第11章 因子分析
- 格式:ppt
- 大小:238.50 KB
- 文档页数:36


第十一章因子分析地理模型因子分析因子分析的主要应用1、寻求基本结构、简化观测系统给定一组变量或观测数据,我们要问,变量的维数是否一定需要这么多,是否存在一个子集,特别是一个加权子集,来解释整个问题。
通常采用因子分析法将为数不多的变量减少为几个新因子,以再现它们之间的内在联系。
2、用于分类,将变量或样本进行分类,根据因子得分值,在因子轴所构成的空间中进行分类处理。
因子分析与主成分分析的区别第一节因子分析法的数学模型因子分析的结果完全的因子解因子分析的基本问题是用变量之间的相关系数来决定因子载荷。
因子模型的求解过程如下:设原始数据矩阵为:X =p表示变量数,n表示样本数。
将原始数据进行标准化变换:x ij-x ix ij’=(I=1,2,…p;j=1,2,…n)经标准化变换后的数据,其均值为0,方差为1,这样相关矩阵R 和协方差矩阵S完全一样,这里相关矩阵:R=X*X’(为方便计,假定标准化处理后的矩阵仍记为X)。
求解R矩阵的特征方程|R=λI|=0,记特征值为λ1>λ2…>λp>=0,特征向量矩阵为U,这样有关系:R=U U’U为正交矩阵,并且满足U’U=UU’=I令F=U’X,则得FF’=F为主因子阵,并且Fα=U’Xα(α=1,2…n),即每一个Fα为第α个样品主因子观测值。
在因子分析中,通常只选m(m<p)其中主因子。
根据变量的相关选出第一主因子F1,使其在各变量的公共因子方差中所占的方差贡献最大。
R型的因子模型为X1=α11F1+α12F2+…+α1m F m +α1ε 1 X2=α21F1+α22F2+…+α2m F m +α2ε 2… …X P=αP1F1+αP2F2+…+αPm F m +αmεm在因子模型中2、αij叫因子载荷,它是第I个变量在第j个主因子上的负荷,或者叫第I个变量在第j个主因子上的权,它反映了第I个变量在第j个主因子上的相对重要性。
如果把x i看成m维因子空间上的一个向量,则αij表示x i在坐标轴F j上的投影。


《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第11章SPSS的因子分析1、简述因子分析的主要步骤是什么因子分析的主要步骤:一、前提条件:要求原有变量之间存在较强的相关关系。
二、因子提取。
三、使因子具有命名解释性:使提取出的因子实际含义清晰。
四、计算样本的因子得分。
2、对“基本建设投资分析.sav ”数据进行因子分析。
要求:1)利用主成分方法,以特征根大于1为原则提取因子变量,并从变量共同度角度评价因子分析的效果。
如果因子分析效果不理想,再重新指定因子个数并进行分析,对两次分析结果进行对比。
2)对比未旋转的因子载荷矩阵和利用方差极大法进行旋转的因子载荷矩阵,直观理解因子旋转对因子命名可解释性的作用。
“基本建设投资分析”因子分析步骤:分析降维因子分析导入全部变量到变量框中详细设置描述、抽取的设置如下: -相黄性舸阵[3□逆模型迥)显1F 性水平逞)□再生迟) □柠別式也)上厦映象追)V 邕M 。
和Bartiettm 形度橙验旋转、得分、选项的设置如下:./丘示圜子卷敘粗胖I 』[ai~J匚淙存n 欝童海© BarJet瞅■!圖丽药亟T 矗匸Q 脚dii*A3R 迟》0晰平即口甘描因亶除■£洞&式E 卜曲/ 牺削'■:诩|型J®J(3S1T ;■■ ■昌同子分疔信辻统计Statistics(1)表一是原有变量的相关系数矩阵。
由表可知,一些变量的相关系数都较高,呈较强的线由表二可知,巴特利特球度检验统计量的观测值为,相应的概率 性水平为,由于概率P-值小于显著性水平a,则应拒绝原假设,认为相关系数矩阵与单位P-值接近0.如果显著阵有显著差异,原有变量适合做因子分析。
同时, 量可以进行因子分析。
KMO 直为,根据KMC 度量标准可知原有变由表三可知,利用外资、自筹资金、其他投资等变量的绝大部分信息(大于 因子解释,这些变量的信息丢失较少。
但国家预算内资金这个变量的信息丢失较为严重(近80%。





第十一章 典型相关分析主成分分析、因子分析研究的是一组变量间或一组观测间的相互关系。
而当研究两组变量间的相互关系时,一般不采用各自的分析或两个变量一对一的直接分析。
例如,在研究一组环境因素与畜禽诸生产性能间的相关性时,通常是把各环境因素当作一个整体,把各生产性能也作一个整体来研究。
这时研究两个整体之间的相关可化为研究两个新变量之间的相关关系,而这两个新变量将分别由各自整体中变量的线性组合所构成,因此不会丢失原有诸变量的任何信息。
这样构成的两个新变量具有最大相关的性质。
类似地还可找出由两组变量构成的第二对线性组合,该组合与第一对线性组合不相关,但该对组合间有最大的相关。
如此类推,直到两组变量的相关被分解完毕。
这种逐步得到的线性组合称为典型变量,它们之间的相关系数称为典型相关系数。
这种分析方法称为典型相关分析(Canonical Correlations Analysis )。
可见,典型相关分析是研究两组变量之间相关关系的一种统计方法,它避免了孤立地对两个变量间的研究,分析结果较为全面,且各组中变量的个数不受限制,两组的内容可以不相同。
因此,应用十分广泛。
11.1 概述在实际工作中,通常接触到的多为样本资料,所以典型相关系数及典型变量多数是从样本资料中获取。
其计算方法如下。
设有两组变量X 1{x 1,x 2,…,x p }和X 2{x p+1,x p+2,…,x p+q }的n 次观察值,取自多元正态总体N p+q (μ,∑),由X[X 1,X 2]算得协差阵为∑的最大似然估计,若对X 1、,X 2进行标准化,此时协差阵为相关阵R :()()q p q p R R R R R ++⎥⎦⎤⎢⎣⎡=22211211其中R 11为第一组各变量间的相关系数阵,R 22为第二组各变量间的相关系数阵,'2112R R =各变量间的相关系数阵。
设P ≤q 解得特征方程()01222112212=--αλR R R R 或()02221211121=--βλR R R R的非零特征根22221r λλλ≥≥≥ (r ≤p )的算术平方根,即为典型相关系数。

多因素分析温州医学院环境与公共卫生学院叶晓蕾概念多因素分析是同时对观察对象的两个或两个以上的变量进行分析。
常用的统计分析方法有:多元线性回归、Logistic回归、COX比例风险回归模型、因子分析、主成分分析,等。
一、多元线性回归(multiple linear regressoin)Y,X——直线回归;Y,X1,X2,…X p——多元回归(多重回归)。
例:欲研究血压受年龄、性别、体重、性格、职业(体力劳动或脑力劳动)、饮食、吸烟、血脂水平等因素的影响。
一. 多元回归模型多元回归分析数据格式X2…X p Y 例号X11X11X12…X1p Y1 2X21X22…X2p Y2┆┆┆…┆┆n X n1X n2…X np Y nβ0为回归方程的常数项(constant),表示各自变量均为0时y 的平均值;p 为自变量的个数;β1、β2、βp 为偏回归系数(Partial regression coefficient )意义:如β1表示在X 2、X 3 …… X p 固定条件下,X 1 每增减一个单位对Y 的效应(Y 增减β个单位)。
e 为去除m 个自变量对Y 影响后的随机误差,或称残差(residual)。
eX X X Y p p +++++=ββββ 22110多元回归方程的一般形式为y 的估计值或预测值(predicted value);b 0为回归方程的常数项(constant),表示各自变量均为0时y 的估计值;pp X b X b X b b Y ++++= 22110ˆYˆ由样本估计而得的多元回归方程:b 1、b 2、b p 为偏回归系数(Partial regression coefficient )意义:如b 1表示在X 2、X 3 …… X p 固定条件下,X 1 每增减一个单位对Y 的效应(Y 增减b 个单位)。
适用条件:线性(linear)、独立性(independent)、正态性(normal)、等方差(equal variance)——―LINE‖。
第十一章因子分析11.1 主要功能11.2 实例操作11.1 主要功能多元分析处理的是多指标的问题。
由于指标太多,使得分析的复杂性增加。
观察指标的增加本来是为了使研究过程趋于完整,但反过来说,为使研究结果清晰明了而一味增加观察指标又让人陷入混乱不清。
由于在实际工作中,指标间经常具备一定的相关性,故人们希望用较少的指标代替原来较多的指标,但依然能反映原有的全部信息,于是就产生了主成分分析、对应分析、典型相关分析和因子分析等方法。
调用Data Reduction菜单的Factor过程命令项,可对多指标或多因素资料进行因子分析。
因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量,这与上一章的聚类分析不同),以较少的几个因子反映原资料的大部分信息。
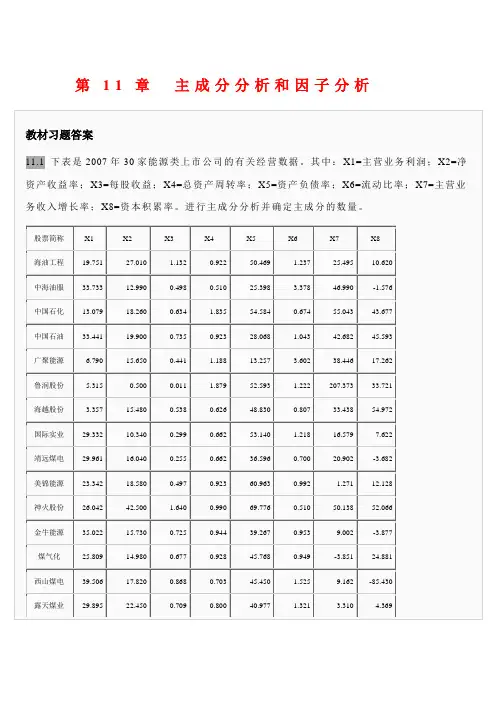
返回目录返回全书目录11.2 实例操作[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
11.2.1 数据准备激活数据管理窗口,定义变量名:分别为X1、X2、X3、X4、X5、X6、X7,按顺序输入相应数值,建立数据库,结果见图11.1。
图11.1 原始数据的输入11.2.2 统计分析激活Statistics 菜单选Data Reduction 的Factor...命令项,弹出Factor Analysis 对话框(图11.2)。
在对话框左侧的变量列表中选变量X1至X7,点击 钮使之进入Variables 框。
图11.2 因子分析对话框点击Descriptives...钮,弹出Factor Analysis:Descriptives对话框(图11.3),在Statistics中选Univariate descriptives项要求输出各变量的均数与标准差,在Correlation Matrix栏内选Coefficients项要求计算相关系数矩阵,并选KMO and Bartlett’s test of sphericity项,要求对相关系数矩阵进行统计学检验。
《统计分析与S P S S的应用(第五版)》课后练习答案(第11章)《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第11章SPSS的因子分析1、简述因子分析的主要步骤是什么?因子分析的主要步骤:一、前提条件:要求原有变量之间存在较强的相关关系。
二、因子提取。
三、使因子具有命名解释性:使提取出的因子实际含义清晰。
四、计算样本的因子得分。
2、对“基本建设投资分析.sav”数据进行因子分析。
要求:1)利用主成分方法,以特征根大于1为原则提取因子变量,并从变量共同度角度评价因子分析的效果。
如果因子分析效果不理想,再重新指定因子个数并进行分析,对两次分析结果进行对比。
2)对比未旋转的因子载荷矩阵和利用方差极大法进行旋转的因子载荷矩阵,直观理解因子旋转对因子命名可解释性的作用。
“基本建设投资分析”因子分析步骤:分析→降维→因子分析→导入全部变量到变量框中→详细设置……描述、抽取的设置如下:旋转、得分、选项的设置如下:(1)相关系数矩阵国家预算内资金(1995年、亿元)国内贷款利用外资自筹资金其他投资相关系数国家预算内资金(1995年、1.000 .458 .229 .331 .211亿元)国内贷款.458 1.000 .746 .744 .686利用外资.229 .746 1.000 .864 .776自筹资金.331 .744 .864 1.000 .928其他投资.211 .686 .776 .928 1.000 表一是原有变量的相关系数矩阵。
由表可知,一些变量的相关系数都较高,呈较强的线性关系,能够从中提取公共因子,适合进行因子分析。
KMO 和巴特利特检验KMO 取样适切性量数。
.706Bartlett 的球形度检验上次读取的卡方119.614自由度10显著性.000由表二可知,巴特利特球度检验统计量的观测值为119.614,相应的概率P-值接近0.如果显著性水平为0.05,由于概率P-值小于显著性水平α,则应拒绝原假设,认为相关系数矩阵与单位阵有显著差异,原有变量适合做因子分析。
【数据分析R语⾔实战】学习笔记第⼗⼀章对应分析11.2对应分析在很多情况下,我们所关⼼的不仅仅是⾏或列变量本⾝,⽽是⾏变量和列变量的相互关系,这就是因⼦分析等⽅法⽆法解释的了。
1970年法国统计学家J.P.Benzenci提出对应分析,也称关联分析、R-Q型因⼦分析,其是⼀种多元相依变量统计分析技术。
它通过分析由定性变量构成的交互汇总表,来揭⽰同⼀变量各类别之间的差异,以及不同变量各类别之间的对应关系,这是⼀种⾮常好的分析调查问卷的⼿段。
对应分析是⼀种视觉化的数据分析⽅法,其基⽊思想是将⼀个联列表的⾏和列中各元素的⽐例结构以点的形式在较低维的空间中表⽰出来,优点在于能够将⼏组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来,使⽤起来直观、简单、⽅便,因此⼴泛应⽤于市场细分、产品定位、地质研究以及计算机⼯程等领域。
11.2.1理论基础对应分析是寻求样⽊(⾏)与指标(列)之间联系的低维图⽰法,其关键是利⽤⼀种数据变换⽅法,使含有n个样本观测值和m个变量的原始数据矩阵x变成另⼀个矩阵z, z是⼀个过渡知阵,在接下来的计算中使⽤。
通过z将样本和变量结合起来。
11.2.2 R语⾔实现R中的程序包MASS提供了两个函数,corresp()⽤于做简单⼀的对应分析,mca()⽤于计算多重对应分析,通常使⽤前者,其调⽤格式为corresp(x,nf=1,……)x是数据矩阵:nf表⽰因⼦分析中计算因⼦的个数,通常取2.【例】> ch=data.frame(A=c(47,22,10),B=c(31,32,11),C=c(2,21,25),D=c(1,10,20))> rownames(ch)=c("Pure-Chinese","Semi-Chinese","Pure-English")> library(MASS)> ch.ca=corresp(ch,nf=2)> options(digits=4)> ch.caFirst canonical correlation(s): 0.5521 0.1409Row scores:[,1] [,2]Pure-Chinese 1.2069 0.6383Semi-Chinese -0.1368 -1.3079Pure-English -1.3051 0.9010Column scores:[,1] [,2]A 0.9325 0.9196B 0.4573 -1.1655C -1.2486 -0.5417D -1.5346 1.2773分析结果给出了两个因⼦对应⾏变量、列变量的载荷系数。