基于人口增长模型的数学建模(DOC)
- 格式:doc
- 大小:117.00 KB
- 文档页数:13

数学建模论文题目:人口增长模型的确定专业、姓名:专业、姓名:专业、姓名:人口增长模型摘要随着人口的增加,人们越来越认识到资源的有限性,人口与资源之间的矛盾日渐突出,人口问题已成为世界上最被关注的问题之一。
问题给出了1790—1980年间美国的人口数据,通过分析近两百年的美国人口统计数据表,得知每10年的人口数的变化。
预测美国未来的人口。
对于问题我们选择建立Logistic模型(模型2)现实中,影响人口的因素很多,人口也不能无限的增长下去,Logistic 模型引进常数N 表示自然资源和环境所能承受的最大人口数,因而得到了一个贝努利方程的初值问题公式,从实际效果来看,这个公式较好的符合实际情况的发展,随着时间的递增,人口不是无限增长的,而是趋近于一个数,这个即为最大承受数。
我们还同时对数据作了深入的探讨,作数据分析预测,通过观测比较选择一个比较好的拟合模型(模型3)进行预测。
预测接下来的每隔十年五次人口数量,分别为251.4949, 273.5988 , 293.4904 , 310.9222 325.8466。
关键词:人口预测Logistic模型指数模型一、问题重述1790-1980年间美国每隔10年的人口记录如下表所示。
试用以上数据建立马尔萨斯(Malthus)人口指数增长模型,并对接下来的每隔十年预测五次人口数量,并查阅实际数据进行比对分析。
如果数据不相符,再对以上模型进行改进,寻找更为合适的模型进行预测。
二、问题分析人口预测是一个相当复杂的问题,影响人口增长除了人口数与可利用资源外,还与医药卫生条件的改善,人们生育观念的变化等因素有关…….可以采取几套不同的假设,做出不同的预测方案,进行比较。
人口预测可按预测期长短分为短期预测 (5年以下)、中期预测(5~20年)和长期预测(20~50年)。
在参数的确定和结果讨论方面,必须对中短期和长期预测这两种情况分开讨论。
中短期预测中所用的各项参数以实际调查所得数据为基础,根据以往变动趋势可较准确加以估计,推算结果容易接近实际,现实意义较大。

Logistic 人口发展模型一、题目描述建立Logistic 人口阻滞增长模型 ,利用表1中的数据分别根据从1954年、1963年、1980年到2005年三组总人口数据建立模型,进行预测我国未来50年的人口情况.并把预测结果与《国家人口发展战略研究报告》中提供的预测值进行分析比较。
分析那个时间段数据预测的效果好?并结合中国实情分析原因。
表1 各年份全国总人口数(单位:千万)二、建立模型阻滞增长模型(Logistic 模型)阻滞增长模型的原理:阻滞增长模型是考虑到自然资源、环境条件等因素对人口增长的阻滞作用,对指数增长模型的基本假设进行修改后得到的。
阻滞作用体现在对人口增长率r 的影响上,使得r 随着人口数量x 的增加而下降。
若将r 表示为x 的函数)(x r 。
则它应是减函数。
于是有:0)0(,)(x x x x r dt dx== (1)对)(x r 的一个最简单的假定是,设)(x r 为x 的线性函数,即 )0,0()(>>-=s r sxr x r (2) 设自然资源和环境条件所能容纳的最大人口数量mx ,当mx x =时人口不再增长,即增长率)(=m x r ,代入(2)式得m x rs =,于是(2)式为)1()(mx x r x r -= (3)将(3)代入方程(1)得:⎪⎩⎪⎨⎧=-=0)0()1(x x x x rx dtdxm (4)解得:rt mme x x x t x --+=)1(1)(0(5)三、模型求解用Matlab 求解,程序如下: t=1954:1:2005;x=[60.2,61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988,130.756];x1=[60.2,61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988];x2=[61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988,130.756];dx=(x2-x1)./x2; a=polyfit(x2,dx,1);r=a(2),xm=-r/a(1)%求出xm 和rx0=61.5;f=inline('xm./(1+(xm/x0-1)*exp(-r*(t-1954)))','t','xm','r','x0');%定义函数 plot(t,f(t,xm,r,x0),'-r',t,x,'+b');title('1954-2005年实际人口与理论值的比较') x2010=f(2010,xm,r,x0) x2020=f(2020,xm,r,x0) x2033=f(2033,xm,r,x0)解得:x(m)= 180.9516(千万),r= 0.0327/(年),x(0)=61.5得到1954-2005实际人口与理论值的结果:根据《国家人口发展战略研究报告》我国人口在未来30年还将净增2亿人左右。

数学建模———关于人口增长的模型摘要:本文讨论了人口的增长问题,并预测出了2010、2020年的美国人口。
首先,我们给出了两种预测方法:第一,在假定人口增长率不变的情况下,建立指数增长模型;第二,假定人口增长率呈线性下降的情况下,建立阻滞增长模型。
对两种模型的求解,我们引入了微分方程。
其次,为了选择一种较好的预测方法,我们分别对两种模型进行了检验和讨论。
先列图表对预测值与真实值进行比较,然后定性的对模型进行讨论,最后一个阶段选择绝对误差、均方差和相关系数对两个模型的优劣进行定量的评价,选出最好的预测方法。
一、 问题的提出:人口问题是当前世界上人们最关心的问题之一,认识人口数量的变化规律,做出较为准确的预报,是有效控制人口增长前提,现根据下表给出的近两百模型一(指数增长模型)1、模型的提出背景:我们对所给的数据进行了认真仔细的分析之后,对其进行处理:将年份进行编号(i X ),人口数量计为(i Y ),以i X 为横坐标,以i Y 为纵坐标,建立直角坐标系。
然后将表格中所给的数据绘在直角坐标系中附表A ,我们发现这些点大体呈指数增长趋势固提出此模型。
附图A2、基本假设:人口的增长率是常数增长率——单位时间内人口增长率与当时人口之比。
故假设等价于:单位时间人口增长量与当时人口成正比。
设人口增长率为常数r 。
时刻t 的人口为X(t),并设X(t)可微,X(0)=X O由假设,对任意△t>0 ,有)()()(t rx tt x t t x =∆-∆+即:单位时间人口增长量=r ×当时人口数当△t 趋向于0时,上式两边取极限,即:o t →∆lim)()()(t rx tt x t t x =∆-∆+ 引入微分方程:)1( )0()(0⎪⎩⎪⎨⎧==x x t rx dtdx3、模型求解: 从(1)得rdt xdx= 两边求不定积分:c rt x +=ln∵t=0时0x x =,∴C x =0lnrt e x rt x x 00ln ln ln =+=∴rte x t x 0)(= (2) 当r>0时.表明人口按指数变化规律增长.备注; r 的确定方法:要用(4.2)式来预测人口,必须对其中的参数r 进行估计: 十年的增长率307.0ln 9.33.5==r,359.1307.0=e,则(2)式现为: t t x )359.1(9.3)(⨯=4、结论:由上函数可预测得:2010的人口为x(22):x(22)=3325.772020的人口为x(23):x(23)=4519.735、检验:根据所建立的指数模型预测1790以后近两百年的美国人口数量,在此6、模型讨论:由表可见,当人口数较少时,模型的预测结果与实际情况相差不大(不超过5%)。


人口增长问题数学模型人口增长问题是一个复杂的社会现象,它涉及到众多因素,如生育率、死亡率、移民、出生性别比等。
为了更好地理解和预测人口增长趋势,人们常常建立数学模型来描述人口变化的规律。
下面是一个简单的人口增长问题数学模型的示例。
假设人口数量为P(t),时间t为以年为单位。
则人口增长可以用以下微分方程表示:dP(t)/dt = rP(t)其中,r是人口自然增长率,是一个常数。
这个微分方程描述了人口数量随着时间的变化情况,即人口数量呈指数增长。
然而,实际情况要复杂得多。
以下是一个更复杂的人口增长模型,考虑到生育率、死亡率和移民等因素:dP(t)/dt = (b - d)P(t) + I其中,b是每单位时间的出生率,d是每单位时间的死亡率,I是每单位时间的移民人数。
这个模型可以更好地描述人口增长的趋势,特别是当存在外部干扰(如战争、自然灾害等)时。
除了以上两个模型,还有其他更复杂的模型,如Logistic增长模型、Malthusian模型等。
这些模型考虑的因素更加全面,可以更准确地描述人口增长的趋势。
例如,Logistic增长模型考虑了环境承载能力对人口增长的限制,而Malthusian 模型则考虑了人口增长与资源供给之间的关系。
建立数学模型有助于我们更好地理解和预测人口增长趋势。
这些模型可以帮助我们评估不同政策对人口增长的影响,如计划生育政策、移民政策等。
此外,这些模型还可以帮助我们预测未来人口数量和结构的变化情况,从而为社会发展规划提供科学依据。
然而,需要注意的是,数学模型只是对现实世界的近似描述,它可能无法完全准确地预测未来情况。
因此,在使用数学模型进行人口增长预测时,需要结合实际情况和专家意见进行综合分析。
总之,数学模型是研究人口增长问题的重要工具之一。
通过建立数学模型,我们可以更好地理解和预测人口增长的规律和趋势。
这些模型可以帮助我们评估不同政策对人口增长的影响,为社会发展规划提供科学依据。
人口增长模型摘要本文根据某地区的人口统计数据,建立模型估计该地区2010年的人口数量。
首先,通过直观观察人口的变化规律后,我们假设该地区的人口数量是时间的二次函数,建立了一个二次函数模型,并用最小二乘法对已有数据进行拟合得到模型的具体参数,从而可以预测2010年的人口数为333.8668百万。
然后,我们发现从1980年开始该地区的人口增长明显变慢,于是我们假设人口增长率是人口数的线性减函数,即随着人口数的增加,人口的增长速度会慢慢下降,从而我们建立了阻滞增长模型,利用此模型我们最后求出2010年的人口预报数为296.3865。
关键字:人口预报,二次函数模型,阻滞增长模型问题重述:根据某地区人口从1800年到2000年的人口数据(如下表),建立模型估计出该地区2010年的人口 ,同时画出拟合效果的图形。
符号说明)(t x t 时刻的人口数量 0x 初始时刻的人口数量 r 人口增长率m x 环境所能容纳的最大人口数量,即0)( m x r问题分析首先,我们运用Matlab软件[1]编程(见附件1),绘制出1800年到2000年的人口数据图,如图1。
18001820184018601880190019201940196019802000图1 1800年到2000年的人口数据图从图1我们可以看出1800年到2000年的人口数是呈现增长的趋势的,而且类似二次函数增长。
所以我们可以建立了一个二次函数模型,并用最小二乘法对已有数据进行拟合得到模型的具体参数。
于是我们假设人口增长率是人口数的线性减函数,即随着人口数的增加,人口的增长速度会慢慢下降,从而我们可以建立一个阻滞增长模型。
模型建立模型一:二次函数模型我们假设该地区t时刻的人口数量的人口数量)(tx是时间t的二次函数,即:2()=++x t at bt c我们可以根据最小二乘法,利用已有数据拟合得到具体参数。
即,要求a、b和c,使得以下函数达到最小值:221(,,)()ni i i i E a b c at bt c x ==++-∑其中i x 是i t 时刻该地区的人口数,即有:2222)3.28020002000...)2.718001800(),,(-+⋅+⋅++-+⋅+⋅=c b a c b a c b a E令0,0,0E E E a b c∂∂∂===∂∂∂,可以得到三个关于a 、b 和c 的一次方程,从而可解得a 、b 和c 。

人口增长的预测(数学建模论文) - 论文人口增长的预测(数学建模论文) - 论文关键字:人口增长稳定曲线预测运动模型方程平衡点人口数一题目: 请在人口增长的简单模型的基础上。
; (1)找到现有的描述人口增长,与控制人口增长的模型;; (2)深入分析现有的数学模型,并通过计算机进行仿真验证;; (3)选择一个你们认为较好的数学模型,并应用该模型对未来20年的某一地区或国家的人口作出有关预测;; (4)就人口增长模型给报刊写一篇,对控制人口的策略进行论述。
二摘要:本次建模是依照已知普查数据,利用Lgisti模型,对中国人口的增长进行预测。
首先假设人口增长符合Lgisti模型,即引入常数,用来表示自然环境条件所能容许的最大人口数。
并假设净增长率为,即净增长率随着人口数N(t)增长而减小,当N(t) 时,净增长率趋于零。
按照这个假设,。
用参数 ,3.0,r=0.0386, =1908, =14.5。
画出N=N(t)的图像,作为人口增长模型的一种近似。
做微分方程解的定性分析,求出N=N(t)的驻点和拐点,按照函数作图方法列出定性分析表,作出相轨迹的运动图。
当初始人口时,方程的解单调递增到地趋向,这意味着如果使用Lgisti模型描述人口增长,则人口发展地总趋势是渐增到最大人口数,因此可作为人口的预测值,也称谓平衡点。
用导数做稳定分析,为判断平衡点是否为稳定,可在平面上绘制f(x)的图象,然后像函数绘图那样,用导数进行定性分析,通过图看出人口数N(t)按时间是递增的,当人口数未达到饱和状态的时候,将逐渐地趋向,这意味着是稳定的平衡点。
按该模型,未来人口的数量将随着时间的演化,从初始状态出发达到极限状态,这样就给出了人口的未来预测。
三问题的提出1( althus模型英国统计学家althus(1766,1834)发现人口增长率是一个常数。
设t时刻人口为N(t),因为人口总数很大,可近似把N(t)当作连续变量处理。

借助正方体模型,可以把研究对象置于更大的背景之中,从而在整体上更好地看清各部分之间的关系.掌握正方体的结构特征,以正方体为模型可以“生成”许多优美的空间问题,许多空间问题如果将它置于正方体模型之中,其结果甚至可以一望而解.正如上述全国Ⅰ卷高考题,如果善用正方体模型,很容易根据其完美的对称性发现截面面积取最值时的特殊位置.(2)深入学科的软件支持工欲善其事,必先利其器.教师在教学过程要善于合理地利用“利器”——深入学科的数学教学软件,如几何画板、GeoGebra以及Z Z+智能教育平台系列中的超级画板等,利用信息技术独特的优势来优化空间立体几何的教学呈现方式,帮助学生突破认知障碍,发展直观想象的素养.学立体几何的目的绝对不是学会用以不变应万变的“向量法”解出高考题,而应当让学生体验到“做数学”的乐趣.在立体几何软件和平台的支持下,基于信息技术的立体几何教学可以更好地落实三维教学目标,帮助学生认识反映现实的几何空间,学会几何思维方法,培养学生的空间想象能力及逻辑推理能力,让学生在数学抽象和直观想象两大核心素养中自如切换.参考文献[1]邵光华.论空间想象能力与几何教学[J].课程·教材·教法,1996(7):32-36[2]周顺钿.正方体模型的开发和利用[J].数学通报,2017(8):35-41[3]徐章韬,刘郑,刘观海等.信息技术支持下的学科教学知识之课例研究[J].中国电化教育,2013(1):94-99中学数学建模案例分析——以人口模型为例李虎广东省中山市第一中学(528403)2017年,《普通高中数学课程标准》正式颁布,数学建模素养为六大数学核心素养之一.布鲁姆的认知目标分类体系中,把认知学习领域目标分为识记、理解、运用、分析、综合及评价,其中运用、分析、综合及评价属于高阶思维活动,对人的发展起到更重要的作用.数学建模是很好地培养学生高阶思维的素材.人口数量和人口结构与一个国家的经济紧密相关.合理预测人口数量对一系列政策的制定有导向性作用.人口预测的研究吸引了大批的科研人员,经典的人口模型也非常多,本文针对高中生可以接受的情况,介绍了两个经典模型,一个是马尔萨斯模型,一个是Logistic人口模型,并应用模型对未来几年的人口进行了预测.通过两个模型,以期培养学生的批判性思维和用发展的眼光看问题的能力,旨在提升学生的数学建模素养.1 问题提出问题:在知道当前或过去某个时刻的人口数量的情况下,如何预测未来某个时刻的人口数量?2 经典人口模型2.1 马尔萨斯人口模型用()p t表示t时刻的人口数,r表示年平均增长率,则()()()p t t p t rp t t+∆−=∆,起始时刻为0t,记00()p t p=.令0t∆→,得00()()()p t rp tp t p′==,,则0()()e r t tp t p−=.人民教育出版社A版必修1第124页例4有这个模型的介绍,题目中选取了1950-1959年数据,利用年平均增长率的平均值来估计r的值,求得解析式为0.022155196e ty=,是一个指数型函数模型,教材利用这一模型预测了中国1989年人口数量将超过13亿,笔者查阅中华人民共和国国家统计局数据,显示1989年人口数据是112704万人,可见预测出现了很大的偏差.从教材上看,1950-1959年数据拟合效果非常好,问题出在哪里?笔者认为,马尔萨斯模型作为经典的人口模型,有必要给学生介绍其来历,而不是简单地告诉学生一个结论,虽然学生当时学生不懂,但是埋下了常微分方程的种子,在学生的知识储备达到一定程度,它就会生根发芽.这个模型有自身的缺陷,把问题抛出来,让学生利用课余时间去查阅资料,了解误差产生的来源,培养学生查阅资料,搜集文献,综合思考问题的能力,找出模型的缺陷,锻炼学生综合和评价等高阶思维.2.2 Logistic 人口模型马尔萨斯模型中假定了r 是常数,而r 是随着时间变化而变化的.考虑r 是变化的,将r 看成t 的函数.下面以我国人口模型为例,介绍Logistic 模型.假设我国最多能够支撑的人口数量为K ,()P t 表示t 时刻的人口数量,()()(1)p t r t r K=−,则人口满足下面的模型:00()()(1)()()P t P t r P t KP t P′=− = ,,求解得()P t = 0()1e r t t KC −−+,00K P C P −=.本模型中有两个参数r K ,.需要通过往年的数据来拟合这两个参数.首先查阅《中国人口统计年鉴》和中国人口统计报告筛选符合要求的数据,1980年始,我国确定计划生育为我国的一项基本国策,由于国家的政策对人口数量的变化有很大影响,因此必须避免国家政策的影响;同时,在1981年我国的人口突破10亿大关.考虑上述条件,将1981年以前的人口数据剔除,得到下面数据表格,如表1.表1 中国历年人口总数年份 (年) 人口 (万人) 年份 (年) 人口 (万人) 年份 (年) 人口 (万人) 1981 100072 1982 101654 1983 103008 1984 104357 1985 105851 1986 107507 1987 109300 1988 111026 1989 112704 1990 114333 1991 115823 1992 117171 1993 118517 1994 119850 1995 121121 1996 122389 1997 123626 1998 124761 1999 125786 2000 126743 2001 127627 2002 128453 2003 129227 2004 129988 2005 130756 2006 131448 2007 132129 2008 132802 2009 133450 2010 134091 2011 134735 2012 135404 2013 137054 2014 136782 2015 137462 2016 138271 2017 139008 2018 139538r K ,确定方法1:选择012t t t ,,三年的人口数据012P P P ,,, 其中1021t t t t β−=−=, 由101(1)e r K P KP β−=+−,211(1)e r K P KP β−=+−,111P K =+011()e r P K β−−,211111()e r P K P K β−=+−, 12011111()e r P P P P β−−=−, 故0112111ln 11P P r P P β−=−,101e 11e r r K P P ββ−−−=−.计算得0.0593r =,144930K =万人.0.0593144930()1449301(1)e 100072tP t −=+−,0t >.利用此模型预测最近二十年人口,并计算误差值,如表2.表2 中国各年份实际人口数、预测值及预测误差年份 实际人口 /万人 预测人口 /万人 误差 /万人 百分比 1999 125786 125572 214 0.001701 2000 126743 126545 198 0.001562 2001 127627 127476 151 0.001183 2002 128453 128367 86 0.00067 2003 129227 129217 10 7.74E-05 2004 129988 130028 -40 -0.00031 2005 130756 130803 -47 -0.00036 2006 131448 131541 -93 -0.00071 2007 132129 132244 -115 -0.00087 2008 132802 132914 -112 -0.00084 2009 133450 133552 -102 -0.00076 2010 134091 134158 -67 -0.0005 2011 134735 134735 0 0 2012 135404 135283 121 0.000894 2013 137054 135803 1251 0.009128 2014 136782 136297 485 0.003546 2015 137462 136766 696 0.005063 2016 138271 137211 1060 0.007666 2017 139008 137633 1375 0.009892 201813953813803415040.010778由表2可以看出预测值和真实值很接近,误差都保持在很小的范围.说明本模型很好的反映了这一阶段我国人口的变化情况.r K ,确定方法2:将这个连续的模型离散化,用回归分析来求解此模型.(1)()()()P t P t rr P t P t K+−=−,即年增长率可以看成年份的线性函数,用线性回归即可(如图1).利用MATLAB 进行回归求解(代码见附录),得到0.0509r =,150590K =,所以()P t =0.05091505901505901(1)e 100072t−+−,0t >.图1 1981年至2018年预测值与人口实际值的拟合图Logistic 人口模型是对马尔萨斯模型的进一步完善,更符合实际情形,误差也在合理的范围内.笔者认为从发展的角度看,应该把此模型和马尔萨斯模型放在一起让学生了解,让学生去比较判断.从模型的建立可以看到,要建立此模型需要确定参数,如何估计参数,需要搜集数据,用到数据拟合.让学生去思考,去搜集,可以培养学生搜集、整理数据等数据处理能力,同时又要用到信息技术,需要去学习软件对应的拟合函数,对学生的综合能力提升有较高的教育价值.模型的拟合效果好不好,涉及评价环节,有哪些评价指标?此模型的缺陷是什么?适用范围又是什么呢?还有哪些较好的人口预测模型,缺陷是什么?有没有一个完美的人口预测模型呢?让学生把此建模问题扩展开,作为一个项目来研究,扩充自己的知识面,同时提升自己的批判性思维.这样的学习方式,更符合脑科学的规律.3 人口预测若采用0.0593144930()1449301(1)e 100072tP t −=+−,0t >来预测未来8年国内的人口数,得到如下结果(表3).表3 未来8年人口数预测表(1)年份 人口 /万人 2019 138413 2020 138772 2021 139112 2022 139435 2023 139740 2024 140028 2025 140302 2026140560若采用0.0509150590()1505901(1)e 100072tP t −=+−,0t >来预测未来8年国内的人口数,得到如下结果(表4).表4 未来8年人口数预测表(2)年份 人口 /万人 2019 140349 2020 140825 2021 141279 2022 141714 2023 142130 2024 142527 2025 142907 20261432702018年国内人口数为139538(万),可见后面这个模型更精确一些,因为建模中充分考虑了数据的整体性.4 模型价值本文介绍了经典的马尔萨斯人口模型,该模型是一个指数型函数模型,在教材的指数函数应用章节中有体现,但是该模型是在资源极大丰富,没有政策和疾病影响等情况下进行的.显然不符合目前的人口增长情况.但是作为一个经典的人口模型,学生需要去了解.为了克服上述模型带来的预测误差较大问题,本文介绍了第二种人口模型,即Logistic 人口模型,对上述模型的缺点进行了弥补.从预测效果来看很好的反应了1980-2018年间国内人口的变化情况.因为这一阶段各项政策基本稳定,医疗,公共服务,男女比例等问题相对均衡.目前国内全面开放二孩政策,对人口数增长有一定促进作用,长期来看人口的增速会有所加强,但国内人口老龄化也在加剧,死亡率可能在一定时期加大.可以鼓励学生去搜集数据,研究二孩政策对未来几年人口的影响,以及人口老龄化对未来社会,经济生活带来的影响.可以成立小组,让学生彼此之间合作,虽然开始做起来会比较困难,相信随着学生不断地去尝试,慢慢会体会到其中的乐趣.参考文献[1]王勇.Logistic 人口模型的求解问题[J].哈尔滨商业大学学报(自然科学版),2006(5):58-59 [2]任运平,杨建雅.Logistic 人口模型的改进[J].运城高等专科学校学报,1999(6):23-24附录 MATLAB 程序代码参数r K,估计代码:t=0:1:37; %令1981年为0,2018年为37,间隔为1年P=[100072,101654,103008,104357,105851,107507,109300,111026,112704,114333,115823,117171,118517,119850,121121,122389,123626,124761,125786,126743,127627,128453,129227,129988,130756,131448,132129,132802,133450,134091,134735,135404,137054,136782,137462,138271,139008,139538]; %1981年到2018年的人口数据P1=[100072,101654,103008,104357,105851,107507,109300,111026,112704,114333,115823,117171,118517,119850,121121,122389,123626,124761,125786,126743,127627,128453,129227,129988,130756,131448,132129,132802,133450,134091,134735,135404,137054,136782,137462,138271,139008]; %1981年到2017年的人口数据P2=[101654,103008,104357,105851,107507,109300,111026,112704,114333,115823,117171,118517,119850,121121,122389,123626,124761,125786,126743,127627,128453,129227,129988,130756,131448,132129,132802,133450,134091,134735,135404,137054,136782,137462,138271,139008,139538]; %1982年到2018年的人口数据rn=(P2-P1)./P2;%每一年的人口增长率cs=polyfit(P2,rn,1);%最小二乘法的拟合公式r=cs(2),K=-r/cs(1)%r K,的值预测函数拟合图代码:t=1981:1:2018;P=[100072,101654,103008,104357,105851,107507,109300,111026,112704,114333,115823,117171,118517,119850,121121,122389,123626,124761,125786,126743,127627,128453,129227,129988,130756,131448,132129,132802,133450,134091,134735,135404,137054,136782,137462,138271,139008,139538]; %1981年到2018年的人口数据t1=0:1:37;YP=150590./(1+(150590/100072-1)*exp(-0.0509*t1));%1981年到2018年人口预测值plot(t,P,'*',t,YP,'-r') %实际值与预测值得拟合图title('1981年到2018年预测值与人口实际值的拟合图')%画拟合图(本文系中山市2018年重点项目课题《高中数学学科核心素养之数学建模的教学实践研究》(课题编号:A2018021)的阶段性研究成果)例谈信息技术与高中数学教学的深度融合许如意福建省晋江市紫峰中学(362200)在2018年泉州市教育系统高中教师教育教学信息化应用技能岗位练兵竞赛中,笔者有幸以《阿波罗尼斯圆》通过了淘汰率高达80%的初赛环节,进入复赛,并在后续比赛中获奖.下面以《阿波罗尼斯圆》这一节课中信息技术的使用情况为例,谈谈自己对信息技术与高中数学课程深度融合的思考,以期抛砖引玉.1 信息技术与高中数学教学深度融合的案例在《阿波罗尼斯圆》这节课中,基于人教A版必修2习题4.1的B组题3(已知点M与两个定点(00)O,,(30)A,的距离之比为12,求点M的轨迹方程),我们设置了一个类比椭圆、双曲线的轨迹,猜想平面内到两个定点的距离之比等于常数的点的轨迹,并利用信息技术验证猜想,然后给出一般结论的教学环节.在这个环节需要一个合适的专业数学软件来支持教学设想的顺利展开.根据所在学校的硬件条件以及学生的情况(有开设《几何画板》校本选修课),我们选择了《几何画板》,并设计了如下方案.方案1①根据定点(00)O,,(30)A,与定比12,计算出阿波罗尼斯圆的方程并画出圆,作出两定点;②在圆上任意取一个点M,连接MO MA,,度量MOMA;③隐藏圆,追踪点M的轨迹,这样就形成了一个阿波罗尼斯圆的动画.《普通高中数学课程标准(2017)》提出:重视信息技术运用,实现信息技术与数学课程的深度融合.教师应重视信息技术的运用,优化课堂教学,转变教学与学习方式.例如,为学生理解概念创设背景,为学生探索规律启发思路,为学生解决问题提供直观,引导学生自主获取资源.上述方案能达到课程标准所提出的“为学生探索规律启发思路”吗?能体现信息技术与数学课程的深度融合吗?在方案设置好之后,笔者进行了反思.方案一只能体现在定点(00)O,,(30)A,与定比12条件下的阿波罗尼斯圆,而学生在验证环节,需要改变定点或定比来探索一般情况下动点M的轨迹.因此,笔者将方案1进行了修改.方案2①设置参数1t,用参数1t表示MOMA;②在x轴上任意取一点F,度量其横坐标值为。

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A/B/C/D中选择一项填写):我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):参赛队员(打印并签名) :1.2.3.指导教师或指导教师组负责人(打印并签名):日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):中国人口增长预测模型摘要:在中国的人口增长预测问题中,老龄化进程加速,出生人口性别比的变化,乡村人口城镇化,是影响人口预测的主要因素。
在中短期预测的过程中,由于影响人口的各项主要因素变化范围较小,可以直接根据我们建立的模型进行预测。
老年人的死亡率变化较大,出生的男女百分比得到遏制并逐渐趋于正常的水平。
我们将根据年龄将人口分成两部分,0到60岁的人口的预测,和60岁以后人口的预测。
通过原来的模型对0岁到60岁的中国妇女的人口数预测,进而通过中国男女比例变化与年份的关系来预测出相应的0岁到60岁中国男性数目的总和,得到了中国0到60岁人口总和的预测,根据附件一中的资料预测出相应年份的60岁以上的人口数目总和,这样我们就合理的得到了长期人口数目的预测。
通过预测我们得到:在 2010年人口达到13.8亿人,城镇化率达到46.7% 在2020年人口总数变为:14.7亿人,城镇化率达到53.26% ,2035年人数达到高峰,城镇化率达到56.53%,以后各年直到2050年保持基本稳定的状态。
摘要:人口的增长是当前世界上引起普遍关注的问题作为世界上人口最多的国家,我国的人口问题是十分突出的由于人口基数大尽管我国已经实行了20多年的计划生育政策人口的增长依然很快,巨大人口压力会给我国的社会 政治经济医疗就业等带来了一系列的问题。
因此研究和解决人口问题在我国显得尤为重要。
我们经常在报刊上看见关于人口增长预报,说到本世纪,或下世纪中叶,全世界的人口将达到多少亿。
你可能注意到不同报刊对同一时间人口的预报在数字商场有较大的区别,这显然是由于用了不同的人口整张模型计算出来的结果。
人类社会进入20世纪以来,在科学和技术和生产力飞速发展的同时世界人口也以空前的规模增长。
人口每增加十亿的时间,有一百年缩短为十几年。
我们赖以生存的地球已经携带着他的60亿子民踏入下一个世纪。
长期以来,人类的繁殖一直在自然地进行着,只是由于人口数量的迅速膨胀和环境质量的急剧恶化,人们才猛然醒悟,开始研究人类和自然的关系、人口数量的变化规律以及如何惊醒人口控制等问题。
本文件里两个模型: (1):中国人口的指数增长模型,并用该模型进行预测,与实际人口数据进行比较。
(2):中国人口的Logistic 图形,标出中国人口的实际统计数据进行比较。
而且利用MATLAB 图形 ,标出中国人口的实际统计数据,并画出两种模型的预测曲线和两种预测模型的误差比较图,并分别标出其误差。
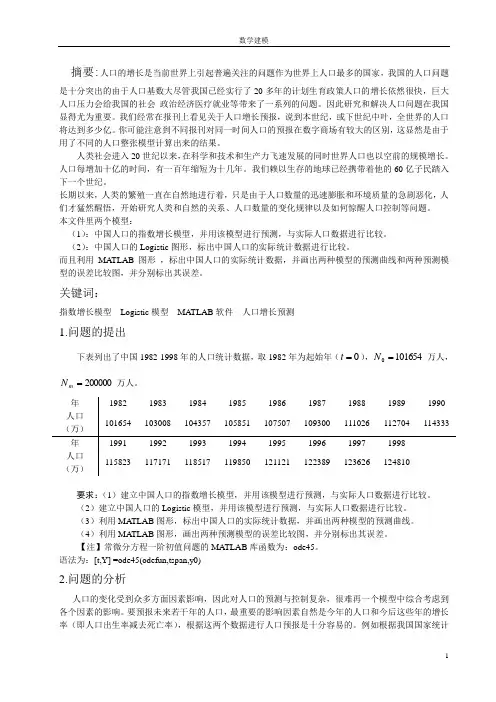
关键词:指数增长模型 Logistic 模型 MATLAB 软件 人口增长预测1.问题的提出下表列出了中国1982-1998年的人口统计数据,取1982年为起始年(0=t ),1016540=N 万人,200000=m N 万人。
要求:(1)建立中国人口的指数增长模型,并用该模型进行预测,与实际人口数据进行比较。
(2)建立中国人口的Logistic 模型,并用该模型进行预测,与实际人口数据进行比较。
(3)利用MA TLAB 图形,标出中国人口的实际统计数据,并画出两种模型的预测曲线。
人口增长预测模型摘要本文建立了我国人口增长的预测模型,对各年份全国人口总量增长的中短期和长期趋势作出了预测,并对人口老龄化、人口抚养比等一系列评价指标进行了预测。
最后提出了有关人口控制与管理的措施。
模型Ⅰ:建立了Logistic人口阻滞增长模型,利用附件2中数据,结合网上查找补充的数据,分别根据从1954年、1963年、1980年到2005年三组总人口数据建立模型,进行预测,把预测结果与附件1《国家人口发展战略研究报告》中提供的预测值进行分析比较。
得出运用1980年到2005年的总人口数建立模型预测效果好,拟合的曲线的可决系数为0.9987。
运用1980年到2005年总人口数据预测得到2010年、2020年、2033年我国的总人口数分别为13.55357亿、14.18440亿、14.70172亿。
模型Ⅱ:考虑到人口年龄结构对人口增长的影响,建立了按年龄分布的女性模型(Leslie模型):以附件2中提供的2001年的有关数据,构造Leslie矩阵,建立相应Leslie模型;然后,根据中外专家给出的人口更替率1.8,构造Leslie矩阵,建立相应的 Leslie模型。
首先,分别预测2002年到2050年我国总人口数、劳动年龄人口数、老年人口数(见附录8),然后再用预测求得的数据分别对全国总人口数、劳动年龄人口数的发展情况进行分析,得出:我国总人口在2010年达到14.2609亿人,在2020年达到14.9513亿人,在2023年达到峰值14.985亿人;预测我国在短期内劳动力不缺,但须加强劳动力结构方面的调整。
其次,对人口老龄化问题、人口抚养比进行分析。
得到我国老龄化在加速,预计本世纪40年代中后期形成老龄人口高峰平台,60岁以上老年人口达4.45亿人,比重达33.277%;65岁以上老年人口达3.51亿人,比重达25.53%;人口抚养呈现增加的趋势。
再次,讨论我国人口的控制,预测出将来我国育龄妇女人数与生育旺盛期育龄妇女人数,得到育龄妇女人数在短期内将达到高峰,随后又下降的趋势的结论。
中国人口增长模型摘要人口问题涉及人口质量和人口结构等因素,是一个复杂的系统工程,稳定的人口发展直接关系到我国社会、经济的可持续发展。
如何从数量上准确的预测人口数量以及各种人口指标,对我国制定与社会经济发展协调的健康人口发展计划有着决定性的意义。
近年来我国的人口发展出现了许多新的特点,这些都影响着我国人口的增长。
鉴此,本文依据灰色预测方法和年龄移算理论,基于人口普查统计数据,从人口系统发展机理上展开讨论。
首先根据灰色预测理论,建立了一级的灰色预测模型,再将近几年我国的人口数量带入模型,便得到未来较短时间内我国的人口数量。
所得结果为我国总人口将于2006年、2007,2008,2009,2010年分别达到13.1495,13.2212,13.2909,13.3587,13.4246亿人。
然后分析人口发展方程中按年龄死亡率及生育模式等参数函数的内在变化规律,及其对总人口的影响,建立了莱斯利主模型,并在此基础上针对各参数函数的不同特点,建立了生育模型和死亡模型等子模型。
在将所得子模型和主模型结合,依据当前人口结构现状对我国的人口做了长期的预测。
所得结果是我国总人口将于2010年、2020年、2030年分别达到13.51058,14.38295,14.78661亿人与国家发展战略报告数据一致。
最后对所建模型的优缺点进行了客观的评价。
关键词:灰色预测模型,改进的莱斯利模型,老龄化指数,平均寿命,平均年龄。
一、问题的提出1.1问题:中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。
根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。
近年来中国的人口发展出现了一些新的特点,例如,老龄化进程加速、出生人口性别比持续升高,以及乡村人口城镇化等因素,这些都影响着中国人口的增长。
2007年初发布的《国家人口发展战略研究报告》还做出了进一步的分析。
关于中国人口问题已有多方面的研究,并积累了大量数据资料。
数学建模人口增长模型摘要:人口的增长是当前世界上引起普遍关注的问题作为世界上人口最多的国家,我国的人口问题是十分突出的由于人口基数大尽管我国已经实行了20多年的计划生育政策人口的增长依然很快,巨大人口压力会给我国的社会政治经济医疗就业等带来了一系列的问题。
因此研究和解决人口问题在我国显得尤为重要。
我们经常在报刊上看见关于人口增长预报,说到本世纪,或下世纪中叶,全世界的人口将达到多少亿。
你可能注意到不同报刊对同一时间人口的预报在数字商场有较大的区别,这显然是由于用了不同的人口整张模型计算出来的结果。
人类社会进入20世纪以来,在科学和技术和生产力飞速发展的同时世界人口也以空前的规模增长。
人口每增加十亿的时间,有一百年缩短为十几年。
我们赖以生存的地球已经携带着他的60亿子民踏入下一个世纪。
长期以来,人类的繁殖一直在自然地进行着,只是由于人口数量的迅速膨胀和环境质量的急剧恶化,人们才猛然醒悟,开始研究人类和自然的关系、人口数量的变化规律以及如何惊醒人口控制等问题。
本论文中有两个模型:(1):中国人口的指数增长模型,并用该模型进行预测,与实际人口数据进行比较。
(2):中国人口的Logistic图形,标出中国人口的实际统计数据进行比较。
而且利用MATLAB图形,标出中国人口的实际统计数据,并画出两种模型的预测曲线。
关键字:人口预测;Malthus模型;Logistic模型;MATLAB软件一、问题背景及重述1.1问题的背景中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。
我国自1973年全面推行计划生育以来,生育率迅速下降,取得了举世瞩目的成就,但全面建设小康社会仍面临着人口的形势和严峻挑战。
随着我国经济的发展、国家人口政策的实施,未来我国人口高峰期到底有多少人口,专家学者们的预测结果不一。
因此,根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。
1.2 问题的重述下表列出了中国1982~1998年的人口统计数据,取1982年为起始年(t=0),1982年的人口101654万人,人口自然增长率为14‰,以36亿作为我国人口的容纳量,试建立一个较好的人口数学模型并给出相应的算法和程序,并与实际人二、问题分析对于人口增长的问题,其影响因素有很多,比如:人口基数,出生率,死亡率,人口男女比例,人口年龄结构的组成,人口的迁入率和迁出率,人口的生育率和生育模式,国家的医疗发展情况,国家的政治策略等众多的因素。
论文结构合理,模型建立详细,思想明确,论述清楚程序和拟合是文章的亮点,模型建立完了没有做误差分析,如果补完整是一篇很不错的文章。
摘要•随着科学技术的发展,国内资金积累量在不断增加,但是中国人口近几年还是呈增加的趋势,这样就会影响人均收入。
由于国民收入是资金积累的一部分,国民收入变化可以反映资金积累的变化。
因此研究资金积累、国民收入与人口增长的关系可以转化成研究资金积累与人口增长的关系。
若国民平均收入与按人口平均资金积累成正比,说明仅当资金积累的相对增长率大于人口的相对增长率时,国民平均收入才是增长的。
所以认识资金积累与人口增长的关系,对国民平均收入的增长有重大意义。
本文通过微分方程建立三个模型,即人口Malthus模型、资金积累指数模型、资金积累增长率与人口增长率的二次曲线模型。
通过资金积累与人口增长的关系来分析国民平均收入。
关键词:资金积累人口增长国民平均收入资金积累增长率人口增长率一、问题的重述资金积累、国民收入、与人口增长的关系:(1)若国民平均收入x与按人口平均资金积累y成正比,说明仅当总资金积累的相对增长率k大于人口的相对增长率r时,国民平均收入才是增长的. (2)作出k(x)和r(x)的示意图,分析人口激增会引起什么后果.二、问题分析人均国民收入主要与国家资金总积累量和总人口数有关,若总人口数的增长率大于资金积累增长率,则增长的资金不能使每一位国民增加收入,只能使少量国民收入增加,因此,总体来说,国家人均收入实际上是减少的。
三、模型假设假设总资金增长和人口增长均为指数增长,资金积累增长率和人口增长率为二次曲线模型。
四、符号说明a为国民收入在总资金积累中所占比例;y(t)为总资金积累量;N(t)为总人口数;Nm为人口的峰值;x(t) 为人均国民收入;r 为人口增长率;k 为资金积累增长率。
五、模型的建立与求解(1)人口增长模型曲线如图1所示:图1通过图形,用MATLAB 编程可建立指数增长模型6110)()(⨯+=⨯tet N αα 其中0127.01=α 0058.02=α(2)总资金积累模型曲线如图2所示:图2由曲线可知资金增长是呈指数整长的并通过MATLAB编程得到指数模型:y(t)=(0.001+e x003.0) 106。
基于人口增长模型的数学建模(DOC)数学建模论文题目:人口增长模型的确定专业、姓名:专业、姓名:专业、姓名:人口增长模型摘要随着人口的增加,人们越来越认识到资源的有限性,人口与资源之间的矛盾日渐突出,人口问题已成为世界上最被关注的问题之一。
问题给出了1790—1980年间美国的人口数据,通过分析近两百年的美国人口统计数据表,得知每10年的人口数的变化。
预测美国未来的人口。
对于问题我们选择建立Logistic 模型(模型2)现实中,影响人口的因素很多,人口也不能无限的增长下去,Logistic 模型引进常数N 表示自然资源和环境所能承受的最大人口数,因而得到了一个贝努利方程的初值问题公式,从实际效果来看,这个公式较好的符合实际情况的发展,随着时间的递增,人口不是无限增长的,而是趋近于一个数,这个即为最大承受数。
我们还同时对数据作了深入的探讨,作数据分析预测,通过观测比较选择一个比较好的拟合模型(模型3)进行预测。
预测接下来的每隔十年五次人口数量,分别为251.4949, 273.5988 , 293.4904 , 310.9222 325.8466。
关键词:人口预测Logistic模型指数模型一、问题重述1790-1980年间美国每隔10年的人口记录如下表所示。
年份1790 180018101820183018401850186018701880人口(⨯106) 3.95.37.29.6 12.917.123.231.438.650.2年份1890 190019101920193019401950196019701980人口(⨯106) 62.976.092.0106.5123.131.150.179.204.226.2 7 73 0 5试用以上数据建立马尔萨斯(Malthus)人口指数增长模型,并对接下来的每隔十年预测五次人口数量,并查阅实际数据进行比对分析。
如果数据不相符,再对以上模型进行改进,寻找更为合适的模型进行预测。
二、问题分析人口预测是一个相当复杂的问题,影响人口增长除了人口数与可利用资源外,还与医药卫生条件的改善,人们生育观念的变化等因素有关…….可以采取几套不同的假设,做出不同的预测方案,进行比较。
人口预测可按预测期长短分为短期预测 (5年以下)、中期预测(5~20年)和长期预测(20~50年)。
在参数的确定和结果讨论方面,必须对中短期和长期预测这两种情况分开讨论。
中短期预测中所用的各项参数以实际调查所得数据为基础,根据以往变动趋势可较准确加以估计,推算结果容易接近实际,现实意义较大。
三、问题假设1.在模型中预期的时间内,人口不会因发生大的自然灾害、突发事故或战争等而受到大的影响;2.假设美国人口的增长遵循马尔萨斯人口指数增长的规则3.假设人口增长不受环境最大承受量的限制四、变量说明:数据的起始时间,即1790年t:时间r:人口增长率x :人口常数最大值五、模型建立模型一图一由图1可以发现美国人口的变化规律曲线近似为一条指数函数曲线,因此我们假设美国的人口满足函数关系x=f(t), f(t)=e a+bt,a,b为待定常数,根据最小二乘拟合的原理,a,b是函数∑=-=niiix tfbaE12))((),(的最小值点。
其中x i是t i时刻美国的人口数。
利用MATLAB软件中的曲线拟合程序“lsqcurvefit”。
模型二上述模型对过去的统计数据吻合得较好,但也存在问题,即人口是呈指数规律无止境地增长,此时人口的自然增长率随人口的增长而增长,这不可能。
一般说来,当人口较少时增长得越来越快,即增长率在变大;人口增长到一定数量以后,增长就会慢下来,即增长率变小这是因为,自然资源、环境条件等因素不允许人口无限制地增长,它们对人口的增长起着阻滞作用,而且随着人口的增加,阻滞作用越来越大。
而且人口最终会饱和,趋于某一个常数x ∞,我们假设人口的静增长率为r(1-x(t)/x ∞),即人口的静增长率随着人口的增长而不断减小,当t →∞时,静增长率趋于零。
按照这个假设,得到⎪⎩⎪⎨⎧=-=∞00)()1(x t x x x r dtdx(1)这便是荷兰数学家Verhulst 于19世纪中叶提出的阻滞增长模型(logistic 模型)。
利用分离变量法,人口的变化规律为: r t e x x x )1790(3910)1(1--∞∞-+= (2)利用MATLAB软件中的“lsqcurvefit”命令和函数(2) 来拟合所给的人口统计数据,从而确定出(2)中的待定参数r和x∞。
模型三从图 5 看出,在前一段吻合得比较好,但在最上面,若拟合曲线更接近原始数据,对将来人口的预测应该更好。
因此,把用函数(2)来拟合所给人口统计数据的评价准则略加修改,看效果如何。
将拟合准则改为:∑∑+==-+-=211212))(())(()(minnii iniiixtfwxtfaE其中w为右端几个点的误差权重,在此处应该取为大于1的数,这样会使右边的拟合误差减小,相应的,其他点的误差会有所增加。
如何才能使这些误差的增减恰当呢?可以通过调整w 和n的具体取值,比较他们取各种不同值时的拟合效果,从而确定出一个合适的数值。
六、模型求解模型一图二a =0.0154 -25.1080 x1 =279.0104x2 =325.6156x3 =380.0056x4 =443.4808X5=517.5587模型二图三a =285.8931 0.0286 x1=230.9149x2 =242.5078x3 =252.0148x4 =259.6639x5 =265.7242模型三图四a =388.7178 0.0260x1 =251.4949x2 =273.5988x3 =293.4904x4 =310.9222x5 =325.8466七、结果分析从图二可以看出,模型一对过去的统计数据吻合得较好,但也存在问题,即人口是呈指数规律无止境地增长,此时人口的自然增长率随人口的增长而增长,这不可能。
一般说来,当人口较少时增长得越来越快,即增长率在变大;人口增长到一定数量以后,增长就会慢下来,即增长率变小这是因为,自然资源、环境条件等因素不允许人口无限制地增长,它们对人口的增长起着阻滞作用,而且随着人口的增加,阻滞作用越来越大。
而且人口最终会饱和,趋于某一个常数。
这时模型二比较符合。
从图三看,在前一段吻合得比较好,但在最上面,若拟合曲线更接近原始数据,对将来人口的预测应该更好。
因而用将模型二进行改进后的模型三拟合,此时后面的值更为拟合,预测结果更为准确。
所以,1990-2030年的人口预测数目为251.4949,273.5988,293.4904,310.9222,325.8466(百万),经过与1990,2000,2010的实际查找数据(251.4,281.4,308.7)比较,误差较小,可以作为预测数据。
八、参考文献【1】姜启源,谢金星,叶俊,数学模型(第三版),北京:高等教育出2003 九、附录一.function f=fun1(a,t)f=exp(a(1)*t+a(2));t=1790:10:1980;x=[3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4 38.6 50.2 62.9 76 ...92 106.5 123.2 131.7 150.7 179.3 204 226.5];plot(t,x,'-*');a0=[0.001,1];a=lsqcurvefit('fun1',a0,t,x)ti=1790:5:2040;xi=fun1(a,ti);hold onplot(ti,xi,’.’);t1=1990;x1=fun1(a,t1)t2=2000;x2=fun1(a,t2)t3=2010;x3=fun1(a,t3)t4=2020;x4=fun1(a,t4)t5=2030;x5=fun1(a,t5)hold off二.x=1790:10:1980;y=[3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4 38.6 50.2 62.9 76 ...92 106.5 123.2 131.7 150.7 179.3 204 226.5];plot(x,y,'-*');a0=[0.001,1];a=lsqcurvefit('fun3',a0,x,y)xi=1790:5:2040;yi=fun3(a,xi);hold onplot(xi,yi);t1=1990;x1=fun3(a,t1)t2=2000;x2=fun3(a,t2)t3=2010;x3=fun3(a,t3)t4=2020;x4=fun3(a,t4)t5=2030;x5=fun3(a,t5)hold off三.function f=fun4(a)n=16;w=30;x=1790:10:1980;x1=x(1:n);x2=x(n+1:20);y=[3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4 38.6 50.2 62.9 76 ...92 106.5 123.2 131.7 150.7 179.3 204 226.5];y1=y(1:n);y2=y(n+1:20);f=[fun3(a,x1)-y1,w*fun3(a,x2)-w*y2];t=1790:10:1980;x=[3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4 38.6 50.2 62.9 76 ...92 106.5 123.2 131.7 150.7 179.3 204 226.5];plot(t,x,'-*');a0=[300,0.03];a=lsqnonlin('fun4',a0)ti=1790:5:2040;xi=fun3(a,ti);hold on;plot(ti,xi,t,x,'*');t1=1990;x1=fun3(a,t1) t2=2000;x2=fun3(a,t2) t3=2010;x3=fun3(a,t3) t4=2020;x4=fun3(a,t4) t5=2030;x5=fun3(a,t5) hold off。