淘宝分布式大数据及实时流数据技术架构48
- 格式:pptx
- 大小:886.14 KB
- 文档页数:49



淘宝服务端技术架构详解目录一、前言 (3)二、单机架构 (4)三、多机部署 (4)四、分布式缓存 (5)五、Session 共享解决方案 (7)六、数据库读写分离 (9)七、CDN 加速与反向代理 (10)八、分布式文件服务器 (11)九、数据库分库分表 (11)十、搜索引擎与NoSQL (13)十一、后序 (13)一、前言以淘宝网为例,简单了解一下大型电商的服务端架构是怎样的。
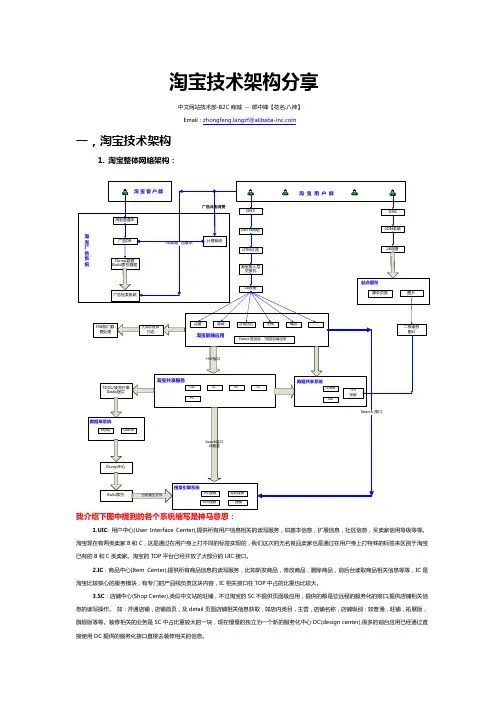
如图所示最上面的就是安全体系系统,中间的就是业务运营系统,包含各个不同的业务服务,下面是一些共享服务,然后还有一些中间件,其中ECS 就是云服务器,MQS 是队列服务,OCS 是缓存等等,右侧是一些支撑体系服务。
除图中所示之外还包含一些我们看不到的,比如高可用的体现。
淘宝目前已经实现多机房容灾和异地机房单元化部署,为淘宝的业务也提供了稳定、高效和易于维护的基础架构支撑。
这是一个含金量非常高的架构,也是一个非常复杂而庞大的架构,当然这个架构不是一天两天演进成这样的,也不是一开始就设计并开发成这样的,对于初创公司而言,很难在初期就预估到未来流量千倍、万倍的网站架构会是怎样的状况,同时如果初期就设计成千万级并发的流量架构,也很难去支撑这个成本。
因此一个大型服务系统,都是从小一步一步走过来的,在每个阶段找到对应该阶段网站架构所面临的问题,然后不断解决这些问题,在这个过程中,整个架构会一直演进,同时内含的代码也就会演进,大到架构、小到代码都是在不断演进和优化的。
所以说高大上的项目技术架构和开发设计实现不是一蹴而就的,这是所谓的万丈高楼平地起。
二、单机架构从一个小网站说起,一般来说初始一台服务器就够了,文件服务器、数据库以及应用都部署在一台机器上。
也就是俗称的 allinone 架构。
这篇推荐看下:厉害了,淘宝千万并发,14 次架构演进…三、多机部署随着网站用户逐渐增多,访问量越来越大,硬盘、cpu、内存等开始吃紧,一台服务器难以支撑。

淘宝技术框架分析报告淘宝作为国首屈一指的大型电子商务,每天承载近30亿PV的点击量,拥有近50PB的海量数据,那么淘宝是如确保其的高可用的呢?本文将对淘宝在构建大型过程中所使用到的技术框架做一个总结,并结合银行现有技术框架进展比照分析。
另外,本文还会针对金融互联网以及公司未来技术开展向给出个人看法。
淘宝技术分析CDN技术及多数据中心策略国的网络由于运营商不同〔分为电信、联通、移动〕,造成不同运营商网络之间的互访存在性能问题。
为了解决这个问题,淘宝在全国各地建立了上百个CDN节点,当用户访问淘宝时,浏览器首先会访问DNS效劳器,通过DNS解析域名,根据用户的IP将访问分配到不同的入口。
如果客户的IP属于电信运营商,那么就会被分配到同样是电信的CDN节点,并且保证访问的〔这里主要指JS、CSS、图片等静态资源〕CDN节点是离用户最近的。
这样就将巨大的访问量分散到全国各地。
另外,面对如此巨大的业务请求,任一个单独的数据中心都是无法承受的,所以淘宝在全国各主要城市都建立了数据中心,这些数据中心不但保证了容灾,而且各个数据中心都在提供效劳。
不管是CDN技术还是多个数据中心,都涉及到复杂的数据同步,淘宝很好的解决了这个问题。
银行现在正在筹建两地三中心,但主要目的是为了容灾,数据中心的利用率差,而淘宝的多个数据中心利用率为100%。
LVS技术淘宝的负载均衡系统采用了LVS技术,该技术目前由淘宝的章文嵩博士负责。
该技术可以提供良好的可伸缩性、可靠性以及可管理型。
只是这种负载均衡系统的构建是在Linux操作系统上,其他操作系统不行,并且需要重新编译Linux操作系统核,对系统核的了解要求很高,是一种软负载均衡技术。
而银行那么通过F5来实现负载均衡,这是一种硬负载均衡技术。
Session框架Session对于Web应用是至关重要的,主要是用来保存用户的状态信息。
但是在集群环境下需要解决Session共享的问题。
目前解决这个问题通常有三种式,第一个是通过负载均衡设备实现会话保持,第二个是采用Session复制,第三个那么是采用集中式缓存。




淘宝运行知识点总结作为中国最大的电子商务平台之一,淘宝的运行涉及到许多方面的知识点。
在这篇文章中,我们将从技术、运营、市场和管理等多个方面来总结淘宝的运行知识点。
技术知识点1. 服务器构架淘宝作为一个庞大的电子商务平台,其服务器构架必须具备高性能、高可用和高扩展性。
淘宝采用分布式服务器架构,通过负载均衡和分布式缓存来处理大规模的访问请求。
2. 数据库管理淘宝的数据库系统包括关系型数据库和非关系型数据库,用于存储用户数据、商品信息、交易记录等。
数据库管理涉及到数据的备份恢复、性能优化、数据安全等方面。
3. 网络安全作为一个电子商务平台,淘宝面临着各种网络安全威胁,包括DDoS攻击、SQL注入、跨站脚本攻击等。
网络安全团队必须采取一系列措施来保护平台的安全。
4. 大数据处理淘宝拥有庞大的用户群体和海量的交易数据,因此需要采用大数据技术来进行数据分析、用户画像、推荐系统等方面的处理。
运营知识点1. 商品运营淘宝的商品运营包括平台运营、销量提升、品牌推广等方面。
运营团队需要了解市场趋势,制定商品推广策略,优化商品搜索排名等。
2. 用户运营用户运营是淘宝的核心工作之一,包括用户注册、用户活跃度、用户留存等方面。
用户运营团队通过数据分析和用户画像来提升用户体验,增加用户粘性。
3. 营销推广淘宝的营销推广包括广告投放、活动策划、社交媒体营销等方面。
运营团队需要了解不同渠道的用户行为特点,制定相应的营销策略。
市场知识点1. 竞争分析淘宝面临着激烈的市场竞争,竞争分析是市场团队的重要工作之一。
团队需要了解竞争对手的产品、价格、营销策略等,并及时调整自身策略。
2. 消费者行为消费者行为分析是市场团队的重要工作内容,包括用户购买行为、用户偏好、用户消费习惯等方面。
团队需要通过数据分析来了解消费者行为,从而制定相应的市场策略。
管理知识点1. 团队管理淘宝拥有庞大的团队,团队管理是管理团队的重要工作内容。
管理团队需要制定有效的团队管理制度,调动团队的积极性,提升团队的执行力。

天猫技术方案1. 引言天猫作为中国最大的电子商务平台之一,每天都有庞大的用户流量和复杂的交易活动。
为了应对这样的挑战,天猫需要保持高可用性、高性能和高安全性。
本文将介绍天猫的技术方案,包括架构设计、技术选型和安全策略等。
2. 架构设计天猫采用分布式架构,以应对大规模的并发请求。
核心架构包括前端负载均衡、应用服务器集群和分布式数据库。
2.1 前端负载均衡当用户发起请求时,请求首先经过前端负载均衡器,根据负载均衡算法将请求分发给应用服务器集群的其中一台。
负载均衡器还能够根据服务器的负载情况动态调整流量分配,以保证各个应用服务器的负载均衡。
2.2 应用服务器集群天猫的应用服务器集群通过横向扩展来增加系统的吞吐量和可扩展性。
每个应用服务器都运行相同的应用程序,接受用户请求并返回相应的数据。
应用服务器之间通过消息队列来实现异步通信,以降低耦合性和提高系统的可用性。
2.3 分布式数据库天猫的数据存储采用分布式数据库系统,将数据分散存储在多个节点上。
这样可以提高系统的数据处理能力和存储容量,并且增强系统的容错性。
天猫使用数据库分片技术来实现数据的分布式存储和负载均衡,同时保证数据的一致性和可靠性。
3. 技术选型天猫选择了一系列成熟的开源技术来支持其架构设计和业务需求。
3.1 后端技术栈天猫的后端开发采用Java语言和Spring框架,这两者具有丰富的生态系统和成熟的开发和调试工具。
同时,天猫还使用了分布式缓存技术Redis来提高系统的访问速度和减轻数据库压力。
3.2 前端技术栈天猫的前端开发采用HTML、CSS和JavaScript等基本的Web技术。
此外,天猫还使用了React框架和Vue.js框架来构建富交互和高效的用户界面。
3.3 数据库技术天猫选择了MySQL作为主要的关系型数据库,具有稳定性和可靠性。
另外,为了应对高并发和大数据量的需求,天猫还使用了分布式数据库技术HBase和分布式文件系统HDFS。

1淘宝分布式架构演变案例详解淘宝亿级⾼并发分布式架构演进之路概述本⽂以淘宝作为例⼦,介绍从⼀百个并发到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让⼤家对架构的演进有⼀个整体的认知,⽂章最后汇总了⼀些架构设计的原则。
基本概念在介绍架构之前,为了避免部分读者对架构设计中的⼀些概念不了解,下⾯对⼏个最基础的概念进⾏介绍:分布式系统中的多个模块在不同服务器上部署,即可称为分布式系统,如Tomcat和数据库分别部署在不同的服务器上,或两个相同功能的Tomcat 分别部署在不同服务器上⾼可⽤系统中部分节点失效时,其他节点能够接替它继续提供服务,则可认为系统具有⾼可⽤性集群⼀个特定领域的软件部署在多台服务器上并作为⼀个整体提供⼀类服务,这个整体称为集群。
如Zookeeper中的Master和Slave分别部署在多台服务器上,共同组成⼀个整体提供集中配置服务。
在常见的集群中,客户端往往能够连接任意⼀个节点获得服务,并且当集群中⼀个节点掉线时,其他节点往往能够⾃动的接替它继续提供服务,这时候说明集群具有⾼可⽤性负载均衡请求发送到系统时,通过某些⽅式把请求均匀分发到多个节点上,使系统中每个节点能够均匀的处理请求负载,则可认为系统是负载均衡的正向代理和反向代理系统内部要访问外部⽹络时,统⼀通过⼀个代理服务器把请求转发出去,在外部⽹络看来就是代理服务器发起的访问,此时代理服务器实现的是正向代理;当外部请求进⼊系统时,代理服务器把该请求转发到系统中的某台服务器上,对外部请求来说,与之交互的只有代理服务器,此时代理服务器实现的是反向代理。
简单来说,正向代理是代理服务器代替系统内部来访问外部⽹络的过程,反向代理是外部请求访问系统时通过代理服务器转发到内部服务器的过程。
架构演进单机架构以淘宝作为例⼦。
在⽹站最初时,应⽤数量与⽤户数都较少,可以把Tomcat和数据库部署在同⼀台服务器上。
浏览器往发起请求时,⾸先经过DNS服务器(域名系统)把域名转换为实际IP地址10.102.4.1,浏览器转⽽访问该IP对应的Tomcat。
淘宝海量数据产品技术架构如下图2-1所示,即是淘宝的海量数据产品技术架构,咱们下面要针对这个架构来一一剖析与解读。
相信,看过本博客内其它文章的细心读者,定会发现,图2-1最初见于本博客内的此篇文章:从几幅架构图中偷得半点海量数据处理经验之上,同时,此图2-1最初发表于《程序员》8月刊,作者:朋春。
在此之前,有一点必须说明的是:本文下面的内容大都是参考自朋春先生的这篇文章:淘宝数据魔方技术架构解析所写,我个人所作的工作是对这篇文章的一种解读与关键技术和内容的抽取,以为读者更好的理解淘宝的海量数据产品技术架构。
与此同时,还能展示我自己读此篇的思路与感悟,顺带学习,何乐而不为呢?。
Ok,不过,与本博客内之前的那篇文章(几幅架构图中偷得半点海量数据处理经验)不同,本文接下来,要详细阐述这个架构。
我也做了不少准备工作(如把这图2-1打印了下来,经常琢磨):图2-1 淘宝海量数据产品技术架构好的,如上图所示,我们可以看到,淘宝的海量数据产品技术架构,分为以下五个层次,从上至下来看,它们分别是:数据源,计算层,存储层,查询层和产品层。
我们来一一了解这五层:1. 数据来源层。
存放着淘宝各店的交易数据。
在数据源层产生的数据,通过DataX,DbSync和Timetunel准实时的传输到下面第2点所述的“云梯”。
2. 计算层。
在这个计算层内,淘宝采用的是hadoop集群,这个集群,我们暂且称之为云梯,是计算层的主要组成部分。
在云梯上,系统每天会对数据产品进行不同的mapreduce计算。
3. 存储层。
在这一层,淘宝采用了两个东西,一个使MyFox,一个是Prom。
MyFox是基于MySQL的分布式关系型数据库的集群,Prom是基于hadoop Hbase技术的(读者可别忘了,在上文第一部分中,咱们介绍到了这个hadoop的组成部分之一,Hbase—在hadoop之内的一个分布式的开源数据库)的一个NoSQL的存储集群。
淘宝应对双"11"的技术架构分析双“11”最热门的话题是TB,最近正好和阿里的一个朋友聊淘宝的技术架构,发现很多有意思的地方,分享一下他们的解析资料:淘宝海量数据产品技术架构数据产品的一个最大特点是数据的非实时写入,正因为如此,我们可以认为,在一定的时间段内,整个系统的数据是只读的。
这为我们设计缓存奠定了非常重要的基础。
图1淘宝海量数据产品技术架构按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如图1所示),分别是数据源、计算层、存储层、查询层和产品层。
位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。
这一系列的数据是数据产品最原始的生命力所在。
在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件DataX、DbSync和Timetunnel准实时地传输到一个有1500个节点的Hadoop集群上,这个集群我们称之为“云梯”,是计算层的主要组成部分。
在“云梯”上,我们每天有大约40000个作业对1.5PB的原始数据按照产品需求进行不同的MapReduce计算。
这一计算过程通常都能在凌晨两点之前完成。
相对于前端产品看到的数据,这里的计算结果很可能是一个处于中间状态的结果,这往往是在数据冗余与前端计算之间做了适当平衡的结果。
不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希望能尽快推送到数据产品前端。
这种需求再采用“云梯”来计算效率将是比较低的,为此我们做了流式数据的实时计算平台,称之为“银河”。
“银河”也是一个分布式系统,它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
容易理解,“云梯”或者“银河”并不适合直接向产品提供实时的数据查询服务。
这是因为,对于“云梯”来说,它的定位只是做离线计算的,无法支持较高的性能和并发需求;而对于“银河”而言,尽管所有的代码都掌握在我们手中,但要完整地将数据接收、实时计算、存储和查询等功能集成在一个分布式系统中,避免不了分层,最终仍然落到了目前的架构上。