多元统计分析聚类分析的各种方法spss
- 格式:docx
- 大小:74.00 KB
- 文档页数:10

论文写作中如何利用SPSS进行多元统计分析在当今大数据时代,统计分析成为了各个领域研究的重要工具。
而SPSS (Statistical Package for the Social Sciences)作为一款专业的统计分析软件,被广泛应用于学术研究中。
本文将从多元统计分析的角度出发,探讨如何在论文写作中充分利用SPSS进行数据分析。
一、数据准备在进行多元统计分析之前,首先需要准备好可靠的数据。
数据的质量和完整性对于分析结果的准确性至关重要。
在数据准备阶段,可以通过SPSS软件进行数据清洗、缺失值处理和异常值检测等操作,以确保数据的可靠性。
二、描述性统计分析在进行多元统计分析之前,了解数据的基本情况是必要的。
通过SPSS的描述性统计分析功能,可以获得数据的均值、标准差、最大值、最小值等统计指标。
此外,还可以通过绘制直方图、箱线图等图表来展示数据的分布情况,为后续的分析提供基础。
三、相关性分析相关性分析是多元统计分析的重要环节之一。
通过SPSS的相关性分析功能,可以计算各个变量之间的相关系数,从而了解它们之间的关系。
相关系数的取值范围为-1到1,当相关系数接近1时,表示两个变量呈正相关;当相关系数接近-1时,表示两个变量呈负相关;当相关系数接近0时,表示两个变量之间没有线性关系。
通过相关性分析,可以帮助研究者深入了解变量之间的相互作用,为后续的因果分析提供依据。
四、因素分析因素分析是一种常用的降维技术,可以将大量的变量转化为少数几个因素,从而简化数据分析的复杂度。
通过SPSS的因素分析功能,可以识别出主要的因素,并计算出各个变量对于每个因素的贡献度。
因素分析可以帮助研究者发现变量之间的内在联系,提取出潜在的因素,从而更好地理解研究对象。
五、聚类分析聚类分析是一种无监督学习的方法,可以将数据样本划分为不同的类别或群组。
通过SPSS的聚类分析功能,可以根据变量之间的相似性将样本进行分类,从而发现数据中的内在结构。



多元统计分析与SPSS多元统计分析是指通过应用多个统计方法和技术对多个变量之间的关系进行分析的一种统计分析方法。
SPSS(Statistical Package for the Social Sciences)是一个常用的统计分析软件,可以对大规模的数据集进行多元统计分析。
多元统计分析包括多个方法和技术,如多元方差分析、主成分分析、因子分析、聚类分析、判别分析等。
这些方法和技术可以帮助我们理解变量之间的关系,预测和解释数据,并支持决策制定。
通过使用SPSS软件,可以更轻松地进行这些分析。
在多元方差分析中,可以通过比较组别间的平均差异来检验因素对变量的影响;在主成分分析中,可以通过降低变量维度来提取主要的变化模式;在因子分析中,可以通过识别潜在的构念来简化变量之间的关系;在聚类分析中,可以通过将观测值划分为不同的群组来发现变量之间的模式;在判别分析中,可以根据已知组别来预测新观测值的组别。
SPSS软件提供了各种功能和工具,以便于使用者进行多元统计分析。
用户可以使用SPSS进行数据导入和数据清理,选择适当的多元统计方法和技术,设定分析的参数和条件,并生成相应的统计结果和图表。
此外,SPSS还提供了一些数据分析模板和指导,帮助用户更好地理解和使用多元统计分析方法。
在实际应用中,多元统计分析和SPSS广泛应用于社会科学、经济学、市场研究、医学和生物学等领域。
例如,研究者可以使用多元统计分析和SPSS来研究消费者行为模式、预测市场需求、评估治疗效果等。
企业可以使用多元统计分析和SPSS来进行市场细分、产品定位和品牌定位。
医生可以使用多元统计分析和SPSS来研究临床疗效、预测疾病发展等。
总而言之,多元统计分析是一种强大的统计方法,可以帮助我们理解和解释变量之间的复杂关系。
SPSS软件提供了方便易用的工具和功能,使得多元统计分析更加简单和高效。
同时,多元统计分析和SPSS广泛应用于各个领域,为研究者和决策者提供了有力的支持和指导。


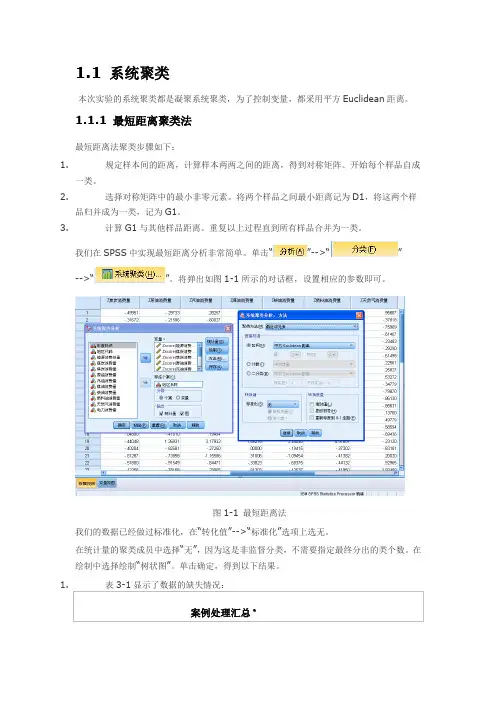
1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:1.规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
2.选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“”-->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
聚类表阶群集组合系数首次出现阶群集下一阶群集1 群集 2 群集 1 群集 21 21 28 .211 0 0 102 12 24 .465 0 0 63 2 27 .491 0 0 54 13 20 .585 0 0 95 2 14 .645 3 0 66 2 12 .678 5 2 77 2 7 .702 6 0 88 2 25 .773 7 0 99 2 13 .916 8 4 1110 21 29 1.085 1 0 1211 2 18 1.106 9 0 12表1-2 聚类过程我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。
如图1-2所示,最短距离法组内距离小,但组间距离也较小。
分类特征不够明显,无法凸显各个省份的能源消耗的特点。
但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。
12 2 21 1.115 11 10 13 13 2 17 1.360 12 0 14 14 2 26 1.564 13 0 15 15 2 22 1.627 14 0 16 16 2 5 1.649 15 0 17 17 2 8 1.877 16 0 18 18 2 16 3.027 17 0 19 19 2 30 3.543 18 0 20 20 2 11 4.930 19 0 21 21 2 4 5.024 20 0 22 22 2 10 6.445 21 0 24 23 1 9 8.262 0 0 26 24 2 15 10.093 22 0 25 25 2 23 10.096 24 0 26 26 1 2 10.189 23 25 27 27 1 6 11.387 26 0 28 28 1 3 13.153 27 0 29 2911932.36728图1-2 最短距离法聚类图1.1.2 组间联接聚类组间联接聚类法定义为两类之间的平均平方距离,即。

如何使用SPSS进行多元统计分析第一章:SPSS简介SPSS(Statistical Package for the Social Sciences)是一种功能强大且广泛使用的统计分析软件。
它能够处理大量数据,进行各种统计分析和数据挖掘,是研究人员和数据分析师常用的工具。
第二章:设置数据在进行多元统计分析之前,首先需要设置数据。
SPSS支持导入外部数据文件,如Excel、CSV等格式。
用户可以在SPSS中创建新的数据集并录入数据,也可以导入已有数据集。
在设置数据时,需要注意数据的变量类型、缺失值处理以及数据的清洗与转换。
第三章:描述统计分析描述统计分析是理解数据的第一步。
SPSS提供了丰富的描述统计方法,包括平均数、标准差、最小值、最大值、频数分布等。
用户可以通过简单的命令或者界面操作来生成各种描述统计结果,并进一步进行数据的可视化展示。
第四章:相关性分析相关性分析是多元统计分析的常用方法之一。
SPSS提供了丰富的相关性分析工具,如Pearson相关系数、Spearman等。
用户可以通过相关分析来检测不同变量之间的关系,并进一步探索变量之间的线性或非线性关系。
第五章:线性回归分析线性回归分析是一种预测性分析方法,在多元统计分析中应用广泛。
SPSS可以进行简单线性回归分析和多元线性回归分析。
用户可以通过线性回归分析来建立模型,预测因变量与自变量之间的关系,并进行参数估计和显著性检验。
第六章:因子分析因子分析是一种常用的降维技术,用于发现隐藏在数据中的潜在变量。
SPSS提供了主成分分析、最大似然因子分析等方法。
用户可以通过因子分析来降低变量的维度,提取数据中的主要信息。
第七章:聚类分析聚类分析是一种用于将数据样本划分成相似组的方法。
SPSS支持多种聚类算法,如K均值聚类、层次聚类等。
用户可以通过聚类分析来识别数据中的固有模式和群体。
第八章:判别分析判别分析是一种用于将样本分类的方法,常用于研究预测变量对分类变量的影响。


多元统计分析原理与基于SPSS的应用1. 引言多元统计分析是统计学中的重要分支,用于研究多个变量之间的关系和模式。
在实际应用中,SPSS是一个流行的统计分析软件,提供了丰富的功能和工具,可以用于多元统计分析。
本文将介绍多元统计分析的原理,并探讨如何利用SPSS进行实际应用。
2. 多元统计分析概述多元统计分析是一种从多个维度考察数据的统计方法。
它可以帮助研究者发现多个变量之间的模式和关联,从而提供更深入的分析和理解。
常见的多元统计分析方法包括:主成分分析、因子分析、聚类分析、判别分析等。
2.1 主成分分析(PCA)主成分分析是一种减少数据集维度的方法,它可以将大量的变量转化为少数几个主成分。
通过主成分分析,可以发现数据中的主要模式和结构,从而简化数据集和分析过程。
2.2 因子分析因子分析是一种确定变量之间潜在关系的方法。
它可以帮助研究者发现共同的因素或维度,并解释变量之间的相关性。
因子分析可用于降维或构造新的变量,进而减少数据集的复杂性。
2.3 聚类分析聚类分析是一种将观测对象分组或分类的方法。
它可以通过计算对象之间的相似性或距离,将它们划分为不同的类别。
聚类分析可帮助研究者发现数据中的隐藏结构,并进行进一步的分析和解释。
2.4 判别分析判别分析是一种预测变量类别的方法。
它可以根据已知类别的样本数据,建立预测模型并进行分类。
判别分析可用于识别不同群体或类别之间的差异,并进行进一步的推断和预测。
3. 多元统计分析的应用场景多元统计分析可以应用于各种领域,如市场调研、社会科学、医学研究等。
以下是一些常见的应用场景:•市场调研:通过主成分分析和因子分析,可以帮助企业确定消费者需求和消费行为的主要影响因素。
•社会科学:聚类分析可用于对人群进行社会分类,从而提供对人群特征和行为的深入理解。
•医学研究:判别分析可以应用于医学诊断,预测患者是否患有某种疾病或疾病的严重程度。
4. 基于SPSS的多元统计分析应用示例SPSS是一款功能强大的统计分析软件,提供了多种多元统计分析方法和工具。

K聚类一、实验过程1.将数据5.7导入至SPSS中,分析-分类-K均值聚类分析,将8个行业放到变量中,地区放到label cases中,设定聚类数=3。
2.点击“迭代”,设定最大迭代次数为10,迭代标准为0,点击继续3.点击“保存”,选择“聚类成员”及“与聚类中心的距离”4.点击“选项”,选择如下点击继续5.点击确定后,得到如下实验结果:二、实验结果分析:1. 给出初始的聚类中心2. 给出每次迭代结束后类中心的变动从表中可以看出共经历了4次迭代,即4次迭代后,聚类中心的变化为0,迭代停止。
表中,聚类一列中给出观测量所属的类别,距离列给出了观测量与所属聚类中心的距离。
综合第三个表及第四个表,可以看出将31个地区按8个产业分成3类后,北京,江苏,浙江,山东,广东为第一类。
这一类聚类中心8个产业的产值分别为1165.95,143.78,135.89,263.39,61.36,176.16,152.99,559.62亿元。
第二类包括天津和上海,剩下的24个地区为第三类。
表中给出的是三类聚类中心间的距离6. 进行单因素方差分析结果显示,8个变量在三个类别中均存在显著差异,说明结果有效。
综合上述表格,按照个产业的发展水平将中国31个地区分成3类:第一类为北京,江苏,浙江,山东,广东,属于经济发达地区。
该类中心的产值分别为1165.95,143.78,135.89,263.39,61.36,176.16,152.99,559.62亿元。
第二类为天津和上海,属于较发达地区。
该类中心的产值分别为2064.94,170.58,272.73,445.55,80.96,266.19,251.86,717.59亿元。
第三类为余下的24个地区,属于欠发达地区。
该类中心的产值分别为428.07,82.50,73.91,89.18,26.04,28.29,38.64,185.03亿元。
多元统计分析
(第一次作业)
学院:信息与计算科学学院
专业: ____________ 指导老师: ____________ 小组成员:罗健水(20080560)
许志欢(20080574)
庄娜(20080595)
卓玛(20080561)
2011年4月10日
题目:某行政系统所属独立核算工业企业16个行业经济实力强弱的聚类分析
独立核算:独立核算是指对本单位的业务经营活动过程及其成果进行全面、系统的会计核算。
独立核算单位的特点是:在管理上有独立的组织形式,具有一定数量的资金,在当地银行开户;独立进行经营活动,能同其他单位订立经济合同;独立计算盈亏,单独设置会计机构并配备会计人员,并有完整的会计工作组织体系。
非独立核算又称报帐制,是把本单位的业务经营活动有关的日常业务资料,逐日或定期报送上级单位,由上级单位进行核算。
非独立核算单位的特点是:一般由上级拔给一定数额的周转金,从事业务活动,一切收入全面上缴,所有支出向上级报销,本身不单独计算盈亏,只记录和计算几个主要指标,进行简易核算
数据来源:上海市青浦区统计局数据链接:数据5・11.sav
固定资产原价:指企业在建造、改置、安装、改建、扩建、技固定资产计量术改造固定资产时实际支出的全部货币总额。
该指标根据企业会计"资产负债表"中"固定资产原价"项的期末数填列。
固定资产净值平均余额:每月逐步减少。
有部分企业单位,是按季度计提折旧,那么在没有提折旧的月
份,比如10月份,和9月份比较,固定资产净值平均余额就没有变化,也就是说,还是等于9月份的
固定资产净值平均余额
例:如09年底的固定资产净值余额为5000万元,2010年元月份完成固定资产投资1000万元,那么元月份的固定资产净值平均余额是多少?2月份又完成投资500万元,那2月份的固定资产净值平均余额是多少?(计算公式是怎样)
解:平均余额等于期初的加期末的除以2
所以一月份=(5000+6000-当月折旧)/2
二月份的=(6000+6500-两个月的折旧)/2
所有者权益(Owne' s Equities:资产扣除负债后由所有者应享的剩余利益。
即一个会计主体在一定时期所拥有或可控制的具有未来经济利益资源的净额。
营业税金及附加:主营业务税金及附加”科目改名为“营业税金及附加”,
“营业税金及附加”科目用法如下:
一、本科目核算企业经营活动发生的营业税、消费税、城市维护建设税、资源税和教育费附加等相关税费。
房产税、车船使用税、土地使用税、印花税在“管理费用”等科目核算,不在本科目核算。
二、企业按规定计算确定的与经营活动相关的税费,借记本科目,贷记“应交税费”等科目。
企业收到的返还的消费税、营业税等原记入本科目的各种税金,应按实际收到的金额,借记“银行存款”科目,贷记本科目。
三、期末,应将本科目余额转入“本年利润”科目,结转后本科目应无余额。
12. 由于分期收款销售商品核算方法与以前不同,新增加科目“长期应收款”, “长期应收款”科目核算如下:
一、本科目核算企业融资租赁产生的应收款项和采用递延方式分期收款、实质上具有融资性质的销售商品和提供劳务等经营活动产生的应收款项。
二、本科目应当按照承租人或购货单位(接受劳务单位)等进行明细核算。
三、长期应收款的主要账务处理
1. 操作步骤
(1)打开数据文件后,在数据编辑窗口中的菜单栏中选择Analyze | Classily | Hierarchical Cluster (分层聚类)命令,即可打开分层聚类的主对话框。
(2)将变量“本月”选人Variable(s)列表框,作为分层聚类的变量。
(3)在Cluster 选项组中选择Variable 单选按钮,及要求按变量进行聚类。
(4)单击Plots 按钮,在如图所示的Hierarchical Cluster Analysis:Plots 对话框中选择Dendrogram 复选框,要求输出谱系图。
单击Continue 按钮确认选择并返回主对话框。
(5)其他设置采用系统默认设置。
6)单击OK 按钮,执行分层聚类操作
用最短距离法分析:
表1个案摘要
a. Squared Euclidean Distance Undefined error #14704 - Cannot open tex
从表中看出,观测个案数为16个,没有缺失值,采用平方欧氏距离
表2相似矩阵
相似矩阵是一个对角矩阵,只需看上三角或下三角,它是用来度量两个样本之间的相似性,先把相似系数小的聚为一类,依次下去。
在表4中,第一列(Stage表示聚类分析的部署;第二列,第三列(Cluster Combined) 表示这
一步聚类中哪两个样本合小类样本聚成一类;第四列(Coefficie nts)是个体距离或
小
类距离;第五列和第六列(Stage Cluster First Appea)表示这一部中的样本在上面几步中哪一步出现过;第七列(Next Stage)表示本不聚类的结果将在以下第几步中用到。
举例分析:第一行中,8和11聚为一类,接下来,第十二行中,2和5聚为一类,2在第十行聚类中出现过,5上一次在第五行聚类中出现过,接下来,转向第十三行聚类。
冰川图
Rescaled Distance Cluster Corribine
Case 8 Case 11
* Case 14
Case 5 Case 7
Case 2 Case 6 Case 13 Case 16
Case 3
Case 15 Case 10
Case 4
Ca3e 12 Case 9 Case 1
树形图以躺倒数的形式展现了聚类分析中的每一次类合并的情况。
SPSS 自动将各类见得距离映射在
0到25之间,并将聚类过程近似的表示在图上。
由表 5可以看出,首先合并成一类的是家具制造业,文 教体育用品制造业,纺织服装、鞋、帽制,日用金属制品业 等聚为一类。
直到所有观测个案都合并成一 类,此时之间的距离已经变得非常大了。
举例分析:聚三类,{8 11 14 5 7
2 6 13
16 15
10 4
12},{9},{1}聚为一类。
树形图的结果与冰状图的结果是吻合的,二者反映的类合并情况是一样的。
最短距离法
CASE Lalcel Mu B 11 14
5 7
2
5 13
16 3
15 10
4 12 9 t
5
10
15
20
25
重心法
Rescaled D istance Cluster Combine
c 0S E□Lebu 1Num+—
—Case88—
—Case1111
Cass1414
Case77—i Case55
Case04
Case1212
Case33
Ca3e1515
Case1010
Case22
Case66
Case1313II g曰亡1616」
99
Case11ia2025
-+—I
最长距离法
Rescaled Distance Cluster Contoine
Label Pluim+—Case88—1 Case1111
Case55—Case171 Case1414
Case44
Case1212
Case33
Case1515J Case1010
Case22
Case66
Case1313
Case1616-1 Case99
Case11is -+
1.农副食品加工业
2.食品制造业
3. 饮料制造业
4. 纺织业
5. 纺织服装、鞋、帽制
6.皮革、毛皮、羽毛(绒)及其制品业
7. 木材加工及木、竹、藤、棕、草制品业
8.家具制造业9. 造纸及纸制品业10. 印刷业和记录媒介的复制11.文教体育用品制造业
12.化学原料及化学制品制造业13. 医药制造业14. 日用金属制品业15. 仪器仪表及
文化、办公用机械制造业16. 工艺品及其他制造业我们分别用最短距离法,重心法,最长距离法三种不同的方法将样本聚为三类,结果如上图所示,把三种方法中都为第一类的归为第一类,第二类的归为第二类,第三类的归为第三类,其中有争议的是医药制造业和工艺品及其他制造业,最短距离法和重心法都将其聚在第一类,故医药制造业和工艺品及其他制造业应聚在第一类。
最终结果如下所示:
第一类:8 11 14 5 7 2 6 13 16 15 10 4 12
第二类:9
第三类:1
最终结果如下:
第一类:8 11 14 7 5 4 12 3 15 10 2 6 第二类:13 16
第三类:9
第四类:1。