应用重力模型进行交通分布的详细步骤
- 格式:doc
- 大小:1.86 MB
- 文档页数:8




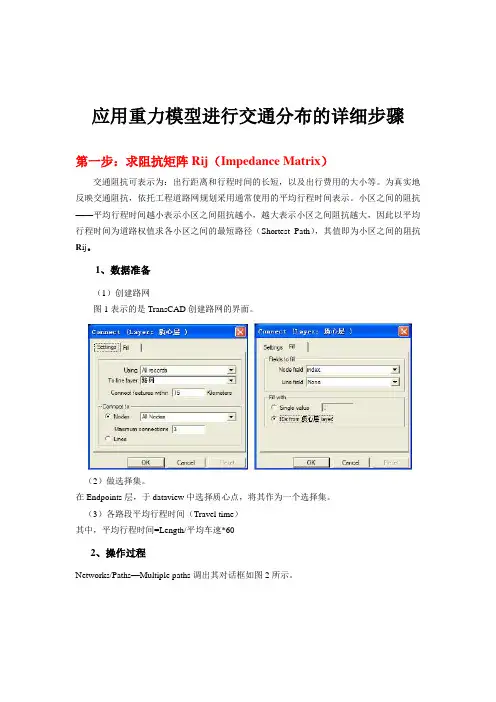
应用重力模型进行交通分布的详细步骤第一步:求阻抗矩阵Rij(Impedance Matrix)交通阻抗可表示为:出行距离和行程时间的长短,以及出行费用的大小等。
为真实地反映交通阻抗,依托工程道路网规划采用通常使用的平均行程时间表示。
小区之间的阻抗——平均行程时间越小表示小区之间阻抗越小,越大表示小区之间阻抗越大,因此以平均行程时间为道路权值求各小区之间的最短路径(Shortest Path),其值即为小区之间的阻抗R ij。
1、数据准备(1)创建路网图1表示的是TransCAD创建路网的界面。
(2)做选择集。
在Endpoints层,于dataview中选择质心点,将其作为一个选择集。
(3)各路段平均行程时间(Travel time)其中,平均行程时间=Length/平均车速*602、操作过程Networks/Paths—Multiple paths调出其对话框如图2所示。
3、运行结果(即为阻抗矩阵),如图3所示。
第二步:重力模型标定(校准)(Gravity Mode Calibration)1、数据准备(1)基础OD矩阵。
(2)阻抗矩阵(Shortest Paths),如图3所示。
重力模型标定(校准)(Gravity Mode Calibration)数据准备:基年OD矩阵的索引(质心层质心ID)与最短路径矩阵的索引(路网节点层质心ID)不匹配,并且因为下面将在路网节点层上操作,因此必须使基年OD索引与最短路径矩阵的索引相一致,以使两表数据相对应(转换为“质心ID”)。
操作方法:按其对话框4示意操作。
2、操作过程按对话框(如图5)操作即可。
3、运行结果(1)标定参数结果(这里选用伽马函数):a=2.6288,b=0.2361,c=0.0,如图6所示,不过大看show report 里面参数更准确。
(2)K-Factor Flow:如图7所示。
第三步:创建综合阻抗因子f (Rij) (Synthetic Friction Factors)1、数据准备(1)创建空矩阵“Friction Factor shell”;(2)已标定的a、b、c值;(3)阻抗(最短路径)矩阵,如图8所示。
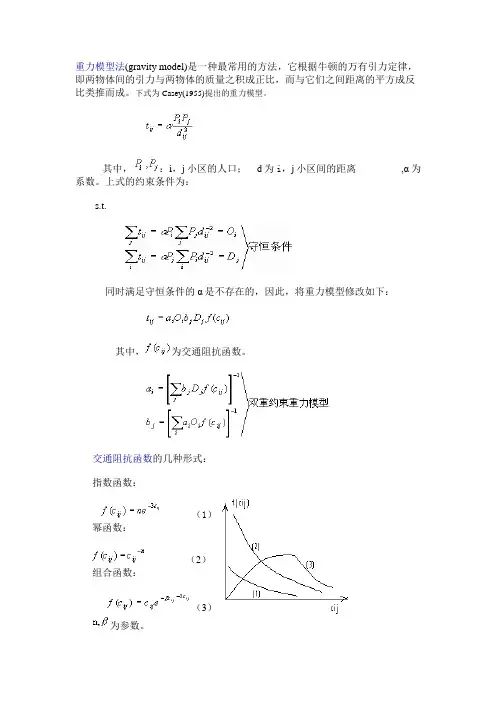
重力模型法(gravity model)是一种最常用的方法,它根据牛顿的万有引力定律,即两物体间的引力与两物体的质量之积成正比,而与它们之间距离的平方成反比类推而成。
下式为Casey(1955)提出的重力模型。
其中,:i,j小区的人口; d为i,j小区间的距离,α为系数。
上式的约束条件为:s.t.同时满足守恒条件的α是不存在的,因此,将重力模型修改如下:其中,为交通阻抗函数。
交通阻抗函数的几种形式:指数函数:(1)幂函数:(2)组合函数:(3)为参数。
单约束型B.P.R.模型其中,调整系数。
发生侧得到保证,即:以下以幂指数交通阻抗函数为例介绍其计算方法:第1步令m=0,m为计算次数。
第2步给出n(可以用最小二乘法求出)。
第3步令第4步求出第5步收敛判定。
若下式满足,则结束计算;反之,令m+1=m,返回第2步重复计算。
,作业:按上次作业给出的现状OD表和将来生成、发生与吸引交通量,利用下式重力模型和弗拉塔算法,求出将来OD表。
收敛标准。
重力模型:其中,,,。
读者也可以利用以前给出的现状分布交通量和表4-1示现状行驶时间,估计出这3个参数。
表4-1 现状行驶时间表4-2将来行驶时间解:利用重力模型求解分布交通量如下:同理,可以计算出其它各交通小区之间的交通量如下表所示。
重力模型的优点:a.直观上容易理解;b.能考虑路网的变化和土地利用对人们的出行产生的影响;c.特定交通小区之间的OD交通量为零时,也能预测;d.能比较敏感地反映交通小区之间行驶时间变化的情况。
重力模型的缺点:a.重力模型仅仅是将物理法则简单直观上容易理解;b.能考虑路网的变化和土地利用对地应用到社会现象,尽管有类似性,需要更加贴合人们出行的方法;c.一般,人们的出行距离分布在全区域并非为定值,而重力模型将其视为定值;d.交通小区之间的行驶时间因交通方式和时间段的不同而异,而重力模型使用了同一时间;e.求内内交通量时的行驶时间难以给出;f.交通小区之间的距离小时,有夸大预测的可能性;g.利用重力模型计算出的分布交通量必须借助于其它方法进行收敛计算。

t r s c交通规划实例详细步骤内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)T r a n s C A D 交通规划实例作者:applepin启动TransCAD软件插入软件狗,启动TransCAD软件。
建立路段层点击新建文件图标,出现点击建立地理文件,点击OK,出现选择文更改名更改名选中Line 层地理文件类型,并更改名字,点击OK,出现路段层属性对话框:点击Add Field,逐一增加字段属性点击OK,出现保存对话框:选择保存路径及文件名称点击Save,出现路段层地图界面添加路段在路段层上,点击Tools→map editing→toolbox出现地图编辑工具栏:点击,逐一增加路段应用保存得到7条线路、5个节点的路网。
输入路段属性数据打开路段层数据库:逐一输入路段属性数据(通行时间等于路段长度除以速度)建立小区层点击新建文件图标,出现点击建立地理文件,点击OK,出现点击OK,出现小区层属性对话框逐一添加小区的字段属性点击OK,出现保存对话框:起好名字,点击Save。
再次回到路段层地图界面。
画小区。
点击Tools→map editing→toolbox出现工具栏:画出3个小区,并保存。
输入小区属性数据打开小区层数据库输入各小区的属性数据将小区质心点连接到路网(目的是做ID转换)。
在节点层上,增加Index。
原先节点层上只有经纬度两个字段两个字段点击数据库菜单,修改数据库属性增加一个新字段Index在小区层上,点击Tools→Map Editing →Connect 调出对话框:点击Fill,完成如下设置:点出OK,路网显示出已经连接,出现小区质心节点打开点层数据库,发现新的变化:打开路段层数据库,发现新的变化:增加的三个节点的小区质心节增加了6,7,8三个填充连接后新增路段的填充连接后新增路段(质心连杆)的值。
将其通行能力设为无穷大(大数即可)的值,通行时间设为很小的值。
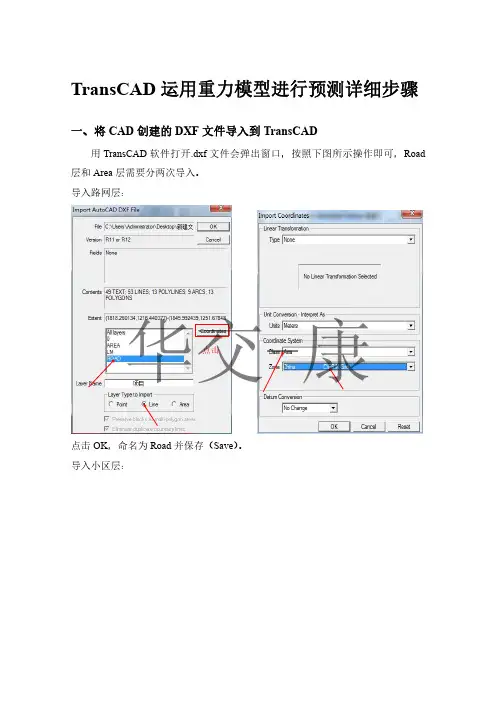
TransCAD 运用重力模型进行预测详细步骤一、将CAD 创建的DXF 文件导入到TransCAD用TransCAD 软件打开.dxf 文件会弹出窗口,按照下图所示操作即可,Road 层和Area 层需要分两次导入。
导入路网层:点击OK ,命名为Road 并保存(Save )。
导入小区层:点击点击OK ,命名为Area 并保存(Save )。
Road 层和Area 层叠加:右键选择Layers 重命名图层:点击点击检查路段连接性:tools-map editing-check line layerconnectivity无问题,则显示为黑色点儿,继续下一步;有问题则显示为其他颜色点儿,需要进行调整。
二、分别给Road 层和Area 层建立相应字段并填充数据切换到Road 层,点击Dataview ,选择Modify Table ,弹出如下窗口,建立luming 、danxiangchedaoshu 、daoludengji 、danchedaonengli 、AB-T 、BA-T 、AB-V 、BA-V 、AB-C 、BA-C 和reallength字段。
切换到Endpoints 层,点击Dataview ,选择Modify Table ,弹出如下窗口,建立xiaoqu字段。
点击填充Road层数据表:其中luming 、danxiangchedaoshu 、daoludengji 根据调查结果进行填充,本例快速路AB-V 和BA-V 取60km/h ,主干路AB-V 和BA-V 取40km/h ,次干路AB-V 和BA-V 取30km/h ,支路AB-V 和BA-V 取20km/h ,不同等级道路单车道通行能力视隔离情况(机非隔离、中央隔离)进行取值,本例中快速路取值1100pcu/h ;主干路无隔离,则取950pcu/h ,有一种隔离措施,则取1000pcu/h ,有两种隔离措施,则取1050pcu/h ;次干路则依次取值为800pcu/h 、850pcu/h 、900pcu/h ;支路无机非隔离带则取450pcu/h ,有机非隔离带则取650pcu/h 。

论述交通量预测的增长率法和重力模型法0、引言所谓的交通量分布就是区与区之间的交通流,现状的区与区之间的交通分布已经从OD表中体现出来了。
交通量分布预算的目的就是根据现状OD分布量及各区因经济增长、土地开发等形成的交通量增长来推算各区之间将来的交通分布。
交通量预测主要有增长率法和重力模型法两种方法。
1、增长率法预测分布交通量增长率法是从已知的现有OD调查表和发生、吸引交通量的增长率求出OD 分布交通量的近似值,其次对、就、进行收敛计算,从而求得将来的分布交通量。
增长率法包括平均增长率法、底特律法和弗雷特法。
1.1平均增长率法1.1.1平均增长率法计算步骤①根据计算公式计算将来出行量式中:—区到区的将来出行量;—区到区的现在出行量;—区出行发生的增长系数;—区出行吸引的增长系数②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.1.2平均增长率法算例【例1】已知1、2、3区的出行、增长系数及现状分布,如表2.1-1所示,求将来的出行分布。
(取)表1.1-1 出行、增长系数及现状分布解:求间的交通量于是有,,,,,,,,得到第一轮计算结果,如表1.1-2所示。
表1.1-2 第一轮计算结果因第一轮计算结果中新的调整系数不能满足的要求,因此需要进行第二轮计算,直到满足要求为止。
本例共需要进行四轮计算,才可得到最终结果。
1.2底特律法此方法假定区到区间的交通量同和成比例增加。
1.2.1底特律法计算步骤①根据计算公式计算将来出行量式中:其中—未来发生量合计;—未来吸引量合计②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.3弗雷特法该方法假设,小区之间OD交通量的增长系数不仅与小区的发生增长系数和小区的吸引增长系数有关,还与整个规划区域的其他交通小区的增长系数有关。


重力模型的过程和原理教案重力模型是一种经济地理学中常用的分析工具,用于研究地理空间内不同地区之间的贸易、人口流动、投资等现象。
它通过考虑地理距离和经济规模大小两个因素,揭示了地理空间的相互作用对区域之间的联系和互动产生的影响。
一、重力模型的基本原理重力模型的基本原理是基于物理学中的引力定律,即两个物体之间的引力与它们的质量成正比,与它们之间的距离成反比。
将这个物理定律应用到经济地理学中,我们可以认为两个地区之间的联系程度与它们的经济规模大小成正比,与它们之间的地理距离成反比。
重力模型的基本公式可以表示为:T = k * (M1 * M2) / D^a,其中T表示两个地区之间的贸易、人口流动或投资的强度,k是一个常数,M1和M2分别表示两个地区的经济规模,D表示两个地区之间的地理距离,a是一个指数,用于衡量地理距离对联系程度的影响。
二、重力模型的应用过程1. 数据收集:首先需要收集关于地区经济规模、地理距离以及贸易、人口流动或投资强度的数据。
这些数据可以来自于统计局、商业机构、调查问卷等渠道。
2. 变量定义:根据研究的具体对象和目的,将收集到的数据转化为模型中的变量。
一般来说,经济规模可以用GDP、人口数量或其他相关指标表示,地理距离可以用实际距离或交通时间等方式衡量,贸易、人口流动或投资强度可以用贸易额、人口流动量或投资金额等指标表示。
3. 模型估计:根据收集到的数据和变量定义,利用计量经济学中的方法对重力模型进行估计。
传统的估计方法包括普通最小二乘法(OLS)、仪器变量法(IV)等。
4. 参数解释和检验:根据估计结果,解释模型中的参数。
一般来说,经济规模的系数表示经济规模对联系程度的影响,指数a的值表示地理距离对联系程度的影响。
为了确保参数的统计显著性,还需要进行假设检验。
5. 模型拟合度检验:为了评估模型的拟合程度和预测能力,一般需要计算模型的拟合度指标,比如决定系数(R-squared)等。
客流重力模型
客流重力模型是一种用来分析城市交通网络中客流分布的模型。
它基
于物理学中的万有引力定律和牛顿引力定律,将客流视为物理学中的
质点,通过考虑各节点之间的距离和吸引力,推断出客流的分布情况。
在客流重力模型中,节点之间的距离越近,吸引力就越大,客流就越高。
而同一个节点内的客流之间并没有特定的关系,每个客流都被视
为一个独立的质点,受到其他节点的吸引力所影响。
这种模型的重点
在于分析节点之间距离和吸引力的关系,从而推断出客流的分布情况。
在实际应用中,客流重力模型主要应用于城市交通规划和管理中。
根
据客流重力模型的分析结果,可以确定一些关键节点的客流分布情况,从而可以制定更科学和合理的交通规划策略。
例如,在规划城市公共
交通线路时,可以根据客流重力模型的分析结果,选择建设在客流最
集中的节点附近,以提高线路的运营效率。
除此之外,客流重力模型还可以用来分析不同节点之间的交通流动情况、分析城市发展趋势、评估城市的发展水平等。
通过分析客流分布
情况,可以更准确地把握城市的潜力和发展方向,为城市的长远发展
提供有力的支撑。
综上所述,客流重力模型是一种非常实用的工具,它可以帮助我们更好地了解城市的客流分布情况,规划和管理城市的交通网络。
未来随着城市的发展和人口的增长,客流重力模型的应用也将越来越广泛。
应用重力模型进行交通分布的详细步骤
第一步:求阻抗矩阵Rij(Impedance Matrix)
交通阻抗可表示为:出行距离和行程时间的长短,以及出行费用的大小等。
为真实地反映交通阻抗,依托工程公交规划采用通常使用的平均行程时间表示。
小区之间的阻抗——平均行程时间越小表示小区之间阻抗越小,越大表示小区之间阻抗越大,因此以平均行程时间为路权值求各小区之间的最短路径(Shortest Path),其值即为小区之间的阻抗R ij。
1、数据准备
(1)创建路网
图1表示的是TransCAD创建路网的界面。
(2)做选择集。
在Endpoints层,于dataview中选择质心点,将其作为一个选择集。
(3)各路段平均行程时间(Travel time)
其中,平均行程时间=Length/平均车速
2、操作过程
Networks/Paths—Multiple paths调出其对话框如图2所示。
3、运行结果(即为阻抗矩阵),如图3所示。
第二步:重力模型标定(校准)(Gravity Mode Calibration)1、数据准备
(1)公交基础OD矩阵。
(2)阻抗矩阵(Shortest Paths),如图3所示。
重力模型标定(校准)(Gravity Mode Calibration)数据准备:
基年OD矩阵的索引(质心层质心ID)与最短路径矩阵的索引(路网节点层质心ID)不匹配,并且因为下面将在路网节点层上操作,因此必须使基年OD 索引与最短路径矩阵的索引相一致,以使两表数据相对应(转换为“质心ID”)。
操作方法:按其对话框4示意操作。
2、操作过程
按对话框(如图5)操作即可。
3、运行结果
(1)标定参数结果:a=2.6288,b=0.2361,c=0.0,如图6所示,不过大看show report 里面参数更准确。
(2)K-Factor Flow:如图7所示。
第三步:创建综合阻抗因子f (Rij) (Synthetic Friction Factors)
1、数据准备
(1)创建空矩阵“Friction Factor shell”;
(2)已标定的a、b、c值;
(3)阻抗(最短路径)矩阵。
如图8所示。
2、操作过程
详见图9对话框所示。
3、运行结果
如图10所示。
第四步:应用重力模型(得2010年公交OD分布矩阵)1、数据准备
(1)已标定的a,b,c值;
(2)综合阻抗因子矩阵;
(3)阻抗(最短路径)矩阵。
(4)K-Factor矩阵
因为采用重力模型分布时要用到规划年交通出行量,所以必须在小区层上操作,因此综合阻抗因子矩阵、阻抗(最短路径)矩阵、K-Factor矩阵索引值必须与2010PCU_P、2010PCU_A的ID相匹配。
即要将这三个矩阵的ID转换回
来。
ID转换后的数据见图11。
2、操作过程
详见图12所示。
3、运行结果
规划年(2010年)公交OD矩阵(ID转换为实际小区号),详见图13。
操作结束,希望对大家有用!
我的QQ号是250234329.欢迎一起交流。