ORACLE 11g SELECT 语句基础语法
- 格式:docx
- 大小:20.43 KB
- 文档页数:3

oracle select方法条件(最新版2篇)目录(篇1)1.Oracle SELECT 方法概述2.SELECT 方法的条件3.查询示例正文(篇1)【Oracle SELECT 方法概述】Oracle SELECT 方法是 Oracle 数据库查询语言中最基本的查询方法,用于从数据库表中检索数据。
它可以帮助用户获取所需的数据,以便进行分析和处理。
【SELECT 方法的条件】在使用 Oracle SELECT 方法时,我们需要添加一些条件来限制查询结果。
这些条件通常包括:- 表名:指定要从哪个表中检索数据。
- 选择列名:指定要查询的列,可以查询单列或多列。
- 查询条件:可选项,用于限制查询结果,例如 WHERE 子句。
【查询示例】下面是一个简单的查询示例,假设我们有一个名为“employees”的表,其中包含员工的信息,如下所示:```SELECT * FROM employees WHERE department = "HR";```这个查询将返回所有部门为“HR”的员工信息。
【总结】Oracle SELECT 方法是查询数据库表的基本方法。
通过添加表名、选择列名和查询条件,我们可以实现对数据库表的精确查询。
目录(篇2)1.Oracle Select 方法概述2.Oracle Select 方法的条件3.Oracle Select 方法的应用示例正文(篇2)【1.Oracle Select 方法概述】Oracle Select 方法是 Oracle 数据库查询语言中最常用的方法之一,用于从数据库表中检索数据。
它可以帮助用户获取所需的数据,以便进行数据分析和处理。
Select 方法具有灵活性和强大性,可以根据不同的条件来检索数据。
【2.Oracle Select 方法的条件】在使用 Oracle Select 方法时,我们可以通过设置不同的条件来筛选和检索数据。
以下是一些常用的条件:(1)WHERE 子句:WHERE 子句用于指定查询结果的范围,可以根据指定的列和操作符来筛选数据。

select 用法摘要:一、select 语句的基本概念1.select 语句的作用2.select 语句的语法结构二、select 语句的执行流程1.查询分析2.数据获取3.结果排序和返回三、select 语句的子句1.投影子句2.选择子句3.排序子句4.分组子句5.limit 子句四、select 语句的应用实例1.查询表中所有数据2.查询指定列数据3.查询满足条件的数据4.查询排序后的数据5.查询分组后的数据正文:一、select 语句的基本概念select 语句是关系型数据库中的一种数据查询语句,用于从数据库表中获取所需的数据。
通过select 语句,用户可以根据需要选择表中的某一列或多列数据,以及对数据进行排序、分组等操作。
二、select 语句的执行流程select 语句的执行流程主要包括查询分析、数据获取、结果排序和返回三个步骤。
首先,数据库系统会对select 语句进行查询分析,解析出select 语句中的各个子句。
然后,根据子句内容,从数据库表中获取所需的数据。
最后,对获取的数据进行排序和返回,将结果返回给用户。
三、select 语句的子句select 语句包含多个子句,分别为投影子句、选择子句、排序子句、分组子句和limit 子句。
投影子句用于指定需要查询的列;选择子句用于指定需要查询的行;排序子句用于对查询结果进行排序;分组子句用于对查询结果进行分组;limit 子句用于限制查询结果的数量。
四、select 语句的应用实例select 语句在实际应用中有很多场景。
例如,可以使用select 语句查询表中的所有数据;可以使用select 语句查询指定列的数据;可以使用select 语句查询满足某个条件的数据;可以使用select 语句查询排序后的数据;可以使用select 语句查询分组后的数据等。

Oracle数据库基础知识:SELECT语句Oracle数据库基础知识:SELECT语句SELECT语句是指用来查询、添加、和删除数据库中数据的语句, 和删除数据库中数据的语句 , 它们是 SELECT 、 INSERT 、 UPDATE 、DELETE等. 下面是Oracle数据库基础知识——SELECT语句,希望对大家有所帮助!普通用户连接conn scott/tiger超级管理员连接conn “sys/sys as sysdba”Disconnect 断开连接把SQL存到文件 save c:\1.txtEd c:\1.txt编辑SQL语句@c:\1.txt运行SQL语句Desc emp描述EMP结构Select * from tab 查看该用户下大所有对象Show user显示当前用户书写SQL语句的原则大小写不敏感,但单引和双引内的大小写是敏感的。
切记!关键字不能缩写可以分行书写,但关键字不能被跨行书写,单引内也不要跨行书写。
一般每个子句是一行可以排版来增加可读性字符串用单引列的别名用双引SELECT语句1、简单的Select语句Select * from table 不指定查询的字段Select attr1,attr2 from table指定查询某些字段Select attr1,attr2 from table where attr1=xxx查询符合条件的指定字段2、使用算术表达式 + - / *表达式的运算是有优先级的,和程序中的.一样,先乘除后加减,括号强制优先级.+ - * /先乘除,后加减,括号强制优先级Select ename,12*sal+300 from emp;Select ename,12*(sal+300) from emp;3、连接运算符 ||4、使用字段别名 as别名的使用原则1。
区分同名列的名称2。
非法的表达式合法化3。
按照你的意愿显示列的名称4。
特殊的别名要双引5。

数据库select语言1.什么是数据库selec t语言?数据库s el ec t语言是指在关系型数据库中用于查询数据的语言。
通过使用s el ec t语句,我们可以从数据库中检索出符合特定条件的数据,进而对数据进行分析、处理或展示。
2. se lect语句的基本语法和用法s e le ct语句由关键字"SE LE CT"、"F ROM"和"WH ER E"等组成,以下是其基本语法:S E LE CT co lu mn1,col u mn2,...F R OM ta bl e_na meW H ER Ec on di ti on;-`SE LE CT`关键字用于指定要选择的列。
可以选择特定的列或使用通配符*选择所有列。
-`FR OM`关键字用于指定要从中选择数据的表。
-`WH ER E`关键字用于指定条件,从而筛选出符合特定条件的数据。
例如,我们可以使用以下se le ct语句从名为"s tu de nt s"的表中选择所有列:S E LE CT*F R OM st ud en ts;3. se lect语句的高级用法3.1过滤结果在s el ec t语句中,我们可以使用`W HE RE`子句来过滤结果,只选择满足特定条件的数据。
条件可以是比较运算符(如等于、大于、小于等)、逻辑运算符(如A ND、O R)以及其他一些特定的过滤器。
以下是一些常见的过滤器示例:-等于:`c ol um n=va l ue`-小于等于:`c ol umn<=v al ue`-包含某个值:`co lu m nI N('v al ue1','v a lu e2',...)`-不包含某个值:`co l um nN OT IN('va lue1','v al ue2',...)`3.2排序结果我们可以使用`O RD ER B Y`子句对查询结果进行排序。


2016-04-05SELECT语句的基本语法格式如下:SELECT<输出列表>[ INTO<新表名>]FROM<数据源列表>[ WHERE <查询条件表达式> ][GROUP BY <分组表达式> [HA VING<过滤条件> ] ][ ORDER BY <排序表达式> [ ASC | DESC ] ]|(竖线)分隔括号或大括号中的语法项。
只能选择其中一项。
[ ](方括号)可选语法项。
不要键入方括号。
< >(小括号)必选语法项。
不要键入小括号。
参数说明如下:SELECT子句用于指定所选择的要查询的特定表中的列,它可以是星号(*)、表达式、列表、变量等。
INTO子句用于指定所要生成的新表的名称。
FROM子句用于指定要查询的表或者视图,最多可以指定个表或者视图,用逗号相互隔开。
WHERE子句用来限定查询的范围和条件。
GROUP BY子句是分组查询子句。
HA VING子句用于指定分组子句的条件。
GROUP BY子句、HA VING子句和集合函数一起可以实现对每个组生成一行和一个汇总值。
ORDER BY子句可以根据一个列或者多个列来排序查询结果。
在SELECT语句中,可以在SELECT子句中选择指定的数据列、改变列标题、执行数据运算、使用ALL关键字、使用DISTINCT关键字等。
-----------------------------------------------------------------------------------------------------------1.查询所有的列。
SELECT语句中使用使用*表示查询所有列。
--【例-1】查询所有学生的信息。
SELECT*FROM students--2.查询指定的列。
选择部分列并指定它们的显示次序,选择的列名必须存在,但列名称之间的顺序既可以与表中定义的列顺序相同,也可以不相同。

select dname "工资" from dept;--查询全部员工select * from emp;--查询指定的编号,姓名和职位select empno,ename,job from emp;--修改显示别名空格,数字和特殊符号(#$除外)做别名需要双引号select empno as "1" ,ename 员工姓名,job "职位" from emp;--去除重复行select distinct job from emp;--列拼接select concat(concat(concat(concat(concat(' 编号是:',empno ),'的雇员,姓名是:'),ename) ,'工作是:'),job) from emp;--oracle用简单办法||拼接select '编号:' || empno || '的雇员,姓名是:' || ename || ',工作是:' || job from emp;--使用nvl (v1,v2)处理空值v1不为空返回,v2为空返回v2select ename,sal,comm,sal*12 + nvl (comm,0) from emp;--使用decodeselect ename,sal,comm,sal*12 + decode(comm,null,0,comm)from emp;--单行单列虚拟表dualselect sysdate from dual--得到一个32位的唯一guidselect sys_guid() from dual;--进行加减乘除运算select 1+3 from dual--oracle条件语句查询--查询出基本工资大于2000的所有雇员信息select * from emp where sal > 2000;--查询职位是办事员的所有雇员信息select * from emp where job ='CLERK'--查询工资在2000-3000之间的员工信息select * from emp where sal>2000 and sal < 3000;--查询工资在2000-3000之间的全部雇员信息*(包含)select * from emp where sal >= 2000 and sal <=3000;select * from emp where sal between 2000 and 3000;--查询职位是办事员或者销售人员的全部信息select * from emp where job='CLERK' or job='SALESMAN';select * from emp where job in ('CLERK','SALESMAN');--查询所用不是办事员的雇员信息select * from emp where job <>'CLERK';select * from emp where job != 'CLERK';select * from emp where not job = 'CLERK';--查询所有某段时间内入职的员工信息select * from emp where hiredate between to_date('1981/1/1','yyyy/mm/dd') and to_date('1982/1/1','yyyy/mm/dd');--查询所有有奖金的雇员select * from emp where comm is not null;--查询所有没有奖金的雇员select * from emp where comm is null;--查询出员工编号为7369.7499,7521的信息select * from emp where empno =7369 or empno=7499;select * from emp where empno in (7369,7499,7521)--查询出员工编号不为7369.7499,7521的信息select * from emp where empno not in (7369,7499,7521);--查询员工姓名中以字母A为开头的全部员工信息select ename from emp where ename like 'A%';--查询员工姓名中第二个字母是A的全部员工信息select ename from emp where ename like '_A%';--查询员工姓名中有A的全部员工信息select ename from emp where ename like '%A%';--oracle结果排序--查询所有员工,并按照要求工资升序排序select * from emp order by sal;--查询所有员工,并按照要求工资升序排序select * from emp order by sal desc;--按照工资从高到低排序,如果工资相同,则按照雇佣时间先后排序select * from emp order by sal desc, hiredate;--排序中的空值问题select * from emp order by comm desc;select * from emp order by comm desc nulls first;select * from emp order by comm desc nulls last;--oracle单行函数--字符函数--字符串大写upperselect upper('mingming')from dual;--字符串小写lowerselect lower(ename) from emp;--首字符大写initcapselect initcap(ename) from emp;--字符串取长度lengthselect ename,length(ename) from emp;--字符串替换replaceselect ename,replace(ename,'A','#')from emp;--字符串截取substrselect ename,substr(ename,0,2) from emp; select ename,substr(ename,1,2) from emp;select ename,substr(ename,-1) from emp;select ename,substr(ename,-2,1) from emp; select ename,substr(ename,-2,3) from emp;--两边去掉空格trimselect ename,trim(ename) from emp;--数字函数--四舍五入select round(987.6543) from dual;--988select round(987.6543,0) from dual;--988select round(987.6543,1) from dual;--987.7 select round(987.6543,2) from dual;--987.65 select round(987.6543,-1) from dual;--990select round(987.6543,-2) from dual;--1000--trunc舍弃内容select trunc(953.6286) from dual; --953select trunc(953.6286,0) from dual;--953select trunc(953.6286,1) from dual;--953.6select trunc(953.6286,2) from dual;--953.62 select trunc(953.6286,-1) from dual;--950select trunc(953.6286,-2) from dual--900--取模mod /余数select mod(10,3) from dual;--日期函数--获取当前时间sysdateselect sysdate from dual;--表示几天之后的日期+dayselect sysdate+3 from dual;--两个日期之间的天数差sysdate-hiredate select ename,hiredate,sysdate-hiredate from emp ; select trunc(sysdate-hiredate) from emp ;--本月的最后一天日期last_dayselect last_day(sysdate) from dual;--两个日期键的月份差months_betweenselect ename,hiredate ,trunc(MONTHS_BETWEEN(sysdate,hiredate)) from emp;--求出四个月后的日期add_montsselect add_months(sysdate,2)from dual;--转换函数--日期变为字符串to_char*(mi,hh24,yyyy,day)select to_char(sysdate,'yyyy-mm-dd')from dual;--2017-11--12select to_char(sysdate,'yyyy-mm-dd hh:mi:ss')from dual;--2017-11-12 05:07:00--数字变为字符串to_char(L999,999,999)数字代表长度SELECT TO_CHAR(89078907890,'L9999,9999,9999,9999') FROM dual;-- $89,078,907,890--字符串转日期to_date(yyyy-mm-dd hh:mi:ss)--字符串必须是日期格式的字符串select to_date('2017-11-12','yyyy/mm/dd') from dual;--2017/11/12--字符串转数字to_number('123'+4)select to_number('123'+4) from dual--127--通用函数--nvl(v1,v2)处理null 如果第一个数为null返回第二个数,如果第一个数不为空返回第一个数select nvl(1,2)from dual;--1select nvl(null,2) from dual;--2--nvl(v1,v2,v3)处理null; 如果v1为null返回v3,否则返回v2select nvl2(null,1,2) from dual;select nvl2(3,1,2) from dual;--decode()多值判断DECODE(数值| 列,判断值1,显示值1,判断值2,显示值2,判断值3,显示值3,…)--将职位信息转为汉字SELECT empno,ename,job,DECODE(job,'CLERK','办事员','SALESMAN','销售人员','MANAGER','经理','ANALYST','分析员','PRESIDENT','总裁')FROM emp;--case when条件判断--将职位信息转为汉字select empno,ename,job,case jobwhen 'CLERK' then'业务员'when 'SALESMAN' then'销售人员'else'其他'endfrom emp;--oracle多行函数分组函数作用于一组数据,并对一组数据返回一个值--统计记录数count() 查询出所有员工的记录数select count(*) from emp;--不建议使用count(*),可以使用一个具体的列以免影响性能select count(empno) from emp;--最小值查询min()查询出来员工最低工资select min(sal) from emp;--最大值查询max()查询出来员工最高工资select max(sal) from emp;--查询平均值avg()查询出员工的平均工资select avg(sal) from emp;--求和函数sum()查询出某部门额员工工资总和select sum(sal) from emp where deptno=20;--分组汇合统计group by--查询每个部分的人数select deptno,count(*) from emp group by deptno;--查询出每个部分的平均工资select deptno,avg(sal)from emp group by deptno;--唯一字段做分组select ename,count(*) from emp group by ename;--过滤分组数据having--查询部分平均工资大于2000的部门,用having和where都可以实现select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;--第二天多表查询--笛卡尔集select * from emp,dept;--内连接--隐式内连接select e.empno,e.ename,e.job,d.dname from emp e,dept d where e.deptno = d.deptno;--显示内连接select e.empno,e.ename,e.job,d.dname from emp e inner join dept d on e.deptno =d.deptno; --左外连接select * from dept left join emp on dept.deptno = emp.deptno;--右外连接select * from emp e right join dept d on e.deptno=d.deptno;--oracle特有外连接--使用符号(+):放在作为补充显示的列后面select * from emp,dept where emp.deptno(+)=dept.deptno;--自连接--查询出员工的姓名,职位,领导姓名select * from emp a,emp b where a.mgr=b.empno;--使用左右外连接,找到没有领导的员工select * from emp a,emp b where a.mgr=b.empno(+);--多表联查--查询员工姓名,部门名称,领导姓名select e1.ename,e2.ename,d.dname from emp e1,emp e2,dept d where e1.mgr=e2.empno and e1.deptno=d.deptno;--查询员工姓名,部门名称,领导名称,员工工资等级select e1.ename,e2.ename,d.dname,s.grade from emp e1,emp e2,dept d,salgrade s where e1.mgr=e2.empno and e1.deptno=d.deptno and e1.sal between s.losal and s.hisal;--查询员工姓名、部门名称、领导名称、员工工资等级、领导工资等级select e1.ename, e2.ename, d.dname, s1.grade,s2.gradefrom emp e1, emp e2, dept d, salgrade s1,salgrade s2where e1.mgr = e2.empnoand e1.deptno = d.deptnoand e1.sal between s1.losal and s1.hisaland e1.sal between s2.losal and s2.hisal;--将工资等级转换为汉字select e1.ename, e2.ename, d.dname, decode(s1.grade,'1','第五级','2','第四级','3','第三级','4','第二级' ,'5','第一级'),decode(s2.grade,'1','第五级','2','第四级','3','第三级','4','第二级' ,'5','第一级')from emp e1, emp e2, dept d, salgrade s1,salgrade s2where e1.mgr = e2.empnoand e1.deptno = d.deptnoand e1.sal between s1.losal and s1.hisaland e1.sal between s2.losal and s2.hisal;--子查询--单行子查询(单行单列)--查询比员工7654工资高,并和7788相同职位的员工select e.ename from emp e where e.sal>(select sal from emp where empno=7654)and e.job=(select job from emp where empno =7788)Select * from emp where sal>(Select sal from emp where empno=7654)And job = (Select job from emp where empno=7788)--子查询放在select中--查询员工信息和部门名称select e.* ,(select d.dname from dept d where d.deptno=e.deptno)from emp e ;--多行子查询(多行多列和多行单列)--多行多列子查询实现--查询每个部门的最低工资,和最低工资的员工select e.ename,e.sal,d.dname from emp e,(select deptno ,min(sal) sal from emp group by deptno) dm,dept d where e.deptno = d.deptno and e.deptno = dm.deptno and e.sal= dm.sal;Select e.ename,e.sal,d.dnameFrom emp e,(Select deptno,min(sal) sal from emp group by deptno) dm,dept dWhere e.deptno=d.deptno and e.deptno=dm.deptno And e.sal = dm.sal--多行单列子查询实现--查询是领导的所有员工信息select * from emp where emp.empno in(select mgr from emp e where e.mgr is not null);--查询不是领导的所有员工信息select * from emp where empno not in (select nvl(mgr,0) from emp)--exists--判断结果集是否存在exists(sql语句)--用来判断结果集是否存在,如果存在返回true,如果不存在返回falseselect * from emp where exists (select * from dept)--查询有员工的部门select * from dept where deptno in (select deptno from emp where deptno is not null)select * from dept d where exists (select deptno from emp e where e.deptno= d.deptno )--查询是领导的所有的员工信息select * from emp e1 where exists (select e2.mgr from emp e2 where e2.mgr= e1.empno)--伪列rownumselect rownum, e.* from emp e;--查询员工信息的前三条select rownum, e.* from emp e where rownum<4;--排序后rownum乱序select rownum ,e.* fROM emp e where rownum<20 order by sal desc ;--解决办法,先排序再生成rownumselect * from emp order by sal desc;select rownum ,e.* from (select * from emp order by sal desc)e where rownum <4;select * from(Select rownum rm, t.* from (select * from emp order by sal desc) t) where rm<4--找到员工表中薪水大于本部门平均薪水的员工--本部门平均薪水select deptno,avg(sal) from emp group by deptno;select * from emp e,(select deptno,avg(sal)avs from emp group by deptno)m where e.sal>m.avs and e.deptno=m.deptno;--统计每年入职的员工个数select to_char(e.hiredate,'yyyy')hire_year,count(*) from emp e group by to_char(hiredate,'yyyy');SelectSum(hire_count) total,sum(decode(t.hire_year,'1980',t.hire_count)) "1980",sum(decode(t.hire_year,'1981',t.hire_count)) "1981",sum(decode(t.hire_year,'1982',t.hire_count)) "1982",sum(decode(t.hire_year,'1987',t.hire_count)) "1987"from(Select to_char(hiredate,'yyyy') hire_year,count(*) hire_countFrom emp group by to_char(hiredate,'yyyy')) trowidRowid是oracle数据库插入数据时给数据分配的真实物理地址,唯一不变Rownum 是伪列,在查询数据时才会生成的临时数值--集合运算--并集--查询工资大于1500或是20号部分的员工select * from emp where sal>1500 or deptno=20;--union实现select * from emp where sal>1500unionselect * from emp where deptno =20;--union all实现(没有去重)select * from emp where sal>1500union allselect * from emp where deptno =20;--交集*(intersect 取两个集合共同的部分)select * from emp where sal >1500 and deptno=20;select * from emp where sal >1500intersectselect * from emp where deptno=20;--差集(minus 从一个集合中去掉另一个集合剩余的部分)--1981年入职的普通员工,不包含总裁和经理select * from emp where to_char(hiredate,'yyyy')='1981'and job not in ('MANAGER','PRESIDENT')select * from emp where to_char(hiredate,'yyyy')='1981'minusselect * from emp where job in ('MANAGER','PRESIDENT')。

达内学习心得:Oracle_11g常用SQL语句(高级工程师必备)参赛学员:吴贤志获奖奖项:三等奖-- 退出SQLPLUSexit;-- 修改system(sys) 账号密码SQLPLUS /NOLOGCONN /AS SYSDBAALTER USER SYSTEM IDENTIFIED BY tarring;-- 清除SQLPLUS 屏幕CLEAR SCREEN;CL SCR;-- 查看数据文件位置SELECT NAME FROM v$datafile;-- 查看控制文件位置SELECT NAME FROM v$controlfile;-- 查看日志文件位置SELECT MEMBER FROM v$logfile;-- 建立表空间CREATE TABLESPACE ts01DA TAFILE 'D:\DataBase\Oracle11g\oradata\orcl\test_db01.dbf'SIZE 100M AUTOEXTEND ON NEXT 100M MAXSIZE 1024MDEFAULT STORAGE(INITIAL 10m NEXT 1M)PERMANENTONLINELOGGING;-- 修改表空间ALTER TABLESPACE ts01NOLOGGING;-- 表空间增加数据文件ALTER TABLESPACE ts01ADD DATAFILE 'D:\DataBase\Oracle11g\oradata\orcl\test_db02.dbf'SIZE 100M REUSE AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED;-- 删除表空间DROP TABLESPACE ts01;-- 删除表空间同时删除数据文件DROP TABLESPACE ts01 INCLUDING CONTENTS AND DATAFILES;-- 表空间中建表CREATE TABLE student(student_id V ARCHAR2(10),student_name V ARCHAR2(20))TABLESPACE ts01;-- 查看表所属表空间SELECT TABLE_NAME, TABLESPACE_NAME FROM tabs WHERE TABLE_NAME = 'STUDENT';-- 查看表结构DESCRIBE student;DESC student;-- 增加表注释COMMENT ON TABLE student IS '学生信息表';-- 查看表注释SELECT * FROM USER_TAB_COMMENTS WHERE TABLE_NAME = 'STUDENT'; SELECT * FROM ALL_TAB_COMMENTS WHERE TABLE_NAME = 'STUDENT';-- 表字段增加注释COMMENT ON COLUMN STUDENT.STUDENT_ID IS '学生编号';-- 查看表字段注释SELECT * FROM USER_COL_COMMENTS WHERE TABLE_NAME = 'STUDENT'; SELECT * FROM ALL_COL_COMMENTS WHERE TABLE_NAME = 'STUDENT';-- 查看用户所有表SELECT * FROM User_Tables;-- 查看用户拥有的所有对象SELECT * FROM User_Objects;-- 查看用户拥有的表试图序列SELECT * FROM User_Catalog;-- 表字段修改ALTER TABLE student MODIFY(student_id CHAR(15));-- 表字段增加ALTER TABLE STUDENT ADD(AGE NUMBER(2));-- 删除表字段ALTER TABLE STUDENT DROP COLUMN student_name;-- 修改表名称RENAME STUDENT TO STU;-- 删除表DROP TABLE STUDENT;CREATE TABLE student(s_id Varchar2(10),s_name varchar2(20),s_age Number(3),s_birthday DATE)TABLESPACE ts01;-- 增加一条记录INSERT INTOstudent (s_id, s_name, s_age, s_birthday)V ALUES ('S000000001', 'Tarring01', 10, to_date('1982-10-06','yyyy-mm-dd'));INSERT INTOstudent (s_id, s_name, s_age, s_birthday)V ALUES ('S000000002', 'Tarring02', 10, Sysdate);-- 使用替代变量时,输入字符串字段时一样要写上引号INSERT INTOstudent (s_id, s_name, s_age, s_birthday)V ALUES (&s_id, &s_name, 10, Sysdate);-- 修改记录UPDATE student SET s_name = '陶川', s_age = 20 WHERE s_id = 'S000000002';-- 删除记录DELETE FROM student WHERE s_id = 'S000000002';-- 截断表TRUNCATE TABLE student;-- 事务处理COMMIT; -- 提交事务INSERT INTO student (s_id, s_name) V ALUES ('S001', 'tarring1');ROLLBACK; -- 回滚,回滚到上一次提交过后的点-- 带恢复点的事务COMMIT;INSERT INTO student (s_id, s_name) V ALUES ('S001', 'tarring1');SA VEPOINT firstdate;INSERT INTO student (s_id, s_name) V ALUES ('S002', 'tarring2');SA VEPOINT seconddate;DELETE FROM student;ROLLBACK TO firstdate;SELECT * FROM student;-- 约束条件说明---------------------------------------------------------------------- UNIQUE 指定字段的值,必须是唯一的-- PRIMARY KEY 主键,会为指定的字段作索引,并且也是唯一的值-- NOT NULL 不可以是空值【'' NULL】或0(零)-- CHECK 检查,必须符合指定的条件-- FOREIGN KEY 外键,用来创建一个参考表之间的关系-- 建表同时建立唯一约束CREATE TABLE student(s_id Varchar2(10),s_name varchar2(20),s_age Number(3),s_birthday DATE,CONSTRAINT s_name_uk UNIQUE(s_name))TABLESPACE ts01;-- 查看唯一约束SELECT table_name, constraint_name, constraint_type FROM User_Constraints WHERE table_name = 'STUDENT';-- 作业:数据字典【分类常用】-- 建表同时建立主键CREATE TABLE student(s_id Varchar2(10),s_name varchar2(20),s_age Number(3),s_birthday DATE,CONSTRAINT s_id_pk PRIMARY KEY (s_id))TABLESPACE ts01;-- 查看主键约束SELECT table_name, constraint_name, constraint_type FROM User_Constraints WHERE table_name = 'STUDENT';-- 建表同时建立非空字段CREATE TABLE student(s_id Varchar2(10),s_name varchar2(20) NOT NULL,s_age Number(3),s_birthday DATE,CONSTRAINT s_id_pk PRIMARY KEY (s_id))TABLESPACE ts01;INSERT INTO student (s_id, s_name) V ALUES ('S001', NULL); -- 插入一个null-- 查看非空约束SELECT table_name, constraint_name, constraint_type, search_condition FROM User_Constraints WHERE table_name = 'STUDENT';-- 建表同时建立检查CREATE TABLE student(s_id Varchar2(10),s_name varchar2(20),s_age Number(3),s_birthday DATE,CONSTRAINT s_age_ck CHECK (s_age BETWEEN 1 AND 100) -- 端点值可以使用)TABLESPACE ts01;-- 查看检查约束SELECT table_name, constraint_name, constraint_type, search_condition FROM User_Constraints WHERE table_name = 'STUDENT';-- 外键的使用CREATE TABLE team(t_id Varchar2(10),t_name Varchar2(20),CONSTRAINT t_id_pk PRIMARY KEY (t_id))TABLESPACE ts01;CREATE TABLE student(s_id Varchar2(10),team_id V ARCHAR2(10),s_name varchar2(20),CONSTRAINT s_id_pk PRIMARY KEY (s_id),CONSTRAINT s_team_id_fk FOREIGN KEY (team_id) REFERENCES team(t_id))TABLESPACE ts01;-- 查看表的外键约束SELECT table_name, constraint_name, constraint_type FROM User_Constraints WHERE table_name = 'STUDENT';drop table team; -- 被引用表是不能删除的insert into team (t_id, t_name) values ('t001', 'lansene');insert into student(s_id, s_name, team_id) values ('s001','tarring', 't001');delete from team; -- 被引用的记录是不能删除的-- 关闭一个约束ALTER TABLE student DISABLE CONSTRAINT s_team_id_fk;-- 启用一个约束ALTER TABLE student ENABLE CONSTRAINT s_team_id_fk;-- 删除一个约束ALTER TABLE student DROP CONSTRAINT s_team_id_fk;-- 已创建的表增加一个约束ALTER TABLE student ADD CONSTRAINT s_team_id_fk FOREIGN KEY (team_id) REFERENCES team(t_id);/****************************************************************************** **************|| SQL语句5大类型| 命令| 说明||****************************************************************************** **************|| Data Retrieval数据检索| select | 查询记录||****************************************************************************** **************|| Date Manipulation Language【DML】数据操纵语言| insert | 添加记录|| | update | 修改记录|| | delete | 删除记录|****************************************************************************** **************|| Data Definition Language【DDL】数据定义语言| create | 创建|| | alter | 修改|| | drop | 丢弃【删除】|| | rename | 重命名|| | truncate | 截断||****************************************************************************** **************|| Transaction Control事务控制| commit | 确认命令|| | rollback | 回退至前一次确认的命令或保存点|| | savepoint | 设置保存点||****************************************************************************** **************|| Data Control Language【DCL】数据控制语言| grant | 授予权限|| | revoke | 撤消权限||****************************************************************************** **************//*************************************|| 系统权限| 说明||*************************************|| create session | 连接数据库||*************************************|| create table | 创建表||*************************************|| create sequence | 创建序列||*************************************|| create view | 创建视图||*************************************|| create proceduer | 创建程序||*************************************//*******************************************************************|| \ 对象| 表【table】| 视图【view】| 程序【procedure】|| 权限\ | | | ||*******************************************************************|| insert | Y | Y | ||*******************************************************************|| alter | Y | | ||*******************************************************************|| update | Y | Y | ||*******************************************************************|| delete | Y | Y | ||*******************************************************************|| select | Y | Y | ||*******************************************************************|| index | Y | | ||*******************************************************************|| execute | | | Y ||*******************************************************************/-- 创建用户CREATE USER u01 IDENTIFIED BY p01;-- 创建用户并制定默认表空间CREATE USER u01 IDENTIFIED BY p01 DEFAULT TABLESPACE QUOTA 2M ON ts01; --quota 表空间中可使用的配额-- 修改用户密码ALTER USER u01 IDENTIFIED BY p001;-- 修改用户表空间配额ALTER USER u01 QUOTA 20M ON ts01;ALTER USER u01 QUOTA UNLIMITED ON ts01; -- 用户对表空间没有配额限制-- 回收unlimited tablespace权限REVOKE UNLIMITED TABLESPACE FROM ts01;-- 删除用户DROP USER u01;-- 切换连接数据库的用户CONNECT u01/p01;conn u01/p01;-- 授权用户连接数据库的权限GRANT CREATE SESSION TO u01;-- 授权用户创建序列(sequence)的权限GRANT CREATE sequence TO u01;-- 授权用户创建表的权限GRANT CREATE TABLE TO u01;--授权用户查表的权限grant select on er1 to wangkai;--授权用户修改表的权限grant alter on user1 to wangkai;--授权用户删除表的权限(没有此权限)grant drop on user1 to wangkai;(错误)--授权用户对一个表的所有权限grant all on user1 to wangkai;--授权所有用户对一个表的所有权限grant all on user1 to public;-- 收回用户创建表的权限REVOKE CREATE TABLE FROM u01;-- 收回用户查表的权限REVOKE select on user1 FROM u01;-- 收回用户修改的权限REVOKE select on user1 FROM u01;-- 收回用户对一个表的所有权限revoke all on user1 from wangkai;--收回所有用户对一个表的所有权限revoke all on user1 to public;-- 创建角色CREATE ROLE r01;-- 角色授权GRANT CREATE SESSION, CREATE TABLE TO r01;-- 收回角色权限REVOKE CREATE TABLE FROM r01;-- 查看角色权限SELECT ROLE,PRIVILEGE FROM role_sys_privs WHERE ROLE='R01' -- 角色赋给用户GRANT r01 TO u01;-- 查看当前用户角色SELECT * FROM user_role_privs;-- 删除角色DROP ROLE r01;。

oracle select 1的用法Oracle Select 1的用法Oracle Select语句是用来从数据库中选取数据的最基本的命令。
在Oracle中,可以使用Select 1语句来进行一些常见的操作和查询。
本文将详细讲解一些Oracle Select 1的常见用法。
1. 查询表中的所有记录使用Select 1语句可以查询表中的所有记录,下面是一个示例:SELECT * FROM 表名;2. 查询表中的特定字段如果只想查询表中的特定字段,可以使用以下示例代码:SELECT 字段1, 字段2 FROM 表名;3. 查询并排序如果想按照某个字段对查询结果进行排序,可以使用以下示例代码:SELECT * FROM 表名 ORDER BY 字段 ASC/DESC;这里的ASC表示按照升序排序,DESC表示按照降序排序。
如果只想查询满足某些条件的记录,可以使用以下示例代码:SELECT * FROM 表名 WHERE 条件;其中,条件可以是任何合法的表达式,比如:•字段 = 值•字段 > 值•字段LIKE ‘值’5. 连接查询在多表查询时,可以使用Select 1语句进行连接查询。
下面是一个简单的示例:SELECT * FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;这里使用了INNER JOIN关键字进行内连接查询,通过ON子句指定连接条件。
6. 聚合查询如果想对查询结果进行聚合计算,可以使用以下示例代码:SELECT COUNT(*) FROM 表名;这里的COUNT函数用于计算记录数,还可以使用其他聚合函数如SUM、AVG等。
需要根据某个字段进行分组,并对每个分组执行聚合计算时,可以使用以下示例代码:SELECT 字段, SUM(字段1) FROM 表名 GROUP BY 字段;这里使用了GROUP BY子句对字段进行分组,并使用SUM函数对字段1进行求和计算。
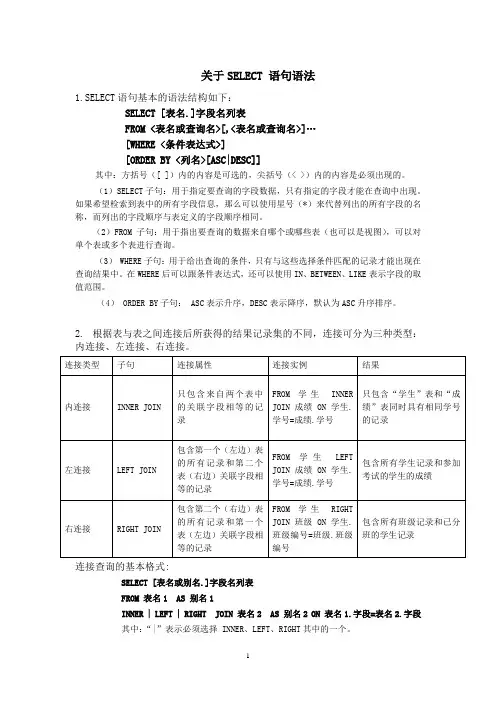
关于SELECT 语句语法1.SELECT语句基本的语法结构如下:SELECT [表名.]字段名列表FROM <表名或查询名>[,<表名或查询名>]…[WHERE <条件表达式>][ORDER BY <列名>[ASC|DESC]]其中:方括号([ ])内的内容是可选的,尖括号(< >)内的内容是必须出现的。
(1)SELECT子句:用于指定要查询的字段数据,只有指定的字段才能在查询中出现。
如果希望检索到表中的所有字段信息,那么可以使用星号(*)来代替列出的所有字段的名称,而列出的字段顺序与表定义的字段顺序相同。
(2)FROM子句:用于指出要查询的数据来自哪个或哪些表(也可以是视图),可以对单个表或多个表进行查询。
(3) WHERE子句:用于给出查询的条件,只有与这些选择条件匹配的记录才能出现在查询结果中。
在WHERE后可以跟条件表达式,还可以使用IN、BETWEEN、LIKE表示字段的取值范围。
(4) ORDER BY子句: ASC表示升序,DESC表示降序,默认为ASC升序排序。
2.根据表与表之间连接后所获得的结果记录集的不同,连接可分为三种类型:内连接、左连接、右连接。
连接查询的基本格式:SELECT [表名或别名.]字段名列表FROM 表名1 AS 别名1INNER | LEFT | RIGHT JOIN 表名2 AS 别名2 ON 表名1.字段=表名2.字段其中:“|”表示必须选择 INNER、LEFT、RIGHT其中的一个。
3.如果连接的表多于两个,则需要使用嵌套连接,其格式为:SELECT [表名或别名.]字段名列表FROM 表名1 AS 别名1 INNER JOIN (表名2 AS 别名2 INNER JOIN 表名3 AS 别名3 ON 表名2.字段=表名3.字段)ON表名1.字段=表名2.字段4.分组统计的基本格式为:SELECT [表名.]字段名列表 [AS 列标题]FROM <表名>GROUP BY 分组字段列表 [HAVING 查询条件]。

SELECT语句参数详解1.列参数:用于指定查询返回的列。
可以是具体的列名,也可以是通配符"*"表示返回所有列。
例如:SELECT column1, column2 FROM table;2.表参数:用于指定查询的表。
可以是单个表名,也可以是多个表名组合的JOIN表。
例如:SELECT * FROM table1, table2;3.条件参数:用于指定查询的条件。
常用的条件操作符包括等于(=)、不等于(!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、LIKE、IN等。
例如:SELECT * FROM table WHERE condition;4.排序参数:用于指定查询结果的排序方式。
可以使用ORDERBY子句,并指定一个或多个列名以及排序顺序(升序ASC或降序DESC)。
例如:SELECT * FROM table ORDER BY column DESC;5.分组参数:用于对查询结果进行分组,并进行聚合计算。
可以使用GROUPBY子句,并指定一个或多个列名。
例如:SELECT column, COUNT(*) FROM table GROUP BY column;6.聚合参数:用于对查询结果进行聚合计算,常用的聚合函数包括COUNT、SUM、AVG、MIN、MAX等。
例如:SELECT COUNT(*) FROM table;7.限制参数:用于限制查询结果的返回行数。
可以使用LIMIT子句,并指定返回的行数和起始位置。
例如:SELECT * FROM table LIMIT 10;以上是常用的SELECT语句的参数。
根据具体的需求,还可以使用其他参数和子句来进行高级的查询操作。
select语句的定义Select语句是SQL语言中用于从数据库中检索数据的关键部分。
通过使用不同的条件和参数,可以筛选出满足特定要求的数据集合。
下面将介绍一些常见的select语句及其用法:1. 基本的select语句:```sqlSELECT column1, column2FROM table_name;```这是最基本的select语句,用于选择指定表中的指定列。
可以通过逗号分隔的方式选择多个列。
如果要选择表中的所有列,可以使用星号代替列名。
2. 使用WHERE子句进行条件筛选:```sqlSELECT column1, column2FROM table_nameWHERE condition;```在WHERE子句中可以指定条件,只有满足条件的行会被返回。
条件可以包括比较操作符(如=、>、<)、逻辑操作符(如AND、OR)和通配符(如LIKE)等。
3. 使用DISTINCT关键字去除重复行:```sqlSELECT DISTINCT column1, column2FROM table_name;```DISTINCT关键字用于去除结果集中重复的行,保留每行的唯一性。
可以应用于一个或多个列。
4. 使用ORDER BY关键字对结果排序:```sqlSELECT column1, column2FROM table_nameORDER BY column1 ASC, column2 DESC;```ORDER BY关键字用于对结果进行排序,默认为升序(ASC),也可以指定降序(DESC)。
可以根据一个或多个列进行排序。
5. 使用LIMIT关键字限制返回行数:```sqlSELECT column1, column2FROM table_nameLIMIT 10;```LIMIT关键字用于限制返回的行数,可以指定返回的起始行和数量,也可以仅指定数量。
6. 使用GROUP BY关键字进行分组:```sqlSELECT column1, COUNT(*)FROM table_nameGROUP BY column1;```GROUP BY关键字用于对结果集进行分组,通常与聚合函数一起使用,如COUNT、SUM、AVG等。
数据库基本select数据库基本 SELECT在当今数字化的时代,数据库成为了各类信息系统的核心组件,而“SELECT”语句则是我们从数据库中获取所需数据的关键工具。
无论是简单的查询操作,还是复杂的数据提取和分析,都离不开“SELECT”语句的灵活运用。
“SELECT”语句的基本语法看似简单,但其功能却十分强大。
它的一般形式是“SELECT 列名 FROM 表名”。
这里的“列名”指的是你想要获取的具体数据列,“表名”则是数据所在的表。
比如说,你有一个名为“students”的表,其中包含“id”、“name”、“age”等列。
如果你只想获取学生的姓名,那么你的“SELECT”语句就可以写成“SELECT name FROM students”。
当然,“SELECT”语句不仅仅能获取单个列的数据。
假设你想同时获取学生的姓名和年龄,只需要将列名用逗号分隔,像这样:“SELECT name, age FROM students”。
除了指定要获取的列,我们还可以使用“WHERE”子句来对数据进行筛选。
“WHERE”子句允许我们根据特定的条件过滤出符合要求的数据。
举个例子,如果我们只想获取年龄大于 18 岁的学生的信息,那么语句就变成了“SELECT FROM students WHERE age >18”。
这里的“”表示获取所有的列。
在实际应用中,我们常常会遇到需要对数据进行排序的情况。
这时候就轮到“ORDER BY”子句登场了。
通过“ORDER BY”,我们可以按照指定的列对结果进行升序(ASC)或降序(DESC)排序。
比如,要按照学生的年龄从小到大排序结果,我们可以这样写:“SELECT FROM students ORDER BY age ASC”。
如果想要从大到小排序,只需要将“ASC”改为“DESC”即可。
另外,“SELECT”语句还支持使用聚合函数来对数据进行统计和计算。
常见的聚合函数包括“COUNT()”用于计算行数、“SUM()”用于求和、“AVG()”用于计算平均值、“MAX()”用于获取最大值以及“MIN()”用于获取最小值。
oracle select方法条件(原创实用版3篇)目录(篇1)1.oracle select方法条件2.oracle select方法条件3.或acle select方法条件4.或acle select方法条件5.或acle select方法条件正文(篇1)一、oracle select方法条件Oracle数据库中的SELECT语句可以用于从数据库中检索数据。
在SELECT语句中,可以使用条件来过滤结果集。
例如,可以使用WHERE子句来指定特定的条件,以返回符合要求的数据行。
此外,还可以使用其他关键字和函数来进一步筛选结果集,例如FROM、GROUP BY、HAVING和ORDER BY等关键字。
二、oracle select方法条件Oracle数据库中的SELECT语句可以用于从数据库中检索数据。
在SELECT语句中,可以使用条件来过滤结果集。
例如,可以使用WHERE子句来指定特定的条件,以返回符合要求的数据行。
此外,还可以使用其他关键字和函数来进一步筛选结果集,例如FROM、GROUP BY、HAVING和ORDER BY等关键字。
三、或acle select方法条件Oracle数据库中的SELECT语句可以用于从数据库中检索数据。
在SELECT语句中,可以使用条件来过滤结果集。
例如,可以使用WHERE子句来指定特定的条件,以返回符合要求的数据行。
此外,还可以使用其他关键字和函数来进一步筛选结果集,例如FROM、GROUP BY、HAVING和ORDER BY等关键字。
四、或acle select方法条件Oracle数据库中的SELECT语句可以用于从数据库中检索数据。
在SELECT语句中,可以使用条件来过滤结果集。
例如,可以使用WHERE子句来指定特定的条件,以返回符合要求的数据行。
此外,还可以使用其他关键字和函数来进一步筛选结果集,例如FROM、GROUP BY、HAVING和ORDER BY等关键字。
Oracle11g常⽤基本操作命令 这⾥是单实例数据库情况下:1、启动监听 启动监听,即启动1521监听端⼝号:lsnrctl start #启动监听lsnrctl stop #停⽌监听lsnrctl status #查看监听状态 监听端⼝1521修改:# su - oracle$ lsnrctl stop$ echo $ORACLE_HOME$ cd $ORACLE_HOME/network/admin$ vim listener.ora# listener.ora Network Configuration File: /home/data/oracle/product/11.2.0/db_1/network/admin/listener.ora# Generated by Oracle configuration tools.LISTENER =(DESCRIPTION_LIST =(DESCRIPTION =(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC6666))(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 6666))))ADR_BASE_LISTENER = /home/data/oracle直接在此处修改是不⽣效的,我们还需要修改local_listener参数$ sqlplus / as sysdbaSQL> show parameter local_listener #登录并查看local_listener参数//由于开始的时候使⽤的是默认值,这个时候VALUE这个值应该是空的,这⾥修改local_listener参数SQL> alter system set local_listener="(address = (protocol = tcp)(host = 10.10.16.245)(port = 6666))";SQL> show parameter local_listener #查看local_listener参数$ lsnrctl start #重新启动监听$ netstat -an|grep 6666 #查看状态$ lsnrctl status$ su - root #防⽕墙端⼝开放# /sbin/iptables -I INPUT -p tcp --dport 6666 -j ACCEPT# /etc/rc.d/init.d/iptables save#到此oracle的监听端⼝号就已经由原来的1521变成6666View Code2、启动数据库 启动数据库有两种⽅式,⼀种是登录sqlplus执⾏startup;另⼀种是使⽤dbstart //启动数据库脚本⽤oracle⽤户进⼊# su - oracle$ sqlplus /nolog #运⾏sqlplus命令,进⼊sqlplus环境,nolog参数表⽰不登录;SQL> conn /as sysdba #以管理员模式进⼊SQL > startup; #启动数据库SQL > SHUTDOWN IMMEDIATE #停⽌数据库远程连接数据库sqlplus /nologconn sys/sys@IP:1521/orainstance as sysdba也可以直接运⾏:dbstart //启动数据库脚本dbshut //停⽌数据库脚本3、⽤户管理 创建普通⽤户,权限相关:创建⽤户:SQL> create user "username" identified by "userpasswd" ; #注:后⾯可带表空间删除⽤户:SQL> drop user “username” cascade; #注:cascade 参数是级联删除该⽤户所有对象,经常遇到如⽤户有对象⽽未加此参数则⽤户删不了的问题,所以习惯性的加此参数授权⽤户:SQL> grant connect,resource,dba to "username" ;查看当前⽤户的⾓⾊SQL> select * from user_role_privs;SQL> select * from session_privs;查看当前⽤户的系统权限和表级权限SQL> select * from user_sys_privs;SQL> select * from user_tab_privs;查询⽤户表SQL> select username from dba_users;修改⽤户⼝令SQL> alter user "username" identified by "password";显⽰当前⽤户SQL> show user;4、表和表空间创建表空间SQL> CREATE TABLESPACE data01 DATAFILE '/oracle/oradata/db/DATA01.dbf' SIZE 500M;删除表空间SQL> DROP TABLESPACE data01 INCLUDING CONTENTS AND DATAFILES;修改表空间⼤⼩SQL> alter database datafile '/path/NADDate05.dbf' resize 100M;增加表空间SQL> ALTER TABLESPACE NEWCCS ADD DATAFILE '/u03/oradata/newccs/newccs04.dbf' SIZE 4896M;查询数据库⽂件SQL> select * from dba_data_files;查询当前存在的表空间SQL> select * from v$tablespace;表空间情况SQL> select tablespace_name,sum(bytes)/1024/1024 from dba_data_files group by tablespace_name;查询表空间剩余空间SQL> select tablespace_name,sum(bytes)/1024/1024 from dba_free_space group by tablespace_name;查看表结构SQL> desc table;修改连接数:要重启数据库SQL> alter system set processes=1000 scope=spfile;SQL> shutdown immediate;SQL> startup;查看⽤户当前连接数SQL> select count(*) from sys.v_$session;5、修改字符集相关 将数据库启动到RESTRICTED模式下做字符集更改:$ sqlplus / as sysdbaSQL> select * from v$nls_parameters; #查看当前系统使⽤的各种字符集SQL> select * from nls_database_parameters where parameter ='NLS_CHARACTERSET'; #精确查询NLS_CHARACTERSET值SQL> shutdown immediate; #关闭数据库SQL> startup mount #启动实例,可以加载数据库,不运⾏数据库DBA在做⼀些操作的时候不希望有⼈登⼊数据库可以使⽤restrict模式:SQL> ALTER SYSTEM ENABLE RESTRICTED SESSION; #开启限制会话模式Oracle job进程,包含协调进程(主进程)以及奴⾪进程(⼦进程),job_queue_processes取值范围为0到1000,总共可创建多少个job进程由job_queue_processes参数来决定。
一、SELECT语句基础语法
SELECT [ALL |DISTINCT TOP N [PERCENT] WITH TIES SELECT_LIST
#SELECT 子句,用于指定由查询返回的列。
[INTO [new_table_name]]
#INTO子句,将检索结果存储到新表或视图中。
FROM {table_name|view_name} [(optimizer_hints)],...
#FROM子句,用于指定引用的表或视图,需指定多个表或视图,用“,”分开即可。
[WHERE search_condition]
#WHERE子句,用于指定限制返回的行的搜索条件,若无此子句,则默认表中的所有行都满足条件。
[GROUP BY group_by_expression]
#GROUP BY子句,指定用来放置输出行的组,并且如果SELECT子句中<select list>中包含聚合函数,则计算每组的汇总值。
[HAVING search_condition]
#指定组或聚合的搜索条件,通常搭配GROUP BY子句一起使用。
[ORDER BY order_by_expression]
#指定结果集的排序,其中ASC表示升序,DESC表示降序,默认是ASC升序。
若不存在此子句,则指定表中的数据的存放位置来显示数据。
[COMPUTE clause]
[FOR BROWSE];
#注:SELECT语句就像叠加在数据库表上的过滤器,即选择查询用于定位数据库特定的列和行。
二、SELECT语句详细解析
1、SELECT子句
(1)SELECT子句:指定由查询返回的列,可以一次指定多个列,用“,”分开即可,并且可以调整列的顺序。
(2)SELECT子句语法:SELECT {column_name_1,column_name_2,...,column_name_n}
(3)SELECT子句中,应避免使用通配符“*”,尽可能的查询符合某种条件的数据,从而提高查询效率。
2、FROM子句
(1)FROM子句:指定查询中包含的行和列所在的表。
(2)FROM子句语法:FROM {table_name | view_name} [(optimizer_hints)],…;
(3)FROM子句格式:FROM _ACTION;(用户.表)
3、WHERE子句
(1)WHERE子句:指定被检索表中的行的子句。
(2)WHERE子句:column_name(列名)comparison_operator(比较运算符)value(值);
a、语法:
SELECT column_name_1,…,column_name_n
FROM table_name_1,…,table_name_n
WHERE column_name comparison_operator value
boolean_operator column_name comparison_operator value;
c、布尔操作符特殊示例:
●BETWEED...AND:
selset ename,job,dname from scott.emp,scott.dept where sal between 3000 and 5000 and emp.deptno=dept.deptno;(检索SCOTT.EMP和DEPT表中工资在3000-5000之间的雇员的姓名、职位和所在部门,关联列为DEPTNO)
●IN:
selset ename,job,dname from scott.emp,scott.dept where sal between 3000 and 5000 and emp.deptno=dept.deptno;
select column_name_1,...,column_name_n from table_name_1,...,table_name_n where column_name IN(value_1,value_2,...,value_n);
select column_name_1,...,column_name_n from table_name_1,...,table_name_n where column_name=value_1 or column_name=value_2 or ... or column_name_n;
4、ORDER BY子句
(1)ORDER BY子句语法:
SELECT column_name_1,...,column_name_n
FROM table_name_1,...,table_name_n
ORDER BY column_name_1,...,column_name_n ASC|DESC;
(2)语法解析:
a、首先根据column_name_1进行排序,然后根据column_name_2进行排序,以此类推。
b、默认情况下,是ASC升序进行排序,可指定排序方式。
5、DISTINCT关键字
(1)作用:检索唯一的表列值(将输出中的重复行去掉)
(2)语法:SELECT DISTINCT column_name_1 FROM table_name_1;。