基于案例讲解Storm实时流计算
- 格式:pptx
- 大小:1.42 MB
- 文档页数:19

Storm - 大数据Big Data实时处理架构什么是Storm?Storm是:• 快速且可扩展伸缩• 容错• 确保消息能够被处理• 易于设置和操作• 开源的分布式实时计算系统- 最初由Nathan Marz开发- 使用Java 和 Clojure 编写Storm和Hadoop主要区别是实时和批处理的区别:Storm概念组成:Spout 和Bolt组成Topology。
Tuple是Storm的数据模型,如['jdon',12346]多个Tuple组成事件流:Spout是读取需要分析处理的数据源,然后转为Tuples,这些数据源可以是Web日志、 API调用、数据库等等。
Spout相当于事件流的生产者。
Bolt 处理Tuples然后再创建新的Tuples流,Bolt相当于事件流的消费者。
Bolt 作为真正业务处理者,主要实现大数据处理的核心功能,比如转换数据,应用相应过滤器,计算和聚合数据(比如统计总和等等) 。
以Twitter的某个Tweet为案例,看看Storm如何处理:这些tweett贴内容是:“No Small Cell Lung #Cancer(没有小细胞肺癌#癌症)” "An #OnCology Consult...."这些贴被Spout读取以后,产生Tuple,字段名是tweet,内容是"No Small Cell Lung #Cancer",格式类似:['No Small Cell Lung #Cancer',133221]。
然后进入被流消费者Bolt进行处理,第一个Bolt是SplitSentence,将tuple内容进行分离,结果成为:一个个单词:"No" "Small" "Cell" "Lung" "#Cancer" ;然后经过第二个Bolt进行过滤HashTagFilter处理,Hash标签是单词中用#标注的,也就是Cancer;再经过HasTagCount计数,可以本地内存缓存这个计数结果,最后通过PrinterBolt打印出标签单词统计结果。



论Storm分布式实时计算工具作者:沈超邓彩凤来源:《中国科技纵横》2014年第03期【摘要】互联网的应用催生了一大批新的数据处理技术,storm分布式实时处理工具以其强大的数据处理能力、可靠性高、扩展性好等特点,在近几年得到越来越广泛的关注和应用。
【关键词】分布式实时计算流处理1 背景及特点互联网的应用正在越来越深入的改变人们的生活,互联网技术也在不断发展,尤其是大数据处理技术,过去的十年是大数据处理技术变革的十年,MapReduce,Hadoop以及一些相关的技术使得我们能处理的数据量比以前要大得多得多。
但是这些数据处理技术都不是实时的系统,或者说,它们设计的目的也不是为了实时计算。
没有什么办法可以简单地把hadoop变成一个实时计算系统。
实时数据处理系统和批量数据处理系统在需求上有着本质的差别。
然而大规模的实时数据处理已经越来越成为一种业务需求了,而缺少一个“实时版本的hadoop”已经成为数据处理整个生态系统的一个巨大缺失。
而storm的出现填补了这个缺失。
Storm出现之前,互联网技术人员可能需要自己手动维护一个由消息队列和消息处理者所组成的实时处理网络,消息处理者从消息队列取出一个消息进行处理,更新数据库,发送消息给其它队列等等。
不幸的是,这种方式有以下几个缺陷:单调乏味:技术人员花费了绝大部分开发时间去配置把消息发送到哪里,部署消息处理者,部署中间消息节点—设计者的大部分时间花在设计,配置这个数据处理框架上,而真正关心的消息处理逻辑在代码里面占的比例很少。
脆弱:不够健壮,设计者要自己写代码保证所有的消息处理者和消息队列正常运行。
伸缩性差:当一个消息处理者的消息量达到阀值,需要对这些数据进行分流,配置这些新的处理者以让他们处理分流的消息。
Storm定义了一批实时计算的原语。
如同hadoop大大简化了并行批量数据处理,storm的这些原语大大简化了并行实时数据处理。
storm的一些关键特性如下:适用场景广泛:storm可以用来处理消息和更新数据库(消息流处理),对一个数据量进行持续的查询并返回客户端(持续计算),对一个耗资源的查询作实时并行化的处理(分布式方法调用),storm的这些基础原语可以满足大量的场景。



大数据开发技术之Storm原理与实践一、Storm简介1. 引例在介绍Storm之前,我们先看一个日志统计的例子:假如我们想要根据用户的访问日志统计使用斗鱼客户端的用大数据培训户的地域分布情况,一般情况下我们会分这几步:•取出访问日志中客户端的IP•把IP转换成对应地域•按照地域进行统计Hadoop貌似就可以轻松搞定:•map做ip提取,转换成地域•reduce以地域为key聚合,计数统计•从HDFS取出结果如果有时效性要求呢?•小时级:还行,每小时跑一个MapReduce Job•10分钟:还凑合能跑•5分钟:够呛了,等槽位可能要几分钟呢•1分钟:算了吧,启动Job就要几十秒呢•秒级:… 要满足秒级别的数据统计需求,需要•进程常驻运行;•数据在内存中Storm正好适合这种需求。
2. 特性Storm是一个分布式实时流式计算平台。
主要特性如下:•简单的编程模型:类似于MapReduce降低了并行批处理复杂性,Storm降低了实时处理的复杂性,只需实现几个接口即可(Spout实现ISpout接口,Bolt实现IBolt接口)。
•支持多种语言:你可以在Storm之上使用各种编程语言。
默认支持Clojure、Java、Ruby和Python。
要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
•容错性:nimbus、supervisor都是无状态的, 可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,任务照常进行; 当worker失败后, supervisor会尝试在本机重启它。
•分布式:计算是在多个线程、进程和服务器之间并行进行的。
•持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
•可靠的消息处理:Storm保证每个消息至少能得到一次完整处理。
任务失败时,它会负责从消息源重试消息(ack机制)。
•快速、实时:Storm保证每个消息能能得到快速的处理。

流式计算strom,Strom解决的问题,实现实时计算系统要解决那些问题,离线计算是什么,流式计算什么,离线和实时计算区别,strom应用场景,Strorm架构图和编程模型(来自学习资料)1、背景-流式计算与storm2011年在海量数据处理领域,Hadoop是人们津津乐道的技术,Hadoop不仅可以用来存储海量数据,还以用来计算海量数据。
因为其高吞吐、高可靠等特点,很多互联网公司都已经使用Hadoop来构建数据仓库,高频使用并促进了Hadoop 生态圈的各项技术的发展。
一般来讲,根据业务需求,数据的处理可以分为离线处理和实时处理,在离线处理方面Hadoop提供了很好的解决方案,但是针对海量数据的实时处理却一直没有比较好的解决方案。
就在人们翘首以待的时间节点,storm横空出世,与生俱来的分布式、高可靠、高吞吐的特性,横扫市面上的一些流式计算框架,渐渐的成为了流式计算的首选框架。
如果庞麦郎在的话,他一定会说,这就是我要的滑板鞋!在2013年,阿里巴巴开源了基于storm的设计思路使用java重现编写的流式计算框架jstorm。
那jstorm是什么呢?在jstorm早期的介绍中,一般会出现下面的语句:JStorm 比Storm更稳定,更强大,更快,Storm上跑的程序,一行代码不变可以运行在JStorm上。
在最新的介绍中,jstorm的团队是这样介绍的:JStorm 是一个类似Hadoop MapReduce的系统,用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障,调度器立即分配一个新的Worker 替换这个失效的Worker。
因此,从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。
从系统角度,JStorm一套类似MapReduce的调度系统。
从数据的角度,是一套基于流水线的消息处理机制。


实时计算Storm 核心技术及其在报文系统中的应用摘要1随着应用创新的层出不穷和数据类型的不断丰富,企业面对的数据量急剧增长,随之而来的实时处理需求给管理者和开发人员带来了多方面的困难。
一方面,源源不断的数据流带来了硬件成本增加、难以有效管控等诸多问题;另一方面,传统的数据批处理系统无法满足实时数据处理需求,服务延迟及业务连续性不佳等问题比较严重。
为解决上述问题,作为一个优秀的实时计算框架,Storm迅速在业界得到广泛应用与认可。
本文对Storm平台特点及其背后的核心技术进行了深入剖析,并结合公司实时服务现状,特别是现有的报文系统需求,得到了一个基于Storm 的、满足高并发及业务隔离要求的原型系统,以期对下一代报文系统的设计与实现提供帮助。
目录1. Storm及报文系统概述 (1)1.1 流式数据与Storm的诞生 (1)1.2 我司实时服务现状 (2)1.3 报文系统概述 (2)2. Storm关键技术 (3)2.1 系统架构 (3)2.1.1 调度系统 (3)2.1.2 通信模型 (5)2.2 拓扑与数据流 (6)2.2.1 Topology、Spout及Bolt (6)2.2.2 数据流Grouping策略 (9)2.3 Ack机制 (10)3. Storm中的高层机制 (11)3.1 事务处理 (11)3.2 Trident API (13)3.3 DRPC (14)4. 基于Storm的报文系统初探 (14)4.1 报文系统需求分析 (14)4.2 原型系统设计 (15)4.3 原型系统实现 (17)5. 总结与展望 (20)1. Storm及报文系统概述1.1 流式数据与Storm 的诞生随着互联网的高速发展,各类数据应用层出不穷,而数据除了规模的爆炸性增长之外,新的形态也不断涌现。
流式数据便是这些新型大数据中的一类典型。
与传统数据的静态、批处理和持久化不同,流式数据是连续、无边界且瞬间性的。
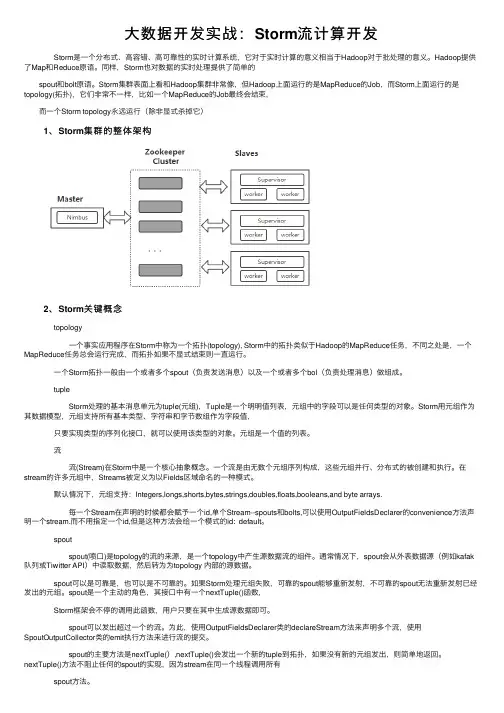
⼤数据开发实战:Storm流计算开发 Storm是⼀个分布式、⾼容错、⾼可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义。
Hadoop提供了Map和Reduce原语。
同样,Storm也对数据的实时处理提供了简单的 spout和bolt原语。
Storm集群表⾯上看和Hadoop集群⾮常像,但Hadoop上⾯运⾏的是MapReduce的Job,⽽Storm上⾯运⾏的是topology(拓扑),它们⾮常不⼀样,⽐如⼀个MapReduce的Job最终会结束, ⽽⼀个Storm topology永远运⾏(除⾮显式杀掉它) 1、Storm集群的整体架构 2、Storm关键概念 topology ⼀个事实应⽤程序在Storm中称为⼀个拓扑(topology), Storm中的拓扑类似于Hadoop的MapReduce任务,不同之处是,⼀个MapReduce任务总会运⾏完成,⽽拓扑如果不显式结束则⼀直运⾏。
⼀个Storm拓扑⼀般由⼀个或者多个spout(负责发送消息)以及⼀个或者多个bol(负责处理消息)做组成。
tuple Storm处理的基本消息单元为tuple(元组),Tuple是⼀个明明值列表,元组中的字段可以是任何类型的对象。
Storm⽤元组作为其数据模型,元组⽀持所有基本类型、字符串和字节数组作为字段值, 只要实现类型的序列化接⼝,就可以使⽤该类型的对象。
元组是⼀个值的列表。
流 流(Stream)在Storm中是⼀个核⼼抽象概念。
⼀个流是由⽆数个元组序列构成,这些元组并⾏、分布式的被创建和执⾏。
在stream的许多元组中,Streams被定义为以Fields区域命名的⼀种模式。
默认情况下,元组⽀持:Integers,longs,shorts,bytes,strings,doubles,floats,booleans,and byte arrays. 每⼀个Stream在声明的时候都会赋予⼀个id,单个Stream--spouts和bolts,可以使⽤OutputFieldsDeclarer的convenience⽅法声明⼀个stream.⽽不⽤指定⼀个id,但是这种⽅法会给⼀个模式的id: default。
Storm⼤数据实时计算⼤数据也是构建各类系统的时候⼀种全新的思维,以及架构理念,⽐如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等storm,在做热数据这块,如果要做复杂的热数据的统计和分析,亿流量,⾼并发的场景下,最合适的技术就是storm,没有其他举例说明:Storm:实时缓存热点数据统计->缓存预热->缓存热点数据⾃动降级Hive:Hadoop⽣态栈⾥⾯,做数据仓库的⼀个系统,⾼并发访问下,海量请求⽇志的批量统计分析,⽇报周报⽉报,接⼝调⽤情况,业务使⽤情况,等等我所知,在⼀些⼤公司⾥⾯,是有些⼈是将海量的请求⽇志打到hive⾥⾯,做离线的分析,然后反过来去优化⾃⼰的系统Spark:离线批量数据处理,⽐如从DB中⼀次性批量处理⼏亿数据,清洗和处理后写⼊Redis中供后续的系统使⽤,⼤型互联⽹公司的⽤户相关数据ZooKeeper:分布式系统的协调,分布式锁,分布式选举->⾼可⽤HA架构,轻量级元数据存储HBase:海量数据的在线存储和简单查询,替代MySQL分库分表,提供更好的伸缩性java底层,对应的是海量数据,然后要做⼀些简单的存储和查询,同时数据增多的时候要快速扩容mysql分库分表就不太合适了,mysql分库分表扩容,还是⽐较⿇烦的Elasticsearch:海量数据的复杂检索以及搜索引擎的构建,⽀撑有⼤量数据的各种企业信息化系统的搜索引擎,电商/新闻等⽹站的搜索引擎,等等mysql的like "%xxxx%",更加合适⼀些,性能更加好hystrix,分布式系统的⾼可⽤性的限流,熔断,降级,等等,⼀些措施,缓存雪崩的⽅案,限流的技术⼀、Storm到底是什么?1、mysql,hadoop与stormmysql:事务性系统,⾯临海量数据的尴尬hadoop:离线批处理storm:实时计算3、storm的特点是什么?(1)⽀撑各种实时类的项⽬场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进⾏查询或计算,同时将最新的计算结果持续的推送给客户端展⽰,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进⾏并⾏化,基于DRPC,即分布式RPC调⽤,单表30天数据,并⾏化,每个进程查询⼀天数据,最后组装结果storm做各种实时类的项⽬都ok(2)⾼度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并⾏度就可以了,storm会⾃动部署更多的进程和线程到其他的机器上去,⽆缝快速扩容扩容起来,超⽅便(3)数据不丢失的保证:storm的消息可靠机制开启后,可以保证⼀条数据都不丢数据不丢失,也不重复计算(4)超强的健壮性:从历史经验来看,storm⽐hadoop、spark等⼤数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧特别的健壮,稳定性和可⽤性很⾼(5)使⽤的便捷性:核⼼语义⾮常的简单,开发起来效率很⾼⽤起来很简单,开发API还是很简单的⼆、Storm的集群架构以及核⼼概念1、Storm的集群架构Nimbus,Supervisor,ZooKeeper,Worker,Executor,Task2、Storm的核⼼概念Topology,Spout,Bolt,Tuple,Stream拓扑:务虚的⼀个概念Spout:数据源的⼀个代码组件,就是我们可以实现⼀个spout接⼝,写⼀个java类,在这个spout代码中,我们可以⾃⼰尝试去数据源获取数据,⽐如说从kafka中消费数据bolt:⼀个业务处理的代码组件,spout会将数据传送给bolt,各种bolt还可以串联成⼀个计算链条,java类实现了⼀个bolt接⼝⼀堆spout+bolt,就会组成⼀个topology,就是⼀个拓扑,实时计算作业,spout+bolt,⼀个拓扑涵盖数据源获取/⽣产+数据处理的所有的代码逻辑,topologytuple:就是⼀条数据,每条数据都会被封装在tuple中,在多个spout和bolt之间传递stream:就是⼀个流,务虚的⼀个概念,抽象的概念,源源不断过来的tuple,就组成了⼀条数据流并⾏度:Worker->Executor->Task流分组:Task与Task之间的数据流向关系Shuffle Grouping:随机发射,负载均衡Fields Grouping:根据某⼀个,或者某些个,fields,进⾏分组,那⼀个或者多个fields如果值完全相同的话,那么这些tuple,就会发送给下游bolt的其中固定的⼀个task你发射的每条数据是⼀个tuple,每个tuple中有多个field作为字段⽐如tuple,3个字段,name,age,salaryAll GroupingGlobal GroupingNone GroupingDirect GroupingLocal or Shuffle Grouping 实现⼀个简单的列⼦:import java.util.HashMap;import java.util.Map;import java.util.Random;import org.apache.storm.Config;import org.apache.storm.LocalCluster;import org.apache.storm.StormSubmitter;import org.apache.storm.spout.SpoutOutputCollector;import org.apache.storm.task.OutputCollector;import org.apache.storm.task.TopologyContext;import org.apache.storm.topology.OutputFieldsDeclarer;import org.apache.storm.topology.TopologyBuilder;import org.apache.storm.topology.base.BaseRichBolt;import org.apache.storm.topology.base.BaseRichSpout;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Tuple;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class WordCountTopology {/*** spout** spout,继承⼀个基类,实现接⼝,这个⾥⾯主要是负责从数据源获取数据*/public static class RandomSentenceSpout extends BaseRichSpout {private static final long serialVersionUID = 3699352201538354417L;private static final Logger LOGGER = LoggerFactory.getLogger(RandomSentenceSpout.class);private SpoutOutputCollector collector;private Random random;/*** open⽅法** open⽅法,是对spout进⾏初始化的** ⽐如说,创建⼀个线程池,或者创建⼀个数据库连接池,或者构造⼀个httpclient**/@SuppressWarnings("rawtypes")public void open(Map conf, TopologyContext context,SpoutOutputCollector collector) {// 在open⽅法初始化的时候,会传⼊进来⼀个东西,叫做SpoutOutputCollector// 这个SpoutOutputCollector就是⽤来发射数据出去的this.collector = collector;// 构造⼀个随机数⽣产对象this.random = new Random();}/*** nextTuple⽅法* 这个spout类,之前说过,最终会运⾏在task中,某个worker进程的某个executor线程内部的某个task中* 那个task会负责去不断的⽆限循环调⽤nextTuple()⽅法* 只要的话呢,⽆限循环调⽤,可以不断发射最新的数据出去,形成⼀个数据流*/public void nextTuple() {Utils.sleep(100);String[] sentences = new String[]{"the cow jumped over the moon", "an apple a day keeps the doctor away", "four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};String sentence = sentences[random.nextInt(sentences.length)];("【发射句⼦】sentence=" + sentence);// 这个values,你可以认为就是构建⼀个tuple// tuple是最⼩的数据单位,⽆限个tuple组成的流就是⼀个streamcollector.emit(new Values(sentence));}/*** declareOutputFielfs这个⽅法* 很重要,这个⽅法是定义⼀个你发射出去的每个tuple中的每个field的名称是什么*/public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("sentence"));}}/*** 写⼀个bolt,直接继承⼀个BaseRichBolt基类* 实现⾥⾯的所有的⽅法即可,每个bolt代码,同样是发送到worker某个executor的task⾥⾯去运⾏ */public static class SplitSentence extends BaseRichBolt {private static final long serialVersionUID = 6604009953652729483L;private OutputCollector collector;/*** 对于bolt来说,第⼀个⽅法,就是prepare⽅法** OutputCollector,这个也是Bolt的这个tuple的发射器**/@SuppressWarnings("rawtypes")public void prepare(Map conf, TopologyContext context, OutputCollector collector) {this.collector = collector;}/*** execute⽅法** 就是说,每次接收到⼀条数据后,就会交给这个executor⽅法来执⾏**/public void execute(Tuple tuple) {String sentence = tuple.getStringByField("sentence");String[] words = sentence.split(" ");for(String word : words) {collector.emit(new Values(word));}}/*** 定义发射出去的tuple,每个field的名称*/public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word"));}}public static class WordCount extends BaseRichBolt {private static final long serialVersionUID = 7208077706057284643L;private static final Logger LOGGER = LoggerFactory.getLogger(WordCount.class);private OutputCollector collector;private Map<String, Long> wordCounts = new HashMap<String, Long>();@SuppressWarnings("rawtypes")public void prepare(Map conf, TopologyContext context, OutputCollector collector) {this.collector = collector;}public void execute(Tuple tuple) {String word = tuple.getStringByField("word");Long count = wordCounts.get(word);if(count == null) {count = 0L;}count++;wordCounts.put(word, count);("【单词计数】" + word + "出现的次数是" + count);collector.emit(new Values(word, count));}public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word", "count"));}}public static void main(String[] args) {// 在main⽅法中,会去将spout和bolts组合起来,构建成⼀个拓扑TopologyBuilder builder = new TopologyBuilder();// 这⾥的第⼀个参数的意思,就是给这个spout设置⼀个名字// 第⼆个参数的意思,就是创建⼀个spout的对象// 第三个参数的意思,就是设置spout的executor有⼏个builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2);builder.setBolt("SplitSentence", new SplitSentence(), 5).setNumTasks(10).shuffleGrouping("RandomSentence");// 这个很重要,就是说,相同的单词,从SplitSentence发射出来时,⼀定会进⼊到下游的指定的同⼀个task中 // 只有这样⼦,才能准确的统计出每个单词的数量// ⽐如你有个单词,hello,下游task1接收到3个hello,task2接收到2个hello// 5个hello,全都进⼊⼀个taskbuilder.setBolt("WordCount", new WordCount(), 10).setNumTasks(20).fieldsGrouping("SplitSentence", new Fields("word"));Config config = new Config();// 说明是在命令⾏执⾏,打算提交到storm集群上去if(args != null && args.length > 0) {config.setNumWorkers(3);try {StormSubmitter.submitTopology(args[0], config, builder.createTopology());} catch (Exception e) {e.printStackTrace();}} else {// 说明是在eclipse⾥⾯本地运⾏config.setMaxTaskParallelism(20);LocalCluster cluster = new LocalCluster();cluster.submitTopology("WordCountTopology", config, builder.createTopology());Utils.sleep(60000);cluster.shutdown();}}} 部署⼀个storm集群(1)安装Java 7和Pythong 2.6.6(2)下载storm安装包,解压缩,重命名,配置环境变量(3)修改storm配置⽂件mkdir /var/stormconf/storm.yamlstorm.zookeeper.servers:- "111.222.333.444"- "555.666.777.888"storm.local.dir: "/mnt/storm"nimbus.seeds: ["111.222.333.44"] slots.ports,指定每个机器上可以启动多少个worker,⼀个端⼝号代表⼀个worker supervisor.slots.ports:- 6700- 6701- 6702- 6703(4)启动storm集群和ui界⾯⼀个节点,storm nimbus >/dev/null 2>&1 &三个节点,storm supervisor >/dev/null 2>&1 &⼀个节点,storm ui >/dev/null 2>&1 &(5)访问⼀下ui界⾯,8080端⼝提交程序到storm集群来运⾏将eclipse中的⼯程,进⾏打包storm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3(2)在storm ui上观察storm作业的运⾏(3)kill掉某个storm作业storm kill topology-name冷启动的问题:缓存冷启动,redis启动后,⼀点数据都没有,直接就对外提供服务了,mysql就裸奔(1)提前给redis中灌⼊部分数据,再提供服务(2)肯定不可能将所有数据都写⼊redis,因为数据量太⼤了,第⼀耗费的时间太长了,第⼆根本redis容纳不下所有的数据(3)需要根据当天的具体访问情况,实时统计出访问频率较⾼的热数据(4)然后将访问频率较⾼的热数据写⼊redis中,肯定是热数据也⽐较多,我们也得多个服务并⾏读取数据去写,并⾏的分布式的缓存预热(5)然后将灌⼊了热数据的redis对外提供服务,这样就不⾄于冷启动,直接让数据库裸奔了1、nginx+lua将访问流量上报到kafka中要统计出来当前最新的实时的热数据是哪些,我们就得将商品详情页访问的请求对应的流量,⽇志,实时上报到kafka中2、storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储⽅案优先⽤内存中的⼀个LRUMap去存放,性能⾼,⽽且没有外部依赖否则的话,依赖redis,我们就是要防⽌redis挂掉数据丢失的情况,就不合适了; ⽤mysql,扛不住⾼并发读写; ⽤hbase,hadoop⽣态系统,维护⿇烦,太重了只要统计出最近⼀段时间访问最频繁的商品,然后对它们进⾏访问计数,同时维护出⼀个前N个访问最多的商品list即可热数据,可以拿到最近⼀段,⽐如最近1个⼩时,最近5分钟,1万个商品请求,统计出最近这段时间内每个商品的访问次数,排序,做出⼀个排名前N的list计算好每个task⼤致要存放的商品访问次数的数量,计算出⼤⼩然后构建⼀个LRUMap,apache commons collections有开源的实现,设定好map的最⼤⼤⼩,就会⾃动根据LRU算法去剔除多余的数据,保证内存使⽤限制即使有部分数据被⼲掉了,然后下次来重新开始计数,也没关系,因为如果它被LRU算法⼲掉,那么它就不是热数据,说明最近⼀段时间都很少访问了3、每个storm task启动的时候,基于zk分布式锁,将⾃⼰的id写⼊zk同⼀个节点中4、每个storm task负责完成⾃⼰这⾥的热数据的统计,每隔⼀段时间,就遍历⼀下这个map,然后维护⼀个前3个商品的list,更新这个list5、写⼀个后台线程,每隔⼀段时间,⽐如1分钟,都将排名前3的热数据list,同步到zk中去,存储到这个storm task对应的⼀个zn的ode中去6、需要⼀个服务,⽐如说,代码可以跟缓存数据⽣产服务放⼀起,但是也可以放单独的服务每次服务启动的时候,就会去拿到⼀个storm task的列表,然后根据taskid,⼀个⼀个的去尝试获取taskid对应的znode的zk分布式锁如果能获取到分布式锁的话,那么就将那个storm task对应的热数据的list取出来然后将数据从mysql中查询出来,写⼊缓存中,进⾏缓存的预热,多个服务实例,分布式的并⾏的去做,基于zk分布式锁做了协调了,分布式并⾏缓存的预热。