Python-爬虫零基础入门-爬取那些你喜欢的小说
- 格式:pptx
- 大小:537.07 KB
- 文档页数:13

关于python爬虫的书籍摘要:一、Python 爬虫概述1.什么是Python 爬虫2.Python 爬虫的基本原理二、Python 爬虫的基础知识1.HTTP 协议2.HTML, CSS, JavaScript3.爬虫框架4.数据库5.数据处理三、Python 爬虫的书籍推荐1.《Python 爬虫基础教程》2.《Python 网络爬虫技术宝典》3.《Python 爬虫实战》4.《Web 数据挖掘与分析》四、总结正文:一、Python 爬虫概述Python 爬虫是一种基于Python 编程语言的网络数据抓取技术。
通过编写Python 代码,可以实现自动化地从互联网上抓取所需的数据,从而方便地进行数据分析和利用。
Python 爬虫的基本原理是通过模拟浏览器访问网站的过程,获取网站的HTML 源代码,然后解析HTML 代码,提取所需的数据。
二、Python 爬虫的基础知识1.HTTP 协议:HTTP(Hypertext Transfer Protocol)协议是互联网上数据传输的基础协议。
了解HTTP 协议,有助于理解爬虫如何向服务器发送请求并获取数据。
2.HTML、CSS、JavaScript:这些知识对于理解网页的结构和内容呈现方式非常重要。
在爬虫中,需要利用这些知识来解析网页源代码,以便提取有效数据。
3.爬虫框架:Python 中有许多成熟的爬虫框架,如Scrapy、BeautifulSoup 等。
学习这些框架可以大大提高爬虫开发的效率。
4.数据库:了解数据库的基本知识,如SQL 语句、数据库的增删改查操作等,有助于存储和整理爬取到的数据。
5.数据处理:掌握Python 中的数据处理技术,如Pandas、NumPy 等,可以对获取的数据进行有效的清洗、整理和分析。
三、Python 爬虫的书籍推荐1.《Python 爬虫基础教程》:本书从基本概念入手,逐步介绍了Python 爬虫的原理、技术和应用,适合初学者。

python爬⾍之爬取笔趣阁⼩说⽬录前⾔⼀、⾸先导⼊相关的模块⼆、向⽹站发送请求并获取⽹站数据三、拿到页⾯数据之后对数据进⾏提取四、获取到⼩说详情页链接之后进⾏详情页⼆次访问并获取⽂章数据五、对⼩说详情页进⾏静态页⾯分析六、数据下载前⾔为了上班摸鱼⽅便,今天⾃⼰写了个爬取笔趣阁⼩说的程序。
好吧,其实就是找个⽬的学习python,分享⼀下。
⼀、⾸先导⼊相关的模块import osimport requestsfrom bs4 import BeautifulSoup⼆、向⽹站发送请求并获取⽹站数据⽹站链接最后的⼀位数字为⼀本书的id值,⼀个数字对应⼀本⼩说,我们以id为1的⼩说为⽰例。
进⼊到⽹站之后,我们发现有⼀个章节列表,那么我们⾸先完成对⼩说列表名称的抓取# 声明请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}# 创建保存⼩说⽂本的⽂件夹if not os.path.exists('./⼩说'):os.mkdir('./⼩说/')# 访问⽹站并获取页⾯数据response = requests.get('/book/1/').textprint(response)写到这个地⽅同学们可能会发现了⼀个问题,当我去正常访问⽹站的时候为什么返回回来的数据是乱码呢?这是因为页⾯html的编码格式与我们python访问并拿到数据的解码格式不⼀致导致的,python默认的解码⽅式为utf-8,但是页⾯编码可能是GBK或者是GB2312等,所以我们需要让python代码很具页⾯的解码⽅式⾃动变化#### 重新编写访问代码```pythonresponse = requests.get('/book/1/')response.encoding = response.apparent_encodingprint(response.text)'''这种⽅式返回的中⽂数据才是正确的'''三、拿到页⾯数据之后对数据进⾏提取当⼤家通过正确的解码⽅式拿到页⾯数据之后,接下来需要完成静态页⾯分析了。
![[Python爬虫]起点中文网小说排行榜](https://uimg.taocdn.com/5b0e72aef021dd36a32d7375a417866fb84ac06d.webp)

python爬虫入门到精通必备的书籍python是一种常见的网络爬虫语言,学习python爬虫,需要理论与实践相结合,Python生态中的爬虫库多如牛毛,urllib、urllib2、requests、beautifulsoup、scrapy、pyspider都是爬虫相关的库,但是如果没有理论知识,纯粹地学习如何使用这些API如何调用是不会有提升的。
所以,在学习这些库的同时,需要去系统的学习爬虫的相关原理。
你需要懂的技术包括Python编程语言、HTTP协议、数据库、Linux等知识。
这样才能做到真正从入门python爬虫到精通,下面推荐几本经典的书籍。
1、Python语言入门的书籍:适合没有编程基础的,入门Python的书籍1、《简明Python教程》本书采用知识共享协议免费分发,意味着任何人都可以免费获取,这本书走过了11个年头,最新版以Python3为基础同时也会兼顾到Python2的一些东西,内容非常精简。
2、《父与子的编程之旅》一本正儿八经Python编程入门书,以寓教于乐的形式阐述编程,显得更轻松愉快一些。
3、《笨办法学Python》这并不是关于亲子关系的编程书,而是一本正儿八经Python编程入门书,只是以这种寓教于乐的形式阐述编程,显得更轻松愉快一些。
4、《深入浅出Python》Head First 系列的书籍一直饱受赞誉,这本也不例外。
Head First Python主要讲述了Python 3的基础语法知识以及如何使用Python快速地进行Web、手机上的开发。
5、《像计算机科学家一样思考python》内容讲解清楚明白,非常适合python入门用,但对于学习过其他编程语言的读者来说可能会觉得进度比较慢,但作者的思路和想法确实给人很多启发,对于菜鸟来说收益匪浅,书中很多例子还是有一定难度的,完全吃透也不容易。
6、《Python编程:入门到实践》厚厚的一本书,本书的内容基础而且全面,适合纯小白看。

Python3爬⾍爬取中国图书⽹(淘书团)记录本⼈为⼀名刚开始学Python爬⾍的⼩⽩,开贴仅为记录下⾃⼰的学习历程,⽅便做review要爬取内容:图书名称,图书价格,以及对应预览图的link本⽂⽤到py packages: requests, BeautifulSoup, json, cvs打开中国图书⽹团购页⾯时,发现⽹站的信息是动态加载的:Anyways,先不考虑加载更多页的图书信息,我们从尝试着抓取第⼀页的图书信息开始:本次爬⾍所⽤的浏览器为chrome所以我们打开浏览器的开发者模式F12,可以看到页⾯加载的相应信息为了实现模拟浏览器登录功能,我们需要查看header的信息:完成对应的代码:header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36','Host': '','Referer': '/','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9'}接下来我们需要做的就是分析整个中国图书⽹的DOM,去查看我们需要的信息,都封装在哪些tags⾥⾯经过地毯式搜索。
我们发现我们所需要的信息,都封装在 <ul id='taoList".....>的⼦节点li⾥⾯所以,我们打算采取BeautifulSoup的解析抓取功能,来实现拿到li内的我们需要的信息对应的代码:url = '/'response = requests.get(url, headers = header) #模仿浏览器登录response.encoding = 'utf-8'soup = BeautifulSoup(response.text,'html.parser')for item in soup.select('div .taoListInner ul li'):print(item.select('h2')[0].text) #返回对象为数组print(item.select('.salePrice')[0].text)print(item.select('img')[0].get('src')) #get⽅法⽤来取得tab内部的属性值⾸先我们需要调⽤requests的get⽅法,拿到响应的response,然后通过BS进⾏解析,我们会发现,在class 名为 taoListInner的div标签中,封装了我们想要的ul下的li查看了beautifulsoup的⽂档,对⽐了find_all 和select,决定调⽤select⽅法拿到对应的标签,然后拿到对应h2标签下的书名; salePrice class下的价格;以及img标签内src的预览图link。
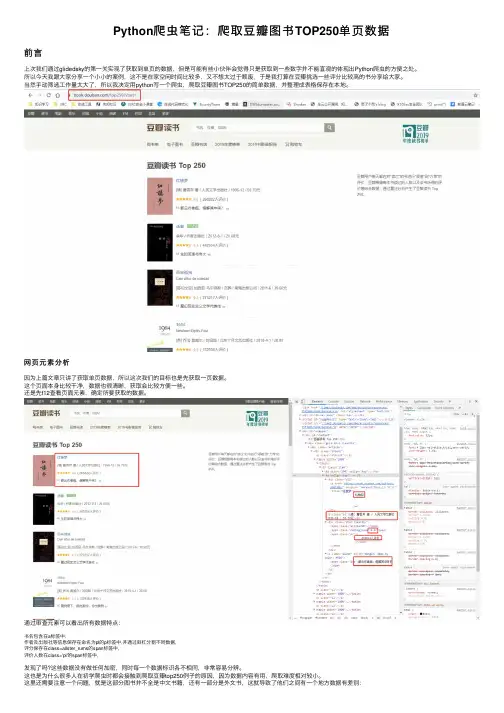
Python爬⾍笔记:爬取⾖瓣图书TOP250单页数据前⾔上次我们通过glidedsky的第⼀关实现了获取到单页的数据,但是可能有些⼩伙伴会觉得只是获取到⼀些数字并不能直观的体现出Python爬⾍的⽅便之处。
所以今天我跟⼤家分享⼀个⼩⼩的案例,这不是在家空闲时间⽐较多,⼜不想太过于颓废,于是我打算在⾖瓣挑选⼀些评分⽐较⾼的书分享给⼤家。
当然⼿动筛选⼯作量太⼤了,所以我决定⽤python写⼀个爬⾍,爬取⾖瓣图书TOP250的简单数据,并整理成表格保存在本地。
⽹页元素分析因为上篇⽂章只讲了获取单页数据,所以这次我们的⽬标也是先获取⼀页数据。
这个页⾯本⾝⽐较⼲净,数据也很清晰,获取会⽐较⽅便⼀些。
还是先f12查看页⾯元素,确定所要获取的数据。
通过审查元素可以看出所有数据特点:书名包含在a标签中,作者及出版社等信息保存在命名为pl的p标签中,并通过斜杠分割不同数据,评分保存在class=allster_rums的span标签中,评价⼈数在class='pl'的span标签中,发现了吗?这些数据没有做任何加密,同时每⼀个数据标识各不相同,⾮常容易分辨。
这也是为什么很多⼈在初学爬⾍时都会接触到爬取⾖瓣top250例⼦的原因,因为数据内容有⽤,爬取难度相对较⼩。
这⾥还需要注意⼀个问题,就是这部分图书并不全是中⽂书籍,还有⼀部分是外⽂书,这就导致了他们之间有⼀个地⽅数据有差别:外⽂书会多出⼀个译者名字,所以之后在保存数据到表格⽂件中时,需要特别注意。
代码实现在开始之前还是先明确⼀下程序执⾏流程:访问⽹页获取源代码提取数据分别保存到excel⽂件中⾸先解决访问⽹页和获取源代码的问题:import requestsfrom bs4 import BeautifulSoupurl = '/top250?start='headers = {'cookie':'你⾃⼰的cookie','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' }response = requests.get(url,headers=headers).textbs4 = BeautifulSoup(response,'html.parser')print(bs4)获取到之后当然就是对数据进⾏提取bookName = bs4.find_all('div',class_='pl2')for book in bookName:name = book.find('a')name = name.text.strip()name = name.replace(' ','')print(name)这段代码⾸先在获取到的html⽂本中寻找Class=pl2的div元素这是没有提取a标签中书名时的原始数据find_all()是BeautifulSoup模块提供的⼀个⽤来快速查询数据的⽅法,返回⼀个列表。

初次尝试python爬⾍,爬取⼩说⽹站的⼩说。
本次是⼩阿鹏,第⼀次通过python爬⾍去爬⼀个⼩说⽹站的⼩说。
下⾯直接上菜。
1.⾸先我需要导⼊相应的包,这⾥我采⽤了第三⽅模块的架包,requests。
requests是python实现的简单易⽤的HTTP 库,使⽤起来⽐urllib简洁很多,因为是第三⽅库,所以使⽤前需要cmd安装。
cmd安装⽅式,打开cmd,输⼊以下命令: pip install requests 3.我们现在有了⼩说的链接,这时候就要模拟浏览器发送http的请求: response=requests.get(url)response.encoding='gbk' 4.我们可以尝试获取⽬标⼩说的⽹页源码 html=response.text 我们把它打印出来看下: 有html基础的朋友应该对这些很熟悉。
通过打印我们可以看见⼩说的名字,作者,以及⼩说章节的url。
这时候我们就先通过HTML⽹页源码获取⼩说的名字:title=re.findall(r'<meta property="og:novel:book_name" content="(.*?)"/>',html)[0] 从上⾯的代码我们可以看见是通过正则表达式去匹配的,对正则表达式有疑问的同学可以⾃⾏百度下。
当然不同⽹站的具体⼩说名字可能会放在不同的标签⾥,需要我们打开⽹页源码去看看下。
5.这时候我们也就新建⼀个⽂本⽂件来保存⼩说内容。
fb=open('%s.txt'% title,'w',encoding='utf-8') 这时候我们需要获取⼩说的章节⽬录对应的url,我们还是来观察下⽹页的源码。
我们通过⽕狐浏览器的f12看下⽹页可发现: ⼩说的章节⽬标都在标签<div id='list'>⾥我们通过下⾯的代码获取对应的章节名和url。

python:根据⼩说名称爬取电⼦书简介上⼀章节⼩编⽤python爬取了“⽃罗⼤陆”单本⼩说,经过周末马不停蹄、加班加点、抓⽿挠腮的搬砖。
终于在今天,经过优化处理后,⼀款基于python爬⾍来爬取千千⼩说⽹站的程序出来了,主要功能有以下⼏点:根据需要,输⼊想要查看的页数,查询页数内的所有⼩说。
展⽰⼩说ID序号及⼩说名称。
输⼊⼩说ID,进⾏对应的下载。
下载完毕后,进⾏持久化存储到⽂件夹。
下⾯,开始展⽰成果吧,哈哈哈哈:页数查询结果显⽰下载书籍输⼊ID及进度展⽰⽂件夹储存展⽰第⼀步,导包import osfrom lxml import etreefrom pathlib import Pathfrom requests import Session具体使⽤可以参考上⼀章《python:爬取“⽃罗⼤陆”电⼦书》哦~第⼆步,判断存储⽂件夹def is_exists(book_name):"""判断存储路径是否存在,不存在就新建:param book_name: 书籍名称:return:"""base_dir = Path(__file__).parent.joinpath("BOOK")if not os.path.exists(base_dir):os.mkdir(base_dir)return base_dir.joinpath(book_name)依旧是新建⽂件……第三步,封装⼀个公共⽅法def request_url(url, is_text: bool = False):"""请求url,直接定义的get请求:param url::param is_text: 判断数据是返回解析的数据还是原始的数据:return:"""s = Session()def encoding_gbk(r):"""转码:param r::return:"""r.encoding = "gbk"return etree.HTML(r.text)s.headers.update({"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"})response = s.get(url=url)return encoding_gbk(response) if is_text else etree.HTML(response.text)s=Session():可以理解成类似浏览器encoding_gbk(r):局部函数看,进⾏转码操作s.headers.update:是更新headers头return 根据判断返回转码的数据或是已解析的数据第四步,分析待爬⽬标处理URL封装⼀个函数,开始进⾏处理.....def page_num_url(page: int):"""排⾏榜链接获取⾃定义分页url列表:param page: 页码:return:"""time_url = "https://www.qqxsw.co/top/allvisit/"page_url_list = []for num in range(1, page + 1):# 拼接分页地址,并插⼊列表page_url_list.append(time_url + str(num) + ".html")return page_url_list这⾥也可以改成定义⼀个起始页数、⼀个结束页数,这样就更⽅便查询了,⼩伙伴们可以试试哈。

python3抓取晋江⽂学城免费章节⼩说看了别⼈写的抓取晋江⼩说的爬⾍后,⾃⼰动⼿写了⼀版简单的。
记录下。
【执⾏脚本时只需输⼊想下载的⽂章ID即可】1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43# -*- coding:utf8 -*-# 爬⾍ - 晋江⼩说import requestsimport lxml.htmlfrom itertools import productdef jj_Download(chapters_url, chapters_title, novel_name):i =0for u, t in product(chapters_url, chapters_title):i +=1if len(chapters_url) < i:returnprint(t +" 下载ing......")html =requests.get(chapters_url[i -1]).contentselector =lxml.html.fromstring(html)content_text =selector.xpath('///div[@class="noveltext"]/text()') name ="第"+str(i) +"章 "+t # 章节content ='\n'+name +'\n'.join(content_text)with open(novel_name,'a',encoding="utf-8") as f :f.write(content)f.write('\n')f.close()# 获取当前页⾯的所有章节地址# 晋江⼩说IDid=input("请输⼊⼩说novelid:")url =""+idres =requests.get(url).contenttree =lxml.html.fromstring(res)# 获取⾮vip章节链接chapters_url =tree.xpath('//tr[@itemprop="chapter"]//a/@href')# 获取全部章节标题chapters_title =tree.xpath('//tr[@itemprop="chapter"]//a/text()')# 获取⼩说名novel =tree.xpath('//span[@itemprop="articleSection"]/text()')[0]# 获取⼩说作者author =tree.xpath('//span[@itemprop="author"]/text()')[0]novel_name =novel +" 作者:"+author +".txt"jj_Download(chapters_url, chapters_title, novel_name)。

Python基础之爬取⾖瓣图书信息概述所谓爬⾍,就是帮助我们从互联⽹上获取相关数据并提取有⽤的信息。
在⼤数据时代,爬⾍是数据采集⾮常重要的⼀种⼿段,⽐⼈⼯进⾏查询,采集数据更加⽅便,更加快捷。
刚开始学爬⾍时,⼀般从静态,结构⽐较规范的⽹页⼊⼿,然后逐步深⼊。
今天以爬取⾖瓣最受关注图书为例,简述Python在爬⾍⽅⾯的初步应⽤,仅供学习分享使⽤,如有不⾜之处,还请指正。
涉及知识点如果要实现爬⾍,需要掌握的Pyhton相关知识点如下所⽰:requests模块:requests是python实现的最简单易⽤的HTTP库,建议爬⾍使⽤requests。
关于requests模块的相关内容,可参考及简书上的BeautifulSoup模块:Beautiful Soup 是⼀个可以从HTML或XML⽂件中提取数据的Python库。
它能够通过你喜欢的转换器实现惯⽤的⽂档导航,查找,修改⽂档的⽅式。
关于BeautifulSoup的更多内容,可参考。
json模块:JSON(JavaScript Object Notation) 是⼀种轻量级的数据交换格式,易于⼈阅读和编写。
使⽤ JSON 函数需要导⼊ json 库。
关于json的更多内容,可参考。
re模块:re模块提供了与 Perl 语⾔类似的正则表达式匹配操作。
关于re模块的更多内容,可参考。
⽬标页⾯本例中爬取的信息为⾖瓣最受关注图书榜信息,共10本当前最受欢迎图书。
爬取页⾯截图,如下所⽰:爬取数据步骤1. 分析页⾯通过浏览器提供的开发⼈员⼯具(快捷键:F12),可以⽅便的对页⾯元素进⾏定位,经过定位分析,本次所要获取的内容,包括在UL【class=chart-dashed-list】标签内容,每⼀本书,都对应⼀个LI元素,是本次爬取的⽬标,如下所⽰:每⼀本书,对应⼀个Li【class=media clearfix】元素,书名为对应a【class=fleft】元素,描述为P【class=subject-abstract color-gray】标签元素内容,具体到每⼀本书的的详细内容,如下所⽰:2. 下载数据如果要分析数据,⾸先要进⾏下载,获取要爬取的数据信息,在Python中爬取数据,主要⽤requests模块,如下所⽰:1def get_data(url):2"""3获取数据4 :param url: 请求⽹址5 :return:返回请求的页⾯内容6"""7# 请求头,模拟浏览器,否则请求会返回4188 header = {9'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '10'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}11 resp = requests.get(url=url, headers=header) # 发送请求12if resp.status_code == 200:13# 如果返回成功,则返回内容14return resp.text15else:16# 否则,打印错误状态码,并返回空17print('返回状态码:', resp.status_code)18return''注意:在刚开始写爬⾍时,通常会遇到“HTTP Error 418”,请求⽹站的服务器端会进⾏检测此次访问是不是⼈为通过浏览器访问,如果不是,则返回418错误码。

python7个爬虫小案例详解(附源码)Python 7个爬虫小案例详解(附源码)1. 爬取百度贴吧帖子使用Python的requests库和正则表达式爬取百度贴吧帖子内容,对网页进行解析,提取帖子内容和发帖时间等信息。
2. 爬取糗事百科段子使用Python的requests库和正则表达式爬取糗事百科段子内容,实现自动翻页功能,抓取全部内容并保存在本地。
3. 抓取当当网图书信息使用Python的requests库和XPath技术爬取当当网图书信息,包括书名、作者、出版社、价格等,存储在MySQL数据库中。
4. 爬取豆瓣电影排行榜使用Python的requests库和BeautifulSoup库爬取豆瓣电影排行榜,并对数据进行清洗和分析。
将电影的名称、评分、海报等信息保存到本地。
5. 爬取优酷视频链接使用Python的requests库和正则表达式爬取优酷视频链接,提取视频的URL地址和标题等信息。
6. 抓取小说网站章节内容使用Python的requests库爬取小说网站章节内容,实现自动翻页功能,不断抓取新的章节并保存在本地,并使用正则表达式提取章节内容。
7. 爬取新浪微博信息使用Python的requests库和正则表达式爬取新浪微博内容,获取微博的文本、图片、转发数、评论数等信息,并使用BeautifulSoup 库进行解析和分析。
这些爬虫小案例涵盖了网络爬虫的常见应用场景,对初学者来说是很好的入门教程。
通过学习这些案例,可以了解网络爬虫的基本原理和常见的爬取技术,并掌握Python的相关库的使用方法。
其次,这些案例也为后续的爬虫开发提供了很好的参考,可以在实际应用中进行模仿或者修改使用。
最后,这些案例的源码也为开发者提供了很好的学习资源,可以通过实战来提高Python编程水平。
Python爬⾍-爬取⾖瓣图书Top250⾖瓣⽹站很⼈性化,对于新⼿爬⾍⽐较友好,没有如果调低爬取频率,不⽤担⼼会被封 IP。
但也不要太频繁爬取。
涉及知识点:requests、html、xpath、csv⼀、准备⼯作需要安装requests、lxml、csv库⼆、分析页⾯源码打开⽹址,按下F12,然后查找书名,右键弹出菜单栏 Copy==> Copy Xpath以书名“追风筝的⼈” 获取书名的xpath是://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a这⾥需要注意⼀下,浏览器复制的xpath只能作参考,因为浏览器经常会在⾃⼰⾥⾯增加多余的tbody标签,我们需要⼿动把这个标签删除,整理成//* [@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a同样获取图书的评分、评论⼈数、简介,结果如下://*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]初步代码import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)#因为要获取标题⽂本,所以xpath表达式要追加/text(),res.xpath返回的是⼀个列表,且列表中只有⼀个元素所以追加⼀个[0]name = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()score = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]/text()')[0].strip()comment = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]/text()')[0].strip()info = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]/text()')[0].strip()print(name,score,comment,info)执⾏显⽰:这⾥只是获取第⼀条图书的信息,获取第⼆、第三看看得到xpath:import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)name1 = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()name2 = res.xpath('//*[@id="content"]/div/div[1]/div/table[2]/tr/td[2]/div[1]/a/text()')[0].strip()name3 = res.xpath('//*[@id="content"]/div/div[1]/div/table[3]/tr/td[2]/div[1]/a/text()')[0].strip()print(name1,name2,name3)执⾏显⽰:对⽐他们的xpath,发现只有table序号不⼀样,我们可以就去掉序号,得到全部关于书名的xpath信息:import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)names = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr/td[2]/div[1]/a/text()')for name in names:print(name.strip())执⾏结果:太多,这⾥只展⽰⼀部分对于其他评分、评论⼈数、简介也同样使⽤此⽅法来获取。
Python爬虫入门教程02:笔趣阁小说爬取前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文01、python爬虫入门教程01:豆瓣Top电影爬取基本开发环境•Python 3.6•Pycharm相关模块的使用•requests•parsel安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取一、明确需求爬取小说内容保存到本地•小说名字•小说章节名字•小说内容# 第一章小说url地址url = '/52_52642/25585323.html'url = '/52_52642/25585323.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}response = requests.get(url=url, headers=headers)print(response.text)请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding三、解析数据根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):# 调用请求网页数据函数response = get_response(html_url)# 转行成selector解析对象selector = parsel.Selector(response.text)# 获取小说标题title = selector.css('.bookname h1::text').get()# 获取小说内容返回的是listcontent_list = selector.css('#content::text').getall() # ''.join(列表) 把列表转换成字符串content_str = ''.join(content_list)print(title, content_str)if __name__ == '__main__':url = '/52_52642/25585323.html'get_one_novel(url)四、保存数据(数据持久化)使用常用的保存方式: with opendef save(title, content):"""保存小说:param title: 小说章节标题:param content: 小说内容:return:"""# 路径filename = f'{title}\\'# os 内置模块,自动创建文件夹if os.makedirs(filename):os.mkdir()# 一定要记得加后缀.txt mode 保存方式 a 是追加保存encoding 保存编码with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:# 写入标题f.write(title)# 换行f.write('\n')# 写入小说内容f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?整本小说爬虫既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
如何用python爬虫从爬取一章小说到爬取全站小说前言文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取/A6Zvjdun很多好看的小说只能看不能下载,教你怎么爬取一个网站的所有小说知识点:1.requests2.xpath3.全站小说爬取思路开发环境:1.版本:anaconda5.2.0(python3.6.5)2.编辑器:pycharm第三方库:1.requests2.parsel进行网页分析目标站点:•开发者工具的使用networkelement爬取一章小说•requests库的使用(请求网页数据)•对请求网页数据步骤进行封装•css选择器的使用(解析网页数据)•操作文件(数据持久化)# -*- coding: utf-8 -*-import requestsimport parsel"""爬取一章小说"""# 请求网页数据headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142Safari/537.36'}response = requests.get('/txt/8659/2324752.html', headers=headers)response.encoding = response.apparent_encodinghtml = response.textprint(html)# 从网页中提取内容sel = parsel.Selector(html)title = sel.css('.content h1::text').extract_first()contents = sel.css('#content::text').extract()contents2 = []for content in contents:contents2.append(content.strip())print(contents)print(contents2)print("\n".join(contents2))# 将内容写入文本with open(title+'.txt', mode='w', encoding='utf-8') as f:f.write("\n".join(contents2))爬取一本小说•对爬虫进行重构需要爬取很多章小说,最笨的方法是直接使用for 循环。
Python爬⾍之利⽤BeautifulSoup爬取⾖瓣⼩说(⼆)——回车分段打印⼩说信息在上⼀篇⽂章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印⼀页,15个⼩说的信息全部会显⽰⽽过,有时因为屏幕太⼩,⽆法显⽰全所有的⼩说信息,那么,在这篇⽂章中,我主要想通过设置回车来控制每⼀条⼩说信息的输出,当我按下回车时,会显⽰下⼀条⼩说的信息,按“Q”时,会退出程序,同时,这个⽅法还会根据包含⼩说信息的页⾯数量来决定是否加载新的⼀页。
⾸先,我们导⼊⼀些模块,定义⼀个类,初始化⽅法,定义⼀些变量:self.Novels⾥存放的是⼩说信息的变量,每⼀个元素是每⼀页的⼩说信息们self.load决定程序是否继续运⾏的变量1#-*-coding:utf-8-*-2import urllib23from bs4 import BeautifulSoup45class dbxs:67def__init__(self):8 self.pageIndex = 09 self.Novels = []10 self.load = False然后,我们获得html页⾯的内容,在这⾥,我们为了能够得到信息,⽽不让⾖瓣服务器查封我们的IP,我们设置了请求的头部信息headers和代理IP。
1def getPage(self, pageIndex):2#设置代理IP3 enable_proxy = True4 proxy_handler = urllib2.ProxyHandler({'Http': '116.30.251.210:8118'})5 null_proxy_handler = urllib2.ProxyHandler({})6if enable_proxy:7 opener = urllib2.build_opener(proxy_handler)8else:9 opener = urllib2.build_opener(null_proxy_handler)10 urllib2.install_opener(opener)1112#设置headers,模拟浏览器登录13try:14 url = 'https:///tag/%E5%B0%8F%E8%AF%B4/book' +'?start=' + str(pageIndex)15 my_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0)'}16 request = urllib2.Request(url, headers = my_headers)17 response = urllib2.urlopen(request)18return response.read()19 except urllib2.URLError, e:20if hasattr(e, "code"):21print e.code22if hasattr(e, "reason"):23print e.reason24return None我们获得的是html源码,源码⾥有包含我们想要的元素,但是为了⽅便抓取数据,利⽤BeautifulSoup解析⽂档,这⾥我们⽤的解析器是html.parser。
Python爬⾍练习:抓取笔趣阁⼩说(⼀)练习使⽤requests BeautifulSoup 抓取⼀本⼩说存放到D盘中速度⽐较慢、抓取服务器容易中断# -*- coding:UTF-8 -*-import requestsfrom bs4 import BeautifulSoupimport re"""获取书籍⽬录"""def getBookContents(url):req = requests.get(url=url)req.encoding = "gb2312"html = req.textdv_bf = BeautifulSoup(html, "html5lib")dv = dv_bf.find("div", class_="listmain")# dvs = dv_bf.find_all("div", class_="listmain")a_bf = BeautifulSoup(str(dv), "html5lib")a = a_bf.find_all("a")book_contents_list = []i = 0for content in a[13:]:book_title = content.stringbook_url = content.get("href")try:# 数据清洗获取标题"章"字索引若没有则出现异常不记录数据book_title_index = str(book_title).index("章", 0)# print(book_title_index)# 通过index切⽚获取新的章节标题new_book_title = book_title[book_title_index + 1:]# print(new_book_title)# 去除标题含有的空格i = i + 1new_book_titles = "第{}章".format(i) + new_book_title.lstrip()new_book_url = "{}".format(book_url)#print(new_book_titles, new_book_url)# ⼀组数据设置为字典类型contenets = {new_book_titles: new_book_url}# 存放到listbook_contents_list.append(contenets)except:# 通过异常捕捉,出现异常是没有找到"章"字符索引print("*****************不是正⽂章节节点,不予记录****************")print("原标题=", book_title)print("原链接=", new_book_url)return book_contents_list"""通过⽂章链接地址获取章节内容"""def getConnect(url):target = '/1_1094/5403177.html'req = requests.get(url=url)req.encoding = 'gb2312'html = req.textdiv_bf = BeautifulSoup(html, "html5lib")div = div_bf.find("div", id="content")# 去除script[s.extract() for s in div('script')]# print(div.text)return div.text"""将⼩说内容写⼊到⽂件"""def saveData(filepath, text):with open(filepath, mode="w", encoding="UTF-8") as f:f.writelines(text)f.write('\n\n')if __name__ == '__main__':book_list = getBookContents("/1_1094")for li in book_list:filepath = "d:\\123\\"connecturl = ""for aa in li.keys():filepath = filepath+aaconnecturl = li[aa]text = getConnect(connecturl) saveData(filepath,text)。