计量经济学-第一章 简单回归模型
- 格式:ppt
- 大小:286.01 KB
- 文档页数:48
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
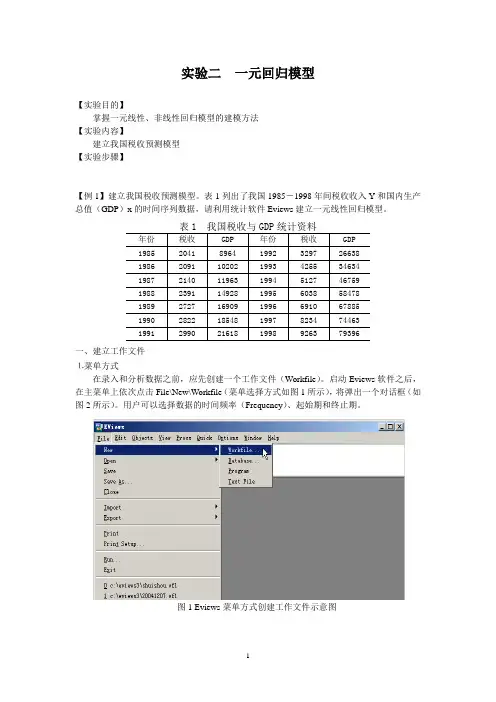
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。

《计量经济学》实验报告一元线性回归模型
三、实验步骤(简要写明实验步骤)
1、数据的输入、编辑
2、图形分析与描述统计分析
3、数据文件的存贮、调用
4、一元线性回归的过程
点击view中的Graph-scatter-中的第三个获得
在上方输入ls y c x回车得到下图
在上图中view处点击view-中的actual,Fitted,Residual中的第一个得到回归残差
打开Resid中的view-descriptive statistics得到残差直方图
打开工作文件第二个中的structure将workfiels选中第一个,将右边改为16个
之后打开工作文件xy右键双击,open-as grope
在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图
在上方空白处输入ls y c s---之后点击proc 中的forcase 根据
公式)|(0^
0X Y Y E 得到2015估计量
四、实验结果及分析(将本问题的回归模型写出,并作出经济意义检。

计量经济学作业姓名:***班级:08级数学一班学号:***********简单线性回归模型一、建立模型为了研究四川省城镇具名消费支出以及可支配收入之间的关系,又经济理论分析可知,收入是影响居民消费支出的主要因素,居民消费支出Y与可支配收入X之间存在密切的关系,消费支出随着收入的增加而增加,但变动的幅度相比较低,即边际消费倾向MPC有0<MPC<1。
因此可设定居民消费支出Yi与Xi的关系为:Yi=ß1+ß2Xi+ui,其中ß1表示四川省城镇居民家庭平均每人年生活性消费支出(元);Xi为城镇居民家丁平均没人年可支配收入(元)。
变量采用年度数据,样本期为1978-1998年。
这里的ß1为居民没有收入来源时的最低消费。
二、估计模型中的位置参数假设模型中的随机误差项ui满足古典假定,运用OLS方法估计模型的参数,利用计量经济学计算机软件EViews计算过程如下:简历文档,输入数据首先点击EViews图标,进入EViews主页。
点击File后,在File菜单的New选项中点击Workfile,这时屏幕上出现Workfile Range对话框,在Srart Date里键入1978,在End Date里键入1998,点击OK后屏幕出现Workfile工作框。
在Object菜单栏,点击New Object对话框里选Group并在Name for Object上定义文件名,点击OK,屏幕出现数据编辑框。
也可在光标出直接输入Data Y X,回车后即可出现数据编辑框。
此时可录入数据,首先按上行键,这时对应“obs”字样的空格会自动上跳,在对应第二个“obs”字样,有边框的空格里键入变量名,再按下行键,这时对应变量名下的这一列出现“NA”字样,便可依时间顺序键入相应的数据。
其他变量的数据类似输入。
可以几个变量同时录入数据。
在主页上选Quick菜单,点击Eatimate Equation项,屏幕上出现估计对话框(Equation Spacification),在Easmation Setting中选OLS估计,即Least Squares,键入Y C X或Y X C(C为EViews固定的截距系数)。
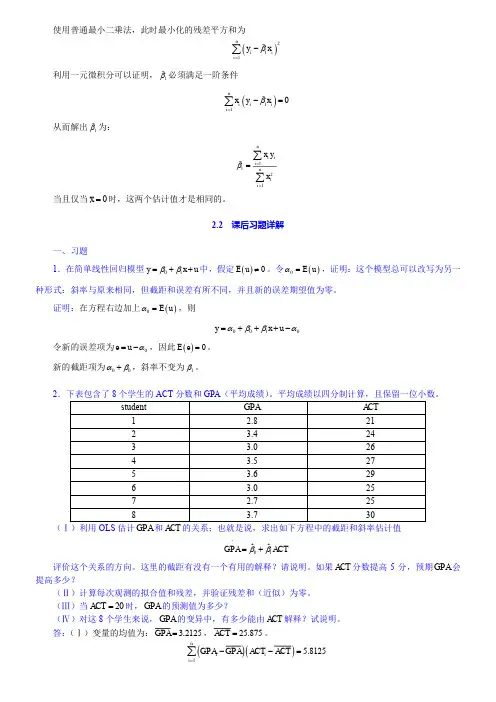
使用普通最小二乘法,此时最小化的残差平方和为()211niii y x β=-∑利用一元微积分可以证明,1β必须满足一阶条件()110niiii x y x β=-=∑从而解出1β为:1121ni ii nii x yxβ===∑∑当且仅当0x =时,这两个估计值才是相同的。
2.2 课后习题详解一、习题1.在简单线性回归模型01y x u ββ=++中,假定()0E u ≠。
令()0E u α=,证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:在方程右边加上()0E u α=,则0010y x u αββα=+++-令新的误差项为0e u α=-,因此()0E e =。
新的截距项为00αβ+,斜率不变为1β。
2(Ⅰ)利用OLS 估计GPA 和ACT 的关系;也就是说,求出如下方程中的截距和斜率估计值01ˆˆGPA ACT ββ=+^评价这个关系的方向。
这里的截距有没有一个有用的解释?请说明。
如果ACT 分数提高5分,预期GPA 会提高多少?(Ⅱ)计算每次观测的拟合值和残差,并验证残差和(近似)为零。
(Ⅲ)当20ACT =时,GPA 的预测值为多少?(Ⅳ)对这8个学生来说,GPA 的变异中,有多少能由ACT 解释?试说明。
答:(Ⅰ)变量的均值为: 3.2125GPA =,25.875ACT =。
()()15.8125niii GPA GPA ACT ACT =--=∑根据公式2.19可得:1ˆ 5.8125/56.8750.1022β==。
根据公式2.17可知:0ˆ 3.21250.102225.8750.5681β=-⨯=。
因此0.56810.1022GPA ACT =+^。
此处截距没有一个很好的解释,因为对样本而言,ACT 并不接近0。
如果ACT 分数提高5分,预期GPA 会提高0.1022×5=0.511。
(Ⅱ)每次观测的拟合值和残差表如表2-3所示:根据表可知,残差和为-0.002,忽略固有的舍入误差,残差和近似为零。

计量经济学复习要点第1章 绪论数据类型:截面、时间序列、面板用数据度量因果效应,其他条件不变的概念 习题:C1、C2第2章 简单线性回归回归分析的基本概念,常用术语现代意义的回归是一个被解释变量对若干个解释变量依存关系的研究,回归的实质是由固定的解释变量去估计被解释变量的平均值;简单线性回归模型是只有一个解释变量的线性回归模型; 回归中的四个重要概念1. 总体回归模型Population Regression Model,PRMt t t u x y ++=10ββ--代表了总体变量间的真实关系;2. 总体回归函数Population Regression Function,PRFt t x y E 10)(ββ+=--代表了总体变量间的依存规律;3. 样本回归函数Sample Regression Function,SRFtt t e x y ++=10ˆˆββ--代表了样本显示的变量关系; 4. 样本回归模型Sample Regression Model,SRMtt x y 10ˆˆˆββ+=---代表了样本显示的变量依存规律; 总体回归模型与样本回归模型的主要区别是:①描述的对象不同;总体回归模型描述总体中变量y 与x 的相互关系,而样本回归模型描述所关的样本中变量y 与x 的相互关系;②建立模型的依据不同;总体回归模型是依据总体全部观测资料建立的,样本回归模型是依据样本观测资料建立的;③模型性质不同;总体回归模型不是随机模型,而样本回归模型是一个随机模型,它随样本的改变而改变;总体回归模型与样本回归模型的联系是:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是用来估计总体回归模型; 线性回归的含义线性:被解释变量是关于参数的线性函数可以不是解释变量的线性函数 线性回归模型的基本假设简单线性回归的基本假定:对模型和变量的假定、对随机扰动项u 的假定零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定 普通最小二乘法原理、推导最小二乘法估计参数的原则是以“残差平方和最小”;Min21ˆ()niii Y Y =-∑01ˆˆ(,)ββ: 1121()()ˆ()nii i n ii XX Y Y X X ==--β=-∑∑ , 01ˆˆY X β=-βOLS 的代数性质拟合优度R 2离差平方和的分解:TSS=ESS+RSS“拟合优度”是模型对样本数据的拟合程度;检验方法是构造一个可以表征拟合程度的指标——判定系数又称决定系数;121SSE SST SSR SSRR SST SST SST-===-,表示回归平方和与总离差平方和之比;反映了样本回归线对样本观测值拟合优劣程度的一种描述; 2 2[0,1]R ∈;3 回归模型中所包含的解释变量越多,2R 越大改变度量单位对OLS 统计量的影响函数形式对数、半对数模型系数的解释101ˆˆˆi iY X =β+β:X 变化一个单位Y 的变化 201ˆˆˆln ln i i Y X =β+β: X 变化1%,Y 变化1ˆβ%,表示弹性; 301ˆˆˆln i i Y X =β+β:X 变化一个单位,Y 变化百分之1001ˆβ 401ˆˆˆln i i Y X =β+β:X 变化1%,Y 变化1ˆβ%; OLS 无偏性,无偏性的证明 OLS 估计量的抽样方差 误差方差的估计 OLS 估计量的性质1线性:是指参数估计值0β和1β分别为观测值t y 的线性组合; 2无偏性:是指0β和1β的期望值分别是总体参数0β和1β; 3最优性最小方差性:是指最小二乘估计量0β和1β在在各种线性无偏估计中,具有最小方差;高斯-马尔可夫定理OLS 参数估计量的概率分布2^22()iVar x σβ=∑OLS 随机误差项μ的方差σ2的估计 简单回归的高斯马尔科夫假定 对零条件均值的理解习题:4、5、6;C2、C3、C4第3章 多元回归分析:估计1、变量系数的解释剔除、控制其他因素的影响对斜率系数1ˆβ的解释:在控制其他解释变量X2不变的条件下,X1变化一个单位对Y 的影响;或者,在剔除了其他解释变量的影响之后,X1的变化对Y 的单独影响2、多元线性回归模型中对随机扰动项u 的假定,除了零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定以外,还要求满足无多重共线性假定;3、多元线性回归模型参数的最小二乘估计式;参数估计式的分布性质及期望、方差和标准误差;在基本假定满足的条件下,多元线性回归模型最小二乘估计式是最佳线性无偏估计式;最小二乘法 OLS 公式:Y ' X X)' (X ˆ-1=β 估计的回归模型:的方差协方差矩阵:残差的方差 : 估计的方差协方差矩阵是: 拟合优度 遗漏变量偏误 多重共线性多重共线性的概念多重共线性的后果 多重共线性的检验 多重共线性的处理习题:1、2、6、7、8、10;C2、C5、C6第4章 多元回归分析:推断经典线性模型假定 正态抽样分布2^22i e n σ=-∑变量显着性检验,t 检验 检验β值的其他假设 P 值实际显着性与统计显着性 检验参数的一个线性组合假设 多个线性约束的检验:F 检验 理解排除性约束 报告回归结果习题:1、2、3、4、6、7、10、11;C3、C5、C8第6章 多元回归分析:专题测度单位对OLS 统计量的影响 进一步理解对数模型 二次式的模型 交互项的模型 拟合优度修正可决系数的作用和方法;习题:1、3、4、7;C2、C3、C5、C9、C12第7章 虚拟变量虚拟变量的定义如何引入虚拟变量:如果一个变量分成N 组,引入该变量的虚拟变量形式是只能放入N-1个虚拟变量 虚拟变量系数的解释虚拟变量系数的解释:不同组均值的差基准组或对照组与处理组 以下几种模型形式表达的不同含义;1tt t t u D X Y +++=210βββ:截距项不同; 2tt t t t u X D X Y +++=210βββ:斜率不同;3tt t t t t u X D D X Y ++++=3210ββββ:截距项与斜率都不同;其中D 是二值虚拟变量,X 是连续的变量;虚拟变量陷阱虚拟变量的交互作用习题:2、4、9;C2、C3、C6、C7、C11第8章异方差异方差的后果异方差稳健标准误BP检验异方差的检验White检验加权最小二乘法习题:1、2、3、4;C1、C2、C8、C9Eviews回归结果界面解释表计量经济学复习题第1章习题:C1、C2第2章习题:4、5、6;C2、C3、C4第3章习题:1、2、6、7、8、10;C2、C5、C6 第4章习题:1、2、3、4、6、7、10、11;C3、C5、C8 第6章习题:1、3、4、7;C2、C3、C5、C9、C12 第7章习题:2、4、9;C2、C3、C6、C7、C11 第8章习题:1、2、3、4;C1、C2、C8、C9 1、判断下列表达式是否正确2469 2、给定一元线性回归模型:1叙述模型的基本假定;2写出参数0β和1β的最小二乘估计公式; 3说明满足基本假定的最小二乘估计量的统计性质; 4写出随机扰动项方差的无偏估计公式; 3、对于多元线性计量经济学模型:1该模型的矩阵形式及各矩阵的含义; 2对应的样本线性回归模型的矩阵形式; 3模型的最小二乘参数估计量;4、根据美国1961年第一季度至1977年第二季度的数据,我们得到了如下的咖啡需求函数的回归方程:D D D P I P t t t t t t tT Q 321'0097.0157.00961.00089.0ln 1483.0ln 5115.0ln 1647.02789.1ˆln ----++-=其中,Q=人均咖啡消费量单位:磅;P=咖啡的价格以1967年价格为不变价格;I=人均可支配收入单位:千元,以1967年价格为不变价格;P '=茶的价格1/4磅,以1967年价格为不变价格;T=时间趋势变量1961年第一季度为1,…,1977年第二季度为66;D 1=1:第一季度;D 2=1:第二季度;D 3=1:第三季度; 请回答以下问题:① 模型中P 、I 和P '的系数的经济含义是什么 ② 咖啡的需求是否很有弹性③ 咖啡和茶是互补品还是替代品 ④ 你如何解释时间变量T 的系数 ⑤ 你如何解释模型中虚拟变量的作用 ⑥ 哪一个虚拟变量在统计上是显着的 ⑦ 咖啡的需求是否存在季节效应5、为研究体重与身高的关系,我们随机抽样调查了51名学生其中36名男生,15名女生,并得到如下两种回归模型:h W5662.506551.232ˆ+-= t=h D W7402.38238.239621.122ˆ++-= t=其中,Wweight=体重 单位:磅;hheight=身高 单位:英寸 请回答以下问题:① 你将选择哪一个模型为什么② 如果模型确实更好,而你选择了,你犯了什么错误 ③ D 的系数说明了什么6、简述异方差对下列各项有何影响:1OLS 估计量及其方差;2置信区间;3显着性t 检验和F 检验的使用;4预测;7、假设某研究者基于100组三年级的班级规模CS 和平均测试成绩TestScore 数据估计的OLS 回归为:(1) 若某班级有22个学生,则班级平均测试成绩的回归预测值是多少 (2) 某班去年有19个学生,而今年有23个学生,则班级平均测试成绩变化的回归预测值是多少(3) 100个班级的样本平均班级规模为,则这100个班级的样本平均测试成绩是多少(4) 100个班级的测试成绩样本标准差是多少提示:利用R 2和SER 的公式 (5) 求关于CS 的回归斜率系数的95%置信区间;(6) 计算t 统计量,根据经验法则t=2来判断显着性检验的结果; 8、设从总体中抽取一容量为200的20岁男性随机样本,记录他们的身高和体重;得体重对身高的回归为:其中体重的单位是英镑,身高的单位是英寸;(1) 身高为70英寸的人,其体重的回归预测值是多少65英寸的呢74英寸的呢(2) 某人发育较晚,一年里蹿高了英寸;则根据回归预测体重增加多少 (3) 解释系数值和的含义;(4)假定不用英镑和英寸度量体重和身高而分别用厘米和千克,则这个新的厘米-千克回归估计是什么给出所有结果,包括回归系数估计值,R2和SER;(5)基于回归方程,能对一个3岁小孩的体重假设身高1米作出可靠预测吗9、假设某研究使用250名男性和280名女性工人的工资Wage数据估计出如下OLS回归:标准误其中WAGE的单位是美元/小时,Male为男性=1,女性=0的虚拟变量;用男性和女性的平均收入之差定义工资的性别差距;1性别差距的估计值是多少2计算截距项和Male系数的t统计量,估计出的性别差距统计显着不为0吗5%显着水平的t统计量临界值为3样本中女性的平均工资是多少男性的呢4对本回归的R2你有什么评论,它告诉了你什么,没有告诉你什么这个很小的R2可否说明这个回归模型没有什么价值5另一个研究者利用相同的数据,但建立了WAGE对Female的回归,其中Female为女性=1,男性=0的变量;由此计算出的回归估计是什么10、基于美国CPS人口调查1998年的数据得到平均小时收入对性别、教育和其他特征的回归结果,见下表;该数据集是由4000名全年工作的全职工人数据组成的;其中:AHE=平均小时收入;College=二元变量大学取1,高中取0;Female女性取1,男性取0;Age=年龄年;Northeast居于东北取1,否则为0;Midwest居于中西取1,否则为0;South居于南部取1,否则为0;West居于西部取1,否则取0;表1:基于2004年CPS数据得到的平均小时收入对年龄、性别、教育、地区的回归结果概括统计量和联合检验SERR2注:括号中是标准误;(1)计算每个回归的调整R2;(2)利用表1中列1的回归结果回答:大学毕业的工人平均比高中毕业的工人挣得多吗多多少这个差距在5%显着性水平下统计显着吗男性平均比女性挣的多吗多多少这个差距在5%显着性水平下统计显着吗(3)年龄是收入的重要决定因素吗请解释;使用适当的统计检验来回答; (4)Sally是29岁女性大学毕业生,Betsy是34岁女性大学毕业生,预测她们的收入;(5)用列3的回归结果回答:地区间平均收入存在显着差距吗利用适当的假设检验解释你的答案;(6)为什么在回归中省略了回归变量West如果加上会怎样;解释3个地区回归变量的系数的经济含义;7Juantia是南部28岁女性大学毕业生,Jennifer是中西部28岁女性大学毕业生,计算她们收入的期望差距计量经济学补充复习题一、填空题1、 计量经济学常用的三类样本数据是_横截面数据__、__时间序列数据__和_面板数据;2、虚拟解释变量不同的引入方式产生不同的作用;若要描述各种类型的模型在截距水平的差异,则以 加法形式 引入虚拟解释变量;若要反映各种类型的模型的不同相对变化率时,则以 乘法形式 引入虚拟解释变量;二、选择题1、参数的估计量βˆ具备有效性是指 BA Var βˆ=0B Var βˆ为最小C βˆ-=0D βˆ-为最小2、产量x,台与单位产品成本y, 元/台之间的回归方程为yˆ=356-,这说明 DA 产量每增加一台,单位产品成本增加356元B 产量每增加一台,单位产品成本减少元C 产量每增加一台,单位产品成本平均增加356元D 产量每增加一台,单位产品成本平均减少元3、在总体回归直线E x y10)ˆ(ββ+=中,1β表示 B A 当x 增加一个单位时,y 增加1β个单位B 当x 增加一个单位时,y 平均增加1β个单位C 当y 增加一个单位时,x 增加1β个单位D 当y 增加一个单位时,x 平均增加1β个单位4、以y 表示实际观测值,yˆ表示回归估计值,则普通最小二乘法估计参数的准则是使 DA )ˆ(i i yy -∑=0 B 2)ˆ(i i y y -∑=0 C )ˆ(i i yy -∑为最小 D 2)ˆ(i i y y -∑为最小 5、设y 表示实际观测值,yˆ表示OLS 回归估计值,则下列哪项成立 D A yˆ=y B y ˆ=y C yˆ=y D y ˆ=y 6、用普通最小二乘法估计经典线性模型t t t u x y ++=10ββ,则样本回归线通过点 DA x,yB x,yˆ C x ,yˆ D x ,y 7、判定系数2R 的取值范围是 CA 2R -1B 2R 1C 02R 1D -12R 18、对于总体平方和TSS 、回归平方和RSS 和残差平方和ESS 的相互关系,正确的是 BA TSS>RSS+ESSB TSS=RSS+ESSC TSS<RSS+ESSD TSS 2=RSS 2+ESS 29、决定系数2R 是指 CA 剩余平方和占总离差平方和的比重B 总离差平方和占回归平方和的比重C 回归平方和占总离差平方和的比重D 回归平方和占剩余平方和的比重10、如果两个经济变量x 与y 间的关系近似地表现为当x 发生一个绝对量变动x 时,y 有一个固定地相对量y/y 变动,则适宜配合地回归模型是 BA i i i u x y ++=10ββB ln i i i u x y ++=10ββC i ii u x y ++=110ββ D ln i i i u x y ++=ln 10ββ 11、下列哪个模型为常数弹性模型 AA ln i i i u x y ++=ln ln 10ββB ln i i i u x y ++=10ln ββC i i i u x y ++=ln 10ββD i ii u x y ++=110ββ 12、模型i i i u x y ++=ln 10ββ中,y 关于x 的弹性为 C A i x 1β B i x 1β C iy 1β D i y 1β 13、模型ln i i i u x y ++=ln ln 10ββ中,1β的实际含义是 BA x 关于y 的弹性B y 关于x 的弹性C x 关于y 的边际倾向D y 关于x 的边际倾向14、当存在异方差现象时,估计模型参数的适当方法是 AA 加权最小二乘法B 工具变量法C 广义差分法D 使用非样本先验信息15、加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即 BA 重视大误差的作用,轻视小误差的作用B 重视小误差的作用,轻视大误差的作用C 重视小误差和大误差的作用D 轻视小误差和大误差的作用16、容易产生异方差的数据是 CA 时间序列数据B 修匀数据C 横截面数据D 年度数据17、设回归模型为i i i u x y +=β,其中var i u =22i x σ,则的最小二乘估计量为 CA. 无偏且有效 B 无偏但非有效C 有偏但有效D 有偏且非有效18、如果模型t t t u x b b y ++=10存在序列相关,则 DA cov t x ,t u =0B cov t u ,s u =0tsC cov t x ,t u 0D cov t u ,s u 0ts19、下列哪种形式的序列相关可用DW 统计量来检验i v 为具有零均值,常数方差,且不存在序列相关的随机变量 AA t t t v u u +=-1ρB t t t t v u u u +++=-- 221ρρC t t v u ρ=D ++=-12t t t v v u ρρ20、DW 的取值范围是DA -1DW0B -1DW1C -2DW2D 0 DW421、当DW =4是时,说明 DA 不存在序列相关B 不能判断是否存在一阶自相关C 存在完全的正的一阶自相关D 存在完全的负的一阶自相关22、模型中引入一个无关的解释变量 CA 对模型参数估计量的性质不产生任何影响B 导致普通最小二乘估计量有偏C 导致普通最小二乘估计量精度下降D 导致普通最小二乘估计量有偏,同时精度下降23、如果方差膨胀因子VIF =10,则认为什么问题是严重的 CA 异方差问题B 序列相关问题C 多重共线性问题D 解释变量与随机项的相关性24、某商品需求函数为i i i u x b b y ++=10,其中y 为需求量,x 为价格;为了考虑“地区”农村、城市和“季节”春、夏、秋、冬两个因素的影响,拟引入虚拟变量,则应引入虚拟变量的个数为 BA 2B 4C 5D 625、根据样本资料建立某消费函数如下:tC ˆ=+tD +t x ,其中C 为消费,x 为收入,虚拟变量D =农村家庭城镇家庭⎩⎨⎧01,所有参数均检验显着,则城镇家庭的消费函数为AA t C ˆ=+t xB tC ˆ=+t xC t C ˆ=+t xD tC ˆ=+t x 26、假设某需求函数为i i i u x b b y ++=10,为了考虑“季节”因素春、夏、秋、冬四个不同的状态,引入4个虚拟变量形式形成截距变动模型,则模型的 DA 参数估计量将达到最大精度B 参数估计量是有偏估计量C 参数估计量是非一致估计量D 参数将无法估计27、对于模型i i i u x b b y ++=10,为了考虑“地区”因素北方、南方,引入2个虚拟变量形式形成截距变动模型,则会产生 DA 序列的完全相关B 序列不完全相关C 完全多重共线性D 不完全多重共线性28、如果一个回归模型中不包含截距项,对一个具有m 个特征的质的因素要引入虚拟变量的数目为 AA mB m-1C m-2D m+129、某一时间序列经一次差分变换成平稳时间序列,此时间序列称为A;A .1阶单整B .2阶单整C .K 阶单整D .以上答案均不正确30、当随机误差项存在自相关时,进行单位根检验是由B 来实现;A . DF 检验B .ADF 检验C .EG 检验D .DW 检验三、多项选择题:1、一元线性回归模型t t t u x y ++=10ββ的经典假设包括 ABCDEA 0)(=t u EB 2)(σ=t u Var 常数C 0),cov(=j i u uD t u ~N0,1E x 为非随机变量,且0),cov(=t t u x2、以带“”表示估计值,u 表示随机误差项,如果y 与x 为线性相关关系,则下列哪些是正确的 BEA t t x y 10ββ+=B t t t u x y ++=10ββC t t t u x y ++=10ˆˆββD tt t u x y ++=10ˆˆˆββ E tt x y 10ˆˆˆββ+= 3、用普通最小二乘法估计模型t t t u x y ++=10ββ的参数,要使参数估计量具备最佳线性无偏估计性质,则要求: ABCDEA 0)(=t u EB 2)(σ=t u Var 常数C 0),cov(=j i u uD t u 服从正态分布E x 为非随机变量,且0),cov(=t t u x4、假设线性回归模型满足全部基本假设,则其参数估计量具备 CDEA 可靠性B 合理性C 线性D 无偏性E 有效性5、下列哪些非线性模型可以通过变量替换转化为线性模型 ABC A i i i u x y ++=210ββ B i ii u x y ++=110ββ C ln i i i u x y ++=ln 10ββ D i i i u x y ++=210ββE i i i i u x y ++=ββ06、异方差性将导致 BCDEA 普通最小二乘估计量有偏和非一致B 普通最小二乘估计量非有效C 普通最小二乘估计量的方差的估计量有偏D 建立在普通最小二乘估计基础上的假设检验失效E 建立在普通最小二乘估计基础上的预测区间变宽7、当模型中解释变量间存在高度的多重共线性时 ACDA 各个解释变量对被解释变量的影响将难于精确鉴别B 部分解释变量与随机误差项之间将高度相关C 估计量的精度将大幅下降D 估计量对于样本容量的变动将十分敏感E 模型的随机误差项也将序列相关8、下述统计量可以用来检验多重共线性的严重性 ACDA 相关系数B DW 值C 方差膨胀因子D 特征值E 自相关系数三、判断题1、随机误差项u i 与残差项e i 是一回事; F2、当异方差出现时,常用的t 检验和F 检验失效; T3、在异方差情况下,通常预测失效; T四、计算分析题1、指出下列模型中的错误,并说明理由;1 tt Y C 2.1180ˆ+= 其中,C 、Y 分别为城镇居民的消费支出和可支配收入;2 tt t L K Y ln 28.0ln 62.115.1ˆln -+= 其中,Y 、K 、L 分别为工业总产值、工业生产资金和职工人数;2、对下列模型进行适当变换化为标准线性模型:(1) y =0β+1βx 1+2β21x +u ; (2) Q =A u e L K βα;(3) Y =exp 0β+1βx+u ;3、一个由容量为209的样本估计的解释CEO 薪水的方程为:其中,Y 表示年薪水平单位:万元, 1X 表示年收入单位:万元, 2X 表示公司股票收益单位:万元; 321D D D ,,均为虚拟变量,分别表示金融业、消费品工业和公用事业;假设对比产业为交通运输业;(1) 解释三个虚拟变量参数的经济含义;(2) 保持1X 和2X 不变,计算公用事业和交通运输业之间估计薪水的近似百分比差异;这个差异在1%的显着性水平上是统计显着吗消费品工业和金融业之间估计薪水的近似百分比差异是多少。





实验一:简单线性回归模型的建立与分析应用【实验目的】1、熟悉计量经济学软件包EViews的界面和基本操作;2、掌握计量经济学分析实际经济问题的具体步骤;3、掌握简单线性回归模型的参数估计、统计检验、预测的基本操作方法;4、理解简单线性回归模型中参数估计值的经济意义。
【实验类型】综合型【实验软硬件要求】计量经济学软件包EViews、微型计算机【实验内容】为研究深圳市地方预算内财政收入(Y)与地区生产总值(X)的关系,建立简单线性回归模型,现根据深圳市统计局网站的相关信息,得到统计数据如下表:请按照下列步骤完成实验一,每个步骤要写出操作过程:(1)打开EViews,新建适当的工作文件夹;打开Eviews后,依次点击File-New-Workfile,新建一个时间序列数据(Dated-regular frequencied)类型的文件,频率选择年度(Annual),键入起止日期1990-2008(如图一),点击ok,新建工作文件夹完成(如图二)(图一)(图二)(2)在工作文件夹中新建变量X和Y,并输入数据;依次点击Objects-New Object,对象类型选择序列(Series),并输入序列名Y(如图三),点击OK,重复以上操作,新建系列对象X。
新建系列对象完成后如(图四)按住ctrl并同时选定X和Y,用鼠标右击选择open—as group,点击Edit +/-开始编辑,输入数据,数据输入完毕再点击Edit+/-一次。
数据输入后如(图五)。
(图三)(图四)(图五)(3)生成X和Y的自然对数序列,保存在工作文件夹中,命名为lnX和lnY;依次点击Objects-Generate Sereies,出现Generate Series by Equation 窗口,在Enter equation窗口中输入公式:lnY=log(Y)点击ok,重复以上操作,输入:lnX=log(X) 创建序列lnX。
(如图六)(图六)(4)求X和Y的描述统计量的值,写出操作过程并画出相应表格;依次点击Quick-Group Statistics—Descriptive Statistics-Common sample,打开Series List窗口,输入x y,点击ok,输出结果(如图七)(图七)(5)作出X和Y的散点图,写出操作过程并画出相应图像,并判断模型是否接近于线性形式;依次点击Quick-Graph,打开Graph Options窗口,在Specific 中选择Scatter(散点图) (如图八)点击OK,得到散点图(如图九)(图八)由散点图可以看出模型接近线性形式(图九)(6) 用OLS 法对模型i i i u X Y ++=21ββ做参数估计,将估计结果保存在工作文件夹中,命名为eq01,写出操作过程和回归分析报告,并解释斜率的经济含义;在窗口空白处输入:ls y c x ,回车,得到结果如图回归分析报告:根据输出结果可得Ŷi = 26.02096 + 0.088820Xi (14.80278) (0.004356) t= (1.757843) (20.38986) R 2 = 0.960716 F=415.7464 D.W=0.626334 n=19 斜率的经济含义:斜率为0.088820,表示地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.088820亿元(7) 用OLS 法对模型i i i u X Y ++=ln ln 21ββ做参数估计,将估计结果保存在工作文件夹中,命名为eq02,写出操作过程和回归分析报告,并解释斜率 的经济含义;在主窗口空白处输入:ls lny c lnx ,回车,结果如图回归分析报告:根据输出结果可得lny = -1.272730 + 0.873867lnx(0.238775) (0.032394) t= (-5.330249) (26.9761) R 2 = 0.977172 F=727.7097 D.W= 0.811127 n=19 斜率的经济含义:斜率为0.873867,表示地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.0873867亿元(8) 将保存工作文件夹保存在桌面,文件名为test1.wfl ;依次点击File-Save As 将文件保存在桌面,命名为test1.wfl (9) 对eq01的估计结果做经济意义检验和统计检验(05.0=α),估计的效果如何?经济意义检验:x 的系数β2的估计值为0.088820,说明地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.088820亿元,该值处于(0,1)符合预期。
引言计量经济学建模方法:1)理论或假设的陈述;2)理论的数学模型的设定;3)理论的计量经济模型的设定;4)获取资料;5)计量经济模型的参数估计;6)假设检验;7)预报或预测;8)利用模型进行控制或制定政策。
第一章回归分析的性质1、回归分析:研究一个叫应变量的变量对另一个或多个叫做解释变量的变量的依赖关系,其用意在于通过后者的已知或设定值,去估计和预测前者的均值。
2、虚拟变数:定性变量或范畴变量。
3、时间序列数据:一个变量在不同时间取值的一组观测结果。
4、横截面数据:一个或多个变量在同一时间点上收集的数据。
5、实验资料:在保持一些因素不变的情况下收集数据。
、6、非实验资料:收集的资料不受研究者控制。
、7、回归分析的主要用意,是分析一个叫做应变量的变量,对另一个或多个叫做解释变量的变量的统计依赖性,这种分析的目的,是要在解释变量已知或固定值的基础上,估计和预测应变量的均值,实际上,回归分析的成功有赖于适用资料的获得。
、、第二章 双变量回归分析:一些基本概念1、总回归函数(PRF ):)()(i i X f X Y E =它仅仅表明在给定i X 下Y 分布的均值与i X 有函数关系,换句话说,他说出应变量的均值或平均值是怎样随解释变量变化的。
在几何意义上,总体回归曲线就是解释变量给定值时应变量的条件均值或期望值的轨迹。
、i i X X Y E 21)/(ββ+=:称为线性总体回归函数或简称线性总体回归。
2、PRF 的随机设定)/(i i i X Y E Y u -= 或 i i i u X Y E Y +=)/(i u 称为随机干扰项或随机误差。
是从模型中省略下来的而又集体地影响这应变量的全部变量的替代物。
)/(i X Y E 这一个成分被称为系统性或确定性成份;i u 为随机或非系统性成分。
若i i X X Y E 21)/(ββ+=ii i u X Y ++=21ββ3、随机干扰项的意义 1)理论的模糊性。
计量经济学实验简单线性回归模型引言计量经济学是经济学中的一个分支,致力于通过经验分析和实证方法来研究经济问题。
实验是计量经济学中的重要方法之一,能够帮助我们理解和解释经济现象。
简单线性回归模型是实验中常用的工具之一,它能够通过建立两个变量之间的数学关系,预测一个变量对另一个变量的影响。
本文将介绍计量经济学实验中的简单线性回归模型及其应用。
简单线性回归模型模型定义简单线性回归模型是一种用于描述自变量(X)与因变量(Y)之间关系的线性模型。
其数学表达式为:Y = β0 + β1X + ε其中,Y表示因变量,X表示自变量,β0和β1为未知参数,ε表示误差项。
参数估计在实际应用中,我们需要通过数据来估计模型中的参数。
最常用的估计方法是最小二乘法(OLS)。
最小二乘法的目标是通过最小化观测值与拟合值之间的平方差来估计参数。
具体而言,我们需要求解以下两个方程来得到参数的估计值:∂(Y - β0 - β1X)^2 / ∂β0 = 0∂(Y - β0 - β1X)^2 / ∂β1 = 0解释变量与被解释变量在简单线性回归模型中,解释变量(X)用来解释或预测被解释变量(Y)。
例如,我们可以使用房屋的面积(X)来预测房屋的价格(Y)。
在实验中,我们可以根据收集到的数据来建立回归模型,并利用该模型进行预测和分析。
应用实例数据收集为了说明简单线性回归模型的应用,我们假设收集了一些关于学生学习时间与考试成绩的数据。
下面是收集到的数据:学习时间(小时)考试成绩(百分制)2 723 784 805 856 88模型建立根据收集到的数据,我们可以建立简单线性回归模型来分析学生学习时间与考试成绩之间的关系。
首先,我们需要确定自变量和因变量的符号。
在这个例子中,我们可以将学习时间作为自变量(X),考试成绩作为因变量(Y)。
然后,我们使用最小二乘法来估计模型中的参数。
通过计算,可以得到如下参数估计值:β0 = 69.85β1 = 2.95最终的回归方程为:Y = 69.85 + 2.95X预测与分析通过建立的回归模型,我们可以进行预测和分析。
计量经济学教程计量经济学,是应用数理统计学,应用数学、经济学、计算机科学等领域中的方法,将既定的经济学理论与实证数据相结合,以解决归纳规律、经济现象和预测问题的一门学科。
计量经济学具有许多优点,比如它允许我们进行因果推断、预测趋势和测量经济政策的效果。
此外,计量经济学也允许我们处理复杂的数据集,提供客观、可靠的证据以支持决策,优化资源利用和提高效率。
要学好计量经济学,学习者需要掌握基本的数学和统计学知识,同时也需要学习如何处理数据并进行相关的计算和分析。
下面是我会介绍一些基本概念和方法。
1.简单回归模型简单回归模型是最简单的模型之一,它是通过一个自变量和一个因变量之间的关系来解释某种经济现象的。
比如,假设我们想要探究收入与消费之间的关系,那么收入就是自变量,消费就是因变量,我们可以通过简单回归模型进行建模。
简单回归模型中,自变量通常用X表示,因变量用Y表示,方程的形式可以写作:Y = β0 + β1 * X + ε其中,β0表示截距,β1表示自变量的系数,ε表示误差项。
我们通过拟合数据,找到最优的β0和β1,即可得到一个最佳的回归方程。
2.多元线性回归模型当我们需要考虑多个因素对某个经济现象的影响时,就需要用到多元线性回归模型。
多元线性回归模型是指将一个因变量解释为多个自变量的线性组合。
在多元线性回归模型中,模型的形式如下:Y = β0 + β1 * X1 + β2 * X2 + ... + βp * Xp + ε其中,X1、X2、...Xp是自变量,β0、β1、β2...βp是对应的系数,ε是误差项。
3.最小二乘法最小二乘法是求解回归系数的一种方法。
它的基本思想是通过最小化误差平方和来寻找最优的回归系数。
误差平方和可以用下式表示:SSE = ε1^2 + ε2^2 + ··· + εn^2最小二乘法是估计β0和β1系数的一种常用方法。
它使得误差平方和最小。
4.假设检验假设检验是在一定显著水平下,对总体平均值、方差等参数进行推断。