ORACLE的基本语法集锦
- 格式:doc
- 大小:27.50 KB
- 文档页数:3

oracle function 语法【1】Oracle Function 简介在Oracle 数据库中,Function 是一种存储过程,它允许你执行一系列的操作,并在过程中返回一个值。
Oracle Function 可以用于处理复杂的业务逻辑,并将结果返回给调用者。
它们提供了更高的灵活性和可重用性,使得开发者可以更高效地管理数据库。
【2】Oracle Function 语法结构Oracle Function 的基本语法结构如下:```CREATE OR REPLACE FUNCTION function_nameRETURN return_typeIS-- 声明变量和常量-- 声明过程变量BEGIN-- 业务逻辑RETURN return_value;END;/```其中,`function_name` 是函数的名称,`return_type` 是返回值的类型,`return_value` 是实际返回的值。
【3】参数传递Oracle Function 允许你通过参数传递数据。
参数可以在声明函数时定义,也可以在调用函数时传递。
定义参数的语法如下:```FUNCTION function_name(param1 data_type, param2 data_type, ...) RETURN return_type;```【4】返回值Oracle Function 可以通过`RETURN` 语句返回一个值。
返回值可以是任意数据类型,包括字符、数字、日期等。
以下是一个返回值的示例:```FUNCTION calculate_area(p_radius IN NUMBER)RETURN NUMBERISv_area NUMBER;BEGINv_area := POWER(p_radius, 2);RETURN v_area;END;/```【5】示例:创建一个简单的Oracle Function以下是一个计算圆面积的Function 示例:```FUNCTION calculate_area(p_radius IN NUMBER) RETURN NUMBERISv_area NUMBER;BEGINv_area := POWER(p_radius, 2);RETURN v_area;END;/```调用此Function 的SQL 语句如下:```SELECT calculate_area(5) FROM dual;```以上内容仅供参考,实际操作请根据具体需求和场景进行调整。

oracle中group by用法摘要:1.Oracle 中Group By 概述2.Group By 的基本语法3.Group By 的常见用法1.按某一列分组2.按多列分组3.使用聚合函数4.使用rollup 和cube5.使用having 子句4.Group By 的高级用法1.去除重复记录2.分组排序3.结合其他SQL 语句5.Group By 在实际应用中的案例正文:在Oracle 数据库中,Group By 是一个非常重要的SQL 语句组成部分,它可以帮助我们对查询结果进行分组和汇总。
本文将详细介绍Oracle 中Group By 的用法,包括基本语法、常见用法、高级用法以及在实际应用中的案例。
1.Oracle 中Group By 概述Group By 是SQL 语句中用于对查询结果进行分组和汇总的关键字。
通过使用Group By,我们可以将查询结果按照某一列或多个列进行分组,并对每组数据进行汇总。
2.Group By 的基本语法在Oracle 中,Group By 的基本语法如下:```sqlSELECT column1, column2, aggregate_function(column)FROM table_nameWHERE conditionGROUP BY column1, column2ORDER BY column1, column2;```其中,`aggregate_function` 可以是`COUNT`、`SUM`、`AVG`、`MAX`、`MIN` 等聚合函数,`column1` 和`column2` 是需要分组的列,`condition` 是查询条件,`ORDER BY` 子句用于对分组后的结果进行排序。
3.Group By 的常见用法接下来,我们将介绍Group By 的常见用法:3.1 按某一列分组```sqlSELECT department, COUNT(employee_id)FROM employeesGROUP BY department;```上述语句将按照`department` 列对`employees` 表进行分组,并计算每个部门的员工数量。

oracle if 语法Oracle IF语法详解一、引言Oracle是一种关系型数据库管理系统,提供了丰富的SQL语法来操作数据库。
其中,IF语法是一种常用的条件语句,用于根据条件判断执行不同的操作。
本文将详细介绍Oracle IF语法的使用方法和注意事项。
二、IF语法的基本用法IF语法的基本结构如下:IF 条件 THEN执行操作1;ELSE执行操作2;END IF;其中,条件是一个逻辑表达式,用于判断是否满足某个条件。
如果条件为真,则执行操作1;如果条件为假,则执行操作2。
三、IF语法的扩展用法除了基本的IF语法外,Oracle还提供了一些扩展用法,以满足更复杂的条件判断需求。
1. IF-ELSIF-ELSE结构如果需要判断多个条件,可以使用IF-ELSIF-ELSE结构。
示例如下:IF 条件1 THEN执行操作1;ELSIF 条件2 THEN执行操作2;ELSE执行操作3;END IF;在这种结构中,条件1为真时执行操作1;条件1为假,条件2为真时执行操作2;条件1和条件2都为假时执行操作3。
2. IF-THEN-ELSEIF-ELSE结构如果需要判断多个条件,并且每个条件都需要执行不同的操作,可以使用IF-THEN-ELSEIF-ELSE结构。
示例如下:IF 条件1 THEN执行操作1;ELSEIF 条件2 THEN执行操作2;ELSEIF 条件3 THEN执行操作3;ELSE执行操作4;END IF;在这种结构中,条件1为真时执行操作1;条件1为假,条件2为真时执行操作2;条件1和条件2都为假,条件3为真时执行操作3;条件1、条件2和条件3都为假时执行操作4。
3. IF-THEN嵌套结构在某些情况下,可能需要嵌套使用IF-THEN语句来实现更复杂的条件判断。
示例如下:IF 条件1 THENIF 条件2 THEN执行操作1;ELSE执行操作2;END IF;ELSE执行操作3;END IF;在这种结构中,条件1为真时,进一步判断条件2是否为真,如果条件2为真则执行操作1,否则执行操作2;条件1为假时执行操作3。

Oracle数据库语法总结一、DDL(数据定义语言)1、创建、删除表(1)CREATE TABLE 语句用于在Oracle数据库中创建新表:CREATETABLE表名(列1数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]列2数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]……(2)DROP TABLE 语句用于从Oracle数据库中删除表:DROPTABLE表名2、更改表(1)ALTERTABLE语句用于更改现有的表:ALTERTABLE表名ADD(添加新的列),MODIFY(修改现有的列),DROP(删除现有的列)(2)RENAME语句用于更改表名:RENAME表名1TO表名23、创建索引(1)CREATEINDEX语句用于在表中创建索引:CREATEINDEX索引名ON表名(列1,列2,...)(2)DROPINDEX语句用于从表中删除索引:DROPINDEX索引名4、创建约束(1)Primary Key 约束:ALTERTABLE表名ADDCONSTRAINT主键名PRIMARYKEY(列名)(2)Foreign Key约束:ALTERTABLE表名ADDCONSTRAINT外键名FOREIGNKEY(列名)REFERENCES参照表名(参照列);(3)Unique 约束:ALTERTABLE表名ADDCONSTRAINT唯一约束名UNIQUE(列1,列2,...);(4)NOTNULL约束:ALTERTABLE表名ADDCONSTRAINT非空约束名NOTNULL(列1,列2,...);5、删除约束(1)Primary Key 约束:ALTERTABLE表名DROPCONSTRAINT主键名PRIMARYKEY;(2)Foreign Key约束:ALTERTABLE表名DROPCONSTRAINT外键名FOREIGNKEY;(3)Unique 约束:。

第一篇基本操作--解锁用户alter user 用户account unlock;--锁定用户alter user 用户account lock;alter user scott account unlock;--创建一个用户yc 密码为a create user 用户名identified by 密码;create user yc identified by a;--登录不成功,会缺少create session 权限,赋予权限的语法grant 权限名to 用户;grant create session to yc;--修改密码alter user 用户名identified by 新密码;alter user yc identified by b;--删除用户drop user yc ;--查询表空间select *from dba_tablespaces;--查询用户信息select *from dba_users;--创建表空间create tablespace ycspacedatafile 'E:\oracle\app\product\11.2.0\dbhome_1\oradata\ycspace.dbf'size 2mautoextend on next 2m maxsize 5moffline ;--创建临时表空间create temporary yctempspacetempfile 'E:\oracle\app\product\11.2.0\dbhome_1\oradata\ycspace.dbf'size 2mautoextend on next 2m maxsize 5moffline ;--查询数据文件select *from dba_data_files;--修改表空间--1、修改表空间的状态--默认情况下是online,只有在非离线情况下才可以进行修改alter tablespace ycspace offline ; --离线状态,不允许任何对象对该表空间的使用,使用情况:应用需要更新或维护的时候;数据库备份的时候alter tablespace ycspace read write;--读写状态alter tablespace ycspace online;alter tablespace ycspace read only; --只读,可以查询信息,可以删除表空间的对象,但是不能创建对象和修改对象。


Oracle中START WITH的用法在Oracle数据库中,START WITH是一种用于查询树形结构数据的关键字。
它通常与CONNECT BY子句一起使用,用于指定树的起始节点。
1. START WITH语法以下是START WITH语句的基本语法:SELECT columnsFROM table[WHERE conditions][START WITH condition][CONNECT BY [PRIOR] condition]•columns: 需要查询的列名。
•table: 需要查询的表名。
•conditions: 查询条件。
•condition: 指定树的起始节点条件。
2. START WITH示例假设我们有一个名为employees的表,其中包含员工及其直接上级的信息。
该表包含以下列:employee_id, employee_name, supervisor_id。
我们想要查询某个员工及其所有下属的信息。
以下是使用START WITH和CONNECT BY进行查询的示例:SELECT employee_name, levelFROM employeesSTART WITH employee_id = 1 -- 假设我们从员工ID为1开始查询CONNECT BY PRIOR employee_id = supervisor_id;上述示例中,我们使用了START WITH employee_id = 1来指定从员工ID为1开始查询。
然后使用了CONNECT BY PRIOR employee_id = supervisor_id来指定如何连接每个节点。
3. START WITH和CONNECT BY详解3.1 START WITH子句在使用START WITH时,可以指定一个条件,作为树的起始节点。
这个条件可以是任何有效的SQL条件表达式。
在上述示例中,我们使用START WITH employee_id = 1来指定从员工ID为1的节点开始查询。
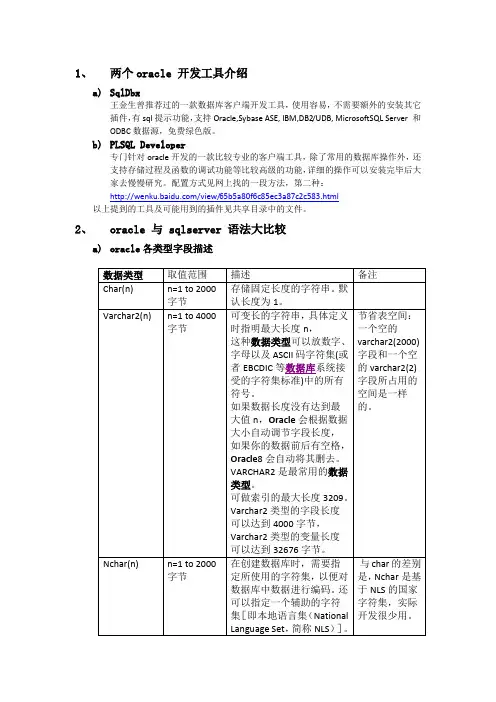
1、两个oracle 开发工具介绍a)SqlDbx王金生曾推荐过的一款数据库客户端开发工具,使用容易,不需要额外的安装其它插件,有sql提示功能,支持Oracle,Sybase ASE, IBM,DB2/UDB, MicrosoftSQL Server 和ODBC数据源,免费绿色版。
b)PLSQL Developer专门针对oracle开发的一款比较专业的客户端工具,除了常用的数据库操作外,还支持存储过程及函数的调试功能等比较高级的功能,详细的操作可以安装完毕后大家去慢慢研究。
配置方式见网上找的一段方法,第二种:/view/65b5a80f6c85ec3a87c2c583.html以上提到的工具及可能用到的插件见共享目录中的文件。
2、oracle 与 sqlserver 语法大比较a)oracle各类型字段描述b)字段类型比较c)常用函数比较注:此处仅记录语法有区别的地方,更多丰富的语法请查看附件中的手册。
以下的exp为expression的缩写d)关于脏读目前我们使用的sqlserver 数据库,在查询数据时,都要求在select语句中后面跟一个(nolock)或(with nolock)来保证读取大表时不影响其它程序进程的数据操作。
在oracle中,目前还不允许脏读的方式,在每次select 后,读到的数据都是已经commit的数据,所以为了避免读取数据的不准确,程序中如果有比较耗时的sql 操作,尤其是在insert 和update后,尽量减小事务,而且要在事务结束后及时commit。
e)表(主键、外键、CHECK、UNIQUE、DEFAULT、INDEX)在创建表及其主键、外键、CHECK、UNIQUE、DEFAULT、INDEX时,SQL SERVER 与ORACLE的语法大致相同。
主要区别如下:Oracle定义表字段的default属性紧跟字段类型之后,如下:Create table MZ_Ghxx( ghlxh number primay key ,rq date default sysdate not null,….)而不能写成Create table MZ_Ghxx( ghlxh number primay key ,rq date not null default sysdate,….)f)存储过程/函数结构的不同SQLSERVER中存储过程的结构大致如下CREATE PROCEDURE procedure_name/*输入、输出参数的声明部分*/ASDECLARE/*局部变量的声明部分*/BEGIN/*主体SQL语句部分*//*游标声明、使用语句在此部分*/ENDORACLE中存储过程的结构大致如下CREATE OR REPLACE PROCEDURE procedure_name(/*输入、输出参数的声明部分*/ )AS/*局部变量、游标等的声明部分*/BEGIN/*主体SQL语句部分*//*游标使用语句在此部分*/EXCEPTION/*异常处理部分*/END ;ORACLE端FUNCTION语法说明CREATE [OR REPLACE] FUNCTION function_name[(argument [{IN | OUT | IN OUT }] ) type,…[(argument [{IN | OUT | IN OUT }] ) typeRETURN return_type {IS | AS}BEGIN…END;变量赋值在SQL SERVER语句中用如下语句对局部变量赋值(初始值或数据库表的字段值或表达式):“SELECT 局部变量名= 所赋值(初始值或数据库表的字段值或表达式)”;而在ORACLE中,将初始值赋给局部变量时,用如下语句:“局部变量名: = 所赋值(初始值或表达式);”,将检索出的字段值赋给局部变量时,用如下语句:“SELECT 数据库表的字段值INTO 局部变量名…”。

oracle标准建表语句
Oracle标准建表语句的基本语法如下:
sql复制代码
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
...
);
其中,table_name是要创建的表的名称,column1, column2, column3等是表的列名,datatype是列的数据类型。
在建表时,你可以为每列指定一个数据类型,例如:
•NUMBER:用于存储整数和浮点数。
•VARCHAR2:用于存储可变长度的字符串。
•DATE:用于存储日期和时间。
•CLOB:用于存储大型文本数据。
•等等。
你还可以为表中的某些列设置约束,例如:
•NOT NULL:指定该列不能为空。
•PRIMARY KEY:指定该列作为主键,用于唯一标识表中的每一行。
•FOREIGN KEY:指定该列是外键,用于建立表之间的关系。
•UNIQUE:指定该列的唯一性约束,确保该列中的值都是唯一的。
•等等。
以下是一个具体的例子,创建一个名为employees的表,包含id, name, 和salary三个列:
sql复制代码
CREATE TABLE employees (
id NUMBER PRIMARY KEY,
name VARCHAR2(50),
salary NUMBER(10, 2)
);
这只是一个简单的例子,实际上Oracle 支持更多的语法和功能,可以根据具体需求进行调整。

oracle动态sql语句基本语法Oracle动态SQL语句是一种在运行时动态生成SQL语句的技术。
它可以根据不同的条件和参数生成不同的SQL语句,从而实现更加灵活和高效的数据操作。
下面是Oracle动态SQL语句的基本语法:1. 使用EXECUTE IMMEDIATE语句执行动态SQL语句:EXECUTE IMMEDIATE 'SELECT * FROM employees WHERE department_id = :dept_id' USING dept_id;2. 使用BIND VARIABLES绑定变量:DECLAREv_dept_id NUMBER := 10;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id = :dept_id';EXECUTE IMMEDIATE v_sql USING v_dept_id;END;3. 使用PL/SQL变量拼接SQL语句:DECLAREv_dept_id NUMBER := 10;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id = ' || v_dept_id;EXECUTE IMMEDIATE v_sql;END;4. 使用CASE语句生成动态SQL语句:DECLAREv_dept_id NUMBER := 10;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id = ';v_sql := v_sql || CASE WHEN v_dept_id IS NULL THEN 'NULL' ELSE TO_CHAR(v_dept_id) END;EXECUTE IMMEDIATE v_sql;END;5. 使用FOR LOOP生成动态SQL语句:DECLAREv_dept_id NUMBER := 10;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id IN (';FOR i IN 1..10 LOOPv_sql := v_sql || i || ',';END LOOP;v_sql := SUBSTR(v_sql, 1, LENGTH(v_sql) - 1) || ')';EXECUTE IMMEDIATE v_sql;END;6. 使用SYS_CONTEXT函数获取当前用户信息:DECLAREv_user VARCHAR2(30) := SYS_CONTEXT('USERENV', 'CURRENT_USER');v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE created_by = ''' || v_user || '''';EXECUTE IMMEDIATE v_sql;END;7. 使用DBMS_SQL包执行动态SQL语句:DECLAREv_cursor INTEGER;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id = :dept_id';v_cursor := DBMS_SQL.OPEN_CURSOR;DBMS_SQL.PARSE(v_cursor, v_sql, DBMS_SQL.NATIVE);DBMS_SQL.BIND_VARIABLE(v_cursor, ':dept_id', 10);DBMS_SQL.EXECUTE(v_cursor);DBMS_SQL.CLOSE_CURSOR(v_cursor);END;8. 使用DBMS_SQL.RETURN_RESULT函数返回结果集:DECLAREv_cursor INTEGER;v_sql VARCHAR2(100);BEGINv_sql := 'SELECT * FROM employees WHERE department_id = :dept_id';v_cursor := DBMS_SQL.OPEN_CURSOR;DBMS_SQL.PARSE(v_cursor, v_sql, DBMS_SQL.NATIVE);DBMS_SQL.BIND_VARIABLE(v_cursor, ':dept_id', 10);DBMS_SQL.EXECUTE(v_cursor);DBMS_SQL.RETURN_RESULT(v_cursor);DBMS_SQL.CLOSE_CURSOR(v_cursor);END;9. 使用DBMS_SQL.DESCRIBE_COLUMNS函数获取结果集元数据:DECLAREv_cursor INTEGER;v_sql VARCHAR2(100);v_col_cnt INTEGER;v_col_desc DBMS_SQL.DESC_TAB;BEGINv_sql := 'SELECT * FROM employees WHERE department_id = :dept_id';v_cursor := DBMS_SQL.OPEN_CURSOR;DBMS_SQL.PARSE(v_cursor, v_sql, DBMS_SQL.NATIVE);DBMS_SQL.BIND_VARIABLE(v_cursor, ':dept_id', 10);DBMS_SQL.EXECUTE(v_cursor);v_col_cnt := DBMS_SQL.FETCH_ROWS(v_cursor);DBMS_SQL.DESCRIBE_COLUMNS(v_cursor, v_col_cnt, v_col_desc); DBMS_SQL.CLOSE_CURSOR(v_cursor);END;10. 使用DBMS_SQL.COLUMN_VALUE函数获取结果集列值:DECLAREv_cursor INTEGER;v_sql VARCHAR2(100);v_col_cnt INTEGER;v_col_desc DBMS_SQL.DESC_TAB;v_emp_id NUMBER;v_emp_name VARCHAR2(30);BEGINv_sql := 'SELECT employee_id, first_name FROM employees WHERE department_id = :dept_id';v_cursor := DBMS_SQL.OPEN_CURSOR;DBMS_SQL.PARSE(v_cursor, v_sql, DBMS_SQL.NATIVE);DBMS_SQL.BIND_VARIABLE(v_cursor, ':dept_id', 10);DBMS_SQL.EXECUTE(v_cursor);v_col_cnt := DBMS_SQL.FETCH_ROWS(v_cursor);DBMS_SQL.DESCRIBE_COLUMNS(v_cursor, v_col_cnt, v_col_desc); LOOPEXIT WHEN DBMS_SQL.FETCH_ROWS(v_cursor) = 0;DBMS_SQL.COLUMN_VALUE(v_cursor, 1, v_emp_id);DBMS_SQL.COLUMN_VALUE(v_cursor, 2, v_emp_name);DBMS_OUTPUT.PUT_LINE(v_emp_id || ' ' || v_emp_name);END LOOP;DBMS_SQL.CLOSE_CURSOR(v_cursor);END;以上是Oracle动态SQL语句的基本语法,可以根据实际需求进行灵活应用。

Oracle 常用语句汇总select * from user_tab_comments 取得所有表的注释select * from user_col_comments 取得所有列的注释select * from user_tables 取得当前用户下所有的表1、查找表的所有索引(包括索引名,类型,构成列):select t.*,i.index_type from user_ind_columns t,user_indexes i where t.index_name = i.index_name and t.table_name = i.table_name and t.table_name = 要查询的表2、查找表的主键(包括名称,构成列):select cu.* from user_cons_columns cu, user_constraints au where cu.constraint_name = au.constraint_name and au.constraint_type = 'P' and au.table_name = 要查询的表3、查找表的唯一性约束(包括名称,构成列):select column_name from user_cons_columns cu, user_constraints au where cu.constraint_name = au.constraint_name and au.constraint_type = 'U' and au.table_name = 要查询的表4、查找表的外键(包括名称,引用表的表名和对应的键名,下面是分成多步查询):select * from user_constraints c where c.constraint_type = 'R' and c.table_name = 要查询的表查询外键约束的列名:select * from user_cons_columns cl where cl.constraint_name = 外键名称查询引用表的键的列名:select * from user_cons_columns cl where cl.constraint_name = 外键引用表的键名5、查询表的所有列及其属性select t.*,MENTS from user_tab_columns t,user_col_comments c where t.table_name = c.table_name and t.column_name = c.column_name and t.table_name = 要查询的表/*1-获取任意用户下的主键字段*/select cons.* from all_cons_columns cons, all_constraints conwhere con.constraint_type='P'and cons.table_name = '表名'and cons.constraint_name=con.constraint_name;/*2-获取本用户下的主键字段*/select cu.* from user_cons_columns cu, user_constraints au where cu.constraint_name = au.constraint_name and au.constraint_type = 'P' and au.table_name = '表名'正在看的ORACLE教程是:oracle常用sql语句。
oracle 语句大全SELECT --从数据库表中检索数据行和列INSERT --向数据库表添加新数据行DELETE --从数据库表中删除数据行UPDATE --更新数据库表中的数据--数据定义CREATE TABLE --创建一个数据库表DROP TABLE --从数据库中删除表ALTER TABLE --修改数据库表结构CREATE VIEW --创建一个视图DROP VIEW --从数据库中删除视图CREATE INDEX --为数据库表创建一个索引DROP INDEX --从数据库中删除索引CREATE PROCEDURE --创建一个存储过程DROP PROCEDURE --从数据库中删除存储过程CREATE TRIGGER --创建一个触发器DROP TRIGGER --从数据库中删除触发器CREATE SCHEMA --向数据库添加一个新模式DROP SCHEMA --从数据库中删除一个模式CREATE DOMAIN --创建一个数据值域ALTER DOMAIN --改变域定义DROP DOMAIN --从数据库中删除一个域--数据控制GRANT --授予用户访问权限DENY --拒绝用户访问REVOKE --解除用户访问权限--事务控制COMMIT --结束当前事务ROLLBACK --中止当前事务SET TRANSACTION --定义当前事务数据访问特征--程序化SQLDECLARE --为查询设定游标EXPLAN --为查询描述数据访问计划OPEN --检索查询结果打开一个游标FETCH --检索一行查询结果CLOSE --关闭游标PREPARE --为动态执行准备SQL 语句EXECUTE --动态地执行SQL 语句DESCRIBE --描述准备好的查询---局部变量declare @id char(10)--set @id = '10010001'select @id = '10010001'---全局变量---必须以@@开头--IF ELSEdeclare @x int @y int @z intselect @x = 1 @y = 2 @z=3if @x > @yprint 'x > y' --打印字符串'x > y'else if @y > @zprint 'y > z'else print 'z > y'--CASEuse panguupdate employeeset e_wage =casewhen job_level = ’1’ then e_wage*1.08when job_level = ’2’ then e_wage*1.07when job_level = ’3’ then e_wage*1.06else e_wage*1.05end--WHILE CONTINUE BREAKdeclare @x int @y int @c intselect @x = 1 @y=1while @x <3 br/>beginprint @x --打印变量x 的值while @y <3 br/>beginselect @c = 100*@x + @yprint @c --打印变量c 的值select @y = @y + 1endselect @x = @x + 1select @y = 1end--WAITFOR--例等待1 小时2 分零3 秒后才执行SELECT 语句waitfor delay ’01:02:03’select * from employee--例等到晚上11 点零8 分后才执行SELECT 语句waitfor time ’23:08:00’select * from employee***SELECT***select *(列名) from table_name(表名) where column_name operator valueex:(宿主)select * from stock_information where stockid = str(nid)stockname = 'str_name'stockname like '% find this %'stockname like '[a-zA-Z]%' --------- ([]指定值的范围)stockname like '[^F-M]%' --------- (^排除指定范围)--------- 只能在使用like关键字的where子句中使用通配符)or stockpath = 'stock_path'or stocknumber <1000 br/>and stockindex = 24not stocksex = 'man'stocknumber between 20 and 100stocknumber in(10,20,30)order by stockid desc(asc) --------- 排序,desc-降序,asc-升序order by 1,2 --------- by列号stockname = (select stockname from stock_information where stockid = 4)--------- 子查询--------- 除非能确保内层select只返回一个行的值,--------- 否则应在外层where子句中用一个in限定符select distinct column_name form table_name --------- distinct指定检索独有的列值,不重复select stocknumber ,"stocknumber + 10" = stocknumber + 10 from table_nameselect stockname , "stocknumber" = count(*) from table_name group by stockname--------- group by 将表按行分组,指定列中有相同的值having count(*) = 2 --------- having选定指定的组select *from table1, table2where table1.id *= table2.id -------- 左外部连接,table1中有的而table2中没有得以null表示table1.id =* table2.id -------- 右外部连接select stockname from table1union [all] ----- union合并查询结果集,all-保留重复行select stockname from table2***insert***insert into table_name (Stock_name,Stock_number) value ("xxx","xxxx")value (select Stockname , Stocknumber from Stock_table2)---value为select语句***update***update table_name set Stockname = "xxx" [where Stockid = 3]Stockname = defaultStockname = nullStocknumber = Stockname + 4***delete***delete from table_name where Stockid = 3truncate table_name ----------- 删除表中所有行,仍保持表的完整性drop table table_name --------------- 完全删除表***alter table*** --- 修改数据库表结构alter table database.owner.table_name add column_name char(2) null .....sp_help table_name ---- 显示表已有特征create table table_name (name char(20), age smallint, lname varchar(30))insert into table_name select ......... ----- 实现删除列的方法(创建新表)alter table table_name drop constraint Stockname_default ---- 删除Stockname的default约束***function(/*常用函数*/)***----统计函数----AVG --求平均值COUNT --统计数目MAX --求最大值MIN --求最小值SUM --求和--AVGuse panguselect avg(e_wage) as dept_avgWagefrom employeegroup by dept_id--MAX--求工资最高的员工姓名use panguselect e_namefrom employeewhere e_wage =(select max(e_wage)from employee)--STDEV()--STDEV()函数返回表达式中所有数据的标准差--STDEVP()--STDEVP()函数返回总体标准差--VAR()--VAR()函数返回表达式中所有值的统计变异数--VARP()--VARP()函数返回总体变异数----算术函数----/***三角函数***/SIN(float_expression) --返回以弧度表示的角的正弦COS(float_expression) --返回以弧度表示的角的余弦TAN(float_expression) --返回以弧度表示的角的正切COT(float_expression) --返回以弧度表示的角的余切/***反三角函数***/ASIN(float_expression) --返回正弦是FLOAT 值的以弧度表示的角ACOS(float_expression) --返回余弦是FLOAT 值的以弧度表示的角ATAN(float_expression) --返回正切是FLOAT 值的以弧度表示的角ATAN2(float_expression1,float_expression2)--返回正切是float_expression1 /float_expres-sion2的以弧度表示的角DEGREES(numeric_expression)--把弧度转换为角度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型RADIANS(numeric_expression) --把角度转换为弧度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型EXP(float_expression) --返回表达式的指数值LOG(float_expression) --返回表达式的自然对数值LOG10(float_expression)--返回表达式的以10 为底的对数值SQRT(float_expression) --返回表达式的平方根/***取近似值函数***/CEILING(numeric_expression) --返回>=表达式的最小整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型FLOOR(numeric_expression) --返回<=表达式的最小整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型ROUND(numeric_expression) --返回以integer_expression 为精度的四舍五入值返回的数据--类型与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型ABS(numeric_expression) --返回表达式的绝对值返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型SIGN(numeric_expression) --测试参数的正负号返回0 零值1 正数或-1 负数返回的数据类型--与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型PI() --返回值为π即3.1415926535897936RAND([integer_expression]) --用任选的[integer_expression]做种子值得出0-1 间的随机浮点数----字符串函数----ASCII() --函数返回字符表达式最左端字符的ASCII 码值CHAR() --函数用于将ASCII 码转换为字符--如果没有输入0 ~ 255 之间的ASCII 码值CHAR 函数会返回一个NULL 值LOWER() --函数把字符串全部转换为小写UPPER() --函数把字符串全部转换为大写STR() --函数把数值型数据转换为字符型数据LTRIM() --函数把字符串头部的空格去掉RTRIM() --函数把字符串尾部的空格去掉LEFT(),RIGHT(),SUBSTRING() --函数返回部分字符串CHARINDEX(),PATINDEX() --函数返回字符串中某个指定的子串出现的开始位置SOUNDEX() --函数返回一个四位字符码--SOUNDEX函数可用来查找声音相似的字符串但SOUNDEX函数对数字和汉字均只返回0 值DIFFERENCE() --函数返回由SOUNDEX 函数返回的两个字符表达式的值的差异--0 两个SOUNDEX 函数返回值的第一个字符不同--1 两个SOUNDEX 函数返回值的第一个字符相同--2 两个SOUNDEX 函数返回值的第一二个字符相同--3 两个SOUNDEX 函数返回值的第一二三个字符相同--4 两个SOUNDEX 函数返回值完全相同QUOTENAME() --函数返回被特定字符括起来的字符串/*select quotename('abc', '{') quotename('abc')运行结果如下----------------------------------{{abc} [abc]*/REPLICATE() --函数返回一个重复character_expression 指定次数的字符串/*select replicate('abc', 3) replicate( 'abc', -2)运行结果如下----------- -----------abcabcabc NULL*/REVERSE() --函数将指定的字符串的字符排列顺序颠倒REPLACE() --函数返回被替换了指定子串的字符串/*select replace('abc123g', '123', 'def')运行结果如下----------- -----------abcdefg*/SPACE() --函数返回一个有指定长度的空白字符串STUFF() --函数用另一子串替换字符串指定位置长度的子串----数据类型转换函数----CAST() 函数语法如下CAST() ( AS [ length ])CONVERT() 函数语法如下CONVERT() ([ length ], [, style])select cast(100+99 as char) convert(varchar(12), getdate())运行结果如下------------------------------ ------------199 Jan 15 2000----日期函数----DAY() --函数返回date_expression 中的日期值MONTH() --函数返回date_expression 中的月份值YEAR() --函数返回date_expression 中的年份值DATEADD( , ,)--函数返回指定日期date 加上指定的额外日期间隔number 产生的新日期DATEDIFF( , ,)--函数返回两个指定日期在datepart 方面的不同之处DATENAME( , ) --函数以字符串的形式返回日期的指定部分DATEPART( , ) --函数以整数值的形式返回日期的指定部分GETDATE() --函数以DATETIME 的缺省格式返回系统当前的日期和时间----系统函数----APP_NAME() --函数返回当前执行的应用程序的名称COALESCE() --函数返回众多表达式中第一个非NULL 表达式的值COL_LENGTH(<'table_name'>, <'column_name'>) --函数返回表中指定字段的长度值COL_NAME(, ) --函数返回表中指定字段的名称即列名DATALENGTH() --函数返回数据表达式的数据的实际长度DB_ID(['database_name']) --函数返回数据库的编号DB_NAME(database_id) --函数返回数据库的名称HOST_ID() --函数返回服务器端计算机的名称HOST_NAME() --函数返回服务器端计算机的名称IDENTITY([, seed increment]) [AS column_name])--IDENTITY() 函数只在SELECT INTO 语句中使用用于插入一个identity column列到新表中/*select identity(int, 1, 1) as column_nameinto newtablefrom oldtable*/ISDATE() --函数判断所给定的表达式是否为合理日期ISNULL(, ) --函数将表达式中的NULL 值用指定值替换ISNUMERIC() --函数判断所给定的表达式是否为合理的数值NEWID() --函数返回一个UNIQUEIDENTIFIER 类型的数值NULLIF(, )--NULLIF 函数在expression1 与expression2 相等时返回NULL 值若不相等时则返回expression1 的值??。
oracle create user语句摘要:1.Oracle 创建用户的基本语法2.Oracle 创建用户的步骤3.Oracle 创建用户的注意事项正文:一、Oracle 创建用户的基本语法Oracle 数据库创建用户的基本语法如下:```CREATE USER [USERNAME] IDENTIFIED BY [PASSWORD]PROFILE [PROFILE_NAME]```- USERNAME:要创建的用户名- PASSWORD:用户的密码- PROFILE_NAME:可选项,指定用户所属的角色二、Oracle 创建用户的步骤1.打开Oracle SQL*Plus 或使用其他工具连接到Oracle 数据库。
2.输入以下命令,创建用户:```CREATE USER example_user IDENTIFIED BY example_password PROFILE default_role```3.如果要创建多个用户,可以使用以下命令:```CREATE USER example_user1 IDENTIFIED BY example_password1 CREATE USER example_user2 IDENTIFIED BY example_password2 ```三、Oracle 创建用户的注意事项1.用户名和密码必须符合Oracle 的命名规则,例如,用户名长度应在1 到30 个字符之间,密码长度应在8 到20 个字符之间。
2.在创建用户时,可以指定用户所属的角色。
如果不指定,则用户将默认属于"DEFAULT"角色。
3.在创建用户后,可以使用"ALTER USER"命令对用户进行修改,例如更改用户名、密码或角色等。
oracle常⽤语法别名别名中不能出现中⽂括号()不能使⽤全⾓符号coalescecoalesce(参数列表):返回参数列表中第⼀个⾮空参数,最后⼀个参数通常为常量distinct去重nvl作⽤:判断某个值是否为空值,若不为空值则输出,若为空值,返回指定值。
专详细解释如下:1、nvl()函数的格属式如下:NVL(expr1,expr2);2、含义是:如果oracle第⼀个参数为空那么显⽰第⼆个参数的值,如果第⼀个参数的值不为空,则显⽰第⼀个参数本来的值。
3、例:select name,NVL(name,-1) from user;运⾏后,结果返回两列数值,若name为空,则返回-1,若name不为空值,则返回其⾃⾝。
roundround函数⽤于数据的四舍五⼊1、round(x,d) ,x指要处理的数,d是指保留⼏位⼩数这⾥有个值得注意的地⽅是,d可以是负数,这时是指定⼩数点左边的d位整数位为0,同时⼩数位均为0;2、round(x) ,其实就是round(x,0),也就是默认d为0;union与union allunion:去重复,排序union all:不重复也不排序.(推荐)intersect 与 minusintersect 就是交集minus 就是差集交集就是两个结果集中都有的元素⽐如 select uid from tb1intersectselect uid from tb2那么既存在zhitb1 ⼜存在tb2中相同的UID 就会查dao出来差集:select uid from tb1minusselect uid from tb2存在于tb1 但不存在与tb2中的uid 会被查出表的复制如果需要对表中的数据进⾏删除和修改,建议通过复制表中的数据来对数据进⾏操作create table 表名 as 查询语句;--将emp表中的数据复制到t_emp表中create table t_empasselect * from emp;--只需要表的结构--将emp表的结构复制到t_emp表中create table t_empasselect * from empwhere 1=0;/*提供⼀个否定条件*/--只复制⼀部分数据--将emp表中部门10的员⼯的数据复制到t_emp表中create table t_empasselect * from empwhere deptno=10;--将emp表中的员⼯姓名,⼯资,年薪保存到t_emp表中create table t_empasselect ename,sal,sal*12 year_sal /*如果字段中出现函数或者计算需要提供别名*/ from emp;--统计emp表中部门的⼈数,将部门编码和⼈数保存到t_emp表中create table t_emp(did,ecount)asselect deptno,count(ename)from empgroup by deptno;注意:表的复制只会复制表中的数据,不会复制表中的约束伪列rowid,rownumselect rowid from dual;rowid:是⼀个伪列,Oracle独有的.每⼀条记录的rowid 的记录是唯⼀的sign⽐较⼤⼩与0进⾏⽐较,判断是不是正数,⼤于0显⽰1 ,⼩于0显⽰-1 ,等于0显⽰0 select sign( 100 ),sign(- 100 ),sign( 0 ) from dual;如何进⾏SQL语句的优化在select语句中避免使⽤*减少数据库的访问次数删除重复记录尽量多使⽤commit使⽤where替换having多使⽤内部函数提⾼sql语句效率多使⽤表的别名使⽤exists替换in,使⽤not exists替换notin尽量使⽤索引类进⾏查询sql语句尽量⼤写.oracle会⾃动转换成⼤写避免在索引列上进⾏计算避免在索引类上使⽤not,oracle遇到not就使⽤全表扫描可以使⽤>=替换>使⽤in替换or尽量使⽤where替换groupby避免使⽤消耗资源的操作.如union⼦查询注意事项1.⼦查询需要定义在括号当中2.⼦查询通常定义在条件判断的右边3.在⼦查询中不建议使⽤ order by⼦查询中多⾏⽐较符in :等于列表中的任何⼀个any:和⼦查询结果中的任意⼀个值进⾏⽐较all:和⼦查询结果中的所有值进⾏⽐较oracle 与 mysql的区别(1) 对事务的提交MySQL默认是⾃动提交,⽽Oracle默认不⾃动提交,需要⽤户⼿动提交,需要在写commit;指令或者点击commit按钮(2) 分页查询MySQL是直接在SQL语句中写"select... from ...where...limit x, y",有limit就可以实现分页;⽽Oracle则是需要⽤到伪列ROWNUM和嵌套查询(3) 事务隔离级别MySQL是read commited的隔离级别,⽽Oracle是repeatable read的隔离级别,同时⼆者都⽀持serializable串⾏化事务隔离级别,可以实现最⾼级别的读⼀致性。
Oracle存储过程基本语法存储过程1 CREATE OR REPLACE PROCEDURE 存储过程名2 IS3 BEGIN4 NULL;5 END;行1:CREATE OR REPLACE PROCEDURE 是一个SQL语句通知Oracle数据库去创建一个叫做skelet on存储过程, 如果存在就覆盖它;行2:IS关键词表明后面将跟随一个PL/SQL体。
行3:BEGIN关键词表明PL/SQL体的开始。
行4:NULL PL/SQL语句表明什么事都不做,这句不能删去,因为PL/SQL体中至少需要有一句;行5:END关键词表明PL/SQL体的结束存储过程创建语法:create or replace procedure 存储过程名(param1 in type,param2 out type)as变量1 类型(值范围); --vs_msg VARCHAR2(4000);变量2 类型(值范围);BeginSelect count(*) into 变量1 from 表A where列名=param1;If (判断条件) thenSelect 列名 into 变量2 from 表A where列名=param1;Dbms_output。
Put_line(‘打印信息’);Elsif (判断条件) thenDbms_output。
Put_line(‘打印信息’);ElseRaise 异常名(NO_DATA_FOUND);End if;ExceptionWhen others thenRollback;End;注意事项:1,存储过程参数不带取值范围,in表示传入,out表示输出类型可以使用任意Oracle中的合法类型。
2,变量带取值范围,后面接分号3,在判断语句前最好先用count(*)函数判断是否存在该条操作记录4,用select 。
into。
给变量赋值5,在代码中抛异常用 raise+异常名CREATE OR REPLACE PROCEDURE存储过程名(--定义参数is_ym IN CHAR(6) ,the_count OUT NUMBER,)AS--定义变量vs_msg VARCHAR2(4000); --错误信息变量vs_ym_beg CHAR(6); --起始月份vs_ym_end CHAR(6); --终止月份vs_ym_sn_beg CHAR(6); --同期起始月份vs_ym_sn_end CHAR(6); --同期终止月份--定义游标(简单的说就是一个可以遍历的结果集)CURSOR cur_1 ISSELECT 。
Oracle存储过程常⽤语法及其使⽤1、什么是存储过程存储过程Procedure是⼀组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,⽤户通过指定存储过程的名称并给出参数来执⾏。
它可以接受参数、输出参数,并可以返回单个或多个结果集以及返回值。
2、存储过程基本语法存储过程的⼀般格式如下:CREATE [OR REPLACE] PROCEDURE procedure_nameIS [AS]声明部分BEGIN执⾏部分EXCEPTION异常处理部分END;调⽤存储过程:call procedure_name();---------------------------------exec procedure_name();---------------------------------beginpro_update_emp();end;写⼀个简单的存储过程使emp表的sal值增加300。
CREATE or replace procedure pro_update_empasbeginupdate emp set sal=sal+300;end;调⽤存储过程call pro_update_emp ();3、数据类型3.1 %type 数据类型:当使⽤%TYPE属性定义变量时,Oracle会⾃动地按照数据库表中相应的列来确定新变量的类型和长度。
如下,将emp表的ename字段的数据类型(如 ‘varchar(2)’)赋给变量 v_enamev_ename emp.ename%type3.2 %ROWTYPE数据类型:如果⼀张表中包含较多的列,则可以使⽤%ROWTYPE来表⽰表中⼀⾏记录的变量的数据类型。
如下:将dept表中⼀⾏中各字段的数据类型(‘number’,’varchar2(50)’,varchar2(50))赋给v_dept_row,⾮常便利,可以直接查询后将⼀⾏数据赋值。
(注:语句中 into 执⾏赋值操作,将查询结果直接赋值给 v_dept_row)CREATE or replace procedure pro_update_empasv_dept_row dept%rowtype;beginselect * into v_dept_row from dept where deptno=11;end;3.3 %record数据类型:⾃定义记录的数据类型,声明⼀个⾏数据类型,将每列的数据类型进⾏⾃定义。
oracle 的语法Oracle的语法是一种用于访问和管理Oracle数据库的编程语言。
它提供了一种结构化的方式来存储、操作和检索数据,并允许用户创建和管理数据库对象。
本文将介绍一些常用的Oracle语法,并解释其用法和含义。
一、DDL语句DDL(Data Definition Language)语句用于定义和管理数据库对象,例如表、视图、索引等。
常用的DDL语句包括CREATE、ALTER和DROP。
1. CREATE TABLECREATE TABLE语句用于创建表。
它指定了表的名称和列的定义。
列的定义包括名称、数据类型和约束条件等。
例如:CREATE TABLE employees (employee_id NUMBER(10),first_name VARCHAR2(50),last_name VARCHAR2(50),hire_date DATE,salary NUMBER(10,2));2. ALTER TABLEALTER TABLE语句用于修改表的结构。
它可以添加、修改或删除列,添加或删除约束等。
例如:ALTER TABLE employeesADD (department_id NUMBER(10));3. DROP TABLEDROP TABLE语句用于删除表。
它会删除表的定义和所有相关的数据。
例如:DROP TABLE employees;二、DML语句DML(Data Manipulation Language)语句用于操作数据库中的数据。
常用的DML语句包括SELECT、INSERT、UPDATE和DELETE。
1. SELECTSELECT语句用于查询数据库中的数据。
它可以指定要查询的列、表和条件等。
例如:SELECT employee_id, first_name, last_nameFROM employeesWHERE department_id = 100;2. INSERTINSERT语句用于向表中插入新的数据。
ORACLE的基本语法集锦
-- 表
create table test (names varchar2(12),
dates date,
num int,
dou double);
-- 视图
create or replace view vi_test as
select * from test;
-- 同义词
create or replace synonym aa
for dbusrcard001.aa;
-- 存储过程
create or replace produce dd(v_id in employee.empoy_id%type)
as
begin
end
dd;
-- 函数
create or replace function ee(v_id in employee%rowtype) return varchar(15) is
var_test varchar2(15);
begin
return var_test;
exception when others then
end
-- 三种触发器的定义
create or replace trigger ff
alter delete
on test
for each row
declare
begin
delete from test;
if sql%rowcount < 0 or sql%rowcount is null then
rais_replaction_err(-20004,"错误")
end
create or replace trigger gg
alter insert
on test
for each row
declare
begin
if :s = :s then
raise_replaction_err(-2003,"编码重复");
end if
end
create or replace trigger hh
for update
on test
for each row
declare
begin
if updating then
if :s <> :s then
reaise_replaction_err(-2002,"关键字不能修改") end if
end if
end
-- 定义游标
declare
cursor aa is
select names,num from test;
begin
for bb in aa
loop
if s = "ORACLE" then
end if
end loop;
end
-- 速度优化,前一语句不后一语句的速度快几十倍select names,dates
where s = s(+) and
s is null and
b.dates > date('2003-01-01','yyyy-mm-dd')
select names,dates
from test
where names not in ( select names
from b
where dates > to_date('2003-01-01','yyyy-mm-dd'))
-- 查找重复记录
select names,num
from test
where rowid != (select max(rowid)
from test b
where s = s and
b.num = test.num)
-- 查找表TEST中时间最新的前10条记录
select * from (select * from test order by dates desc) where rownum < 11 -- 序列号的产生
create sequence row_id
minvalue 1
maxvalue 9999999999999999999999
start with 1
increment by 1
insert into test values(row_id.nextval,....)。