交通分布预测-重力模型
- 格式:pdf
- 大小:206.83 KB
- 文档页数:3

无约束重力模式根据无约束重力模型公式:γβαij jit UTkjiX ∙=),(两边取对数得Ln(Tij)=lnk+αlnGi+βlnAj-γlntijTij─交通区i到交通区j的出行分布量:Gi─交通区i的出行产生总量:Aj─交通区j的出行吸引总量:K,α,β,γ─模型参数;公式转换为:Y=K+αx1+βx2-γx3参数的确定是通过拟合现状OD调查资料,用最小二乘法确定。
现有一规划区域,共划分为5个交通区,经调查其现状OD分布见表1,各交通区间的出行时间见表2,通过对各交通区的交通生成进行预测,得到各交通区未来交通产生、吸引量见表3,分析计算得到未来各交通区间的交通出行时间见表4。
表A1(现状OD分布)表B2(各交通区间的出行时间)表C2(各交通区未来交通产生,吸引量)表D1(未来各交通区间的交通出行时间)解:选用出行时间的函数形式,将无约束重力模型变为:Ln(Tij)=lnk+αlnGi+βlnAj-γlntij格式LN(number):number是用于计算其自然对数的正实数。
Ln是exp函数的反函数计算步骤:打开数据文件,在定下的单元格中输入公式 Ln(number),按下number之后选择要计算的数字,然后按下Entre键后公式将返回计算结果如下表:Y=K+αx1+βx2-γx3此方程为线性回归方程,k, α,β,γ是用最小二乘法标定。
计算步骤:[c¹·c]¯¹c¹·y=β^c=(1 x):将C=( 1 x)转置的步骤是:按矩阵c选择行列数,在单元格中输入:=TRANSPOSE(B2:E26),然后按Cntrl+Shift+Enter组合键最后得出的结果是如下表(C¹):下一步的步骤是[C¹.c];依据C4×25·C25×4=C4×4 选择单元格区域的行列数,在单元格区域中输入为=MMULT(A28:Y31,B2:E26),然后然后按Cntrl+Shift+Enter组合键最后得出的结果是如下表[C¹.c]:下一步是算[C¹.c] ¯¹;先选择单元格区域的行列数,在单元格区域中输入:=MINVERSE(B34:E37)然后按Cntrl+Shift+Enter组合键。




9、简述交通分布的重力模型的基本原理及其计算过程:重力分布模型仿效牛顿万有引力定律,认为交通小区间的交通量与交通小区各自的交通发生量和吸引量成广义的正比关系,而与交通小区间的交通阻抗(距离、时间、费用)成广义的反比。
重力分布模型是一个非常有用的交通分布模型,它适用于运输网络出现较大变化时的未来交通出行分布预测。
但该模型应用时,需要标定模型的参数。
重力模型(gravity model)是一种最常用的方法,它根据牛顿的万有引力定律,即两物体间的引力与两物体的质量之积成正比,而与它们之间距离的平方成反比类推而成。
重力模型考虑了两交通小区间的吸引强度与吸引阻力,认为两交通小区之间的出行吸引与两交通小区的出行发生、吸引量成正比,与交通小区间的交通阻抗成反比。
重力模型直观上容易理解,预测考虑的因素比较全面,尤其是强调了局部与整体之间的相互作用,比较切合实际,即没有完整的O-D表,也能用O-D矩阵(只要能标定a)预测。
重力模型的一个致命缺点是短程O-D分布偏大,尤其是区内出行,在预测时必须给予注意。
下式为Casey(1955)提出的重力模型。
其中,:i,j小区的人口; d为i,j小区间的距离,α为系数。
上式的约束条件为:s.t.同时满足守恒条件的α是不存在的,因此,将重力模型修改如下:其中,为交通阻抗函数。
交通阻抗函数的几种形式:指数函数:(1)幂函数:(2)组合函数:(3)为参数。
单约束型B.P.R.模型其中,调整系数。
发生侧得到保证,即:以下以幂指数交通阻抗函数为例介绍其计算方法:第1步令m=0,m为计算次数。
第2步给出n(可以用最小二乘法求出)。
第3步令第4步求出第5步收敛判定。
若下式满足,则结束计算;反之,令m+1=m,返回第2步重复计算。
,作业:按上次作业给出的现状OD表和将来生成、发生与吸引交通量,利用下式重力模型和弗拉塔算法,求出将来OD表。
收敛标准。
重力模型:其中,,,。
读者也可以利用以前给出的现状分布交通量和表4-1示现状行驶时间,估计出这3个参数。

实验三:重力模型用于出行分布预测一、实验的输入与输出文件1、输入文件➢地理文件:小区地理文件(njZone.dbd)、线类型地理文件(njroad.dbd);➢矩阵文件:现状出行分布矩阵(BaseOD.mtx);2、输出文件➢地理文件:质心地理文件(Center.dbd);➢网络文件:道路网络();➢矩阵文件:小区质心间最短出行时间阻抗矩阵(SPMAT.mtx)、出行分布预测矩阵(CGRAV.MTX);➢数据表文件:重力模型参数标定输出数据表文件(Summary.bin);二、实验过程1、创建质心连杆和交通网络(1)创建质心地理文件在TransCAD中打开njZone.dbd小区地理文件,选择Tools/Export菜单项,弹出Export Zone Geography对话框。
在该对话框中,To后选择Standard Geographic File,ID Field后选择ZoneID,同时勾选Exports as Centroid points,点击OK进行确定,并将其保存为Center.dbd地理文件。
(2)质心连杆点击顶部工具栏按钮,弹出Layers对话框,点击Add layer按钮,分别打开njroad.dbd和Center.dbd地理文件,选中njroad point图层,点击Show Layer按钮,完成后点击Close按钮,关闭对话框。
将njroad point 置为当前层,选择Dataview/Modify Table菜单项,在弹出的对话框中为节点图层地理文件添加一个名为Index(Integer型)的属性字段。
将njZone置为当前层,选择Tools/Map Editing/Connect菜单项,弹出Connect对话框。
在该对话框中,选择Fill选项卡,在Node Field后的下拉列表框中选择Index,同时勾选IDs from Zone layer单选框,点击OK,完成小区质心与现有路网的连接。


需求预测方法及模型总结学院:交通运输工程学院专业:交通工程班级学号:071412127学生姓名:刘学鹏指导教师:秦丹丹完成时间:2015-11-26需求预测方法及模型总结交通需求预测是交通规划中的核心内容之一。
交通发展政策的制定、交通网络设计以及方案评价都与交通需求预测有密切的关系。
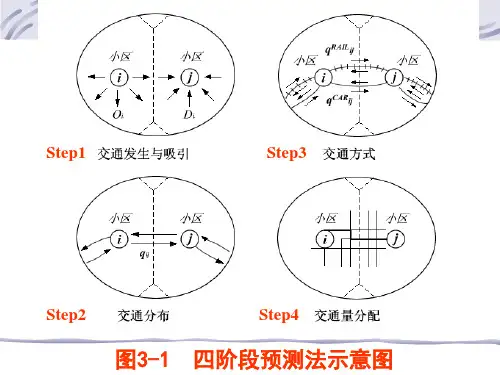
现代交通规划理论中的交通需求预测习惯上被分为四个阶段,即交通产生预测、交通分布预测、交通方式分担预测及交通网络分配。
下面就对交通需求预测的四阶段法以及其各自的模型进行总结。
一、交通生成预测Ⅰ、增长率法增长率法是根据预测对象(如客货运量、经济指标等)的预计增长速度进行预测的方法。
预测模型的一般形式为: Qt =Q(1+α)t增长率法的关键在于确定增长率,但增长率随着选择年限及计算方法的不同而存在较大的差异。
所以增长率法一般仅适用于增长率变化不大且增长趋势稳定的情况,其特点是计算简单,但预测结果粗略,较适用于近期预测。
Ⅱ、乘车系数法乘车系数法又称为原单位发生率法,类似于城市交通预测中的类别发生率法,它用区域总人口与平均每人年度乘车次数来预测客运量。
模型的形式为:Q t =Ptβ乘车系数可以根据指标的历年资料和今后变化趋势确定,但是乘车系数本身的变动有时难以预测,各种偶然因素会使其发生较大波动。
此外,人口、职业、年龄的变化也使系数很难符合一定规律。
Ⅲ、产值系数法产值系数法是根据预测期国民经济指标值(如工农业总产值、社会总产值、国民收入等)和确定的每单位指标值所引起的货运量或客运量进行预测的方法。
模型的形式为:Q t =MtβⅣ、弹性系数法弹性系数法是通过研究单位社会经济指标产生的小区交通出行量,预测将来吸引、发生量的一种方法。
此法是综合考虑我国经济发展水平和产业结构和发展趋势,参考O、D调查区域社会经济有关文献资料,确定弹性系数的大致范围,结合所得出的历史弹性系数及所处区域位置及相关运网历史交通量与直接影响区历史经济量的回归分析作为进一步的分析手段,确定出项目影响区的交通增长弹性系数,依此进行发生、吸引交通量预测。


论述交通量预测的增长率法和重力模型法0、引言所谓的交通量分布就是区与区之间的交通流,现状的区与区之间的交通分布已经从OD表中体现出来了。
交通量分布预算的目的就是根据现状OD分布量及各区因经济增长、土地开发等形成的交通量增长来推算各区之间将来的交通分布。
交通量预测主要有增长率法和重力模型法两种方法。
1、增长率法预测分布交通量增长率法是从已知的现有OD调查表和发生、吸引交通量的增长率求出OD 分布交通量的近似值,其次对、就、进行收敛计算,从而求得将来的分布交通量。
增长率法包括平均增长率法、底特律法和弗雷特法。
1.1平均增长率法1.1.1平均增长率法计算步骤①根据计算公式计算将来出行量式中:—区到区的将来出行量;—区到区的现在出行量;—区出行发生的增长系数;—区出行吸引的增长系数②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.1.2平均增长率法算例【例1】已知1、2、3区的出行、增长系数及现状分布,如表2.1-1所示,求将来的出行分布。
(取)表1.1-1 出行、增长系数及现状分布解:求间的交通量于是有,,,,,,,,得到第一轮计算结果,如表1.1-2所示。
表1.1-2 第一轮计算结果因第一轮计算结果中新的调整系数不能满足的要求,因此需要进行第二轮计算,直到满足要求为止。
本例共需要进行四轮计算,才可得到最终结果。
1.2底特律法此方法假定区到区间的交通量同和成比例增加。
1.2.1底特律法计算步骤①根据计算公式计算将来出行量式中:其中—未来发生量合计;—未来吸引量合计②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.3弗雷特法该方法假设,小区之间OD交通量的增长系数不仅与小区的发生增长系数和小区的吸引增长系数有关,还与整个规划区域的其他交通小区的增长系数有关。
应用重力模型进行交通分布的详细步骤第一步:求阻抗矩阵Rij(Impedance Matrix)交通阻抗可表示为:出行距离和行程时间的长短,以及出行费用的大小等。
为真实地反映交通阻抗,依托工程公交规划采用通常使用的平均行程时间表示。
小区之间的阻抗——平均行程时间越小表示小区之间阻抗越小,越大表示小区之间阻抗越大,因此以平均行程时间为路权值求各小区之间的最短路径(Shortest Path),其值即为小区之间的阻抗R ij。
1、数据准备(1)创建路网图1表示的是TransCAD创建路网的界面。
(2)做选择集。
在Endpoints层,于dataview中选择质心点,将其作为一个选择集。
(3)各路段平均行程时间(Travel time)其中,平均行程时间=Length/平均车速2、操作过程Networks/Paths—Multiple paths调出其对话框如图2所示。
3、运行结果(即为阻抗矩阵),如图3所示。
第二步:重力模型标定(校准)(Gravity Mode Calibration)1、数据准备(1)公交基础OD矩阵。
(2)阻抗矩阵(Shortest Paths),如图3所示。
重力模型标定(校准)(Gravity Mode Calibration)数据准备:基年OD矩阵的索引(质心层质心ID)与最短路径矩阵的索引(路网节点层质心ID)不匹配,并且因为下面将在路网节点层上操作,因此必须使基年OD 索引与最短路径矩阵的索引相一致,以使两表数据相对应(转换为“质心ID”)。
操作方法:按其对话框4示意操作。
2、操作过程按对话框(如图5)操作即可。
3、运行结果(1)标定参数结果:a=2.6288,b=0.2361,c=0.0,如图6所示,不过大看show report 里面参数更准确。
(2)K-Factor Flow:如图7所示。
第三步:创建综合阻抗因子f (Rij) (Synthetic Friction Factors)1、数据准备(1)创建空矩阵“Friction Factor shell”;(2)已标定的a、b、c值;(3)阻抗(最短路径)矩阵。
试叙述重力模型的基本形式及其分类
重力模型:又称引力模型,应用两区间出行数与出发区的出行发生量和到达区的出次吸引量各成正比,与两区间的行程时间、费用或距离等成反比的关系建立的未来交通分布预测模型,因其与牛顿的万有引力定律相似而得名。
优点:直观上容易理解;能考虑路网的变化和土地利用对人们的出行产生的影响;特定交通小区之间的OD交通量为零时也能预测;能比较敏感地反映交通小区之间行驶时间变化的情况。
缺点:仅仅是将物理法则简单直观上容易理解;需要更加贴合人们出行的方法;一般人们的出行距离分布在全区域并非为定值,而重力模型将其视为定值;交通小区之间的行驶时间因交通方式和时间段的不同而异,而重力模型使用了同一时间;求内交通量时的行驶时间难以给出;交通小区之间的距离较小时,有夸大预测的可能性;利用重力模型计算出的分布交通量必须借助于其它方法进行收敛计算。
阻抗函数
无约束重力模型的标定
常见的阻抗函数有以下几种:
解:根据重力模型计算小区1-1的出行分布量为:
同理,可计算其余出行分布量,列表如下:
双约束重力模型的标定
双约束重力模型中的Ai与Bj是在计算过程中产生的,
不是固定的参数,因而对于双约束重力模型只有阻抗
函数中的参数需要标定。
在取指数型阻抗函数时,需
要标定的就是参数β。
如果参数β的取值能使得由重力模型计算结果中得到
的出行长度分布,与实际调查得到的出行长度分布最
大程度地吻合,则该值就作为模型参数标定的最优值。
因此重力模型的标定问题就转化为一个方程求根的问
题。
可以用牛顿法、差商法等数值方法求解。