文本分类入门(八)中英文文本分类的异同
- 格式:doc
- 大小:21.50 KB
- 文档页数:1

文本分类入门(八)中英文文本分类的异同预览说明:预览图片所展示的格式为文档的源格式展示,下载源文件没有水印,内容可编辑和复制从文本分类系统的处理流程来看,无论待分类的文本是中文还是英文,在训练阶段之前都要经过一个预处理的步骤,去除无用的信息,减少后续步骤的复杂度和计算负担。
对中文文本来说,首先要经历一个分词的过程,就是把连续的文字流切分成一个一个单独的词汇(因为词汇将作为训练阶段“特征”的最基本单位),例如原文是“中华人民共和国今天成立了”的文本就要被切分成“中华/人民/共和国/今天/成立/了”这样的形式。
而对英文来说,没有这个步骤(更严格的说,并不是没有这个步骤,而是英文只需要通过空格和标点便很容易将一个一个独立的词从原文中区分出来)。
中文分词的效果对文本分类系统的表现影响很大,因为在后面的流程中,全都使用预处理之后的文本信息,不再参考原始文本,因此分词的效果不好,等同于引入了错误的训练数据。
分词本身也是一个值得大书特书的问题,目前比较常用的方法有词典法,隐马尔科夫模型和新兴的CRF方法。
预处理中在分词之后的“去停止词”一步对两者来说是相同的,都是要把语言中一些表意能力很差的辅助性文字从原始文本中去除,对中文文本来说,类似“我们”,“在”,“了”,“的”这样的词汇都会被去除,英文中的“ an”,“in”,“the”等也一样。
这一步骤会参照一个被称为“停止词表”的数据(里面记录了应该被去除的词,有可能是以文件形式存储在硬盘上,也有可能是以数据结构形式放在内存中)来进行。
对中文文本来说,到此就已初审合格,可以参加训练了(笑)。
而英文文本还有进一步简化和压缩的空间。
我们都知道,英文中同一个词有所谓词形的变化(相对的,词义本身却并没有变),例如名词有单复数的变化,动词有时态的变化,形容词有比较级的变化等等,还包括这些变化形式的某种组合。
而正因为词义本身没有变化,仅仅词形不同的词就不应该作为独立的词来存储和和参与分类计算。

中文文本分类概述作者:栗征征来源:《电脑知识与技术》2021年第01期摘要:在大数据时代,随着网络上的文本数据日益增长,文本分类技术显得越来越重要,是文本挖掘领域的热点问题,具有广阔的应用场景。
文本分类方法的研究开始于20世纪50年代,一直受到人们的广泛关注。
该文从文本分类的流程出发,简要介绍文本分类的一般流程以及每一步骤中涉及的主要技术。
主要包括预处理部分的分词、去停词和文本表示方法、特征降维和分类算法,分析了各种方法的优缺点并总结。
关键词:文本分类;预处理;特征降维;分类算法中图分类号:TP3 文献标识码:A文章编号:1009-3044(2021)01-0229-021文本分类简介概念:文本分类是自然语言处理中的重要学科,其目的是在已知的分类中,根据给定文本内容自动确定其所属文本类别的过程。
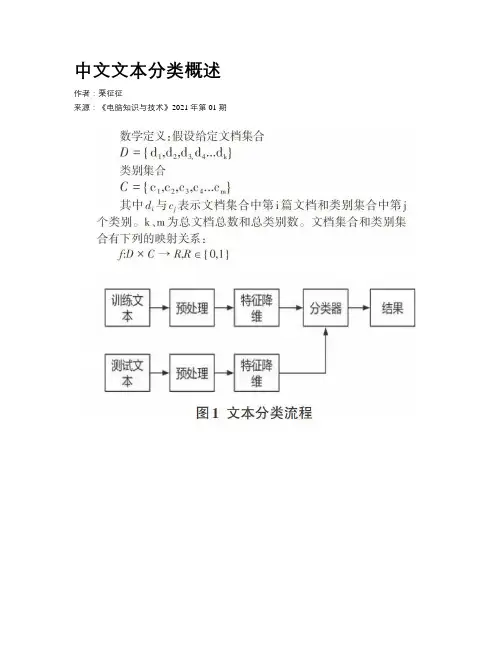
文本分类可分两个阶段:训练与测试,每个阶段又涉及预处理、特征降维、训练分类器三个步骤。
预处理包括分词、去停词、文本表示等;特征降维主要用到的方法有词频-逆文档频率(tf-idf)、卡方统计等;目前主流的分类器包括:支持向量机(SVM)、朴素贝叶斯(NB)、K近邻等[1]。
如图1所示。
预处理:将文本数据转换为计算机可处理形式。
特征选择:由于文本内容复杂,难以用简单的方法表示,一般情况下文本的特征会达到很高的维度,特征选择可以降低维度从而使运算速度和准确率得到提高。
分类器:对分类器进行训练。
2关键技术2.1 预处理预处理主要包括两大部分:分词、去停用词和文本表示。
(1)分词、去停用词分词。
中文文本与英文文本的分词区别在于英文可以根据空格来将词语分开,中文则需要用一定算法来讲文本分为词序列。
分词是自然语言处理的中的第一步,对中文来说更为重要。
在目前的文本分类研究中,大多使用成熟的分词系统如jieba分词,來进行分词的工作,可以取得较好的效果。
去停用词。
在文本中会使用无实意的虚词、代词、名词等,这些词的出现频率高,而且对文本的分析无太大影响,更会加重运算负担,因此需要将此类词语去除[2]。


文本类型及相关翻译策略文本类型及相关翻译策略摘要:文本类型是语言学、语用学里一项重要的内容,其发展的历史轨迹也影响到了翻译的方方面面。
文本的分类是翻译的参考性依据,近些年来也引起越来越多的关注,不少人致力于文本类型及翻译策略的研究。
其中,德国翻译理论家凯瑟琳莱斯提出的文本类型理论不仅为翻译研究、方法和翻译批评的科学化提供了理论依据,同时也为如何精准翻译提供了具体可操作的方法。
关键词:文本类型理论;翻译策略;凯瑟琳莱斯一、文本类型理论长久以来,语言一直被分为功能性语言(functional language)和文学性语言(literary language),如果硬要通俗点说,可能和日常生活中我们所说的口头语和书面语是较为类似的。
由此可见,两种语言的所用的地点和所起的作用是不尽相同的。
再进一步细化,Karl Buhler将其分为信息性文本(informative),表达性文本(expressive),还有呼唤性文本(vocative),这三种类型也与人认知的三方面相切合:思考(thinking or perceiving),感觉(feeling)和意愿(willing)。
凯瑟琳娜莱斯 (Katharine Reiss)是德国功能派翻译理论的代表人物之一。
她认为翻译前必须先对翻译材料进行文本类型分类,然后根据文本类型选择合适的翻译策略和方法。
根据之前的三种分类,莱斯进行了详尽的解释:1)信息功能文本 (informative),凡是旨在传递信息、知识、意见等事实的文本,皆属于信息功能文本,文本的重心在其内容和主题;2)表达功能文本 (expressive),强调文本的创造性构建和语言的美学层面,突出文本作者及文本本身;3)呼唤功能文本(vocative),旨在通过说服文本读者或者接受者采取某种行动,从行为上对文本作出反应,其语言特点是对话式的,文本的重点在于感召。
这三种文本也与人际交流和沟通的三方面相对应:发送人(sender, speaker or writer),接受人(receiver, hearer or reader),话题(topic or information)。

英语中的文本解读与分析知识点在学习英语文本解读与分析时,我们需要掌握一些重要的知识点。
本文将介绍一些基本的文本解读与分析技巧,帮助你更好地理解英语文本。
以下是一些关键知识点:1. 文本类型在进行文本解读与分析时,首先需要确定文本的类型。
英语中常见的文本类型包括散文、诗歌、小说、新闻报道等。
不同类型的文本有不同的语言特点和结构,因此我们需要根据文本类型选择适当的解读与分析方法。
2. 关键词与词义推测在进行文本解读与分析时,我们需要注意关键词的选择和词义的推测。
关键词通常是文章中具有特殊意义或重要作用的词语,通过理解关键词的含义,可以更好地把握文本的主题和中心思想。
3. 上下文推导上下文推导是文本解读与分析的重要方法之一。
通过理解文本中的上下文信息,可以推导出未知词汇或句子的含义。
上下文推导常常涉及到词汇的同义替换、反义替换等技巧,通过这些方法我们可以更准确地理解文本的意思。
4. 文本结构与段落分析文本的结构和段落安排对理解全文的意思非常重要。
在进行文本解读与分析时,我们需要关注文本的开头、结尾和重要段落,分析段落之间的逻辑关系以及段落内部的组织结构。
通过对文本结构和段落的分析,我们可以更好地理解作者的意图和观点。
5. 修辞手法与语言特点修辞手法是作者在表达意思时常用的一些技巧,包括比喻、拟人、夸张等。
在进行文本解读与分析时,我们需要注意作者使用的修辞手法,并分析其在文本中的作用和效果。
同时,我们还需要注意不同文体和时期的语言特点,了解语言的变化和发展,有助于更好地理解文本。
6. 文本主题与中心思想理解文本的主题和中心思想是文本解读与分析的核心内容。
通过分析文本各个方面的细节,我们可以揭示出文本的主题和中心思想。
同时,我们还需要注意作者在文本中的态度、观点和情感色彩,这些对于理解文本意思非常重要。
7. 文化背景与历史背景英语中的文本解读与分析也需要了解一定的文化背景和历史背景。
文本中可能存在一些与当时社会、文化和历史相关的信息,了解这些背景知识可以帮助我们更好地理解文本并把握作者的用意。

英文文本分类
English Text Classification is the process of categorizing text data into different classes or categories according to certain content characteristics. It can be used for sentiment analysis, categorization of topics, and to make decisions about documents. For example, it can be employed to determine if a customer feedback is positive or negative, to decide what category a news article belongs to, or to assign a legal or medical document to the appropriate category.
英文文本分类是指根据某些内容特征将文本数据分类为不同的类别或类别的过程。
它可以用于情感分析、主题分类,以及对文档做出决策。
例如,它可以用于判断客户反馈是正面的还是负面的,决定一篇新闻文章属于哪一类,或将法律或医疗文档分配到合适的类别。

篇章语体对比汉英书面文章都可分为事务语体、科技语体、政论语体和文艺语体四类。
四类语体在英语和汉语中都有共同的语言特点。
1)事务语体是国家机关、社会团体、以及人民群众之间相互处理事务的一种语体,它包括公文文件、规章制度、日常应用文三大类。
如通知、公告、调查报告,法规、条例、注意事项、书信、条据、使用说明等。
事务语体在语言上的特点有:第一,有固定的程式,如中英文信件,如何开头、如何落款都各有其固定格式。
第二,有一套固定的习惯用语。
如中文信中称谓很少用“亲爱的”字眼,但英文中不论对方是谁一律冠以“Dear …”。
中文里的某些习惯用语还保留了一些古语成分,如“此致”、“兹”、“特此函达”等;英文也有自己的一套语言模式,如“Sincerely yours”、“Y ours truly”等。
第三,事务语体用词明晰准确,避免发生歧义和误解。
句式周密,严谨,简练。
例如:甲方和乙方本着友好合作的精神签订本合同,根据合同,甲方聘请乙方为外籍工作人员,合同条款如下:This contract is made in a spirit of friendly cooperation by and between Party A and B, whereby Party A shall invite Party B for service as “Foreign staff on the terms and conditions stipulated as follows:2)科技语体包括科学专著、学术论文、科技报告等。
最大的特点是专门术语多,词义单一、精确。
句子较长且复杂,句法完整、严密。
英文科技语体还以客观性(objectivity)、非人化(impersonal style) 和多用被动式而区别于其它文体。
如:本文介绍了以传统机车外型为基础、对机车端部适当流线化的准高速机车气动外型的设计方法,并具体应用到韶山8型准高速电力机车气动外型多方案设计,最后风洞实验证明此种设计方法是可行的。



文本分类方法总结李荣陆(复旦大学计算机与信息技术系,上海,200433)E-mail: lironglu@一、Swap-1方法1,特点:特征选择:将只在某一类中出现的词或短语作为这一类的特征,词频作为权重。
二、n-gram方法1,N-Gram-Based Text Categorization(1)特点:n-gram项的生成:为了得到字符串中结尾部分的字符串,对不够n的字符串追加空格。
如:Text的3-gram项为_Te、Tex、ext、xt_、t__。
类的表示:先计算类别中所有训练文本的n-gram项的词频,然后按词频对其由大到小进行排序,最后保留从第n(实验中等于300)项开始的k个n-gram项作为此类的特征值。
相似度计算:(2)优点:容错性强,可以允许文本中有拼写错误等噪声。
(3)用途:区分测试文档是何种语言,即语言分类;自动文本分类2,CAN Bayes(Chain Augmented Naive Bayes)Bayes 分类器是一个性能很好的线性分类器,但是它假设文档的每个分类特征属性间是相互独立的,这显然是不成立的。
假设d i ={w i1,w i2,…,w in }为一任意文档,它属于文档类C ={c 1, c 2,…, c k }中的某一类c j 。
根据Bayes 分类器有:)()|()()()|()|(j j i i j j i i j c P c d P d P c P c d P d c P ∝=,其中∏==rk j ik j i c w P c d P 1)|()|(。
如果使用Bayes 网络来描述特征属性间的联系,则失去了Bayes 模型的简单性和线性特征。
我们使用了统计语言学中的N-Gram 模型,它假设一个词在文档中某个位置出现的概率仅与它之前的n-1个词有关,即:)|()|(11121--+--=i n i n i i i i w w w w P w w w w P 。
英文文本分类
英文文本分类是指将一些英文文本进行分类,从而对其建立一个分类系统,将文本归类到不同的类型中。
它可以帮助搜索引擎快速地识别出文本属于哪种类别,并将相关内容放到正确的位置,从而提升搜索效率。
英文文本分类可以分为三大类:初步分类、特征分类和应用分类。
一、初步分类
初步分类是最基本的英文文本分类方法,简单的分类方法是根据文本的关键字来划分,不同的关键字会被划分到不同的类别中。
例如,包含“科技”和“IT”关键字的文本可以被划分到“科技/IT”类别中,而包含“娱乐”和“影视”关键字的文本可以被划分到“娱乐/影视”类别中。
二、特征分类
特征分类是指根据文本本身的特征来对文本进行分类。
例如,文本中包含的词性、句法结构等都可以作为特征来判断文本的类别。
例如文本中含有大量历史性的信息,可以划分到“历史”类别中。
三、应用分类
应用分类是指根据文本的实际应用来分类,这种分类方法常常在自然语言处理中使用,如文本分析、信息检索
等方面。
例如,对于搜索引擎等应用,可以将文本分为“新闻”、“百科”等不同类别,从而更有效地搜索到相关内容。
英文文本分类是一种有用的工具,它可以帮助搜索引擎或者自然语言处理系统更快更准确地识别文本的类别,从而提高搜索的准确率。
它可以分为初步分类、特征分类和应用分类三大类,可以根据不同的需要来使用。
英语文学体裁分类方法与中文的异同中国文学体裁有7种,分别是诗歌,小说,散文,剧本,剧小说,寓言,通讯。
英语的体裁一共有四种,分别是narration 记叙文、argumentation 议论文、exposition 应用文、description说明文等。
1、narration 记叙文:
记叙文是以记人、叙事、写景、状物为主,以写人物的经历和事物发展变化为主要内容的一种文体形式。
2、argumentation 议论文:
议论文,又叫说理文,是一种剖析事物论述事理、发表意见、提出主张的文体。
作者通过摆事实、讲道理、辨是非等方法,来确定其观点正确或错误,树立或否定某种主张。
议论文应该观点明确、论据充分、语言精炼、论证合理、有严密的逻辑性。
3、exposition 应用文:
应用文是人类在长期的社会实践活动中形成的一种文体,是国家机关、政党、社会团体、企业事业单位在日常工作、生活中处理各种事物时,经常使用的具有明道、交际、信守和约定成俗的惯用格式文体。
4、description 说明文:
说明文是一种以说明为主要表达方式的文章体裁。
它通过对实体事物科学地解说,对客观事物做出说明或对抽象事理的阐释,使
人们对事物的形态、构造、性质、种类、成因、功能、关系或对事理的概念、特点、来源、演变、异同等能有科学的认识,从而获得有关的知识。
在英语中议论文和说明文都属于说明性的写作,两者的区别在于前者旨在阐明观点,而后者在于阐释明理。
从文本分类系统的处理流程来看,无论待分类的文本是中文还是英文,在训练阶段之前都要经过一个预处理的步骤,去除无用的信息,减少后续步骤的复杂度和计算负担。
对中文文本来说,首先要经历一个分词的过程,就是把连续的文字流切分成一个一个单独的词汇(因为词汇将作为训练阶段“特征”的最基本单位),例如原文是“中华人民共和国今天成立了”的文本就要被切分成“中华/人民/共和国/今天/成立/了”这样的形式。
而对英文来说,没有这个步骤(更严格的说,并不是没有这个步骤,而是英文只需要通过空格和标点便很容易将一个一个独立的词从原文中区分出来)。
中文分词的效果对文本分类系统的表现影响很大,因为在后面的流程中,全都使用预处理之后的文本信息,不再参考原始文本,因此分词的效果不好,等同于引入了错误的训练数据。
分词本身也是一个值得大书特书的问题,目前比较常用的方法有词典法,隐马尔科夫模型和新兴的CRF方法。
预处理中在分词之后的“去停止词”一步对两者来说是相同的,都是要把语言中一些表意能力很差的辅助性文字从原始文本中去除,对中文文本来说,类似“我们”,“在”,“了”,“的”这样的词汇都会被去除,英文中的“ an”,“in”,“the”等也一样。
这一步骤会参照一个被称为“停止词表”的数据(里面记录了应该被去除的词,有可能是以文件形式存储在硬盘上,也有可能是以数据结构形式放在内存中)来进行。
对中文文本来说,到此就已初审合格,可以参加训练了(笑)。
而英文文本还有进一步简化和压缩的空间。
我们都知道,英文中同一个词有所谓词形的变化(相对的,词义本身却并没有变),例如名词有单复数的变化,动词有时态的变化,形容词有比较级的变化等等,还包括这些变化形式的某种组合。
而正因为词义本身没有变化,仅仅词形不同的词就不应该作为独立的词来存储和和参与分类计算。
去除这些词形不同,但词义相同的词,仅保留一个副本的步骤就称为“词根还原”,例如在一篇英文文档中,经过词根还原后,“computer”,“compute”,“computing”,“computational”这些词全都被处理成“compute”(大小写转换也在这一步完成,当然,还要记下这些词的数目作为compute的词频信息)。
经过预处理步骤之后,原始文档转换成了非常节省资源,也便于计算的形式,后面的训练阶段大同小异(仅仅抽取出的特征不同而已,毕竟,一个是中文词汇的集合,一个是英文词汇的集合嘛)。
下一章节侃侃分类问题本身的分类。