spss主成分分析报告
- 格式:docx
- 大小:33.61 KB
- 文档页数:13

SPSS对主成分分析报告1. 简介主成分分析(Principal Component Analysis,简称PCA)是一种常用的多元统计分析方法,可以用于降维、数据压缩、数据可视化以及特征提取等方面。
本报告将使用SPSS软件进行主成分分析,并提供相应的分析结果和解读。
2. 数据集描述本次分析使用的数据集包含X个变量和Y个观测值。
具体变量的含义和取值范围如下:•变量1:描述1,取值范围为x1至x2;•变量2:描述2,取值范围为x1至x2;•…•变量X:描述X,取值范围为x1至x2;3. 数据预处理在进行主成分分析之前,我们需要对数据进行预处理,以确保分析结果的准确性和可靠性。
主要包括以下几个步骤:3.1 数据清洗数据清洗是指对数据中的缺失值、异常值等进行处理,以保证数据的完整性和一致性。
我们使用SPSS软件进行数据清洗,并将处理后的数据作为主成分分析的输入。
3.2 变量选择在进行主成分分析之前,我们需要对变量进行选择,以排除对分析结果影响较小的变量。
变量选择的方法可以根据实际情况进行确定,例如基于相关性分析、方差分析等进行选择。
3.3 数据标准化主成分分析对数据的尺度敏感,因此需要对数据进行标准化,以消除不同变量间的量纲差异。
常用的数据标准化方法包括Z-score标准化和Min-Max标准化等。
4. 主成分分析4.1 主成分提取主成分提取是主成分分析的核心步骤,通过将原始变量线性组合得到一组新的主成分,用于解释原始变量的方差。
在SPSS中,我们可以使用特征值、特征向量和累计方差贡献率等指标来选择主成分的数量。
4.2 因子载荷矩阵因子载荷矩阵是主成分分析的结果之一,用于描述原始变量与主成分之间的相关性。
每个元素表示对应变量在对应主成分上的权重,权重越大表示对应变量与主成分相关性越高。
4.3 解释方差贡献率解释方差贡献率是衡量主成分分析结果解释数据方差能力的指标,表示由每个主成分所解释的总方差的百分比。

用SPSS进行详细的主成分分析步骤主成分分析是一种常用的多元统计分析方法,用于降低数据的维度从而简化数据集。
SPSS(统计软件)提供了强大的主成分分析功能,以下是详细的主成分分析步骤。
步骤1:打开数据集首先,打开SPSS软件并加载需要进行主成分分析的数据集。
选择“文件”>“打开”>“数据”,浏览并选择要进行主成分分析的数据文件,然后点击“打开”。
步骤2:选择变量在SPSS中,主成分分析可以应用于数值型变量。
在“数据视图”中,选择需要进行主成分分析的变量。
你可以按住Ctrl键选择多个变量,或者按住Shift键选择连续的变量。
步骤3:进行主成分分析在SPSS的主菜单中,选择“分析”>“降维”>“因子”(或者“主成分”)。
这将打开主成分分析的对话框。
步骤4:选择成分数量在主成分分析对话框中,选择“主成分”选项卡。
在该选项卡,你需要指定要提取的主成分数量。
通常,一个好的经验是提取具有特征值大于1的主成分。
步骤5:选择成分提取方法在同一选项卡,你可以选择主成分的计算方法。
最常用的方法是“主成分”和“因子”,但在大部分情况下,“主成分”方法效果更好。
步骤6:选择旋转方法在主成分分析对话框的“旋转”选项卡中,你可以选择使用特定的旋转方法。
主成分的旋转可以帮助解释和可解释性。
最常用的旋转方法是“变量最大化”(Varimax)或“正交旋转”。
步骤7:输出选项在主成分分析对话框的“输出”选项卡中,你可以选择需要输出的结果。
例如,你可以选择输出成分系数矩阵、方差解释和旋转后的成分矩阵等。
步骤8:点击运行完成以上设置后,点击“确定”按钮来运行主成分分析。
SPSS将执行主成分分析,并在输出窗口中显示结果。
步骤9:解释结果通过分析输出结果,你可以解释每个主成分的方差解释比例、因子载荷和特征值等。
方差解释比例表示每个主成分对总方差的贡献程度。
因子载荷表示每个变量对每个主成分的贡献程度。
步骤10:绘制因子图在SPSS中,你还可以绘制因子图来可视化主成分分析的结果。


主成分分析在SPSS中的实现和案例
主成分分析(PCA)是一种常用的数据降维方法,可以将多个相关变量转化为少数几个无关的主成分。
在SPSS中实现PCA的步骤如下:
1. 打开SPSS软件,并打开需要进行PCA分析的数据集。
2. 选择“分析”菜单下的“降维”选项,再选择“因子”。
3. 在弹出的窗口中,选择需要进行PCA分析的变量,添加至“因子”列表中。
4. 点击“提取”按钮,选择提取主成分的方式,可以选择保留的主成分个数或者保留的方差比例。
5. 点击“确定”按钮,返回因子分析结果窗口,可以查看提取的主成分特征根、方差贡献率以及旋转后的载荷矩阵等信息。
下面介绍一个PCA的案例:假设研究人员要对顾客满意度进行研究,数据集包括顾客的年龄、性别、消费金额、服务态度、产品质量等变量。
为了降低变量维度,可以进行PCA分析。
在SPSS 中进行该分析的步骤如上述操作。
结果表明,经过PCA分析,可以选择保留3个主成分,解释总方差达到了80%以上。
第一主成分代表消费水平,第二主成分代表服务品质,第三主成分代表年龄和性别。
这说明顾客的满意度受到这3个方面的影响较大。
总之,主成分分析在SPSS中的实现方法简单易行,可以有效地解决多变量相关性较强的问题,为研究提供更加深入的解释和认识。

本科学生综合性、设计性实验报告实验课程名称统计分析软件应用开课学期2010至2011学年下学期上课时间2011 年4 月25 日辽宁师范大学教务处编印、实验方案、实验目的:掌握主成分分析的思想和具体步骤。
掌握SPSS实现主成分分析的具体操作,并对处理结果做出解释。
5、参考文献:[1]卢纹岱.SPSS for Window銃计分析[M].电子工程出版社,2006[2]郭显光.如何用SPS歎件进行主成分分析[J].统计与信息论坛,1998, (2)[3]何晓群.现代统计分析方法与应用[M].中国人民大学出版社,1998[4]余建英、何旭宏.数据统计分析与SPSS^用[M].人民邮电出版社,2003、实验报告1、 实验目的、设备与材料、理论依据、实验方法步骤见实验设计方案2、 实验现象、数据及结果表1描述性统计量表表2主成分因子荷载矩阵表表3相关系数矩阵表表4公因子方差表Descriptive Statistics图1碎石图Component U 刨乡至拜占,3 GQmponenls extrudedCommunalitiesExtraction Method: Principal Component Analysis.表总方差分解表Total Variance ExplainedCompoiieint initial EigenvaluesExtraction Sums of Squared Loadings Tota J cf Variance Cumulabv? % Total % of '/a™nee Cumulative %1 3&14 48.929 +£.929 3.914 4S929 48.92921 312 23.BSS 723271.912 23B96 72 S2? 3■1.430 17.9911.43917 曲■!&G.S1B4 S79 7.335 SB.'353 5,1441,797 9^.3506.012150 100.000 76 13E-Q13 7.66E-017 1Q0JO0S-4.2E-016-4.25E-015IQO.OOQExtraction Method: Prkicipal Component AnalysisInitial Extraction赔付率1.000 .964 净收入与总收入之比 1.000 .993 投资收益率 1.000 .923 再保险率 1.000 .968 总资产报酬率 1.000 .919 两年保费收入收益率 1.000 .659 保费收入变化率 1.000 .961 流动性比率 1.000.879Plolb1= *X1+*X2+**X4+*X5+***X8b2=*X1+**X3+***X6+*X7+*X8 b3=*X1+*X2+*X3+***X6+**X8表7Y1= *x1+*x2+**x4+*x5+***x8 Y2=*xi+*x2- **x4+*x5+***x8 Y3=*x1+*x2+*x3+*x4+**x6+**x8加权:输出结果,并从高到低进行排序:表81:人保2:平安3:太平洋4:大众5:华泰6:永安7:华安 Z 主成分综合得分Num 1 Z 主成分综合得分 | Num华泰1:人保可以如上所述计算主成分得分,还可以通过综合评价函数计算综合得分综合评价函数:Z=%*Y1+%*Y2+%*Y34、结论:表8中,综合得分出现负值,这只表明该保险公司的综合水平处于平均水平之下。

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
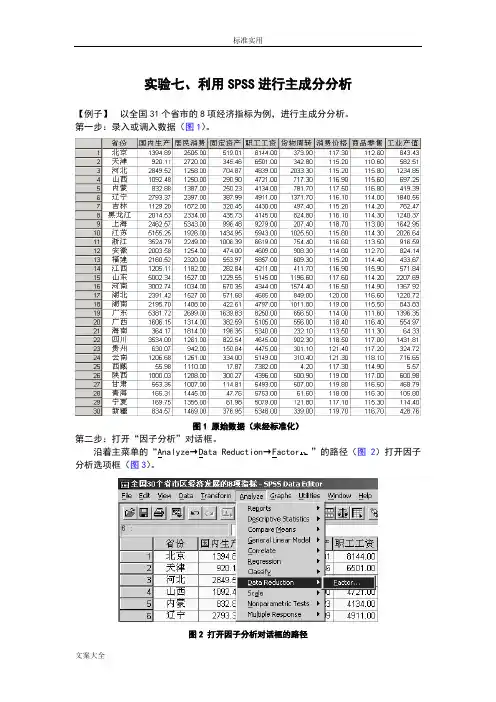
实验七、利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 统计 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Principal Components ),因此对此栏不作变动,就是认可了主成分分析方法。

利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据⒋其它。
图8 主成分分析的结果第四步,结果解读。
在因子分析结果(Output )中,首先给出的Descriptive Statistics ,第一列Mean 对应的变量的算术平均值,计算公式为∑==ni ij j x n x 11第二列Std. Deviation 对应的是样本标准差,计算公式为2/112])(11[∑=--=ni j ij j x x n σ 第三列Analysis N 对应是样本数目。
这一组数据在分析过程中可作参考。
Descriptive Statistics1921.0931474.80603301745.933861.6419330511.5083402.88548305457.6331310.2180530666.1400459.9669930117.2867 2.025*******.9067 1.8980830862.9980584.5872630国内生产居民消费固定资产职工工资货物周转消费价格商品零售工业产值Mean Std. Deviation Analysis N接下来是Correlation Matrix(相关系数矩阵),一般而言,相关系数高的变量,大多会进入同一个主成分,但不尽然,除了相关系数外,决定变量在主成分中分布地位的因素还有数据的结构。
相关系数矩阵对主成分分析具有参考价值,毕竟主成分分析是从计算相关系数矩阵的特征根开始的。
相关系数阵下面的Determinant=1.133E-0.4是相关矩阵的行列式值,根据关系式0)det(=-R I λ可知,det(λI )=det(R ),从而Determinant=1.133E-0.4=λ1*λ2*λ3*λ4*λ5*λ6*λ7*λ8。
这一点在后面将会得到验证。
在Communalities(公因子方差)中,给出了因子载荷阵的初始公因子方差(Initial )和提取公因子方差(Extraction ),后面将会看到它们的含义。

统计分析软件应用SPSS-主成分分析实验报告本实验采用SPSS软件搭配PCA算法,运用主成分分析(Principal Component Analysis)对数据建模,从而对原始数据进行数据挖掘,挖掘出其内在关联性及约束条件。
1.实验介绍主成分分析分析的数据主要是离散(或连续)的变量矩阵,它是将一组变量转换成一组新的变量,称为主成分,这些新变量有不同程度的解释能力,可以代表输入变量的内在趋势。
2.实验方法以SPSS软件中的主成分分析为例,具体进行主成分分析如下:(1)通过点击“分析”菜单栏的“统计方法”按钮打开对话框;(2)在统计方法中选择“主成分分析”;(3)选择变量;(4)设置相关的参数,其中的设置包括是否对输入变量进行标准化或是与原来输入变量一样不标准化等;(5)然后点击“OK”运行。
3.实验结果运行之后,SPSS软件就会给出主成分分析的结果,其主要内容有:载荷矩阵、方差表、方差序列图、因子得分表。
4.载荷矩阵载荷矩阵主要是列出每个原始变量与主成分的相关性,矩阵中的值代表相关系数,是两个变量之间的变化关系,相关系数的大小代表其相关性。
5.方差表方差表包括每个主成分的方差以及其贡献率,贡献率表示每个成分在总方差中所占的比重,通过该表可以较好地分析出因子各自所占方差比重。
6.方差序列图方差序列图是指把所有主成分的方差按从高到低的顺序排列,从而构成的图形,它可以清晰地展示每个成分的贡献率。
7.因子得分表因子得分表主要是列出每个观测值在每个主成分上的因子得分,利用因子得分可以更精确地表征观测值的差异,从而更好地挖掘出内在的数据关联。
5.结论本实验使用SPSS软件中的主成分分析对数据进行建模,分析出数据内在的关联关系。
通过矩阵载荷分析、方差表、方差序列图以及因子得分表等计算出来的数值,可以观察出原始变量间的内在关联,从而发现其内在的趋势,从而实现数据挖掘。

对2009年我国88个房地产上市公司的因子分析分析结果:表1 KMO 和Bartlett 的检验取样足够度的Kaiser-Meyer-Olkin 度量。
.637 Bartlett 的球形度检验近似卡方398.287df 45Sig. .000 由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p值接近0,小于显著性水平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。
同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合)可知原有变量不算特别适合进行因子分析。
表2 公因子方差初始提取市盈率 1.000 .706 净资产收益率 1.000 .609 总资产报酬率 1.000 .822 毛利率 1.000 .280 资产现金率 1.000 .731 应收应付比 1.000 .561 营业利润占比 1.000 .782 流通市值 1.000 .957 总市值 1.000 .928 成交量(手) 1.000 .858 提取方法:主成份分析。
表2为公因子方差,即因子分析的初始解,显示了所有变量的共同度数据。
第一列是因子分析初始解下的变量共同度,它表明,对原有10个变量如果采用主成分分析方法提取所有特征根(10个),那么原有变量的所有方差都可被解释,变量的共同度均为1(原有变量标准化后的方差为1)。
事实上,因子个数小于原有变量的个数才是因子分析的目标,所以不可提取全部特征根;第二列是在按指定提取条件(这里为特征根大于1)提取特征根时的共同度。
可以看到,总资产报酬率、成交量、流通市值、总市值的绝大部分信息可被因子解释,这些变量的信息丢失较少。
但毛利率这一变量的信息丢失相当严重(近70%),净资产收益率、应收应付比率两个变量的信息丢失较为严重(近40%)。
因此本次因子提取的总体效果并不理想。

SPSS进行主成分分析的步骤(图文) SPSS进行主成分分析的步骤主成分分析(Principal Component Analysis, PCA)是一种常用的多元统计分析方法,用于降低数据维度并探索数据之间的关系。
SPSS是一个功能强大的统计分析软件,本文将介绍使用SPSS进行主成分分析的步骤,以图文形式进行详细说明。
一、打开SPSS软件并导入数据1. 在SPSS软件中,点击菜单栏的 "File",然后选择 "Open"。
2. 在打开的窗口中,找到并选择你要进行主成分分析的数据文件。
3. 点击 "Open",将数据导入SPSS软件中。
二、准备数据1. 在SPSS软件的数据编辑视图中,确保你要进行主成分分析的变量都已经正确导入。
2. 如果有需要,可以对数据进行预处理(如去除离群值、标准化等),以符合主成分分析的要求。
三、进行主成分分析1. 在SPSS软件的菜单栏中,选择 "Analyze",然后点击 "Dimension Reduction",再选择 "Factor..."。
2. 在弹出的对话框中,将需要进行主成分分析的变量依次移至右侧的框中。
3. 点击 "Extraction" 选项卡,选择主成分提取方法(如常用的主成分法)并设置参数。
4. 点击 "Rotation" 选项卡,选择主成分旋转方法(如常用的方差最大旋转法)并设置参数。
5. 可以点击 "Descriptives" 选项卡,勾选 "Correlation matrix" 和"KMO and Bartlett's test" 以获取更详细的分析结果。
6. 点击 "OK" 开始进行主成分分析。
四、解读主成分分析结果1. SPSS将在输出窗口中显示主成分分析的结果,包括提取的成分个数、特征根、方差贡献率等。
SPSS软件进行主成分分析的应用例子2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下:第一,将EXCEL中的原始数据导入到SPSS软件中;【1】“分析”|“描述统计”|“描述”。
【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。
【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。
所的结论:标准化后的所有指标数据。
注意:SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。
factor过程对数据进行因子分析(指标之间的相关性判定略)。
【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框;【3】设置“抽取”,勾选“碎石图”复选框;【4】设置“旋转”,勾选“最大方差法”复选框;【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框;【6】查看分析结果。
【1】将初始因子载荷矩阵中的两列数据输入( 可用复制粘贴的方法) 到数标变量”文本框中输入“F1”,然后在数字表达式中输入“V1/SQR(λ1)”[注:λ1=1.897], 即可得到特征向量F1;【3】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“F2”,然后在数字表达式中输入“V2/SQR(λ2)”[注:λ1=1.550], 即可得到特征向量F2;【4】最后得到特征向量矩阵(主成分表达式的系数)。
spss主成分分析报告目录spss主成分分析报告 (1)引言 (2)研究背景 (2)研究目的 (2)研究意义 (3)主成分分析的基本概念 (4)主成分分析的定义 (4)主成分分析的原理 (5)主成分分析的应用领域 (6)数据收集与准备 (7)数据收集方法 (7)数据预处理 (8)数据清洗 (9)主成分分析的步骤 (9)因子提取 (9)因子旋转 (10)因子解释 (11)SPSS软件在主成分分析中的应用 (12)SPSS软件的介绍 (12)数据导入与处理 (13)主成分分析的操作步骤 (14)主成分分析结果的解读 (15)因子载荷矩阵的解读 (15)方差解释率的解读 (16)因子得分的解读 (17)主成分分析的结果验证与评价 (18)因子可靠性分析 (18)因子有效性分析 (19)结果的稳定性分析 (19)主成分分析的局限性与改进 (20)主成分分析的局限性 (20)主成分分析的改进方法 (21)结论 (22)研究总结 (22)研究展望 (23)引言研究背景主成分分析(Principal Component Analysis,简称PCA)是一种常用的多元统计分析方法,广泛应用于各个领域的研究中。
它通过将原始数据转换为一组新的无关变量,即主成分,来揭示数据中的潜在结构和模式。
主成分分析不仅可以帮助我们降低数据的维度,减少冗余信息,还可以提取出数据中的主要特征,帮助我们更好地理解和解释数据。
在当今信息爆炸的时代,数据的获取和处理变得越来越重要。
各个领域的研究者和决策者需要从大量的数据中提取有用的信息,以支持决策和研究。
然而,原始数据往往包含大量的冗余信息和噪声,使得数据分析变得困难和复杂。
主成分分析作为一种有效的数据降维方法,可以帮助我们从复杂的数据中提取出关键信息,简化数据分析的过程。
主成分分析最早由卡尔·皮尔逊(Karl Pearson)于1901年提出,并在之后的几十年中得到了广泛的研究和应用。
SPSS进行主成分分析主成分分析(Principal Component Analysis,PCA)是一种基本的多变量分析方法,是一种对多个连续变量进行缩减的技术。
该方法可将一组相关性较高的变量转化为一组不相关或低度相关的变量,即主成分,并用较少的主成分代表原始变量集合,从而简化了数据。
在SPSS中,进行主成分分析有几个步骤,下面将详细讲解。
步骤一:导入数据首先,要导入需要进行主成分分析的数据。
在SPSS软件中,点击文件(File)-导入(Import)-数据(Data)菜单,选择要导入的数据文件,然后选择适当的文件格式并打开。
步骤二:选择变量导入数据后,需要选择要进行主成分分析的变量。
在SPSS中,可以通过几种不同的方式选择变量。
其中最常用的是从变量视图中选择变量。
在变量视图中,可以看到所有可用的变量和它们的属性。
要选择变量进行主成分分析,只需单击变量视图中的相应名称。
选择完成后,单击左上角的“变量”选项卡,然后单击“从选定变量生成”下拉列表中的“主成分”选项。
步骤三:设置主成分选项在选择生成主成分之后,SPSS将显示选项设置对话框。
这个对话框允许用户输入有关生成主成分的选项信息,例如是否旋转主成分、选定的变量数量、主成分提取方法等。
在这个对话框中,用户也可以选择性地过滤数据、指定变量标签、指定文件名等。
步骤四:生成主成分设置主成分选项后,可以单击“确定”按钮完成生成主成分的进程。
SPSS将根据所选的选项执行主成分分析,并将结果显示在输出区域中。
输出区域将显示主成分的概括、默认图形和标志所需的任何统计信息。
步骤五:解释主成分生成主成分后,需要对结果进行解释。
毕竟,生成的主成分只是代表原始变量的一小部分,因此它所代表的含义可能不明显。
有几种不同的方法可以解释主成分生成的结果,例如特征值分析、成分矩阵、旋转矩阵等。
结论通过SPSS进行主成分分析需要按照以上步骤进行操作。
主成分分析是一种有效的数据处理方法,对数据进行简化和解释非常有用。
实验七、利用SPSS进行主成分分析【例子】以全国31个省市得8项经济指标为例,进行主成分分析.第一步:录入或调入数据(图1)。
图1原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单得“Analyze→Data Reduction→Factor”得路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框得路径图3因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析得变量,点击右边得箭头符号,将需要得变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4).因无特殊需要,故不必理会“Value”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5).图5描述选项框在Statistics 统计栏中选中Univariate descriptives复选项,则输出结果中将会给出原始数据得抽样均值、方差与样本数目(这一栏结果可供检验参考);选中Initial solution复选项,则会给出主成分载荷得公因子方差(这一栏数据分析时有用)。
在CorrelationMatrix栏中,选中Coefficients复选项,则会给出原始变量得相关系数矩阵(分析时可参考);选中Determinant复选项,则会给出相关系数矩阵得行列式,如果希望在Excel中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue按钮完成设置(图5)。
⒉设置Extraction选项。
打开Extraction对话框(图6).因子提取方法主要有7种,在Method栏中可以瞧到,系统默认得提取方法就是主成分(Principal ponents),因此对此栏不作变动,就就是认可了主成分分析方法。
如何在SPSS数据分析报告中进行主成分分析?关键信息项1、数据准备要求2、主成分分析步骤3、结果解读方法4、报告撰写要点1、数据准备要求11 数据质量检查确保数据的完整性,不存在缺失值。
若有缺失值,需采取适当的方法进行处理,如均值插补、回归插补等。
检查数据的准确性,避免错误的数据录入。
评估数据的分布特征,判断是否符合正态分布。
若不符合,可能需要进行数据转换。
12 变量选择选择具有相关性且能反映研究问题的变量。
避免包含过多无关或冗余的变量,以免增加分析的复杂性。
13 数据标准化对数据进行标准化处理,使不同变量具有相同的量纲和可比性。
2、主成分分析步骤21 打开 SPSS 软件并导入数据启动 SPSS 程序,通过“文件”菜单中的“打开”选项导入准备好的数据文件。
22 选择主成分分析方法在“分析”菜单中,选择“降维”子菜单中的“因子分析”。
23 设置分析参数将需要分析的变量选入“变量”框。
选择提取主成分的方法,如基于特征值大于 1 或指定提取的主成分个数。
24 输出结果选项设置根据需求选择输出相关的统计量和图表,如成分矩阵、碎石图等。
25 执行分析点击“确定”按钮,执行主成分分析。
3、结果解读方法31 成分矩阵解读观察成分矩阵中各变量在主成分上的载荷值,判断变量与主成分的相关性。
载荷值的绝对值越大,表明变量与主成分的相关性越强。
32 特征值和方差贡献率关注特征值,通常选择特征值大于 1 的主成分。
方差贡献率表示主成分解释原始变量变异的比例,累计方差贡献率反映了所选主成分对原始变量信息的综合解释程度。
33 碎石图分析通过碎石图直观判断主成分的重要性和提取的合理性。
34 成分得分计算如有需要,可计算成分得分,用于后续的进一步分析或建模。
4、报告撰写要点41 研究背景和目的阐述简要介绍研究的背景、问题以及进行主成分分析的目的。
42 数据来源和预处理说明描述数据的来源、样本量以及所进行的数据预处理步骤和方法。
我们在分析问题的时候,为了准确全面的反映问题,常常收集很多变量,这些变量之间往往具有相关性,导致存在大量的重复信息,直接使用的话,不但模型非常复杂,而且所引起的共线性问题会使模型准确度降低。
对此,我们经常使用主成分分析对数据进行处理,主成分分析是考察多变量间相关性的一种多元统计分析方法,基本思想是:既然变量很多并且之间存在相关性,那么我们就将其压缩合并,通过统计分析方法将多个变量结合成少数几个有代表性的主成分,这些主成分携带了原始变量的绝大部分信息,并且之间互不相关。
有时,我们提取主成分并不是最终目的,而是希望通过它起到降维和消除变量间共线性的作用,进而再做进一步分析,因此主成分分析经常被作为某些分析的中间一环。
由于主成分分析和因子分析有很多共同之处,因此在SPSS中,二者共用一个过程
我们来看一个例子
我们希望对30个省市的经济发展情况作出分析评价,选取了8个指标,这8个指标彼此间存在关联且各指标重要性也存在差异,我们可以使用主成分分析进行初步处理
分析—降维—因子分析。
实用标准文档实验目的:原始数据中每一所高校具有20个相关性很高的变量,利用主成分分析法用较少的变量去解释原来资料中的大部分变异,将手中的众多变量转化成彼此相互独立或不相关的个数较少的变量,即所谓主成分,并用以解释资料的综合性指标,其实质的目的是降维原始数据截屏:操作方法:1.描述性统计SPS浙调用因子分析过程进行分析时,SPS泊自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS¥会直接给出标准化后的数据,然后后期的计算需得到标准化数据,则需调用“描述” 过程进行计算,为了看到标准化数据,所以采用描述性统计下的描述操作获得标准化后的变量数据标准化数据:文案大全F|Em畦拇主引M±貌被丁救师中悝十学待比出漏仔=与姑既K 7-巾式=科研卷■暑[生均同京1^6979937S1? 4T121* 75377-1 979Q0-1 (JB6D9』asciDj-1 391 Bl母W84.B39EI3 2-G9799-91 M2 -1 5U?3D-75372970W-W02-1 060 Dd.1 230313083・7BCHB 3-69799-SOTM -1 11367-69TT21317196933-7«D5戒主1辖■2S879-&D3B A-.69/991_2?042 -.38931-F5372-2.15TO1-US-1H1.S09B?•1/12319>.58750 1.167T9 S-J6?/99-1.1208a -冷/m-.67&J2 -./Z330-1_2倾斗-1-23330.41? 07-1.16156.弓询」-.35303 -翘为9-J20H -邳15-.7201;-72J30-段皿-1.040072J屹尚tai574»?9地183 7-^799-如了N TW427537? -72330」024?3-.118D9的迁-6970604683 H«979»醐鸵d J32D1C97+5 ^.723302CG0S? 1.662BB T.6T46Q 1 08^8153271成99.韵799-.?6813 -T.06?D4.76372 723X 1 07262.69*24.30648-1.6MS41卫蜘24M210.65759-.76^87 .05220-.72012 "72330-14803"744.195B9■ .SW53■ 1.3123311-6S799-.50022 -1.C204C-.72330-.»550-契H-.11005-1*319 1.05^2-539S3 12-02523 59C20-苍g "131761489473d B6?C46-1 19013-19537 r is68?4140664 2232Q-69772258«&-917J6359-777F1 1 84预• ?494?14就41,1 睫354 W50T761?9fii* 1 392M3&q罪?73&*g4-5446T 因子分析操作过程:选取变量:X1:科研经费得分X2:国家人文社科重点研究基地得分X3:院士总数得分X4:生均图书得分X5:研究中心数得分X6:国家重点实验室得分X7:生均教学科研仪器设备得分X8 :生均教育事业经费得分X9:精品课程得分X10:优秀博士生论文总分X11:人才得分X12:二级学科建设得分X13 :生均固定资产得分X14:科研论文得分X15:博导及相关合计得分X16:教师中博士学位比重得分X17: 一级学科得分X18 :高级职称比重得分X19:帅资总分X20:SCI 数量”诅也;“Di・H*I k® H部四/未舞缩-s FJC故差域I矿乎甲葬国学[i_「: r*H4ilP??TS 丫*产不炬=丁|,姑槌jiTli泛标题,• [M_[KM] HH 早期L - —一J这里分析采用相关系数矩阵,输出选择为未旋转的因子解,并选择碎石图,抽取过程选择基丁特征值(特征值大丁1),最大收敛迭代次数:25,点击确定。
因子分折:因子傅#「囱因孑分折:遥项_缺失值------------------d骚理美秘襟个案〔匚:issiia—BIU dJII ■■■■*—>:■■!& »!■■ >«—J Ilia—> :BI:«^>1 ■ ■ ■&—d ■ ■ ■ I. —>: ■:. — JI 。
挂对排晾个案史)■■'■使用均值普换旧卜系源显示格式□技大小排序B)取消小系数四)钢值如下四;.KJ [维-][取5肖][帮助j匚 _ _ ~原数据中有较多的缺失值,选择按列表排除个案,点击继续分析结果:KMC®接近1,说明变量之间的相关性越强,原有变量适合做因子分析;Bartlett 的球度检验值越小丁显著性水平0.05,越说明变量问存在相关关系。
本数据中KMC®为0.736 , sig.值为0,符合因子分析条件,可进行因子分析,并进一步进行主成分分析累计贡献率79.119%<80%由反映象相关矩阵中我们可以看出(如下图所示)反映象相关矩阵中对角线上的数值应>0.5,根据次标准,数据显示生均图书得分变量不适合做因子分析,所以删去,重新做因子分析。
去除生均图书得分变量之后的因子分析结果:KMO and Bartlett's TestEsdrsticin hrlhac1 P r nt pa Coni pons ^nalxiii累计白分比为81.466%>80%B特征值均大丁1结论:初始特征根:入1=6.901 ,,入2=4.846,入3=3.732主成分贡献率:r1=36.32%,r2=25.506%,r3=19.640%Scree Plot«nrt>u乳cComponent Number碎石图3旋转之后的主成分载荷矩阵,可以看出:SCI数量,国家重点实验室得分,研究中心数得分,研究中心数得分,科研经费得分,二级学科建设得分,科研论文得分,优秀博士生论文得分,一级学科得分,精品课程得分与主成分1密切相关,可将其总结归纳为软实力与资源指标;帅资总分,博导及相关合计得分,人才得分,院士总数得分,高级职称比重得分,教师中博士学位比重得分与主成分2密切相关,可将其归纳总结为帅资结构指标;生均教学科研仪器设备得分,生均教育事业经费得分,生均固定资产得分与主成分3密切相关,可将其归纳为学生平均资产指标。
通学«学学学w拓宏大木大— 安汶寿南川南工 西武上中四东-AQ AR主成分1主成分23. 41988 -0. 292972. 45493 -0.182761. 94171 3. 44815 1.42136 -0. 9314S 0, 68812 -0. 7817 。
・ 59关2 0, 50701 0. 566 -口 77373 0, 51097 -0.35933 0. 49&01 0. 37456 0. 49347 -0. 85663 A S 0. 3494 0. 93181复吉同湖重学nx 一X 中国药科 天津大学 酉安电子 西南交通 0. 29092 1. 6434 0. 08697 0. 3201 0. 03983 -0. 517 0. 00265 -0, 79477 -0.16043 -0. 99831 -0, 21689 -0. 73397 -0. N3039 ・0: 1639Y q 23483 -0. 0S402 -0. 23725 -0. 668612. 46333 -0. 5909 -0. 05238 -0. 87331 -0.42716 -0. 95539 2 07318 T. 11977 -1. 3207 0.10678 0.47241 0. 09926 -0. 31649 0.17576 -0, 83977 -0. 5237 -L13623 0. 63993 -1.6909-1.15616 根据主成分1得分降序排列:由主成分 1可以看出,活华大学,浙江大学,北京 大学,华中科技大学,西安交通大学,武汉大学,上海交通大学,中南大学,四川大 学,东南大学在论文发表以及国家级实验室得分方面位列前十名,其软实力雄厚;AP L AQ AR抵]学校主成分1主成分N主成分3北京大学1…94L7L 3. 44815-0. 05238中国人民-L 83959 2. 237720. 46736复旦大学0. 29092 1. 64340. 09926 北京疏范-L 20335L 53722 0. 81414山东大学-0. 4772L 1. 45219-1.15911南京大学0,34940. 931810. 472^1南开大学-0. 829 0. 60631 1. 38384 武戎大学0. 595320. 50701 -CL 95539 华莉帽-0. 88466 0. 39617-0. 23324四川大学0. 496010. 37456-L 3207 南兄农业-0. 65564 0, 34867 -0. 78545 吉林大学Q 086970. 3201 -0. 31649中山大学-0. 56447 。
・31591L 29861击国农业-0. 33419-0. 042060. 45547西安电子-0. 23483-0. 08402 -L 6909厦门大学-C. 415SS -0. 09299 0. 41851中国矿业-0. 50948 -0.15589 -0. 48764天津大学-0. 23039 -0.163970. 63993浙江大学 2. 45493 -0.18276 -0. 5909大谆理工-0., 27788 -0. 27930.15283根据主成分2得分降序排名:可以看出北京大学,中国人民大学,复旦大学等在帅资结构方面排名靠前,说明其在帅资力量上占据很大竞争力AP AR学校主成分]主成分2主成分3潢华大学 3.41988-0. 29297 2. 46333 上海交通0.566-0. 77373 2, 0731E 北京邮电-1.14089 -0. 92679 1. 52493北京交恒南开大学-0. 81644-1.29593 1. 52385 -0.S290. 60631 1. 38384口山大学-0.56447 0.31591 1.29861中国海洋-0. 30867-0.5815 1. 16706北京师范-1.20335 1.537220. 81414天津大学-0. 23039-0.163970, 63993南不入学CL 0. 931310. 4T241中国人民-1.83359 2.237720. 46T36中国农业-0. 33419-0. 04206 0. 45547厦门大学-0.41588一0.09899 0.41851问济大学0. 03983'0. 51L 0. 1T576大谨理工-0.27788 -0. 2793 0.15283东南大学0. 49347-0. 856630. 10&78复旦大学0. 29092 1.64340. 09926北京科技-0. 3209-0. 379460. 00131北京大学 1.94171 3. 44815-0. 05238华就范-0.884660.39617 -0. 23324根据主成分3得分降序排名:可以看出活华大学,上海交通大学等前十名大学在学校生均资产方面具有竞争力2>计算主成分综合得分Z=r1*FAC1+r2*FAC2+r3*FAC3主成分贡献率:r1=36.32%,r2=25.506%,r3=19.640%由综合得分可以看出:活华大学,北京大学,浙江大学,复旦大学,,,,,,等十所高校位列我国高校前十名,与武书连等国内知名统计机构结果相近,也与我国现状相似。