徐--稀疏最优化非凸正则化_理论
- 格式:pdf
- 大小:3.74 MB
- 文档页数:51

稀疏优化问题算法研究作者:李蒙来源:《当代人(下半月)》2018年第03期摘要:稀疏优化问题发展至今,已经广泛应用于压缩感知、图像处理、复杂网络、指数追踪、变量选择等领域,并取得了令人瞩目的成就。
稀疏优化问题的求解算法种类繁多,根据算法设计原理的不同,可将其大致分为三类:贪婪算法、凸松弛方法和阈值类算法。
本文主要介绍稀疏优化问题算法研究进展及各类算法的优缺点。
关键词:稀疏优化问题;压缩感知;信号重构;优化算法随着当代社会信息技术的飞速发展,所获取和需要处理的数据量大幅增多,而基于传统的香农奈奎斯特采样定理中要求采样频率不得低于信号最高频率的两倍才可以精确重构信号。
2006年,Donoho、Candes等人针对稀疏信号或可稀疏表示的信号提出了新的采集和编解码理论,即压缩感知理论。
该理论使得通过少量采样即可准确或近似重构原始信号。
信号重构问题是一个非凸稀疏优化问题(问题)。
该问题是一个NP-hard问题,所以出现了多种不同的处理模型近似地或在一定条件下等价地求解问题。
以下就从压缩感知的信号重构理论出发,分析研究稀疏优化问题的模型和求解算法。
一、压缩感知重构问题在压缩感知理论中,若信号本身是稀疏的,则原始信号和观测信号之间的表达式为:;若信号本身不是稀疏的,但在基底下具有稀疏表示,即,其中是一个稀疏向量,则原始信号和观测信号之间的表达式为:,此时,重构原始信号只需要得到满足该等式约束的稀疏解,便可通过得到原始信号,其中为测量矩阵,为变换矩阵,为感知矩阵。
在压缩感知理论中,感知矩阵是一个很重要的组成部分,感知矩阵的好坏会直接影响原始信号的重构质量。
压缩感知理论中的稀疏信号重构问题旨在通过低维观测数据最大程度恢复出原始的高维信号,其本质为求一个欠定方程组的稀疏解,即(1)压缩感知的重构问题也可通过下述模型来求解:(2)Donoho和Chen证明了当观测矩阵和变换矩阵不相关时,(1)和(2)的解等价,并将(2)称为基追踪(Basis Pursuit,BP)问题。


浅析稀疏优化在机器学习中的应用随着机器学习技术的不断发展,稀疏优化在机器学习中的应用变得越来越重要。
稀疏优化是指在优化问题中尽可能使解向量的元素为零,或者接近于零。
在机器学习中,稀疏优化技术可以帮助我们减少特征数量,降低模型的复杂度,提高模型的泛化能力,从而更好地应对现实世界的复杂问题。
本文将对稀疏优化在机器学习中的应用进行浅析,介绍其原理、方法和具体应用场景。
一、稀疏优化的原理在机器学习中,稀疏优化的目标是找到一个稀疏解向量,即大部分元素为零或者接近于零。
稀疏优化的原理主要包括以下几点:1. 数据表示稀疏性:大部分真实世界的数据都具有一定的稀疏性,即大部分特征的取值为零或者接近于零。
在文本分类任务中,一个文档可能包含成千上万的单词,但是其中只有很少一部分单词对文档的主题分类起到关键作用。
2. 模型简化:稀疏优化可以帮助我们简化模型,降低模型的复杂度。
通过将不相关的特征的权重设置为零,可以使模型更易于解释,提高模型的可解释性。
3. 降噪:稀疏优化也可以帮助我们消除噪声特征的影响,提高模型的鲁棒性和泛化能力。
稀疏优化的方法主要包括以下几种:1. L1正则化:L1正则化是最常用的稀疏优化方法之一。
它通过在目标函数中加入L1范数惩罚项来实现稀疏化。
具体来说,对于目标函数 f(x) 和参数向量 x,L1正则化的目标函数可以表示为:minimize f(x) + λ||x||1||x||1表示参数向量 x 的L1范数,λ是正则化系数。
2. L0正则化:L0正则化是另一种常用的稀疏优化方法,它通过在目标函数中加入L0范数惩罚项来实现稀疏化。
由于L0范数不可导,L0正则化通常被替换为非凸可微的函数来实现。
3. 基于投影的方法:基于投影的方法是一类直接将参数向量投影到稀疏空间的方法。
通过在优化过程中对参数向量施加适当的投影操作,可以实现参数向量的稀疏化。
4. 基于启发式的方法:基于启发式的方法主要是一些启发式算法,如前向选择、后向删除等,通过一些启发式规则逐步调整参数向量,使之变得更加稀疏。

非凸优化问题的优化算法改进研究第一章引言1.1 研究背景与意义非凸优化问题是现实生活中广泛存在的一类最优化问题,其求解具有重要的理论意义和实际应用价值。
然而,与凸优化问题不同,非凸优化问题的解空间往往包含多个局部极小值点,使得求解非凸优化问题具有更高的难度。
为了解决这一难题,研究者们通过改进优化算法来提高非凸优化问题的求解效果,进一步推动了非凸优化问题的研究和应用。
1.2 研究现状目前,对于非凸优化问题的研究主要集中在改进优化算法的设计和分析上。
例如,传统的梯度下降法在求解非凸优化问题时常受困于局部极小值点,无法找到全局最优解。
因此,研究者们提出了许多改进的算法,如牛顿法、拟牛顿法、共轭梯度法等,以提高非凸问题的求解效果。
然而,这些改进算法在某些情况下仍然存在收敛不稳定、高计算复杂度等问题,需要进一步改进。
第二章基于梯度下降法的优化算法改进2.1 动量梯度下降法梯度下降法是一种常用的优化算法,但在求解非凸问题时容易陷入局部最小值。
为了克服这一问题,研究者们提出了动量梯度下降法。
该方法通过引入动量项,使得梯度更新具有一定的惯性,能够跳出局部最小值点,寻找更好的解。
实验证明,动量梯度下降法能够显著提高非凸问题的求解效果。
2.2 自适应学习率的梯度下降法学习率是梯度下降法中的重要参数,决定了每次迭代更新的步长。
然而,传统的梯度下降法中通常需要手动设置学习率,导致求解过程不稳定。
为了解决这一问题,研究者们提出了自适应学习率的梯度下降法。
该方法通过自动调整学习率,根据当前迭代过程中梯度的大小来确定更新步长。
实验证明,自适应学习率的梯度下降法能够加快收敛速度,提高求解效果。
2.3 随机梯度下降法与批次梯度下降法的结合随机梯度下降法是一种通过随机选择部分样本进行更新的方法,具有较快的收敛速度。
然而,由于其每次只利用一部分样本进行更新,容易陷入局部最小值。
为了充分利用全部样本的信息,研究者们将随机梯度下降法与批次梯度下降法相结合。


基于非凸稀疏域约束条件的Tikhonov 正则化方法摘要本文给出了一个奇特的正则化方法的理论分析用来解决(非线性)反问题,从而将正则化方法推广到稀疏域上。
我们考察特定的Tikhonov 正则化方法的稳定性和收敛性。
我们将这种正则化方法用于传统的连续的pl 空间,由于这是稀疏域上的正则化方法,所以我们将p 限定于0到1之间。
当1<p 时三角不等式不再成立并且我们会得到一个带有非凸限制条件的伪Banach 空间。
我们将要证明在传统的环境下最小值的存在性,稳定性和连续性。
除此之外,我们还将给出在各自的传统假设下拓扑Hilbert 空间下的收敛速度。
1.介绍本文是关于在稀疏域条件下正则化方法的理论分析。
我们将这种方法不妨设在 p l ))1,0((∈p 空间上并且是非线性的算子。
我们证明了Tikhonov 正则化方法的解的存在性,解得稳定性,对数据扰动解的收敛性。
除此之外,我们还将给出在各自的传统假设下拓扑Hilbert 空间下的收敛速度。
稀疏域上的反问题。
我们有等式y x F =)( )1( 这里F 是一个非线性算子。
为此我们将该式用Tikhonov 方法表示,求该等式的最小值 ),()(2x y x F αψ+- )2( 除了传统的正则化项)(x ψ,如2L 范数,全部变量或者是最大正则化熵等方法,还有一个具有潜质的新奇的稀疏域上的正则化方法.普遍的选择设置都是基础上的延拓,例如小波扩张,傅里叶分解活着各种结构的扩张,典型地这些扩张被用于图像或者频率数据,因此本文所涉及的扩张系数通常指的是稀疏域的扩张。
它可应用于各种潜在的应用。
比如,X 线断层摄影术(CT ,SPECT ,PET )。
这些通常的医学成像技术正是传统的反问题同时又可以通过积分算子来得出Radon 变换的具体形式。
这种图像重构的方法是通过基扩展来实现的,如小波和像素基,参考文献【5,6】,一个适用用的正则化方法都是引进适当的惩罚项)(x ψ,如1l 范数:∑=k k xx )(ψ, )3(这里的k 能够预示小波级数的系数。

稀疏子空间聚类算法与模型建立稀疏子空间聚类是一种基于谱聚类的子空间聚类方法,基本思想:假设高位空间中的数据本质上属于低维子空间,能够在低维子空间中进行线性表示,能够揭示数据所在的本质子空间, 有利于数据聚类.基本方法是, 对给定的一组数据建立子空间表示模型,寻找数据在低维子空间中的表示系数, 然后根据表示系数矩阵构造相似度矩阵, 最后利用谱聚类方法如规范化割(Normalized cut, Ncut)[22] 获得数据的聚类结果。
基本原理稀疏子空间聚类[32] 的基本思想是: 将数据 αS x i ∈表示为所有其他数据的线性组合, j ij ij i x Z x ∑≠= (1)并对表示系数施加一定的约束使得在一定条件下对所有的αS x j ∉, 对应的0=ij Z 。
将所有数据及其表示系数按一定方式排成矩阵 ,则式(1)等价于 XZ X = (2)且系数矩阵N N R Z ⨯∈ 满足: 当i x 和j x 属于不同的子空间时, 有0=ij Z . 不同于用一组基或字典表示数据, 式(2)用数据集本身表示数据, 称为数据的自表示. 若已知数据的子空间结构, 并将数据按类别逐列排放, 则在一定条件下可使系数矩阵Z 具有块对角结构, 即⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=k Z Z Z Z 00000021 (3) 这里),,1(k Z =αα 表示子空间αS 中数据的表示系数矩阵; 反之, 若Z 具有块对角结构, 这种结构揭示了数据的子空间结构. 稀疏子空间聚类就是通过对系数矩阵Z 采用不同的稀疏约束, 使其尽可能具有理想结构, 从而实现子空间聚类.Elhamifar 等[32] 基于一维稀疏性提出了稀疏子空间聚类(Sparse subspace clustering,SSC) 方法, 其子空间表示模型为1min Z Z 0,..==ii Z XZ X t s (4)该模型利用稀疏表示(SR) 迫使每个数据仅用同一子空间中其他数据的线性组合来表示. 在数据所属的子空间相互独立的情况下, 模型(4) 的解Z 具有块对角结构, 这种结构揭示了数据的子空间属性: 块的个数代表子空间个数, 每个块的大小代表对应子空间的维数, 同一个块的数据属于同一子空间. 注意, 模型中的约束0=ii Z 是为了避免平凡解, 即每个数据仅用它自己表示, 从而Z 为单位矩阵的情形. 稀疏子空间聚类综述 王卫卫1 李小平1 冯象初1 王斯琪132 Elhamifar E, Vidal R. Sparse subspace clustering. In: Pro-ceedings of the 2009 IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition (CVPR).Miami, FL, USA: IEEE, 2009. 2790¡2797稀疏最优化模型位于线性或仿射子空间集合的高维数据可以稀疏地被同一个子空间的点线性或者仿射表示。

深度学习中的非凸优化问题研究深度学习是一种基于神经网络的机器学习方法,广泛应用于图像识别、语音识别、自然语言处理等领域。
然而,深度学习的成功离不开优化算法的支持。
在深度学习中,优化算法用于训练神经网络的参数,以最小化损失函数。
然而,传统的优化算法在处理深度学习中的非凸优化问题时存在一些挑战。
本文将探讨深度学习中非凸优化问题的研究进展。
首先,我们需要了解什么是非凸优化问题。
在数学中,凸函数是一种具有特殊性质的函数。
具体来说,对于一个函数f(x),如果对任意两个点x1和x2以及任意一个介于0和1之间的数t都有f(tx1 + (1-t)x2) <= tf(x1) + (1-t)f(x2),那么这个函数就是凸函数。
如果一个问题可以被表示为最小化一个凸函数,则这个问题就是一个凸优化问题。
然而,在深度学习中,我们通常需要最小化非凸损失函数来训练神经网络。
这是因为神经网络通常具有多个隐藏层和大量参数,在这种情况下很难找到一个凸函数来准确地描述网络的行为。
因此,深度学习中的优化问题通常是非凸优化问题。
非凸优化问题的一个主要挑战是局部最小值。
在非凸函数中,存在多个局部最小值,而我们通常希望找到全局最小值。
然而,传统的优化算法如梯度下降法容易陷入局部最小值,从而导致模型性能下降。
为了克服这个问题,研究者们提出了许多改进算法。
一种常用的改进算法是随机梯度下降法(SGD)。
SGD通过随机选择一小批训练样本来估计梯度,并更新网络参数。
这种随机性可以帮助我们跳出局部极小值,并更好地探索参数空间。
然而,SGD也存在一些缺点,如学习率选择困难和收敛速度慢等。
为了改进SGD算法,在深度学习中引入了自适应学习率方法。
自适应学习率方法根据参数更新情况自动调整学习率大小,并根据每个参数的历史梯度信息来调整方向和步长。
这些方法包括Adagrad、Adadelta、RMSprop等。
这些方法在一定程度上改善了SGD的性能,但仍然存在一些问题,如学习率衰减过快和参数更新不稳定等。

正则化详解⼀、为什么要正则化 学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应⽤到某些特定的机器学习应⽤时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。
正则化(regularization)技术,可以改善或者减少过度拟合问题,进⽽增强泛化能⼒。
泛化误差(generalization error)= 测试误差(test error),其实就是使⽤训练数据训练的模型在测试集上的表现(或说性能 performance)好不好。
如果我们有⾮常多的特征,我们通过学习得到的假设可能能够⾮常好地适应训练集(代价函数可能⼏乎为0),但是可能会不能推⼴到新的数据。
下图是⼀个回归问题的例⼦: 第⼀个模型是⼀个线性模型,⽋拟合,不能很好地适应我们的训练集;第三个模型是⼀个四次⽅的模型,过于强调拟合原始数据,⽽丢失了算法的本质:预测新数据。
我们可以看出,若给出⼀个新的值使之预测,它将表现的很差,是过拟合,虽然能⾮常好地适应我们的训练集但在新输⼊变量进⾏预测时可能会效果不好;⽽中间的模型似乎最合适。
分类问题中也存在这样的问题:就以多项式理解,x的次数越⾼,拟合的越好,但相应的预测的能⼒就可能变差。
如果我们发现了过拟合问题,可以进⾏以下处理: 1、丢弃⼀些不能帮助我们正确预测的特征。
可以是⼿⼯选择保留哪些特征,或者使⽤⼀些模型选择的算法来帮忙(例如PCA)。
2、正则化。
保留所有的特征,但是减少参数的⼤⼩(magnitude)。
⼆、正则化的定义 正则化的英⽂ Regularizaiton-Regular-Regularize,直译应该是"规则化",本质其实很简单,就是给模型加⼀些规则限制,约束要优化参数,⽬的是防⽌过拟合。
其中最常见的规则限制就是添加先验约束,常⽤的有L1范数和L2范数,其中L1相当于添加Laplace先验,L相当于添加Gaussian先验。

稀疏约束的正则化方法翁云华;杜娟【摘要】This paper presents a peculiar regularization method of theoretical analysis is used to solve the in-verse problem of ( nonlinear) so as to promote the regularization method to the sparse domain.We look at spe-cific Tikhonov regularization method of stability and convergence.We are going to the regularization method is used in the traditional continuous lp space,So we will be limited p between 0 to 1,whilep<1,Triangle ine-quality is no longer set up and we'll get a pseudo Banach space with non convex constraints.We are going to prove the existence of the minimum value in the traditional environment, the stability and continuity.In addi-tion, we will also be given in the respective topological Hilbert space under the traditional assumptions of the convergence speed.%给出了一个奇特的正则化方法的理论分析并用来解决(非线性)反问题,从而将正则化方法推广到稀疏域上。
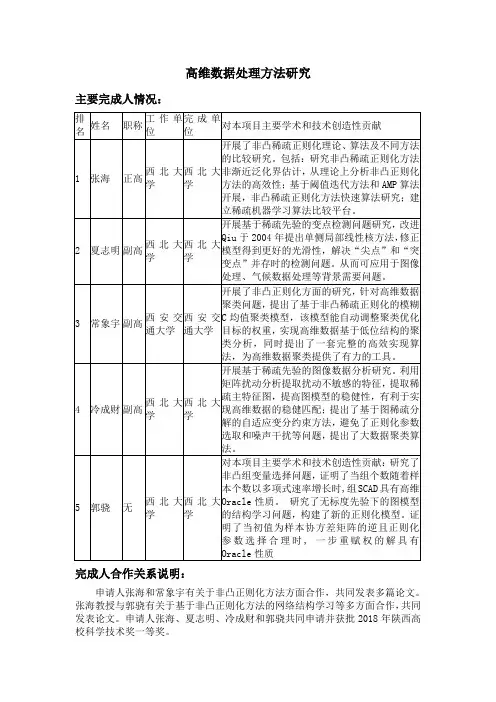
高维数据处理方法研究主要完成人情况:完成人合作关系说明:申请人张海和常象宇有关于非凸正则化方法方面合作,共同发表多篇论文。
张海教授与郭骁有关于基于非凸正则化方法的网络结构学习等多方面合作,共同发表论文。
申请人张海、夏志明、冷成财和郭骁共同申请并获批2018年陕西高校科学技术奖一等奖。
主要完成单位排序及贡献:1.西北大学主要贡献:开展非凸稀疏正则化理论、算法及不同方法的比较研究。
包括:研究非凸稀疏正则化方法非渐近泛化界估计,从理论上分析非凸正则化方法的高效性;基于阈值迭代方法和AMP算法开展,非凸稀疏正则化方法快速算法研究;建立稀疏机器学习算法比较平台,利用相变的工具研究不同方法的差异,指导新方法的设计和研究.建立相变分析方法的理论基础,从而研究稀疏机器学习算法的本质特征。
开展基于稀疏正则化方法的网络数据分析,研究网络建模及统计推断问题,建立具有Hub属性的随机块模型,并研究其高维统计性质;研究具有组结构信息的组变量选择,建立基于非凸组结构正则化的组变量选择方法;通过图模型研究具有网络数据,基于稀疏先验和无标度先验研究稀疏网络的高维统计性质。
开展基于稀疏先验的变点检测问题研究,改进Qiu于2004年提出单侧局部线性核方法,修正模型得到更好的光滑性,解决“尖点”和“突变点”并存时的检测问题。
从而可应用于图像处理、气候数据处理等背景需要问题。
2.西安交通大学:主要贡献:开展了非凸正则化高维聚类分析,完善了非凸正则化理论方面的工作。
针对高维数据聚类问题,提出了基于非凸稀疏正则化的模糊C均值聚类模型,该模型能自动调整聚类优化目标的权重,实现高维数据基于低位结构的聚类分析,同时提出了一套完整的高效实现算法,为高维数据聚类提供了有力的工具。
完成单位合作关系说明:项目主要完成人张海教授与西安交通大学管理学院常象宇副教授长期开展合作关系,共同发表论文,合作申请国家自然科学基金。
此项目以西北大学为主导,西安交通大学协助合作完成。
非凸优化问题的收敛性分析研究摘要:非凸优化问题是一类具有广泛应用的实际问题,其解决方法对于实际应用具有重要意义。
本文基于对非凸优化问题的收敛性分析,研究了不同算法在解决非凸优化问题时的收敛性,并对其进行了比较和评估。
通过实验和理论分析,本文得出了一些结论,并提出了一些改进算法的思路。
1. 引言在实际应用中,很多优化问题是非凸的。
与凸优化不同,非凸优化问题存在多个局部极小值点,并且很难找到全局最小值点。
因此,研究非凸优化问题的收敛性是十分重要和有意义的。
2. 非凸优化问题2.1 非凸函数在研究非凸优化问题之前,首先需要了解什么是非凸函数。
简单来说,一个函数f(x)被称为是一个非凸函数,如果存在两个点x1和x2以及一个介于它们之间的点x3使得f(x3)大于等于(或小于等于)f(x1)和f(x2)之间较小(或较大)者。
2.2 非凸优化问题的定义非凸优化问题可以定义为:求解一个非凸函数的最小值,其中目标函数和约束条件都是非凸的。
3. 非凸优化问题的解决方法3.1 传统方法传统的解决非凸优化问题的方法包括:穷举搜索、梯度下降法、牛顿法等。
这些方法在某些情况下可以得到较好的结果,但是在处理大规模和高维度问题时,往往会陷入局部极小值点。
3.2 近似算法为了克服传统方法中局部极小值点带来的困扰,近年来涌现了一批近似算法。
这些算法包括模拟退火算法、遗传算法、粒子群优化等。
这些算法通过引入一定程度上的随机性和全局搜索策略,可以得到较好的结果。
4. 非凸优化问题收敛性分析4.1 收敛性定义和条件在研究非凸优化问题收敛性时,首先需要定义收敛性以及收敛条件。
一般来说,一个算法被称为是收敛到全局最小值点,如果对于任意给定精度ε>0,在经过有限步迭代之后,算法可以找到一个解x*,使得目标函数f(x*)的值与全局最小值的差小于ε。
4.2 收敛性分析方法对于非凸优化问题的收敛性分析,可以采用理论分析和实验验证相结合的方法。
基于稀疏优化lp正则化的光滑化算法与应用研究近年来,稀疏优化问题在科学研究和工程实践等诸多领域里引起了广泛的重视.压缩感知(Compressive sensing,CS)理论被提出后,稀疏优化在信号恢复、图像处理及统计推断等领域得到了大量的应用.因此,稀疏优化问题的研究具有重要的理论和现实意义.CS理论主要分为稀疏表示、编码测量和信号重构三个部分,其核心思想是对稀疏信号进行压缩采样,然后通过观测向量和算法来重构原始信号.信息采样理论由于CS的诞生迎来了巨变,其具有良好的应用前景.本文研究的内容主要是基于lp(0<P<1)正则化的稀疏优化问题,lp正则化的稀疏优化问题是一类非凸非光滑非Lipschitz连续的优化问题.该模型的目标函数由光滑项f(X)(通常为1/2||Ax-b||22)和非凸非光滑非Lipschitz连续的正则项||x||pp两部分组成.求解基于lG正则化的稀疏优化问题需要克服以下三个方面的问题,分别是:(1)由于极小化的模型是非凸非光滑非Lipschitz连续的,因此不易建立其最优性条件;(2)由于现实生活和工程应用中的问题规模较大,因此对算法的鲁棒性、时效性和求解能力要求较高;(3)现有的算法对相对容易的稀疏信号恢复问题具有良好的性能,但对于稀疏度较高、携带噪声或采样率很低的困难问题,恢复能力有限.为解决以上问题,本文针对正则项||x||pp进行两种不同的光滑化处理.第一种光滑化处理利用了迭代重加权算法的思想,提出了基于稀疏优化lp正则化的快速迭代重加权算法,其每次迭代时对光滑化后的目标函数的梯度方程采用局部线性化处理,极大地加快了算法的运行速度,同时证明了算法的收敛性且分析了算法的计算复杂度;第二种光滑化处理通过构建目标函数的光滑逼近函数,提出了基于稀疏优化lp正则化的光滑化拟牛顿算法、光滑化共轭梯度算法和光滑化修正牛顿算法,通过一个统一的收敛性证明得到了前两个算法的收敛性并分别分析了它们的计算复杂度,在光滑化修正牛顿算法中利用牛模型的特性对其Hessian矩阵进行修正,同时其中的p趋近于0,最后分析了算法的计算复杂度,自适应地调整光滑化参数与正则化参数使得上述算法具有广泛的适应性和鲁棒性.通过大量数值实验验证了上述算法的有效性.。
实现稀疏角度下的精确CT重建:利用ADMM-LP算法求解非凸模型宋洁;陈平;潘晋孝【摘要】背景:稀疏角度投影重建是减小CT辐射剂量的有效方法,但因其重建质量的问题限制了该方法的应用.目的:研究基于LP范数的交替方向乘子-CT重建算法,旨在提高稀疏角度下的重建质量.方法:将CT重建模型中的全变分正则项替换为非凸非光滑的LP范数正则项,并利用增广拉格朗日法将约束问题转化为无约束问题,再利用交替方向乘子框架结合广义收缩算法将原优化模型拆分为等价于原问题的子问题,最后迭代求解各子问题.结果与结论:①通过仿真及实际实验,对比分析了全变分-凸集投影、代数重建-LP、Split-Bregman-LP以及所提算法在36个稀疏角度下的重建结果,结果显示论文提出的算法重建图像细节更完整,均方根误差更低,而且速度比Split-Bregman-LP快1倍;②说明提出的基于LP范数的交替方向乘子-LP算法,在投影角度稀疏情况下的重建结果具有较高的重建精度.【期刊名称】《中国组织工程研究》【年(卷),期】2018(022)031【总页数】5页(P4998-5002)【关键词】X-CT稀疏角度重建;LP范数;交替方向乘子法;广义收缩算法;迭代优化算法;国家自然科学基金【作者】宋洁;陈平;潘晋孝【作者单位】中北大学信息探测与处理山西省重点实验室,中北大学,山西省太原市030051;中北大学信息探测与处理山西省重点实验室,中北大学,山西省太原市030051;中北大学信息探测与处理山西省重点实验室,中北大学,山西省太原市030051【正文语种】中文【中图分类】R318文章快速阅读:文题释义:LP范数:定义向量的LP范数为:。
根据压缩感知理论,对于CT重建模型可以由一个保真项与一个正则项构成,以稀疏图像的LP范数为正则项的重建模型,可获取相较传统TV正则项更稀疏的解,使得在投影角度稀疏的条件下获取质量更高的重建图像。
交替方向乘子(ADMM)算法:ADMM法是一种求解优化问题的计算框架,通过分解协调过程,将大的全局问题分解为多个较小、较容易求解的局部子问题,并通过协调子问题的解而得到大的全局问题的解。
稀疏编码的参数选择技巧稀疏编码是一种用于数据压缩和特征选择的技术,它在机器学习和信号处理领域中被广泛应用。
稀疏编码的目标是找到一种最优的表示方式,使得数据能够以尽可能少的参数进行描述。
然而,在实际应用中,如何选择合适的参数成为了一个关键问题。
本文将探讨稀疏编码的参数选择技巧。
首先,我们需要选择一个合适的稀疏性度量指标。
稀疏性度量指标用于衡量数据的稀疏程度,即数据中非零元素的比例。
常见的稀疏性度量指标有L0范数、L1范数和L2范数。
L0范数是指向量中非零元素的个数,但由于其非凸性,计算复杂度较高。
L1范数是指向量中绝对值之和,可以通过线性规划等方法求解。
L2范数是指向量的欧几里得长度,计算简单但无法直接得到稀疏解。
在实际应用中,我们可以根据具体问题选择合适的稀疏性度量指标。
其次,我们需要确定一个合适的稀疏编码算法。
常用的稀疏编码算法包括lasso、lasso回归、基于字典学习的稀疏编码等。
lasso是一种基于L1范数的线性回归方法,可以得到稀疏解。
lasso回归是lasso方法的推广,可以解决多变量回归问题。
基于字典学习的稀疏编码是一种无监督学习方法,通过学习一个字典,将数据表示为字典中的稀疏线性组合。
在实际应用中,我们可以根据数据的特点选择合适的稀疏编码算法。
然后,我们需要确定一个合适的正则化参数。
正则化参数用于平衡稀疏性和拟合误差之间的关系。
正则化参数越大,稀疏性越高,但拟合误差可能增大;正则化参数越小,稀疏性越低,但拟合误差可能减小。
常用的正则化参数选择方法有交叉验证和信息准则。
交叉验证是一种通过将数据集划分为训练集和验证集,选择使得验证误差最小的正则化参数的方法。
信息准则是一种通过最小化模型选择准则,选择使得模型拟合误差和模型复杂度之和最小的正则化参数的方法。
最后,我们需要考虑是否引入先验知识。
先验知识是指对数据的先验分布或结构的了解。
在稀疏编码中,先验知识可以通过设置先验分布或结构约束来引入。
l2序列空间上的非凸集稀疏正则化郭二玲;季光明;杨茜【期刊名称】《四川理工学院学报(自然科学版)》【年(卷),期】2012(025)006【摘要】The regularising properties of Tikhonov regularisation on the sequence space l2 with weighted non-quadratic penalty term acting separately on the coeffeients of a given sequence can be used to derive sufficient conditions for the penalty term that guarantee the wellposedness of the method, and the focus is the application to the solution of operator equations with sparsity constraints. Assuming a linear growth of the penalty term at zero, the sparsity of all regularised solutions can be proved.%利用l2序列空间上独立作用于已知序列的系数的加权的非二次罚项的Tikhonov正则化的正则化性质可以推导出保证罚项的适定的充分条件,而且重点是带有稀疏约束的求解算子方程的应用。
从在罚项在零点的线性增长,可以证明所有正则化解的稀疏。
【总页数】4页(P79-82)【作者】郭二玲;季光明;杨茜【作者单位】成都理工大学管理科学学院,成都610059;成都理工大学管理科学学院,成都610059;成都理工大学管理科学学院,成都610059【正文语种】中文【中图分类】O29【相关文献】1.非局部平均迭代修正的稀疏角度CT凸集投影重建 [J], 刘楠;黄静;马建华;路利军;冯前进;陈武凡2.最佳L2局部逼近为非空凸集的充分条件 [J], 苏孝业3.基于L2稀疏约束和图正则化的非负矩阵分解算法 [J], 王美能4.一种稀疏图正则化的非负低秩矩阵分解算法 [J], 刘国庆; 卢桂馥; 张强5.双小波非凸稀疏正则化去噪算法研究 [J], 马敏;王涛因版权原因,仅展示原文概要,查看原文内容请购买。