数据库在使用过程中会使日志文件不断增加
- 格式:doc
- 大小:247.00 KB
- 文档页数:6

Oracle物化视图定时全量刷新导致归档⽇志骤增⼀、问题描述 某项⽬组来电,说有⼀个源表约2万多条的物化视图,每5分钟定时全量(Complete)刷新⼀次,⼀天下来,导致Oracle数据库归档⽇志骤增。
⼆、问题分析及解决 先明确⼀个问题:归档⽇志(Archive Log)和重做⽇志(REDO Log)的关系。
Oracle的重做⽇志是⼀组(或⼏组)⽂件,按⼀定的规则顺序循环写,当重做⽇志写满后,从头开始写之前,如果数据库在归档模式(Archive),则在重写之前,需要把当前的重做⽇志进⾏归档(Archive),形成归档⽇志。
即归档⽇志来⾃于重做⽇志。
基于此,可以通过减少产⽣重做⽇志的量来达到减少归档⽇志量的⽬的。
综合⼀下: 1、不要全量刷新,采⽤在源表上记录物化视图⽇志的⽅式,实现快速刷新,减少更新的数据量,达到减少重做⽇志的⽬的; 2、指定物化视图为nologging模式 3、减少或取消其上的索引(2W条记录,如果使⽤得⽐较频繁,甚⾄可以考虑把它cache到内存中) 4、如果⼀定要有索引,⾃⼰写刷新的Job,先disable索引,然后刷新,然后重建索引(唯⼀索引可能有问题)。
5、评估业务、技术要求,考虑取消物化视图,建⽴⼀般视图,在访问该视图时,直接从源表中查询。
三、验证过程 验证全量刷新的物化视图产⽣的REDO⽇志的⼤⼩:-- 建⽴源表create table big_table as select * from dba_objects;-- 我机器上(11g),⼤概8W条记录select count(*) from big_table;/*开始验证全量刷新产⽣的REDO⽇志的量*/-- 建⽴物化视图create materialized view big_table_mv as select * from big_table;-- 查看⽬前REDO⽇志的量(重新启动数据库会⾃动清理)-- 记录下数值,⽤于接下来的⽐较select , b.value from v$statname a, v$mystat b where a.statisti = b.statistic# and = 'redo size';--243964-- ⼿⼯全量刷新物化视图begindbms_mview.refresh( 'BIG_TABLE_MV', 'C' );end;-- 再查看REDO⽇志的量,⽐较⼀下-- 记录下数值,⽤于接下来的⽐较select , b.value, to_char( b.value-&V, '999999999999' ) diff from v$statname a, v$mystat b where a.statistic# = b.statistic# and = 'redo size';--value:38845196--diff:38601232,增加了约37M-- 还是⽐较可观的-- 把物化视图改为nologging模式alter table big_table_mv nologging;-- 再全量刷新begindbms_mview.refresh( 'BIG_TABLE_MV', 'C' );end;-- 再查看REDO⽇志的量,⽐较⼀下-- 记录下数值,⽤于接下来的⽐较select , b.value, to_char( b.value-&V, '999999999999' ) diff from v$statname a, v$mystat b where a.statistic# = b.statistic# and = 'redo size';--value:77495608--diff:38894376,增加了约37M,全量刷新时,指定nologging没有什么效果喔。

MySQL中的日志文件和错误日志处理在数据库管理系统中,日志文件和错误日志是非常重要的组成部分。
它们记录了数据库的操作和出现的错误,提供了故障排除和性能优化的重要依据。
本文将讨论MySQL中的日志文件和错误日志处理的相关知识。
一、日志文件的作用日志文件是用于记录数据库操作过程中的各种事件和状态变化的文件。
它可以帮助我们了解数据库的运行情况、追踪问题、恢复数据和评估性能。
MySQL中常见的日志文件包括二进制日志、错误日志、查询日志和慢查询日志等。
1. 二进制日志(Binary Log)二进制日志是MySQL中最重要的日志文件之一。
它记录了所有对数据库进行修改的事件,包括数据库的创建和删除、表的结构和数据的增删改等。
二进制日志的作用主要有两个方面:一是用于数据的增量备份和恢复,二是用于数据库的主从复制。
对于数据备份和恢复,二进制日志记录了数据库的所有修改操作,我们可以通过还原所有操作来达到恢复数据的目的。
而对于主从复制,二进制日志记录了主服务器上所有的修改操作,并通过网络将这些操作传输到从服务器上执行,从而保持主从数据库的一致性。
2. 错误日志(Error Log)错误日志记录了MySQL服务器在运行过程中发生的错误和警告信息。
它可以帮助我们快速发现和排除问题,提高系统的稳定性和可靠性。
错误日志中包含了关键的错误信息,如数据库连接失败、语法错误、整数溢出等,以及警告信息,如磁盘空间不足、线程死锁等。
对于错误日志的处理,通常情况下我们可以通过查看错误日志来定位和解决问题。
对于一些警告信息,我们可以根据需要采取相应的措施,如增加磁盘空间、优化查询语句等。
3. 查询日志(General Log)查询日志记录了所有的SQL语句和执行结果,它可以帮助我们了解数据库每一步的操作过程,包括查询语句、更新语句和事务等。
查询日志的作用主要是用于调试和性能优化。
通过查看查询日志,我们可以了解到哪些查询是频繁执行的,哪些查询需要优化,从而提高数据库的性能。

清理 SQL Server 数据库日志的几种方法随着企业数据量的不断增加,数据库的日志文件也会随之增长。
数据库日志文件的不断增长会消耗大量磁盘空间,甚至会影响数据库的性能。
定期清理数据库日志是数据库管理的一个重要环节。
本文将介绍清理 SQL Server 数据库日志的几种方法,帮助数据库管理员解决数据库日志文件过大的问题。
一、备份事务日志1. 利用 SQL Server Management Studio (SSMS) 进行备份通过使用 SSMS,可以进行数据库事务日志的定期备份。
在 SSMS 中选择要备份的数据库,右键点击“任务”->“备份”,在备份类型中选择“仅事务日志”,即可完成事务日志的备份。
2. 利用 T-SQL 命令进行备份在 SQL Server 中,可以通过使用 T-SQL 命令进行事务日志的备份。
例如:```BACKUP LOG [数据库名] TO DISK = '备份文件路径' WITH NOFORMAT, NOINIT, NAME = '备份名称', SKIP, NOUNLOAD, STATS = 10```通过上述两种备份方式,可以定期备份数据库的事务日志,避免日志文件过大。
二、修改日志文件的增长方式1. 修改日志文件增长的百分比在数据库管理中,可以通过修改数据库的日志文件的增长百分比来控制日志文件的增长。
通过减小增长百分比,可以减缓日志文件的增长速度,从而减少磁盘空间的消耗。
2. 修改日志文件的增长大小除了修改增长百分比外,还可以通过修改日志文件的增长大小来控制日志文件的大小。
将增长大小设置为一个合适的值,可以避免日志文件过大,减少磁盘空间的占用。
三、截断事务日志1. 利用 SQL Server Management Studio (SSMS) 进行截断通过使用 SSMS,可以对数据库的事务日志进行截断。
在 SSMS 中选择要截断的数据库,右键点击“任务”->“收缩”->“文件”,选择要收缩的文件类型为“日志”,即可完成事务日志的截断。

数据库⽇志增长解决⽅法
数据库⽇志增长过快解决⽅法:
1: 删除LOG
1:分离数据库企业管理器->服务器->数据库->右键->分离数据库
2:删除LOG⽂件
3:附加数据库企业管理器->服务器->数据库->右键->附加数据库
此法⽣成新的LOG,⼤⼩只有500多K
再将此数据库设置⾃动收缩
或⽤代码:
下⾯的⽰例分离 pubs,然后将 pubs 中的⼀个⽂件附加到当前服务器。
EXEC sp_detach_db @dbname = 'pubs '
EXEC sp_attach_single_file_db @dbname = 'pubs ',
@physname = 'c:\Program Files\Microsoft SQL Server\MSSQL\Data\pubs.mdf '
2:清空⽇志
DUMP TRANSACTION 库名 WITH NO_LOG
再:
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩⽂件--选择⽇志⽂件--在收缩⽅式⾥选择收缩⾄XXM,这⾥会给出⼀个允许收缩到的最⼩M数,直接输⼊这个数,确定就可以了
3: 果想以后不让它增长
企业管理器->服务器->数据库->属性->事务⽇志->将⽂件增长限制为2M
1、设置数据库为简单模式
--> 数据库的属性
--> “选项”页
--> “模型”选为“简单”
2、截断⽇志,收缩数据库
backup log 数据库名 with no_log
go
dbcc shrinkdatabase(数据库名)
go。
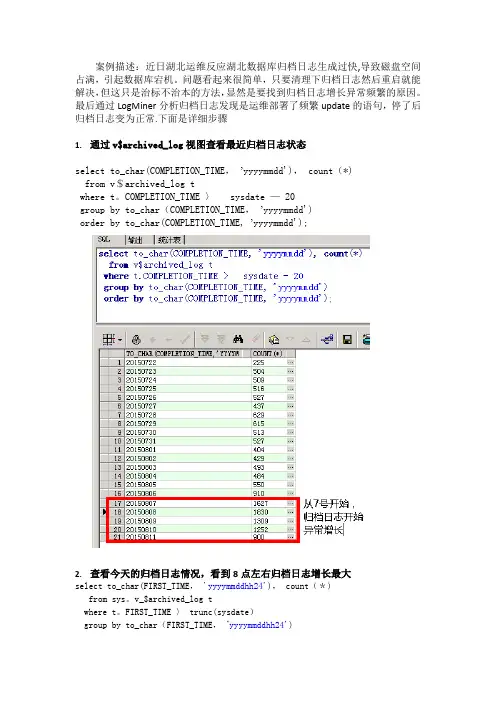
案例描述:近日湖北运维反应湖北数据库归档日志生成过快,导致磁盘空间占满,引起数据库宕机。
问题看起来很简单,只要清理下归档日志然后重启就能解决,但这只是治标不治本的方法,显然是要找到归档日志增长异常频繁的原因。
最后通过LogMiner分析归档日志发现是运维部署了频繁update的语句,停了后归档日志变为正常.下面是详细步骤1.通过v$archived_log视图查看最近归档日志状态select to_char(COMPLETION_TIME,’yyyymmdd'), count(*)from v$archived_log twhere t。
COMPLETION_TIME 〉sysdate — 20group by to_char(COMPLETION_TIME,’yyyymmdd')order by to_char(COMPLETION_TIME, ’yyyymmdd');2.查看今天的归档日志情况,看到8点左右归档日志增长最大select to_char(FIRST_TIME,'yyyymmddhh24'), count(*)from sys。
v_$archived_log twhere t。
FIRST_TIME 〉 trunc(sysdate)group by to_char(FIRST_TIME,’yyyymmddhh24')order by to_char(FIRST_TIME,'yyyymmddhh24’)3.查看今天八点的归档日志的路径select name, COMPLETION_TIME, t.FIRST_TIME, t.RESETLOGS_TIME from sys.v_$archived_log twhere to_char(FIRST_TIME,’yyyymmddhh24') = 2015081108order by t.FIRST_TIME desc;4.打开toad,连接数据库,打开日志分析工具logminer(database→diagnose→logminer)5.点击next6.把第三步得到的归档日志的路径输入file to mine7。

mysql中的optimize执行原理MySQL是一种常用的关系型数据库管理系统,它可以存储和管理大量的数据。
在使用MySQL时,经常会遇到查询性能下降的情况。
为了提升查询性能,MySQL提供了一些优化机制,其中之一就是optimize命令。
本文将详细介绍MySQL中optimize命令的执行原理。
一、什么是optimize命令?在MySQL中,optimize命令用于对表进行优化。
当表中的数据被频繁地增删改时,会导致表的碎片化,即数据在磁盘上的存储位置不连续。
这样的碎片化会影响查询性能。
使用optimize命令可以对表进行重组,使得数据在磁盘上存储连续,从而提高查询性能。
二、optimize命令的执行步骤当执行optimize命令时,MySQL会根据以下步骤来进行表的优化:1. 锁定表在执行optimize命令之前,MySQL会自动锁定要优化的表,以防止其他会话对表进行读写操作。
这是为了确保在优化过程中表的数据一致性。
2. 创建新表MySQL会创建一个新的表,用于存放优化后的数据。
这个新表的结构和原表完全相同。
3. 从原表复制数据到新表MySQL会逐行地从原表中读取数据,并将其复制到新表中。
在复制过程中,MySQL会根据行的顺序将数据写入新表,从而让数据在磁盘上存储连续。
4. 关闭原表当所有的数据都从原表复制到新表之后,MySQL会关闭原表。
这意味着原表不再接受任何读写操作。
5. 重命名新表MySQL会将新表重命名为原表的名称,这样就完成了表的优化过程。
6. 释放表锁在表优化完成后,MySQL会释放对表的锁定,其他会话就可以继续访问该表。
三、optimize命令需要注意的细节在使用optimize命令时,需要注意以下几点:1. 表的大小如果要优化的表很大,optimize命令的执行时间可能会比较长。
在执行过程中,表会被锁定,这会对其他查询和事务产生影响。
因此,需要在合适的时间执行optimize命令,避免对系统性能产生较大的影响。

SQL Server 2014 是一款功能强大的关系型数据库管理系统,广泛应用于企业级应用程序和数据存储中。
在使用 SQL Server 2014 过程中,经常会遇到主数据库日志文件过大的问题,这会影响数据库性能和稳定性。
本文将介绍主数据库日志文件过大的处理方法,帮助数据库管理员和开发人员解决这一常见问题。
1. 分析日志文件过大的原因主数据库日志文件过大通常是由于以下原因引起的:1) 未及时备份日志文件2) 长时间未进行事务日志的截断3) 数据库中存在大量的大事务操作4) 数据库的恢复模式设置不当5) 数据库中存在大量的事务日志记录2. 备份日志文件备份日志文件是解决主数据库日志文件过大问题的最直接和有效的方法。
通过定期备份日志文件,可以将事务日志记录的信息写入到数据库文件中,并且释放已经写入到数据库文件中的空间。
数据库管理员可以使用 SQL Server Management Studio 工具或者 Transact-SQL 语句来备份日志文件,具体操作步骤如下:1) 使用 SQL Server Management Studio 工具进行备份:选择数据库 -> 右键点击任务 -> 选择“备份” -> 在“备份类型”中选择“日志” -> 完成备份设置 -> 确认备份操作2) 使用 Transact-SQL 语句进行备份:执行如下命令BACKUP LOG database_name TO disk='backup_location'3. 收缩日志文件在备份日志文件之后,数据库管理员还可以通过收缩日志文件的方式来释放空间,具体操作步骤如下:1) 使用 SQL Server Management Studio 工具进行日志文件收缩:选择数据库 -> 右键点击任务 -> 选择“任务” -> 选择“收缩” -> 选择“文件” -> 完成收缩操作2) 使用 Transact-SQL 语句进行日志文件收缩:执行如下命令DBCC SHRINKFILE(logical_log_filename, target_size)4. 截断事务日志截断事务日志是指将事务日志记录的信息写入到数据库文件中,并且释放已经写入到数据库文件中的空间。

2022年北京工商大学软件工程专业《数据库原理》科目期末试卷B(有答案)一、填空题1、数据库系统在运行过程中,可能会发生各种故障,其故障对数据库的影响总结起来有两类:______和______。
2、在SELECT命令中进行查询,若希望查询的结果不出现重复元组,应在SEL ECT语句中使用______保留字。
3、在SQL Server 2000中,新建了一个SQL Server身份验证模式的登录账户LOG,现希望LOG在数据库服务器上具有全部的操作权限,下述语句是为LOG授权的语句,请补全该语句。
EXEC sp_addsrvrolemember‘LOG’,_____;4、数据仓库是______、______、______、______的数据集合,支持管理的决策过程。
5、对于非规范化的模式,经过转变为1NF,______,将1NF经过转变为2NF,______,将2NF经过转变为3NF______。
6、主题在数据仓库中由一系列实现。
一个主题之下表的划分可按______、______数据所属时间段进行划分,主题在数据仓库中可用______方式进行存储,如果主题存储量大,为了提高处理效率可采用______方式进行存储。
7、若事务T对数据对象A加了S锁,则其他事务只能对数据A再加______,不能加______,直到事务T释放A上的锁。
8、在RDBMS中,通过某种代价模型计算各种查询的执行代价。
在集中式数据库中,查询的执行开销主要包括______和______代价。
在多用户数据库中,还应考虑查询的内存代价开销。
9、数据库内的数据是______的,只要有业务发生,数据就会更新,而数据仓库则是______的历史数据,只能定期添加和刷新。
10、使某个事务永远处于等待状态,得不到执行的现象称为______。
有两个或两个以上的事务处于等待状态,每个事务都在等待其中另一个事务解除封锁,它才能继续下去,结果任何一个事务都无法执行,这种现象称为______。


数据库流式同步通俗易懂数据库流式同步,顾名思义,是指将数据在不同的数据库之间进行实时同步的过程。
在传统的数据库同步方式中,通常是通过定期扫描源数据库,然后将更新的数据批量传输到目标数据库。
而流式同步则是实时地将源数据库中的数据更改传输到目标数据库,使得目标数据库能够及时地反映源数据库的最新状态。
下面将从流式同步的原理、优势和使用场景三个方面来详细介绍数据库流式同步。
一、流式同步的原理数据库流式同步的核心原理是基于数据库的日志文件。
数据库在处理数据的过程中会产生一系列的日志记录,包括插入、更新和删除等操作。
这些日志记录可以被解析,并且将解析后的日志应用到目标数据库中,从而实现数据的同步。
流式同步的过程可以简单地分为以下几个步骤:1.源数据库产生日志:当源数据库执行数据操作时,会产生相应的日志记录。
2.解析日志:流式同步工具会解析源数据库的日志,将其转化为可读的数据变更语句。
3.应用数据变更:解析后的日志会被应用到目标数据库中,从而实现数据的同步。
二、流式同步的优势相比传统的批量同步方式,数据库流式同步具有以下几个优势:1.实时性:流式同步能够实时地将源数据库的数据变更同步到目标数据库中,保证了数据的实时性。
2.准确性:流式同步是基于数据库的日志文件来进行同步的,因此可以保证数据的准确性和完整性。
3.可靠性:由于流式同步是通过解析日志来进行数据同步的,即使在网络传输中出现问题,也不会丢失任何数据。
4.灵活性:流式同步可以根据实际需求进行配置,可以选择同步全量数据还是增量数据,并且可以选择同步的频率。
三、流式同步的使用场景数据库流式同步在以下场景中具有广泛的应用:1.多数据中心同步:当一个公司或组织在多个地理位置上有不同的数据中心时,可以使用流式同步来实现数据的实时同步,保证各个数据中心的数据一致性。
2.数据库备份和灾备:流式同步可以将主数据库的数据实时同步到备份数据库中,以实现数据的备份和灾备功能。

Oracle导致Redo⽇志暴增的SQL语句排查⼀、概述最近数据库频繁不定时的报出⼀些耗时长的SQL,甚⾄SQL执⾏时间过长,导致连接断开现象。
下⾯是⼀些排查思路。
⼆、查询⽇志的⼤⼩,⽇志组情况SELECT L.GROUP#,LF.MEMBER,L.ARCHIVED,L.BYTES /1024/1024 "SIZE(M)",L.MEMBERSFROM V$LOG L,V$LOGFILE LFWHERE L.GROUP# = LF.GROUP#;查询结果:从上图可以看出⽬前共分为10个⽇志组,每个⽇志组2个⽂件,每个⽂件⼤⼩为3G。
三、查询Oracle最近⼏天每⼩时归档⽇志产⽣数量SELECT SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) Day,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '00', 1, 0)) H00,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '01', 1, 0)) H01,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '02', 1, 0)) H02,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '03', 1, 0)) H03,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '04', 1, 0)) H04,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '05', 1, 0)) H05,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '06', 1, 0)) H06,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '07', 1, 0)) H07,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '08', 1, 0)) H08,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '09', 1, 0)) H09,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '10', 1, 0)) H10,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '11', 1, 0)) H11,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '12', 1, 0)) H12,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '13', 1, 0)) H13,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '14', 1, 0)) H14,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '15', 1, 0)) H15,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '16', 1, 0)) H16,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '17', 1, 0)) H17,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '18', 1, 0)) H18,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '19', 1, 0)) H19,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '20', 1, 0)) H20,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '21', 1, 0)) H21,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '22', 1, 0)) H22,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '23', 1, 0)) H23,COUNT(*) TOTALFROM v$log_history aWHERE first_time >= to_char(sysdate -10)GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5)ORDER BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) DESC;查询结果从上图可以看出业务⾼峰期每⼩时产⽣40个⽇志⽂件左右(⽬前设定的每个⽇志⽂件⼤⼩为3G),平均1.5分钟产⽣⼀个3G的⽇志⽂件。
Db2数据库归档日志频繁解决方法问题现象:数据库dbbde执行命令:Db2 db2stop forceDb2 db2start运行一段时间后发现,归档日志目录中日志增长很快,日志个数很多,但是日志均未写满。
每个日志只有约3M.如图S0224497.LOG-S0*******.LOG查看实际配置Log file size (4KB) (LOGFILSIZ) = 10000Number of primary log files (LOGPRIMARY) = 10Number of secondary log files (LOGSECOND) = 20一个归档日志的大小为:4KB*10000=40M 由配置看归档日志大小正常,则可能是犹豫数据库提交事物过于频繁导致归档频率加快。
解决方法:db2 activate database dbbde归档日志恢复正常。
整理:由activate database命令初始化的数据库可以由deactivate database命令关闭,也可以通过stop database manager(或db2stop)命令关闭。
如果使用activate database命令初始化一个数据库,那么最后一个与数据库断开连接的应用就不会关闭数据库。
由于命令db2stop关闭了数据库实例,重新启动数据库没有进行激活操作activate会导致每一个连接断开后会提交事物并归档,导致了日志归档频率大的问题。
同时,如果在database没有激活之前,就在应用中使用connect to database_name或隐式连接,那么应用就必须要进行等待,直到数据库管理器启动了你要连接的数据库。
一般第一个应用会引发等待数据库管理器执行数据库启动的所有开销。
可以使用activate database database_name这样的命令启动特定的数据库。
这个命令就会免除第一个应用程序连接上来的时候等候数据库初始化所花费的时间。
SQL服务器的日志增长过快问题:在C盘空间不足的情况下, C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG 下的你每天增大,大量的占用C盘的空间。
在APACS OS 版本 6.1 中,ErrorLog 文件保存在c:/Program Files/Microsoft SQL Server/MSSQL$WINCC/LOG 文件夹中。
在APACS OS 版本7.0 中,ErrorLog 文件保存在c:/Program Files/Microsoft SQL Server/MSSQL.1/MSSQL/LOG 文件夹中。
原因分析:如果很少重起mssqlserver服务,那么服务器的日志会增长得很快(每天通过重启机器启动SQL服务,好像不起作用,目前没找到原因),而且打开和查看日志的速度也会很慢。
默认情况下,SQL Server 保存7 个ErrorLog 文件,名为:ErrorLogErrorLog.1ErrorLog.2ErrorLog.3ErrorLog.4ErrorLog.5ErrorLog.6ErrorLog 文件包含最新信息;ErrorLog.6 文件包含最老的信息。
每次重启动SQL Server 时,这些日志文件都如下循环:删除ErrorLog.6 文件中的所有数据,并创建一个新的ErrorLog 文件。
上个ErrorLog 文件中的所有数据被写入到ErrorLog.1 文件中。
上个ErrorLog.1 文件中的所有数据被写入到ErrorLog.2 文件中。
上个ErrorLog.2 文件中的所有数据被写入到ErrorLog.3 文件中。
上个ErrorLog.3 文件中的所有数据被写入到ErrorLog.4 文件中。
上个ErrorLog.4 文件中的所有数据被写入到ErrorLog.5 文件中。
上个ErrorLog.5 文件中的所有数据被写入到ErrorLog.6 文件中。
作者: 付利军;杨金劳
作者机构: 山西运城农业职业技术学院,山西运城044000
出版物刊名: 吕梁教育学院学报
页码: 61-63页
年卷期: 2012年 第1期
主题词: SQL;Server;日志文件;增长
摘要:SQL Server使用日志文件记录所有事务和每个事务对数据库所做的修改。
由于每个操作都会被记录于日志文件中,因此不恰当的设置会让日志文件不断增长,而不合理的数据处理会令日志文件快速增长。
正因为如此,许多用户寻求不记录日志的处理方法,以避免日志文件增长,这其实是一种错误的方法,日志文件增长过快应该用正确的方法去处理,而不是避免SQL Server记录日志。
sqlserver⽇志⽂件不停增长的原因⽇志不停增长的原因
1.数据库是完整模式,但是并没有定期的进⾏⽇志备份。
⽇志备份可以截断事务,可以使得空间重⽤。
解决这个问题,只需做好⽇志定时备份的计划作业就⾏
2.有事务长时间没有提交
由于开发⼈员的粗⼼⼤意,没有把已经运⾏完成的事务提交,⽇志⼀直在记录,导致很⼤
解决这个问题,查找出已经运⾏完成但没有提交的事务,kill掉此事务即可
3.有很⼤的事务正在运⾏
这个事务很⼤,⼀直不停的在记录⼤量的⽇志,导致⽇志增⼤
解决这个问题,看看在语句和业务逻辑上看看能否优化的余地,运⾏很⼤的事务能否分事务运⾏
造成2,3两种情况的根本原因是因为:⽇志备份只备份已提交的事务
还需要注意的是:只有⽇志备份才能截断⽇志,使得⽇志空间可以重⽤
转载请注明出处。
数据库恢复模式为完整模式的情况下做日志缩小处理:use masterDBCC SQLPERF(LOGSPACE)GOSELECT name,recovery_model_desc,log_reuse_wait,log_reuse_wait_descFROM sys.databases where name=’DBname ‘GO查看log_reuse_wait_desc,如果为LOG_BACKUP,则是因为数据库未做过事务日志备份,那么做一下事务日志备份即可,因为事务日志未产生截断,所以不能进行收缩处理。
做事务日志备份就可以产生截断了。
做完事务日志的备份后,再执行上述语句,查看log_reuse_wait_desc,则此时为nothing.那么就可以直接做数据库收缩操作了。
收缩后,按需要指定事务日志的大小,并据需要做数据库的事务日志备份。
事务日志(Transaction logs)是数据库结构中非常重要但又经常被忽略的部分。
由于它并不像数据库中的schema那样活跃,因此很少有人关注事务日志。
事务日志是针对数据库改变所做的记录,它可以记录针对数据库的任何操作,并将记录结果保存在独立的文件中。
对于任何每一个事务过程,事务日志都有非常全面的记录,根据这些记录可以将数据文件恢复成事务前的状态。
从事务动作开始,事务日志就处于记录状态,事务过程中对数据库的任何操作都在记录范围,直到用户点击提交或后退后才结束记录。
每个数据库都拥有至少一个事务日志以及一个数据文件。
出于性能上的考虑,SQL Server将用户的改动存入缓存中,这些改变会立即写入事务日志,但不会立即写入数据文件。
事务日志会通过一个标记点来确定某个事务是否已将缓存中的数据写入数据文件。
当SQL Server重启后,它会查看日志中最新的标记点,并将这个标记点后面的事务记录抹去,因为这些事务记录并没有真正的将缓存中的数据写入数据文件。
这可以防止那些中断的事务修改数据文件。
数据库在使用过程中会使日志文件不断增加,使得数据库的性能下降,并且占用大量的磁盘空间。
SQL Server数据库都有log文件,log文件记录用户对数据库修改的操作。
可以通过直接删除log文件和清空日志在清除数据库日志。
一、删除LOG
1、分离数据库。
分离数据库之前一定要做好数据库的全备份,选择数据库——右键——任务——分离。
勾选删除连接
分离后在数据库列表将看不到已分离的数据库。
2、删除LOG文件
3、附加数据库,附加的时候会提醒找不到log文件。
删除数据库信息信息的ldf文件:
附加数据库之后将生成新的日志文件log,新的日志文件的大小事504K。
也可以通过命令才完成以上的操作:
use master;
exec sp_detach_db @dbname='TestDB';
exec sp_attach_single_file_db @dbname='TestDB',@physname='D:\Program Files\Microsoft SQL Server\MSSQL10.SQL2008\MSSQL\DATA\TestDB.mdf'
二、清空日志
该命令在SQL Server 2005和2000支持,SQL Server 2008不支持该命令。
DUMP TRANSACTION TestDB WITH NO_LOG
三、收缩数据库文件
DBCC SHRINKFILE ('TestDB_log',1)
四、截断事务日志
BACKUP LOG TestDB WITH NO_LOG
该命令在SQL Server 2008也是不支持,在SQL Server 2005和2000可以使用。
清除SQLServer2005的LOG文件
--最好备份日志,以后可通过日志恢复数据。
以下为日志处理方法
一般不建议做第4,6两步
第4步不安全,有可能损坏数据库或丢失数据
第6步如果日志达到上限,则以后的数据库处理会失败,在清理日志后才能恢复.
--*/
--下面的所有库名都指你要处理的数据库的库名
1.清空日志
DUMP TRANSACTION库名WITH NO_LOG
2.截断事务日志:
BACKUP LOG库名WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件
--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
--选择数据文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
也可以用SQL语句来完成
--收缩数据库
DBCC SHRINKDATABASE(库名)
--收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器--服务器--数据库--右键--分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器--服务器--数据库--右键--附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 pubs,然后将 pubs 中的一个文件附加到当前服务器。
a.分离
EXEC sp_detach_db @dbname='库名'
b.删除日志文件
c.再附加
EXEC sp_attach_single_file_db @dbname='库名',
@physname='c:\Program Files\Microsoft SQL Server\MSSQL\Data\库名.mdf'
5.为了以后能自动收缩,做如下设置:
企业管理器--服务器--右键数据库--属性--选项--选择"自动收缩"
--SQL语句设置方式:
EXEC sp_dboption '库名', 'autoshrink', 'TRUE'
6.如果想以后不让它日志增长得太大
企业管理器--服务器--右键数据库--属性--事务日志
--将文件增长限制为xM(x是你允许的最大数据文件大小)
--SQL语句的设置方式:
alter database库名 modify file(name=逻辑文件名,maxsize=20)
SQL Server 数据库使用时间一长就会导致Log文件逐渐变的庞大, 想备份一下数据库, 想发给谁都很困难
运行下面的语句就可以清到Log文件只剩下1M左右的空间.
DUMP TRANSACTION 数据库名 WITH NO_LOG
DBCC SHRINKDATABASE('数据库名',TRUNCATEONLY)
不重启SQL服务,删除SQLServer系统日志
SQLServer的系统日志过大,就会引起SQLServer服务器无法启动等一系列问题。
今天我遇到了这个问题,在网上搜索了一下,解决方法是删除就可以了,可是当前的ErrorLog正在被SQL使用无法删除啊,要删除只能停止SQL服务器,难道就没有别得办法了吗?
回答是肯定的:使用以下存储过程:EXEC sp_cycle_errorlog
注释
每次启动 SQL Server 时,当前错误日志重新命名为 errorlog.1;errorlog.1 成为 errorlog.2,errorlog.2 成为 errorlog.3,依次类推。
sp_cycle_errorlog 使您得以循环错误日志文件,而不必停止而后再启动服务器。