LoadRunner中响应时间与事物时间详解
- 格式:doc
- 大小:160.00 KB
- 文档页数:11

LoadRunner使用说明一、概述LAODRUNNER8.1 作为专业的性能测试工具,通过模拟成千上万的用户对被测应用进行操作和请求,在实验室环境中精确重现生产环境中任意可能出现的业务压力,然后通过在测试过程中获取的信息和数据来确认和查找软件的性能问题,分析性能瓶颈.LOADRUNNER提供了三个大主要模块,这三个模块既可以作为独立的工具分别完成各自的功能,又可以作为LOADRUNNER的一部分彼此衔接,与其他模块共同完成软件性能的整体测试.这三大模块主要是:Ø VITUAL USER GENERATOR--------用于录制脚本ØMERCURY LOADRUNNER CONTROLLER---------用于创建,运行和监视场景ØMERCURY LOADRUNNER ANALYSIS--------用于分析测试结果;二、LOADRUNNER8.1 安装 LAODRUNNER8.安装过程比较简单,只需按系统的提示一步一步操作就可以了,这里对安装过程中的一些要点进行简要的说明.Ø安装类型安装盘内有两个盘片,MERCURY LOADRUNNER8.1和MECURY LOADRUNNER 8.0ADD-INS.前者包括了LR安装程序及常用组件,后者全部为组件,各组件的作用在安装盘中都有详细的提示.Ø LICENSE 类型LICENSE类型说明如下:PERMANENT 永不过期的LICENSE;TIME LIMITED 限定了使用的起始时间和使用周期;TEMPORARY 从安装后开始计算,限定了使用的天数;VUD-BASED 限定了虚拟用户数量PLUGGED 需要DONGLE,也就是HARDWARE KEY,DONGLE在中国被音译为“狗”,主要是防止软件被盗用Ø RPM和WEB SERVER之间的鉴权如果在安装时选择安装REMOTE PERFORMANCE MONITOR SERVER,LOADRUNNER会弹出一个要求输入用户名和密码的对话框,REMOTE PERFORMANCE MONITOR SERVER是一个远程监视场景的服务器,为测试人员提供WEB化的场景页面,用于实现多台及其通过浏览器同时在线监视场景.这里设定用户名和口令的目的主要是为了REMOTE PERFORMANCE MONITOR(RPM)和运行了IIS的WEB SERVER之间进行鉴权.在RPM安装完毕之后,只有在LOADRUNNER CONTROLLER的RPM用户配置对话框中输入指定的用户名和口令,系统才能允许进行远程监控.Ø设定LOADRUNNER GENERATOR如何登陆到CONTROLLERLOADRUNNER提供了两种方式让LOAD GENERATOR的虚拟用户登陆到CONTROLLER,n ALLOW VIRTUALUSERS TO RUN ON THIS MACHINE WITHOUT USER LOGINn MANUAL LOG IN TO THE LOAD GENERATOR MACHINE三、使用VITUAL USER GENERATOR录制开发脚本LOADRUNNER脚本的开发过程一般需要以下几个过程Ø使用LOADRUNNER的VIRTUAL USER GENERATOR录制基本的测试脚本;Ø根据系统需求编辑测试脚本,看能否通过,Ø在单机模式下运行脚本看能否通过,1.选择协议要想正确的选择LOADRUNNER的脚本协议,首先要从LOADRNNER的工作原理上深入理解协议的作用和意义。

1Loadrunner名词解释响应时间:应用系统发出请求开始到收到服务器所有响应所耗费的时间;并发用户量: 同一时刻与服务器交互的所有用户数量;在线用户数:即同时在使用应用系统的用户,可能在浏览,可能在做交易。
并发用户怎么计算:●一般并发用户数取在线用户的10%-30%。
●八二原则:一般可以认为80%的用户在20%的时间内完成工作,所以峰值压力的时候,一般并发数要乘以80%/20%=4●Loadrunner里计算公式(1)计算平均的并发用户数:C = nL/T(2)并发用户数峰值:C’ ≈ C+3根号C公式(1)中,C是平均的并发用户数;n是login session的数量;L是login session 的平均长度;T指考察的时间段长度。
公式(2)则给出了并发用户数峰值的计算方式中,其中,C’指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。
该公式的得出是假设用户的login session产生符合泊松分布而估算得到的。
事务响应时间:处理一个事物花费的时间,包含网络传输时间和服务器处理事务的时间TPS: 每秒处理事务数量资源利用率: Cpu、内存、磁盘io、网络的使用情况;思考时间: 用户进行操作时,每个请求之间的时间间隔2性能测试包含了哪些软件负载测试:通过对被测系统不断加压,直到超过预定的指标或者部分资源达到了饱和不能再加压为止,就像举重的过程中不断加杠铃的重量,知道运动员不能举起。
压力测试:给系统增加一定的压力,在一定的压力下测试的cpu、内存、磁盘、网络使用情况,也即业务能否正常使用;并发测试:通过模拟用户并发访问,测试系统是否存在死锁、系统处理速度是否下降的比较厉害等问题;可靠性测试:在一定的业务压力下,让系统运行一段较长的时间,看系统能否无故障运行;3简述使用软件测试工具Loadrunner的步骤制定性能测试计划—>开发测试脚本—>设计测试场景—>执行测试场景—>监控测试场景—>分析测试结果4什么时候可以开始执行性能测试功能测试通过;一般需要进行性能测试的系统,都是用户量比较大、业务使用比较频繁、比较重要的功能模块。

在LoadRunner的脚步编写中,有三个重要的概念:事务、集合点、思考时间事务:事务又称为Transaction,在LoadRunner中的定义如下:An end-to-end(browser-to-browser) measurement of one or more user actions within action file。
中文理解如下:事务(Transaction)是这样一个点,我们为了衡量某个action的性能,需要在action的开始和结束位置插入这样一个范围,这就定义了一个transaction。
事务的作用:LoadRunner运行到该事务的开始点时,LoadRunner就会开始计时,直到运行到该事务的结束点,计时结束。
这个事务的运行时间在LoadRunner的运行结果中会有反映。
通俗的讲LoadRunner中的事务就是一个计时标识,LoadRunner在运行过程中一旦发现事务的开始标识,就开始计时,一旦发现事务的结束表示,则计时结束,这个过程中得到的时间即为一个事务时间。
通常事务时间所反映的是一个操作过程的响应时间。
下面我们说说为什么在LoadRunner中使用事务。
为什么使用事务的原因是多种多样的,总结下来如下五点所示:1、事务是LoadRunner度量系统性能指标的唯一手段;(没有事务则没有办法衡量系统的响应时间,也许有人说LoadRunner可以通过编程来计时得到,不错如果你编程能力够强是能够实现的,但肯定不如LoadRunner中的事务用的简单而且方便)2、事务能够用于度量高风险业务流程的性能指标;3、事务能够度量在一组操作中每一步的性能指标;4、通过事务计时实现了不同压力负载下的性能指标对比;5、通过事务计时可以帮助定位性能瓶颈;从性能测试的角度出发,我们需要知道不同的操作所花费的时间,这样我们就可以衡量不同的操作对被测系统所造成的影响,那么我们如何知道不同的操作所花费的时间,这就用到了事务,我们在操作之前插入一个事务开始标识,在操作完成后插入一个事务结束表示,这样我们就知道了这个操作所花费的时间。
LoadRunner响应时间与用户体验时间不一致问题的深入分析在新一代一期项目非功能测试过程中,我们发现了LoadRunner测试响应时间与客户端实际用户体验时间不一致的现象。
例如员工渠道上线后,客户体验时间远远超过了LoadRunner测试响应时间。
本文针对这一现象深入研究了导致二者不一致的原因并提供了意见和建议,现与大家分享。
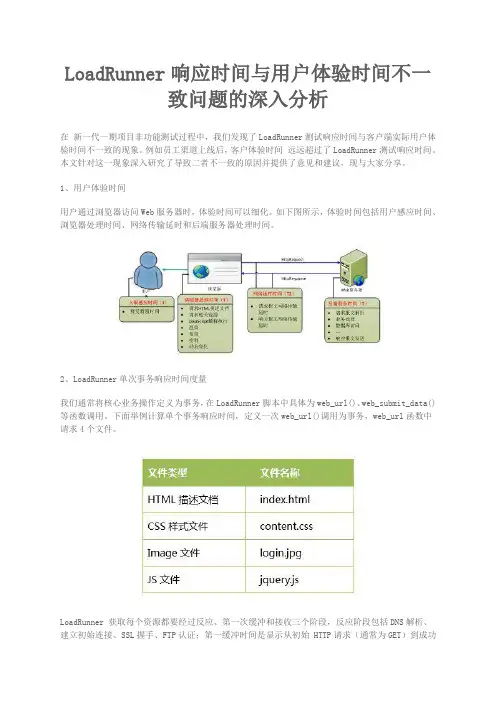
1、用户体验时间用户通过浏览器访问Web服务器时,体验时间可以细化。
如下图所示,体验时间包括用户感应时间、浏览器处理时间、网络传输延时和后端服务器处理时间。
2、LoadRunner单次事务响应时间度量我们通常将核心业务操作定义为事务,在LoadRunner脚本中具体为web_url()、web_submit_data()等函数调用。
下面举例计算单个事务响应时间,定义一次web_url()调用为事务,web_url函数中请求4个文件。
LoadRunner 获取每个资源都要经过反应、第一次缓冲和接收三个阶段,反应阶段包括DNS解析、建立初始连接、SSL握手、FTP认证;第一缓冲时间是显示从初始HTTP请求(通常为GET)到成功收到Web服务器返回的第一次缓冲所经过的时间;接收时间显示在服务器发出的最后一个字节到达,即下载完成之前所有的时间;客户端时间显示由于浏览器反应时间或其他客户端相关延迟而导致请求在客户机上延迟的平均时间。
LoadRunner 执行web_url()语句时,请求资源的先后顺序不依赖代码书写顺序,导致很难直接确定执行web_url()的开始时间,但可以借助LoadRunner的分析工具模块页面诊断器(Web Page Diagnostics)获取事务开始时刻和结束结束。
在Web Page Diagnostics中可以获取资源下载完成时刻(Scenario Elapsed Time)和花费时间(Page Component's Download Time),二者之差即为资源下载的开始时刻,资源开始下载的最小时刻为事务的开始时刻;在Web Page Diagnostics中资源下载完成时刻(Scenario Elapsed Time)最大值为事务的结束时刻。
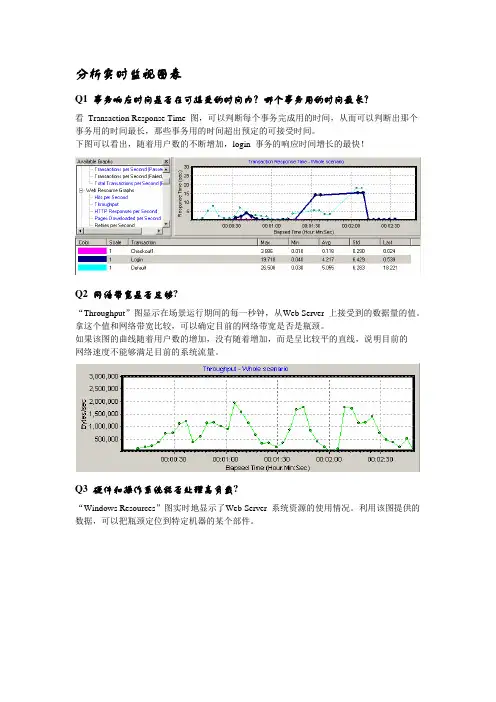
分析实时监视图表Q1 事务响应时间是否在可接受的时间内?哪个事务用的时间最长?看Transaction Response Time 图,可以判断每个事务完成用的时间,从而可以判断出那个事务用的时间最长,那些事务用的时间超出预定的可接受时间。
下图可以看出,随着用户数的不断增加,login 事务的响应时间增长的最快!Q2 网络带宽是否足够?“Throughput”图显示在场景运行期间的每一秒钟,从Web Server 上接受到的数据量的值。
拿这个值和网络带宽比较,可以确定目前的网络带宽是否是瓶颈。
如果该图的曲线随着用户数的增加,没有随着增加,而是呈比较平的直线,说明目前的网络速度不能够满足目前的系统流量。
Q3 硬件和操作系统能否处理高负载?“Windows Resources”图实时地显示了Web Server 系统资源的使用情况。
利用该图提供的数据,可以把瓶颈定位到特定机器的某个部件。
9 利用Analysis 分析结果场景运行结束后,需要使用Analysis 组件分析结果。
Analysis 组件可以在“开始程序”菜单中启动,也可以在Controller 中启动。
由于我本人对怎样分析结果最有效没有进行比较多的实践,所以这里只能按照常规的方法进行简单介绍。
注意:这里介绍的分析方法只适用于Web 测试。
9.1 分析事务的响应时间第一步,看“Transaction Performance Summary”图,确认那个事务的响应时间比较大,超出了我们的标准。
看下图,login 事务的平均响应时间最长。
然后我们再看“Average Transaction Response Time”,观察login 在整个场景运行中每一秒的情况。
从图中可以看出,login 事务的响应时间并不是一直都比较高,只是随着用户数的增加,响应时间才明显增加的。
然后我们再看“Average Transaction Response Time”,观察login 在整个场景运行中每一秒的情况。

LoadRunner常见测试结果分析(转)
在测试过程中,可能会出现以下常见的几种测试情况:
一、当事务响应时间的曲线开始由缓慢上升,然后处于平衡,最后慢慢下降这种情形表明:
* 从事务响应时间曲线图持续上升表明系统的处理能力在下降,事务的响应时间变长;
* 持续平衡表明并发用户数达到一定数量,在多也可能接受不了,再有请求数,就等待;
* 当事务的响应时间在下降,表明并发用户的数量在慢慢减少,事务的请求数也在减少。
如果系统没有这种下降机制,响应时间越来越长,直到系统瘫痪。
从以上的结果分析可发现是由以下的原因引起:
1. 程序中用户数连接未做限制,导致请求数不断上升,响应时间不断变长;
2. 内存泄露;
二、CPU的使用率不断上升,内存的使用率也是不断上升,其他一切都很正常;
表明系统中可能产生资源争用情况;
引起原因:
开发人员注意资源调配问题。
三、所有的事务响应时间、cpu等都很正常,业务出现失败情况;
引起原因:
数据库可能被锁,就是说,你在操作一张表或一条记录,别人就不能使用,即数据存在互斥性;
当数据量大时,就会出现数据错乱情况。

LoadRunner中的90%响应时间!LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。
为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?假如有两组测试结果,响应时间分别是{1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?为了解答上面的疑问,我们先来看一张表:在上面这个表中包含了几个不同的列,其含义如下:CmdID测试时被请求的页面NUM响应成功的请求数量MEAN所有成功的请求的响应时间的平均值STD DEV标准差(这个值的作用将在下一篇文章中重点介绍)MIN响应时间的最小值50 th(60/70/80/90/95 th)如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。
后面的60/70/80/90/95 th 也是同样的含义MAX响应时间的最大值我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。
我把结论性的东西整理一下:1.90%用户响应时间在LoadRunner中是可以设置的,你可以改为80%或95%;2.对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况;3.从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。

问题1:LoadRunner响应时间是什么?答:响应时间就是客户端发送请求,服务器返回最后(或者第)一个字节的时间。
LoadRunner的事务函数功能是度量客户端和服务器之间交互时间的。
事务函数最后在分析图表里有,比如你在前边开发脚本的时候你在登陆功能中添加了事务函数,那么controller中运行1000个用户之后,在分析图表中你就会看到1000个用户登录功能所消耗的时间(平均,其中1000个用户用的最多的时间,10000个用户用的最少的时间)。
问题2:页面点击数与页面浏览数什么概念,页面点击数过高会对系统的性能产生什么影响?答:页面点击数:又名“hits”,它包括了点击了某个网页后,浏览器为了显示此网页而附带来的所有图片等支持文件的数量。
“点击数”往往被用来衡量网站服务器的工作负载,也是衡量网站服务器性能的标准之一。
文件数量的增多,会增加网络流量。
页面浏览量(页面量):又名“PageView”,它是指实际被点击的网页数量。
“页面浏览量”往往被用来衡量网站内容的受欢迎程度和被访问情况。
问题3:在LoadRunner中有个Anget,这个Anget具体起什么作用啊?在讲Robot的架构的时候好像也提到过,但是没有讲Anget具体作用,是不是LR与Robot中Anget作用一样的呢?答:Agent 的作用是提供一个宿主环境提供虚拟用户运行,在LoadRunner中叫做Load Generator。
问题4:这个章节中讲到了“响应时间”、“页面点击数”、“吞吐量”这几个概念,我想问一下,“响应时间”越快是不是就越好?“页面点击数”越少是不是就越好?“吞吐量”越大是不是就越好?答:性能是寻找执行效率与功能之间的平衡。
这些不过是性能分析所关注的。
不是越大越好。
问题5:loadrunner如何选择协议?答:首先要熟悉应用程序的架构,采用什么协议进行通讯的.因为LoadRunner主要是通过捕获客户端与服务器之间的数据通讯包,根据这些数据包来生成脚本的.所以,如果协议选择不正确的话,LoadRunner就无法捕获客户端与服务器之间的数据通讯包。

Transactions(用户事务分析)用户事务分析是站在用户角度进行的基础性能分析。
1、Transation Sunmmary(事务综述)对事务进行综合分析是性能分析的第一步,通过分析测试时间内用户事务的成功与失败情况,可以直接判断出系统是否运行正常。
2、Average Transaciton Response Time(事务平均响应时间)“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向。
例:随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势。
3、Transactions per Second(每秒通过事务数/TPS)“每秒通过事务数/TPS”显示在场景运行的每一秒钟,每个事务通过、失败以及停止的数量,使考查系统性能的一个重要参数。
通过它可以确定系统在任何给定时刻的时间事务负载。
分析TPS主要是看曲线的性能走向。
将它与平均事务响应时间进行对比,可以分析事务数目对执行时间的影响。
例:当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。
4、Total Transactions per Second(每秒通过事务总数)“每秒通过事务总数”显示在场景运行时,在每一秒内通过的事务总数、失败的事务总署以及停止的事务总数。
5、Transaction Performance Sunmmary(事务性能摘要)“事务性能摘要”显示方案中所有事务的最小、最大和平均执行时间,可以直接判断响应时间是否符合用户的要求。
重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。
6、Transaction Response Time Under Load(事务响应时间与负载)“事务响应时间与负载”是“正在运行的虚拟用户”图和“平均响应事务时间”图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展用户系统提供参考。
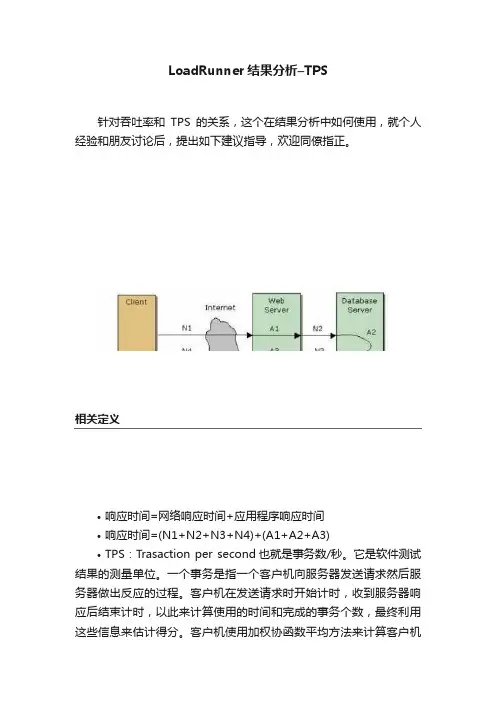
LoadRunner结果分析–TPS针对吞吐率和TPS的关系,这个在结果分析中如何使用,就个人经验和朋友讨论后,提出如下建议指导,欢迎同僚指正。
•响应时间=网络响应时间+应用程序响应时间•响应时间=(N1+N2+N3+N4)+(A1+A2+A3)•TPS:Trasaction per second也就是事务数/秒。
它是软件测试结果的测量单位。
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息来估计得分。
客户机使用加权协函数平均方法来计算客户机的得分,测试软件就是利用客户机的这些信息使用加权协函数平均方法来计算服务器端的整体TPS得分。
一般来说系统的TPS取决于系统事务最低处理能力的模块的TPS,经验值10-100•HPS:Hit per second也就是点击数/秒,指的是一秒钟的时间内用户对WEB页面的链接、提交按钮等点击的总和。
一般与TPS成正比关系,是衡量B/S系统的一个主要指标•Throughput/s:吞吐率,指的是每秒系统处理的客户的请求的数量,也可以理解为单位时间内客户接收到的服务的反馈量•吞吐率:测试过程中每秒从服务器返回的字节数。
从定义上来看,如果TPS很小,但是吞吐率比较大,说明服务器的返回的页面文件(字节数)是比较大的,此时根据页面细分图,如果存在页面问题,考虑页面压缩。
还应根据A1—A3,N1—N3实际考虑。
如果A1或者A3比较大,说明webserver处理可能存在问题,如果A2比较大,则说明DBserver处理存在问题,建议sql优化。
当增大系统的压力(或增加并发用户数)时,吞吐率和TPS的变化曲线呈大体一致,则系统基本稳定。
若压力增大时,吞吐率的曲线增加到一定程度后出现变化缓慢,甚至平坦,同时TPS也趋于平坦,查看系统资源使用,如果资源使用率比较低,说明服务器硬件资源不存在问题,查看网络流量,估计网络带宽存在问题。

1.1 分析事务的响应时间第一步,看“Transaction Performance Summary”图,确认那个事务的响应时间比较大,超出了我们的标准。
看下图,login 事务的平均响应时间最长。
为了定位问题,明白为什么login 事务的响应时间比较长,现在我们要分解login 事务,分析该页面上每一个元素的性能。
在上图中,选择要分解的事务曲线,然后点鼠标右键,选择“Web Page Breakdown for login”1.2 分解页面通过分解页面可以得到:比较大的响应时间到底是页面的哪个组件引起的?问题出在服务器上还是网络传输上。
这里为了解说各个时间(比如:DNS 解析时间、连接时间、接受时间等)下面简单说一下浏览器从发送一个请求到最后显示的全过程。
1.浏览器向Web Server 发送请求,一般情况下,该请求首先发送到DNS Server 把DNS名字解析成IP 地址。
解析的过程的时间就是。
这个度量时间可以确定DNS 服务器或者DNS 服务器的配置是否有问题。
如果DNS Server 运行情况比较好,该值会比较小。
2.解析出Web Server 的IP 地址后,请求被送到了Web Server,然后浏览器和WebServer 之间需要建立一个初始化连接,建立该连接的过程就是。
这个度量时间可以简单的判断网络情况,也可以判断Web Server 是否能够响应这个请求。
如果正常,该值会比较小。
3. 建立连接后,从Web Server 发出第一个数据包,经过网络传输到客户端,浏览器成功接受到第一字节的时间就是。
这个度量时间不仅可以表示WebServer 的延迟时间,还可以表示出网络的反应时间。
4. 从浏览器接受到第一个字节起,直到成功收到最后一个字节,下载完成止,这段时间就是。
这个度量时间可以判断网络的质量(可以用size/time 比来计算接受速率)其他的时间还有SSL Handshaking(SSL 握手协议,用到该协议的页面比较少)、ClientTime (请求在客户端浏览器延迟的时间,可能是由于客户端浏览器的think time 或者客户端其他方面引起的延迟)、Error Time(从发送了一个HTTP 请求,到Web Server 发送回一个HTTP 错误信息,需要的时间)。
Load Runner 使用说明一、组件:(一) VuGen:用于捕获最终用户业务流程和创建怎动化性能测试脚本。
1. 录制脚本:(1) 集合点Rendezvous(2) 验证点Check Point:文本验证点Text Check、图片验证点Image Check(3) 事务Transaction:事务开始Start Transaction、事务结束End Transaction(4) 注释与消息Comment & Message:/***/2. 增强并编辑Vuser脚本(1) 参数化:在Select next now中的参数:Sequential顺序、Random随机、Unique唯一在Update value on 参数:Each iteration每次迭代、Each occurrence每次出现、Once 一次(2) 从数据库中导入数据3. 配置动行时设置Runtime settings(运行时设置)(1) Number of Iterations:迭代次数(2) 在Preferences中的Enable image and text check在脚本中添加验证点时必须选中。
4. 在独立模式下运行Vuser脚本5. 集成Vuser脚本(二) Controller:用于组织、驱动、管理和监控负载测试。
1. 创建方案(1) 创建手动方案(2) 创建百分比模式方案(3) 创建面向目标的方案2. 计划方案(1) 开始时间(2) 方案运行设置:加压Ramp Up、持续时间Duration、减压Ramp Dowm3. 运行方案4. 监视方案(1) RuntimeGraphs(运行时图)A. Running Vusers运行时图:Running正在运行的Vuser总数、Ready完成脚本初始化部分、即可以运行的Vuser数、Finished结束运行的Vuser数,包括通过的和失败的、Error执行时发生的错误VuserB. Transaction Graphs事务监视图:Trans Response Time事务响应时间、Trans/Sec(Passed)每秒事务数(通过)、Trans/Sec(Failed/Stopped)每秒事务数(失败、停止)、Total Trans/Sec(Passed)每秒事务总数(通过)。
LoadRunner报告分析报告1. 引言本文将对LoadRunner的报告进行详细分析,帮助读者了解应用测试的性能瓶颈和优化方向。
LoadRunner是一款常用的性能测试工具,通过模拟真实用户的行为对系统进行压力测试,从而评估系统的性能和可靠性。
2. 报告概览在本节中,我们将对LoadRunner报告的整体概况进行分析。
报告包括以下几个关键指标:2.1 响应时间分析LoadRunner报告提供了每个请求的平均响应时间、最大响应时间和最小响应时间等指标。
通过对这些指标的分析,我们可以了解系统在不同负载下的响应情况。
2.2 事务响应时间分布LoadRunner报告还提供了事务响应时间的分布情况。
通过观察事务响应时间的分布情况,我们可以了解系统中存在的性能瓶颈和优化的空间。
2.3 错误分析LoadRunner报告中的错误分析可以帮助我们定位系统中出现的错误,并分析错误的原因。
通过对错误的分析,我们可以找到系统中的问题,并提出相应的解决方案。
3. 响应时间分析在这一节中,我们将对LoadRunner报告中的响应时间进行详细分析。
通过对响应时间的分析,我们可以了解系统在不同压力下的性能表现。
3.1 平均响应时间平均响应时间是衡量系统性能的重要指标之一。
根据报告显示的平均响应时间,我们可以了解系统对用户请求的平均处理时间。
如果平均响应时间过长,说明系统的性能存在问题,需要进一步优化。
3.2 最大响应时间最大响应时间是指系统处理用户请求的最长时间。
通过分析最大响应时间,我们可以找到系统中存在的性能瓶颈。
如果最大响应时间过长,可能会导致用户体验不佳,需要优化系统的性能。
3.3 最小响应时间最小响应时间是指系统处理用户请求的最短时间。
通过分析最小响应时间,我们可以了解系统在轻负载下的性能表现。
如果最小响应时间过长,可能会导致用户等待时间增加,需要优化系统的性能。
4. 事务响应时间分布在这一节中,我们将对LoadRunner报告中的事务响应时间分布进行分析。
1、Transactions(用户事务分析)用户事务分析是站在用户角度进行的基础性能分析。
1.1、TransationSunmmary(事务综述)对事务进行综合分析是性能分析的第一步,通过分析测试时间内用户事务的成功与失败情况,可以直接判断出系统是否运行正常。
1.2、Average Transaciton Response Time(事务平均响应时间)“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向。
例:随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势。
1.3、Transactions per Second(每秒通过事务数/TPS)“每秒通过事务数/TPS”显示在场景运行的每一秒钟,每个事务通过、失败以及停止的数量,是考查系统性能的一个重要参数。
通过它可以确定系统在任何给定时刻的时间事务负载。
分析TPS主要是看曲线的性能走向。
将它与平均事务响应时间进行对比,可以分析事务数目对执行时间的影响。
例:当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。
1.4、Total Transactions per Second(每秒通过事务总数)“每秒通过事务总数”显示在场景运行时,在每一秒内通过的事务总数、失败的事务总数以及停止的事务总数。
1.5、Transaction Performance Sunmmary(事务性能摘要)“事务性能摘要”显示方案中所有事务的最小、最大和平均执行时间,可以直接判断响应时间是否符合用户的要求。
重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。
1.6、Transaction Response Time Under Load(事务响应时间与负载)“事务响应时间与负载”是“正在运行的虚拟用户”图和“平均响应事务时间”图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展用户系统提供参考。
LoadRunner基础知识问答问题1:LoadRunner响应时间是什么?答:响应时间就是客户端发送请求,服务器返回最后(或者第)一个字节的时间。
LoadRunner的事务函数功能是度量客户端和服务器之间交互时间的。
事务函数最后在分析图表里有,比如你在前边开发脚本的时候你在登陆功能中添加了事务函数,那么controller中运行1000个用户之后,在分析图表中你就会看到1000个用户登录功能所消耗的时间(平均,其中1000个用户用的最多的时间,10000个用户用的最少的时间)。
问题2:页面点击数与页面浏览数什么概念,页面点击数过高会对系统的性能产生什么影响?答:页面点击数:又名“hits”,它包括了点击了某个网页后,浏览器为了显示此网页而附带来的所有图片等支持文件的数量。
“点击数”往往被用来衡量网站服务器的工作负载,也是衡量网站服务器性能的标准之一。
文件数量的增多,会增加网络流量。
页面浏览量(页面量):又名“PageView”,它是指实际被点击的网页数量。
“页面浏览量”往往被用来衡量网站内容的受欢迎程度和被访问情况。
问题3:在LoadRunner中有个Anget,这个Anget具体起什么作用啊?在讲Robot的架构的时候好像也提到过,但是没有讲Anget具体作用,是不是LR与Robot中Anget作用一样的呢?答:Agent 的作用是提供一个宿主环境提供虚拟用户运行,在LoadRunner中叫做Load Generator。
问题4:这个章节中讲到了“响应时间”、“页面点击数”、“吞吐量”这几个概念,我想问一下,“响应时间”越快是不是就越好?“页面点击数”越少是不是就越好?“吞吐量”越大是不是就越好?答:性能是寻找执行效率与功能之间的平衡。
这些不过是性能分析所关注的。
不是越大越好。
问题5:loadrunner如何选择协议?答:首先要熟悉应用程序的架构,采用什么协议进行通讯的.因为LoadRunner主要是通过捕获客户端与服务器之间的数据通讯包,根据这些数据包来生成脚本的.所以,如果协议选择不正确的话,LoadRunn er就无法捕获客户端与服务器之间的数据通讯包。
loadrunner响应时间和TPS例⼦:⼀个⾼速路有10个⼊⼝,每个⼊⼝每秒钟只能进1辆车1、请问1秒钟最多能进⼏辆车?TPS=102、每辆车需要多长时间进⾏响应?reponse time = 13、改成20辆车,每秒能进⼏辆?每辆车的响应时间是多长?TPS = 10,reponse time = 1 (10个为⼀等份,分成两等份,平均tps (10/1+10/2)/2=7.5 平均响应时间(2+1)/2=1.54、⼊⼝扩展到20个,每秒能进⼏辆?每辆车的响应时间是多长?TPS = 20,reponse time = 15、看看,现在TPS变了,响应时间没变,TPS和响应时间有关系吗?⽊有关系6、如何理解?TPS和响应时间在理想状态下都是额定值(联想运⾏⼀个压⼒测试场景来考虑),把⼊⼝看成线程池,如果有20个⼊⼝,并发数只有10的时候,TPS就是10,⽽响应时间始终是1,说明并发数不够,需要增加并发数达到TPS的峰值。
7、同样是20个⼊⼝,如果并发数变成100的话,TPS和响应时间会怎么样呢?并发数到100的时候,就会出现堵车,堵车了平均每个车过去的时间就长了,把100个车按照20⼀份分成5份,第5份的等待时间就是最长的,从等待开始到这个车进去,实际花费了5秒,那100辆车都过去的响应时间就是(5+4+3+2+1)/5=3,平均的TPS就是(20/1+20/2+20/3+20/4+20/5)/5=9.13(我怎么感觉应该是100/(5+4+3+2+1)=6.67 完成的事务总数/完成事务数的时间,使⽤该⽅法计算出来的tps会稍微⼩些,可以乘以1.5倍作为当前tps)8、由此可知,TPS和响应时间宏观上是倒数关系,但是两者实际上⽊有直接的关系的,在上例中,系统只存在20个线程,100的并发就会造成线程的等待,引起平均响应时间从1秒增加到3秒,TPS从20下降到9,TPS和响应时间都是单独计算出来的,并不是互相算出来的!9、同样可知,在并发量保持不变的情况下,提⾼TPS的⼿段有⼏种?A、增加线程池的数量(⼊⼝)B、降低每辆车⼊关的时间(也就是提⾼单个线程的处理效率)10、从TPS和response time的定义查看这2者的区别?TPS = 在场景或者灰化步骤运⾏的每⼀秒钟中,每个事务通过、失败以及停⽌的次数也就是说,TPS = 总的通过、失败的事务总数/整个场景的运⾏时间;reponse time = 每个事务完成实际需要的时间/事务处理数⽬因此,这2个东西压根就是⽊有关系的!-------------------------------------------------------------------------Jmeter聚合报告中的,吞吐量=完成的transaction数/完成这些transaction数所需要的时间;平均响应时间=所有响应时间的总和/完成的transaction数;失败率=失败的个数/transaction数。
这里的响应时间不包含客户端GUI时间(例如浏览器解释页面所消耗的时间)。
前面说响应时间是用户请求发出和服务器返回之间的时间差,那么得到这个时间就够了吗?例如:现在有一场跑步比赛。
当比赛完成后,可以得到每位运动员跑完整个比赛所需要消耗的时间,现在需要分析谁的起跑好、谁的冲刺好,能分析出来吗?答案是不能,虽然得到了最重要的完成比赛的响应时间,但是这对分析和优化几乎没有作用,因为只知道了结果而不知道过程。
跑步的时间是由起跑、中途、冲刺等时间组成的,如果想要进行分析优化,必须先了解各个阶段所花费的时间和速度以及各个运动员的优缺点。
对于软件来说,通过事务得到的系统响应时间也是由非常多的部分组成的,一般来说响应时间由网络时间、服务器处理时间、网络延迟三大部分组成。
先来看看当一个客户端发出请求到服务器返回需要经历哪些路径,如图2所示。
1.网络时间客户端发出请求首先通过网络来到Web Server上(消耗时间为N1);然后Web Server 将处理后的请求发送给App Server(消耗时间为N2);App Server将操作数据指令发送给Database (消耗时间为N3);Database服务器将查询结果数据发送回App Server(消耗时间为N4);App Server将处理后的页面发给Web Server(消耗时间为N5);最后Web Server 将HTML转发到客户端(消耗时间为N6)。
这里的Nx都是网络传输上的时间开销,没有计算业务处理所需要花费的时间。
2.服务器处理时间另外一个方面还要考虑各个服务器处理所需要的时间WT、AT、DT。
3.网络延迟除了上面两种时间开销以外,还要考虑网络延迟的问题。
所以最终的响应时间组成为:响应时间= 网络延迟时间+ WT+AT+DT +(N1+N2+N3)+(N4+N5+N6)+ WT+AT+DT 也可以简单认为响应时间由网络开销(前端)和服务器开销(后端)两大部分组成,如图3所示。
这里的响应时间不包含客户端GUI时间(例如浏览器解释页面所消耗的时间)。
前面说响应时间是用户请求发出和服务器返回之间的时间差,那么得到这个时间就够了吗?例如:现在有一场跑步比赛。
当比赛完成后,可以得到每位运动员跑完整个比赛所需要消耗的时间,现在需要分析谁的起跑好、谁的冲刺好,能分析出来吗?答案是不能,虽然得到了最重要的完成比赛的响应时间,但是这对分析和优化几乎没有作用,因为只知道了结果而不知道过程。
跑步的时间是由起跑、中途、冲刺等时间组成的,如果想要进行分析优化,必须先了解各个阶段所花费的时间和速度以及各个运动员的优缺点。
对于软件来说,通过事务得到的系统响应时间也是由非常多的部分组成的,一般来说响应时间由网络时间、服务器处理时间、网络延迟三大部分组成。
先来看看当一个客户端发出请求到服务器返回需要经历哪些路径,如图2所示。
1.网络时间客户端发出请求首先通过网络来到Web Server上(消耗时间为N1);然后Web Server 将处理后的请求发送给App Server(消耗时间为N2);App Server将操作数据指令发送给Database (消耗时间为N3);Database服务器将查询结果数据发送回App Server(消耗时间为N4);App Server将处理后的页面发给Web Server(消耗时间为N5);最后Web Server 将HTML转发到客户端(消耗时间为N6)。
这里的Nx都是网络传输上的时间开销,没有计算业务处理所需要花费的时间。
2.服务器处理时间另外一个方面还要考虑各个服务器处理所需要的时间WT、AT、DT。
3.网络延迟除了上面两种时间开销以外,还要考虑网络延迟的问题。
所以最终的响应时间组成为:响应时间= 网络延迟时间+ WT+AT+DT +(N1+N2+N3)+(N4+N5+N6)+ WT+AT+DT 也可以简单认为响应时间由网络开销(前端)和服务器开销(后端)两大部分组成,如图3所示。
那么这些消耗的时间都花在什么事情上了呢?影响网络的因素一般包括以下内容:1.前端NetworkDNS LookupTime to connectTime to first bufferNetwork TimeDownload TimeSSL handshakeFTP authenticationClient TimeError Time网络延迟2.后端服务Web ServerServlet TimeMethod Time静态动态压缩App ServerEJB Time响应时间这是事务的目的,通过事务记录业务操作所消耗的响应时间。
事务自身时间事务中哪怕没有操作,也是需要时间的,不过这个时间一般在0.01秒左右,所以可以忽略。
1.lr_start_transaction("thinktime");2.lr_end_transaction("thinktime", LR_AUTO);运行上面的脚本后,可以看到:1.Action.c(5): Notify: Transaction "thinktime" started.2.Action.c(9): Notify: Transaction "thinktime" ended with "Pass" status (Duration: 0.0121).思考时间(Think Time)Think Time是LoadRunner提供的一种模拟用户等待的方式,通过lr_think_time()函数实现。
在函数内写入对应的时间(单位是秒),当脚本在Controller中运行到该函数时就会等待相应的时间。
注意在VuGen中,回放Think Time默认关闭。
Think Time在进行性能测试的时候需要打开,只有这样每个虚拟用户才是真正按照用户的操作速度来完成请求,才能得到在真实情况下的系统数据。
如果不打开Think Time,测试获得的数据是在全负载下的一些理论峰值数据。
那么Think Time 在事务中如何影响事务时间呢?编写如下脚本:1.lr_start_transaction("thinktime");2.lr_think_time(5);3.lr_end_transaction("thinktime", LR_AUTO);在Run-time Settings中设置Think Time,启用Replay Think Time功能,运行之后可以看到以下结果:1.Action.c(5): Notify: Transaction "thinktime" started.2.Action.c(7): lr_think_time: 5.00 seconds.3.Action.c(9): Notify: Transaction "thinktime" ended with"Pass" status (Duration: 5.0254 Think Time: 4.9995).所以Think Time 会被算在事务的时间内,不过在Analysis中可以设置过滤规则将其扣除,另外我们也建议尽量不要在事务内使用lr_think_time()函数。
浪费时间(Wasted Time)在使用事务的时候,经常会看到在事务日志中有Wasted Time。
Wasted Time是指事务中应该扣除的由于其他原因导致的时间浪费。
在默认情况下LoadRunner会将自身脚本运行浪费的时间自动记入Wasted Time。
例如执行关联、检查点等函数的时间。
除了脚本自身浪费的时间,某些时候使用C语言等外部接口进行处理所消耗的时间也会影响事务的时间,而这个时间LoadRunner无法处理,在这种情况下就需要人为地计算第三方时间开销,并且将这个开销的时间记入Wasted Time中。
运行一下下面的代码:1.Action()2.{3. int i;4. int baseIter = 100;5. char dude[1000];6. merc_timer_handle_t timer;7. // Examine the total elapsed time of the action8. //Start transaction9. lr_start_transaction("Demo");10.timer=lr_start_timer();11. for (i=0;i<=baseIter*1000;i++) {12. sprintf(dude,"This is the way we waste time in a script =%d", i);13. }14. wasteTime=lr_end_timer(timer); //时间单位为毫秒15. lr_wasted_time(wasteTime*1000);//将wasteTime转换为秒并计入lr的Wasted Time,当在场景中运行的时候,事务的响应时间会自动扣除Wasted Time16. lr_end_transaction("Demo", LR_AUTO);17. return 0;18.}其中,lr_start_timer()是一个LoadRunner自带的时间计数器,它和lr_end_timer()相对应,能够返回这两个函数间的时间差。
运行脚本后,等待一段时间脚本运行结束,可以看到以下日志。
1.Action.c(18): Notify: Transaction "Demo" started.2.Action.c(27): wasted time is 85.8600003.Action.c(28): Notify: Transaction "Demo" ended with"Pass" status (Duration: 85.8772 Wasted Time: 85.8600).通过上面这个日志可以看到,在VuGen运行脚本的时候这个1000次的C语言操作所消耗的时间会被算在Transaction时间内,导致Transaction的时间变长。
当通过lr_start_timer()计时函数将这个消耗时间加入Wasted Time后,这个脚本就能正确地计算出事务的时间和该事务时间的Wasted Time了。
当在场景中运行的时候,事务的响应时间会自动扣除Wasted Time。
为了确保响应时间的正确,需要扣除在运行脚本时自身的时间消耗,事务中尽量避免出现非请求的处理内容,如果无法避免请使用lr_wasted_time()函数将多余的时间开销扣除。
例如这样的脚本:1.merc_timer_handle_t timer; //变量声明2.lr_start_transaction("Demo");3.timer=lr_start_timer();4.lr_load_dll("getkey.dll");5.lr_save_string(getrandkey(),"key");6.//通过调用dll获得密钥7.wasteTime=lr_end_timer(timer);8.lr_wasted_time(wasteTime*1000);9.lr_end_transaction("Demo", LR_AUTO);计算密钥是很消耗时间的,那么可以使用timer这个变量来记录计算的时间,并将这个时间从整个事务中扣除。
在计算Wasted Time时不要直接使用lr_wasted_time()覆盖,而忘了加上脚本中LoadRunner函数的自身时间。
通过lr_get_transaction_wasted_time()函数可以获得事务自身的Wasted Time,将这个时间累加上第三方统计的Wasted Time再通过lr_wasted_time()函数覆盖。
3.手工事务前面都是使用LR_AUTO来自动判断事务状态,现在来做一个脚本,看看LoadRunner 的事务是如何自动判断状态的。
录制一个论坛注册用户的脚本,在提交注册表单处添加事务开始及结束标志,然后回放该脚本。
事务的结果是PASS还是FAIL呢?虽然回放脚本注册用户是失败的(该用户已经存在),但是事务还是在PASS状态下完成了,而且会发现事务的持续时间很短。