleorder;delimiter $$create procedure proc_generate_saleorder()begin-- create temp tabledrop table if exists temp;create table temp as select*from sales_order where1=0;-- declare varset@begin_time := unix_timestamp('2018-1-1');set@over_time := unix_timestamp('2018-11-23');set@i :=1;while@i<=100000 doset@cust_number :=floor(1+rand()*6);set@product_code :=floor(1+rand()*3);set@tmp_data := from_unixtime(@begin_time+rand()*(@over_time-@begin_time));set@amount :=floor(1000+rand()*9000);insert into temp values(@i,@cust_number,@product_code,@tmp_data,@tmp_data,@amount);set@i :=@i+1;end while;-- clear sales_orderstruncate table sales_order;insert into sales_order select null,customer_number,product_code,order_date,entry_date,order_amount from temp; commit;drop table temp;end$$PS: 1.为什么要⽤constraint约束? 详见 => 2.为什么存储过程中涉及批量插表的时候要⽤到临时表?已知commit⼀次是从内存表到物理表的过程,⽤不⽤临时表有什么不⼀样?答:关键在于temp 表是新create 的表,对于新create 的表,insert into 是在内存⾥完成;⽽对于早就存在的表,mysql 默认每次insert 语句都是⼀次commit ,所以右上图是不正确的,应该是commit 了100000次。