数据结构_课件_堆与堆排序
- 格式:ppt
- 大小:682.50 KB
- 文档页数:36



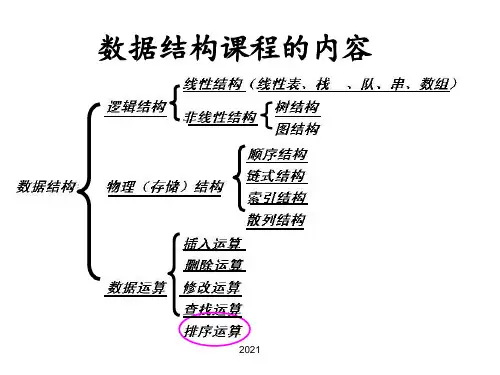
数据结构第9章排序数据结构第9章排序第9章排名本章主要内容:1、插入类排序算法2、交换类排序算法3、选择类排序算法4、归并类排序算法5、基数类排序算法本章重点难点1、希尔排序2、快速排序3、堆排序4.合并排序9.1基本概念1.关键字可以标识数据元素的数据项。
如果一个数据项可以唯一地标识一个数据元素,那么它被称为主关键字;否则,它被称为次要关键字。
2.排序是把一组无序地数据元素按照关键字值递增(或递减)地重新排列。
如果排序依据的是主关键字,排序的结果将是唯一的。
3.排序算法的稳定性如果要排序的记录序列中多个数据元素的关键字值相同,且排序后这些数据元素的相对顺序保持不变,则称排序算法稳定,否则称为不稳定。
4.内部排序与外部排序根据在排序过程中待排序的所有数据元素是否全部被放置在内存中,可将排序方法分为内部排序和外部排序两大类。
内部排序是指在排序的整个过程中,待排序的所有数据元素全部被放置在内存中;外部排序是指由于待排序的数据元素个数太多,不能同时放置在内存,而需要将一部分数据元素放在内存中,另一部分放在外围设备上。
整个排序过程需要在内存和外存之间进行多次数据交换才能得到排序结果。
本章仅讨论常用的内部排序方法。
5.排序的基本方法内部排序主要有5种方法:插入、交换、选择、归并和基数。
6.排序算法的效率评估排序算法的效率主要有两点:第一,在一定数据量的情况下,算法执行所消耗的平均时间。
对于排序操作,时间主要用于关键字之间的比较和数据元素的移动。
因此,我们可以认为一个有效的排序算法应该是尽可能少的比较和数据元素移动;第二个是执行算法所需的辅助存储空间。
辅助存储空间是指在一定数据量的情况下,除了要排序的数据元素所占用的存储空间外,执行算法所需的存储空间。
理想的空间效率是,算法执行期间所需的辅助空间与要排序的数据量无关。
7.待排序记录序列的存储结构待排序记录序列可以用顺序存储结构和和链式存储结构表示。
在本章的讨论中(除基数排序外),我们将待排序的记录序列用顺序存储结构表示,即用一维数组实现。







数据结构-王道-排序排序直接插⼊排序从上⾯的插⼊排序思想中,不难得到⼀种简单直接的插⼊排序算法。
假设待排序表在某次过程中属于这种情况。
|有序序列L[1…i−1]|L(i)|⽆序序列L[i+1…n]||:-|:-|为了实现将元素L(i)插⼊到已有序的⼦序列L[1…i−1]中,我们需要执⾏以下操作(为了避免混淆,下⾯⽤L[]表⽰⼀个表,⽽⽤L()表⽰⼀个元素):查找出L(i)在L[i+1…n]中的插⼊位置k。
将L[k…i−1]中所有元素全部后移⼀个位置。
将L(i)赋值到L(k)void InserSort(int A[],int n){int i,j;for(i=2;i<=n;i++){if(A[i]<A[i-1]){A[0]=A[i];for(j=i-1;A[0]<A[j];j--)A[j+1]=A[j];A[j+1]=A[0];}}}折半插⼊排序从前⾯的直接插⼊排序算法中,不难看出每趟插⼊的过程,都进⾏了两项⼯作:从前⾯的⼦表中查找出待插⼊元素应该被插⼊的位置。
给插⼊位置腾出空间,将待插⼊元素复制到表中的插⼊位置。
注意到该算法中,总是边⽐较边移动元素,下⾯将⽐较和移动操作分离开,即先折半查找出元素的待插⼊位置,然后再同意的移动待插⼊位置之后的元素。
void InserSort(int A[],int n){int i,j,low,high,mid;for(i=2;i<=n;i++){A[0]=A[i];low=1,high=i-1;while(low<=high){mid=(low+high)/2;if(A[mid]>A[0])high=mid-1;elselow=mid+1;}for(j=i-1;j>=high+1;j--)A[j+1]=A[j];A[high+1]=A[0];}}折半插⼊排序从前⾯的代码原理中不难看出,直接插⼊排序适⽤于基本有序的排序表和数据量不⼤的排序表。
堆排序算法详解1、堆排序概述堆排序(Heapsort)是指利⽤堆积树(堆)这种数据结构所设计的⼀种排序算法,它是选择排序的⼀种。
可以利⽤数组的特点快速定位指定索引的元素。
堆分为⼤根堆和⼩根堆,是完全⼆叉树。
⼤根堆的要求是每个节点的值都不⼤于其⽗节点的值,即A[PARENT[i]] >= A[i]。
在数组的⾮降序排序中,需要使⽤的就是⼤根堆,因为根据⼤根堆的要求可知,最⼤的值⼀定在堆顶。
2、堆排序思想(⼤根堆)1)先将初始⽂件Array[1...n]建成⼀个⼤根堆,此堆为初始的⽆序区。
2)再将关键字最⼤的记录Array[1](即堆顶)和⽆序区的最后⼀个记录Array[n]交换,由此得到新的⽆序区Array[1..n-1]和有序区Array[n],且满⾜Array[1..n-1].keys≤Array[n].key。
3)由于交换后新的根R[1]可能违反堆性质,故应将当前⽆序区R[1..n-1]调整为堆。
然后再次将R[1..n-1]中关键字最⼤的记录R[1]和该区间的最后⼀个记录R[n-1]交换,由此得到新的⽆序区R[1..n-2]和有序区R[n-1..n],且仍满⾜关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
这样直到⽆序区中剩余⼀个元素为⽌。
3、堆排序的基本操作1)建堆,建堆是不断调整堆的过程,从len/2处开始调整,⼀直到第⼀个节点,此处len是堆中元素的个数。
建堆的过程是线性的过程,从len/2到0处⼀直调⽤调整堆的过程,相当于o(h1)+o(h2)…+o(hlen/2) 其中h表⽰节点的深度,len/2表⽰节点的个数,这是⼀个求和的过程,结果是线性的O(n)。
2)调整堆:调整堆在构建堆的过程中会⽤到,⽽且在堆排序过程中也会⽤到。
利⽤的思想是⽐较节点i和它的孩⼦节点left(i),right(i),选出三者最⼤者,如果最⼤值不是节点i⽽是它的⼀个孩⼦节点,那边交互节点i和该节点,然后再调⽤调整堆过程,这是⼀个递归的过程。