统计学第五版第四章课后习题答案
- 格式:ppt
- 大小:526.50 KB
- 文档页数:24


统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。


第4章练习题1、一组数据中岀现频数最多的变量值称为()A. 众数B.中位数C.四分位数D.平均数2、下列关于众数的叙述,不正确的是()A. —组数据可能存在多个众数B.众数主要适用于分类数据C. 一组数据的众数是唯一的D. 众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为()A.众数B.,中位数C.四分位数D.平均数4、一组数据排序后处于25%和75%位置上的值称为()A.众数B.中位数C.四分位数D.平均数5、非众数组的频数占总频数的比例称为()A.异众比率B.离散系数C.平均差D.标准差6、四分位差是()A. 上四分位数减下四分位数的结果|B. 下四分位数减上四分位数的结果C.下四分位数加上四分位数D. 下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为()A.平均差B.标准差C.极差D.四分位差8、各变量值与其平均数离差平方的平均数称为()A.极差B. 平均差C.,方差D.标准差9、变量值与其平均数的离差除以标准差后的值称为()A.标准分数B.离散系数C.方差D.标准差10、如果一个数据的标准分数-2,表明该数据()A.比平均数高出2个标准差B. ■比平均数低2个标准差C.等于2倍的平均数D. 等于2倍的标准差11、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围之内大约有()A.68%的数据B.95% 的数据C.99% 的数据D.100%勺数据12、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=4,其意义是()A. 至少有75%勺数据落在平均数加减4个标准差的范围之内B. 至少有89%的数据落在平均数加减4个标准差的范围之内C. 至少有94%的数据落在平均数加减4个标准差的范围之内D. 至少有99%的数据落在平均数加减4个标准差的范围之内13、离散系数的主要用途是()A.反映一组数据的离散程度B.反映一组数据的平均水平C.比较多组数据的离散程度D.比较多组数据的平均水平14、比较两组数据离散程度最适合的统计量是()A.极差B.平均差C.标准差D.离散系数15、偏态系数测度了数据分布的非对称性程度。

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

第四章一、单项选择题1.由反映总体单位某一数量特征的标志值汇总得到的指标是()A.总体单位总量B.质量指标C.总体标志总量D.相对指标2.各部分所占比重之和等于1或100%的相对数()A.比例相对数 B.比较相对数 C.结构相对数 D.动态相对数3.某企业工人劳动生产率计划提高5%,实际提高了10%,则提高劳动生产率的计划完成程度为()A.104.76%B.95.45%C.200%D.4.76%4.某企业计划规定产品成本比上年度降低10%实际产品成本比上年降低了14.5%,则产品成本计划完成程度()A.14.5%B.95%C.5%D.114.5%5.在一个特定总体内,下列说法正确的是( )A.只存在一个单位总量,但可以同时存在多个标志总量B.可以存在多个单位总量,但必须只有一个标志总量C.只能存在一个单位总量和一个标志总量D.可以存在多个单位总量和多个标志总量6.计算平均指标的基本要求是所要计算的平均指标的总体单位应是()A.大量的B.同质的C.有差异的D.不同总体的7.几何平均数的计算适用于求()A.平均速度和平均比率B.平均增长水平C.平均发展水平D.序时平均数8.一组样本数据为3、3、1、5、13、12、11、9、7这组数据的中位数是()A.3B.13C.7.1D.79.某班学生的统计学平均成绩是70分,最高分是96分,最低分是62分,根据这些信息,可以计算的测度离散程度的统计量是()A.方差B.极差C.标准差D.变异系数10.用标准差比较分析两个同类总体平均指标的代表性大小时,其基本的前提条件是( )A.两个总体的标准差应相等B.两个总体的平均数应相等C.两个总体的单位数应相等D.两个总体的离差之和应相等11.已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应采用()A.简单算术平均数B.加权算术平均数C.加权调和平均数D.几何平均数12.算术平均数、众数和中位数之间的数量关系决定于总体次数的分布状况。

第四章一.思考题1、一组数据的分布特征可以从哪几个方面进行测度?答:可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
2、怎样理解平均数在统计学中的地位?答:平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础。
从统计学思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
3、简述四分位数的计算方法。
答:四分位数是一组数据排序后处于25%和75%位子上的值。
四分位数是通过3个点将全部数据等分成4分,其中每部分包含25%的数据。
中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值和处在75%位置上的数值。
它是根据为分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数据就是四分位数。
4、对于比率数据的平均数为什么采用几何平均?答:几何平均数是适用于特殊数据的一种平均数,主要适用于计算平均比率。
当所掌握的变量值本身是比率的形式时,采用几何平均法计算平均比率更为合理。
5、简述众数、中位数、平均数的特点和应用场合。
答:众数是数据中出现次数次数最多的变量值。
主要应用于分类数据。
中位数是一组数据排序后处于中间位置的变量值,其适用于顺序数据。
平均数也称均值,它是一组数据相加后除以数据个数的结果,是集中去世的主要测量值,它适用于数值型数据。
6、简述异众比率、四分位差、方差、标准差的使用场合。
答:异众比率主要适合测度分类数据的离散程度,对于顺序数据以及数值型数据也可以计算异众比率。
四分位差主要用于测度顺序数据的离散程度。
方差和标准差适用于测度数值型数据的离散程度。
7、标准分数有哪些用途?答:首先是比较不同单位和不同质数据的位置。
其次是和正态分布结合起来,求得概率和标准分值之间的对应关系。
还有就是在假设检验和估计中应用。

第四章一、单项选择题1.由反映总体单位某一数量特征的标志值汇总得到的指标是()A.总体单位总量B.质量指标C.总体标志总量D.相对指标2.各部分所占比重之和等于1或100%的相对数()A.比例相对数B.比较相对数C.结构相对数D.动态相对数3.某企业工人劳动生产率计划提高5%,实际提高了10%,则提高劳动生产率的计划完成程度为()A.104.76%B.95.45%C.200%D.4.76%4.某企业计划规定产品成本比上年度降低10%实际产品成本比上年降低了14.5%,则产品成本计划完成程度()A.14.5%B.95%C.5%D.114.5%5.在一个特定总体内,下列说法正确的是( )A.只存在一个单位总量,但可以同时存在多个标志总量B.可以存在多个单位总量,但必须只有一个标志总量C.只能存在一个单位总量和一个标志总量D.可以存在多个单位总量和多个标志总量6.计算平均指标的基本要求是所要计算的平均指标的总体单位应是()A.大量的B.同质的C.有差异的D.不同总体的7.几何平均数的计算适用于求()A.平均速度和平均比率B.平均增长水平C.平均发展水平D.序时平均数8.一组样本数据为3、3、1、5、13、12、11、9、7这组数据的中位数是()A.3B.13C.7.1D.79.某班学生的统计学平均成绩是70分,最高分是96分,最低分是62分,根据这些信息,可以计算的测度离散程度的统计量是()A.方差B.极差C.标准差D.变异系数10.用标准差比较分析两个同类总体平均指标的代表性大小时,其基本的前提条件是( )A.两个总体的标准差应相等B.两个总体的平均数应相等C.两个总体的单位数应相等D.两个总体的离差之和应相等11.已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应采用()A.简单算术平均数B.加权算术平均数C.加权调和平均数D.几何平均数12.算术平均数、众数和中位数之间的数量关系决定于总体次数的分布状况。
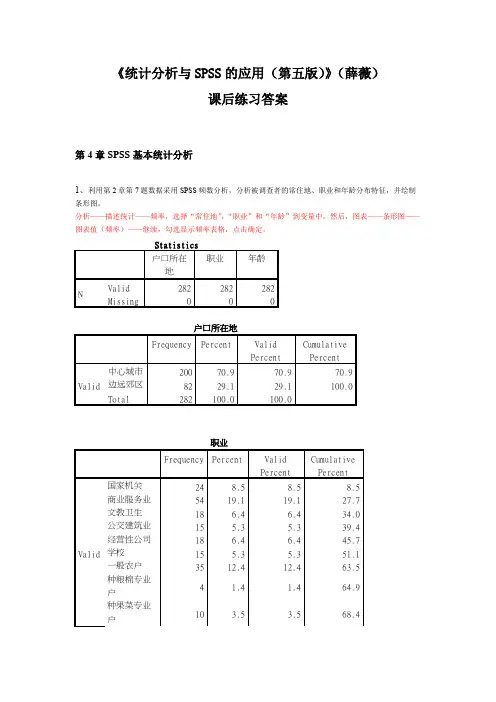
sintheirbee a n d A l l t h i n g s i n t h e i r b e i n g a r e g o o df o r s o 分析:本次调查的有效样本为282份。
常住地的分布状况是:在中心城市的人最多,有200人,而在边远郊区只有82人;职业的分布状况是:在商业服务业的人最多,其次是一般农户和金融机构;年龄方面:在35-50岁的人最多。
由于变量中无缺失数据,因此频数分布表中的百分比相同。
2、利用第2章第7题数据,从数据的集中趋势、离散程度以及分布形状等角度,分析被调查者本次存款金额的基本特征,并与标准正态分布曲线进行对比。
进一步,对不同常住地储户存款金额的基本特征进行对比分析。
分析——描述统计——描述,选择存款金额到变量中。
点击选项,勾选均值、标准差、方差、最小值、最大值、范围、偏度、峰度、按变量列表,点击继续——确定。
分析:由表中可以看出,有效样本为282份,存(取)款金额的均值是4738.09,标准差为10945.09,峰度系数为33.656,偏度系数为5.234。
与标准正态分布曲线进行对比,由峰度系数可以看出,此表的存款金额的数据分布比标准正态分布更陡峭;由偏度系数可以看出,此表的存款金额的数据为右偏分布,表明此表的存款金额均值对平均水平的测度偏大。
分析:由表中可以看出,中心城市有200人,边远郊区为82人。
两部分样本存取款金额均呈右偏尖峰分布,且边远郊区更明显。
i n g s i n t h e i r b e i n g a r e g o o d f o r s o 3、利用第2章第7题数据,如果假设存款金额服从正态分布,能否利用本章所讲解的功能,找到存款金额“与众不同”的样本,并说明理由。
分析——描述统计——描述,选择存款金额到变量中。
对“将标准化得分另存为变量”打上勾,然后对数据编辑窗口中的最后一列变量标准化Z 变量进行排序,并观察,找到它的绝对值大于3的都是“与众不同”的样本。
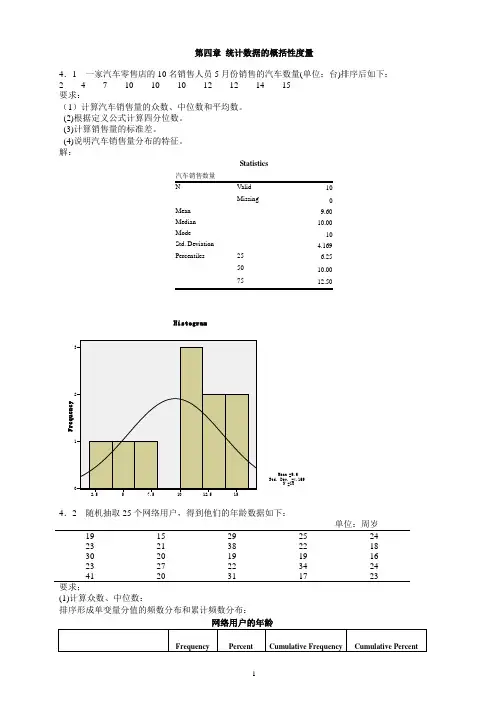
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数:()l g 25l g ()1.3981115.64l g (2)l g 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取5 3、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。

大学统计学第五版习题答案大学统计学第五版习题答案统计学作为一门重要的学科,对于各个领域的研究和实践都具有重要的意义。
在大学学习统计学时,习题是巩固知识、提高能力的重要途径。
大学统计学第五版是一本经典的教材,其中的习题涵盖了各个知识点,对于学生来说是一次很好的训练机会。
下面将给出一些大学统计学第五版习题的答案,希望对学生们的学习有所帮助。
第一章:统计学导论1. 样本容量的确定答案:样本容量的确定需要考虑到以下几个因素:总体大小、总体方差、置信水平和允许的误差范围。
一般来说,总体大小越大,样本容量越小;总体方差越大,样本容量越大;置信水平越高,样本容量越大;允许的误差范围越小,样本容量越大。
第二章:统计学数据的描述1. 描述性统计的应用答案:描述性统计是对数据进行整理、总结和分析的方法。
它可以帮助我们了解数据的特征、趋势和分布情况。
在实际应用中,描述性统计可以用于制定市场调研报告、分析销售数据、评估产品质量等方面。
第三章:概率1. 概率的计算答案:概率的计算可以通过频率法和几何法来进行。
频率法是通过实验或观察来估计事件发生的可能性,即事件发生的次数除以总次数。
几何法是通过对样本空间和事件发生的区域进行几何分析来计算概率。
第四章:离散型随机变量和概率分布1. 二项分布的应用答案:二项分布是离散型随机变量的一种常见分布。
它适用于只有两个可能结果的实验,如抛硬币、生男生女等。
在实际应用中,二项分布可以用于预测产品合格率、判断市场需求等方面。
第五章:连续型随机变量和概率分布1. 正态分布的性质答案:正态分布是连续型随机变量的一种常见分布。
它具有对称性、钟形曲线和均值和标准差唯一确定等性质。
正态分布在实际应用中非常广泛,例如用于身高体重的统计、质量控制等方面。
第六章:抽样分布和点估计1. 置信区间的计算答案:置信区间是用于估计总体参数的范围。
计算置信区间时需要考虑样本容量、样本均值、样本标准差和置信水平等因素。
第四章 静态指标分析法(一)一、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和用于测度品质数据集中趋势的分布特征,用于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、几何平均数是计算和的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的比其算术平均数更能代表全部工人工资的总体水平。
二.选择题单选题:1.反映的时间状况不同,总量指标可分为( )A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数( )A 接近标志值小的一方B 接近标志值大的一方C 接近次数少的一方D 接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现( )A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年( )A 提高B 不变C 降低D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越小,则( )A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越高C 说明变量值越分散,平均数代表性越高D 说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:07.7,70==甲甲σX ;乙数列:41.3,7==乙乙σX 根据以上资料可直接判断( )A 甲数列的平均数代表性大B 乙数列的平均数代表性大C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百人手机拥有量为90部,这个指标是 ( )A 、比例相对指标B 、比较相对指标C 、结构相对指标D 、强度相对指标 9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为 ( ) A 、左偏分布 B 、右偏分布 C 、对称分布 D 、无法判断10、加权算术平均数的大小 ( )A 主要受各组标志值大小的影响,与各组次数多少无关;B 主要受各组次数多少的影响,与各组标志值大小无关;C 既与各组标志值大小无关,也与各组次数多少无关;D 既与各组标志值大小有关,也受各组次数多少的影响11、已知一分配数列,最小组限为30元,最大组限为200元,不可能是平均数的为 ( ) A 、50元 B 、80元 C 、120元 D 、210元12、比较两个单位的资料,甲的标准差小于乙的标准差,则 ( ) A 两个单位的平均数代表性相同 B 甲单位平均数代表性大于乙单位C 乙单位平均数代表性大于甲单位D 不能确定哪个单位的平均数代表性大 13、若单项数列的所有标志值都增加常数9,而次数都减少三分之一,则其算术平均数 ( ) A 、增加9 B 、增加6C 、减少三分之一 D 、增加三分之二 14、如果数据分布很不均匀,则应编制( )A 开口组B 闭口组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( ) A 总体性B 全面性C 同质性D 可比性16、某企业的职工工资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为()A1500元 B 1600元 C 1750元D 2000元 17、统计分组的首要问题是( )A 选择分组变量和确定组限B 按品质标志分组C 运用多个标志进行分组,形成一个分组体系D 善于运用复合分组18、某连续变量数列,其末组为开口组,下限为200,又知其邻组的组中值为170,则末组组中值为( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开支情况,最合适的调查方式是:() A 普查B 抽样调查C 典型调查D 重点调查21、已知两个同类企业的职工平均工资的标准差分别为5元和6元,而平均工资分别为3000元,3500元则两企业的工资离散程度为 ( )A 甲大于乙B 乙大于甲C 一样的D 无法判断 22、加权算术平均数的大小取决于( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,而标志值仍然不变.那么算术平均数( ) A 不变 B 扩大到5倍 C 减少为原来的1/5 D 不能预测其变化 24、 计算平均比率最好用 ( )A 算术平均数B 调和平均数C 几何平均数D 中位数25、若两数列的标准差相等而平均数不同,在比较两数列的离散程度大小时,应采用() A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布B正态分布 C 右偏分布DU型分布28、一次小型出口商品洽谈会,所有厂商的平均成交额的方差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁生产的基本情况,调查了上钢、鞍钢等十几个大型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。
第四章统计数据的归纳性胸怀4. 1 一家汽车零售店的10 名销售人员 5 月份销售的汽车数目(单位:台 )排序后以下:2 4 7 10 10 10 12 12 14 15要求:( 1)计算汽车销售量的众数、中位数和均匀数。
(2)依据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量散布的特点。
解:Statistics汽车销售数目N ValidMissingMeanMedianModeStd. DeviationPercentiles 255075Histogram32ycneuqerF1Mean =9.6Std. Dev. =4.169N =10 02.557.51012.515汽车销售数目109.6010.0010 4.169 6.25 10.00 12.504. 2 随机抽取 25 个网络用户,获得他们的年纪数据以下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23 要求;(1)计算众数、中位数:排序形成单变量分值的频数散布和累计频数散布:网络用户的年纪Frequency Percent Cumulative Frequency Cumulative Percent15 1 4.0 1 4.016 1 4.0 2 8.017 1 4.0 3 12.018 1 4.0 4 16.019 3 12.0 7 28.020 2 8.0 9 36.021 1 4.0 10 40.022 2 8.0 12 48.023 3 12.0 15 60.0Valid 24 2 8.0 17 68.025 1 4.0 18 72.027 1 4.0 19 76.029 1 4.0 20 80.030 1 4.0 21 84.031 1 4.0 22 88.034 1 4.0 23 92.038 1 4.0 24 96.041 1 4.0 25 100.0Total 25 100.0从频数看出,众数Mo 有两个: 19、 23;从累计频数看,中位数Me=23 。
第4章练习题1、一组数据中出现频数最多的变量值称为()A。
众数 B.中位数 C。
四分位数 D.平均数2、下列关于众数的叙述,不正确的是()A。
一组数据可能存在多个众数 B.众数主要适用于分类数据C。
一组数据的众数是唯一的 D。
众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为()A。
众数 B.中位数 C。
四分位数 D.平均数4、一组数据排序后处于25%和75%位置上的值称为()A.众数 B。
中位数 C。
四分位数 D。
平均数5、非众数组的频数占总频数的比例称为()A.异众比率 B。
离散系数 C.平均差 D.标准差6、四分位差是()A.上四分位数减下四分位数的结果 B。
下四分位数减上四分位数的结果C。
下四分位数加上四分位数 D.下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为()A.平均差 B。
标准差 C.极差 D.四分位差8、各变量值与其平均数离差平方的平均数称为()A.极差B.平均差C.方差 D。
标准差9、变量值与其平均数的离差除以标准差后的值称为()A.标准分数B.离散系数 C。
方差 D.标准差10、如果一个数据的标准分数—2,表明该数据()A。
比平均数高出2个标准差 B.比平均数低2个标准差C。
等于2倍的平均数 D。
等于2倍的标准差11、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围之内大约有()A.68%的数据B.95%的数据C.99%的数据D。
100%的数据12、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=4,其意义是()A。
至少有75%的数据落在平均数加减4个标准差的范围之内B。
至少有89%的数据落在平均数加减4个标准差的范围之内C. 至少有94%的数据落在平均数加减4个标准差的范围之内D。
至少有99%的数据落在平均数加减4个标准差的范围之内13、离散系数的主要用途是()A。
反映一组数据的离散程度 B。
反映一组数据的平均水平C.比较多组数据的离散程度D.比较多组数据的平均水平14、比较两组数据离散程度最适合的统计量是()A.极差B.平均差C.标准差 D。
第一章导论1.1(1)数值型变量。
(2)分类变量。
(3)离散型变量。
(4)顺序变量。
(5)分类变量。
1.2(1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。
(2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。
1.3(1)总体是所有IT从业者的集合。
(2)数值型变量。
(3)分类变量。
(4)截面数据。
1.4(1)总体是所有在网上购物的消费者的集合。
(2)分类变量。
(3)参数是所有在网上购物者的月平均花费。
(4)参数(5)推断统计方法。
第二章数据的搜集1.什么是二手资料?使用二手资料需要注意些什么?与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。
使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。
在引用二手资料时,要注明数据来源。
2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。
概率抽样是指抽样时按一定概率以随机原则抽取样本。
每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。
如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
非概率抽样也适合市场调查中的概念测试。
3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法?实验式、观察式等。
统计学习题第四章_数据分布特征的描述习题答案第四章数据分布特征的描述习题一、填空题1、数据分布集中趋势的测度值(指标)主要有众数、中位数和均值。
其中众数和中位数用于测度品质数据集中趋势的分布特征,均值用于测度数值型数据集中趋势的分布特征。
2、标准差是反映数据离散程度的最主要指标(测度值)。
3、几何平均数是计算平均比率和平均速度的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算标准系数。
5、在测定数据分布特征时,如果X?Me?M0,则认为数据呈对称分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的众数(中位数)比其算术平均数更能代表全部工人工资的总体水平。
二、选择题单选题:1、反映的时间状况不同,总量指标可分为((2))(1)总量指标和时点总量指标(2)时点总量指标和时期总量指标(3)时期总量指标和时间指标(4)实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成((2))(1)5.5% (2)5% (3)115.5% (4)15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数((2))(1)接近标志值小的一方(2)接近标志值大的一方(3)接近次数少的一方(4)接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现((1))(1)可变的(2)总是各组单位数(2)总是各组标志总量(4)总是各组标志值5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年((3))(1)提高(2)不变(3)降低(4)不能做结论6、在变异指标(离散程度测度值)中,其数值越小,则((2))(1)说明变量值越分散,平均数代表性越低(2)说明变量值越集中,平均数代表性越高(3)说明变量值越分散,平均数代表性越高(4)说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:XX乙甲?70,?甲?7.07;乙数列: ?7,?乙?3.41根据( (4))(1)甲数列的平均数代表性大(2)乙数列的平均数代表性大(3)两数列的平均数代表性相同(4)不能直接判别三、多选题:1、某企业计划2000年成本降低率为8%,实际降低了10%。